↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Prior research on using diffusion models for discriminative tasks has largely overlooked the vast number of internal signals (activations) and focused only on a limited subset. This paper revisits the feature selection problem, emphasizing the need for a more comprehensive analysis given recent advancements in diffusion model architectures. The early studies had performed large-scale comparisons but missed many potential activation candidates.
This study addresses these issues by taking a new approach. Instead of exhaustive quantitative comparisons, the researchers focused on identifying and analyzing universal properties inherent to diffusion models’ activations. They found three such properties that allow for efficient qualitative filtering of inferior activations. This streamlined the process leading to a greatly improved quantitative comparison. The final feature selection solutions outperformed existing state-of-the-art methods on various discriminative tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the overlooked problem of feature selection within diffusion models, significantly impacting the field’s future research direction. It provides generic insights applicable beyond specific models, offering efficient feature selection solutions and validating their superiority across multiple tasks. This will accelerate progress in various discriminative tasks leveraging diffusion models.
Visual Insights#

This figure compares the approach of previous studies and the proposed approach of this paper for selecting discriminative features from diffusion models. Previous studies only considered a limited set of activations (inter-module activations), leading to suboptimal performance with advanced models like SDXL. In contrast, this paper considers a much wider range of activations, including those from ViT modules, and uses qualitative filtering to reduce the search space before quantitative comparison. This improved approach resulted in superior performance (75.2 PCK@0.1). The figure visually shows examples of activations considered in each approach.
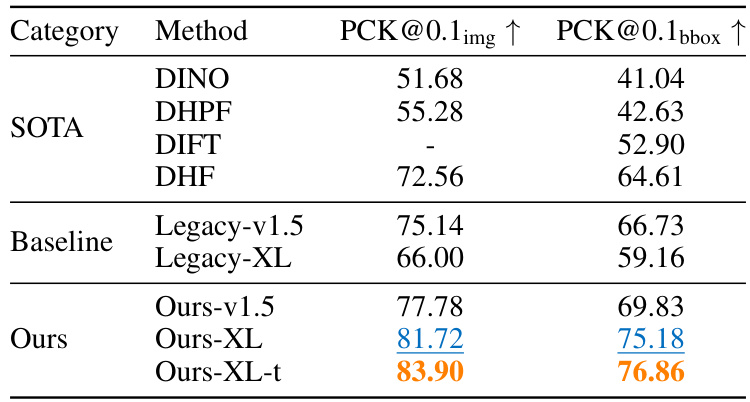
This table presents the performance comparison of different methods on the semantic correspondence task, including state-of-the-art (SOTA) methods, baseline methods using conventional activation selection approaches, and the proposed methods. The results are shown using two metrics: PCK@0.1img↑ and PCK@0.1bbox↑. The proposed methods (Ours-v1.5, Ours-XL, Ours-XL-t) consistently outperform the baselines and achieve competitive or superior performance compared to the SOTA methods, highlighting the effectiveness of their proposed feature selection approach.
In-depth insights#
Diffusion Feature Revisted#
