↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Selective Classification (SC) systems, which can reject low-confidence predictions, are crucial for real-world applications. However, current SC evaluation methods rely on pre-defined rejection thresholds, limiting a comprehensive performance assessment. This paper identifies 5 key requirements for improved metrics and shows how existing metrics fall short.
The authors propose the Area Under the Generalized Risk Coverage curve (AUGRC) as a new metric for SC evaluation. AUGRC meets all requirements, is directly interpretable as the average risk of undetected failures, and significantly alters metric rankings compared to existing methods. Empirical validation across six datasets and thirteen confidence scoring functions confirms the metric’s relevance and effectiveness in improving SC evaluation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with selective classification systems. It introduces a novel metric, AUGRC, addressing critical flaws in existing evaluation methods. This leads to more reliable and interpretable results, improving the design and benchmarking of SC systems and opening new avenues for methodological advancements in the field. The empirical validation on diverse datasets further strengthens its significance, making it a must-read for anyone involved in developing or evaluating SC systems.
Visual Insights#

This figure illustrates the proposed AUGRC metric and compares it to existing metrics for selective classification. Panel (a) shows the different evaluation approaches for selective classification: working-point evaluation versus multi-threshold evaluation. It highlights how the existing Area Under the Risk Coverage (AURC) curve uses the ‘Selective Risk’, which is not suitable for multi-threshold evaluation. Instead, the authors propose using the ‘Generalized Risk’ which leads to the new Area Under the Generalized Risk Coverage Curve (AUGRC) metric. Panel (b) summarizes five key requirements for multi-threshold metrics in selective classification. It then shows how the AUGRC metric satisfies these requirements, while existing metrics (AURC, e-AURC, AUROC, and Brier Score) do not.

This table shows the selected hyperparameters for the DeepGambler reward and dropout for different datasets used in the study. The selection is based on the AUGRC metric on the validation set. For each dataset, the table lists the selected hyperparameter value for different confidence scoring functions.
In-depth insights#
Selective Class. Eval#
Selective classification evaluation presents unique challenges compared to standard classification. Traditional metrics often focus on fixed thresholds, which fail to capture the overall performance across various rejection levels. A key insight is the need for multi-threshold metrics that comprehensively assess risk and coverage trade-offs. The paper emphasizes the importance of metrics that are task-aligned, interpretable, and flexible with respect to confidence scoring functions and error metrics. It critiques existing metrics like AURC and e-AURC for their shortcomings in meeting these criteria, particularly their failure to adequately reflect the holistic risk of undetected failures (silent failures). The proposed AUGRC metric offers a compelling alternative by directly addressing these issues and providing a more meaningful and interpretable evaluation of selective classification systems.
AUGRC Metric#
The AUGRC (Area Under the Generalized Risk Coverage curve) metric is a proposed solution to overcome limitations in evaluating selective classification (SC) systems. Current methods often rely on fixed thresholds, providing an incomplete performance picture. AUGRC addresses this by integrating performance across all possible rejection thresholds, offering a more holistic assessment. The metric is designed with key requirements in mind: task alignment (jointly evaluating classification and confidence scoring function quality), interpretability (directly interpretable as average risk of undetected failures), flexibility (adaptable to various confidence functions and error metrics), and monotonicity (improved metric value with improved factors). Empirical validation demonstrates AUGRC’s superiority over existing metrics, notably by changing metric rankings across multiple datasets and confidence scoring functions. This highlights AUGRC’s potential as a robust evaluation tool to drive methodological progress in the field of SC.
Empirical Study#
An empirical study section in a research paper provides crucial validation for the theoretical claims. It involves conducting experiments using real-world data and comparing the performance of different methods using suitable metrics. In this context, a robust empirical study should involve a comprehensive benchmark spanning multiple datasets and various conditions. The study should also rigorously test the proposed method against existing state-of-the-art approaches and include statistical analysis to ensure the reliability of the findings. The results should be presented clearly and comprehensively, including visualizations and statistical significance tests. The detailed description of the experimental setup, including data preprocessing and parameter tuning, is vital for reproducibility. Moreover, an in-depth discussion of the findings is needed, emphasizing the implications of the results and how they relate to the theoretical claims. A thoughtful analysis of the limitations of the study and suggestions for future work should also be included.
