↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current methods for open-world 3D instance segmentation often struggle with under- and over-segmentation due to a heavy reliance on 2D information and limited use of 3D priors. These limitations lead to inaccurate results and hinder progress in this crucial field of computer vision. Existing benchmarks also suffer from annotation inconsistencies, further complicating evaluation and comparison of different approaches.
SA3DIP tackles these challenges directly. It generates improved 3D primitives by incorporating both geometric and textural information from the point cloud, minimizing errors in the initial segmentation stage. Furthermore, it leverages a 3D detector to constrain the merging process, addressing over-segmentation issues. To address benchmarking shortcomings, the study introduces the ScanNetV2-INS dataset, which features improved and more complete annotations for fairer evaluations. Extensive experiments demonstrate SA3DIP’s effectiveness, particularly on challenging datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SA3DIP, a novel method for 3D instance segmentation that significantly improves accuracy by leveraging 3D priors. It also introduces ScanNetV2-INS, an improved dataset addressing limitations in existing benchmarks, which enhances the reliability of future research. The work opens new avenues for open-world 3D scene understanding, particularly in addressing over-segmentation issues inherent to current 2D-to-3D lifting approaches. This methodology is highly relevant to autonomous driving, robotics, and virtual reality.
Visual Insights#

This figure compares the proposed SA3DIP method with other existing methods, specifically SAI3D. It highlights the limitations of SAI3D in distinguishing instances with similar normals during superpoint computation, leading to error accumulation and inaccurate final segmentation. SAI3D also suffers from transferring part-level 2D segmentations to 3D, resulting in over-segmentation. In contrast, SA3DIP leverages additional 3D priors (geometric and textural) and 3D spatial constraints for improved accuracy and reduced over-segmentation.

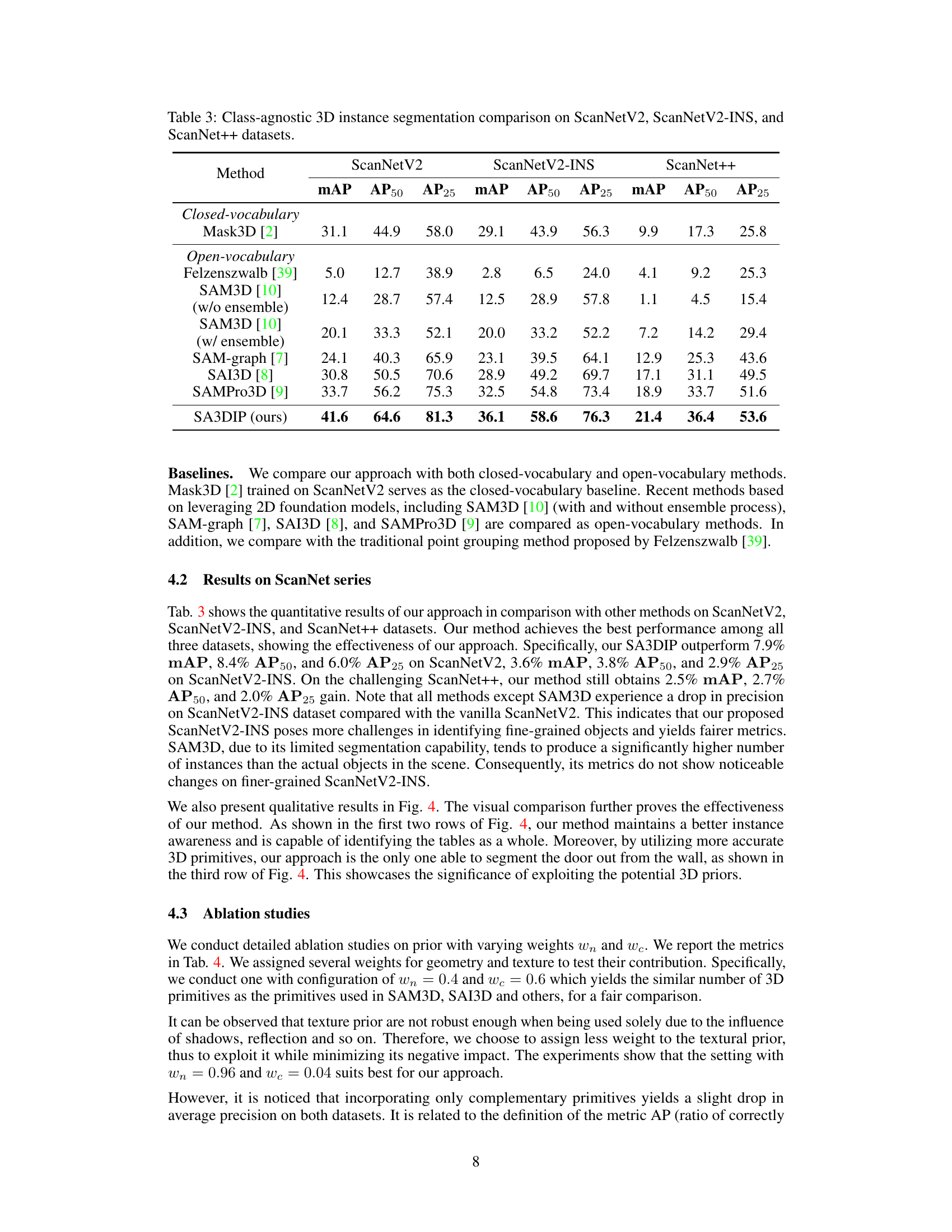
This table compares the performance of different methods for class-agnostic 3D instance segmentation on three datasets: ScanNetV2, the enhanced version ScanNetV2-INS, and ScanNet++. The metrics used for comparison are mean Average Precision (mAP), Average Precision at 50% IoU (AP50), and Average Precision at 25% IoU (AP25). The table allows readers to assess the relative performance of various approaches, including both closed-vocabulary and open-vocabulary methods, across different datasets with varying levels of annotation quality and complexity.
