↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Understanding how large language models (LLMs) work is a major challenge. One approach is to identify “circuits,” which are small subnetworks capturing specific behaviors. Current methods for finding these circuits are either very slow or produce inaccurate results, especially for massive LLMs. This limits our understanding of how these complex models actually function.
This paper introduces “Edge Pruning,” a new method to find circuits. Unlike previous methods, Edge Pruning efficiently prunes edges (connections) between components, rather than whole components. It uses gradient-based optimization which is more efficient and accurate. Using Edge Pruning, researchers were able to find circuits in a model 100x larger than those previously studied. The results show circuits are highly sparse and match the accuracy of the full models, providing valuable insights into how they work.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI interpretability and large language models. It introduces a novel, scalable method for finding important subgraphs (circuits) within large models, addressing a critical limitation of existing methods. This opens new avenues for understanding model behavior and mechanisms, particularly in massive models where such analysis was previously infeasible. The results shed light on the inner workings of LLMs, a current research hot topic.
Visual Insights#
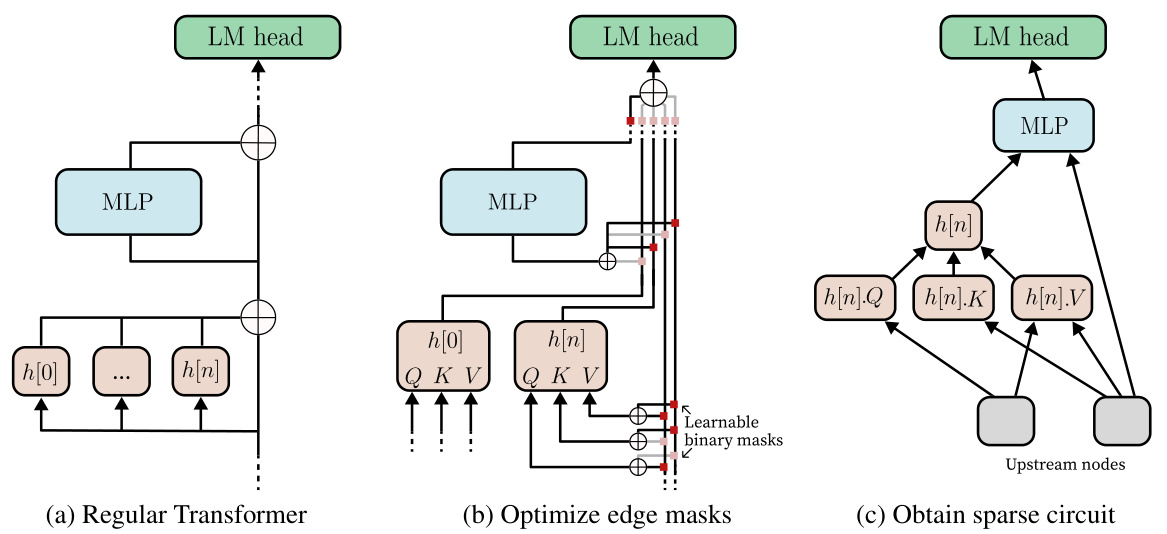
This figure illustrates the Edge Pruning method. (a) shows a regular Transformer with a residual stream. (b) shows the modified Transformer architecture where the residual stream is replaced with a disentangled residual stream, allowing for the introduction of learnable binary masks on the edges. These masks control which components are read from. (c) shows the resulting sparse circuit after optimizing the masks and discretizing them to 0 or 1. The full model is represented by the case where all masks are 1.

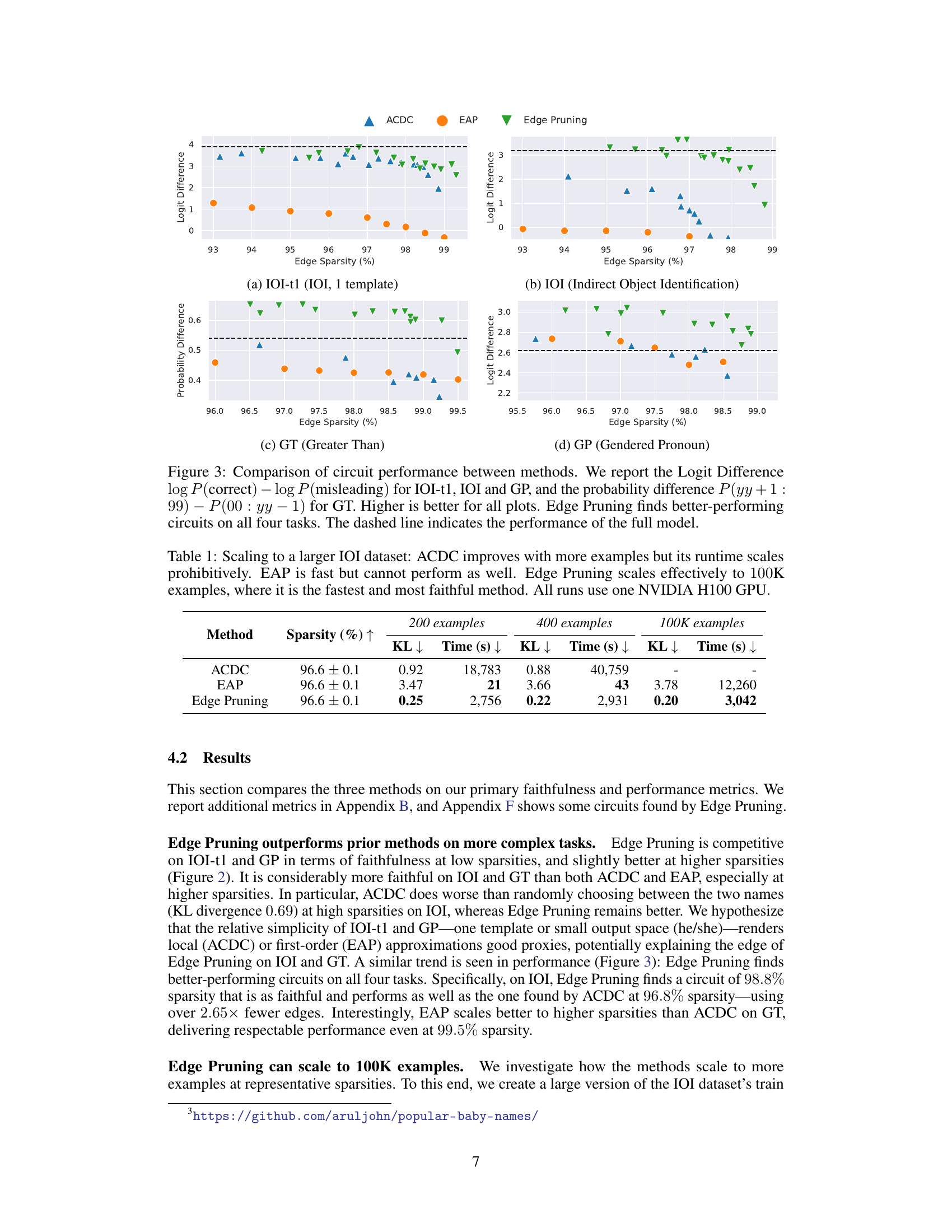
This table compares three methods (ACDC, EAP, and Edge Pruning) for circuit discovery on a larger dataset (100k examples). It shows how the KL divergence, runtime, and sparsity of the obtained circuits change as the number of examples increases. The results highlight the scalability and efficiency of Edge Pruning compared to other methods.
