↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Continual learning, where AI systems learn new tasks without forgetting old ones, is a major challenge. Current methods often struggle to maintain performance as they learn more and more information because they have issues with their inherent structure and optimization approaches. The primary visual cortex’s limited role in object categorization in humans hints at a novel approach.
The proposed Saliency-driven Experience Replay (SER) tackles this problem by using visual saliency prediction to guide the learning process. SER modulates the learning of classification models with saliency information, leading to improved accuracy (up to 20%) on various continual learning benchmarks. Furthermore, SER creates features more robust to spurious information and adversarial attacks. The model agnostic nature of SER makes it broadly applicable.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant challenge of catastrophic forgetting in continual learning, a persistent issue hindering the development of truly intelligent AI systems. By offering a biologically-inspired solution that leverages visual saliency, it provides a novel and effective approach to improve the robustness and performance of continual learning models. This has implications for various real-world applications dealing with non-stationary data streams. The work also opens new research avenues in bridging neuroscience and machine learning.
Visual Insights#

The figure shows a comparison between the performance of saliency prediction and classification models in continual learning settings. The left panel shows that saliency prediction remains stable over time, while classification accuracy suffers from catastrophic forgetting. The right panel illustrates this by comparing activation maps (GradCAM, which are classifier-dependent and show forgetting) to saliency maps (which are stable over time).
