↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current generative retrieval methods struggle with multi-graded relevance data, limiting their real-world applicability. The challenge lies in reconciling likelihood probabilities for docid pairs and handling multiple relevant documents with the same identifier. This often leads to less effective ranking systems that do not accurately reflect the varying degrees of relevance among documents.
The proposed GR2 framework directly addresses these issues. It introduces a novel multi-graded constrained contrastive (MGCC) loss function and a regularized fusion approach for docid generation. The MGCC loss leverages the relationships between relevance grades to guide the training process, while the regularized fusion ensures semantically relevant and distinct identifiers. The results demonstrate that GR2 significantly outperforms existing methods across various benchmark datasets, showing its effectiveness in both binary and multi-graded relevance scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between generative retrieval (GR) and multi-graded relevance, a significant limitation in current IR research. By introducing a novel framework that handles multi-graded relevance data effectively, the study opens doors for improved information retrieval systems and inspires further investigation into more nuanced ranking models. It offers a significant advancement in a rapidly evolving field and directly impacts the design and evaluation of next-generation search systems.
Visual Insights#
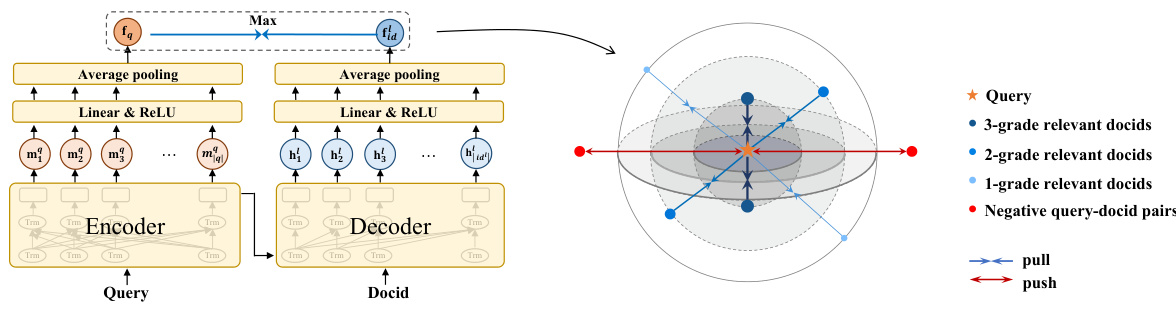
This figure illustrates the overall architecture of the proposed GR2 framework for generative retrieval. It uses a sequence-to-sequence (Seq2Seq) encoder-decoder model. The encoder processes queries and the decoder generates relevant document identifiers (docids). The key innovation is the use of a multi-graded constrained contrastive loss function to better handle multi-graded relevance judgments, where documents can have varying degrees of relevance to a given query. The figure also shows how the framework generates relevant and distinct docids, crucial for effective retrieval, and how the contrastive loss pulls representations of queries and relevant docids closer together based on their relevance grades while pushing away representations of irrelevant docids.