In-depth insights#
Edge Pruning#
The proposed technique, Edge Pruning, offers a novel approach to automated circuit discovery within transformer models. Instead of the conventional methods that prune neurons or components, Edge Pruning directly targets the edges, leveraging gradient-based pruning. This approach is computationally efficient, even when handling datasets with a large number of examples. By framing circuit discovery as an optimization problem and using gradient-based techniques, it addresses limitations of previous methods that relied on inefficient search algorithms or inaccurate approximations. Edge Pruning demonstrates superior performance, achieving higher fidelity to full model predictions while using fewer edges. The scalability is a significant advantage, allowing the exploration of substantially larger models compared to existing approaches. This technique is not just efficient and effective but also paves the way for a deeper understanding of complex model behaviors in large language models.
Circuit Discovery#
Circuit discovery in neural networks aims to identify sparse subgraphs, or “circuits,” that explain specific model behaviors. This is crucial for mechanistic interpretability, moving beyond simple input-output analysis to understand the internal workings. Early approaches were largely manual, painstakingly tracing activations to pinpoint key components. However, the scale and complexity of modern models necessitate automated methods. Automated circuit discovery methods face challenges in efficiently searching the vast space of possible circuits while ensuring faithfulness to the full model’s behavior. Gradient-based methods offer scalability, but approximations can sacrifice accuracy. The trade-off between efficiency and accuracy remains a central challenge. Future work should focus on developing more robust and scalable techniques that can handle increasingly large models, address the complexity of circuit interactions, and provide more comprehensive explanations of model behavior. Ultimately, the goal is to use circuit discovery to gain deeper insights into the decision-making processes within neural networks, revealing the underlying logic and potentially leading to more reliable and interpretable AI systems.
Interpretability#
The concept of “Interpretability” in the context of large language models (LLMs) is a crucial area of research. The core challenge lies in understanding the complex internal mechanisms of these models, which often operate as “black boxes.” This research directly addresses interpretability by focusing on the discovery and analysis of “circuits.” These circuits are essentially sparse subgraphs within the model’s architecture that capture specific behaviors or aspects of its functionality. By identifying and analyzing these circuits, researchers aim to gain insights into how models process information