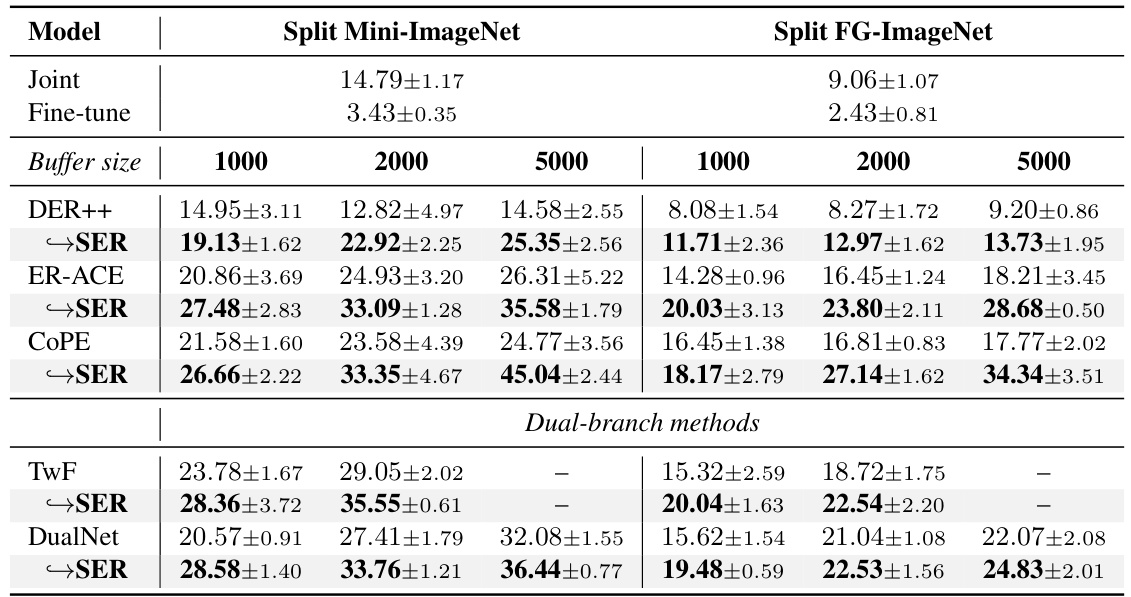
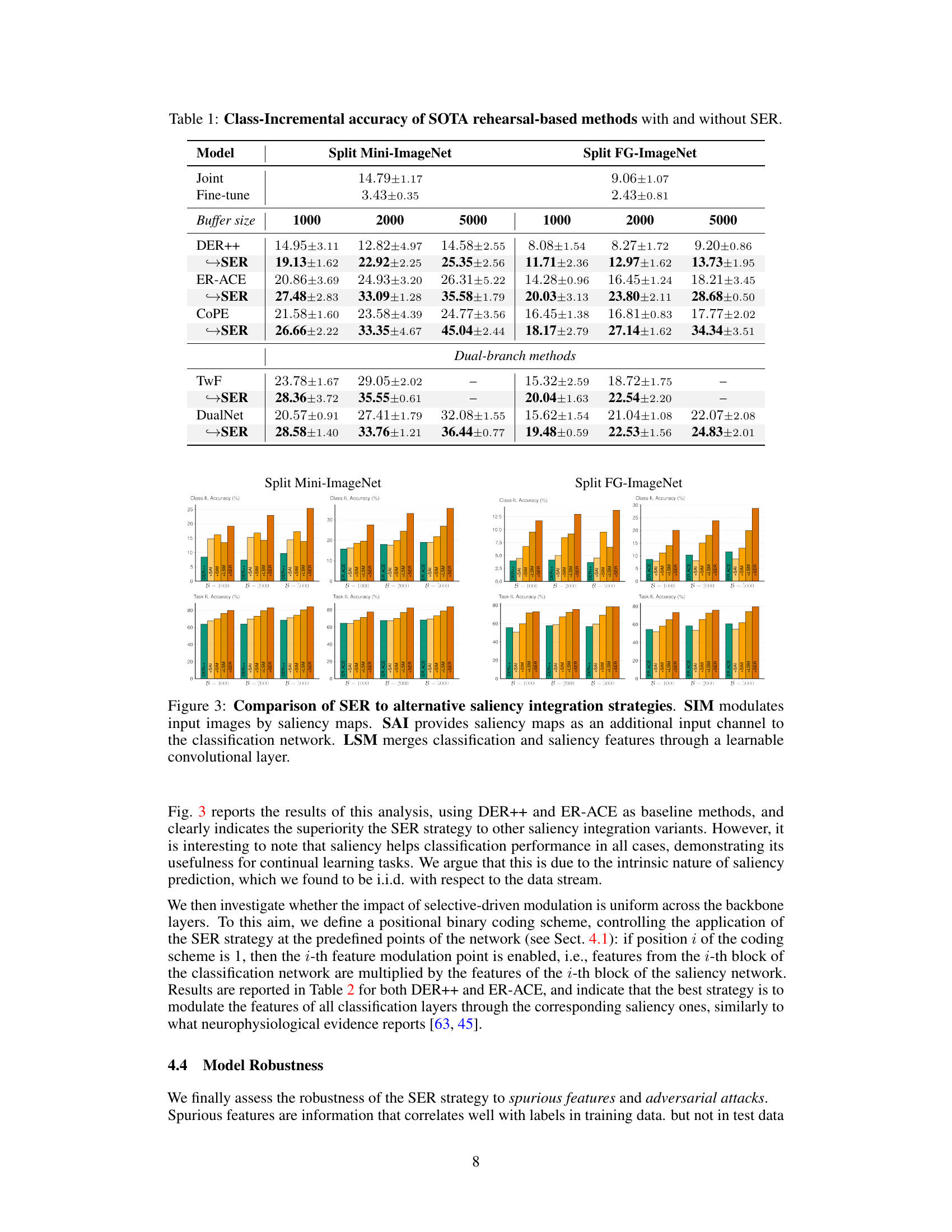
This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) technique. The table shows results on two benchmarks: Split Mini-ImageNet and Split FG-ImageNet. For each method, accuracy is reported for different buffer sizes (1000, 2000, and 5000), allowing for a comparison of performance with and without SER across various memory capacities. The results demonstrate the effectiveness of SER in improving the accuracy of existing continual learning methods.
In-depth insights#
SER: Bio-Inspired CL#
The heading ‘SER: Bio-Inspired CL’ suggests a novel continual learning (CL) approach named SER, grounded in biological principles. This implies SER likely addresses the catastrophic forgetting problem inherent in traditional CL methods by mimicking how biological systems, like the human brain, achieve continual learning. The bio-inspired aspect is crucial, implying the algorithm incorporates mechanisms observed in nature, likely related to memory consolidation or selective attention. The ‘SER’ acronym itself likely represents an abbreviation of a more descriptive name which will be explained within the paper. The technique likely improves upon existing CL methods by offering a biologically-plausible approach that is more robust and efficient, possibly through the use of mechanisms such as saliency maps or other attention-based mechanisms to focus learning on relevant information. A successful SER method would demonstrate superior performance compared to existing state-of-the-art CL techniques, suggesting a significant advancement in the field.