AURC Shortcomings#
The analysis of AURC shortcomings reveals its inability to holistically assess selective classification (SC) systems due to its reliance on selective risk, which focuses only on accepted predictions. This leads to an excessive weighting of high-confidence failures, distorting the overall performance assessment and violating monotonicity and interpretability requirements. The AURC’s limitations are further amplified by its insensitivity to different error functions, hindering its general applicability beyond accuracy-based evaluations. Empirical evidence demonstrates that the AURC produces misleading rankings of SC methods, highlighting its inadequacy for benchmarking and driving methodological progress in the field. A superior metric is needed that addresses these flaws to enable a more reliable evaluation of SC systems.
Future Directions#
Future research should explore extending the AUGRC’s applicability beyond binary classification tasks. Investigating its performance with multi-class problems and different loss functions would significantly broaden its utility. Another crucial area is refining the AUGRC’s behavior under various data distributions and tackling imbalanced datasets. A deeper theoretical analysis of AUGRC’s relationship to existing metrics, like AUROC and AURC, is also warranted. This could reveal potential synergies or limitations and inform the design of even more comprehensive SC evaluation methods. Furthermore, developing efficient computational approaches for AUGRC calculation is important, especially when dealing with massive datasets. Exploring AUGRC’s integration with uncertainty quantification techniques would enhance its ability to reliably assess the performance of SC systems in high-stakes settings.
More visual insights#
More on figures
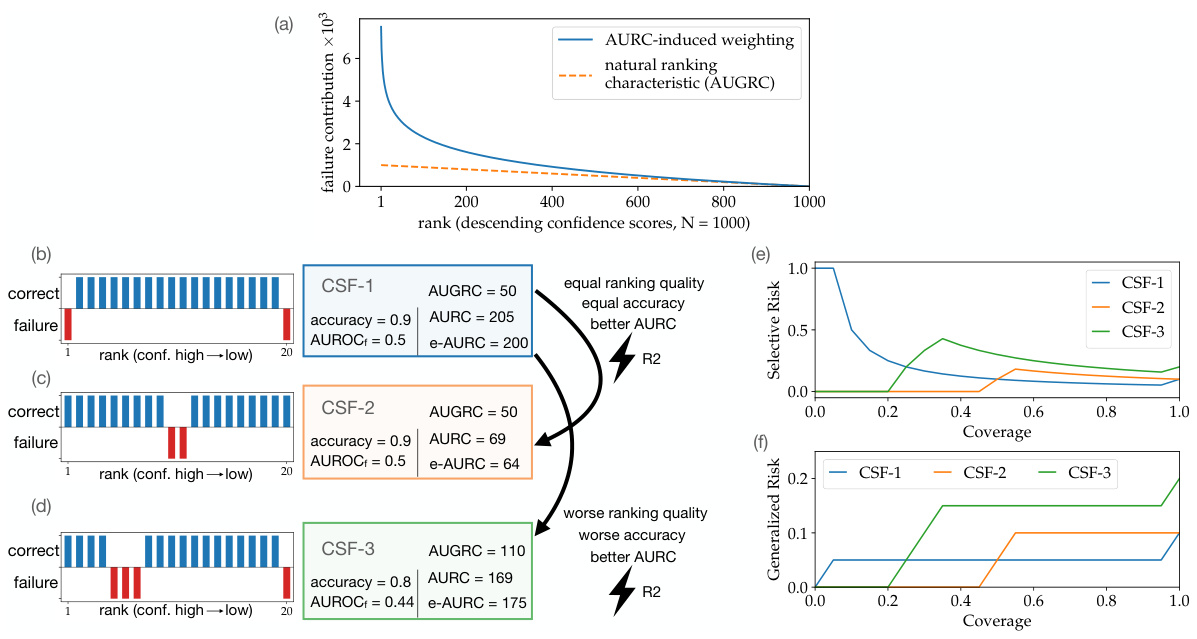
This figure demonstrates the advantages of the proposed AUGRC metric over the existing AURC metric for evaluating selective classification systems. It highlights how AUGRC addresses the shortcomings of AURC by providing a more intuitive and robust measure of system performance. The figure uses a combination of visualizations (graphs and diagrams) to illustrate the different weighting schemes of AUGRC and AURC for failure cases across various confidence levels, showing how AUGRC avoids the excessive weighting of high-confidence failures that is present in AURC. This results in a more consistent and meaningful evaluation, especially when assessing the general performance of the system across multiple thresholds, addressing the monotonicity problems of AURC.
