↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current graph learning methods often oversimplify hierarchical graph structures by compressing each cluster into a single embedding, resulting in the loss of valuable information. This limitation hinders performance in many graph-level tasks. The methods also frequently rely on fixed graph coarsening routines, further restricting their flexibility and adaptability.
To address these issues, the paper introduces Cluster-wise Graph Transformer (Cluster-GT), which views graphs as networks of interconnected node sets, avoiding the need to compress each cluster. Cluster-GT employs a novel Node-to-Cluster Attention (N2C-Attn) mechanism which incorporates multiple kernel learning to capture information at both node and cluster levels efficiently. The resulting architecture achieves linear time complexity and exhibits superior performance on various graph-level tasks, demonstrating the benefits of capturing dual-granularity information effectively.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel approach to graph learning that outperforms existing methods. It addresses limitations of current techniques by avoiding the oversimplification of cluster representations and integrates dual-granularity information effectively, opening new avenues for research in hierarchical graph representation learning and improving the performance of graph-level tasks. The efficient implementation and linear time complexity make it particularly valuable for large-scale applications.
Visual Insights#
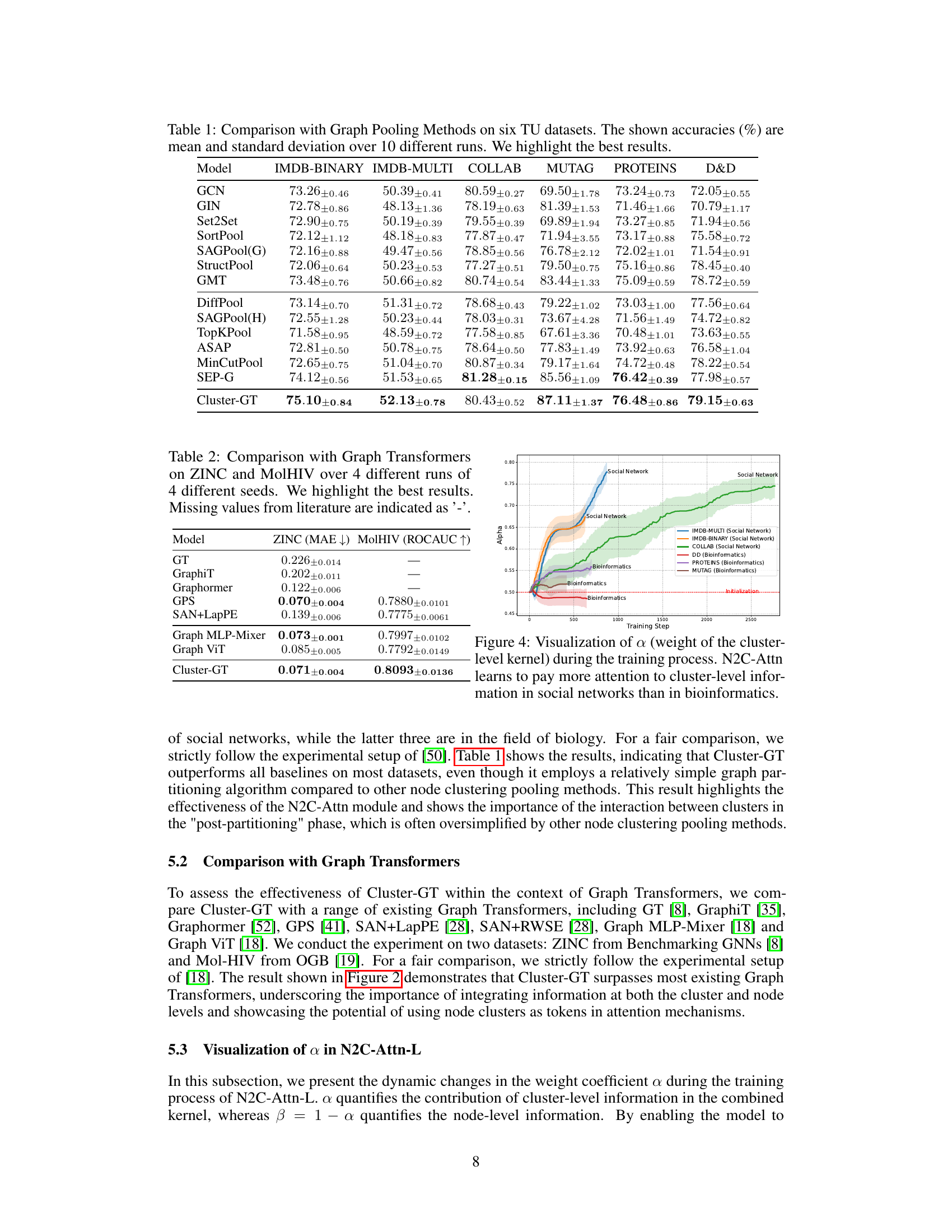
This figure illustrates the core idea of the Node-to-Cluster Attention (N2C-Attn) mechanism. Instead of the traditional approach of compressing each cluster into a single embedding, N2C-Attn treats the graph as a network of interconnected node sets. It uses a bi-level attention mechanism that considers both node-level and cluster-level information to effectively transfer information between clusters. The figure visually depicts this process, showing how N2C-Attn integrates multiple kernel learning to capture hierarchical graph structure and preserves node-level details.
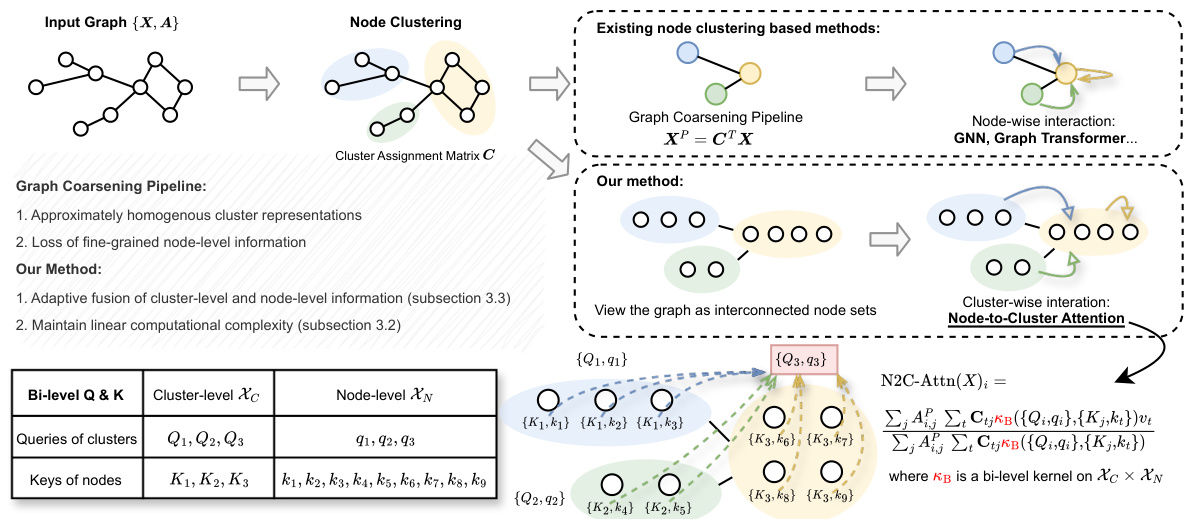
This table compares the performance of the proposed Cluster-GT model against various graph pooling methods on six datasets from the TUDataset collection. The results are presented as the mean accuracy and standard deviation across 10 independent runs, allowing for a statistical evaluation of the model’s performance. The best-performing model for each dataset is highlighted.