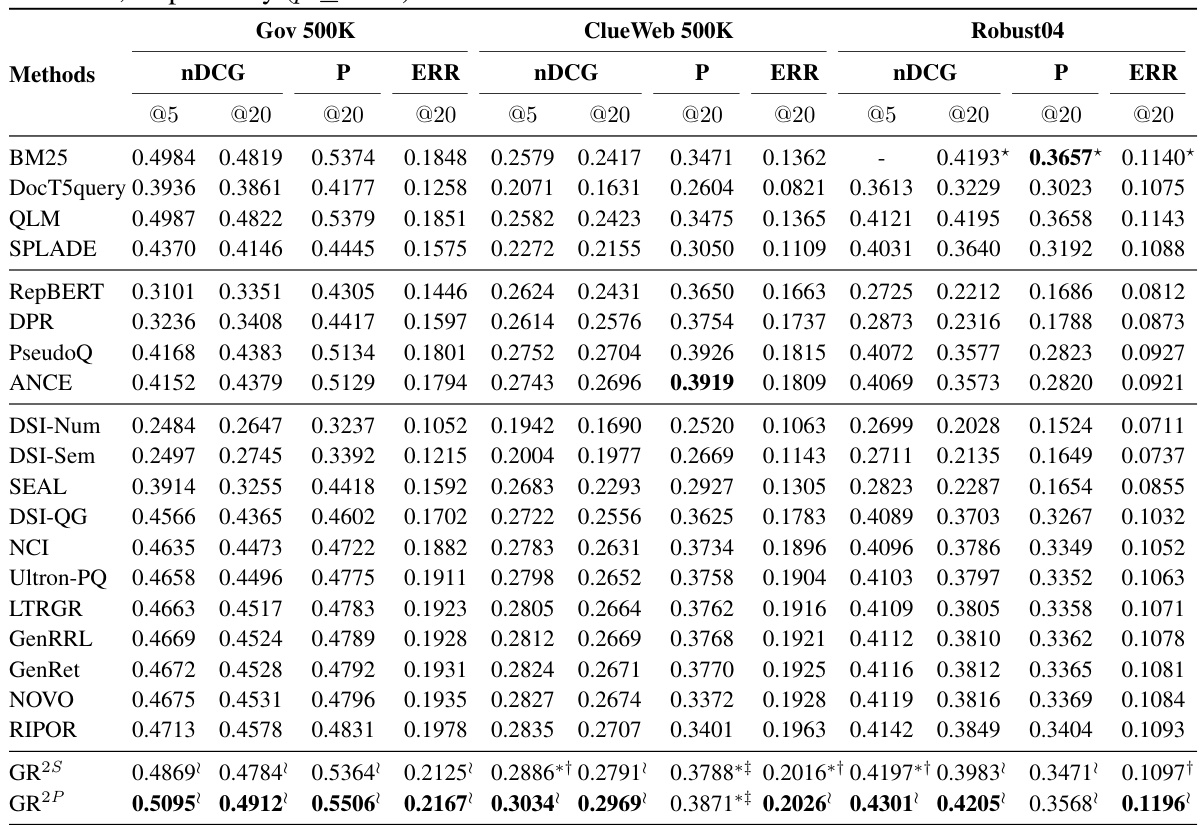
This table presents the experimental results of various generative retrieval models and baselines on three datasets with multi-graded relevance. It compares the performance of these models using several evaluation metrics (nDCG@5, nDCG@20, P@20, ERR@5, ERR@20). The results highlight the statistically significant improvements achieved by the proposed GR2 model over other baselines, particularly in terms of precision and NDCG.
In-depth insights#
Multi-Grade GR#
Multi-Grade Generative Retrieval (GR) signifies a substantial advancement in information retrieval, moving beyond the limitations of binary relevance models. Its core innovation lies in effectively handling documents with varying degrees of relevance to a given query, enriching the retrieval process with nuanced judgments of relevance. This approach directly addresses the limitations of existing GR methods which typically only handle binary relevance classifications (relevant or irrelevant). By incorporating multi-graded relevance scores, Multi-Grade GR allows for more accurate ranking and retrieval of documents, better reflecting the complexities of real-world information needs. This enhanced granularity is crucial, especially in scenarios demanding fine-grained distinctions in document ranking. The technique is likely to utilize advanced loss functions that consider the ordinal nature of the grades and innovative methods for generating and optimizing document identifiers to represent various relevance grades. The ability to integrate such multi-graded data will likely lead to improvements in overall retrieval performance and accuracy, creating a more effective and robust information retrieval system. Key challenges addressed by Multi-Grade GR include reconciling different likelihood probabilities across various relevance grades and managing multiple relevant documents with the same identifier. Addressing these challenges results in a sophisticated system capable of handling intricate relevance patterns.
