↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Sparse-to-dense methods in semantic scene completion often use shared, context-independent queries across input images. This leads to issues like undirected feature aggregation and depth ambiguity due to a lack of depth information handling. Existing approaches also struggle with aggregating information from different images effectively.
To address these challenges, this paper introduces CGFormer, a context and geometry-aware voxel transformer. CGFormer uses a context-aware query generator to create context-dependent queries tailored to each input image, capturing unique characteristics. It extends deformable cross-attention from 2D to 3D, differentiating points based on depth, and also incorporates a depth refinement block. The model uses both voxel and TPV representations to leverage local and global perspectives, resulting in state-of-the-art performance on SemanticKITTI and SSCBench-KITTI-360 benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D computer vision and autonomous driving because it presents CGFormer, a novel approach that significantly improves semantic scene completion. Its context and geometry-aware voxel transformer addresses limitations of existing methods, pushing the boundaries of accuracy and efficiency. This opens avenues for advanced 3D perception systems and inspires further research into efficient feature aggregation and multi-modal fusion techniques.
Visual Insights#
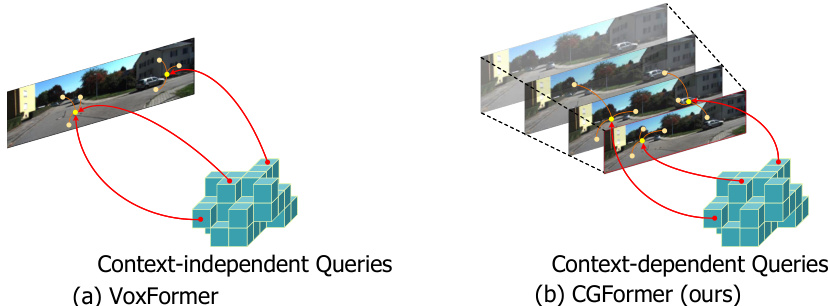
This figure compares feature aggregation methods between VoxFormer and CGFormer. (a) shows VoxFormer’s use of shared, context-independent queries, leading to undirected feature aggregation and depth ambiguity due to the lack of depth information. (b) illustrates CGFormer’s context-dependent queries, which are tailored to individual input images, resulting in improved feature aggregation and depth disambiguation.