Saliency Modulation#
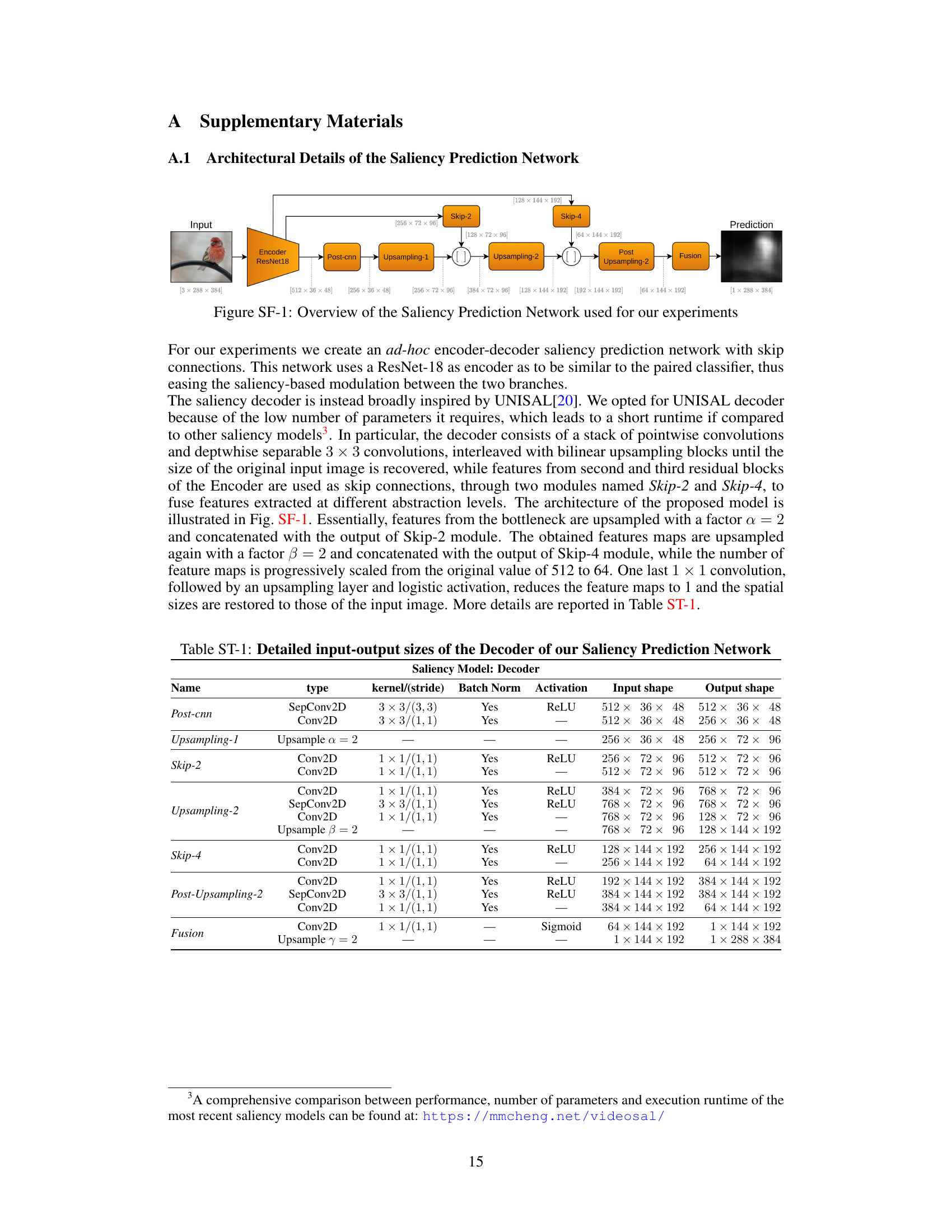
Saliency modulation, a core concept in the presented research, leverages the inherent stability of human visual attention to improve continual learning models. The method introduces a two-branch architecture where one branch predicts visual saliency maps and the other performs classification. Saliency maps, being relatively invariant across tasks, act as a modulation signal. This signal is integrated multiplicatively with classification network activations, selectively emphasizing salient features and dampening the impact of spurious or adversarial inputs. This approach addresses catastrophic forgetting by stabilizing feature learning, particularly in the early layers of the network, consistent with neuroscientific findings. The key innovation is in using saliency to drive and stabilize the learning process, not merely as a form of attention, but as a crucial modulating factor that prevents the classifier from overfitting to task-specific features. This results in more robust and generalized performance compared to traditional continual learning methods.