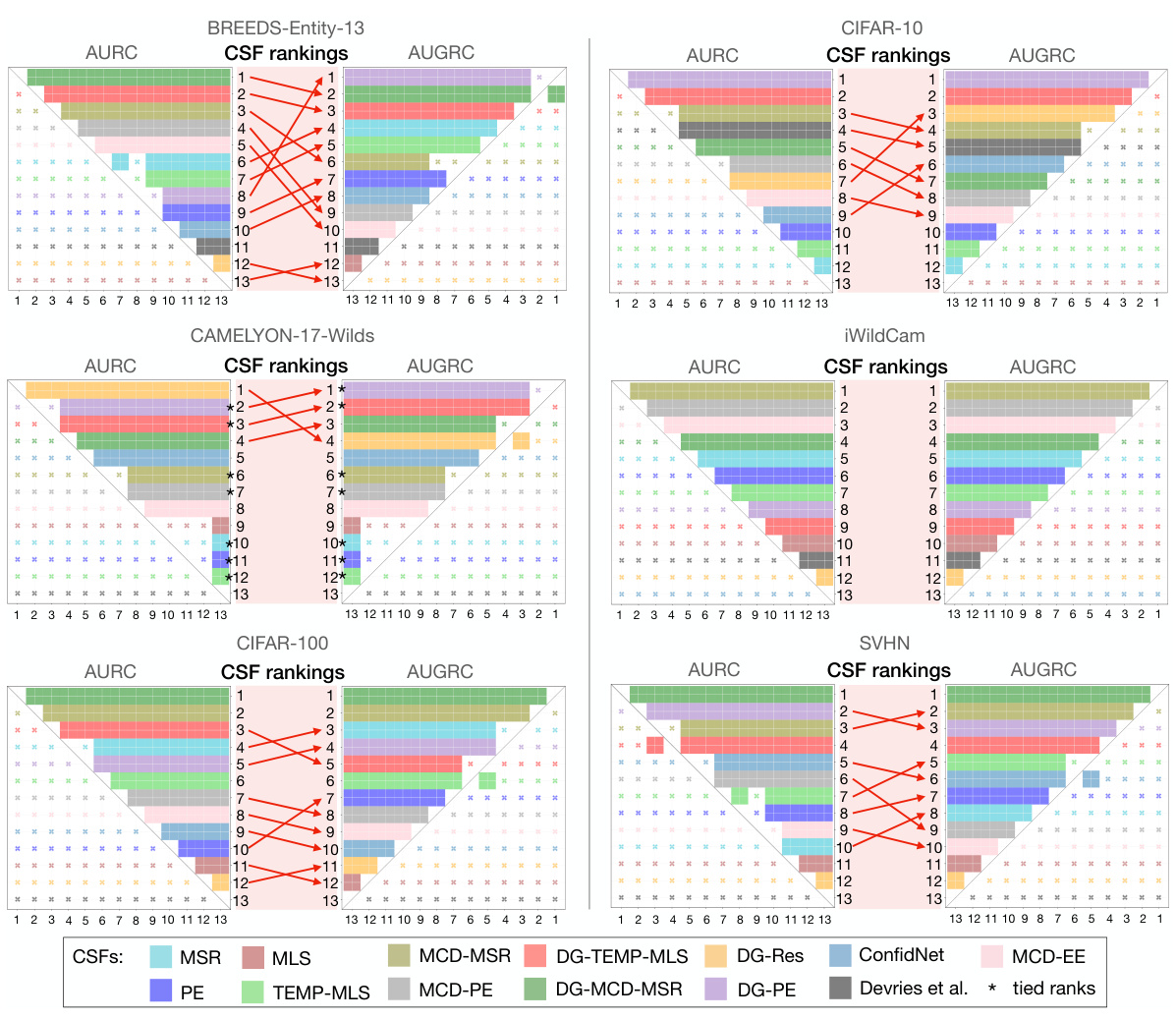
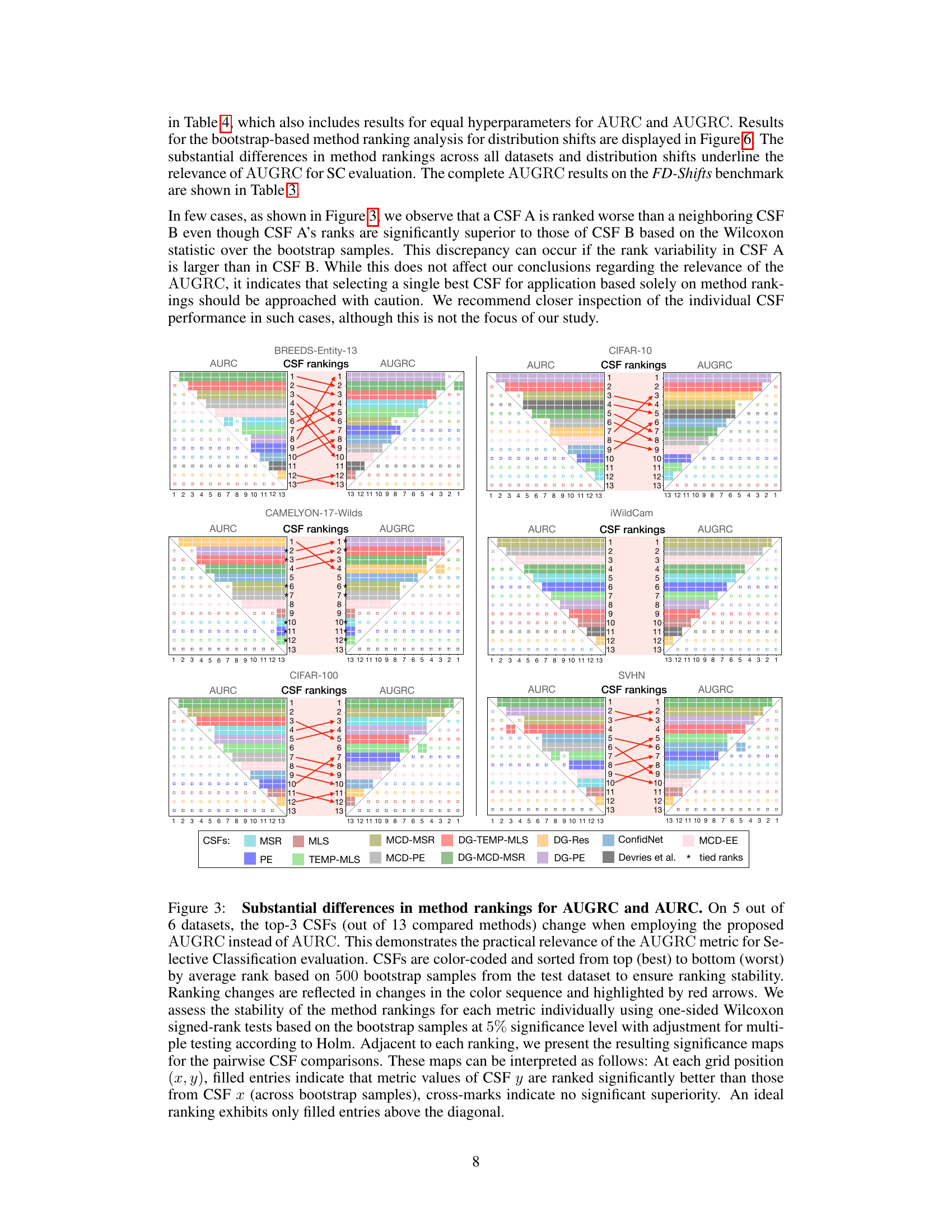
This figure compares the ranking of 13 confidence scoring functions (CSFs) for selective classification using two different metrics: AUROC and AUGRC. It shows that the AUGRC metric leads to substantially different rankings of CSFs compared to the AURC, especially in the top-performing CSFs. The visualization helps to understand the impact of metric choice on CSF evaluation.