and make predictions, paving the way for better understanding and potentially more robust and reliable AI systems. The research highlights the critical need for efficient and scalable methods for discovering these circuits, as prior approaches have faced limitations in terms of speed and accuracy. This is where the proposed Edge Pruning technique shines, offering a significant advancement in the field by providing an efficient and scalable method for identifying and analyzing these crucial circuits within LLMs.
Scalability#
The paper’s exploration of scalability focuses on the efficiency and effectiveness of Edge Pruning when applied to increasingly larger models and datasets. Edge Pruning’s gradient-based approach, unlike prior methods relying on exhaustive search or inaccurate approximations, proves efficient even with 100K examples. This scalability is demonstrated by successfully applying the method to CodeLlama-13B, a model significantly larger than those previously studied. The ability to scale to such a large model size allows for insightful case studies, such as comparing instruction prompting and in-context learning, uncovering subtle mechanistic differences that emerge only in large models. While the memory footprint increases with the disentangled residual stream, the authors demonstrate that parallelization techniques effectively mitigate this, proving the practical scalability of the technique for real-world applications involving large-scale models and substantial datasets. However, limitations are acknowledged, such as the memory cost compared to other techniques. The paper’s demonstration of successful scaling to a large model and dataset is a key strength, highlighting the technique’s practical applicability for mechanistic interpretability research.
Future Work#
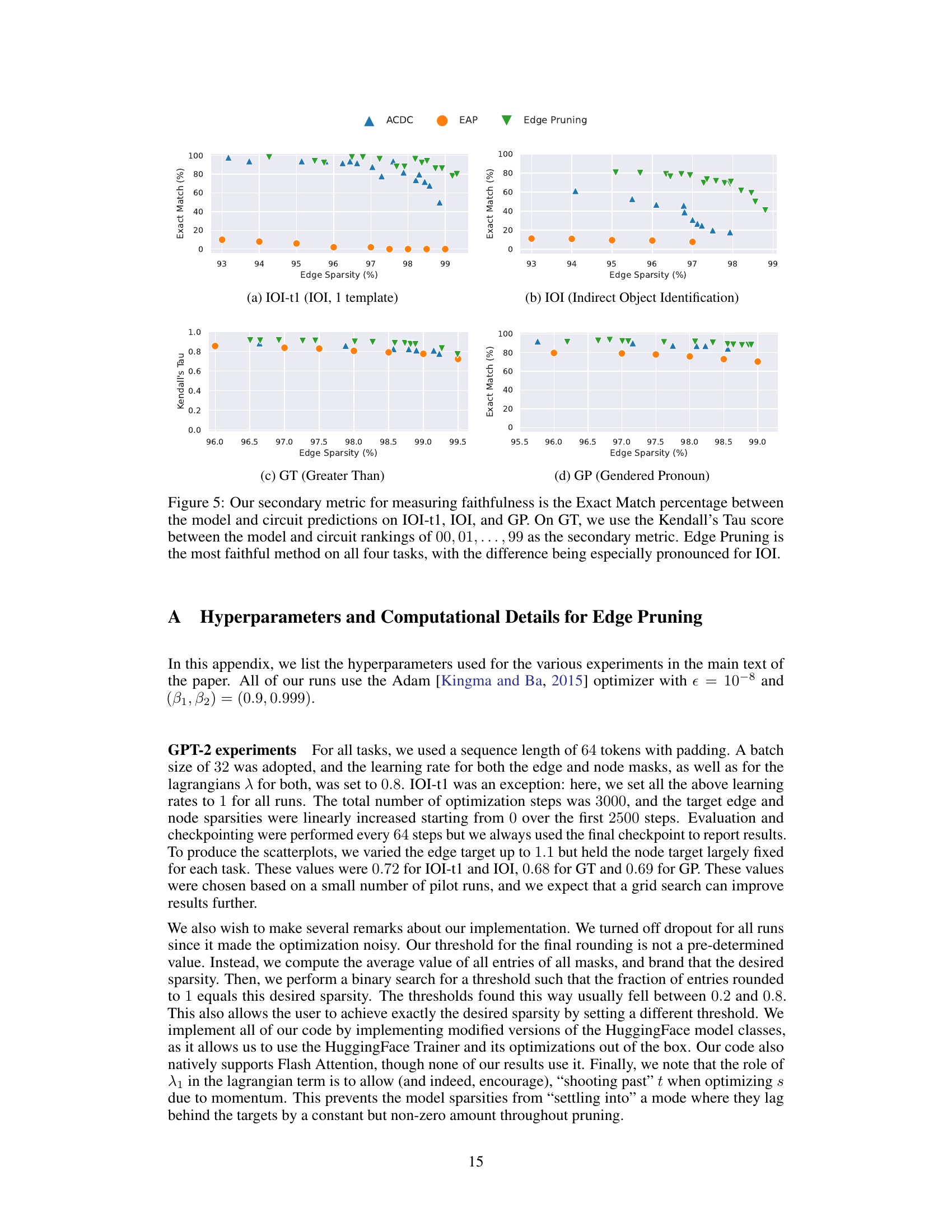
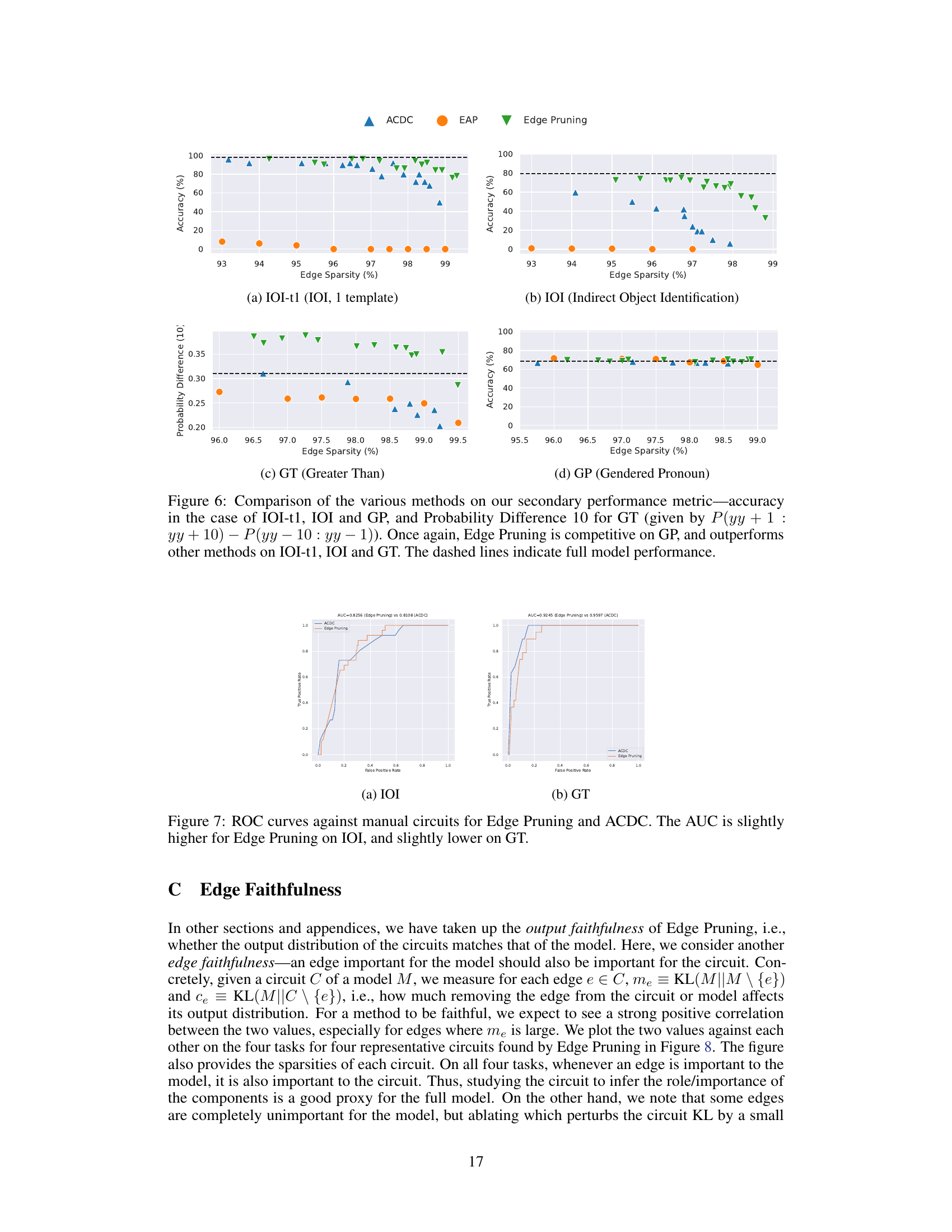
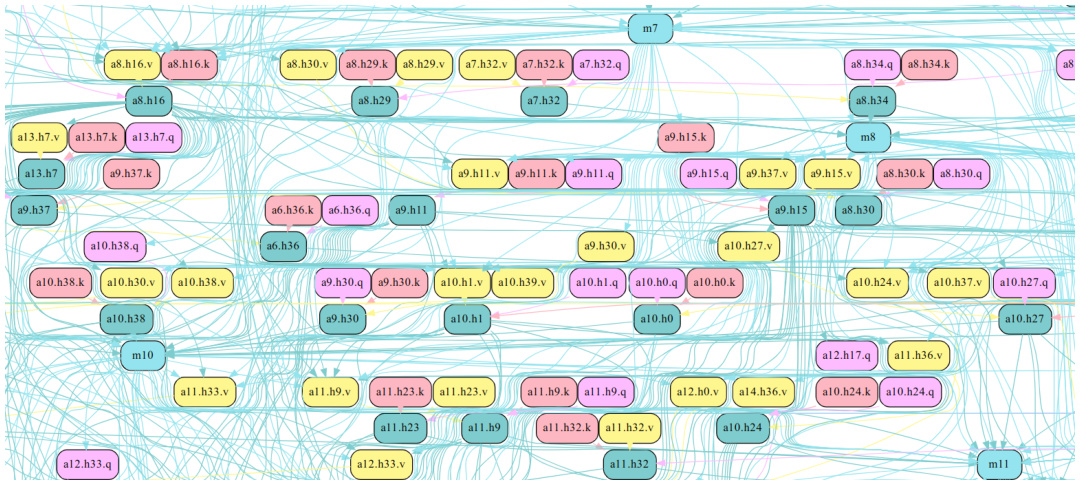
Future research directions stemming from this paper could significantly advance mechanistic interpretability. Scaling Edge Pruning to even larger models (beyond 13B parameters) is crucial to understanding emergent capabilities in massive language models. Improving the efficiency of Edge Pruning is also warranted, potentially through exploring more sophisticated optimization algorithms or incorporating pre-pruning techniques. A key area for future exploration is developing more robust faithfulness metrics, moving beyond KL divergence and exploring measures that better capture the nuanced behavior of circuits. A deeper dive into manual analysis of large-scale circuits is needed to extract more meaningful insights; current methods struggle to interpret circuits with thousands of edges. Finally, rigorous investigation into the existence of multiple optimal circuits and their properties would shed light on the inherent redundancy and robustness of neural networks.