Docid Fusion#
Docid fusion, as a technique, aims to improve both the relevance and distinctiveness of document identifiers (docids). The core idea is to combine the strengths of different docid generation methods, often involving a query generation (QG) model and an autoencoder (AE) model. The QG model generates pseudo-queries representing documents, while the AE model reconstructs original docids from their representations. Joint optimization of these modules ensures docids are semantically relevant to their corresponding documents yet sufficiently distinct to avoid ambiguity when multiple documents share similar content. This approach is particularly valuable in generative retrieval where a single model directly produces docids for a given query. By regularizing the fusion process, it becomes possible to achieve a balance between semantic relevance and unique representation, improving the overall performance of the retrieval system. The regularization terms might incorporate measures to maximize similarity between a document and its generated docid while simultaneously increasing the distances between docids of different documents, thereby enhancing distinctiveness and overall retrieval performance. The outcome is a more robust and efficient system for information retrieval tasks, especially in scenarios dealing with multi-graded relevance judgments.
MGCC Loss#
The proposed Multi-Graded Constrained Contrastive (MGCC) loss function is a novel approach to training generative retrieval models for multi-graded relevance. It addresses the limitations of existing methods that primarily focus on binary relevance by incorporating information about the relationships between different relevance grades. MGCC achieves this by employing a grade penalty to pull representations of queries and relevant documents closer together, with the strength of the pull being proportional to the relevance grade. This ensures that highly relevant documents are more strongly associated with the query than moderately relevant ones. Furthermore, the method integrates a grade constraint that helps maintain the order of relevance grades in the embedding space. This is crucial for preserving the hierarchical structure of relevance judgments and enhances the model’s ability to discriminate between different levels of relevance. Overall, the MGCC loss presents a significant advancement in generative retrieval by effectively handling multi-graded relevance data, leading to improved retrieval performance.
GR2 Framework#
The GR2 framework presents a novel approach to generative retrieval, addressing limitations of existing methods which primarily focus on binary relevance. GR2 tackles multi-graded relevance, a more realistic scenario where documents possess varying degrees of relevance to a given query. This is achieved through two key components: docid design, employing a regularized fusion approach to generate semantically relevant and distinct identifiers, and multi-graded constrained contrastive (MGCC) training, which leverages the relationships between different relevance grades to improve the quality of generated docids. This framework ensures that generated identifiers effectively represent individual documents and incorporates graded relevance information directly into the training process, thereby overcoming challenges related to likelihood probability reconciliation and the handling of multiple relevant documents with identical identifiers. The result is a more effective and nuanced approach to generative retrieval, surpassing existing methods in experimental evaluations and demonstrating the robustness of GR2 across both multi-graded and binary relevance datasets. The combination of enhanced docid design and sophisticated training methodology contributes to GR2’s superior performance.
Future of GR#
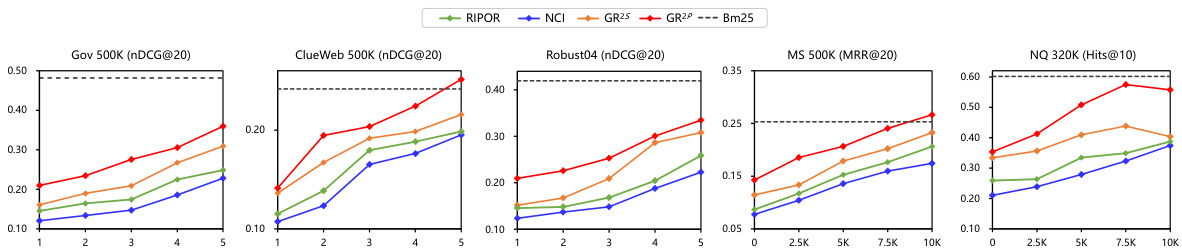
The future of Generative Retrieval (GR) is promising, yet faces significant challenges. Scalability to ultra-large datasets remains a key hurdle; current methods struggle with corpora beyond millions of documents. Addressing this requires innovative indexing and retrieval techniques that handle both efficiency and semantic richness. Multi-graded relevance is another important area; expanding GR beyond binary relevance to model nuanced relevance degrees will enhance search results. This necessitates advanced loss functions and training strategies that capture the relationships between varying relevance levels. Furthermore, research into efficiency is crucial. While GR offers the potential for reduced latency, its current implementations sometimes exhibit slower inference times compared to traditional methods. Optimizing model architectures and algorithms for faster processing is essential for widespread adoption. Finally, exploring the ethical implications of GR, including issues of bias and misinformation, is paramount. Building robust safeguards and responsible release mechanisms is critical for mitigating potential harm.