SER: Robustness#
The robustness of the Saliency-driven Experience Replay (SER) method is a crucial aspect of its effectiveness in continual learning. The authors explore SER’s resilience to spurious features, which are data artifacts that correlate with labels in training data but not in testing, and adversarial attacks, which are carefully designed inputs meant to fool the model. The results demonstrate SER’s capacity to learn features more robust than baseline methods, mitigating the negative impact of spurious features and adversarial perturbations. This improved robustness likely stems from SER’s use of saliency maps which remain stable over time, unlike classification features affected by catastrophic forgetting. The attention-driven nature of saliency provides a stable modulation signal that enhances the learning process and strengthens feature representations against various forms of noise or manipulation. In essence, the robustness evaluation showcases SER’s ability to generalize effectively beyond training data and withstand potential attacks, highlighting a critical advantage of this biologically-inspired approach in real-world continual learning scenarios.
Continual Learning#
Continual learning addresses the critical challenge of enabling systems to learn continuously without catastrophic forgetting of previously acquired knowledge. This is in stark contrast to traditional machine learning, which often assumes stationary data distributions. The core problem lies in the inherent instability of artificial neural networks when presented with non-stationary data streams. Approaches to continual learning often involve strategies such as regularization, rehearsal (replaying past data), and architectural modifications designed to mitigate forgetting and preserve previously learned representations. Biologically plausible methods inspired by human learning mechanisms are also gaining traction, aiming to incorporate the brain’s ability to integrate new knowledge while retaining old memories. The field is highly active, with research focused on developing robust and efficient algorithms capable of handling various continual learning scenarios (class-incremental, task-incremental, online continual learning), leading to applications in areas such as robotics, personalized medicine, and autonomous systems.
Future of SER#
The future of Saliency-driven Experience Replay (SER) appears promising, building upon its biologically-plausible foundation and demonstrated effectiveness in continual learning. Further research should focus on exploring the integration of SER with more diverse network architectures, moving beyond the ResNet-18 backbone used in the initial study. Investigating the applicability of SER to various modalities, such as audio or multi-modal data, could significantly broaden its impact. Addressing the limitations related to high-quality input image requirements is also crucial for wider adoption, perhaps by exploring techniques that can effectively handle lower-resolution or noisy data. Finally, exploring the theoretical underpinnings of SER to better understand its performance characteristics could lead to more refined and efficient implementations. These avenues of research would pave the way for SER to become a dominant technique in robust and adaptable AI systems.
More visual insights#
More on figures

The figure shows the architecture of the Saliency-driven Experience Replay (SER) strategy. It highlights two main branches: a saliency prediction network and a classification backbone. The saliency prediction network, designed to be robust to forgetting, generates saliency maps. These maps modulate the features learned by the classification network, helping to stabilize learning across multiple tasks and reduce catastrophic forgetting. The attention modulation mechanism is depicted as a Hadamard product between the saliency and classification features.