The concept of “Diffusion Feature Revisited” suggests a critical re-evaluation of using diffusion models’ internal activations as discriminative features. Early works focused on a limited subset of activations, overlooking many potentially valuable ones, especially within newer, more complex architectures like those employing Vision Transformers. This revisited approach advocates a broader consideration of activation types, going beyond simple inter-module comparisons. The authors propose a qualitative filtering strategy based on identified universal properties of diffusion U-Nets, aiming to efficiently reduce the search space before quantitative evaluation. These properties encompass the asymmetric nature of diffusion noise, in-resolution granularity changes, and locality without positional embeddings. By understanding these properties, the authors present enhanced feature selection methods, demonstrating improved performance across multiple discriminative tasks, including semantic correspondence and segmentation. This approach allows for a more efficient and effective selection of activation features, overcoming limitations of previous studies. Ultimately, this revised understanding of diffusion features promotes more robust and generalizable solutions.
Activation Selection#
The selection of optimal activations from within a diffusion model is crucial for effective feature extraction. Early approaches focused on a limited set of readily available activations, overlooking potentially valuable signals within attention mechanisms and newer architectures. This paper highlights the inadequacy of prior activation selection methods, emphasizing the need for a more comprehensive evaluation. By identifying key properties inherent in diffusion U-Nets – asymmetric diffusion noises, in-resolution granularity changes, and locality without positional embeddings – the authors propose a refined feature selection strategy. This involves a two-stage process: qualitative filtering based on the identified properties, followed by quantitative comparison to select a subset of superior activations. This approach leads to improved performance across multiple discriminative tasks, showcasing the importance of carefully considering the diverse range of activations available within diffusion models for enhanced downstream performance.
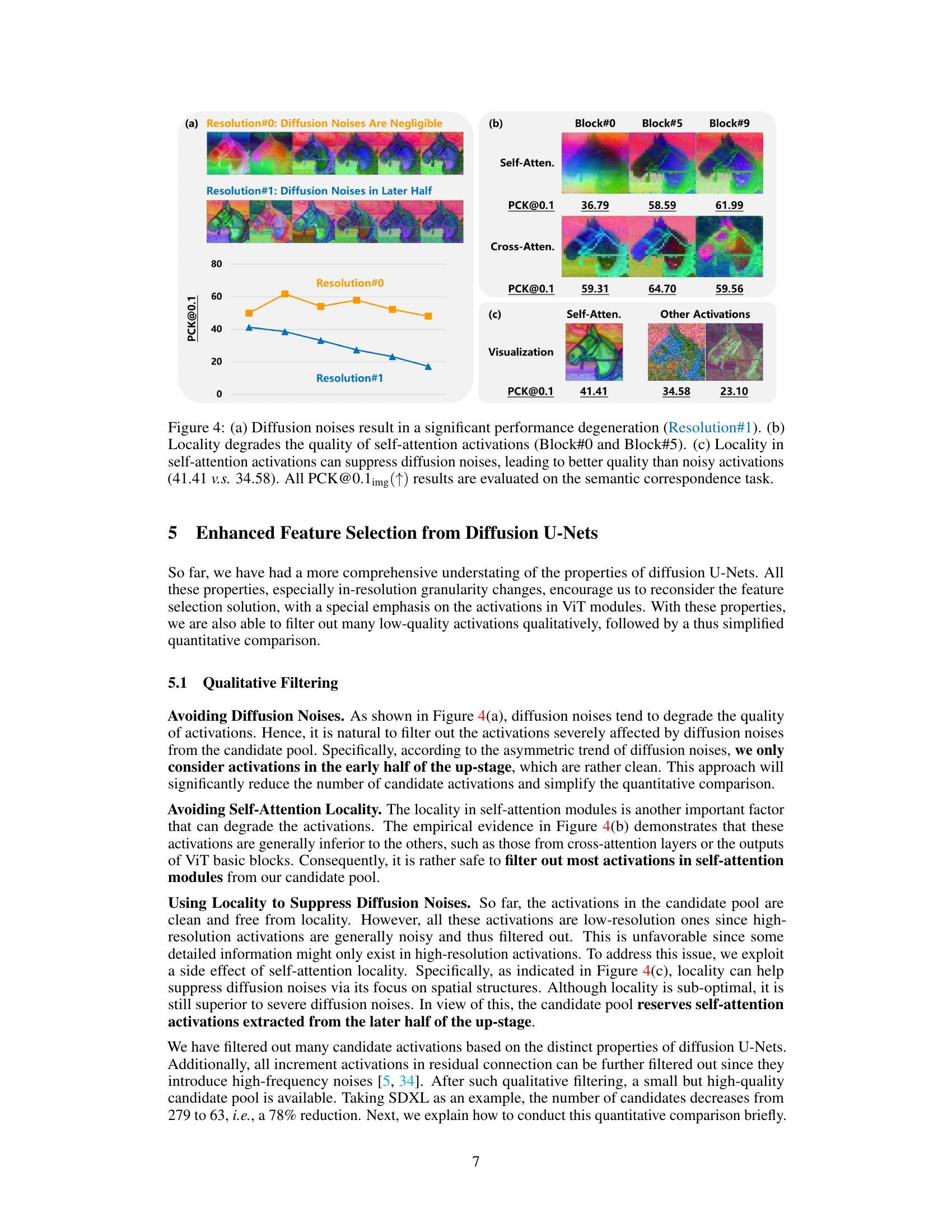
Qualitative Filtering#
The heading ‘Qualitative Filtering’ suggests a methodology employed to intelligently reduce the number of candidate features before a computationally expensive quantitative comparison. This approach leverages insights gained from analyzing inherent properties of diffusion U-Nets, moving beyond a purely quantitative analysis of discriminative ability. By focusing on specific properties such as asymmetric diffusion noises, in-resolution granularity