More visual insights#
More on figures
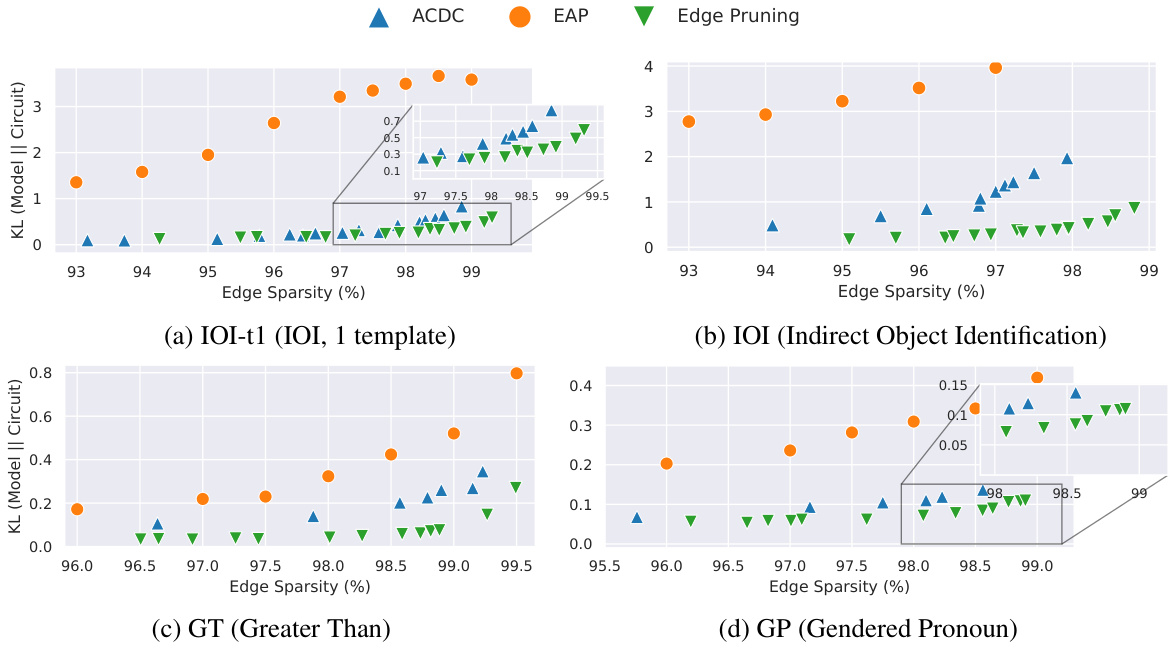
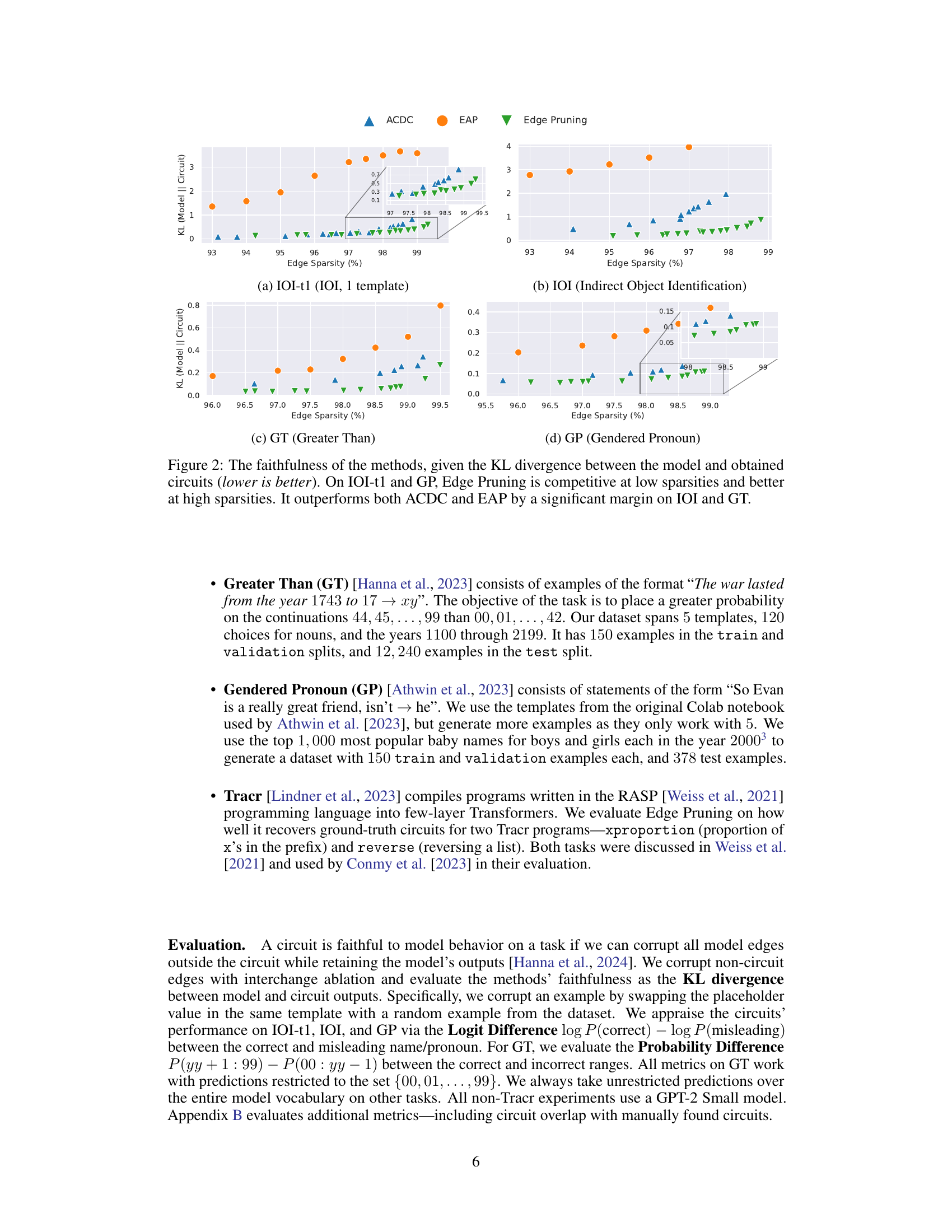
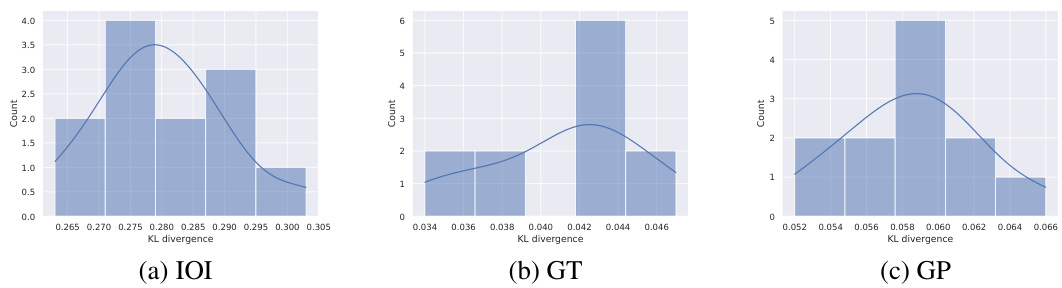
This figure compares three methods (ACDC, EAP, and Edge Pruning) for finding circuits in a language model, evaluating their faithfulness to the full model. Faithfulness is measured by KL divergence, a lower score indicating better faithfulness. The results are shown across four different tasks (IOI-t1, IOI, GT, and GP), with varying levels of edge sparsity in the circuits. Edge Pruning consistently demonstrates higher faithfulness, especially for the IOI and GT tasks, meaning that the pruned circuits accurately represent the full model’s behavior.
