↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current 3D generation methods often struggle with incomplete object representation, focusing mainly on visible surfaces. This limitation hinders the creation of realistic and accurate 3D models, particularly from single-view inputs. Existing methods rely on rendering techniques, which inherently struggle to capture hidden information. They lack the ability to understand and reconstruct complete 3D shapes.
The paper introduces X-Ray, a novel sequential 3D representation inspired by X-ray scans. X-Ray transforms a 3D object into a sequence of surface frames at various depths, capturing detailed geometric and textural features. This multi-frame representation is similar to a video, enabling the use of efficient video diffusion models for generation. The two-stage pipeline first uses a diffusion model to create a low-resolution X-Ray, followed by an upsampler to enhance resolution and a mesh decoder to construct the final 3D model. This approach significantly improves the quality and completeness of 3D object generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D generation due to its novel X-Ray representation, which overcomes limitations of existing methods by capturing both visible and hidden surfaces. This opens exciting avenues for improving 3D model accuracy and efficiency, especially in areas like image-to-3D and video processing. The proposed generative model, based on video diffusion models, significantly improves the quality of 3D object generation and sets a new benchmark for image-to-3D modeling.
Visual Insights#
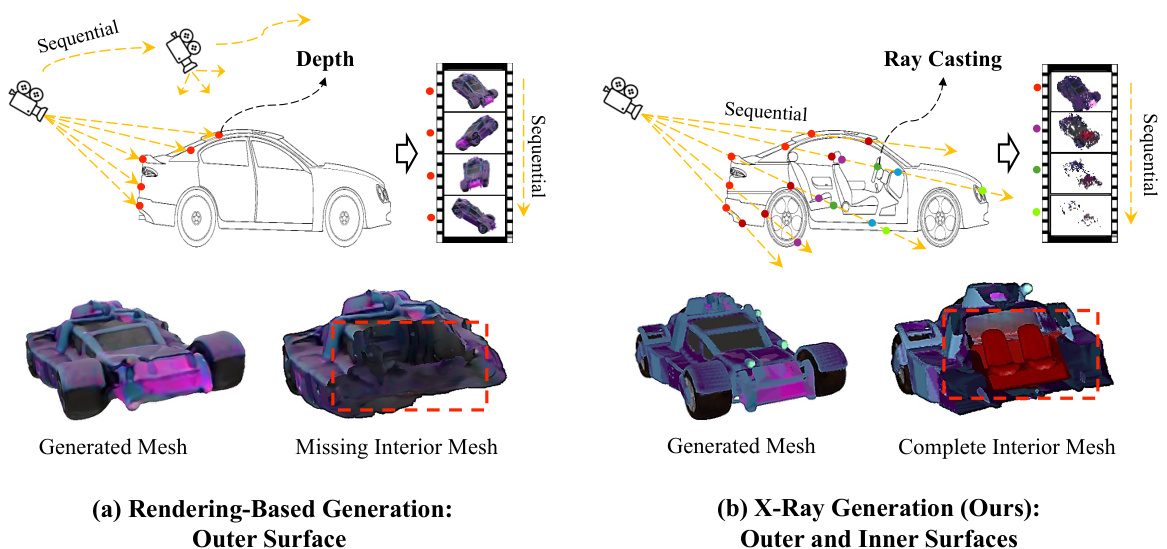
This figure compares two different approaches to 3D object generation: rendering-based and the authors’ proposed X-Ray method. Rendering-based methods typically use multiple camera views to reconstruct only the visible outer surface of an object, resulting in incomplete 3D models with missing interior details. The X-Ray method, on the other hand, uses a single camera view and leverages ray casting to capture both visible and hidden surfaces, generating complete 3D models with full interior details. The bottom row shows a visual comparison of the results, highlighting the difference in completeness between the two approaches.

