↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Real-time neural rendering using point-based techniques like 3D Gaussian Splatting has gained popularity. However, these methods often suffer from high storage overheads, hindering scalability and efficiency, especially for unbounded scenes with millions of points. This paper addresses these scalability challenges by focusing on compressing 3D Gaussian representations.
LightGaussian tackles this problem by implementing a three-step pipeline: Gaussian Pruning and Recovery to reduce redundancy, SH Distillation to compact spherical harmonic coefficients, and Vector Quantization to further reduce bitwidth. Through these methods, LightGaussian achieves an average 15x compression rate, while significantly boosting FPS (from 144 to 237) and maintaining high visual quality. The method also demonstrates adaptability to other 3D representations, suggesting broad applicability and potential for future improvements in real-time neural rendering.
Key Takeaways#
Why does it matter?#
This paper is important because it presents LightGaussian, a novel method that significantly improves the efficiency of 3D scene representation. This addresses a critical challenge in real-time rendering by reducing storage needs and improving rendering speed. The techniques used are broadly applicable, opening up new avenues of research in neural rendering and related fields.
Visual Insights#
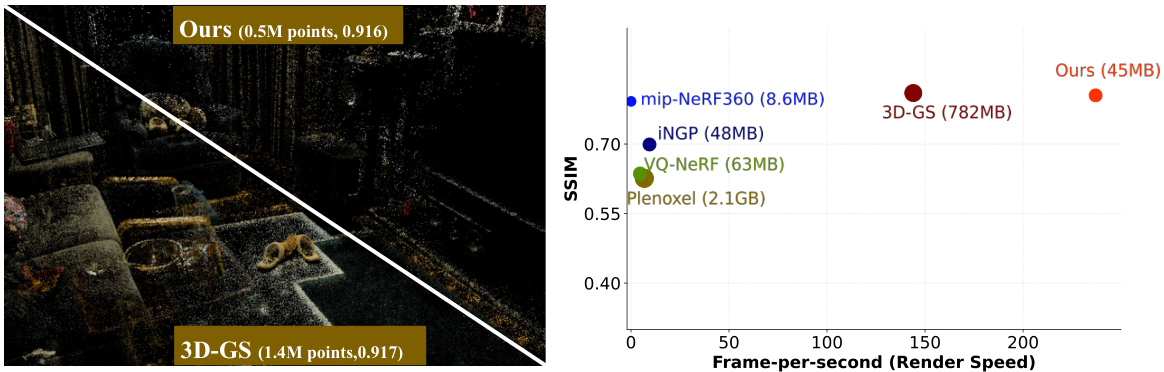
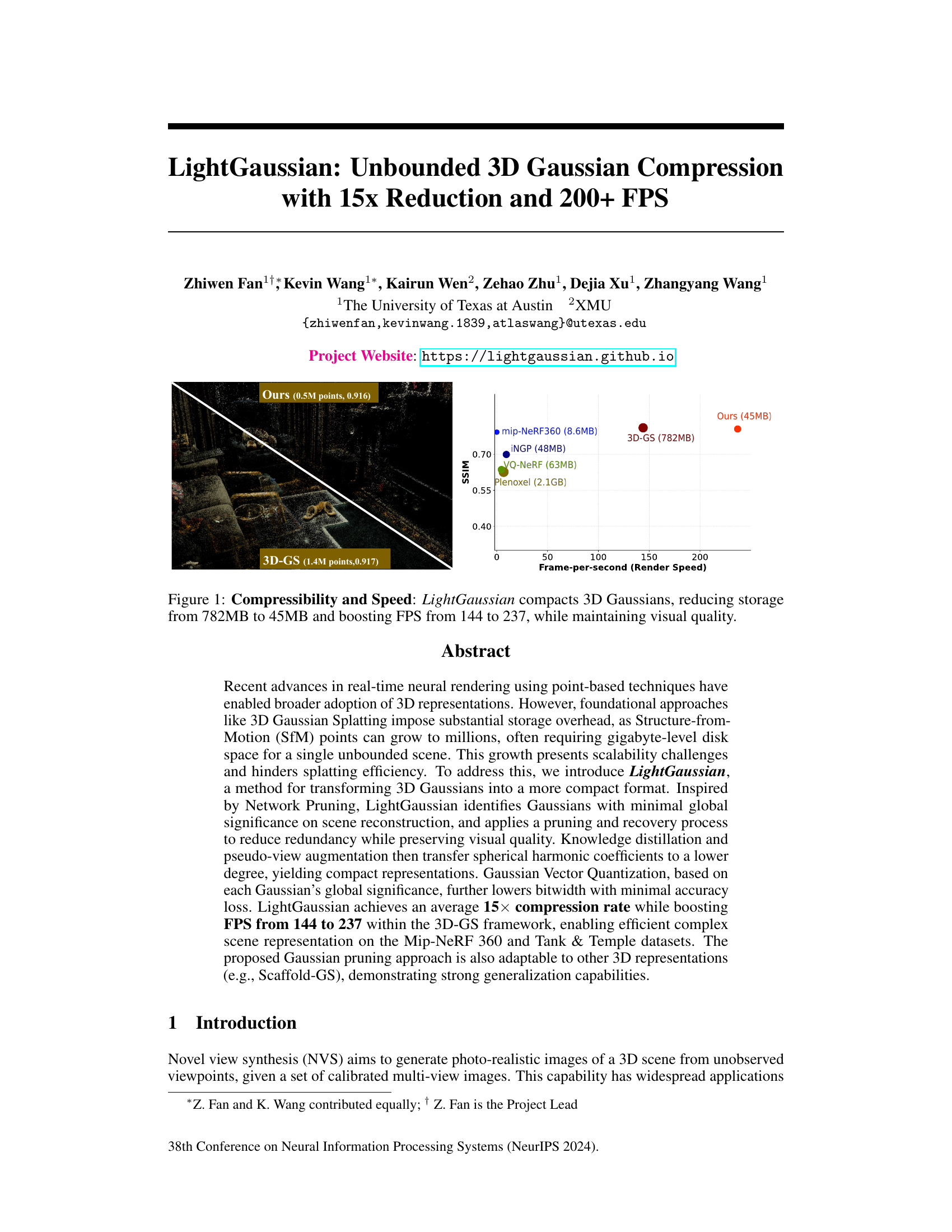
This figure demonstrates the effectiveness of LightGaussian in compressing 3D Gaussian representations. It shows a comparison of storage size and rendering speed between LightGaussian and other state-of-the-art methods (3D-GS, Mip-NeRF 360, INGP, VQ-NeRF, Plenoxels). LightGaussian significantly reduces the storage size (from 782MB to 45MB) while achieving a substantial increase in rendering speed (from 144 FPS to 237 FPS), all while maintaining comparable visual quality.
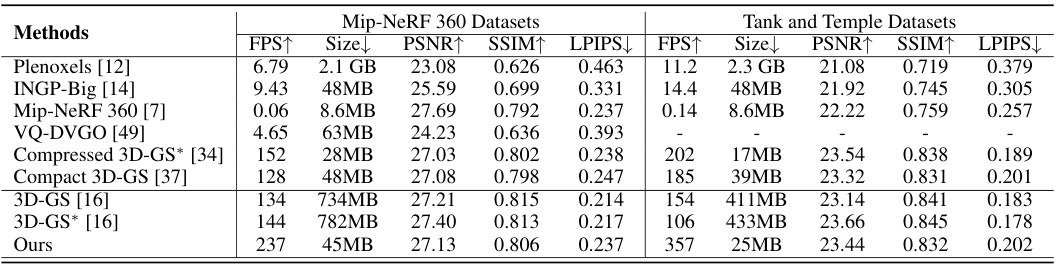
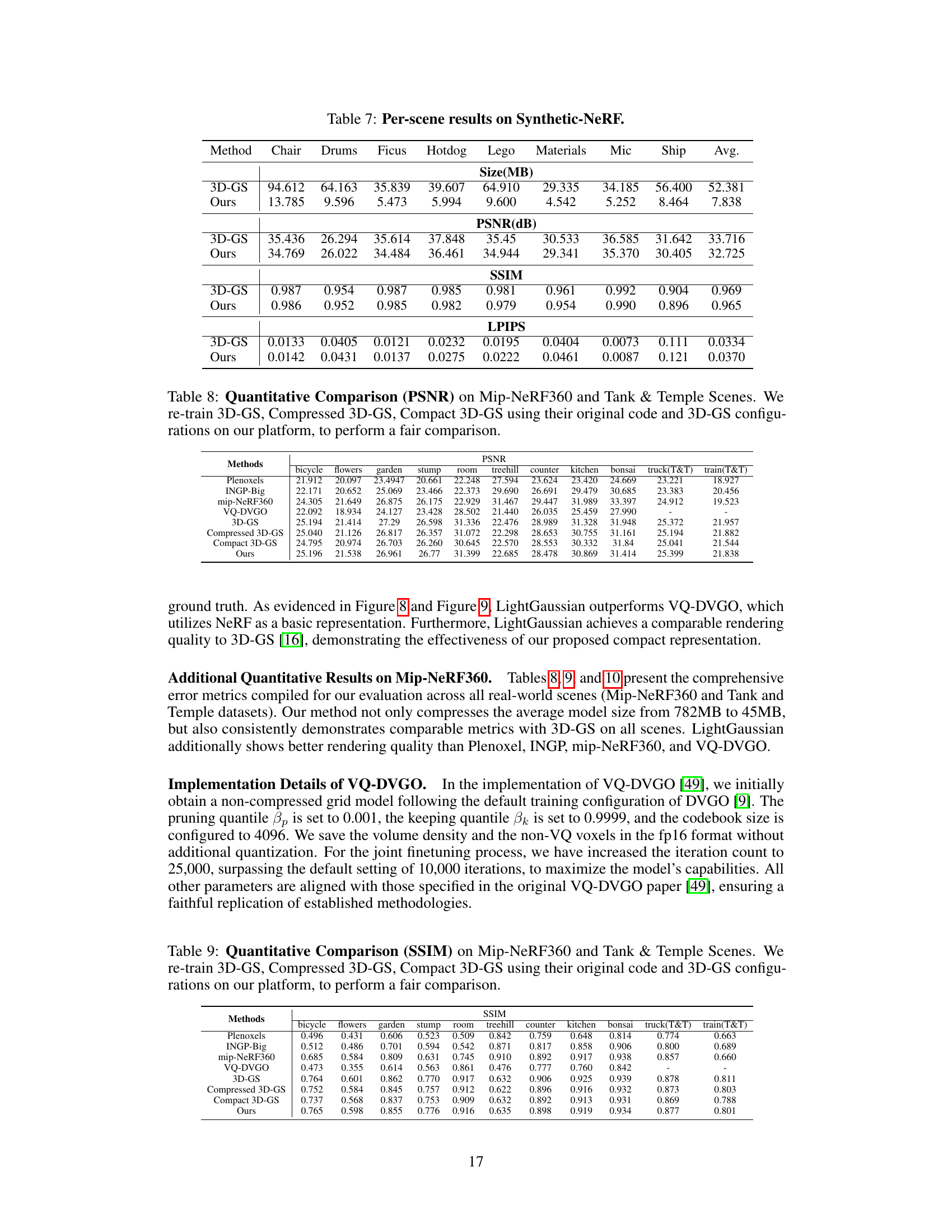
This table provides a quantitative comparison of LightGaussian against several state-of-the-art methods for large-scale scene representation on real-world datasets (Mip-NeRF 360 and Tanks & Temples). The comparison includes metrics like FPS, model size (Size), PSNR, SSIM, and LPIPS, highlighting LightGaussian’s superior balance of speed, size, and visual quality.