In-depth insights#
SA3DIP Overview#
An overview of SA3DIP would highlight its innovative approach to 3D instance segmentation. SA3DIP leverages both geometric and textural priors to generate more accurate and detailed 3D primitives, overcoming limitations of previous methods that relied solely on geometric information. This leads to improved segmentation accuracy, especially in scenes with objects exhibiting similar geometries but different textures. The method also incorporates a 3D detector to introduce supplemental constraints from 3D space, enhancing its performance in distinguishing instances, mitigating over-segmentation issues common in methods solely using 2D information. The integration of 2D and 3D information through an affinity matrix allows SA3DIP to effectively group primitives, leading to more precise and comprehensive instance segmentation results. The pipeline is designed to handle challenging scenarios where traditional methods struggle, yielding a significant improvement in accuracy and robustness, particularly on datasets with imperfect annotations. Ultimately, SA3DIP offers a more complete and sophisticated approach to 3D instance segmentation, showcasing the importance of integrating multiple data sources and advanced processing techniques for improved results.
3D Prior Integration#
Integrating 3D priors effectively enhances 3D instance segmentation by leveraging readily available 2D data. This approach addresses limitations of methods solely reliant on 2D information, such as under-segmentation of geometrically similar objects or over-segmentation due to inherent ambiguities in 2D masks. Key to success is the synergistic combination of geometric and textural priors, allowing for more refined 3D primitive generation. This moves beyond reliance on simple normal estimations, leading to superior superpoint grouping and improved accuracy. Further integration of 3D detection results provides crucial spatial constraints, guiding the merging process and rectifying over-segmentation issues. This holistic approach, incorporating both geometric and visual cues from multiple views, results in a robust and accurate segmentation pipeline, showcasing the advantages of exploiting 3D information within a 2D-3D framework. The careful selection of weights balancing geometric and textural features further optimizes performance. Overall, the integration of 3D priors offers a significant advancement in open-world 3D instance segmentation, overcoming previous challenges in achieving high-quality results.