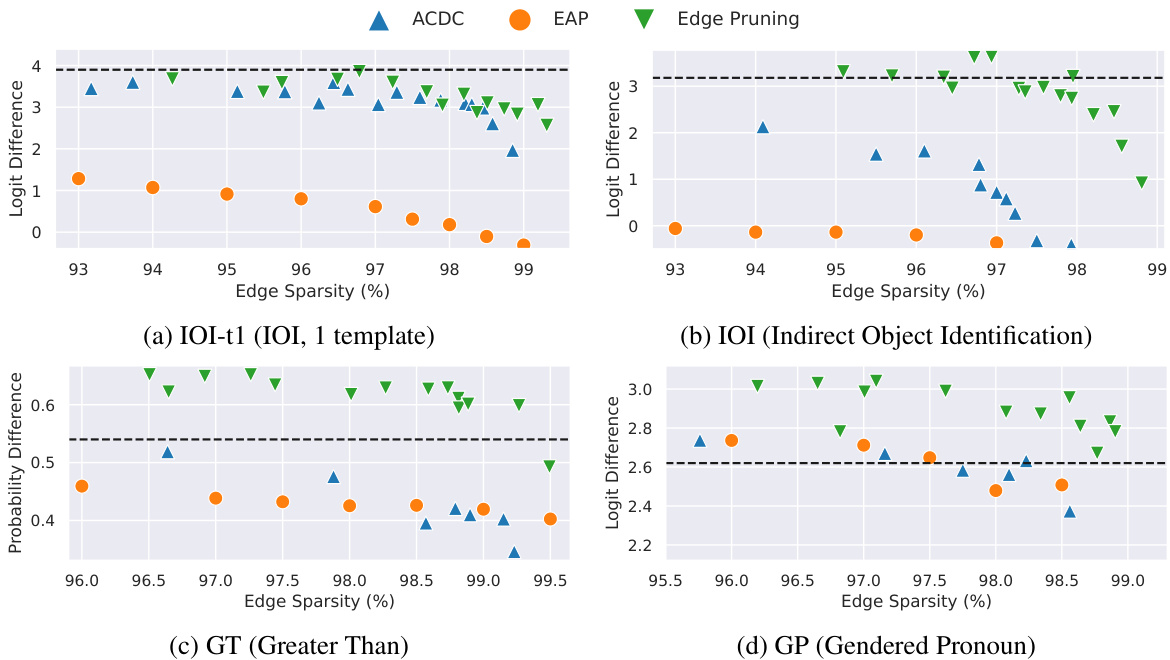
This figure compares three methods (ACDC, EAP, and Edge Pruning) for circuit discovery based on their faithfulness to the full model’s predictions. Faithfulness is measured using KL divergence, a metric that quantifies the difference between the probability distributions of model outputs and circuit outputs. Lower KL divergence indicates higher faithfulness. The figure shows that Edge Pruning consistently achieves lower KL divergence than the other methods across four different tasks (IOI-t1, IOI, GT, and GP), indicating that it produces more faithful circuits. Notably, while Edge Pruning and ACDC are comparable on IOI-t1 and GP at lower sparsities, Edge Pruning significantly outperforms them on IOI and GT, particularly at higher sparsities.
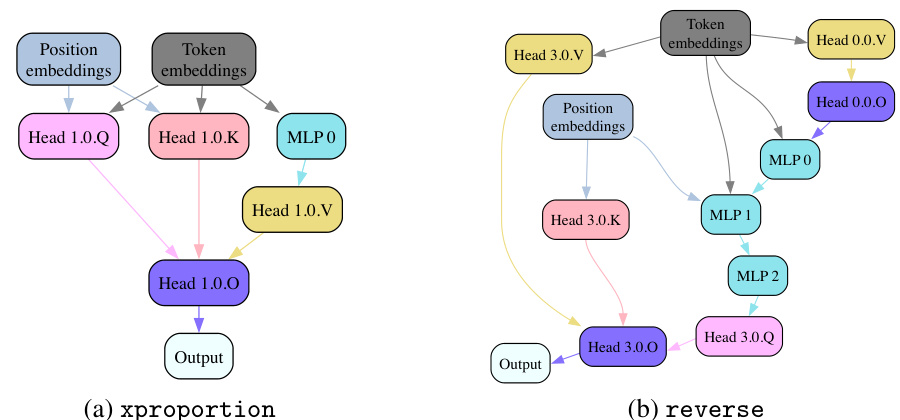
This figure shows the ground truth circuits for two programs compiled using Tracr, a tool that compiles programs into Transformers. The figure demonstrates that Edge Pruning, the method proposed in the paper, is able to perfectly recover these ground truth circuits, highlighting its accuracy and effectiveness.
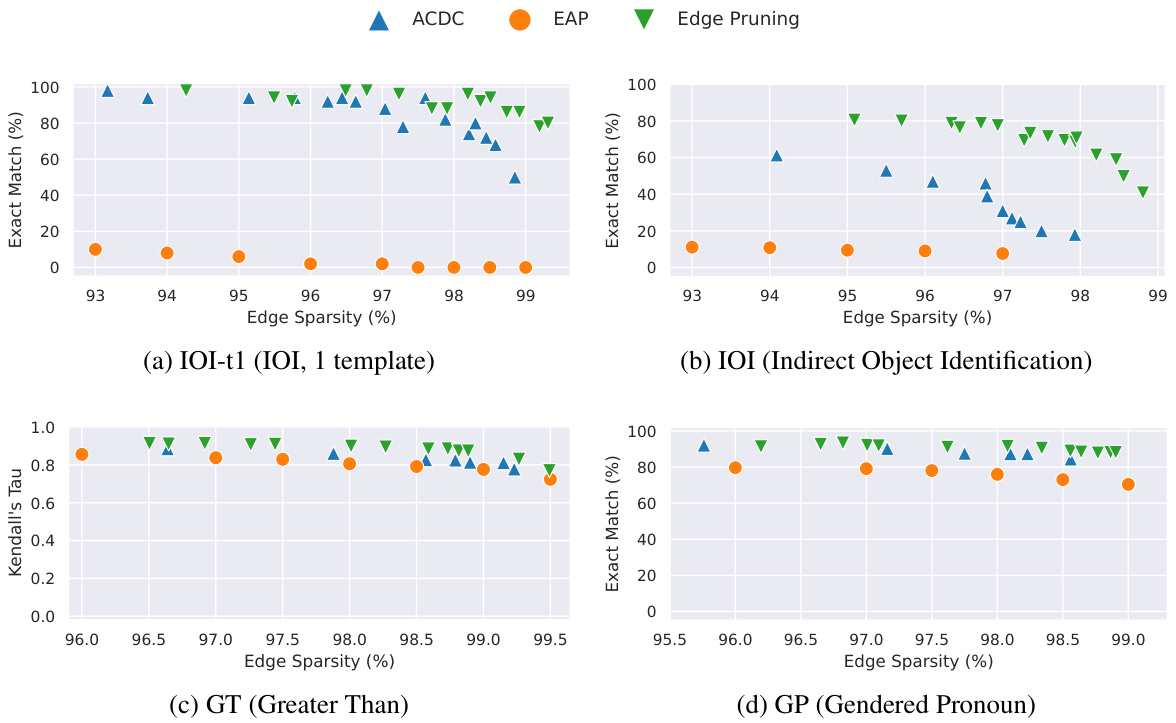
This figure compares the faithfulness of three circuit discovery methods (ACDC, EAP, and Edge Pruning) across four different tasks (IOI-t1, IOI, GT, and GP). Faithfulness is measured by the KL divergence between the full model’s predictions and the predictions of the generated circuits; lower KL divergence indicates higher faithfulness. The x-axis represents the sparsity of the circuit (percentage of edges retained), and the y-axis represents the KL divergence. The results show that Edge Pruning consistently achieves lower KL divergence (higher faithfulness) than ACDC and EAP, particularly at higher sparsities, demonstrating its superior ability to find sparse circuits that accurately represent the behavior of the full model.
