↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current CAD software lacks intelligent systems for quick model generation. This paper introduces Text2CAD, the first AI framework to generate parametric CAD models from text prompts, ranging from abstract descriptions to detailed instructions. This addresses the need for efficient model prototyping across various skill levels.
Text2CAD uses a novel annotation pipeline leveraging LLMs and VLMs to create a dataset of ~170K models and ~660K annotations. It employs an end-to-end transformer network to generate CAD construction sequences from text prompts and shows improvement over baseline models in accuracy, geometrical precision, and visual quality, opening up possibilities for AI-assisted CAD applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI-aided design and CAD. It introduces the first AI framework for generating parametric CAD models from text descriptions, addressing a significant gap in current technology. This opens avenues for automating design processes and making CAD accessible to users of all skill levels, impacting various industries. The novel dataset and methodology presented also advance research in text-to-3D generation and multi-modal learning.
Visual Insights#

This figure illustrates the core concept of Text2CAD, showing how a user can generate a 3D model using only text prompts describing the desired shapes. Three different prompts—abstract, intermediate, and detailed—are given as examples, demonstrating the system’s ability to create CAD models from various levels of description. It emphasizes that Text2CAD handles design instructions for all levels of user expertise.

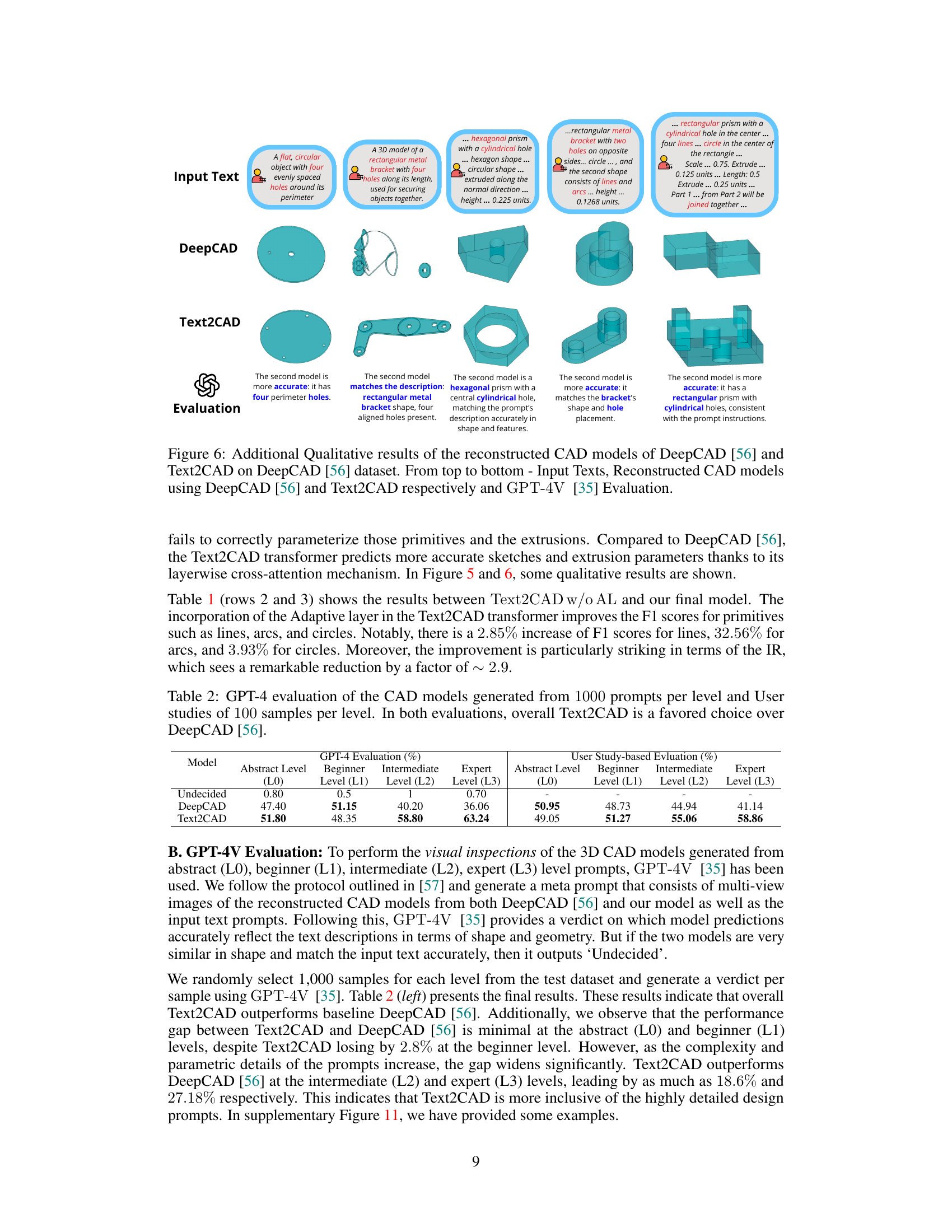
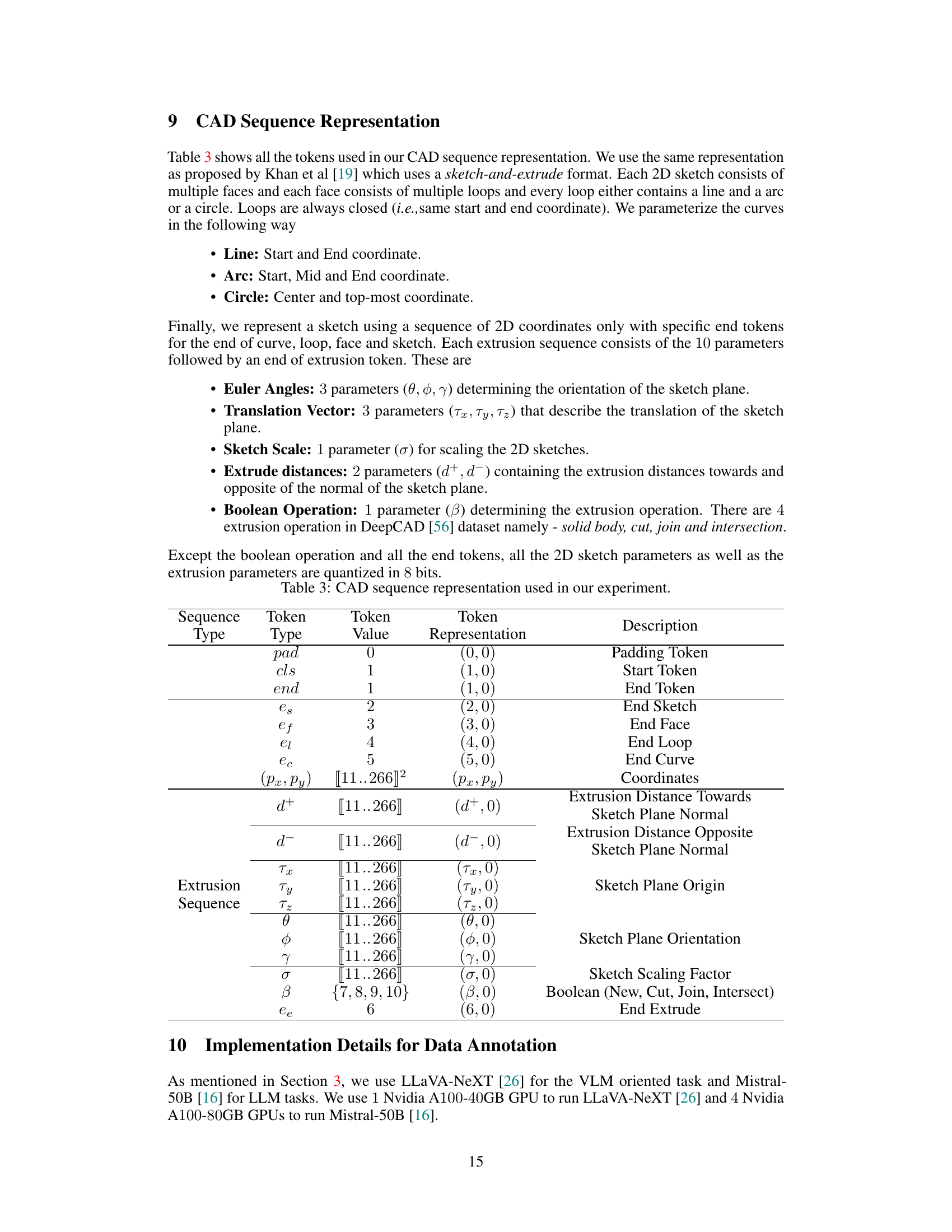
This table presents a quantitative comparison of the performance of the proposed Text2CAD model against the DeepCAD baseline. The evaluation metrics used are F1 scores for primitives (lines, arcs, circles) and extrusions, median and mean Chamfer Distance (CD), and Invalidity Ratio (IR). Importantly, the results shown are only for the expert-level prompts (L3), reflecting the most detailed and parametrically rich descriptions.
In-depth insights#
Text2CAD Framework#
The Text2CAD framework represents a novel approach to AI-assisted CAD design, bridging the gap between natural language descriptions and parametric CAD models. Its core innovation lies in a transformer-based autoregressive network that directly generates CAD construction sequences (parameters for 2D sketches and extrusions) from textual prompts. This differs from previous methods which often involve multiple stages or lack the designer-friendly, human-editable parametric nature of true CAD. The framework’s effectiveness hinges on a multi-level annotation pipeline that leverages both LLMs and VLMs to produce a diverse dataset of textual design prompts ranging from abstract to highly detailed parametric instructions, catering to various skill levels. This approach allows for more intuitive and flexible CAD design, greatly reducing the time and effort involved in creating complex models. Evaluation metrics, including visual quality, parametric precision, and geometrical accuracy, demonstrate the framework’s potential for AI-aided design applications. However, limitations such as sensitivity to perspective distortions in image-based prompts and dataset imbalance remain areas for future improvement.