changes, and locality without positional embeddings, the researchers effectively filter out low-quality activations. This qualitative pre-filtering significantly enhances the efficiency of the feature selection process, making a comprehensive quantitative comparison feasible while still maintaining high accuracy. The emphasis is on understanding the underlying characteristics of the activation maps, to guide feature selection rather than solely relying on performance metrics of downstream tasks.
Universal Properties#
The concept of “Universal Properties” in the context of diffusion models suggests inherent characteristics applicable across various model architectures. This implies that certain behaviors or patterns emerge regardless of specific design choices, offering a basis for generalizable analysis and potentially more efficient feature selection. Identifying these properties is crucial because it allows for the development of methods that transcend individual model limitations, enabling a deeper understanding of the underlying mechanisms driving diffusion model performance. The universality of these properties simplifies the task of feature selection by allowing researchers to focus on general principles rather than model-specific details, potentially leading to more effective and efficient feature selection strategies. This approach is particularly relevant given the complexity and variety of diffusion models. The discovery of universal properties offers a significant advance, enabling the creation of more robust and adaptable techniques that can be applied to a wider range of diffusion models and tasks, ultimately contributing to improved efficiency and broader applicability in the field.
Future Directions#
The paper’s “Future Directions” section would ideally explore extending the research to more challenging discrimination scenarios such as long-tail and out-of-distribution problems. Investigating how the identified properties of diffusion U-Nets influence performance in these settings is crucial. The impact of disentanglement in prompt engineering and the potential of using diffusion models for data synthesis to address class imbalance should be explored. Further research could focus on integrating evaluation metrics like AUC for improved assessment, particularly for long-tail scenarios. Finally, a critical future direction is applying the findings to diverse diffusion models, going beyond the U-Net architecture to models like DiT and exploring whether the discovered properties remain consistent and how the feature selection strategies might need to be adapted.
More visual insights#
More on figures