In-depth insights#
Dual-Granularity Focus#
A dual-granularity focus in a research paper likely refers to a methodology that considers and integrates information from two different levels of granularity simultaneously. This approach is particularly useful when dealing with complex data structures like graphs, where information exists at both the node-level (individual data points) and the cluster-level (groups of interconnected data points). The key advantage of a dual-granularity approach lies in its ability to capture both fine-grained details and broader patterns. Ignoring either level can lead to an incomplete understanding of the system being modeled. The challenge lies in effectively combining these disparate levels of information, likely requiring sophisticated techniques to avoid information loss or dominance of one level over the other. Successful integration of dual granularity often necessitates mechanisms to manage the trade-off between detail and abstraction leading to a more robust and holistic model capable of capturing nuances often missed by single-level approaches.
N2C-Attn Mechanism#
The core contribution of this research paper centers around the novel Node-to-Cluster Attention (N2C-Attn) mechanism. N2C-Attn addresses the limitations of existing graph learning methods that rely on fixed graph coarsening routines. These methods often compress cluster information, leading to a loss of node-level detail and overly homogenous representations. N2C-Attn avoids this compression, viewing the graph as a network of interconnected node sets. It leverages Multiple Kernel Learning (MKL) to integrate information from both node and cluster levels within a kernelized attention framework. This dual-granularity approach allows for a richer representation of hierarchical graph structures, enabling more effective information transfer between clusters. Furthermore, the efficient implementation of N2C-Attn using message passing ensures linear time complexity, a significant advantage over other hierarchical attention methods. The use of bi-level queries and keys, combined with the flexible options for kernel combination (tensor product or convex linear combination), provides adaptability and control over the relative importance of node and cluster information within the attention mechanism. Ultimately, N2C-Attn forms the backbone of the proposed Cluster-wise Graph Transformer architecture, significantly improving performance on various graph-level tasks.
Cluster-GT Model#
The Cluster-GT model presents a novel approach to graph-level learning by integrating a cluster-wise interaction mechanism. Unlike traditional methods that compress node clusters into single embeddings, Cluster-GT retains the granularity of individual nodes within each cluster, enabling richer interactions. This is achieved through the innovative Node-to-Cluster Attention (N2C-Attn) module. N2C-Attn leverages multiple kernel learning, effectively capturing information at both node and cluster levels, thereby avoiding the loss of fine-grained information often seen in graph coarsening techniques. Its efficient design ensures linear time complexity, a significant improvement over existing methods. The model’s performance is demonstrated through superior results on various graph-level tasks, showcasing the effectiveness of its dual-granularity approach and its ability to handle diverse graph structures. The adaptability of N2C-Attn to different data domains is highlighted through analysis of kernel weights, suggesting its robustness across various applications.
Graph Partitioning#
Graph partitioning plays a crucial role in many graph-based machine learning methods, particularly those employing hierarchical or cluster-based approaches. The effectiveness of these methods hinges on the quality of the partitioning, which determines how well the graph’s structure and information are preserved at different granularities. Poor partitioning can lead to loss of important information, overly homogeneous cluster representations, and reduced overall performance. There are numerous graph partitioning algorithms, varying in their complexity, scalability, and ability to handle different graph properties (e.g., size, density, community structure). The choice of algorithm should consider the specific application and characteristics of the graph. Commonly used techniques include greedy algorithms, spectral methods, and multilevel refinement approaches. Moreover, the partitioning process can significantly affect computational complexity, as some algorithms are more computationally expensive than others. Researchers are continuously exploring and developing novel graph partitioning techniques to optimize for different criteria, including balance, edge-cut, and modularity. Learnable graph partitioning is an active area of research, aiming to integrate the partitioning process directly into the learning framework for better adaptation to the specific data and task. This approach holds significant potential for improving the effectiveness and efficiency of hierarchical graph learning methods.
Future Enhancements#
The paper’s core contribution, the Node-to-Cluster Attention mechanism, presents a promising direction for future research. Improving the efficiency and scalability of the N2C-Attn algorithm, especially for very large graphs, is a key area. Exploring alternative graph partitioning methods beyond the static Metis approach could significantly enhance the model’s adaptability to dynamic network structures and various data characteristics. Incorporating learnable graph partitioning strategies would allow the model to optimize the cluster assignments during training, improving the quality of the attention mechanism. Furthermore, research into more sophisticated kernel combinations within the N2C-Attn framework could lead to richer and more nuanced representations of both node and cluster-level information. Finally, thorough investigation into the robustness and generalization capabilities of the proposed method across diverse datasets and domains is essential to solidify its practical applicability and identify potential limitations.