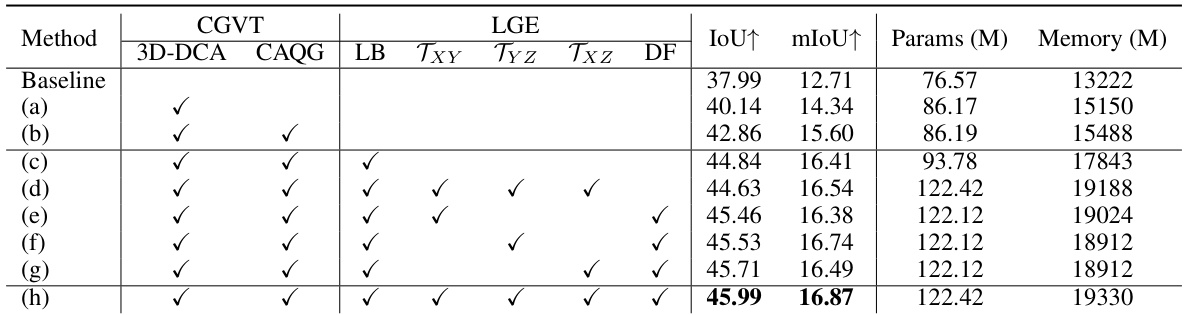
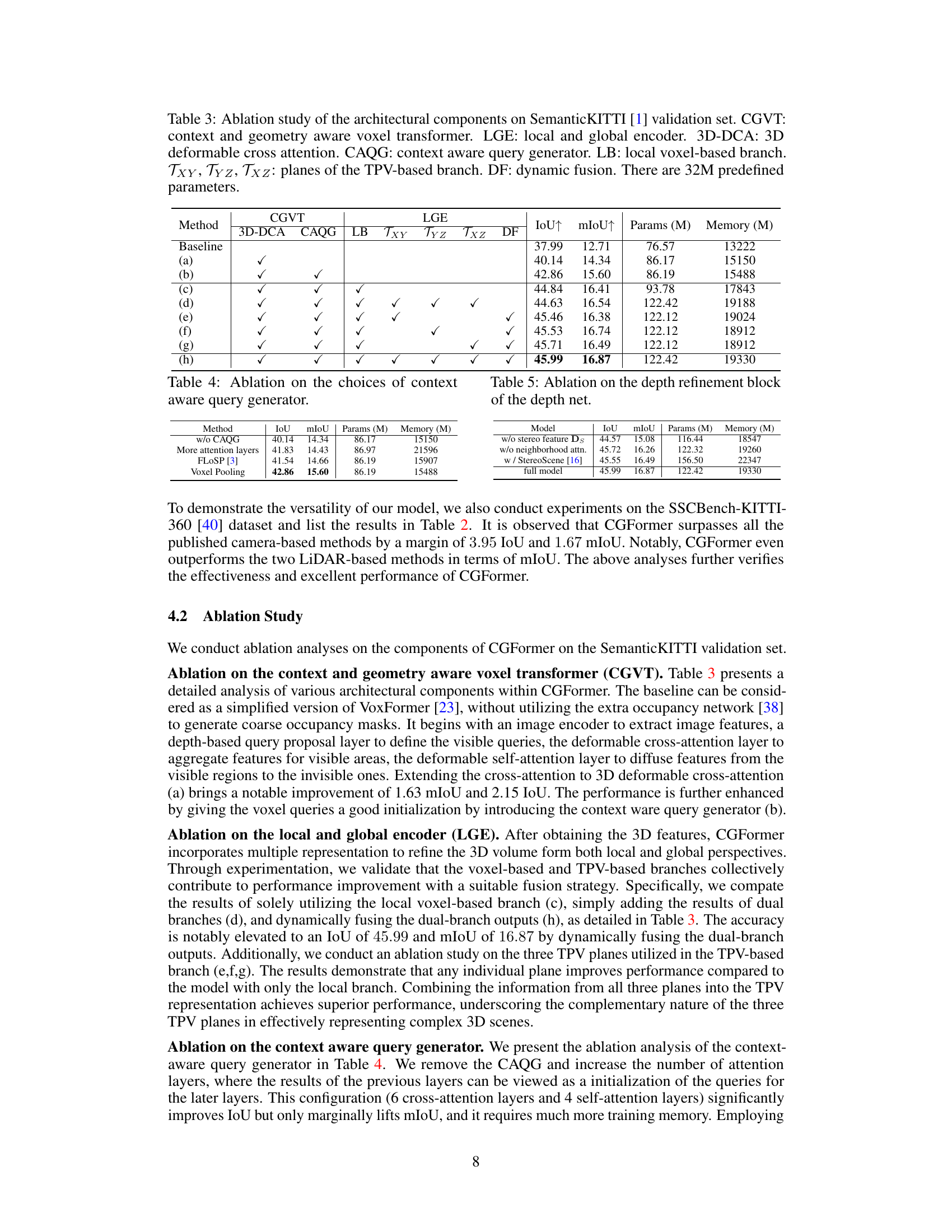
This ablation study analyzes the impact of different components of the CGFormer model on the SemanticKITTI validation set. It systematically removes or modifies components (context and geometry aware voxel transformer (CGVT), local and global encoder (LGE), 3D deformable cross-attention (3D-DCA), context-aware query generator (CAQG), local voxel-based branch (LB), TPV-based branches (Txy, Tyz, Txz), dynamic fusion (DF)) to isolate their individual effects on model performance (measured by IoU and mIoU). The baseline represents the model without any of the modifications. Each row shows the results with a specific combination of components, clearly showing the effect of each feature on performance.
In-depth insights#
CGFormer: SSC Approach#
CGFormer presents a novel approach to semantic scene completion (SSC), a crucial task in 3D perception. Its core innovation lies in a context and geometry-aware voxel transformer (CGVT), addressing limitations of previous methods. CGVT generates context-dependent queries tailored to each input image, avoiding the undirected feature aggregation seen in context-independent approaches. Further, it extends deformable cross-attention to 3D pixel space, resolving depth ambiguity. The integration of multiple 3D representations (voxel and tri-perspective view) enhances both semantic and geometric understanding. Experimental results on SemanticKITTI and SSCBench-KITTI-360 benchmarks demonstrate state-of-the-art performance, surpassing methods utilizing temporal images or larger backbones. CGFormer’s effectiveness highlights the significance of context-aware queries and 3D deformable attention for improved feature extraction and depth estimation in SSC. While exhibiting strong performance, limitations exist regarding accuracy on certain object classes and assumptions made about depth estimation; future work should address these.