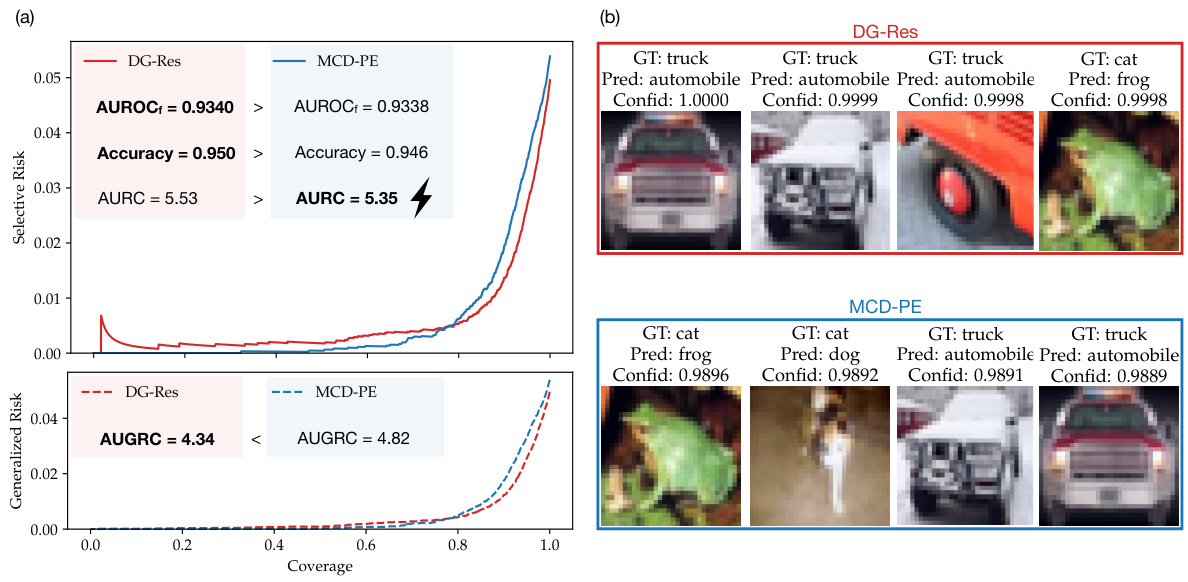
This figure demonstrates how the proposed AUGRC metric addresses the shortcomings of the existing AURC metric in evaluating selective classification systems. It highlights the differences in how AUGRC and AURC weigh the contribution of individual failure cases based on their confidence scores, showing that AUGRC provides a more intuitive and accurate assessment. The figure uses a toy example and risk-coverage curves to illustrate how AUGRC overcomes the issues of monotonicity and ranking interpretability present in AURC.