ScanNetV2-INS#
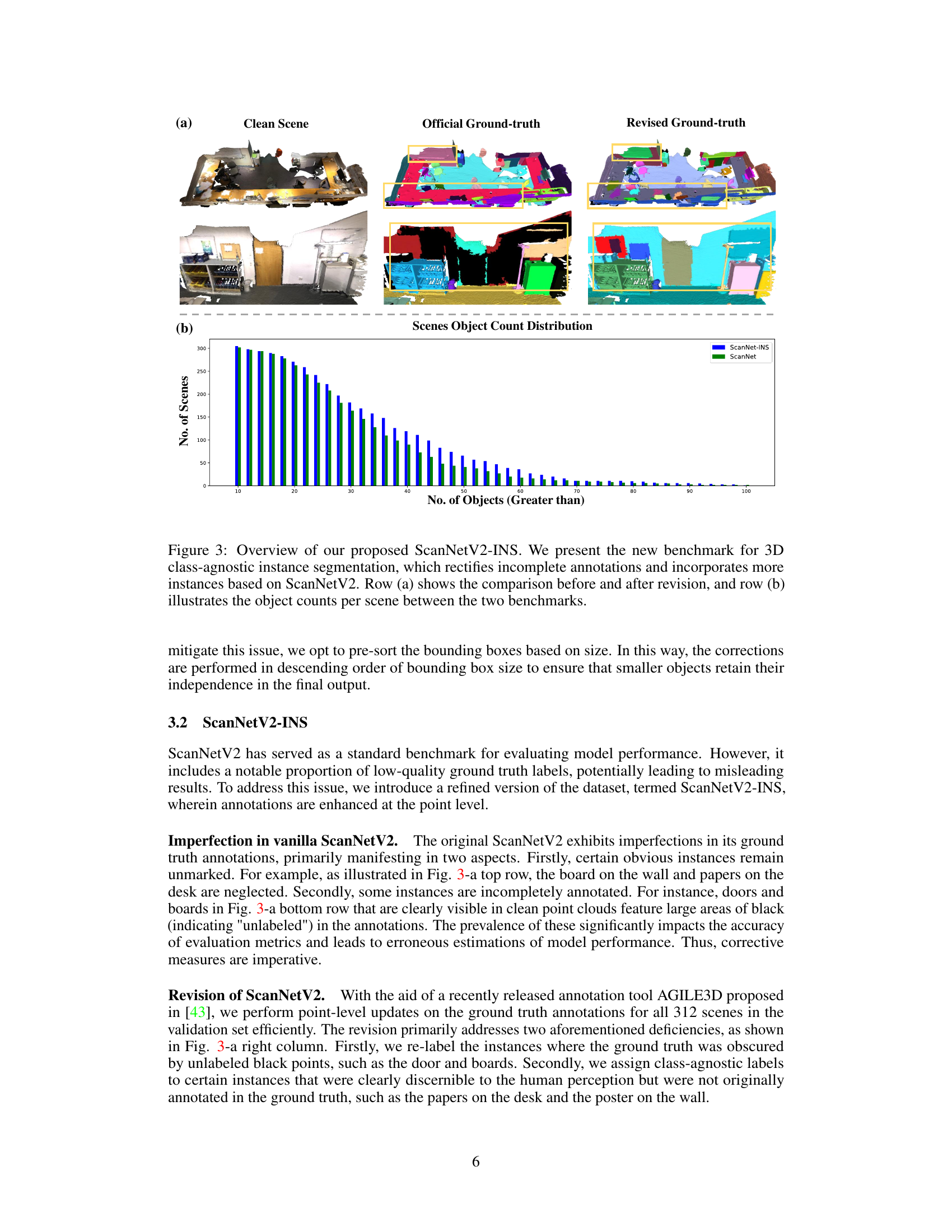
The proposed ScanNetV2-INS dataset significantly enhances the existing ScanNetV2 benchmark for 3D instance segmentation. Addressing the limitations of ScanNetV2, which includes a considerable number of low-quality and incomplete annotations, ScanNetV2-INS provides a refined dataset with fewer missing instances and more complete ground truth labels. This improvement directly impacts the accuracy and fairness of model evaluation, thus leading to more robust and reliable results. The enhanced quality of ScanNetV2-INS makes it a more suitable benchmark for evaluating the performance of 3D instance segmentation models, particularly those employing class-agnostic approaches. The inclusion of additional instances, especially smaller objects often overlooked in the original dataset, further increases the dataset’s challenge and makes it a more comprehensive evaluation tool. By rectifying the inherent biases in the original ScanNetV2, ScanNetV2-INS establishes a new standard for evaluating the performance of 3D instance segmentation models, pushing the field towards more accurate and reliable evaluations.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, an ablation study might involve removing or altering aspects of the proposed method (e.g., geometric priors, textural priors, or the 3D detector) to determine their effect on the overall performance. The results would reveal the relative importance of each component, shedding light on the factors driving the model’s success. For example, if removing the textural priors significantly degrades performance, it highlights the crucial role of this feature. Conversely, a minimal performance change after removing a certain component suggests it is less