In-depth insights#
Gaussian Pruning#
Gaussian pruning, a core technique in the LightGaussian framework, addresses the challenge of excessive storage in point-based 3D scene representations. The method efficiently reduces redundancy by identifying and removing Gaussians with minimal global impact on visual quality. This process is crucial for achieving the 15x compression rate reported in the paper. The key innovation lies in the global significance calculation, which goes beyond simple metrics like opacity to assess a Gaussian’s contribution to the overall scene rendering. By prioritizing Gaussians with high global significance, the algorithm effectively preserves essential details while removing less influential components. The subsequent recovery step further ensures smooth adaptation after pruning, preventing visual artifacts and maintaining overall scene quality. This intelligent pruning strategy, combined with SH distillation and vector quantization, demonstrates a powerful approach to compressing 3D Gaussian splatting representations without significant visual loss, making real-time rendering of complex scenes feasible.
SH Distillation#
The technique of SH Distillation, as described in the context of the research paper, is a crucial method for compressing the 3D Gaussian splatting representation. It directly tackles the high dimensionality of Spherical Harmonics (SH) coefficients, a significant contributor to the large file sizes associated with this type of 3D scene representation. The core idea involves transferring knowledge from a high-degree SH representation (the teacher model) to a low-degree SH representation (the student model). This process cleverly reduces the number of SH coefficients required to represent the scene, leading to substantial compression without excessively sacrificing visual quality. The method cleverly uses pseudo-view augmentation, synthesizing additional views to enrich the training data and improve the accuracy of the knowledge transfer. This technique demonstrates a compelling balance between compression