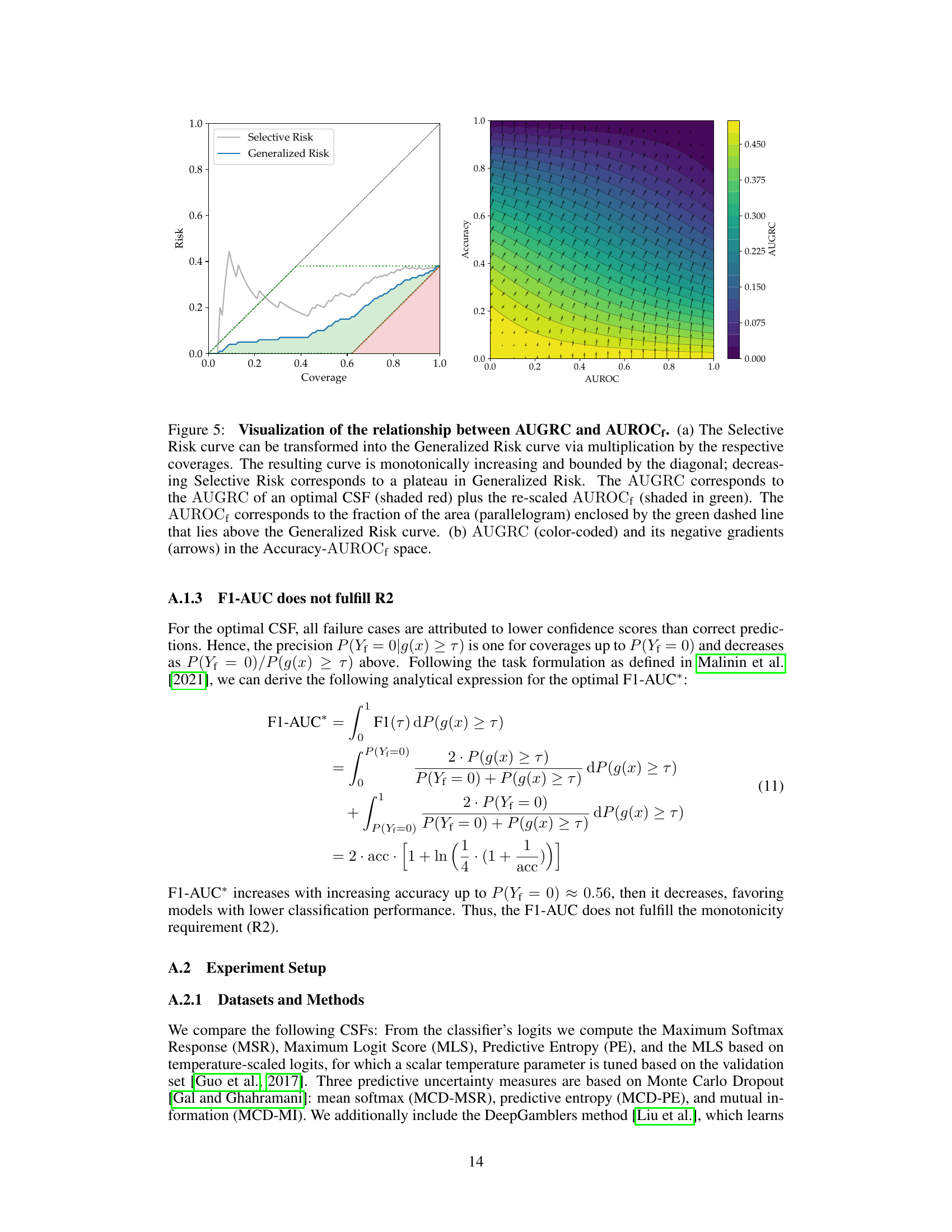
This figure visualizes the relationship between AUGRC and AUROCf. Panel (a) shows how the Selective Risk curve can be transformed into the Generalized Risk curve by multiplying by the respective coverages. The AUGRC is shown to be composed of the AUGRC of an optimal CSF (shaded red) plus the rescaled AUROC (shaded green). The AUROCf is visualized as the fraction of the area above the Generalized Risk curve. Panel (b) shows a heatmap of the AUGRC values (color-coded) and the negative gradients (arrows) plotted in the Accuracy-AUROCf space.

This figure compares the ranking of 13 confidence scoring functions (CSFs) for selective classification using two different metrics: AUROC and AUGRC. The results show that the AUGRC metric leads to substantially different rankings of the CSFs compared to AURC, highlighting the importance of AUGRC for a more accurate evaluation of selective classification systems. The figure uses color-coding and statistical significance testing to illustrate the differences and the stability of the rankings.