critical. This analysis allows researchers to understand the design choices better, potentially simplifying the model or improving it by emphasizing the most influential components. By comparing variants with and without different features, ablation studies provide quantitative evidence for design decisions, strengthening the paper’s conclusions and offering valuable insights into the model’s architecture.
Future Work#
Future research directions stemming from this work could focus on enhancing the robustness of 3D superpoint generation, particularly when dealing with high-resolution point clouds exhibiting complex lighting and shadow effects. Exploring alternative 3D primitive representations, beyond the geometric and textural priors used here, could further improve segmentation accuracy. Another avenue is developing a more sophisticated merging algorithm that lessens reliance on the accuracy of 2D foundation model outputs, perhaps through a more robust integration of 3D constraints or the use of advanced techniques like graph neural networks. Finally, the impact of different 2D foundation models on the overall performance should be rigorously examined. Investigating the generalizability of the proposed method across a wider variety of architectural styles and object complexities would provide further evidence of its efficacy and versatility. By addressing these areas, the proposed approach can be made even more powerful and reliable in tackling the challenges of open-world 3D instance segmentation.
More visual insights#
More on figures

This figure illustrates the overall pipeline of the SA3DIP method. It consists of three main steps: 1. Complementary Primitives Generation: generating finer-grained 3D primitives using both geometric and textural information. 2. Scene Graph Construction: constructing a superpoint graph based on the generated primitives and their relationships, and using 2D masks from SAM to compute edge weights. 3. Region growing & Instance-aware refinement: performing region growing and instance-aware refinement on the constructed graph to obtain final instance segmentation results. The 3D detector is integrated into step 3 to further refine the results by using 3D prior.
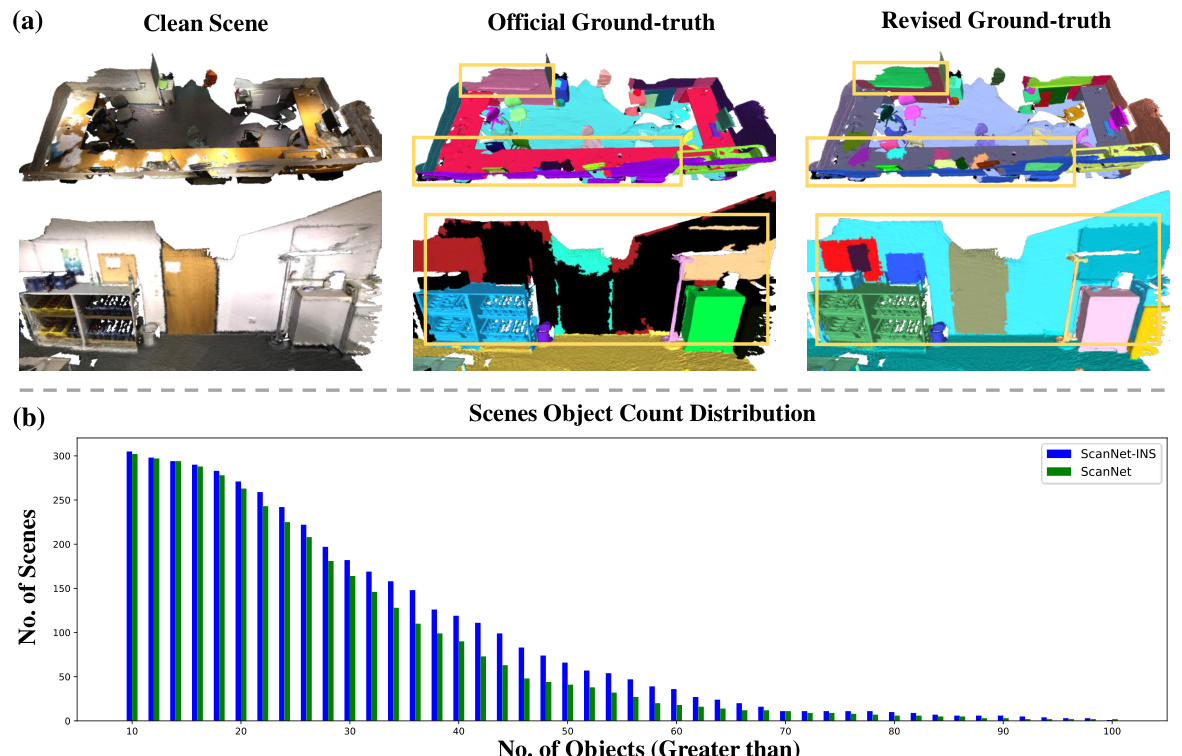
This figure provides a visual comparison of the original ScanNetV2 dataset and the improved ScanNetV2-INS dataset. Subfigure (a) shows 3D point cloud scenes with their respective ground truth annotations. The left column displays clean point clouds, the middle shows the original annotations, and the right column depicts the revised, enhanced annotations for ScanNetV2-INS. Subfigure (b) presents a bar graph comparing the object count distribution in each dataset. The graph shows that ScanNetV2-INS has a higher number of scenes with more objects, indicating a more challenging and representative dataset for 3D instance segmentation.

This figure shows a visual comparison of the proposed SA3DIP method against three other state-of-the-art methods (SAM3D, SAMPro3D, and SAI3D) and the ground truth on three different datasets (ScanNetV2, ScanNetV2-INS, and ScanNet++). Each row represents one dataset, and each column shows either the input RGB-D images, the segmentation results produced by each method, or the ground truth segmentation. The red boxes highlight specific regions of interest where the differences between methods are most apparent. The figure demonstrates the superior performance of SA3DIP in generating robust and accurate 3D instance segmentations across various datasets.