efficiency and visual fidelity, paving the way for more efficient and compact representations of complex 3D scenes. Combining this with other techniques like Gaussian pruning and vector quantization further enhances the compression rate, resulting in a significantly smaller 3D model that maintains high visual quality. It’s a critical step in enabling efficient real-time rendering of complex scenes.
VQ Compression#
Vector quantization (VQ) is a powerful compression technique, particularly relevant in the context of high-dimensional data like the 3D Gaussian representations used in neural radiance fields. The core idea is to replace high-dimensional vectors with indices pointing to a smaller codebook of representative vectors. This significantly reduces storage requirements. However, naively applying VQ to all Gaussian attributes can lead to significant quality loss. A key insight is to selectively apply VQ based on a metric of significance, pruning less important features while retaining crucial information. This selective approach helps in achieving a good balance between compression and the fidelity of the 3D scene reconstruction. This strategy is effective as it avoids excessive quantization of essential attributes (like position and color), retaining visual quality while dramatically reducing file size. The combination of pruning and VQ allows for an extremely high compression ratio compared to existing methods in the paper.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, it would involve removing elements like Gaussian pruning, SH distillation, or vector quantization one at a time to understand their effects on model performance (e.g., PSNR, SSIM, FPS). The results would reveal which components are crucial for achieving high performance and compression, informing design choices and highlighting potential areas for future improvement. For instance, removing Gaussian pruning might lead to significantly increased model size, whereas disabling SH distillation could reduce rendering quality. A well-designed ablation study would provide a clear picture of the trade-offs involved in each component and validate the overall approach by demonstrating that each element plays a significant role in achieving the final results.