More visual insights#
More on figures

This figure illustrates the overall architecture of the GR2 model proposed in the paper. It shows a sequence-to-sequence (Seq2Seq) encoder-decoder model that takes a query as input and outputs a ranked list of relevant document identifiers (docIDs). The key innovation is the use of a multi-graded constrained contrastive loss function to model the relationships between different grades of relevance for the docIDs. The figure also highlights how relevant and distinct docIDs are generated using a regularized fusion approach. The model pulls the query representation closer to the representations of its relevant docIDs and pushes it away from the irrelevant ones, with the strength of the pull/push determined by the relevance grades.
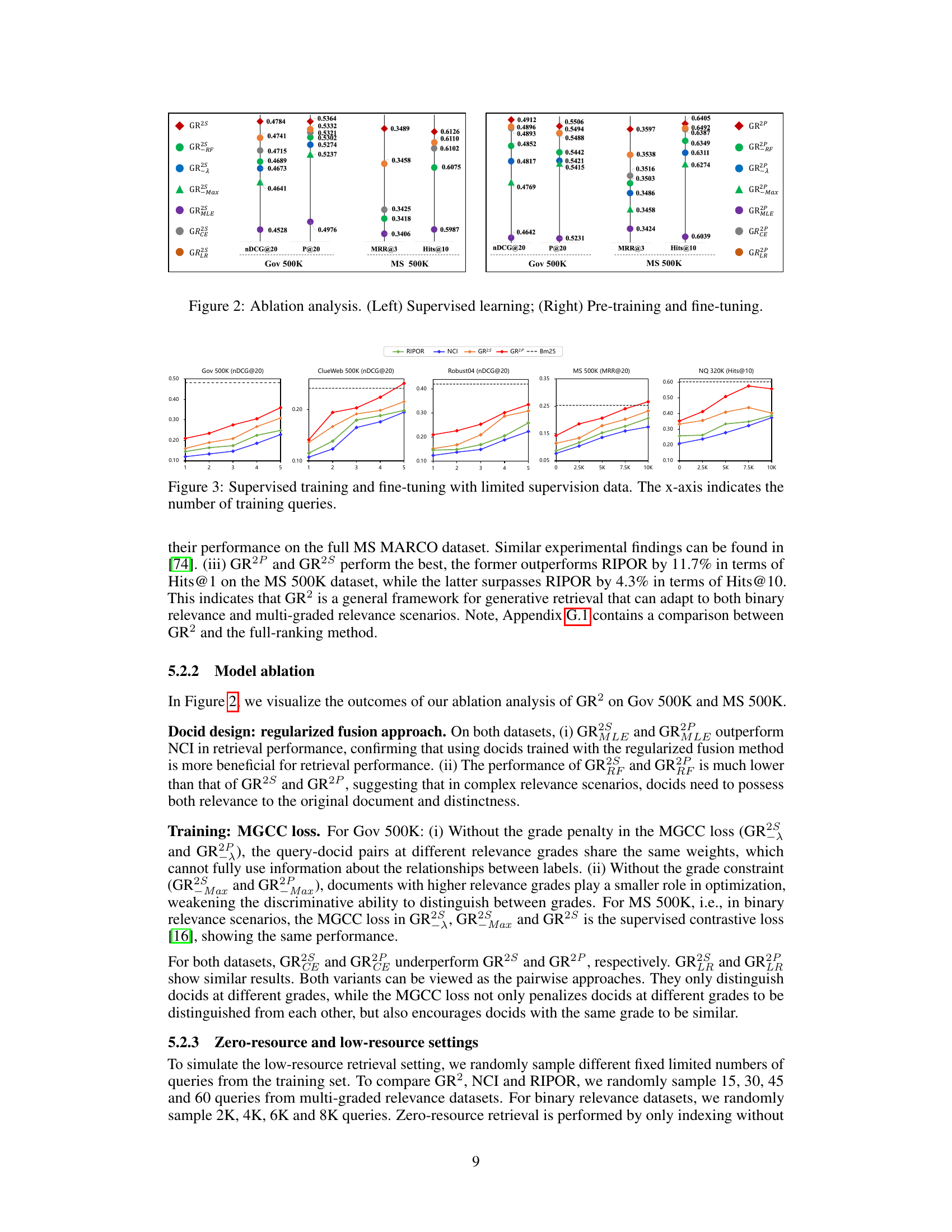
This ablation study analyzes the impact of different components of the GR2 model on its performance. The left panel shows the results for supervised learning, while the right panel presents the results for pre-training and fine-tuning. The figure compares various configurations of the GR2 model against baselines on different datasets (Gov 500K, MS 500K, etc.) and metrics (nDCG@20, P@20, MRR@3, Hits@10). By systematically removing or modifying specific parts of the GR2 model, such as the regularized fusion approach, the MGCC loss, or the pre-training stage, the authors evaluate the contribution of each component to the overall performance. This helps to demonstrate the effectiveness and robustness of each component within the GR2 framework and highlights the impact of using both supervised learning and pre-training.