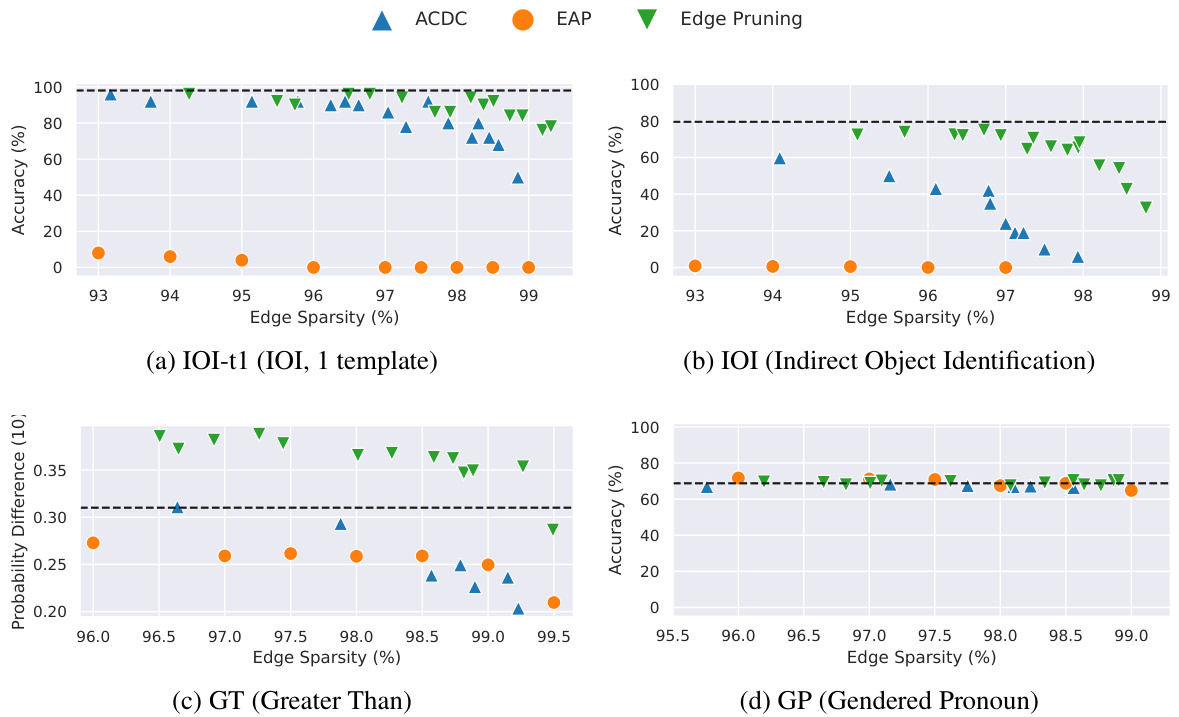
This figure compares three methods (ACDC, EAP, and Edge Pruning) for circuit discovery based on their faithfulness to the full model, measured by KL divergence. Lower KL divergence indicates higher faithfulness. The x-axis represents the edge sparsity of the discovered circuit (higher is more sparse). The y-axis shows the KL divergence between the full model’s predictions and the circuit’s predictions. The figure includes four subplots, each representing a different task: IOI-t1 (a single template version of Indirect Object Identification), IOI (a multi-template version of Indirect Object Identification), GT (Greater Than), and GP (Gendered Pronoun). Edge Pruning demonstrates consistently lower KL divergence across various sparsities, indicating better faithfulness to the model, particularly for the IOI and GT tasks.
This figure compares three different methods (ACDC, EAP, and Edge Pruning) for discovering circuits in a transformer model, based on how faithfully the discovered circuit represents the behavior of the full model. The faithfulness is measured using KL divergence, with lower values indicating higher faithfulness. The figure shows that Edge Pruning consistently achieves better faithfulness, particularly on more complex tasks (IOI and GT). Specifically, it demonstrates superior performance at higher sparsities (i.e., when the circuit is more sparse), showcasing its ability to find concise yet accurate representations of model behavior.
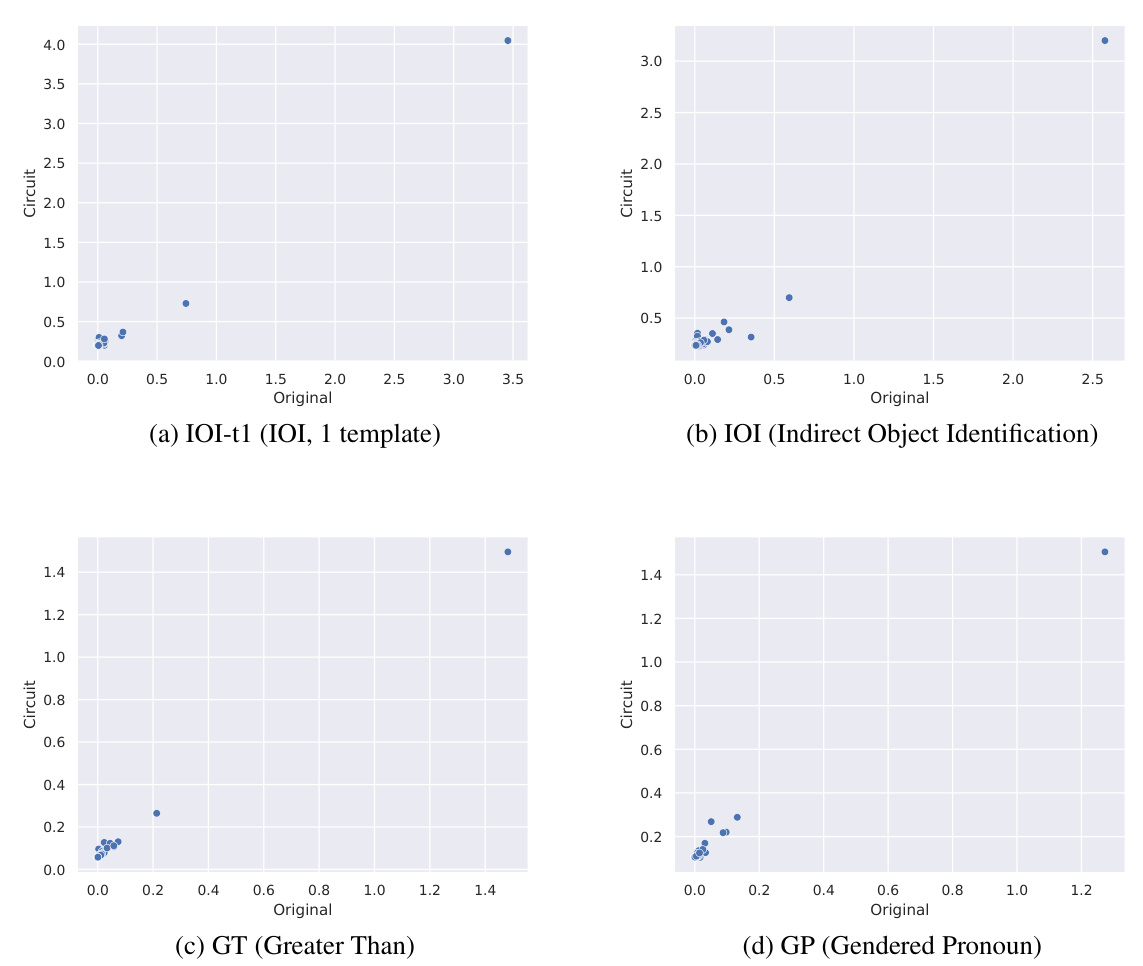
This figure compares three methods (ACDC, EAP, and Edge Pruning) for discovering circuits in a transformer model based on their faithfulness. Faithfulness is measured by the Kullback-Leibler (KL) divergence between the full model’s predictions and the predictions of the discovered circuit. Lower KL divergence indicates higher faithfulness. The x-axis represents the sparsity (percentage of edges removed) of the discovered circuit. The y-axis represents the KL divergence. The plots show that Edge Pruning consistently achieves lower KL divergence (higher faithfulness) than ACDC and EAP across four different tasks (IOI-t1, IOI, GT, and GP) and particularly at higher sparsities.
