↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current large language and vision-language models (LLMs and VLMs) struggle with in-context learning due to their reliance on high-quality example demonstrations. This research highlights that providing sub-optimal demonstrations to these models leads to inefficient and error-prone outcomes. The need for high-quality demonstrations poses a significant challenge, as creating them requires significant manual effort and expertise.
This paper introduces ICAL (In-Context Abstraction Learning), a novel method that addresses these issues. ICAL uses VLMs to generate and refine their own high-quality examples, even from noisy initial demonstrations, and incorporates human feedback in the process. This approach significantly reduces the reliance on manual prompt engineering and delivers superior performance across multiple benchmark tasks, surpassing the state-of-the-art in dialogue-based instruction following, multimodal web agents, and action forecasting.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents ICAL, a novel method that significantly improves in-context learning. It addresses the limitations of existing methods by enabling large language and vision-language models to generate their own high-quality examples from suboptimal demonstrations and human feedback. This opens avenues for more efficient, robust, and generalizable AI agents across multiple domains. The improved performance across various benchmarks showcases ICAL’s potential for real-world applications.
Visual Insights#

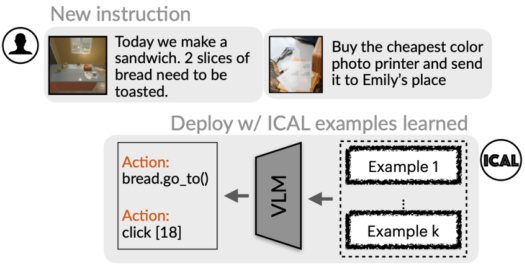
This figure illustrates the In-Context Abstraction Learning (ICAL) method. The left side shows how the agent processes a noisy video demonstration, generating refined examples with added linguistic annotations for later use in vision-language models (VLMs). The right side demonstrates the human-in-the-loop aspect, where humans provide feedback to correct errors and contribute additional knowledge, leading to improved agent learning.
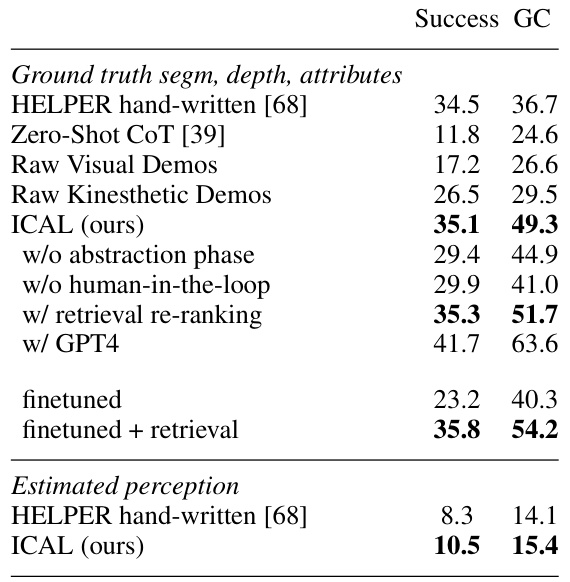
This table presents the results of the evaluation of the ICAL method and several baseline methods on the unseen validation set of the TEACh benchmark. The table shows the success rate (SR) and goal condition success rate (GC) for various methods, including the ICAL method with and without certain components (such as the abstraction and human-in-the-loop phases). Baselines include HELPER (using hand-written examples), zero-shot chain of thought (CoT), and raw visual and kinesthetic demonstrations. The results are broken down into those using ground truth segmentation, depth and attributes and those using estimated perception. The results demonstrate the ICAL method’s superior performance compared to the baselines.
In-depth insights#
VLM Memory Distillation#
VLM Memory Distillation represents a novel approach to enhance the capabilities of Vision-Language Models (VLMs). The core idea revolves around distilling experiences – both successful and unsuccessful – into a structured, reusable memory. This contrasts with traditional in-context learning, which relies heavily on pre-selected, high-quality examples. By learning from suboptimal demonstrations, and incorporating human feedback, the method enables the VLM to abstract relevant features, correct errors and refine actions. This process leads to improved task completion rates and reduced reliance on manual prompt engineering, effectively boosting VLM efficiency and generalization. The distilled memories contain multimodal data, including visual information and language annotations (causal relationships, state transitions, and subgoals), which makes this approach particularly powerful in embodied AI scenarios.
ICAL Method#
The In-Context Abstraction Learning (ICAL) method is a novel approach to improve the in-context learning capabilities of large language and vision-language models (LLMs/VLMs). ICAL addresses the challenge of learning from noisy demonstrations by creating a memory of multimodal experiences. This memory is built iteratively by abstracting sub-optimal demonstrations into generalized programs and refining these through human feedback. The core idea is to distill the crucial insights and knowledge from imperfect data into reusable, easily-digested forms that enhance in-context learning for VLMs. This process focuses on generating and iteratively improving four types of cognitive abstractions: task and causal relationships, changes in object states, temporal subgoals, and task-relevant visual elements. By incorporating these abstractions into prompts, ICAL significantly improves VLM performance across a variety of tasks, demonstrating the value of structured knowledge representation for efficient few-shot learning. The method also reduces reliance on manual prompt engineering and demonstrates continual learning and efficiency improvements as the memory grows.