Multi-Level Prompts#
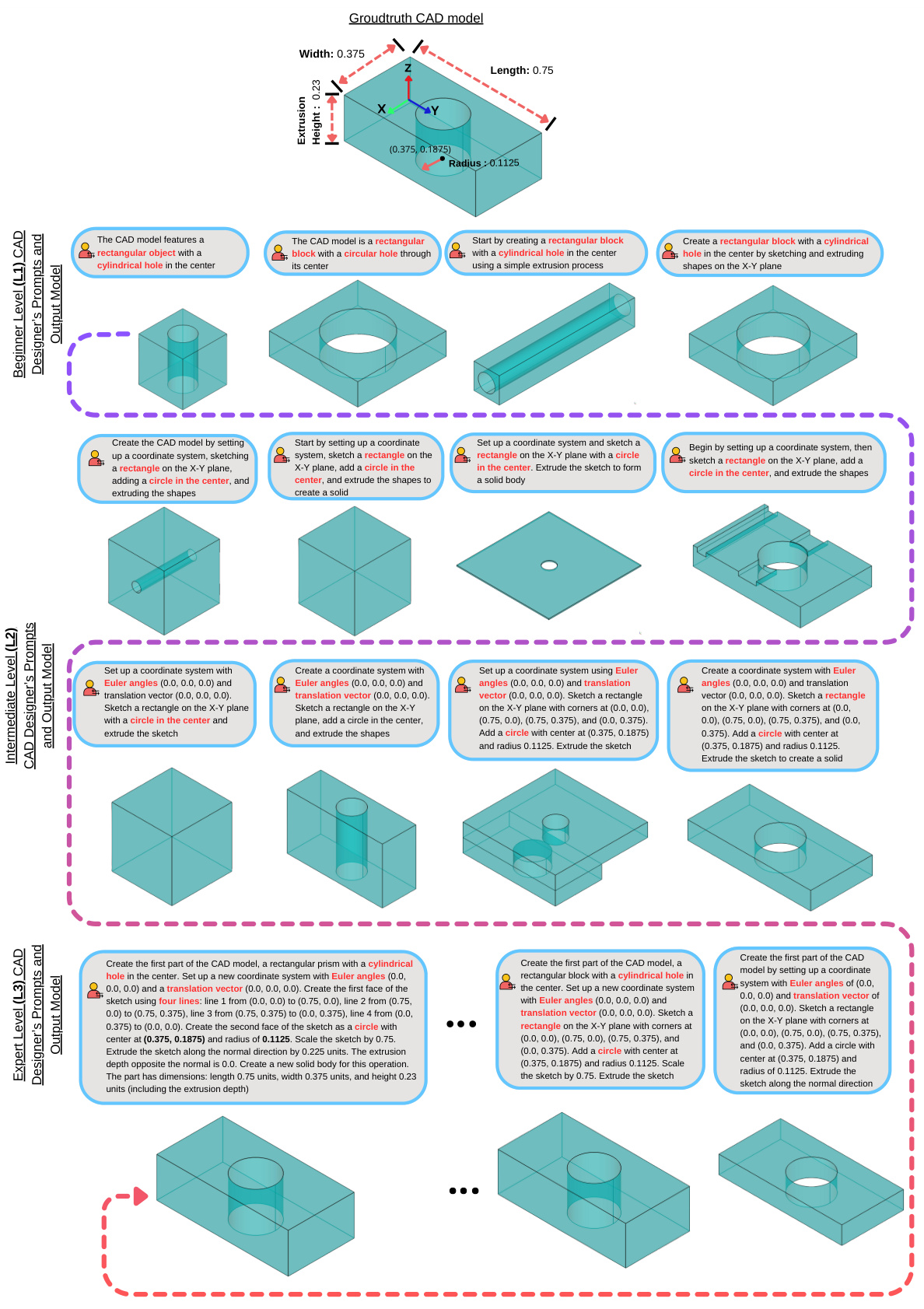
The concept of “Multi-Level Prompts” in the context of a CAD generation model like Text2CAD is a powerful approach to bridge the gap between novice and expert users. It suggests a hierarchy of prompt complexity, allowing users of varying skill levels to interact with the system effectively. Beginner-level prompts would focus on simple shape descriptions, relying on high-level abstract language to convey the desired outcome. Intermediate prompts might introduce more detail, perhaps specifying basic dimensions or relationships between components. Finally, expert-level prompts would incorporate precise parametric instructions, using technical terminology and numerical values to define the exact geometry. This multi-level system enhances accessibility by providing a user-friendly interface for those unfamiliar with CAD, while at the same time offering highly detailed control for experienced users. The success of this approach hinges on the model’s ability to understand and appropriately respond to diverse levels of prompt detail, demonstrating a robust capability for natural language understanding and parametric CAD model generation. The creation of such a system requires a large-scale, carefully curated dataset of CAD models paired with corresponding multi-level prompts to train the AI. It showcases an innovative approach to human-computer interaction, which can have important consequences for the wider adoption of AI tools in various design fields. This is critical to ensure that the technology benefits a broad user base, reducing the entry barrier for those unfamiliar with complex design software.
Transformer Network#
Transformer networks are a powerful class of neural networks that have revolutionized various fields, including natural language processing. Their core innovation lies in the self-attention mechanism, allowing the model to weigh the importance of different parts of the input sequence when processing each element. This contrasts sharply with recurrent networks, which process sequentially and thus struggle with long-range dependencies. The parallel processing nature of transformers significantly speeds up training and inference, making them suitable for large-scale datasets. However, memory and computational complexity become significant challenges when dealing with extremely long sequences. Different architectural variations exist, such as encoder-decoder models (like in machine translation), which leverage separate networks to encode input and decode output. Variations in attention mechanisms (e.g., multi-head attention) and positional encodings further enhance performance and adaptability to diverse tasks. Successfully applying transformers necessitates careful consideration of hyperparameter tuning, and addressing the inherent limitations when dealing with extremely large sequences or extremely high-dimensional data. The overall impact of transformer networks has been transformative across various domains, but further research and development are crucial to fully optimize their potential and address any limitations.