Future Directions#
Future research could explore improving the efficiency of LightGaussian further by investigating more sophisticated pruning techniques or by leveraging advancements in quantization methods. Another promising avenue is extending LightGaussian’s applicability to other 3D representations beyond Gaussian splatting, potentially adapting the core principles to handle meshes or point clouds directly. Incorporating uncertainty quantification into the compression process is crucial for robust handling of noisy data. Finally, a key area for future work is developing LightGaussian for real-time applications, possibly via hardware acceleration techniques, thus enabling widespread usage in AR/VR and other interactive contexts.
More visual insights#
More on figures
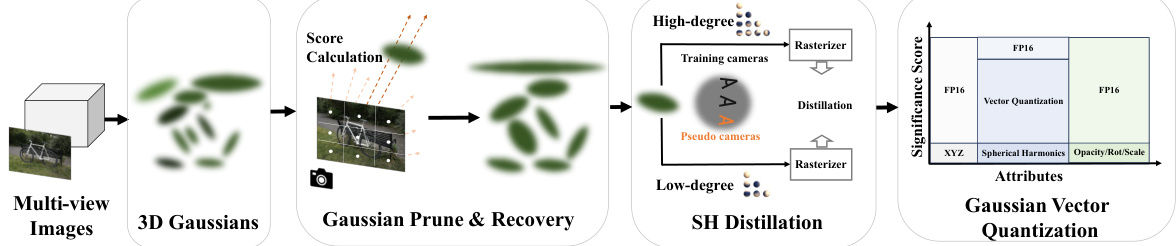
This figure illustrates the pipeline of the LightGaussian method. It starts with multi-view images and Structure from Motion (SfM) points to generate 3D Gaussians. Then, a Gaussian pruning and recovery step removes less significant Gaussians. Spherical harmonic (SH) coefficients are distilled to lower degrees using pseudo-views. Finally, vector quantization compresses the remaining attributes.
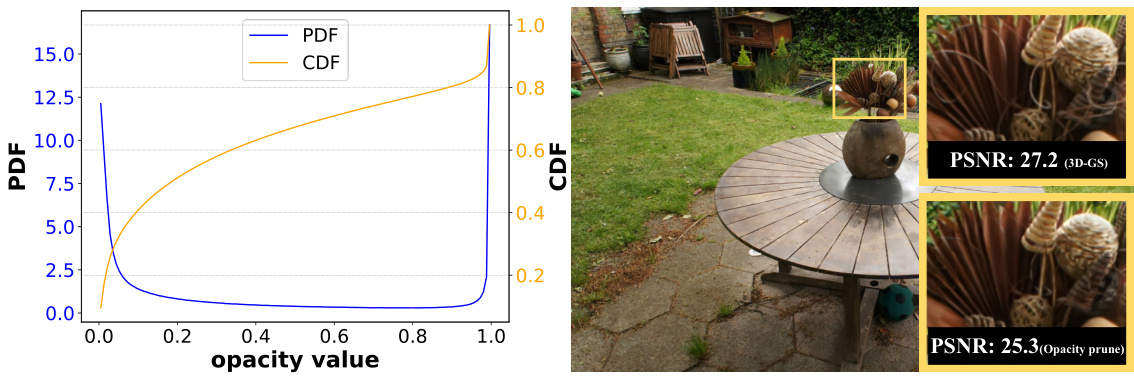
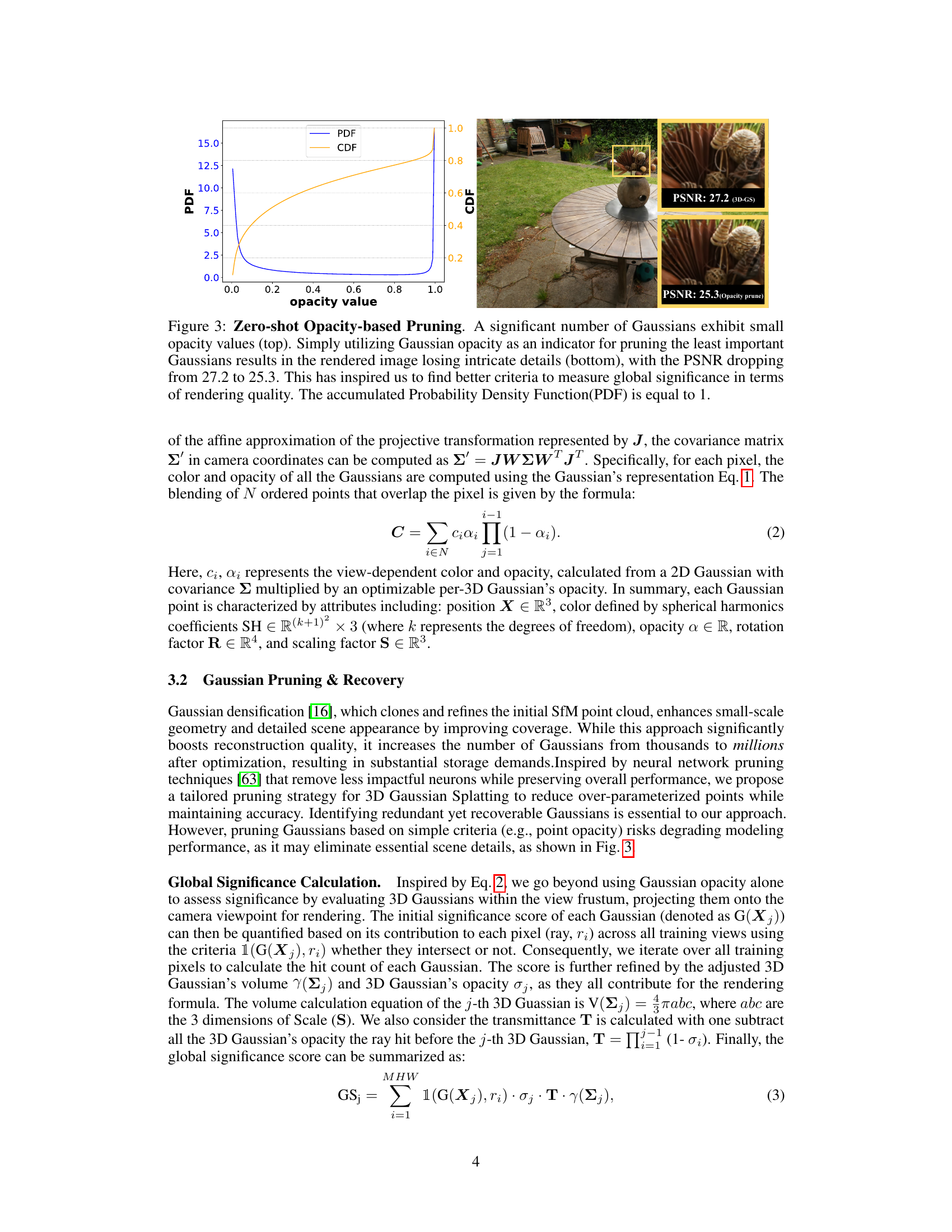