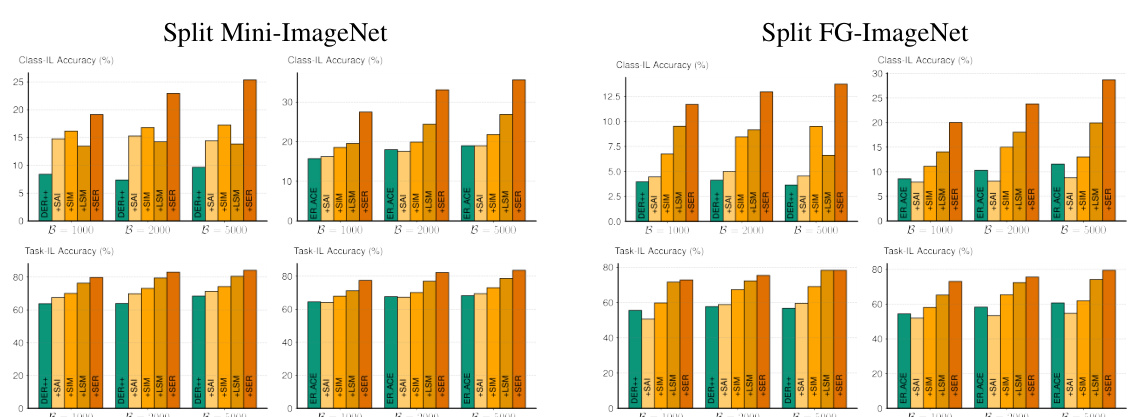
This figure compares the performance of saliency prediction and classification models in continual learning settings. The left graph shows that saliency prediction remains stable or even improves over time, while classification accuracy decreases significantly. The right side shows GradCAM activation maps and predicted saliency maps, visually demonstrating the catastrophic forgetting in the classification model compared to the stability in the saliency prediction model.

The figure shows a comparison between the forgetting-free behavior of saliency prediction and the catastrophic forgetting in classifiers during continual learning. The left plot shows that saliency prediction accuracy improves over time as more tasks are introduced, while classifier accuracy degrades. The right part shows Grad-CAM activation maps (top), which are highly affected by catastrophic forgetting, while saliency maps remain stable over time (bottom).

The figure shows the architecture of the Saliency-driven Experience Replay (SER) method. It consists of two branches: a classification branch and a saliency prediction branch. The saliency prediction branch, which is designed to be robust to forgetting, generates saliency maps. These saliency maps are then used to modulate the features learned by the classification branch, improving the model’s ability to learn new tasks without forgetting previous ones. The modulation happens through an attention mechanism that incorporates the saliency map into the classification feature learning process.
The figure compares the performance of saliency prediction and classification models in continual learning settings. The left graph shows that saliency prediction remains stable while classification accuracy degrades over time. The right side displays activation maps and demonstrates how saliency maps are more robust to catastrophic forgetting than activation maps.
More on tables
This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. It compares their performance on two benchmark datasets (Split Mini-ImageNet and Split FG-ImageNet) with and without the integration of the proposed Saliency-driven Experience Replay (SER) method. The results show the accuracy achieved with different buffer sizes (1000, 2000, 5000) and highlight the improvement provided by SER across various methods and datasets.
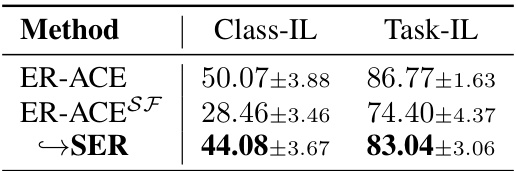
This table presents the results of an ablation study evaluating the robustness of the SER strategy against spurious features. It compares the performance of ER-ACE (a continual learning method) with and without SER in a class-incremental and task-incremental learning settings. The ‘ER-ACESF’ row represents the performance when training data includes spurious features (class signatures added to training images, while test images remain unchanged), illustrating the negative impact of spurious features on generalization. The ‘→SER’ row demonstrates the benefit of the SER strategy in mitigating this negative effect, showcasing its ability to improve robustness by integrating visual saliency information.
This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) technique. It shows the performance across different buffer sizes (1000, 2000, 5000) on two benchmark datasets: Split Mini-ImageNet and Split FG-ImageNet. The results demonstrate the improvement in accuracy achieved by incorporating SER into these existing methods.