Context-Aware Queries#
The concept of “Context-Aware Queries” in the domain of semantic scene completion is a significant advancement over traditional methods. Instead of employing generic, context-independent queries that treat all input images uniformly, context-aware queries are dynamically generated based on the unique characteristics of each individual image. This approach directly addresses the limitations of methods that fail to differentiate between diverse inputs, leading to inaccurate feature aggregation. By tailoring queries to specific image contexts, the model can effectively focus on regions of interest, improving both the accuracy and efficiency of feature extraction. Moreover, the depth ambiguity often encountered in 2D-to-3D lifting is mitigated by incorportating depth information into the query generation process. This allows for a more precise identification of 3D points, enhancing the overall semantic understanding of the scene. The strategy results in a more refined and accurate representation of the 3D scene, ultimately improving the overall performance of the semantic scene completion task. The innovative aspect lies in the intelligent adaptation of the query mechanism, which makes it more robust and effective for diverse and complex scenarios.
3D Deformable Attention#
3D deformable attention is a powerful mechanism that extends the capabilities of traditional attention mechanisms to three-dimensional data. Unlike standard attention which uses fixed kernels to weigh features, deformable attention allows for adaptive sampling of features, attending to relevant locations in the 3D space rather than being constrained to a grid. This adaptability is particularly beneficial when dealing with sparse or irregular 3D point clouds, as it enables the network to focus on the most informative parts of the input. The deformable nature of the attention mechanism further improves performance by allowing the model to dynamically adjust its receptive field based on the specific features present in the input. The extension to 3D is non-trivial, requiring efficient methods for sampling features in a continuous 3D space, which may involve interpolation or other techniques. This adaptability, flexibility and efficiency makes 3D deformable attention a valuable tool for 3D vision tasks such as scene completion, object detection and semantic segmentation. It has the potential to significantly improve accuracy and reduce computational costs compared to more traditional approaches.
Ablation Study Analysis#
An ablation study systematically evaluates the contribution of individual components within a model. In the context of a semantic scene completion model, this might involve removing or altering aspects like the context-aware query generator, the 3D deformable cross-attention mechanism, or the local and global encoders. By analyzing the impact of each ablation on the overall performance (e.g., mIoU), researchers can determine the importance and effectiveness of each component. A well-designed ablation study reveals which architectural choices are crucial for success and which parts might be simplified or improved. This analysis is essential for understanding model behavior, guiding future improvements, and establishing the validity of design choices. The results often highlight unexpected interactions between components, providing deep insights into the model’s inner workings, and potentially pointing to areas for future research and refinement. Finally, a strong ablation study helps in building a robust and justified model architecture, rather than relying on intuition alone.
Future Work: Limitations#
A section titled “Future Work: Limitations” in a research paper would offer a crucial reflective space. It should honestly acknowledge shortcomings, like inability to handle certain object classes effectively or over-reliance on specific data types. The discussion would also highlight areas for improvement, such as exploring alternative data modalities or architectural enhancements to address computational limitations. Addressing robustness to noisy or incomplete data should be a key focus, along with specifying the techniques used to mitigate them. Finally, it should discuss the generalizability of findings beyond the specific datasets used, acknowledging potential biases or limitations that could restrict wider applicability. This section is key for demonstrating self-awareness and guiding future research directions.