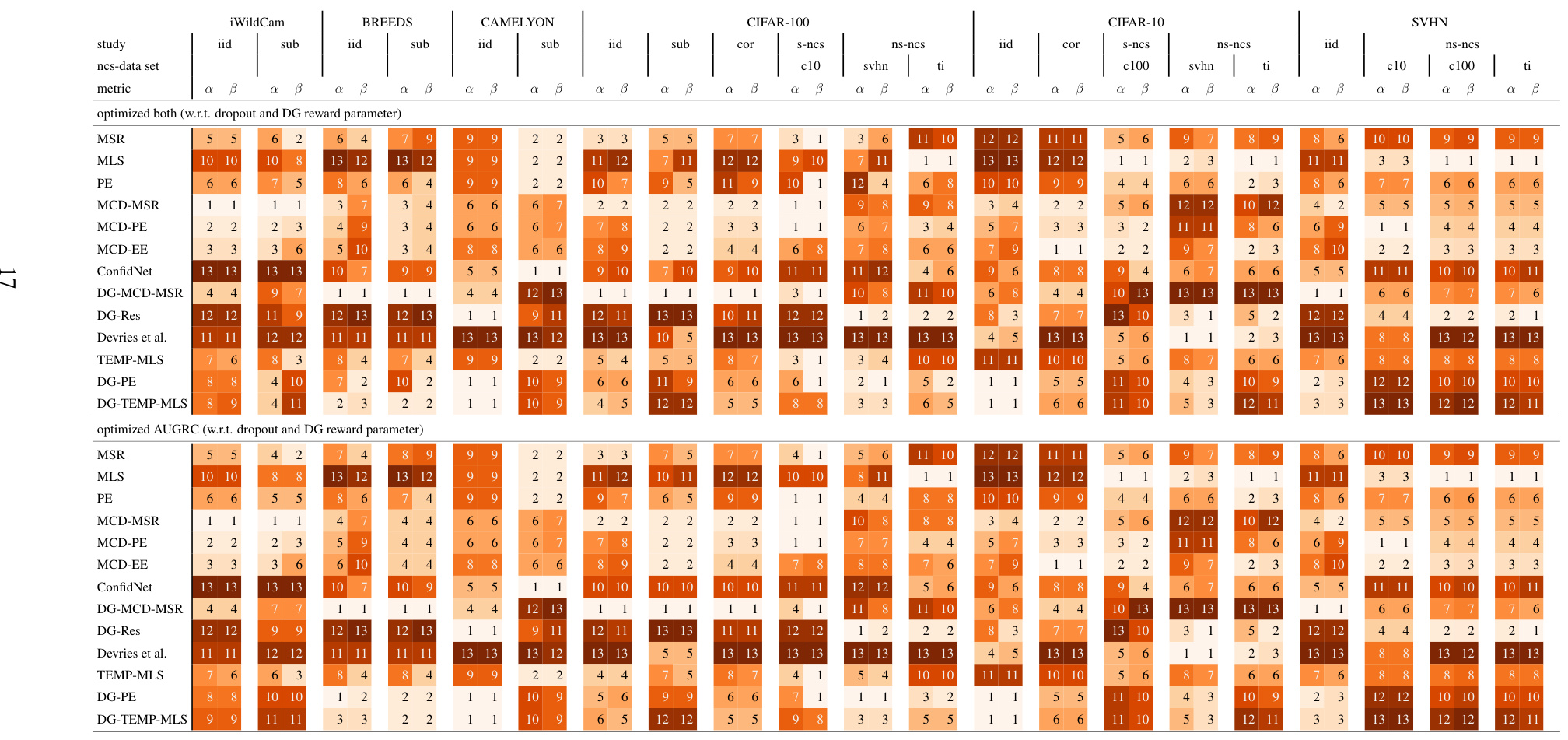
Figure 3 shows that using AUGRC instead of AURC changes the ranking of the confidence scoring functions (CSFs) significantly. It highlights the practical importance of AUGRC as a superior evaluation metric for selective classification. The figure visually compares the rankings of 13 CSFs across six datasets using both AUGRC and AURC metrics, demonstrating the considerable differences that arise when adopting the proposed AUGRC metric. The figure also includes statistical significance testing to validate the robustness of the observed ranking differences.

This figure compares the ranking of 13 confidence scoring functions (CSFs) for selective classification using two different metrics: AURC and AUGRC. The key finding is that AUGRC leads to substantially different rankings compared to AURC, highlighting the importance of using the AUGRC metric. The visualization uses color-coding and significance maps to show the stability and differences in rankings.