Benchmark Results#
The benchmark results section of a research paper is crucial for evaluating the proposed method’s effectiveness. A strong presentation will include comparisons against relevant baselines, using established metrics appropriate to the task. Clear visualizations, such as graphs and tables, are essential for easily grasping the performance differences. A detailed analysis should delve into the reasons behind the observed results, exploring factors like dataset characteristics, hyperparameter settings, and computational costs. Statistical significance should be established to ensure that the reported improvements are not due to random chance. The discussion of limitations is crucial, acknowledging any shortcomings or areas where the method underperforms. Finally, a robust benchmark analysis will place the research findings within the broader context of existing work, highlighting the contribution’s significance to the field and outlining future research directions.
Abstraction Learning#
The concept of ‘Abstraction Learning’ in the context of AI agents centers on the ability of an agent to distill complex experiences into simplified, generalizable knowledge representations. Instead of relying solely on raw sensory data or explicit instructions, the agent learns to abstract key features, causal relationships, and temporal patterns from its interactions with the environment. This abstraction process allows the agent to generalize from limited or noisy training data, improving its efficiency and adaptability in novel situations. A key aspect is the iterative refinement of these abstractions through human feedback or other forms of supervision, ensuring that the agent’s internal model accurately reflects relevant task dynamics. This learning approach is particularly powerful in environments with high-dimensional state spaces, where raw experience may be insufficient to learn effective behavior. Successful abstraction learning allows for efficient in-context learning, requiring fewer training samples and less interaction with the environment to achieve high performance.
Future of ICAL#
The future of In-Context Abstraction Learning (ICAL) holds immense potential. ICAL’s ability to distill complex experiences into generalized programs of thought could revolutionize how AI agents learn and adapt. Future research should explore more robust methods for handling noisy and incomplete demonstrations, perhaps incorporating techniques from active learning or uncertainty quantification. Improving the efficiency of human-in-the-loop feedback is crucial; automating aspects of this process or designing more intuitive interfaces for human feedback could significantly enhance scalability. Furthermore, extending ICAL to more complex and diverse environments is key, especially dynamic or partially observable settings. Investigating transfer learning and generalization across different tasks and domains will unlock ICAL’s full potential. Finally, thorough ethical considerations surrounding bias, privacy, and potential misuse are paramount for responsible development and deployment.
More visual insights#
More on figures

This figure illustrates the In-Context Abstraction Learning (ICAL) process. The top half shows the process of transforming a noisy trajectory (a sequence of actions and observations from a demonstration) into a refined trajectory by using a Vision-Language Model (VLM). This involves correcting inefficient actions and adding annotations such as causal relationships, object state changes, and subgoals. This refined trajectory is then executed in the environment, with human feedback used to further improve the trajectory if it fails. The bottom half provides a visual comparison of the raw, noisy trajectory and the final, optimized trajectory produced by ICAL, highlighting the improvements made through abstraction and feedback.