Evaluation Metrics#
Choosing the right evaluation metrics is crucial for assessing the performance of any text-to-CAD model. A good evaluation strategy should consider both parametric accuracy (how well the generated CAD parameters match the input text description) and geometric accuracy (how close the generated 3D model is to the intended design). Qualitative assessment, involving visual inspection and expert evaluation, is also valuable to capture nuances missed by quantitative metrics. A balanced approach, using multiple metrics including F1 scores for primitives and extrusions, Chamfer distance (CD), and Invalidity Ratio (IR), provides a more holistic understanding of model performance across different aspects. Furthermore, using multiple levels of textual prompts (abstract to expert) for evaluation helps to reveal the model’s strengths and limitations across various levels of design complexity, and incorporating human evaluation adds an essential layer of qualitative assessment to complement and validate quantitative results. Ultimately, a robust evaluation needs to align metrics with the practical goals and the user experience of the target application to make sound conclusions about system capabilities.
Future of Text2CAD#
The future of Text2CAD hinges on several key advancements. Improving data diversity is crucial; current datasets are limited, skewing towards simple shapes. Expanding the dataset to include more complex designs, intricate features, and diverse materials will significantly enhance the model’s capabilities. Enhanced multi-modal learning is another critical aspect. By integrating more diverse data types (e.g., images, sketches, and physical properties) and leveraging advanced techniques, Text2CAD can produce more sophisticated and accurate models. Refining the generative process to handle more complex designs with greater precision is crucial. This requires improving the architecture’s ability to manage intricate geometric relationships and incorporate real-world constraints more effectively. Additionally, integrating user feedback into the generative loop will allow for a more iterative and interactive design process, enabling users to seamlessly refine designs based on their specific needs. Finally, exploring broader applications beyond simple CAD models is a promising avenue. The potential applications are vast, ranging from generative design of complex manufactured parts to robotics and architectural planning, showcasing the transformative power of AI-assisted CAD.
More visual insights#
More on figures

This figure illustrates the two-stage data annotation pipeline used in the Text2CAD project. The first stage utilizes a Vision Language Model (VLM) to generate abstract shape descriptions from multi-view images of the 3D CAD models. These descriptions capture the overall structure of the model. The second stage employs a Large Language Model (LLM) to produce multi-level natural language instructions (NLIs) based on the shape descriptions and detailed CAD construction information. These instructions are categorized into four levels of complexity: abstract, beginner, intermediate, and expert, making them suitable for users of varying CAD skill levels.