More visual insights#
More on figures
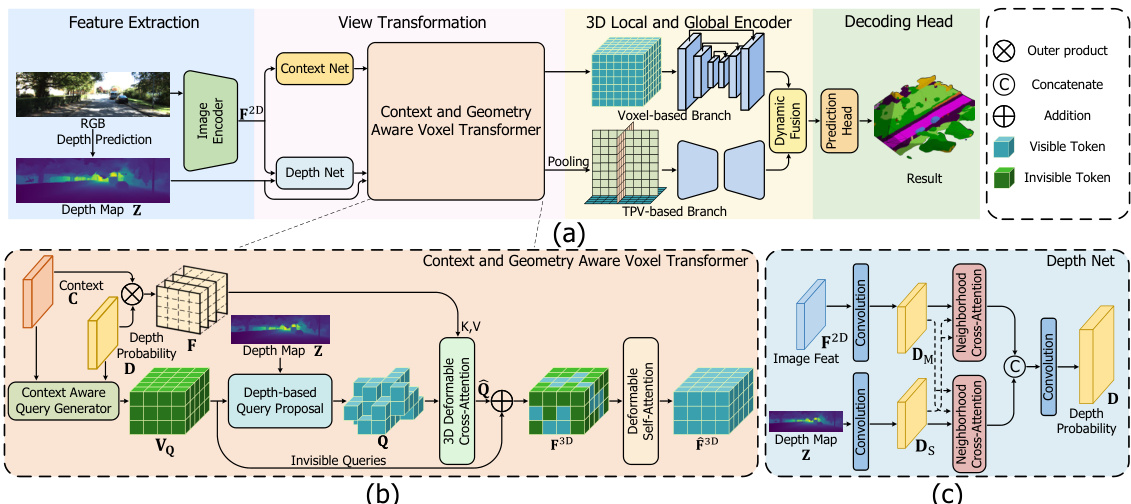
This figure shows the overall architecture of CGFormer, a neural network for semantic scene completion. It is divided into four parts: feature extraction, view transformation using a context and geometry aware voxel transformer (CGVT), a 3D local and global encoder (LGE) for enhancing the 3D features, and a decoding head to output the final semantic occupancy prediction. The CGVT module includes context-aware query generation and 3D deformable cross and self-attention mechanisms. The depth net refines depth estimation using information from stereo depth estimation. The figure provides detailed schematics of each component, including the CGVT and the depth net.
This figure visualizes how the proposed context-aware query generator in CGFormer focuses the sampling points of the deformable cross-attention on the regions