More on tables

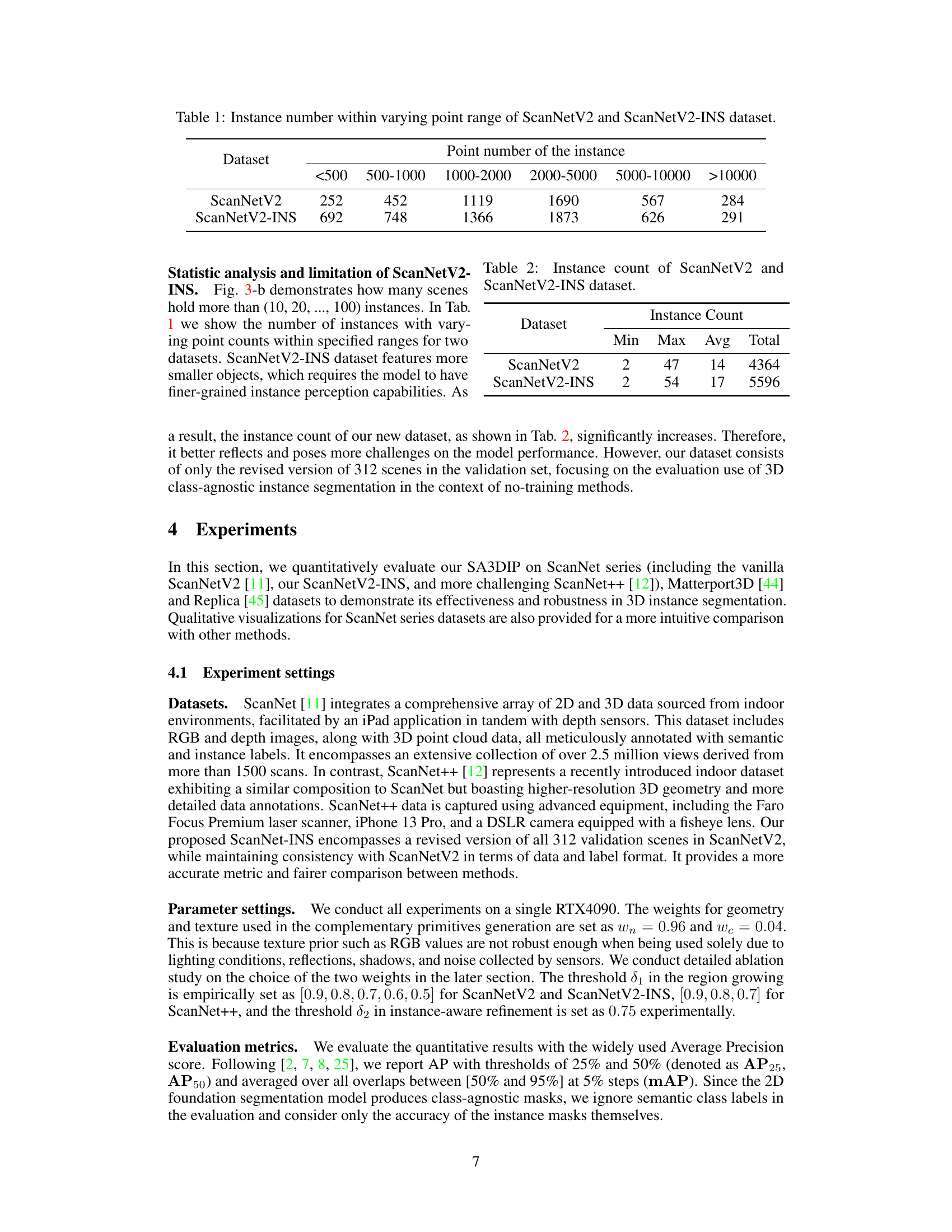
This table shows the distribution of instance counts in the ScanNetV2 and ScanNetV2-INS datasets, categorized by the number of points in each instance. It helps to illustrate the difference in the point cloud density and object size between the two datasets.

This table presents a statistical summary of the number of instances found in the ScanNetV2 and the improved ScanNetV2-INS datasets. It shows the minimum, maximum, average, and total number of instances across all scenes within each dataset. This information highlights the difference in instance density between the original and the enhanced dataset, which is relevant for evaluating the performance of 3D instance segmentation models.