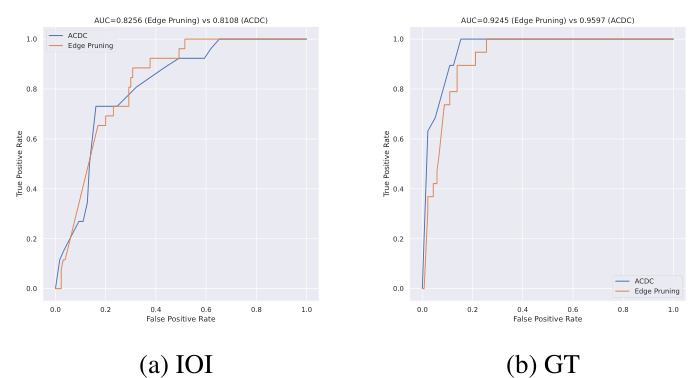
This figure compares three methods (ACDC, EAP, and Edge Pruning) for circuit discovery in terms of their faithfulness to the full model. Faithfulness is measured using the Kullback-Leibler (KL) divergence, which quantifies the difference between the full model’s predictions and the predictions of the sparse circuit produced by each method. Lower KL divergence indicates higher faithfulness. The figure shows that across four different tasks (IOI-t1, IOI, GT, and GP), Edge Pruning consistently achieves lower KL divergence, especially at higher sparsity levels (more edges pruned), demonstrating its superior faithfulness to the full model.
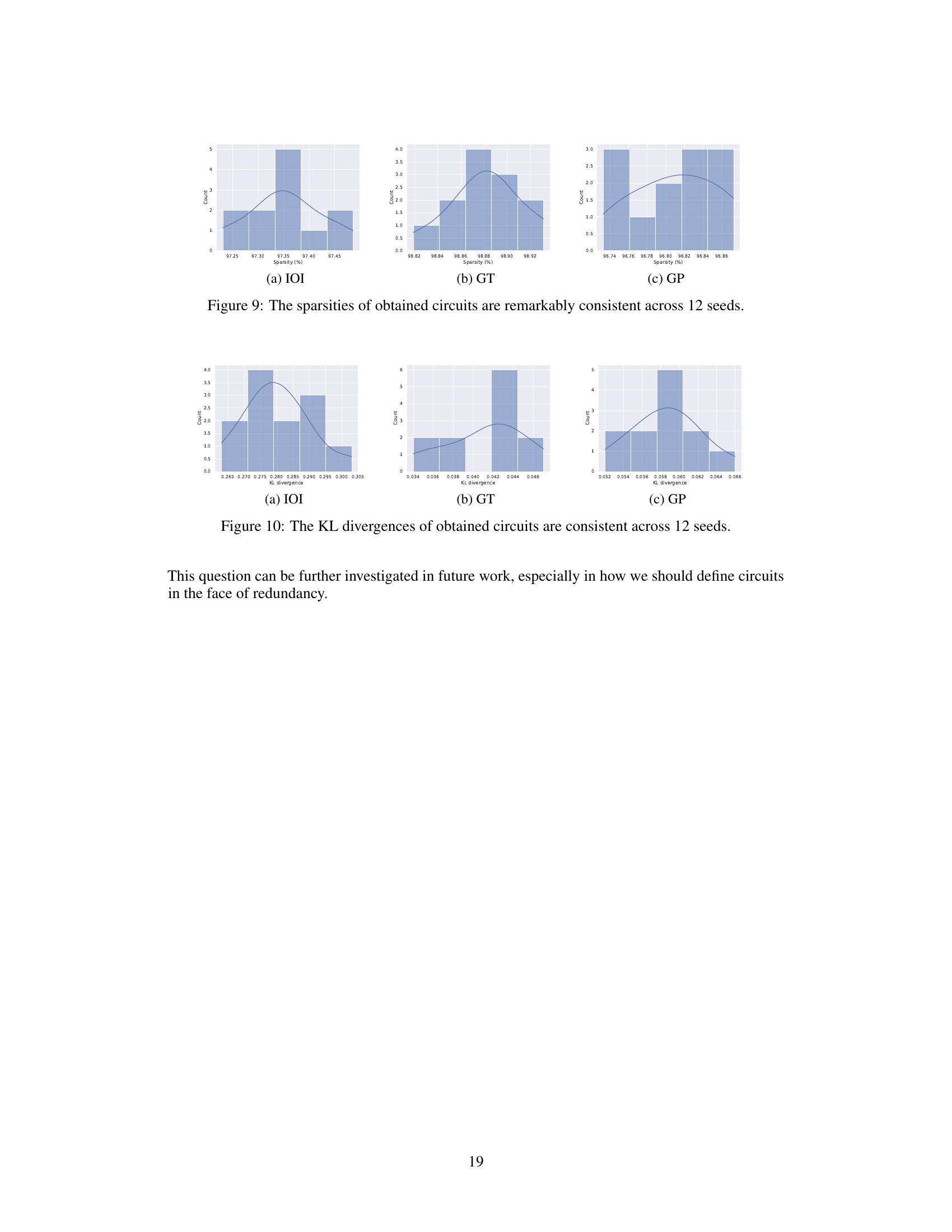
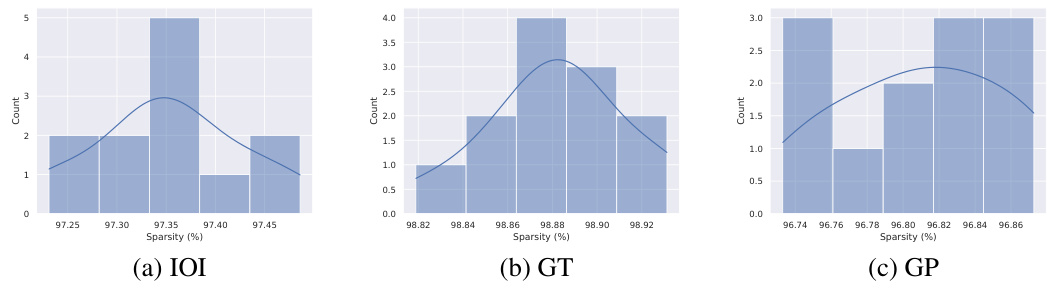
This figure shows the consistency of Edge Pruning’s results across multiple random initializations. Three histograms display the distribution of sparsity values obtained from running the algorithm 12 times on IOI, GT, and GP tasks, respectively. The consistency in the spread of sparsity values obtained suggests that the algorithm’s outcome is not overly sensitive to random initialization.
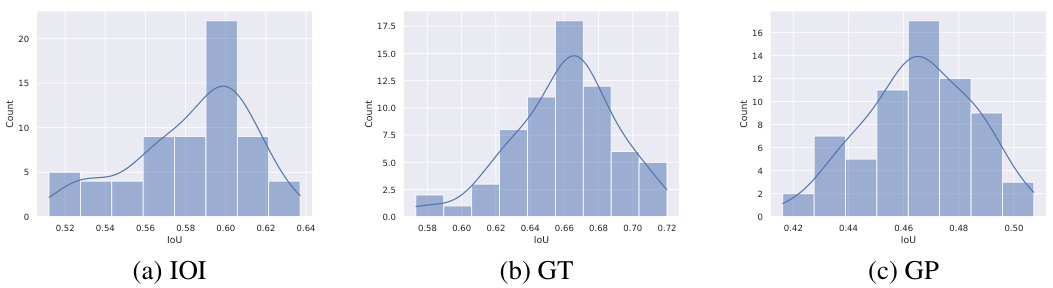
This figure shows the faithfulness of three different circuit discovery methods (ACDC, EAP, and Edge Pruning) across four different tasks (IOI-t1, IOI, GT, and GP). Faithfulness is measured using the KL divergence between the full model’s predictions and the predictions of the discovered circuits. Lower KL divergence indicates higher faithfulness. The x-axis represents the sparsity of the circuit (percentage of edges removed). The y-axis shows the KL divergence. Edge Pruning consistently shows lower KL divergence (higher faithfulness) compared to ACDC and EAP, particularly at higher sparsities. The results highlight the superior performance of Edge Pruning in accurately capturing the model’s behavior with significantly fewer edges.