This figure illustrates the In-Context Abstraction Learning (ICAL) method. The left side shows how the agent processes a noisy visual demonstration, generating refined examples with language annotations for later use by a Vision-Language Model (VLM). The right side shows the human-in-the-loop process where humans provide feedback, correct errors, and supply additional knowledge, improving the agent’s learning efficiency.
This figure illustrates the ICAL process. The top half shows how a noisy trajectory is transformed into a refined trajectory with added language annotations using a VLM. The bottom half shows an example of a raw, noisy trajectory compared to the final, optimized abstracted trajectory created by ICAL. The process involves both VLM processing and human-in-the-loop feedback.
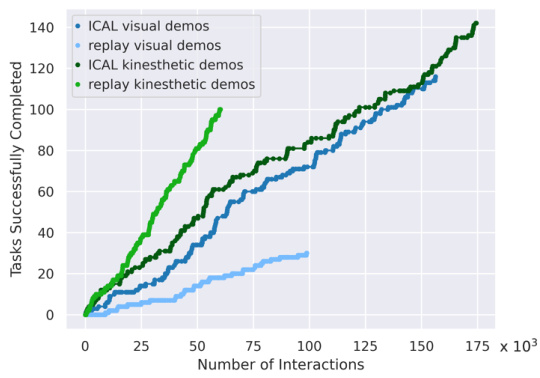
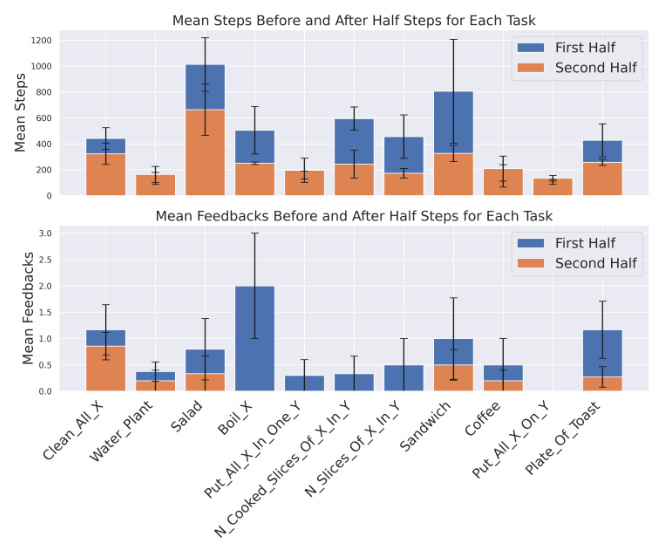
This figure shows the cumulative number of successfully completed tasks as a function of the number of interactions with the environment. The results for four conditions are displayed: (1) ICAL using visual demonstrations; (2) directly replaying the original visual demonstrations; (3) ICAL using kinesthetic demonstrations; and (4) directly replaying the original kinesthetic demonstrations. The plot demonstrates that the ICAL method, which generates its own improved examples, outperforms the strategy of simply replaying the original demonstrations. The gap between ICAL and the replay-only conditions grows as the number of interactions increases, highlighting ICAL’s ability to improve performance over time.
This figure shows the cumulative number of successfully completed tasks plotted against the number of interactions for four different conditions: ICAL with kinesthetic demonstrations, replaying kinesthetic demonstrations, ICAL with visual demonstrations, and replaying visual demonstrations. It demonstrates that ICAL significantly improves task success rate compared to simply replaying the original (noisy) demonstrations. The improvement is consistent across both kinesthetic and visual demonstration types.