This figure visualizes the query and document representations learned by three different models: GR2P, RIPOR, and NCI. t-SNE is used to reduce the dimensionality of the data for visualization. Each point represents a document, colored according to its relevance grade to the query (red: query, green: 2-grade relevant, blue: 1-grade relevant, gray: irrelevant). GR2P shows clear clustering of documents by relevance grade, with higher-grade documents closer to the query. In contrast, RIPOR and NCI show less clear separation, indicating that GR2P better captures the relationships between query and documents across different relevance grades.

This figure illustrates the architecture of the regularized fusion approach used for docid design. It consists of two main components: a query generation (QG) model and an autoencoder (AE) model. Both models employ an encoder-decoder structure, sharing the same decoder. The QG model takes a document (d) as input, generates a pseudo-query (eQG), and reconstructs the original document (d) using the decoder. The AE model takes a query (q) as input, generates a query embedding (eAE), and reconstructs the query (q) via the decoder. The training process jointly optimizes both the relevance and distinctness of generated docids by leveraging two regularization terms: LRel which encourages the representation of the document and pseudo-query to be close to each other and LDiv which pushes away the representations of different documents in the document space and different docids in the docid space.
More on tables
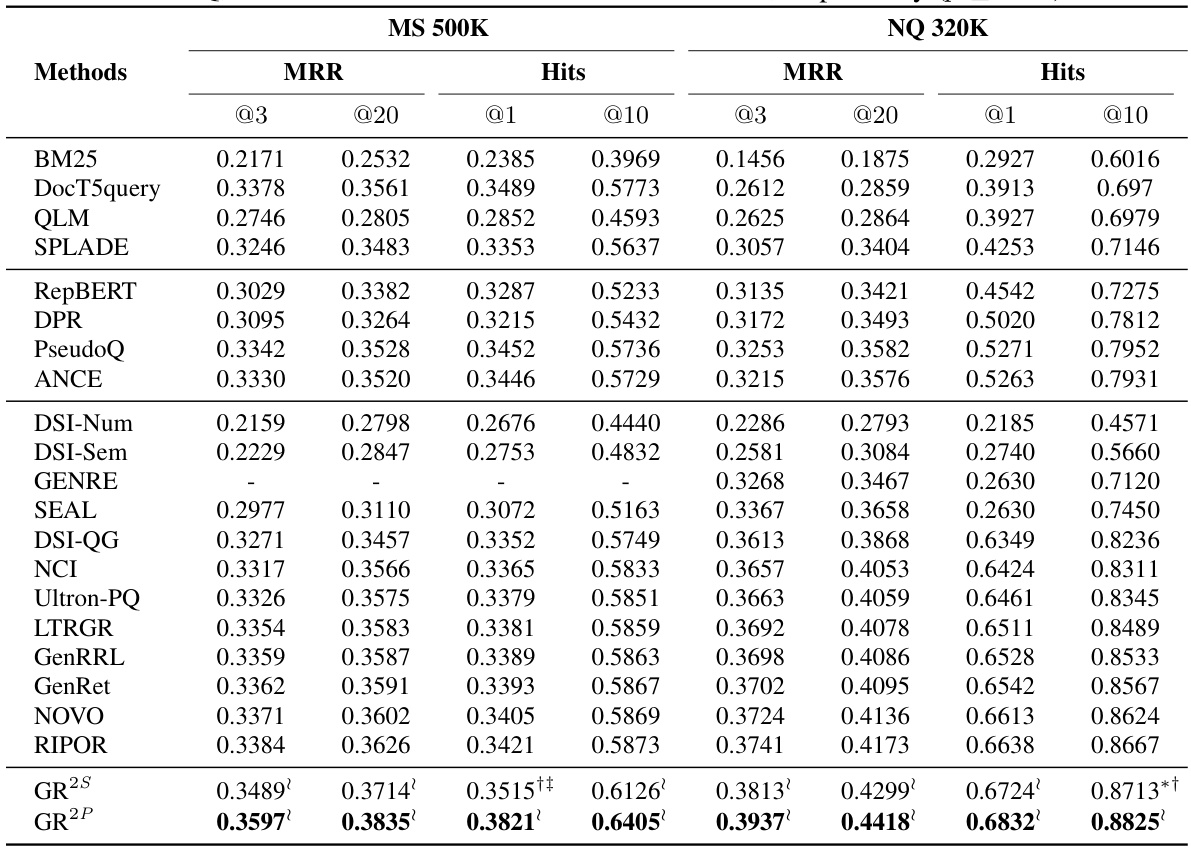