This table compares the efficiency of five different 3D representations: 3D Grid, Multi-View Depths, MPI, Point Cloud, and X-Ray. For each representation, it provides the memory usage, encoding method, encoding time, decoding method, decoding time, and Chamfer Distance (CD). The metrics are designed to evaluate the efficiency of each representation for 3D generation. Lower values for Memory, Encoding Time, Decoding Time, and CD indicate better efficiency. The X-Ray representation shows a significant advantage in terms of memory usage and encoding time compared to other methods.
In-depth insights#
X-Ray Encoding#
The X-Ray encoding method is a novel approach to represent 3D objects that leverages the concept of X-ray penetration. Unlike traditional methods that focus on visible surfaces, X-Ray encoding captures both visible and hidden surfaces. The process involves ray casting from a camera’s viewpoint, intersecting with the object’s surface at multiple layers. For each intersection, geometric and textural attributes are recorded, such as depth, normal, color, and a hit indicator. This data forms a sequential multi-frame representation, creating a video-like format suited for video diffusion models. This approach elegantly condenses complex 3D geometry into a compact and efficient representation, enhancing both accuracy and efficiency, especially in situations where internal object structures are important.
3D Generation#
The paper explores 3D object generation, focusing on the limitations of existing methods. Current approaches often struggle to represent and generate complete 3D models, particularly capturing hidden surfaces. The authors introduce X-Ray, a novel 3D representation inspired by X-ray scans, enabling the capture of both visible and hidden surfaces from a single viewpoint. This sequential representation, structured like a video, leverages the power of video diffusion models for efficient generation. X-Ray’s multi-layer surface frames condense 3D information while maintaining efficiency, addressing the incompleteness inherent in traditional rendering-based methods. The proposed two-stage pipeline, utilizing a diffusion model and upsampler, demonstrates state-of-the-art results in 3D object generation from single images. A key aspect is the demonstration of superior accuracy and completeness compared to existing methods, showcased by quantitative and qualitative evaluations. While the approach demonstrates promising capabilities, limitations regarding complex scenes and layer handling are acknowledged.
Efficiency Analysis#
An efficiency analysis of a 3D object representation method would typically involve a multifaceted examination. It would start by quantifying the memory footprint of the representation itself, comparing it to existing alternatives like meshes, point clouds, or voxel grids. This comparison should consider the impact of factors such as object complexity and resolution on memory usage. Next, the analysis should assess the computational cost of encoding and decoding the representation. This means measuring the time required for encoding a 3D model into the new representation, and the time needed to reconstruct the model from the representation. Benchmarks against existing methods are crucial for demonstrating the efficiency gains or trade-offs. Crucially, the analysis must also address the scalability of the approach: how does the memory usage and processing time scale with the complexity of the scene or the resolution of the model? A truly efficient method should exhibit good scalability, showing linear or near-linear growth rather than exponential growth. Finally, the analysis needs to demonstrate the efficiency gains translate to real-world applications in terms of speed and resource usage in tasks such as 3D model generation or manipulation.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, an ablation study on a 3D object generation model might involve progressively removing elements such as the depth, normal, or color channels from the X-Ray representation, or perhaps disabling specific model components like the diffusion model or upsampler. By observing how the model’s performance degrades after each removal, researchers can quantify the importance of each component and identify potential weaknesses or redundancies. The results might reveal that certain features (e.g., normal vectors) significantly contribute to accuracy, while others are less critical. This allows for model optimization by streamlining less impactful parts or focusing development efforts on crucial components. A well-executed ablation study not only improves the model but offers valuable insights into its inner workings, enhancing understanding and guiding future research directions.
Future Works#
The paper’s core contribution, X-Ray, presents exciting avenues for future research. Improving the efficiency of the two-stage generation process is crucial; the current method, while effective, could benefit from optimizations, perhaps via exploring more efficient architectures for video diffusion models or refining the upsampling technique. Addressing the limitations of the current model in handling high-complexity objects is another key area. The inability to accurately represent objects with a very large number of layers warrants investigating alternative encoding strategies or techniques for managing highly complex surface geometry. Furthermore, while the paper demonstrates impressive results in image-to-3D generation, extending X-Ray to other 3D generation tasks such as 3D shape completion, 3D object retrieval, and 3D inpainting would significantly broaden its applicability. Finally, a more comprehensive investigation into the impact of the layer count (L), resolution (H,W), and dataset diversity on overall performance could lead to enhanced generalization and robustness, refining the optimal configurations for X-Ray in various scenarios.
More visual insights#
More on figures