This figure illustrates the architecture of the Text2CAD Transformer, a deep learning model designed to generate parametric CAD models from text prompts. It shows how the model processes text input (T) and an existing CAD sequence (C1:t-1) using a BERT encoder, an adaptive layer, and multiple transformer decoder blocks to produce a complete CAD sequence (C2:t). The figure highlights the different components of the model, including the embedding layers, attention mechanisms, and feedforward networks, illustrating the autoregressive generation process step-by-step. The final output is a reconstructed 3D CAD model.
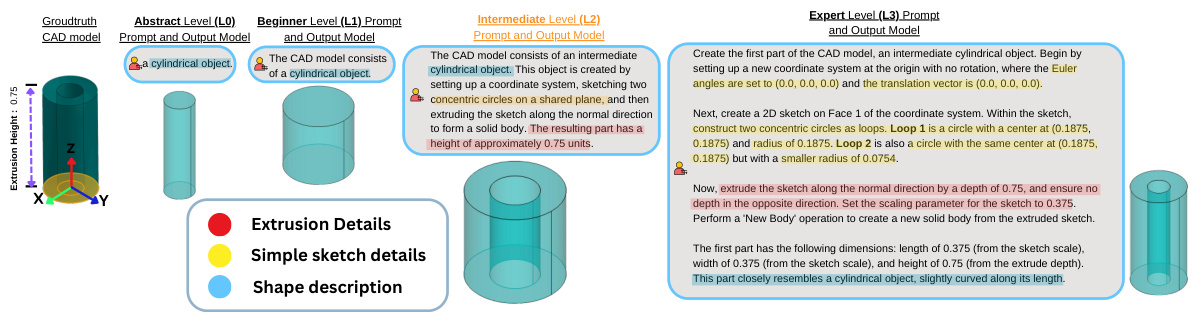
This figure shows the CAD models generated by the Text2CAD model using different levels of text prompts. The prompts are color-coded to represent the level of detail: teal for abstract and beginner levels, yellow for intermediate, and red for expert. The figure demonstrates how the model generates more detailed and parametric CAD models from more detailed prompts.
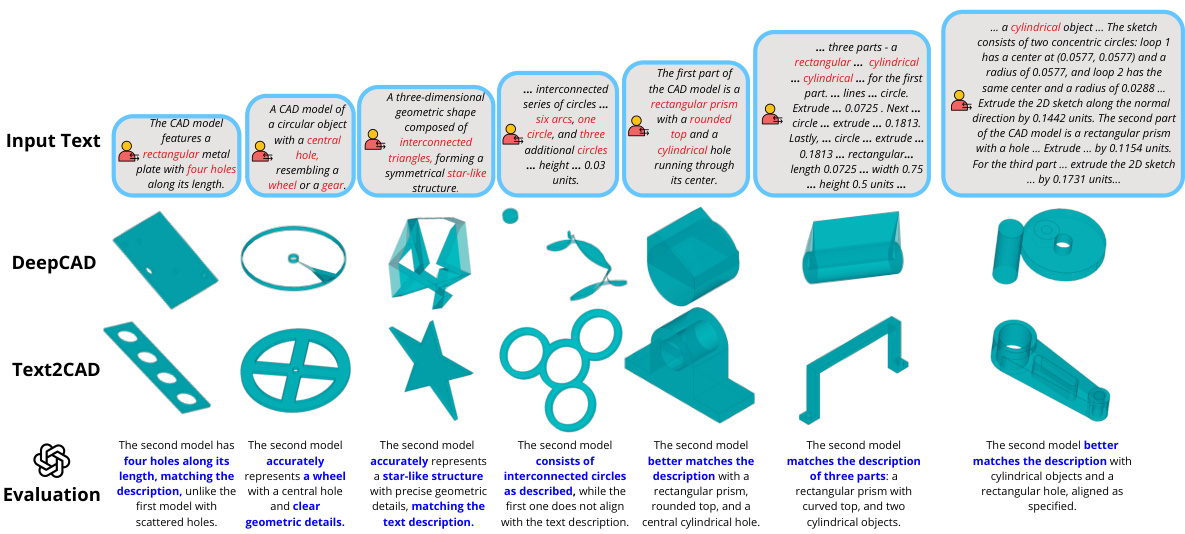
This figure shows the different CAD models generated by using different levels of text prompts (abstract, beginner, intermediate, and expert). Each level of prompt is color-coded to easily distinguish the type of description used in the prompt, and the resulting CAD model demonstrates the complexity of the model based on the prompt’s detail level.
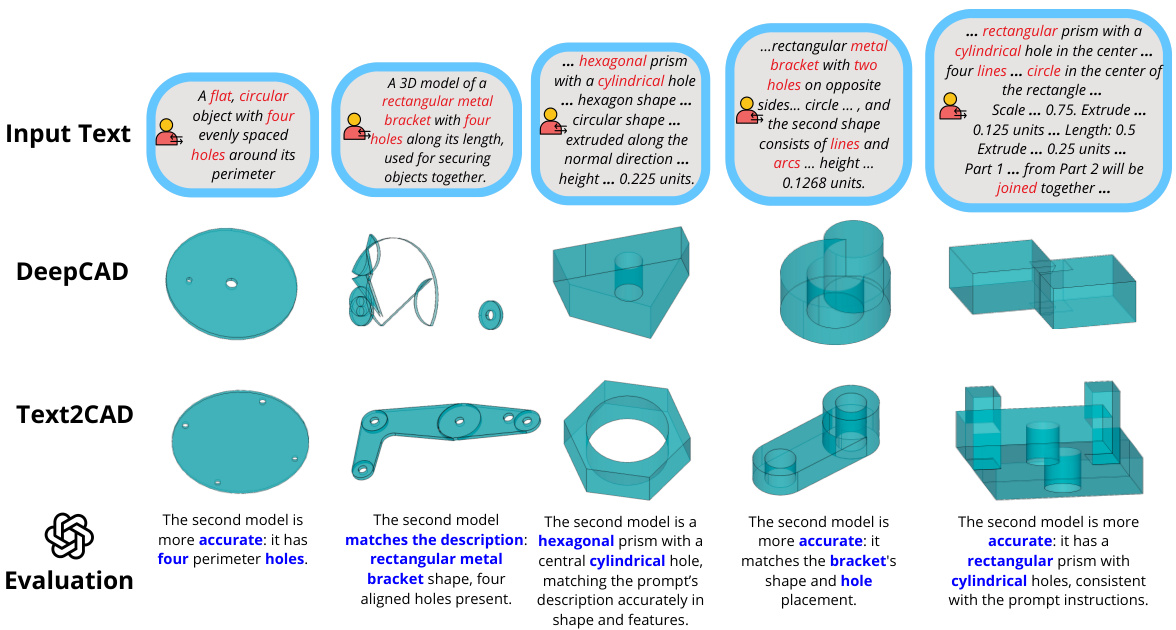
This figure shows how the Text2CAD model generates CAD models from different levels of text prompts. The prompts range from abstract shape descriptions to detailed parametric instructions. The figure showcases the impact of prompt detail on the generated CAD model, illustrating the model’s ability to handle varying levels of user expertise.