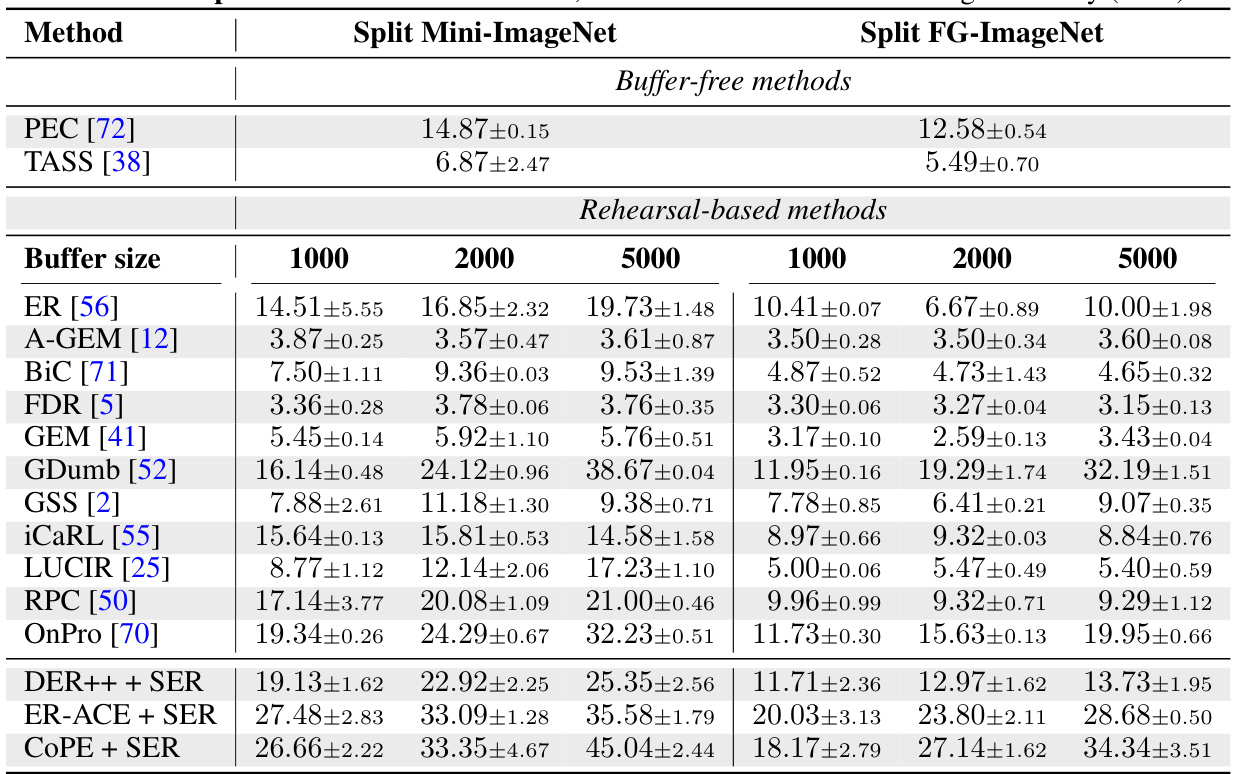
This table compares the Class-Incremental accuracy of several state-of-the-art (SOTA) rehearsal-based continual learning methods with and without the proposed Saliency-driven Experience Replay (SER) strategy. It shows the accuracy achieved by each method on two benchmark datasets (Split Mini-ImageNet and Split FG-ImageNet) with different buffer sizes (1000, 2000, 5000). The results demonstrate the significant performance improvement achieved by incorporating SER into existing methods.