This figure shows four examples of the X-Ray 3D sequential representation. Each example shows a 3D object (car, mug, gun, book) and its corresponding X-Ray representation. The X-Ray representation is a sequence of frames, each showing the hit (H), depth (D), normal (N), and color (C) information for the surfaces intersected by a ray cast from the camera. The number of frames in the X-Ray representation varies depending on the complexity of the 3D object. The dotted yellow lines show the direction of the ray cast.
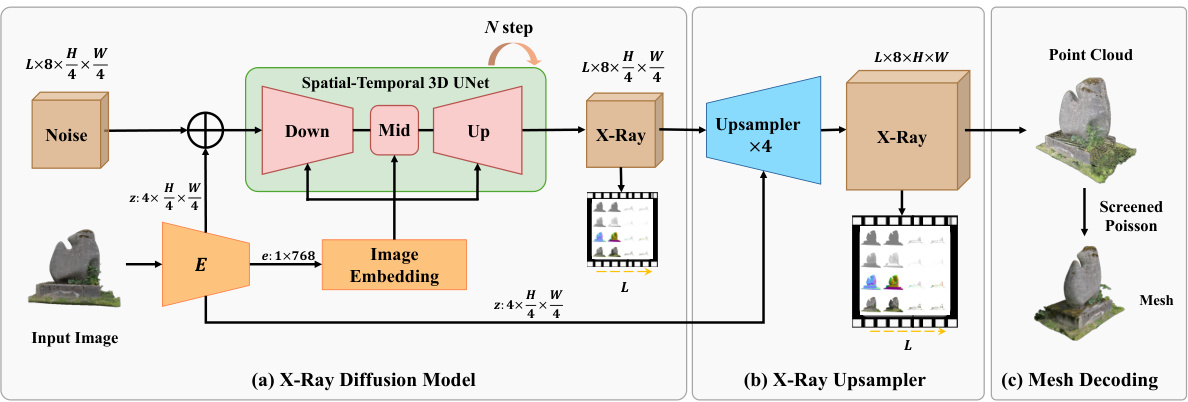
This figure illustrates the three-stage pipeline for generating 3D models using the X-Ray representation. First, an image is fed into the X-Ray diffusion model to create a low-resolution X-Ray representation. This is then upsampled to a higher resolution. Finally, the high-resolution X-Ray is decoded into a 3D point cloud, which is converted to a mesh.

This figure shows two plots illustrating the encoding-decoding intrinsic error of the X-Ray representation. The left plot shows how the error (measured by Chamfer Distance) decreases as the number of layers (L) increases, stabilizing around 8 layers. The right plot shows how the error decreases with increasing frame resolution (H or W), also stabilizing after 256. This analysis helps determine the optimal balance between accuracy and efficiency for the X-Ray representation.
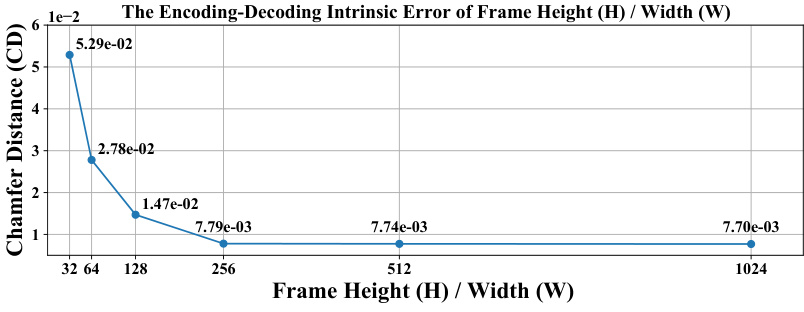
This figure shows the relationship between the encoding-decoding intrinsic error and the resolution (height and width) and number of layers of the X-Ray representation. The encoding-decoding intrinsic error is the difference between the original 3D mesh and the 3D mesh reconstructed from the encoded X-Ray representation. As shown in the graph, the error decreases as the resolution increases and the number of layers increases. This suggests that a higher resolution and more layers leads to a more accurate reconstruction.