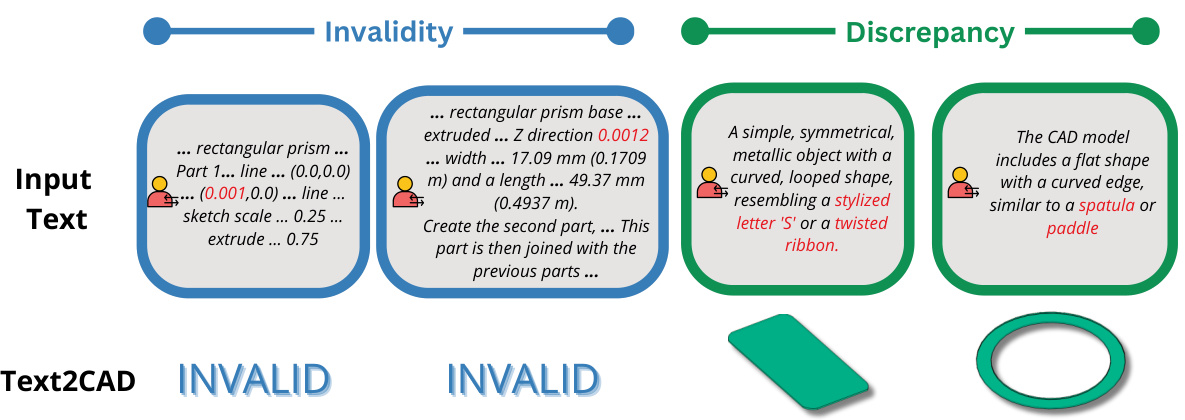
This figure shows two examples to demonstrate the robustness of the Text2CAD model to different prompt styles. The first example shows three different prompts that all successfully generate the same ring-like CAD model. These prompts vary in descriptive detail, with one prompt being highly abstract while others provide more specific details of the shape’s features. The second example demonstrates that three prompts, each employing different wording and emphasis on specific star features, all yield the same star-shaped CAD model. This illustrates the model’s ability to handle diverse phrasing and contextual clues in natural language design instructions.
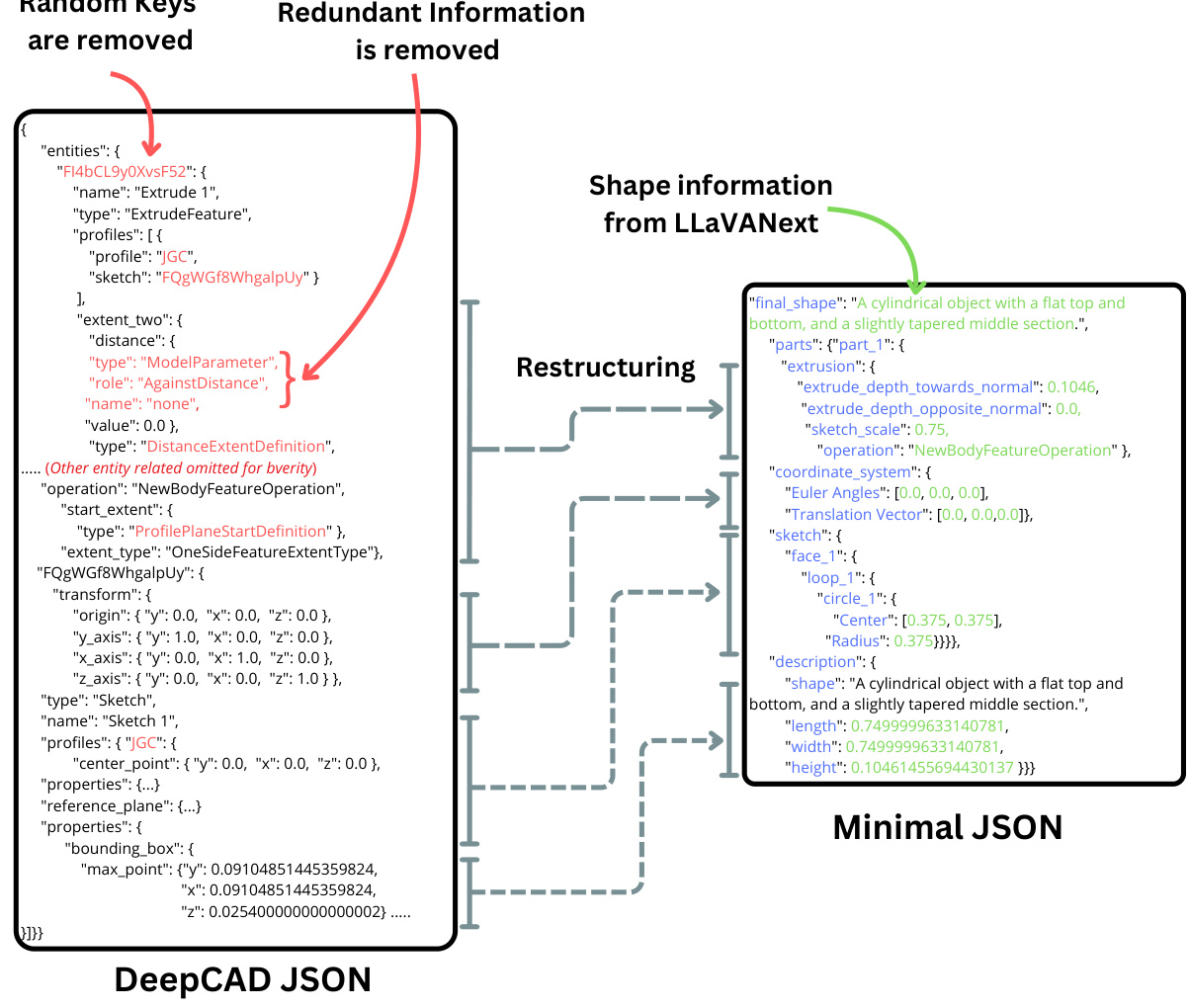
This figure illustrates the two-stage data annotation pipeline used in the Text2CAD project. Stage 1 employs a Vision Language Model (VLM) to generate abstract shape descriptions from multi-view images of CAD models. These descriptions are then used in Stage 2, which leverages a Large Language Model (LLM) to produce multi-level textual instructions detailing the CAD construction process. These instructions range from abstract descriptions to detailed parametric instructions, catering to various user skill levels.