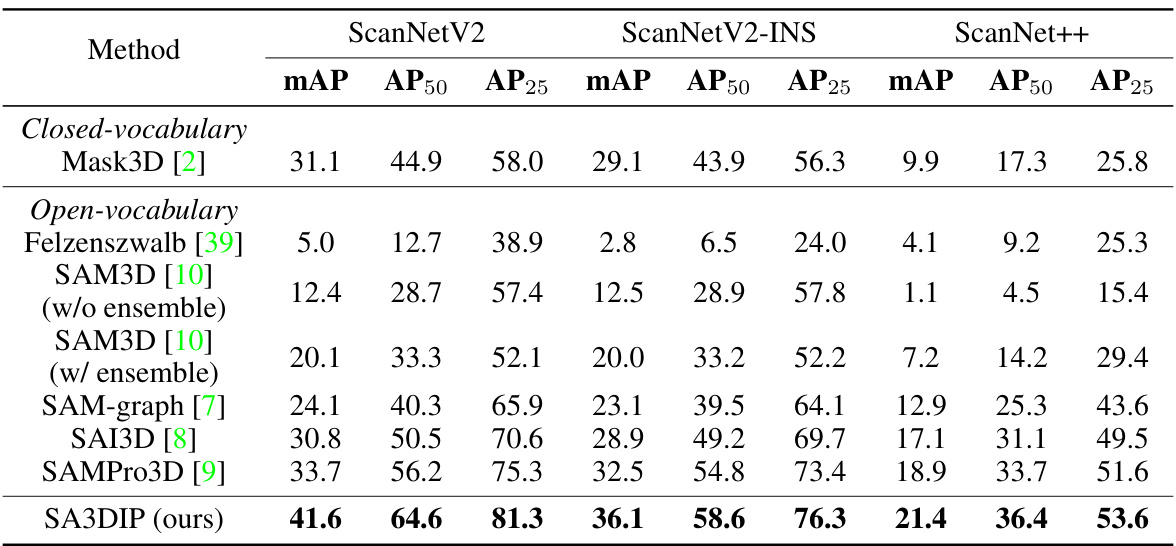
This table presents a quantitative comparison of different methods for class-agnostic 3D instance segmentation across three datasets: ScanNetV2, the improved ScanNetV2-INS, and ScanNet++. The metrics used for comparison are mean Average Precision (mAP), Average Precision at 50% IoU (AP50), and Average Precision at 25% IoU (AP25). The methods compared include both closed-vocabulary and open-vocabulary approaches, allowing for a comprehensive evaluation of the state-of-the-art.
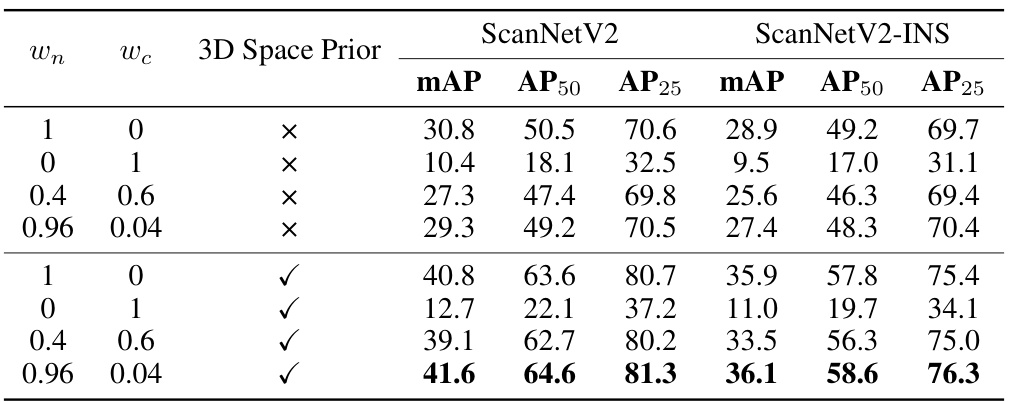
This table presents the ablation study results on the impact of using different combinations of geometric and textural priors for 3D instance segmentation. It shows the performance (mAP, AP50, AP25) on ScanNetV2 and ScanNetV2-INS datasets when varying the weights assigned to geometric (Wn) and textural (Wc) priors, with and without the inclusion of 3D space priors. The results demonstrate the optimal balance between the two types of priors and the importance of integrating 3D space constraints for improved accuracy.

This table presents a comparison of class-agnostic 3D instance segmentation performance across three datasets: ScanNetV2, the enhanced ScanNetV2-INS, and ScanNet++. Multiple methods are compared, showing their mean Average Precision (mAP), AP at 50% IoU (AP50), and AP at 25% IoU (AP25) for each dataset. The table allows for a direct comparison of different approaches’ performance in segmenting 3D instances in varying data complexities.
Full paper#