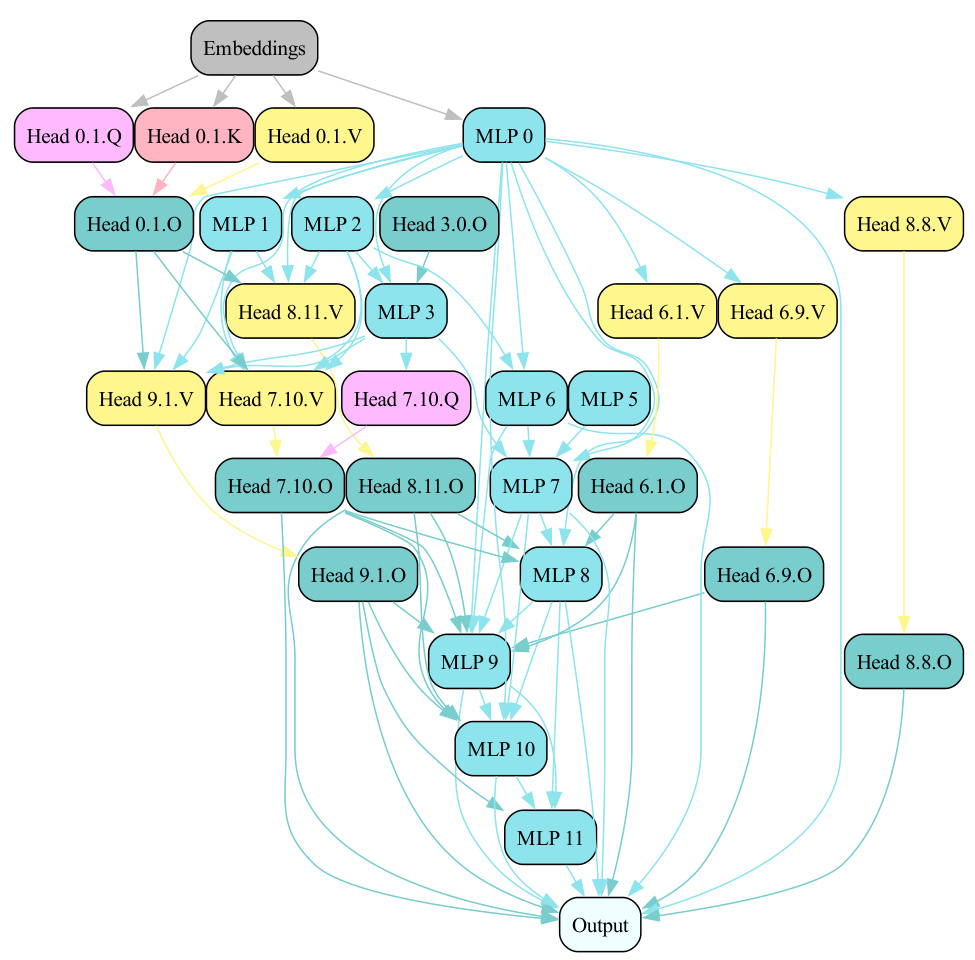
This figure illustrates the Edge Pruning method. It shows how the residual stream in a standard Transformer is disentangled, allowing for the introduction of edge masks. These masks control which components are read from, enabling the optimization of sparse circuits using gradient-based techniques. The final circuit is obtained by discretizing the continuous masks to binary values (0 or 1), with the full model corresponding to a scenario where all masks are set to 1.
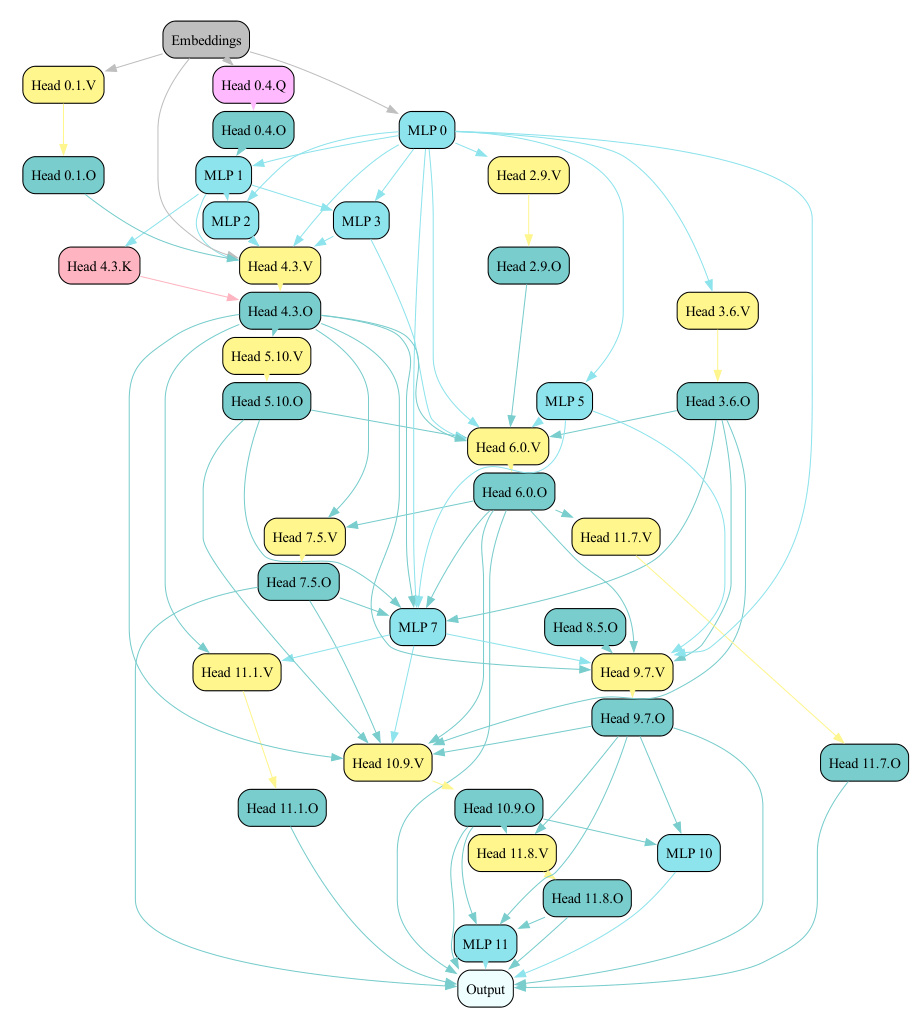
The figure illustrates the process of Edge Pruning, a method for finding sparse computational subgraphs (circuits) within Transformer models. It shows three stages: (a) a regular Transformer with a residual stream; (b) the introduction of learnable binary masks that control which components are read from the residual stream, optimized using gradient descent; and (c) the resulting sparse circuit obtained by discretizing the masks. The full model is represented by the scenario where all masks are 1.
This figure illustrates the process of Edge Pruning. (a) shows a regular Transformer with a residual stream. (b) shows how Edge Pruning modifies the architecture by introducing learnable binary masks to control the flow of information between components. These masks are optimized using gradient descent. (c) shows the resulting sparse circuit after discretizing the masks to 0 or 1, where 1 indicates an active edge and 0 indicates a pruned edge.
Full paper#