This figure shows a quantitative comparison of image-to-3D mesh generation results using different methods. The input images are shown in the leftmost column, followed by reconstruction results from four different models: One-2-3-4-5, OpenLRM, TripoSR, and the authors’ proposed X-Ray method. The ground truth (GT) meshes are shown in the rightmost column. The comparison demonstrates the superior performance of the X-Ray method in generating complete and accurate 3D models from single input images across various object categories including boxes, footwear, cabinets, bowls, and cars.

This figure demonstrates failure cases of the X-Ray 3D generation method. The top row shows an example with a hamburger. The X-Ray representation successfully captures the visible layers, but the model fails to reconstruct the complete object, missing parts of the interior (indicated by the red dashed box). A similar problem is observed in the bottom row with a banana image, where the generated mesh is incomplete and lacks details.

This figure illustrates the three main components of the proposed generative pipeline for X-Ray 3D representation. The pipeline consists of an X-Ray diffusion model that generates a low-resolution X-Ray from an image; an upsampler that increases the resolution of the low-resolution X-Ray by a factor of 4; and a mesh decoding model that converts the high-resolution X-Ray into a point cloud, which is then converted into a 3D mesh.

This figure illustrates the three-stage pipeline for generating 3D mesh from a single image. First, an X-Ray diffusion model takes an image as input and produces a low-resolution X-Ray representation. Second, an upsampler increases the resolution of this X-Ray fourfold. Finally, a mesh decoding model converts the high-resolution X-Ray into a 3D point cloud with color and normal information, which is then transformed into the final 3D mesh.

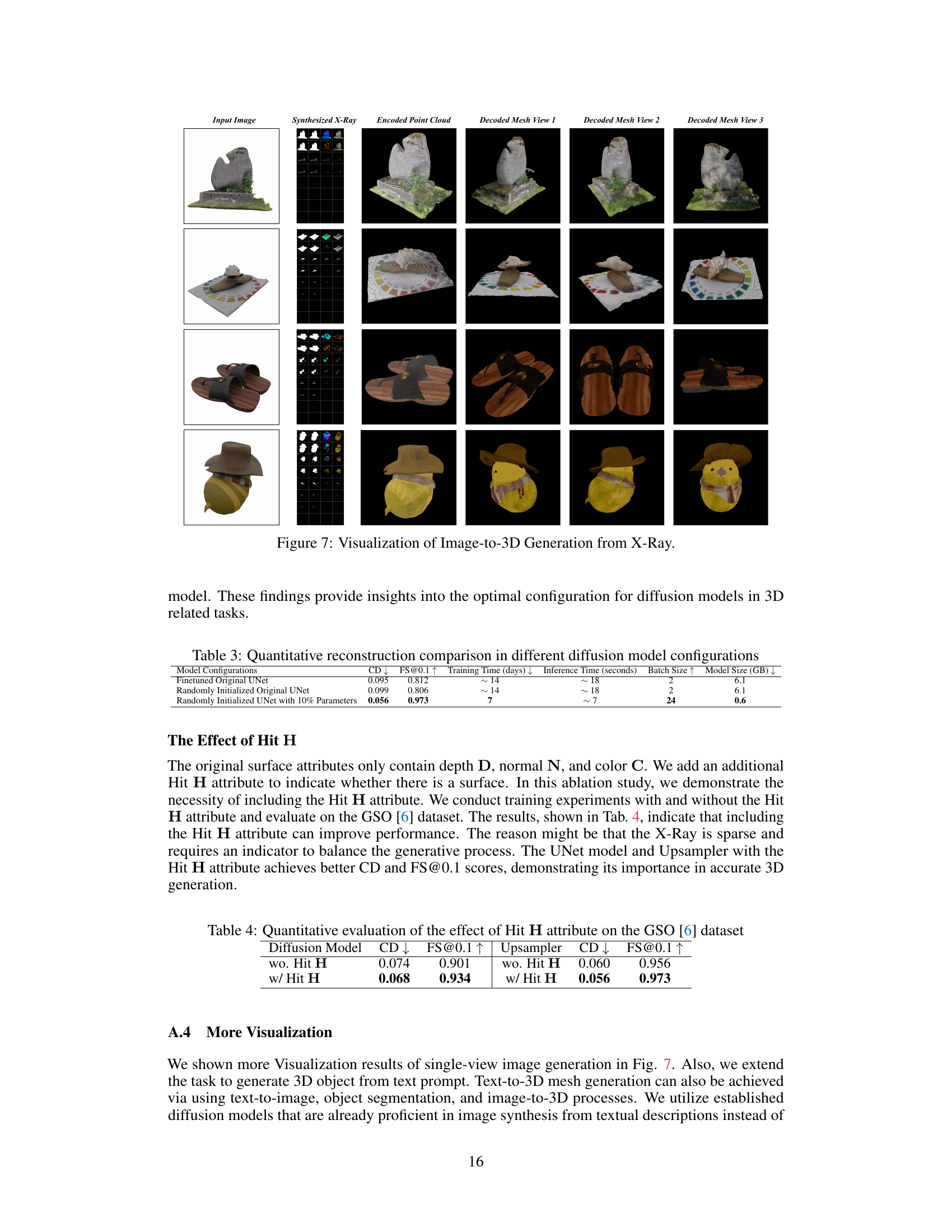
This figure visualizes the image-to-3D generation process using the X-Ray representation. It shows four examples, each with an input image and the resulting synthesized X-Ray, the encoded point cloud, and three views of the decoded mesh. The figure demonstrates the method’s ability to reconstruct 3D models from single images, highlighting the quality and detail achieved in the output meshes.