This figure illustrates the architecture of the Text2CAD Transformer model. The model takes as input a text prompt and a partial CAD sequence. It uses a pre-trained BERT encoder and an adaptive layer to process the text, creating a text embedding. This embedding is then integrated with the partial CAD sequence embedding using a transformer decoder with layer-wise cross-attention mechanisms. The decoder generates the complete CAD sequence autoregressively.
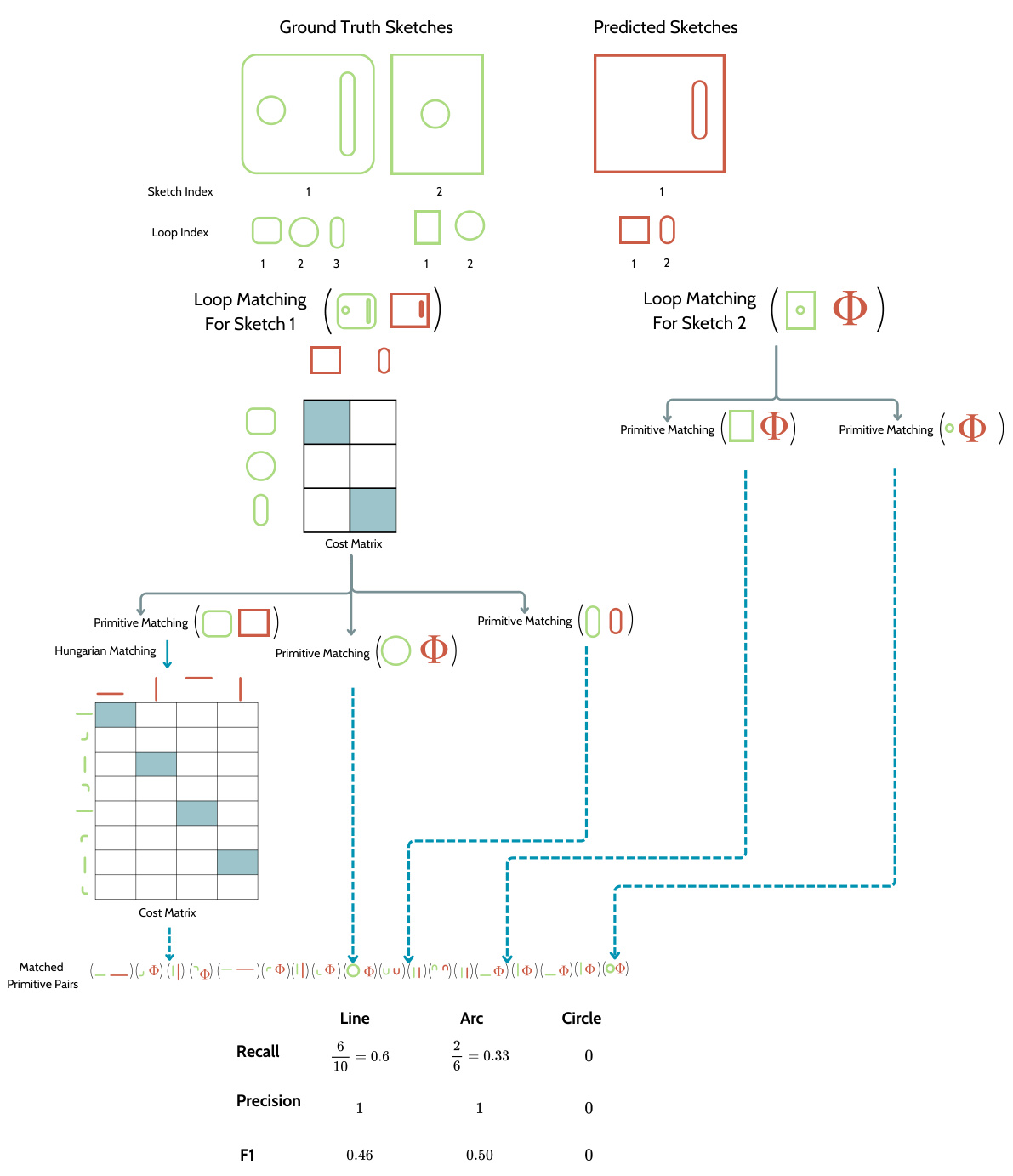
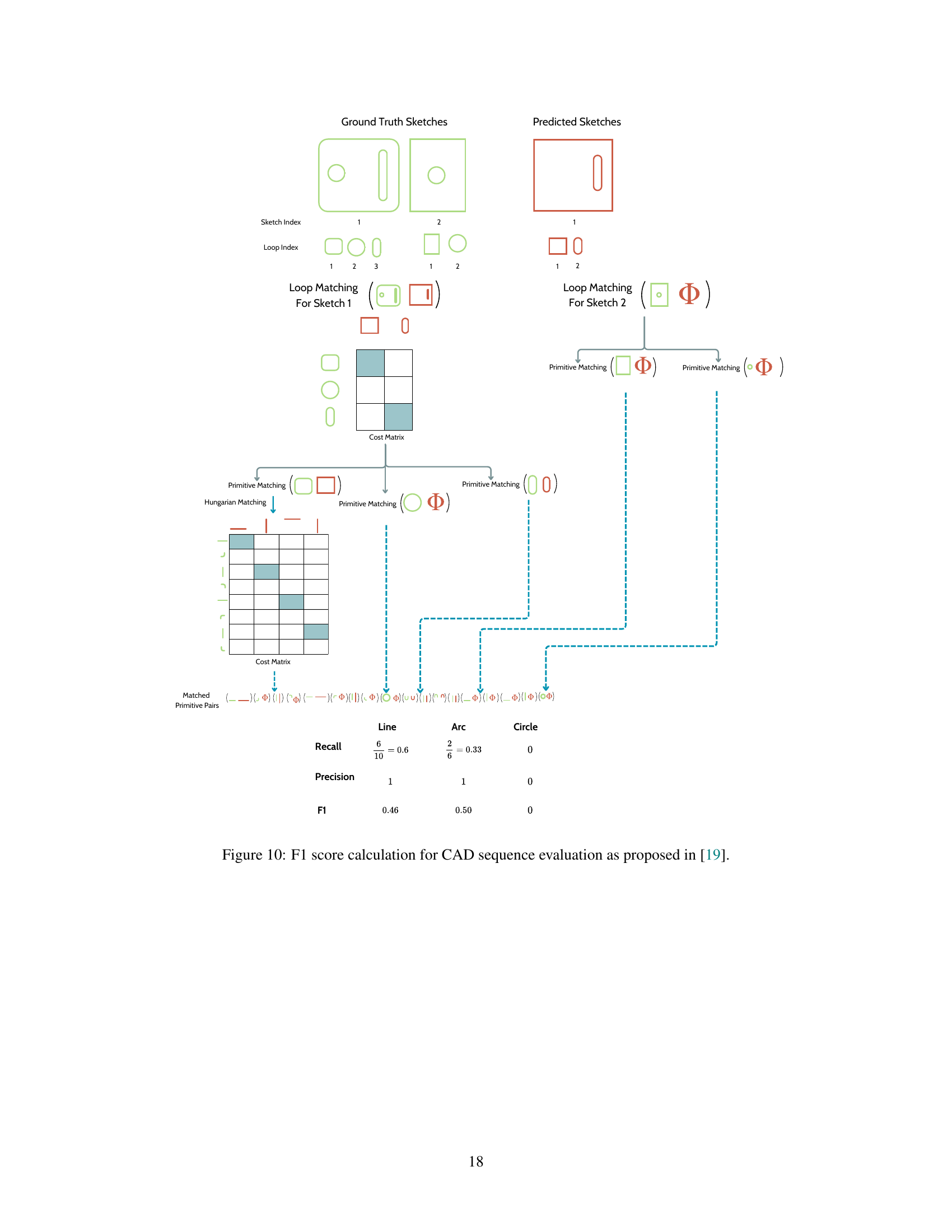
This figure illustrates the F1 score calculation method for evaluating CAD sequences, as proposed in reference [19]. It shows a comparison between ground truth sketches and predicted sketches, detailing the process of loop matching and primitive matching to arrive at the final F1 score. The steps include