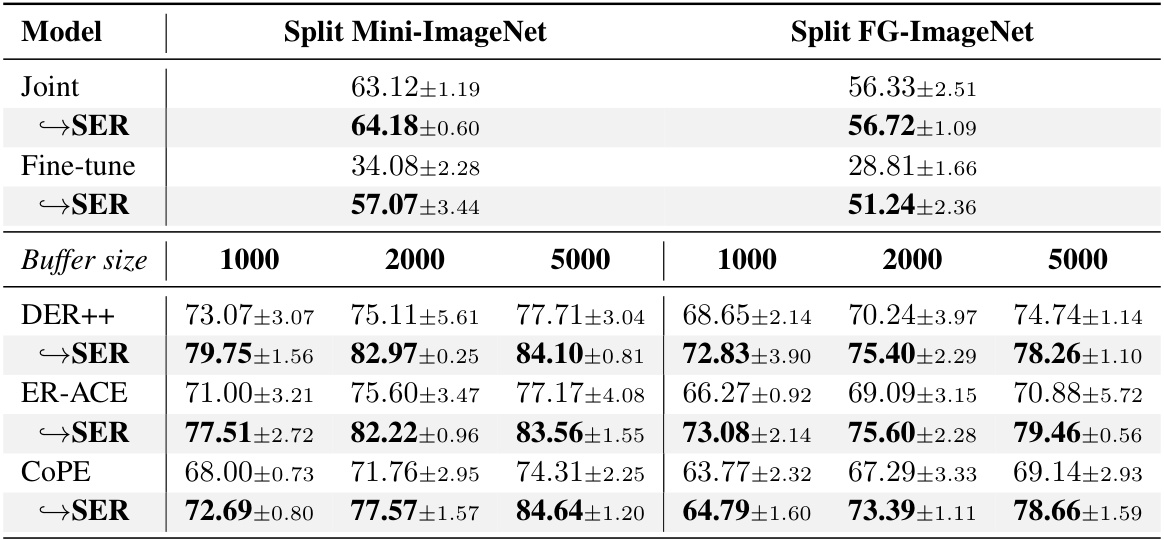
This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. It compares their performance with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are shown for two different datasets, Split Mini-ImageNet and Split FG-ImageNet, and for different buffer sizes (1000, 2000, and 5000). The table allows for a direct comparison of the performance gains achieved by incorporating the SER method into existing continual learning techniques.

This table presents a comparison of the performance of several state-of-the-art (SOTA) rehearsal-based continual learning methods, with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are shown for two different benchmark datasets (Split Mini-ImageNet and Split FG-ImageNet) and various buffer sizes (1000, 2000, 5000). It demonstrates the performance improvement achieved by incorporating SER into these existing methods, highlighting the effectiveness of the SER approach in enhancing continual learning capabilities.

This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. It compares their performance with and without the integration of the proposed Saliency-driven Experience Replay (SER) method. The results are shown for two different datasets (Split Mini-ImageNet and Split FG-ImageNet) and various buffer sizes (1000, 2000, 5000), demonstrating the impact of SER across different experimental settings.
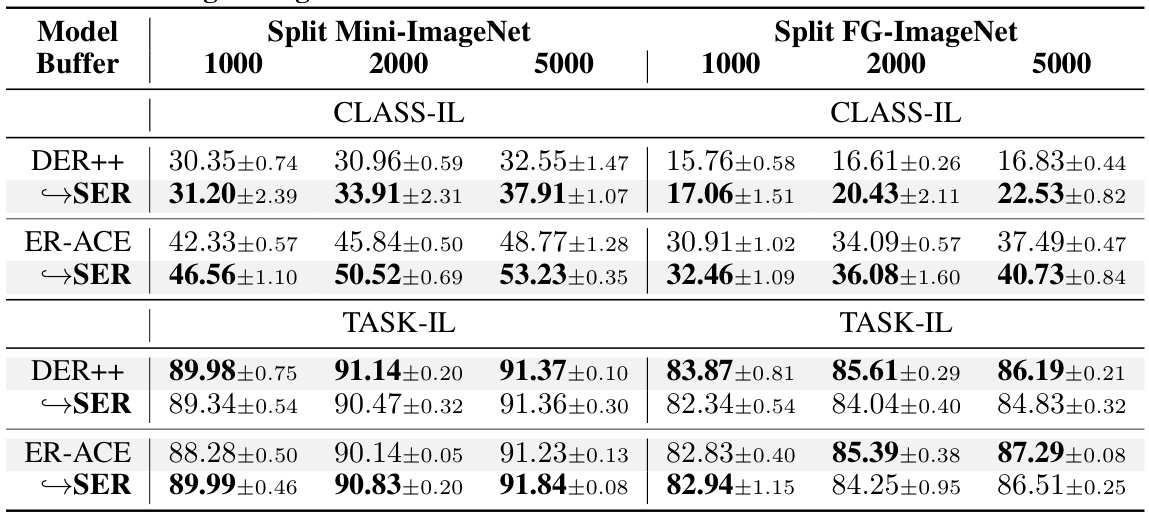
This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are shown for two different datasets (Split Mini-ImageNet and Split FG-ImageNet) and across various buffer sizes (1000, 2000, and 5000). The table allows for a comparison of the performance gains achieved by incorporating the SER method into existing continual learning approaches.