This figure illustrates the In-Context Abstraction Learning (ICAL) process. The top panel shows the process of transforming a noisy trajectory into a refined example with the help of a VLM and human feedback. The bottom panel provides a visual comparison of a raw, noisy trajectory and its abstracted counterpart after the ICAL process has been applied.
This figure illustrates the In-Context Abstraction Learning (ICAL) process. The top part shows the overall workflow: ICAL takes a noisy trajectory (a sequence of actions and observations), uses a Vision-Language Model (VLM) to optimize the actions and add annotations, executes the optimized trajectory in an environment (getting human feedback for any errors), and stores successful examples in a memory. The bottom part displays a concrete example: on the left, a raw, noisy trajectory, and on the right, the same trajectory after it has been processed by ICAL, showing optimized actions and added annotations (like summaries, task decomposition, and explanations).

This figure illustrates the ICAL process. The top half shows how a noisy trajectory is transformed into useful abstractions using a VLM and human feedback. The bottom half provides a before-and-after comparison of a raw, noisy trajectory and the refined, abstracted example produced by ICAL.

This figure illustrates the In-Context Abstraction Learning (ICAL) process. The top half shows how a noisy trajectory is processed by a Vision-Language Model (VLM) to generate optimized actions and add language annotations. These are then executed in an environment, with human feedback incorporated to correct errors. Successful examples are stored in a memory. The bottom half provides a before-and-after comparison of a raw, noisy trajectory and its ICAL-refined version, highlighting the transformation and abstraction involved.
More on tables
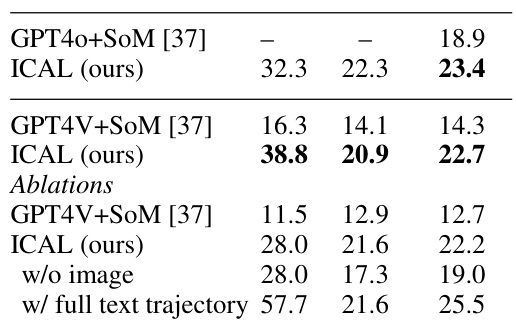
This table presents the results of the VisualWebArena experiment. The ICAL approach is compared against the state-of-the-art method, GPT40/V + Set of Marks. The table also includes ablation studies using GPT4V to examine the impact of removing image input and using full text trajectory on the performance of ICAL.
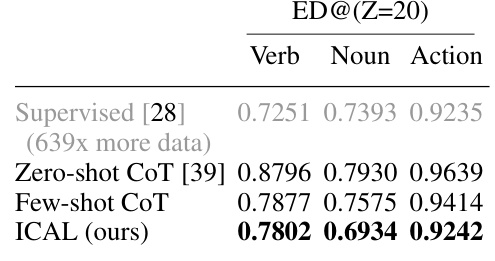
This table presents the results of the Ego4D experiment, comparing ICAL’s performance against few-shot and zero-shot GPT4V and a supervised baseline. The key metric is Edit Distance (ED) at Z=20, measuring the difference between predicted and ground truth action sequences. ICAL shows improvement over few-shot GPT4V, and is competitive with a supervised model trained on substantially more data.