This figure illustrates the architecture of a U-Net used in diffusion models, specifically highlighting the SDXL model as an example. The upper part shows the overall U-Net structure, divided into three main stages: down-stage, mid-stage, and up-stage. Each stage involves multiple resolution modules, which in turn contain ResModules (convolutional ResNet structures), ViT Modules, and down/up samplers. The lower part focuses on a single ViT module, showing its internal structure composed of several basic blocks. Each basic block consists of self-attention, cross-attention (in modern versions), and feed-forward layers. The figure uses color-coding to differentiate between different components and illustrates the flow of activations through the network.

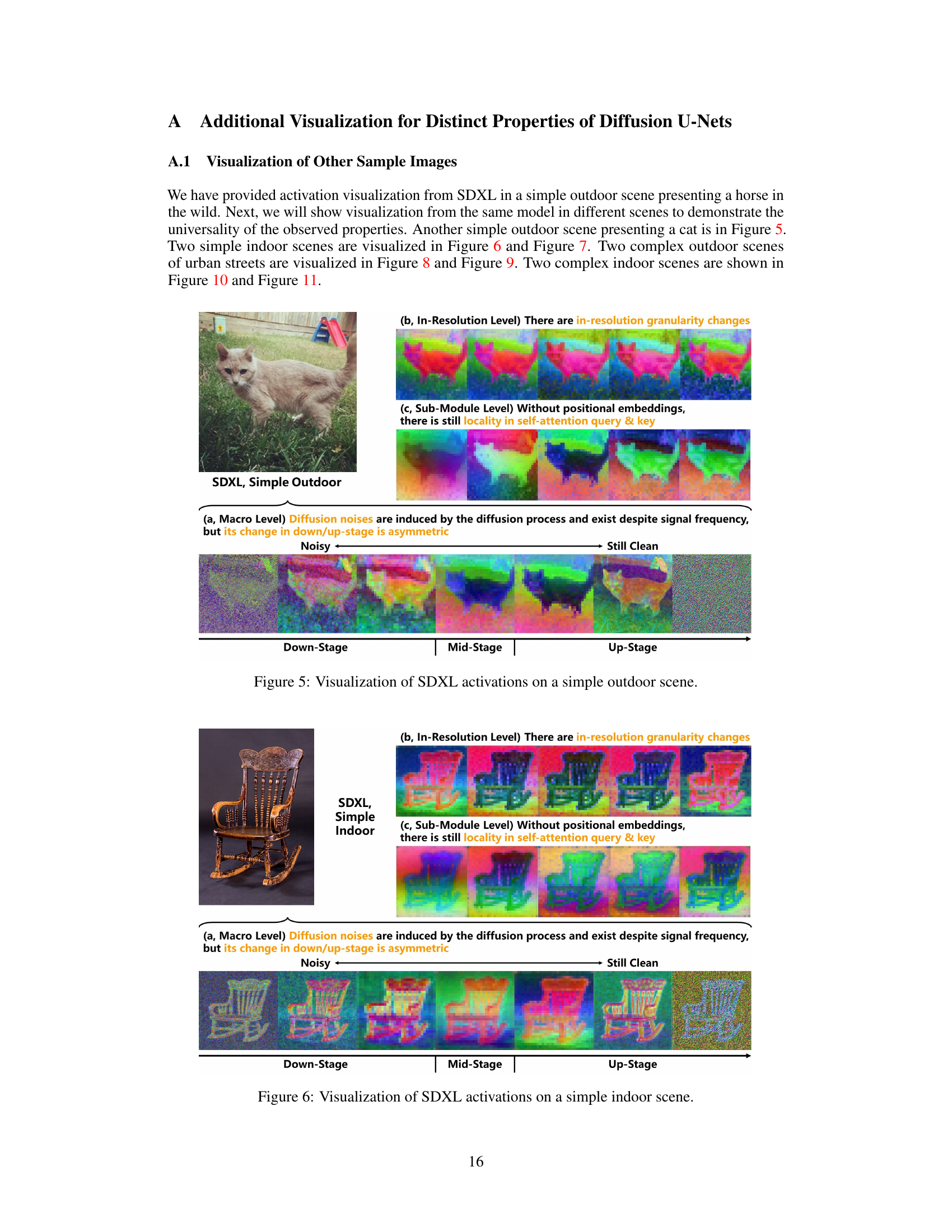
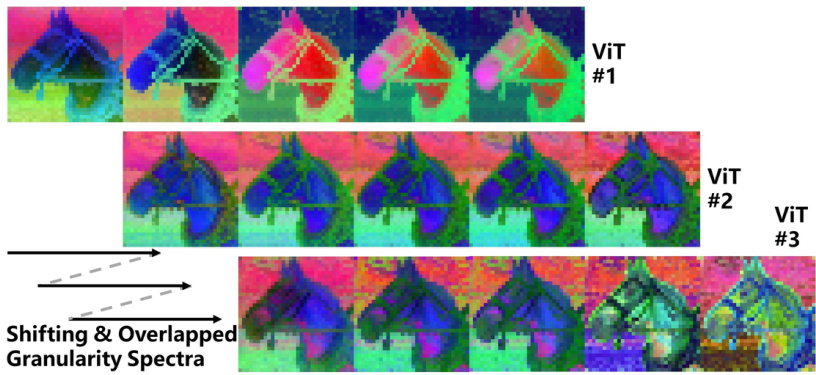
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets or Vision Transformers (ViTs). It visually demonstrates these properties through activation visualizations: (a) Asymmetric Diffusion Noises: Diffusion models introduce noise at various frequencies during training; this figure shows that this noise is not uniformly distributed across the network, being more pronounced in the downsampling stages and less in the upsampling stages. (b) In-Resolution Granularity Changes: Traditional U-Nets have a gradual change in granularity across resolutions. Diffusion U-Nets, however, show a significant granularity change within a single resolution. This is visually shown as the activations evolving from coarse to fine granularity within a single resolution. (c) Locality without Positional Embeddings: ViTs typically use positional embeddings to maintain spatial information. However, the diffusion U-Net’s ViT modules exhibit a form of locality despite the absence of positional embeddings, where nearby pixels are more similar than semantically close, distant pixels. This is highlighted with an orange circle around a region of pixels that have more resemblance to surrounding background pixels than to semantically similar pixels further away.
This figure compares the activation selection methods in previous studies and the proposed method in the paper. The left side shows that previous studies only considered a small fraction of potential activations from diffusion models, which resulted in suboptimal performance for more advanced architectures such as SDXL. The right side illustrates that the proposed method considers a broader range of activations, qualitatively filters them, and achieves superior performance, as shown by the higher PCK@0.1 value.

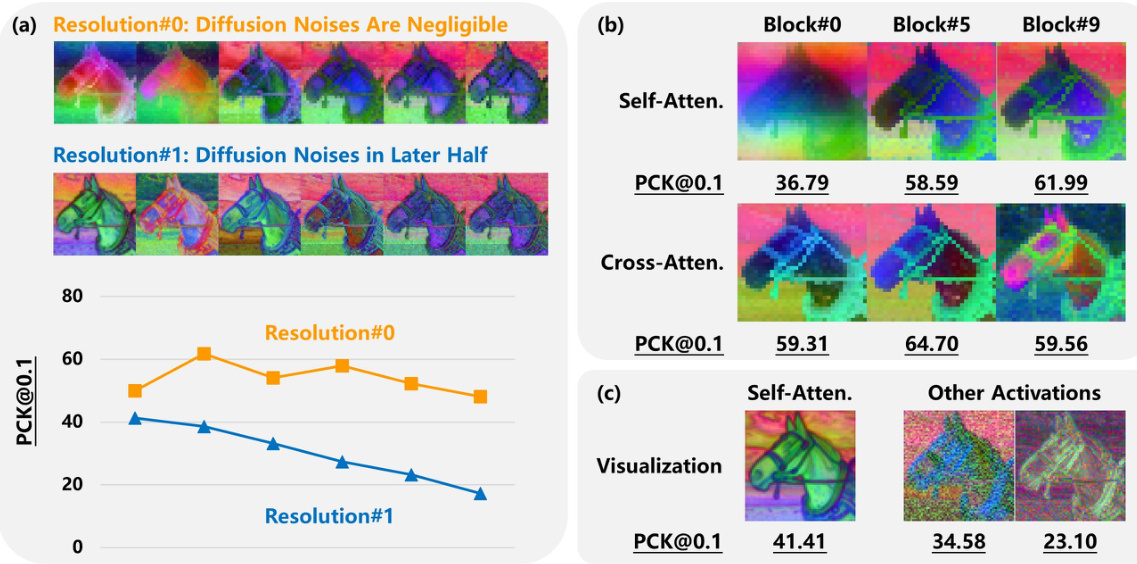
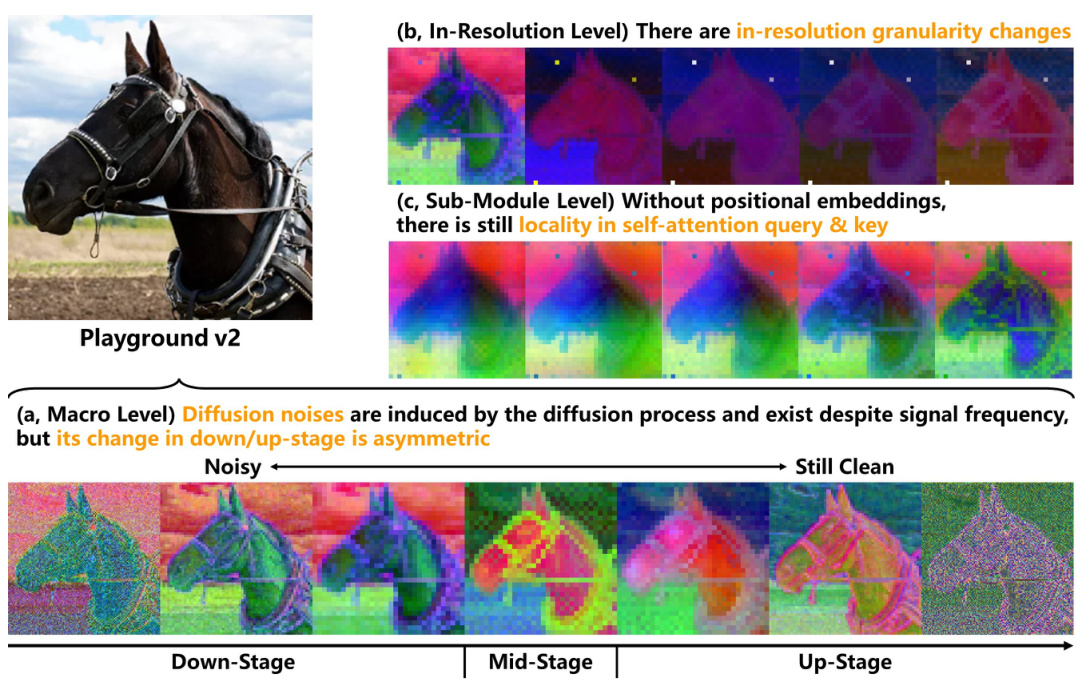