This figure shows the limitations of using opacity alone for pruning Gaussians. The top graph shows the probability density function (PDF) and cumulative distribution function (CDF) of Gaussian opacity, revealing that many Gaussians have low opacity. The bottom part shows that simply pruning Gaussians with low opacity leads to loss of detail in the rendered image, as shown by the lower PSNR (25.3 vs 27.2). This motivates the authors to develop a more sophisticated metric for global significance.

This figure compares the visual quality of images rendered using LightGaussian and the baseline 3D-Gaussian Splatting (3D-GS) method. It shows ground truth images alongside images generated by both methods, and also shows residual maps which highlight the differences between the rendered images and the ground truth. The residual maps show that LightGaussian maintains a high degree of visual fidelity compared to 3D-GS, particularly in preserving specular highlights and subtle details, despite achieving a significantly smaller model size.

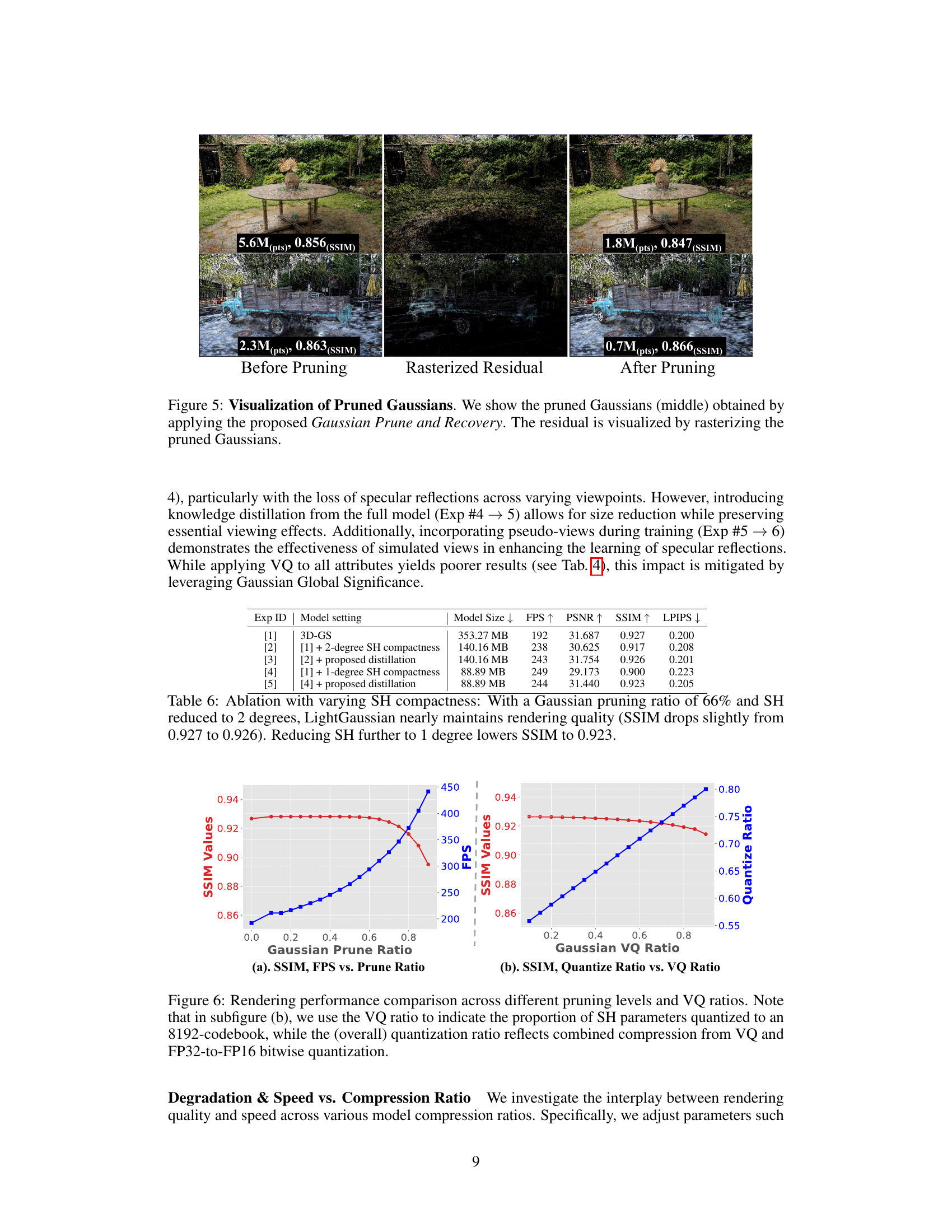
This figure shows the effect of the Gaussian Pruning and Recovery method. The left image shows the original scene with a large number of Gaussians. The middle image shows the pruned Gaussians, which have been identified and removed by the algorithm. The right image shows the final scene after the pruning and recovery process. The residual map (middle image) visualizes the difference between the original and the pruned scenes, showing where the pruned Gaussians were located.
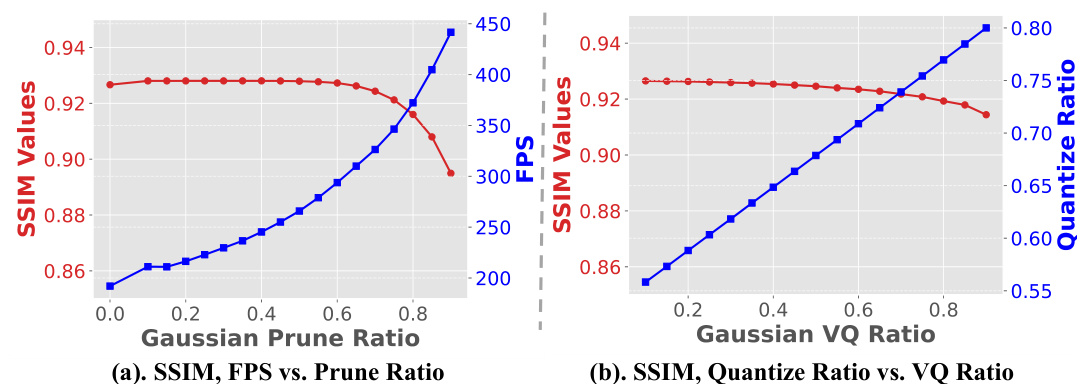
The figure shows two plots that illustrate the trade-off between rendering performance (SSIM and FPS) and compression ratio. The left plot shows how SSIM and FPS change with varying levels of Gaussian pruning. The right plot shows how SSIM and the quantization ratio change with varying levels of Gaussian vector quantization. Both plots demonstrate that increased compression leads to lower SSIM (quality) and potentially FPS (speed), with a steeper drop-off at higher compression ratios.

This figure shows a visual comparison of the results from the ablation study. The rendered RGB images and the residual maps (SSIM) are displayed for each experiment (Exp #1 to Exp #9). Experiment #9, representing the full LightGaussian method, shows results very close to the baseline 3D-GS method (Exp #1). This demonstrates the effectiveness of the Gaussian Co-adaptation and SH distillation components in mitigating information loss during the compression process. The residual maps (SSIM) visually illustrate the differences between rendered images and the ground truth.

This figure compares the visual quality of images rendered using LightGaussian and the original 3D-GS method. It shows the ground truth images alongside the renderings from both methods, and highlights the differences using residual maps (difference between the rendering and ground truth). The residual maps are scaled to emphasize subtle differences and clearly show that LightGaussian achieves comparable quality to 3D-GS while using significantly less data.