More visual insights#
More on figures
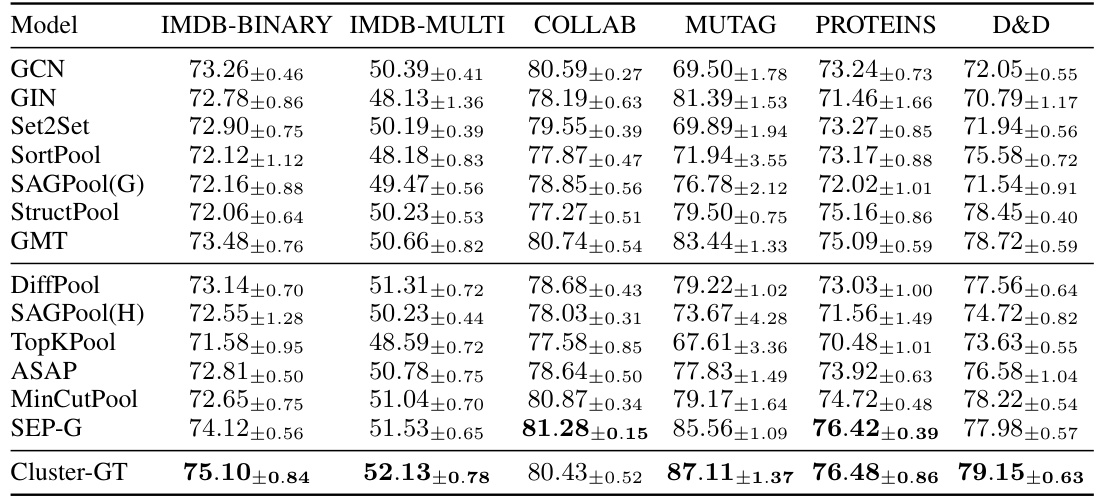
This figure illustrates an efficient implementation of the Node-to-Cluster Attention with Tensor Product of Kernels (N2C-Attn-T) using a message-passing framework. It breaks down the computation into four steps, visualizing the process of aggregating node-level information, calculating cluster-wise similarity, propagating messages among clusters, and finally, combining aggregated information with node-level queries.
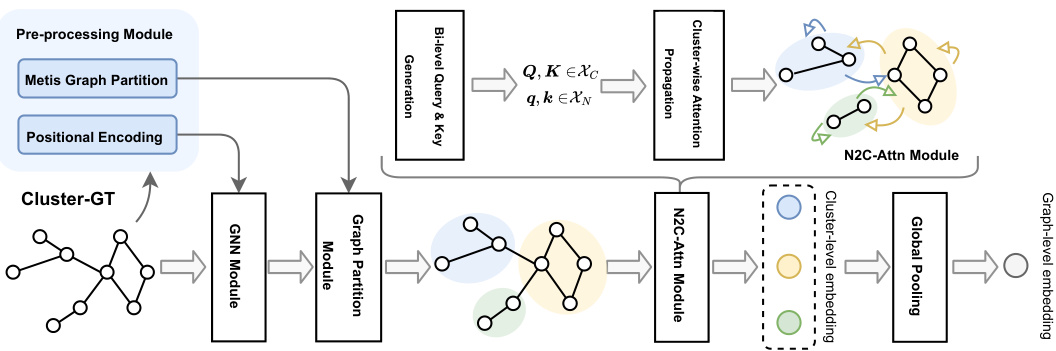
This figure illustrates the architecture of the Cluster-wise Graph Transformer (Cluster-GT) model. It shows a workflow diagram with three main modules: 1) a pre-processing module that uses Metis for graph partitioning and positional encoding; 2) a node-wise convolution module using a Graph Neural Network (GNN); 3) a cluster-wise interaction module using the Node-to-Cluster Attention (N2C-Attn) mechanism. The output of the model is a graph-level embedding.