matching loops within each sketch, creating a cost matrix for primitives (lines, arcs, circles) within the matched loops, and applying the Hungarian algorithm to find the best matches. Finally, precision, recall, and the F1 score are calculated.
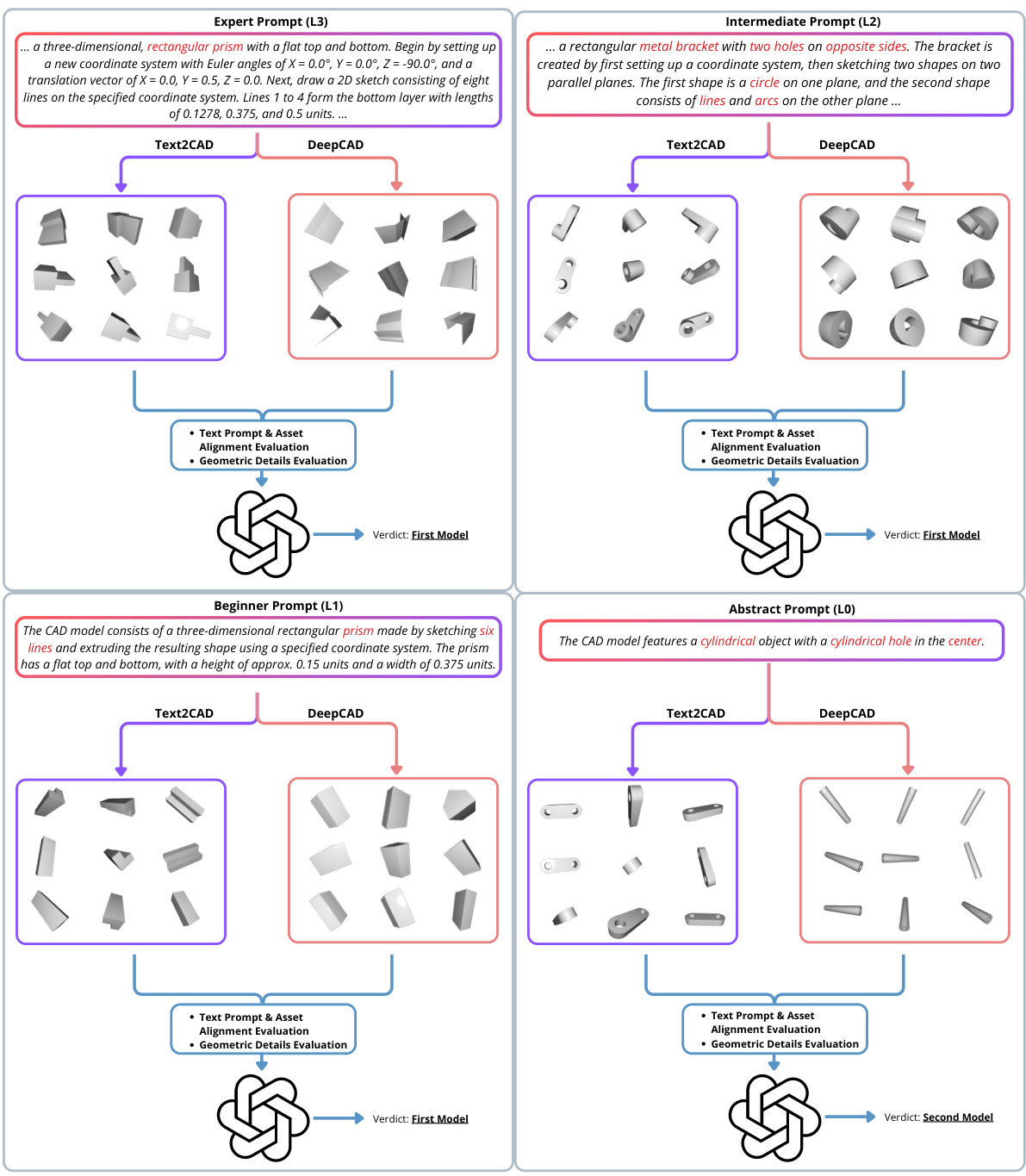
This figure shows examples of CAD models generated by the Text2CAD model using different levels of textual prompts. The prompts vary in complexity from abstract shape descriptions to highly detailed, parametric instructions. The color-coding of the prompts highlights the different types of information provided (shape description, simple sketch details, extrusion details). The figure demonstrates how the model’s output changes depending on the level of detail in the prompt, highlighting the model’s ability to generate CAD models from various levels of user input.