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). It visually demonstrates these properties using activation visualizations from a diffusion model applied to an image of a horse. (a) Asymmetric Diffusion Noises: Shows that diffusion noises impact both high and low-frequency signals asymmetrically during the forward and reverse passes of the diffusion process. (b) In-Resolution Granularity Changes: Illustrates that within a single resolution, the granularity of information changes significantly, unlike traditional U-Nets. (c) Locality without Positional Embeddings: Demonstrates that even without positional embeddings, there’s a degree of locality in self-attention mechanisms, where nearby pixels in the feature space are more similar than semantically related but spatially distant pixels.
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers. It visually demonstrates these properties using activation visualizations from different stages of a diffusion U-Net. Specifically: (a) shows how diffusion noise affects activations asymmetrically across the down- and up-sampling stages, (b) shows in-resolution granularity changes within each resolution level of the U-Net, and (c) illustrates how locality is preserved in self-attention query and key activations even without positional embeddings.

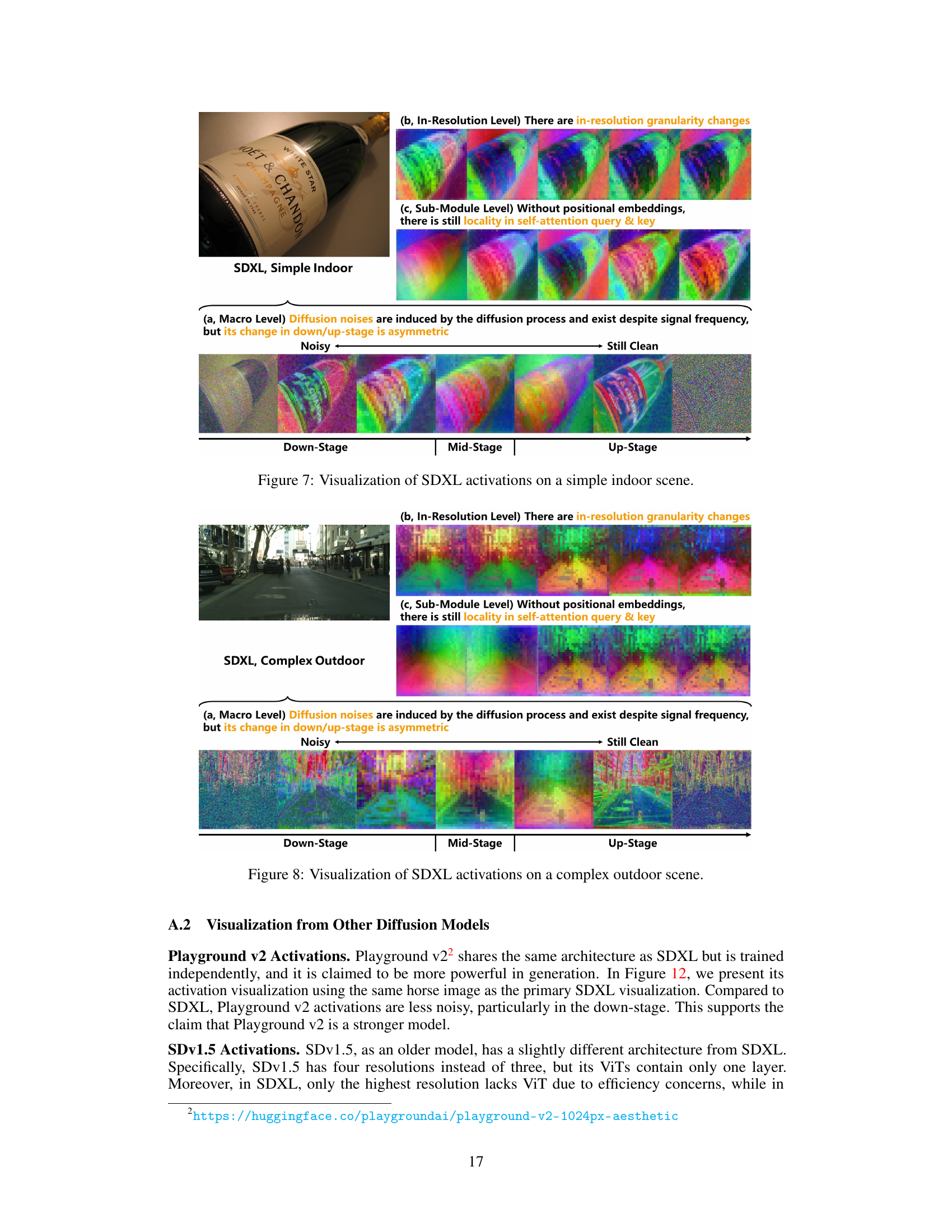
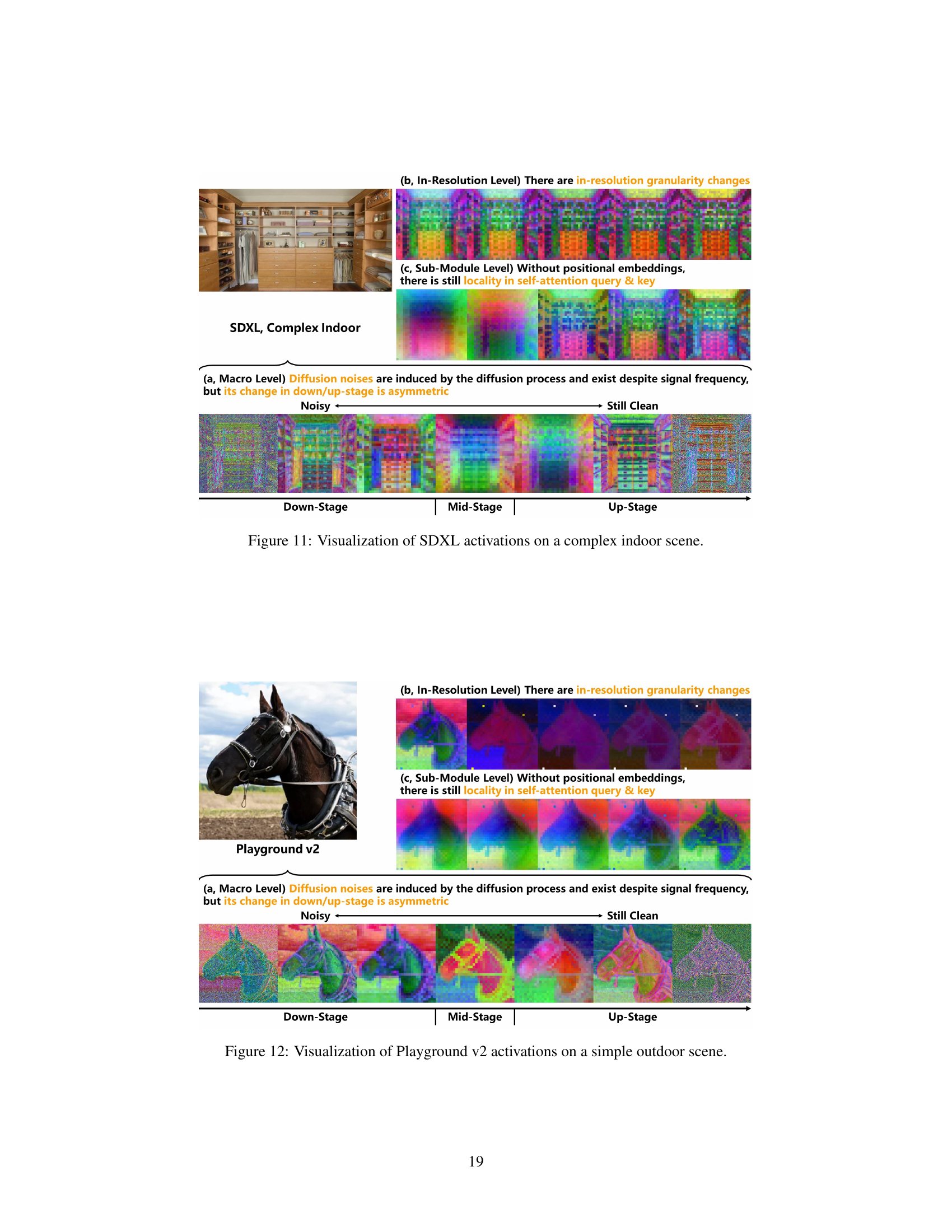
This figure visualizes the activations of the Stable Diffusion XL (SDXL) model on a simple indoor scene. It highlights three key properties of diffusion U-Nets that distinguish them from traditional U-Nets and Vision Transformers (ViTs): asymmetric diffusion noise, in-resolution granularity changes, and locality without positional embeddings. The visualization shows how these properties manifest across the down-stage, mid-stage, and up-stage of the U-Net architecture. Specifically, it demonstrates that diffusion noise is significant in the down-stage, less so in the mid-stage, and only partially reappears in the later half of the up-stage. It also shows how granularity changes within a single resolution and the persistence of locality within self-attention despite the absence of positional embeddings.

This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). It visually demonstrates these properties through activation visualizations at different levels of the network: (a) Asymmetric Diffusion Noises: Shows how diffusion noise, introduced during the diffusion process, affects both high and low-frequency components asymmetrically across the different stages (down-sampling, middle, up-sampling) of the U-Net. (b) In-Resolution Granularity Changes: Illustrates how within a single resolution, the granularity of information changes, unlike traditional U-Nets where this change is primarily assumed to occur across different resolutions. (c) Locality without Positional Embeddings: Demonstrates the presence of locality in self-attention mechanisms even without explicit positional embeddings. This shows how activations related to the same semantic concept cluster together spatially, even without positional information.