This figure compares the visual quality of images rendered using LightGaussian and the baseline 3D-Gaussian Splatting method (3D-GS). It shows both RGB images and residual maps (difference between rendered and ground truth images) for four different scenes. The residual maps highlight that LightGaussian, despite its significantly smaller size, maintains high visual fidelity, especially preserving specular highlights.
More on tables
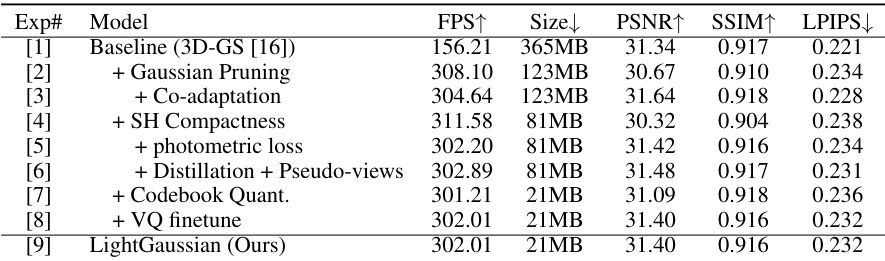
This table presents the ablation study results for LightGaussian. It shows the impact of each component (Gaussian Pruning & Recovery, SH Compactness, and Vector Quantization) on the overall performance. The results are presented for a single scene (‘Room’) and demonstrate how each component contributes to the final model’s size, speed, and quality.
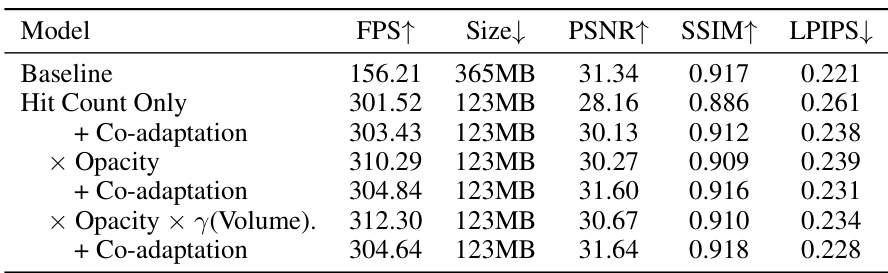
This table presents an ablation study evaluating different criteria for Gaussian pruning in the LightGaussian model. It compares using only hit counts, opacity, volume, and combinations thereof, with and without co-adaptation. The results demonstrate that incorporating opacity and volume into the significance calculation significantly improves performance, while co-adaptation helps mitigate losses from pruning.
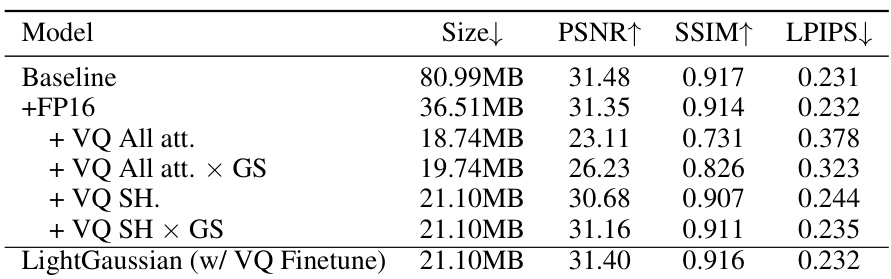
This table presents an ablation study on the impact of vector quantization (VQ) on model size and performance. Different VQ strategies are compared, showing that applying VQ to all attributes significantly reduces accuracy, while selectively applying VQ to spherical harmonics (SH) coefficients based on their global significance produces a good balance between model size reduction and visual quality. The final row shows the results after fine-tuning the model using the combined VQ and significance approach.

This table presents a comparison of the performance of Scaffold-GS alone and Scaffold-GS enhanced with LightGaussian. It demonstrates the effectiveness of LightGaussian in reducing model size and improving frame rates (FPS) while maintaining comparable visual quality (PSNR, SSIM, LPIPS). The results are averages across the MipNeRF-360 dataset.

This table presents ablation study results focusing on the impact of reducing the degree of spherical harmonics (SH) coefficients in the LightGaussian model. It shows the effect of reducing SH coefficients to 2 degrees and 1 degree while maintaining a 66% Gaussian pruning ratio. The metrics evaluated are model size, frames per second (FPS), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results demonstrate the trade-off between model size, rendering speed, and visual quality when decreasing the SH degree.

This table quantitatively compares LightGaussian with several state-of-the-art methods for large-scale scene rendering. It focuses on metrics like model size, rendering speed (FPS), PSNR, SSIM, and LPIPS, showcasing LightGaussian’s superior balance between speed, size, and visual quality compared to alternatives like Plenoxels, INGP, Mip-NeRF 360, and 3D-GS.