This figure illustrates the architecture of the Text2CAD Transformer model. It shows how the model processes text prompts and existing CAD sequences to generate a complete parametric CAD model. The process starts with a pre-trained BERT encoder to process the text prompt, followed by an adaptive layer to refine the embedding. This refined text embedding and the existing CAD sequence are then fed into multiple transformer decoder blocks which produce a sequence representing the steps for creating a CAD model. The output of the decoder is a full CAD sequence, allowing autoregressive generation of the model.
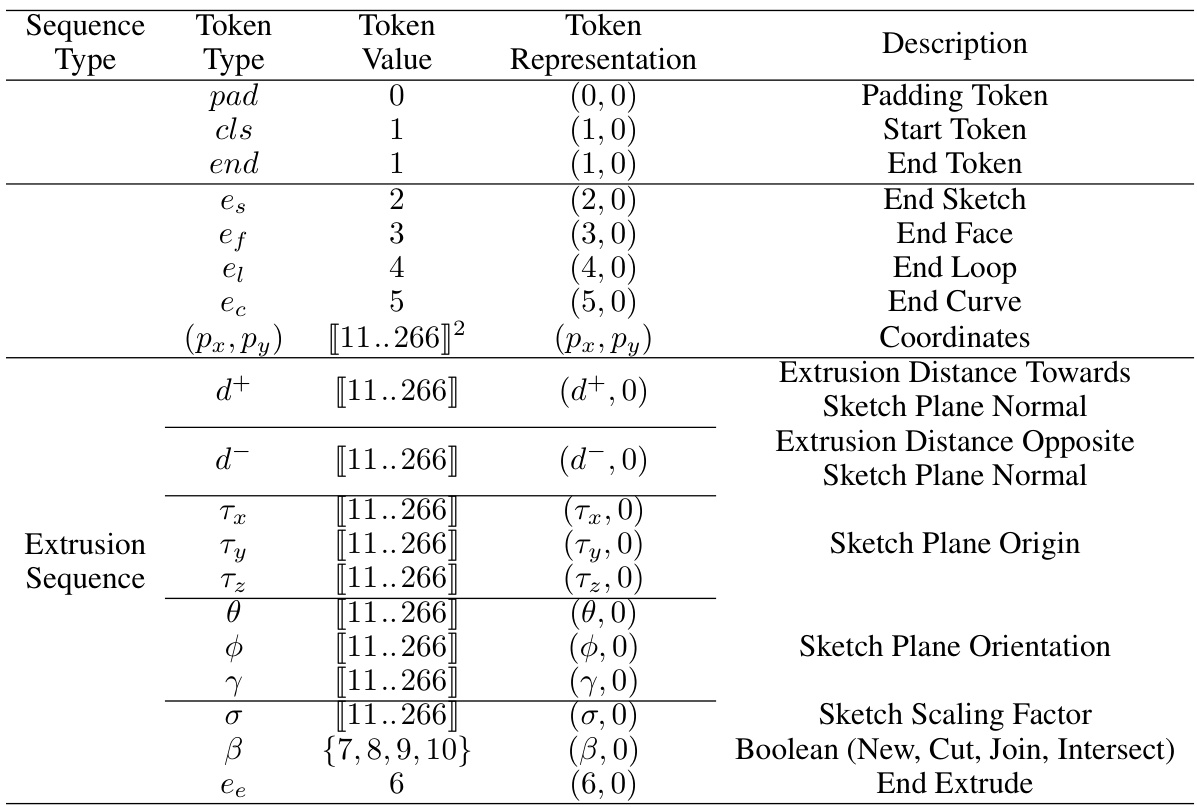
This figure illustrates the architecture of the Text2CAD Transformer, a deep learning model designed to generate parametric CAD models from text descriptions. The model takes as input a text prompt and a sequence of previously generated CAD tokens. It processes the text prompt using a pre-trained BERT encoder and an adaptive layer to create a contextual text embedding. This embedding, combined with the existing CAD sequence embedding, is fed into multiple transformer decoder blocks. These blocks generate the next CAD tokens in an auto-regressive manner, sequentially building up the complete CAD model description.
More on tables

This table presents a quantitative comparison of the performance of the proposed Text2CAD model and the baseline DeepCAD model. The evaluation focuses on expert-level prompts (L3) and uses several metrics: F1 scores for primitives (line, arc, circle) and extrusions, mean and median Chamfer Distance (CD), and Invalidity Ratio (IR). Lower CD and IR values indicate better performance. The table highlights the superior performance of Text2CAD compared to DeepCAD across all metrics.
This table presents a quantitative comparison of the performance of the proposed Text2CAD model against the DeepCAD baseline model. The evaluation metrics used are F1 scores (for primitives and extrusions), Chamfer Distance (CD), and Invalidity Ratio (IR), focusing solely on Expert Level (L3) prompts, which are the most detailed and complex prompts in the dataset. Lower CD and IR values indicate better performance.
Full paper#