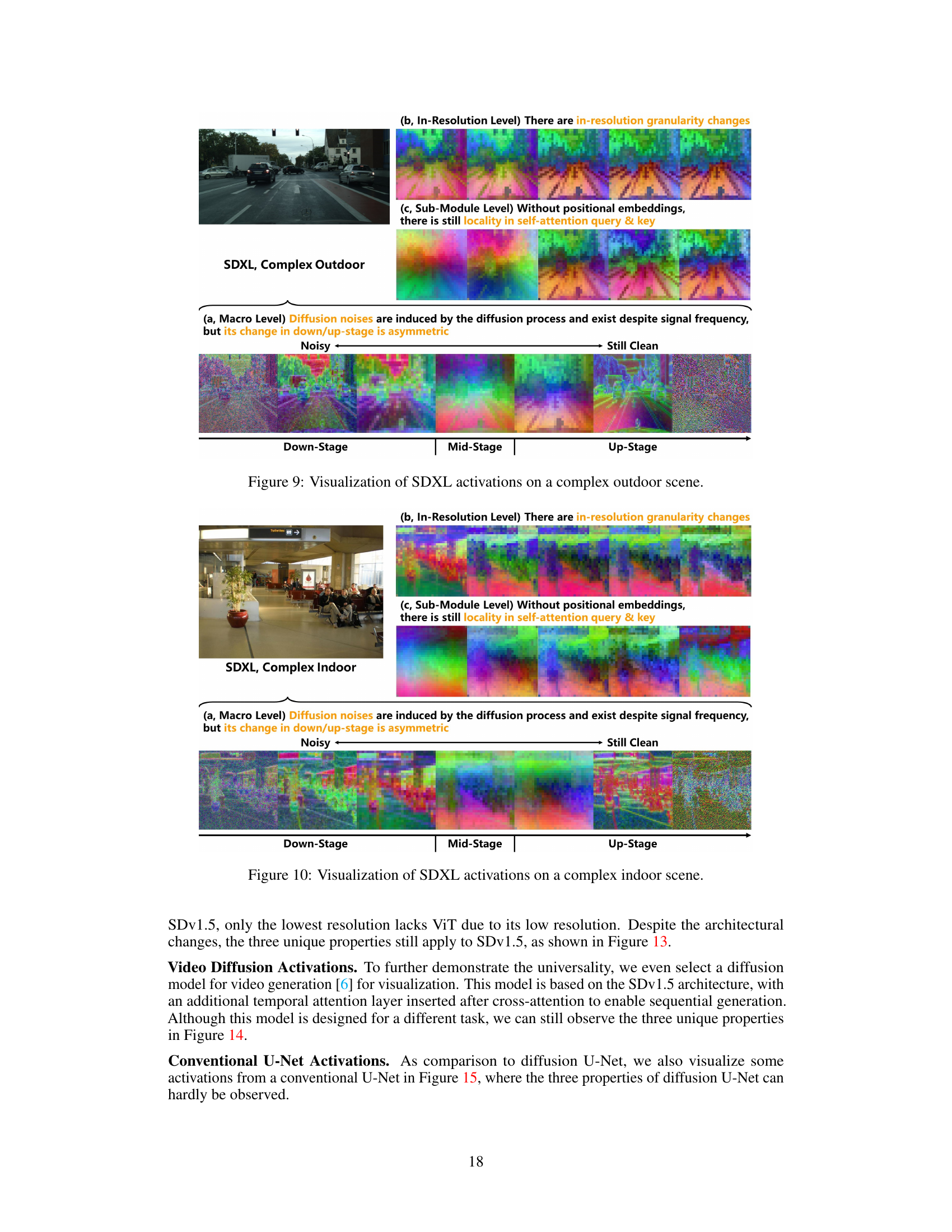
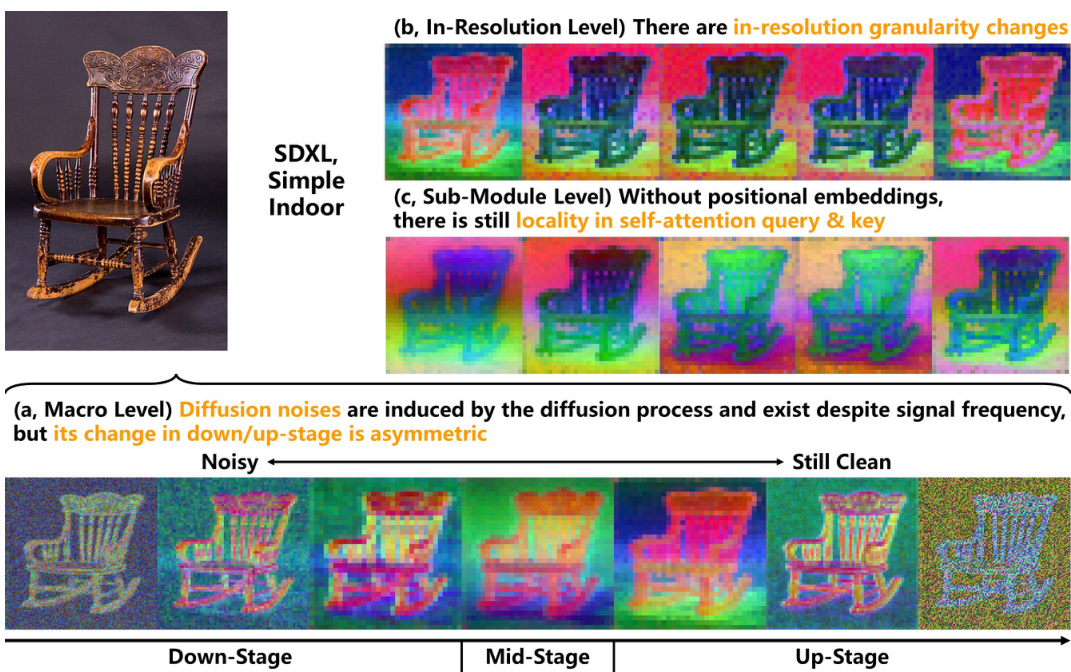
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). (a) shows that diffusion noises, introduced by the diffusion process, affect both high and low-frequency signals asymmetrically across the down-stage and up-stage of the U-Net. (b) illustrates in-resolution granularity changes, demonstrating that the information granularity varies within a single resolution, due to the increased size of each resolution in modern diffusion U-Nets. Finally, (c) shows locality without positional embeddings, where pixels within a localized region share similar features despite being semantically distant compared to those farther away.
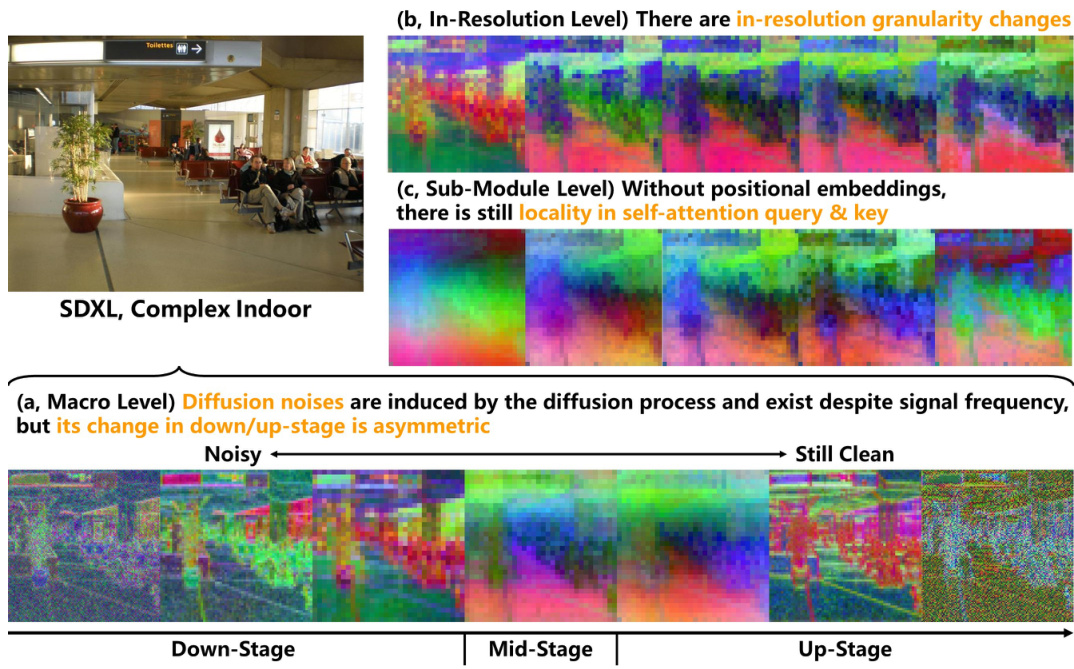
This figure visualizes the activations of the Stable Diffusion XL (SDXL) model on a complex indoor scene. It highlights the three distinct properties of diffusion U-Nets: asymmetric diffusion noises, in-resolution granularity changes, and locality without positional embeddings. The visualization shows how these properties manifest in different stages (down-stage, mid-stage, up-stage) and resolutions of the U-Net architecture. Each level displays a series of activation maps, illustrating the changes in noise levels, granularity, and locality across the network.