of interest for individual input images, enhancing the accuracy and efficiency of feature aggregation compared to context-independent methods.
This figure shows the architecture of CGFormer, a novel neural network for semantic scene completion. It illustrates the four main components: feature extraction, view transformation, 3D local and global encoder, and a decoding head. It details the context and geometry-aware voxel transformer (CGVT), which lifts 2D image features into 3D volumes while considering individual image contexts and geometry. Finally, it provides a close-up of the Depth Net module.

This figure shows the overall architecture of CGFormer, a novel neural network for semantic scene completion. It is broken down into four main parts: feature extraction, view transformation, 3D local and global encoding, and the decoding head. The view transformation module is further detailed, showing its use of a context-aware query generator and deformable 3D attention. Finally, the details of the depth estimation network are also shown.
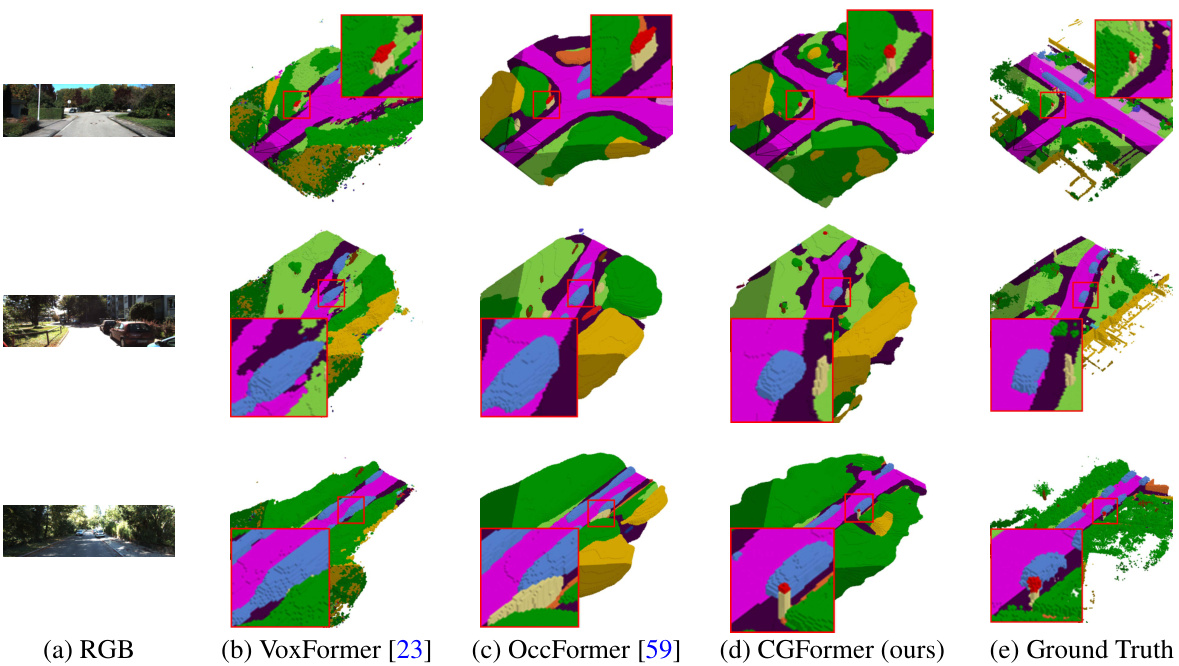
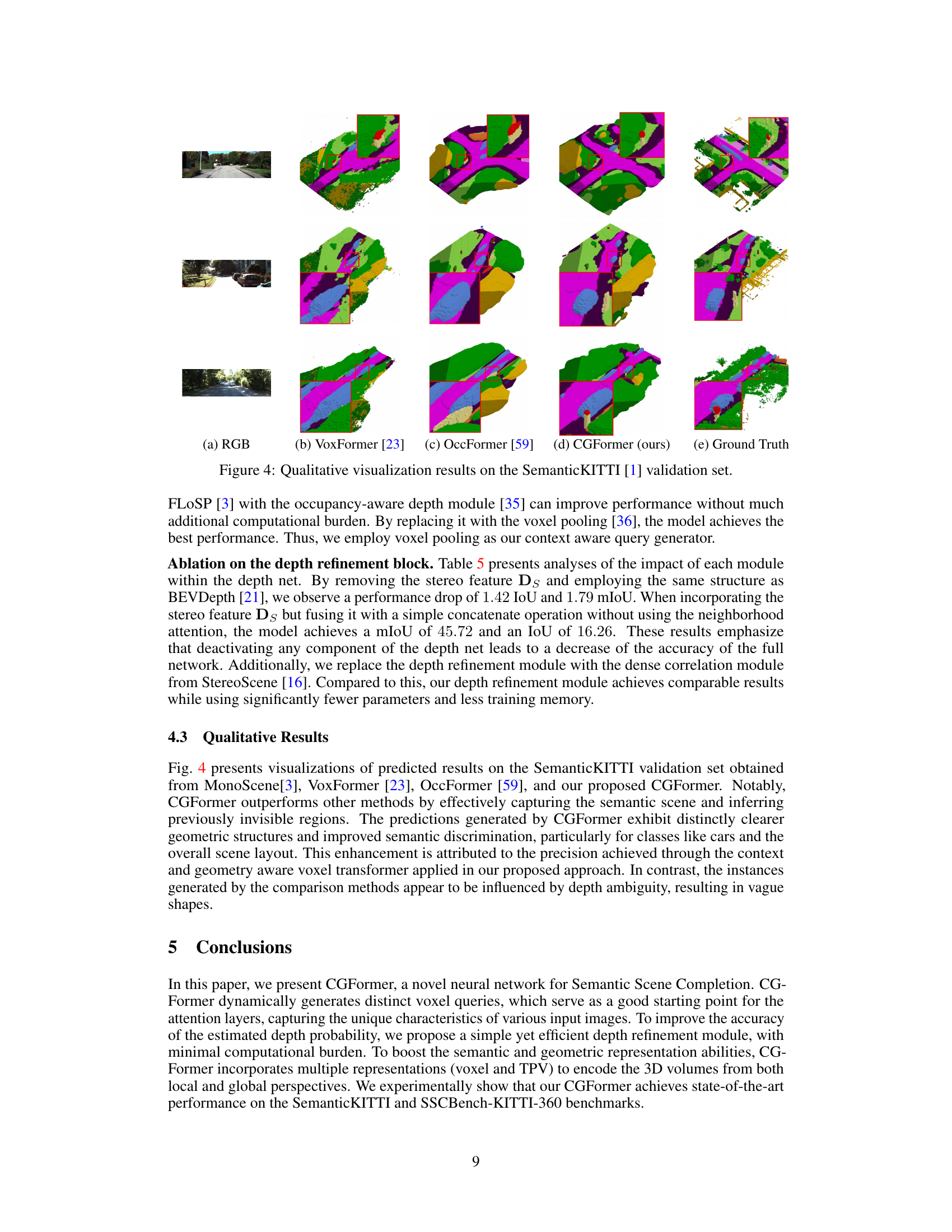
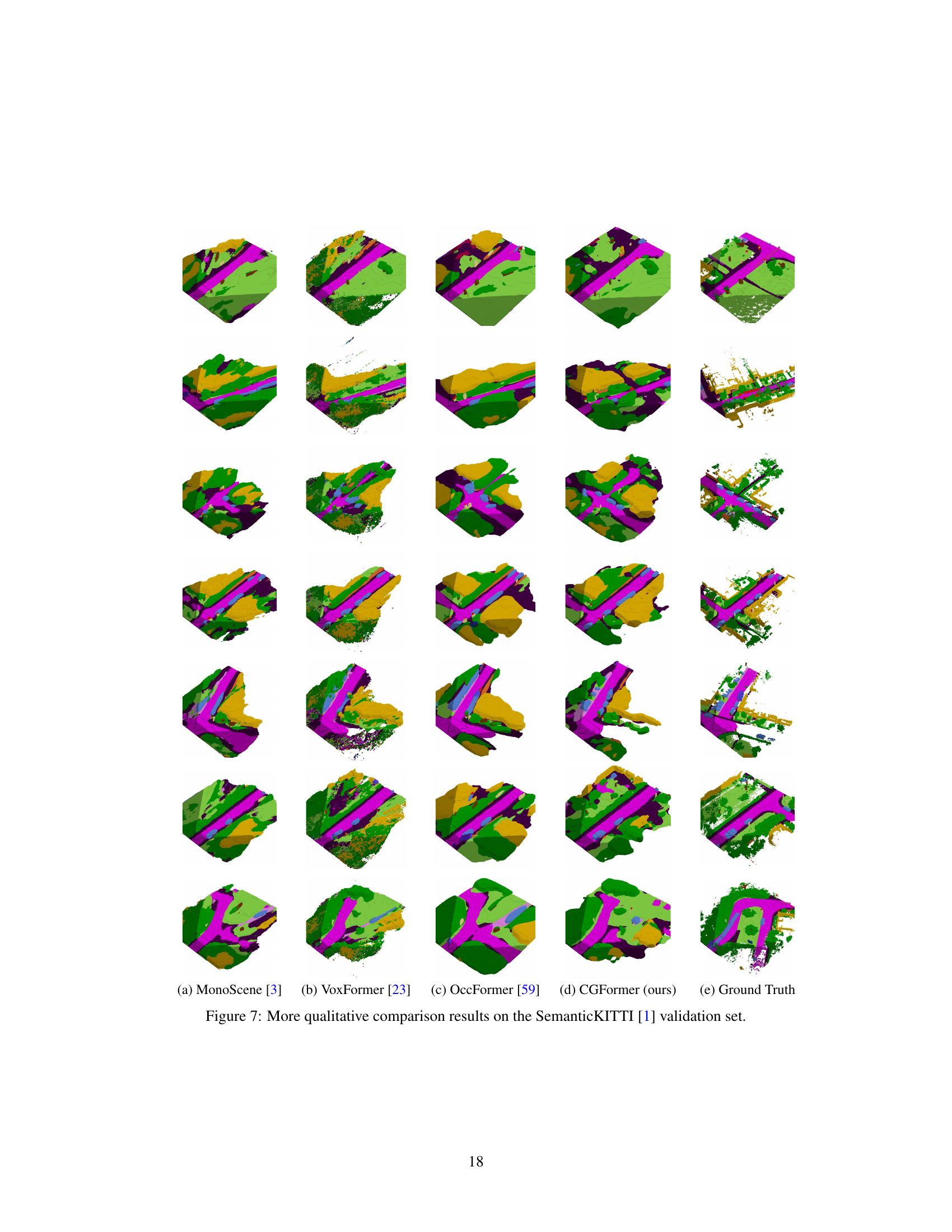
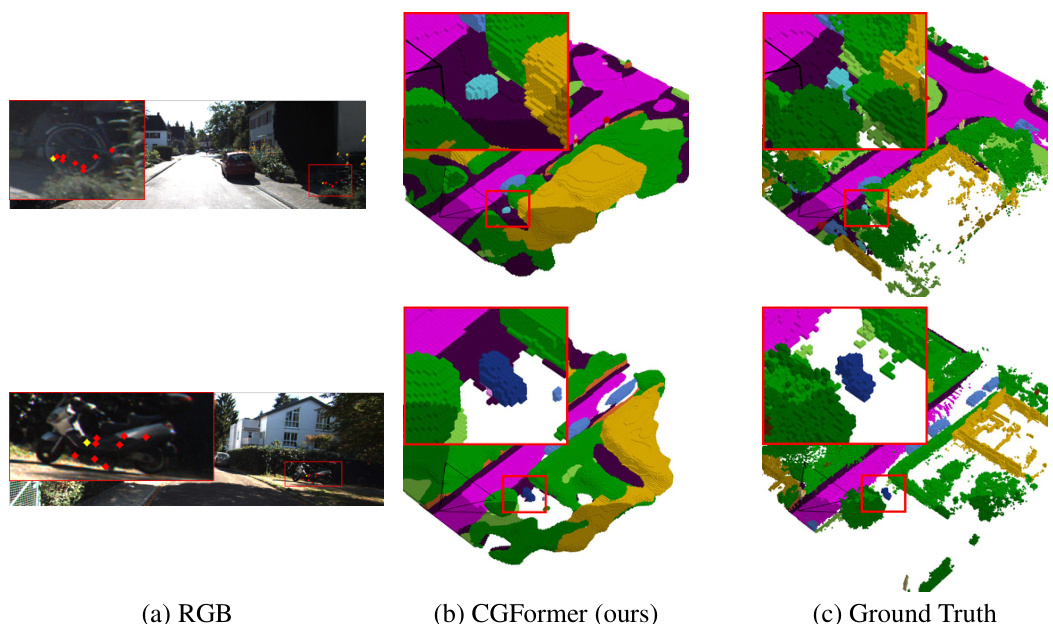
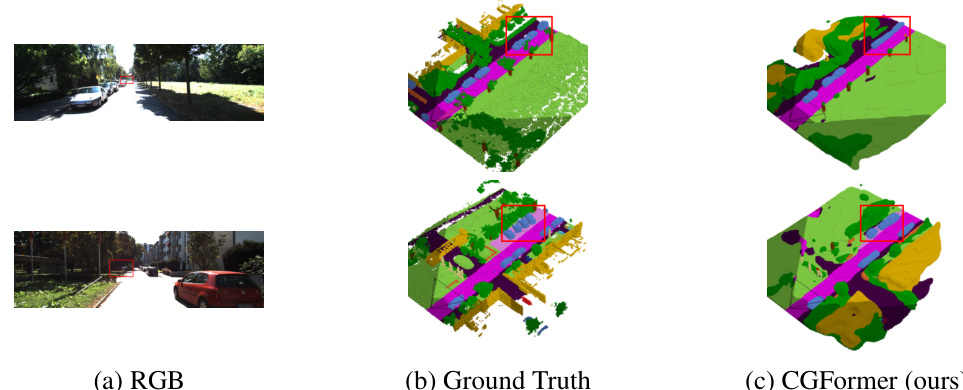
The figure qualitatively compares the scene completion results of MonoScene [3], VoxFormer [23], OccFormer [59], and CGFormer (ours) on the SemanticKITTI validation set. Each row shows a different scene, with the input RGB image and the predicted semantic scene completion from each method, alongside the ground truth. The red boxes highlight areas where the methods differ significantly, illustrating CGFormer’s improved accuracy and detail in semantic prediction, especially regarding the clearer depiction of geometric structures and smaller objects compared to the other methods.
This figure shows the overall architecture of CGFormer, a novel neural network for semantic scene completion. It illustrates the four main parts of the network: feature extraction from 2D images, view transformation (lifting 2D features to 3D volumes using CGVT), 3D local and global encoding (enhancing 3D features using LGE), and a decoding head for semantic occupancy prediction. Sub-figures (b) and (c) provide detailed breakdowns of the CGVT and Depth Net components, respectively.
This figure visualizes how the proposed context-aware query generator in CGFormer effectively focuses on the region of interest when aggregating features. It compares the sampling points of context-independent queries (like in VoxFormer) against the context-dependent queries in CGFormer, highlighting the improved feature aggregation and performance due to the focus on relevant areas.