This table presents a comparison of the performance of several state-of-the-art (SOTA) rehearsal-based continual learning methods, with and without the integration of the proposed Saliency-driven Experience Replay (SER) technique. The results are shown for two different benchmark datasets (Split Mini-ImageNet and Split FG-ImageNet) and various buffer sizes (1000, 2000, and 5000). The table highlights the improvements in classification accuracy achieved by incorporating SER into the existing methods.

This table compares the performance of several state-of-the-art continual learning methods (DER++, ER-ACE, COPE, DualNet, TwF) on two benchmark datasets (Split Mini-ImageNet and Split FG-ImageNet) in a class-incremental setting. The results show the accuracy achieved by each method with and without the proposed Saliency-driven Experience Replay (SER) technique. Different buffer sizes are used for the methods that employ rehearsal. The table highlights the improvement in accuracy provided by integrating SER with each of the baseline continual learning methods.

This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. It compares the performance of these methods both with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are shown for two different datasets (Split Mini-ImageNet and Split FG-ImageNet) and various buffer sizes (1000, 2000, 5000) for methods that utilize a buffer. The table demonstrates the performance improvement achieved by incorporating SER into these existing methods.

This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are broken down by buffer size (1000, 2000, 5000) and dataset (Split Mini-ImageNet and Split FG-ImageNet). It allows for a comparison of the performance improvement achieved by incorporating SER into existing continual learning algorithms.

This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. It compares their performance both with and without the integration of the proposed Saliency-driven Experience Replay (SER) technique. The results are shown for two different datasets (Split Mini-ImageNet and Split FG-ImageNet) and various buffer sizes (memory capacity for past experiences). The table highlights the performance improvement achieved by incorporating SER into these existing continual learning methods.

This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. The results are broken down by dataset (Split Mini-ImageNet and Split FG-ImageNet), buffer size (1000, 2000, 5000), and whether SER was used. It allows for a comparison of the performance improvement achieved by incorporating SER into various continual learning approaches.
This table presents the Class-Incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods, both with and without the integration of the proposed Saliency-driven Experience Replay (SER) strategy. It compares the performance across different buffer sizes (1000, 2000, and 5000) on two benchmark datasets: Split Mini-ImageNet and Split FG-ImageNet. The results demonstrate the effectiveness of SER in enhancing the performance of existing continual learning methods.

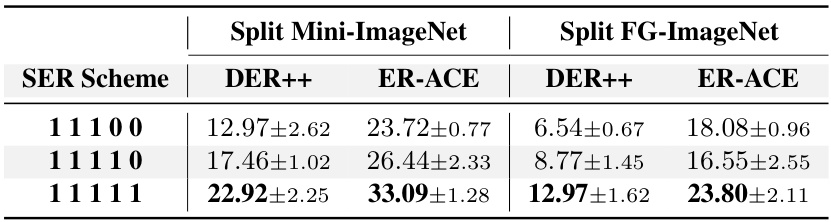
This table presents the class-incremental accuracy results for several state-of-the-art (SOTA) rehearsal-based continual learning methods. The results are shown for two different datasets (Split Mini-ImageNet and Split FG-ImageNet) and varying buffer sizes (1000, 2000, 5000). The table compares the performance of each method both with and without the Saliency-driven Experience Replay (SER) strategy. It highlights the improvement in accuracy achieved by integrating the SER strategy across different methods and datasets. The improvement is given in percentage points.
Full paper#