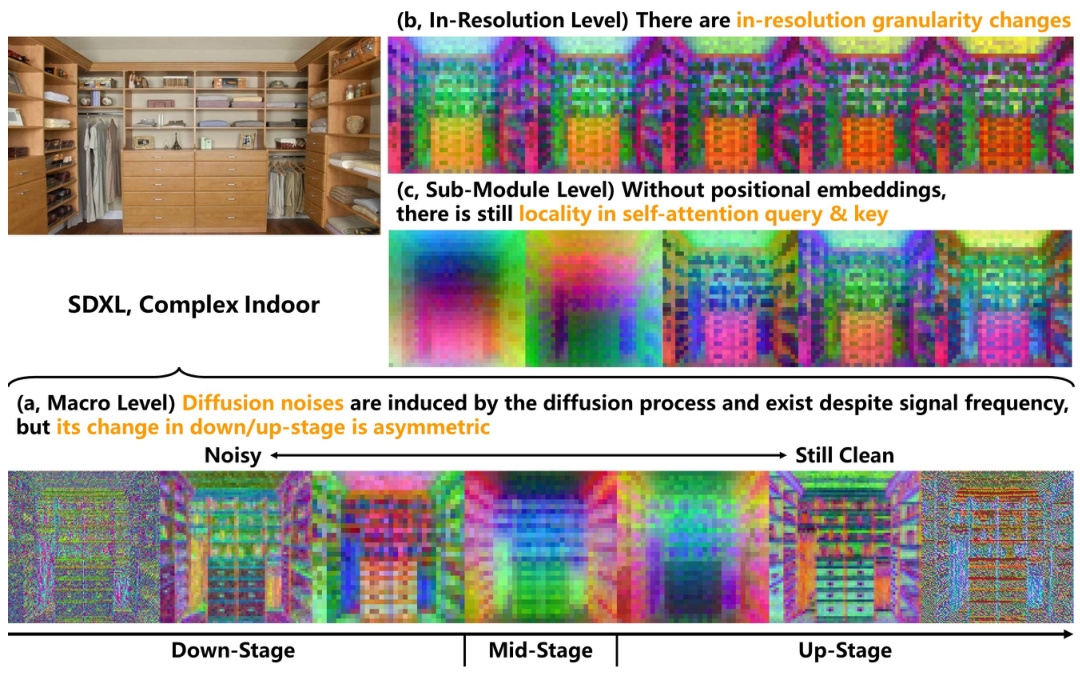
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). It visually demonstrates these properties using activation visualizations from a Stable Diffusion XL (SDXL) model. Specifically: (a) Asymmetric Diffusion Noises: Shows that diffusion noise affects both high and low-frequency signals asymmetrically throughout the U-Net’s processing stages (down-sampling, mid-stage, up-sampling). The noise is more prevalent in earlier stages and decreases in the early part of the up-sampling process, only to reappear later. (b) In-Resolution Granularity Changes: Illustrates that within each resolution level, there are variations in granularity, indicating a change in the level of detail of information extracted at different layers or stages within a resolution. (c) Locality without Positional Embeddings: Demonstrates that even without explicit positional embeddings, there’s still a form of locality within the self-attention mechanism. Nearby pixels share more similar features than semantically related but spatially distant pixels.
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). It shows visualizations demonstrating: (a) Asymmetric Diffusion Noises: Diffusion models introduce noise at all frequencies, but this noise’s effect is not symmetric across the network’s down-sampling and up-sampling stages. Noise is more significant in the down-sampling stages. (b) In-Resolution Granularity Changes: Unlike traditional U-Nets that focus on granularity change across different resolutions, diffusion U-Nets display significant granularity changes within a single resolution, which is important for feature selection. (c) Locality without Positional Embeddings: Even without positional embeddings, the self-attention mechanism in ViTs within diffusion U-Nets exhibits locality, meaning that activations show similarity to spatially close pixels rather than semantically similar but distantly located pixels. The orange circle highlights this effect, where activations in that region resemble background activations more than distant pixels.

This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets or Vision Transformers (ViTs). It visually demonstrates these properties across different stages (down-stage, mid-stage, up-stage) of a diffusion U-Net’s architecture. Specifically: (a) Asymmetric Diffusion Noises: Diffusion models introduce noise, and this noise impacts both high and low-frequency signals unevenly across the network’s stages. The asymmetry means the effect of this noise isn’t uniform as the model processes an image. (b) In-Resolution Granularity Changes: Unlike traditional U-Nets, diffusion U-Nets exhibit significant granularity changes within a single resolution, altering the quality of features extracted from different levels of the same resolution. This is due to the ‘fatter’ structure of the networks (fewer resolutions, more feature channels). (c) Locality Without Positional Embeddings: While lacking conventional positional embeddings, self-attention mechanisms in ViT modules within diffusion U-Nets still demonstrate locality. This means that activations respond more strongly to nearby pixels in space than semantically similar but distant pixels.