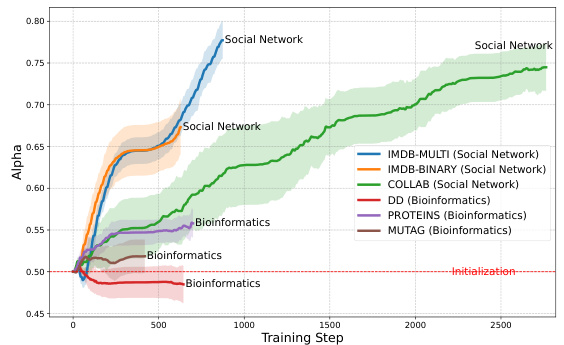
This figure visualizes how the weight assigned to the cluster-level kernel (α) changes during the training process of the N2C-Attn model. It shows that the model dynamically adjusts the balance between node-level and cluster-level information. For social networks, α tends to be higher (more attention to cluster-level information), while for bioinformatics datasets, α is lower (more balanced attention). This indicates N2C-Attn adapts its attention strategy based on the dataset’s characteristics.
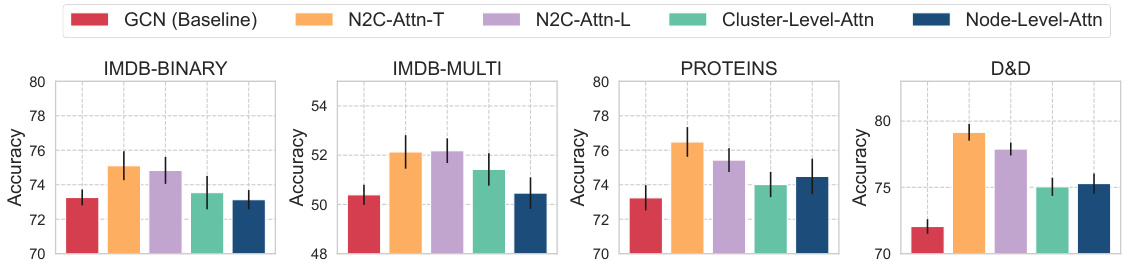
This figure compares the performance of four different attention mechanisms on four different datasets. The x-axis represents the datasets (IMDB-BINARY, IMDB-MULTI, PROTEINS, D&D), and the y-axis represents the accuracy. Each bar represents the accuracy achieved by a different attention mechanism: GCN (baseline), N2C-Attn-T, N2C-Attn-L, Cluster-Level-Attn, and Node-Level-Attn. The variations in accuracy across the different methods highlight the impact of integrating node and cluster-level information in the attention mechanism.
More on tables
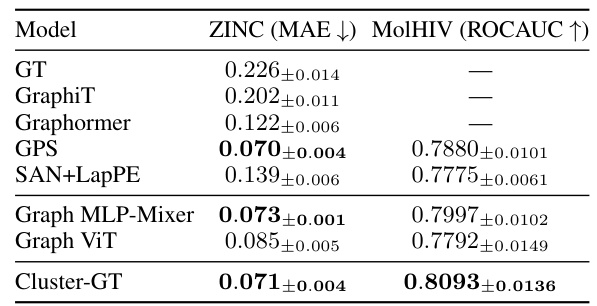
This table compares the performance of Cluster-GT against other graph transformer models on two datasets, ZINC and MolHIV. The evaluation metrics used are Mean Absolute Error (MAE) for ZINC (a regression task) and Area Under the ROC Curve (ROCAUC) for MolHIV (a classification task). The results are averages from 4 different runs with 4 different seeds, highlighting Cluster-GT’s superior performance. Missing values from other papers are indicated by a ‘-’.
This table compares the performance of the proposed Cluster-GT model against various graph pooling methods on six datasets from the TUDataset collection. The evaluation metric is accuracy, and the results are averaged over ten runs with standard deviation reported, highlighting the best-performing method for each dataset.
Full paper#