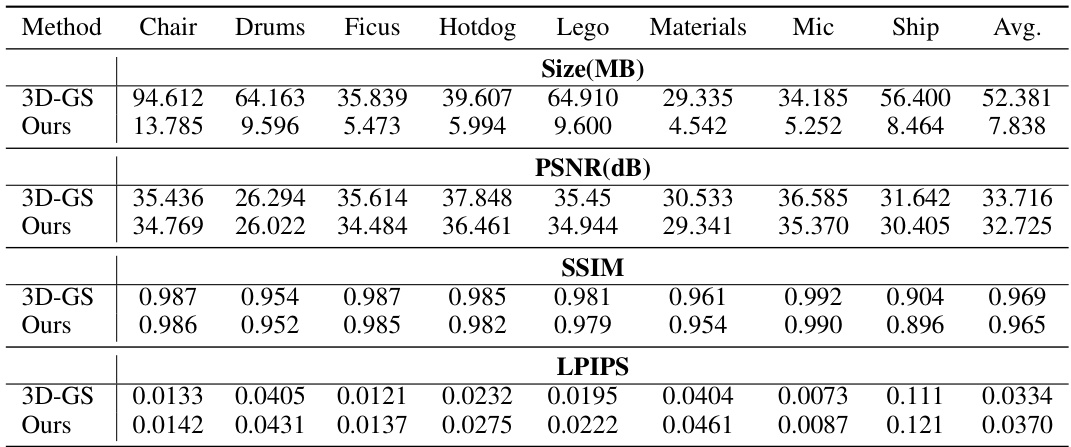
This table provides a quantitative comparison of LightGaussian against several state-of-the-art methods for large-scale scene representation on the Mip-NeRF 360 and Tanks & Temples datasets. The comparison includes metrics such as model size, rendering speed (FPS), PSNR, SSIM, and LPIPS. It highlights LightGaussian’s superior balance between speed, model size, and visual quality, outperforming other methods in terms of overall efficiency.
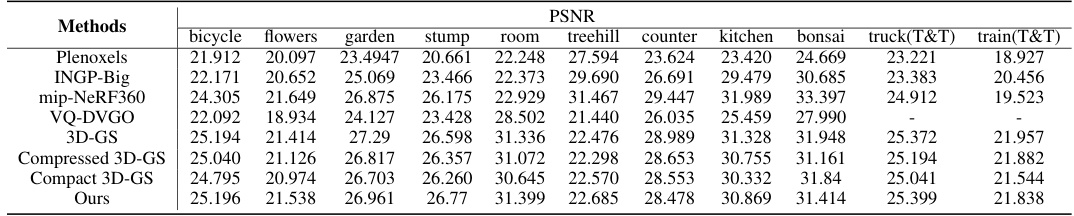
This table presents a quantitative comparison of LightGaussian against several state-of-the-art methods for large-scale scene rendering. It compares model size, rendering speed (FPS), PSNR, SSIM, and LPIPS scores across different methods on the Mip-NeRF 360 and Tanks & Temples datasets. The results highlight LightGaussian’s balance between speed, model size, and visual quality.
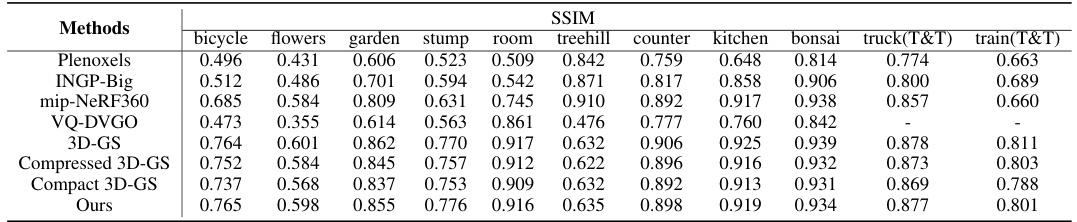
This table compares the performance of LightGaussian against other state-of-the-art methods for large-scale scene rendering. It shows a comparison of model size, rendering speed (FPS), PSNR, SSIM, and LPIPS scores on standard benchmark datasets. LightGaussian achieves a good balance between model size, speed, and visual quality compared to other methods.
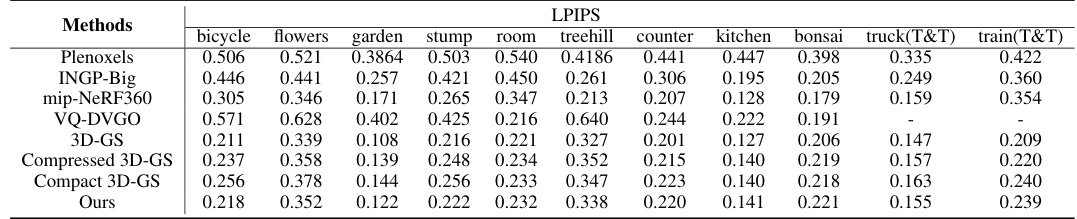
This table compares the performance of LightGaussian against other state-of-the-art methods for large-scale scene rendering. Metrics include model size, frames per second (FPS), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). It highlights LightGaussian’s superior balance between speed, size, and visual quality.
Full paper#