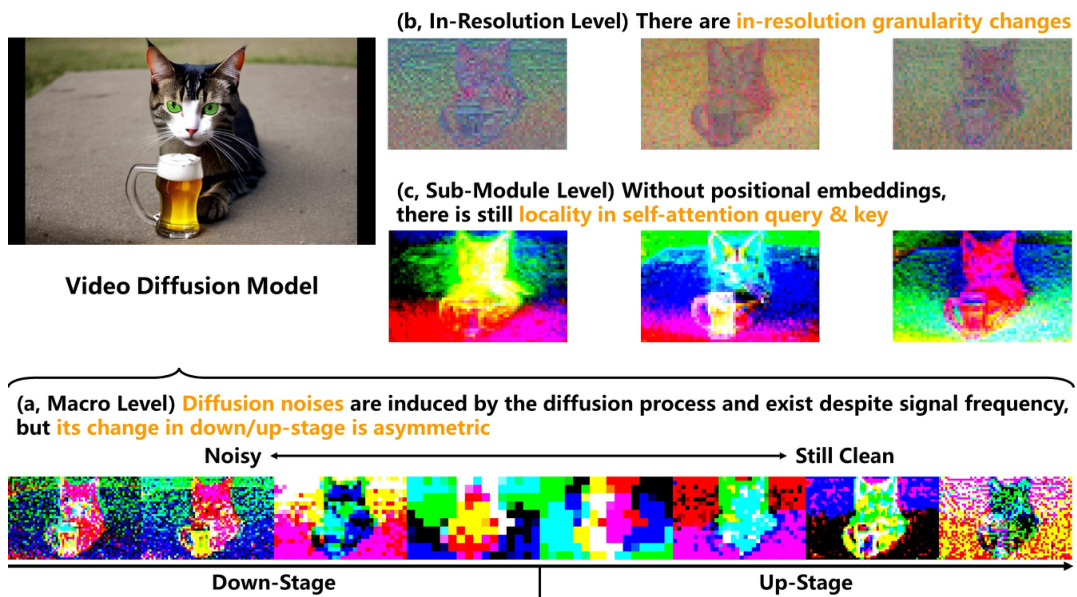
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). It visually demonstrates these properties using activation visualizations from a diffusion model. (a) Asymmetric Diffusion Noises: Shows that diffusion-induced noise affects both high and low-frequency signals asymmetrically across the down- and up-sampling stages of the U-Net. (b) In-Resolution Granularity Changes: Illustrates that within a single resolution, the granularity (level of detail) of the activations changes significantly, unlike traditional U-Nets. (c) Locality without Positional Embeddings: Highlights the existence of locality (nearby pixels are more similar) in self-attention mechanisms even without explicit positional embeddings, which differs from standard ViTs.

The figure shows a comparison of previous studies and the proposed method for selecting activations in diffusion models. Previous studies only considered a small fraction of potential activations, leading to suboptimal performance in advanced models like SDXL. The authors’ method considers a broader range of activations and uses qualitative filtering to reduce the number of candidates before quantitative comparison, resulting in superior performance.
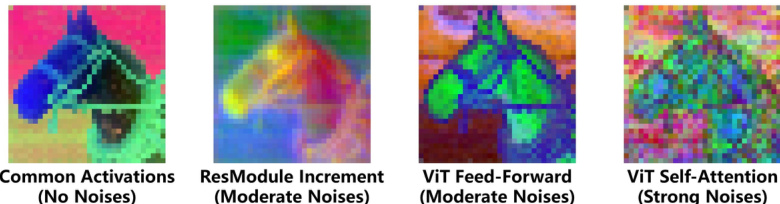
This figure highlights three key properties of diffusion U-Nets that differentiate them from traditional U-Nets and Vision Transformers (ViTs). Panel (a) shows that diffusion models introduce ‘diffusion noise’ that impacts both high and low-frequency signals asymmetrically during the denoising process. Panel (b) demonstrates that in-resolution granularity changes are significant in diffusion U-Nets due to their design with fewer but wider resolutions compared to traditional U-Nets. Finally, panel (c) illustrates that, despite lacking positional embeddings (common in ViTs), there is still a notion of locality where a pixel’s representation is more similar to nearby pixels than semantically-related distant pixels.
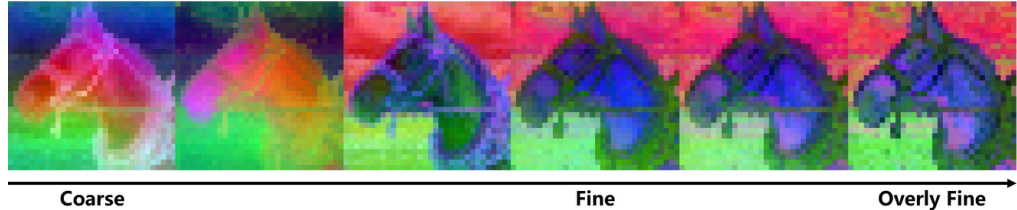
This figure shows how the granularity of the activations changes from coarse to fine as the network processes the input. The progression is visualized across multiple inter-module activation outputs from a single resolution layer within the U-Net. At the very end, the appearance of slight noise in the activations suggests that the refinement process has gone too far, indicating a potential point of diminishing returns in terms of extracting useful features.
The figure compares two approaches to selecting activation features from diffusion models for discriminative tasks. Previous studies only considered a limited subset of activations, resulting in lower performance for more advanced models like SDXL. The proposed method considers a wider range of activations and employs qualitative filtering to reduce the number of candidates for a quantitative comparison. This approach leads to significantly improved performance.
More on tables

This table presents the experimental results for semantic segmentation and its label-scarce version. It compares the performance of the proposed method (Ours-v1.5, Ours-XL, Ours-XL-t) against several state-of-the-art (SOTA) methods and two baselines (Legacy-v1.5, Legacy-XL) across three different datasets: ADE20K, Cityscapes (standard setting), and Horse-21 (label-scarce setting). The metric used is mean Intersection over Union (mIoU), which measures the average overlap between predicted and ground truth segmentations. The best performing method for each setting is highlighted in bold.

This table compares the performance of two feature selection methods on a label-scarce segmentation task using two different subsets of images (simple and complex scenes). The Generic Solution uses features selected using a general approach, while the Specific Solution uses features selected based only on the simple scenes subset. The table demonstrates the impact of the feature selection method on the generalizability of the model’s performance across different scene complexities. The results show that the Generic Solution generalizes better across both simple and complex scenes compared to the Specific Solution, highlighting the importance of considering diverse image types during the feature selection process.

This table presents a quantitative comparison of the discriminative performance of different activations from SDXL and Playground v2 diffusion models. The activations are evaluated at the lowest resolution of the U-Net. Each row represents an activation, identified by its ID, with its performance scores (Simple and Complex scenes). The best and second-best performing activations are highlighted in bold and underlined respectively.

This table presents a quantitative comparison of different activation features extracted from two diffusion models, SDXL and Playground v2, at their lowest resolution. Each row represents a different activation feature identified by its ID. The table shows the performance (likely a metric like PCK@0.1img) of each activation on two types of scenes: simple and complex. The best and second-best performing activations are highlighted.

This table presents a comparison of different methods for the semantic correspondence task. It shows the performance of various methods, including state-of-the-art (SOTA) approaches and baseline methods (using only inter-module activations), as well as the proposed method (Ours) applied to two different diffusion models (SDv1.5 and SDXL). The performance is measured using two metrics: PCK@0.1img and PCK@0.1bbox. The table highlights the superior performance achieved by the proposed method, demonstrating the effectiveness of the proposed feature selection approach.
Full paper#