This table presents the results of the VisualWebArena experiment. The ICAL method is compared to the previous state-of-the-art (GPT4V + Set of Marks) and ablation studies using GPT4V are performed on a smaller dataset to analyze the effect of each component. The table shows a significant improvement in performance by the ICAL method compared to the baseline.
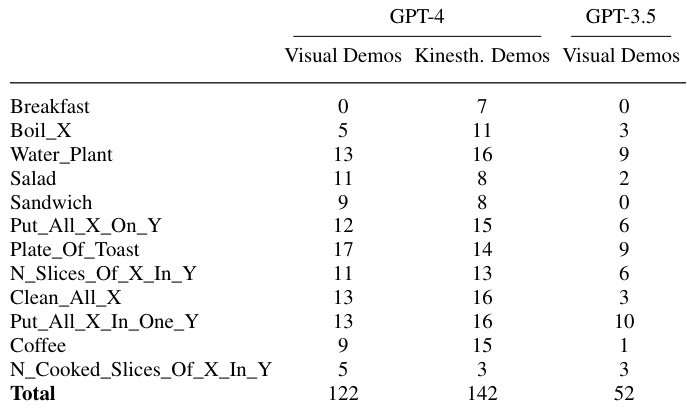
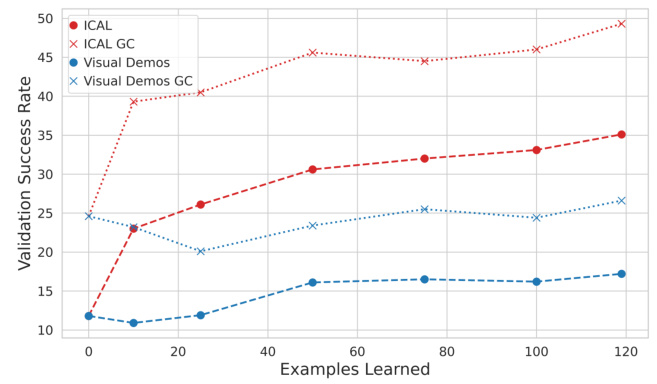
This table compares the number of tasks successfully completed by ICAL using either visual demonstrations (actions labeled using an inverse dynamics model) or kinesthetic demonstrations (actions with ground truth labels). The results are broken down by task type and show how the use of accurate action labels improves ICAL’s performance.
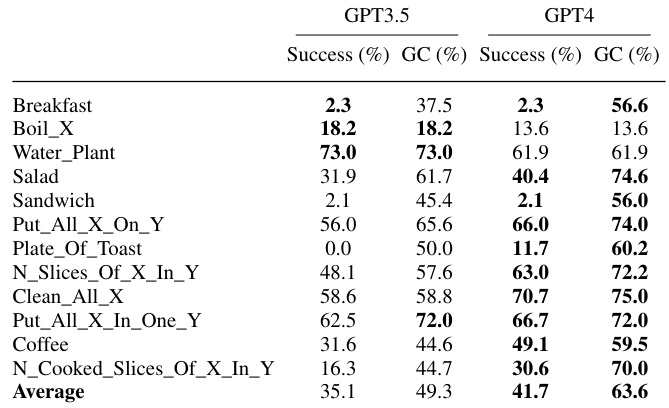
This table presents the results of evaluating different methods on the unseen validation set of the TEACh benchmark. The methods compared include using hand-written examples from the state-of-the-art HELPER model, zero-shot chain of thought prompting, raw visual demonstrations with predicted actions, raw kinesthetic demonstrations with ground truth actions, and the proposed ICAL method. The evaluation metrics are task success rate (SR) and goal-condition success rate (GC). The table highlights the improvements achieved by ICAL compared to other methods, particularly in goal-condition success rate.

This table presents the results of an experiment evaluating the performance of different methods on the unseen validation set of the TEACh dataset. It compares the success rate (SR) and goal condition success rate (GC) of several approaches: HELPER (hand-written examples), zero-shot chain of thought, raw visual demonstrations (with predicted and true actions), and the ICAL method. The table helps to show the improvement achieved by ICAL over baseline methods.

This table presents the results of evaluating different methods on the unseen validation set of the TEACh benchmark for household instruction following. It compares the performance of ICAL against several baselines, including hand-written examples from HELPER (a state-of-the-art method), zero-shot chain-of-thought prompting, and methods using raw visual or kinesthetic demonstrations. The metrics used are task success rate (SR) and goal-condition success rate (GC), showing the percentage of tasks completed successfully and the percentage of tasks that partially fulfilled the instructions, respectively.

This table presents a comparison of the accuracy of different open-source Vision-Language Models (VLMs) in detecting attributes of objects in images from the TEACh dataset. The models were evaluated on both ‘clean’ (posed, unoccluded) and ‘random’ (various angles, potentially occluded) viewpoints. CogVLM demonstrates superior performance across both viewpoints.
Full paper#



