This figure demonstrates the Text-to-3D generation pipeline using X-Ray representation. Starting from textual descriptions (e.g., “a black and silver power supply”, “green wine bottle”, “a polar bear”, “a rolled haystack”), the pipeline first generates images using a pre-trained text-to-image diffusion model. Then, image segmentation is applied to isolate the object from the background. Next, the X-Ray representation is extracted from the segmented images, followed by point cloud encoding and mesh decoding to obtain the final 3D mesh model. The figure shows the synthesized image, segmented image, synthesized X-Ray, encoded point cloud, and the resulting decoded mesh for each textual input. This showcases the capability of X-Ray in translating text descriptions into 3D object representations.
More on tables

This table presents a quantitative comparison of the proposed X-Ray method with existing state-of-the-art methods for image-to-3D mesh generation. It shows the Chamfer Distance (CD) and F-Score (FS@0.1) metrics on the Google Scanned Objects (GSO) and OmniObject3D datasets. Lower CD values and higher FS@0.1 values indicate better reconstruction performance. The table highlights the superior performance of the X-Ray method compared to the other methods.

This table presents a quantitative comparison of the reconstruction performance achieved by three different diffusion model configurations: a finetuned original UNet, a randomly initialized original UNet, and a randomly initialized UNet with only 10% of the original parameters. The evaluation metrics are Chamfer Distance (CD) and F-Score at a threshold of 0.1 (FS@0.1). Training time (in days), inference time (in seconds), batch size, and model size (in GB) are also reported for each configuration. The results demonstrate the impact of different model sizes and initialization strategies on the model’s performance in 3D reconstruction tasks.

This table presents a quantitative comparison of the performance of the X-Ray generation model with and without the Hit H attribute. The results are evaluated using the Chamfer Distance (CD) and F-Score (FS@0.1) metrics on the Google Scanned Objects (GSO) dataset. The Hit H attribute indicates the presence of a surface in each layer of the X-Ray representation. The results show that including the Hit H attribute improves the model’s performance, suggesting its importance in ensuring accurate 3D object generation.
Full paper#