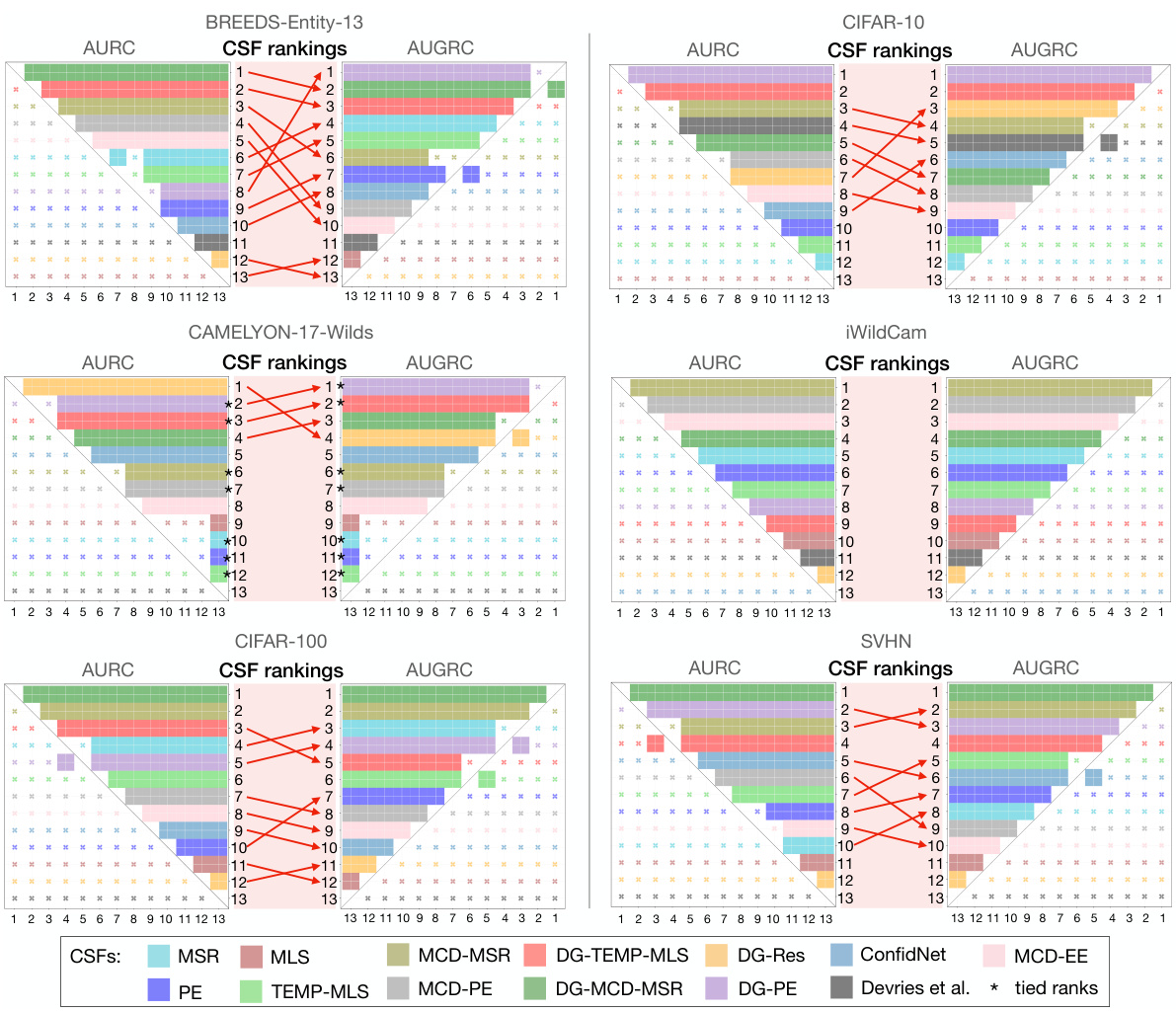
This figure compares the ranking of 13 confidence scoring functions (CSFs) using two different metrics: AUROC and AUGRC. It shows that the rankings significantly differ between the two metrics, especially for the top 3 performing CSFs. The differences highlight the AUGRC’s ability to provide a more reliable and practical evaluation of selective classification systems.
Full paper#