This table presents the performance of various information retrieval methods on datasets with multi-graded relevance. It compares the proposed GR2 method (GR2S and GR2P) against several baselines categorized as sparse retrieval (SR), dense retrieval (DR), and generative retrieval (GR) methods. The results are evaluated using nDCG@5, nDCG@20, ERR@20, and P@20 metrics, showing GR2’s statistically significant improvements over existing state-of-the-art methods.
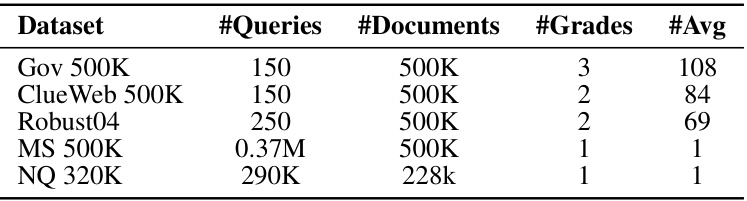
This table presents the statistics of five datasets used in the paper’s experiments. For each dataset, it shows the number of labeled queries, the number of documents, the number of relevance grades, and the average number of relevant documents per query. The datasets include multi-graded relevance datasets (Gov 500K, ClueWeb 500K, Robust04) and binary relevance datasets (MS 500K, NQ 320K).

This table compares the performance of different generative retrieval (GR) methods against a full-ranking baseline (BM25+monoBERT) on two datasets: Gov 500K and MS 500K. The GR methods are RIPOR and GR2P. The asterisk (*) indicates statistically significant improvements (p < 0.05) of BM25+monoBERT compared to GR2P. The table shows nDCG@5 and MRR@20 scores for each method on each dataset. This comparison highlights the performance gap between the purely generative retrieval approaches and those that combine sparse retrieval with re-ranking.
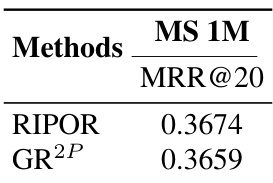
This table presents the performance comparison between RIPOR and GR2P on the MS 1M dataset, a million-scale dataset. The results show MRR@20 for both methods, indicating that GR2P achieves comparable results to RIPOR on a large-scale dataset, despite GR2P being designed with a multi-graded relevance approach.
Full paper#