This figure shows a qualitative comparison of semantic scene completion results on the SemanticKITTI validation set. It compares the output of four different methods: MonoScene [3], VoxFormer [23], OccFormer [59], and the proposed CGFormer, against the ground truth. Each row represents a different scene, and each column represents the output from a different method. The figure visually demonstrates the strengths and weaknesses of each method in terms of accuracy, detail, and overall scene understanding. CGFormer aims to outperform other methods by providing clearer geometric structures and improved semantic discrimination.

This figure visualizes how the context-aware query generator in CGFormer focuses the attention on the region of interest. It compares the sampling locations of context-independent queries (as used in previous methods) with the context-dependent queries introduced by CGFormer. The context-dependent queries’ sampling points are concentrated in the relevant areas, leading to improved feature aggregation and better performance in semantic scene completion.
More on tables

This ablation study analyzes the impact of different context-aware query generator designs on the model’s performance. It compares a model without a context-aware query generator, a model with more attention layers, a model using the FLOSP module, and a model using voxel pooling. The results show the impact of the choice of context-aware query generator on IoU and mIoU metrics, as well as model parameters and memory usage.
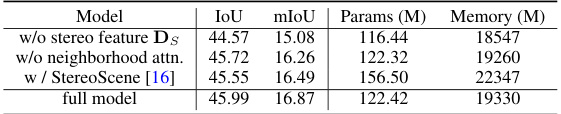
This table presents the ablation study on the depth refinement block. It compares the performance of the model with and without different components of the depth refinement block, including removing the stereo feature, removing the neighborhood attention, replacing with StereoScene [16], and the full model. The results show that each component contributes to the improvement of the accuracy.

This table presents an ablation study on the impact of using different backbone networks on the performance of CGFormer. It compares the results obtained using EfficientNetB7 with Swin Block, ResNet50 with Swin Block, and ResNet50 with ResBlock. The table shows that while using lighter backbone networks reduces parameters and training memory, the performance (IoU and mIoU) remains relatively stable.
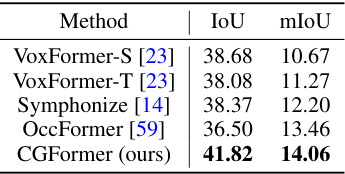
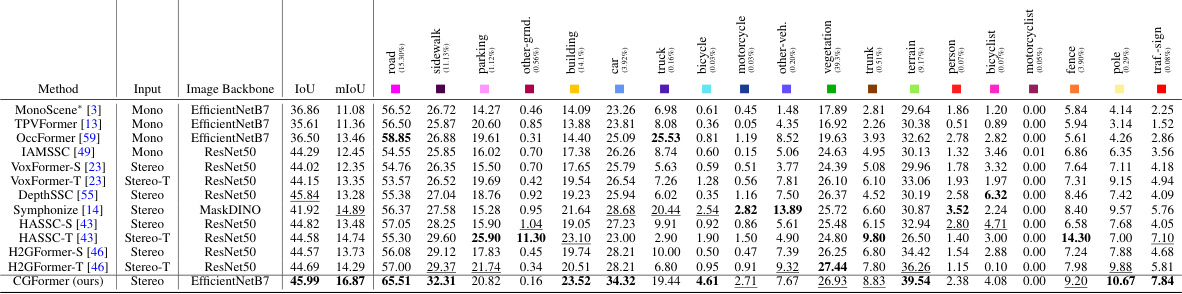
This table compares the performance of several semantic scene completion methods when only using monocular RGB images as input. The methods compared include VoxFormer-S, VoxFormer-T, Symphonize, OccFormer, and the authors’ proposed CGFormer. For fair comparison, stereo-based methods (those using depth information) replace their original depth estimation network (MobileStereoNet) with Adabins to ensure a consistent monocular input setting. The table shows that CGFormer achieves the best results in terms of both IoU and mIoU metrics, indicating improved performance on semantic scene completion when leveraging only monocular information.

This table compares the training memory and inference time of CGFormer with other state-of-the-art (SOTA) methods on the SemanticKITTI test set. The metrics were measured using an NVIDIA 4090 GPU. The table provides a quantitative comparison of resource usage and computational efficiency.

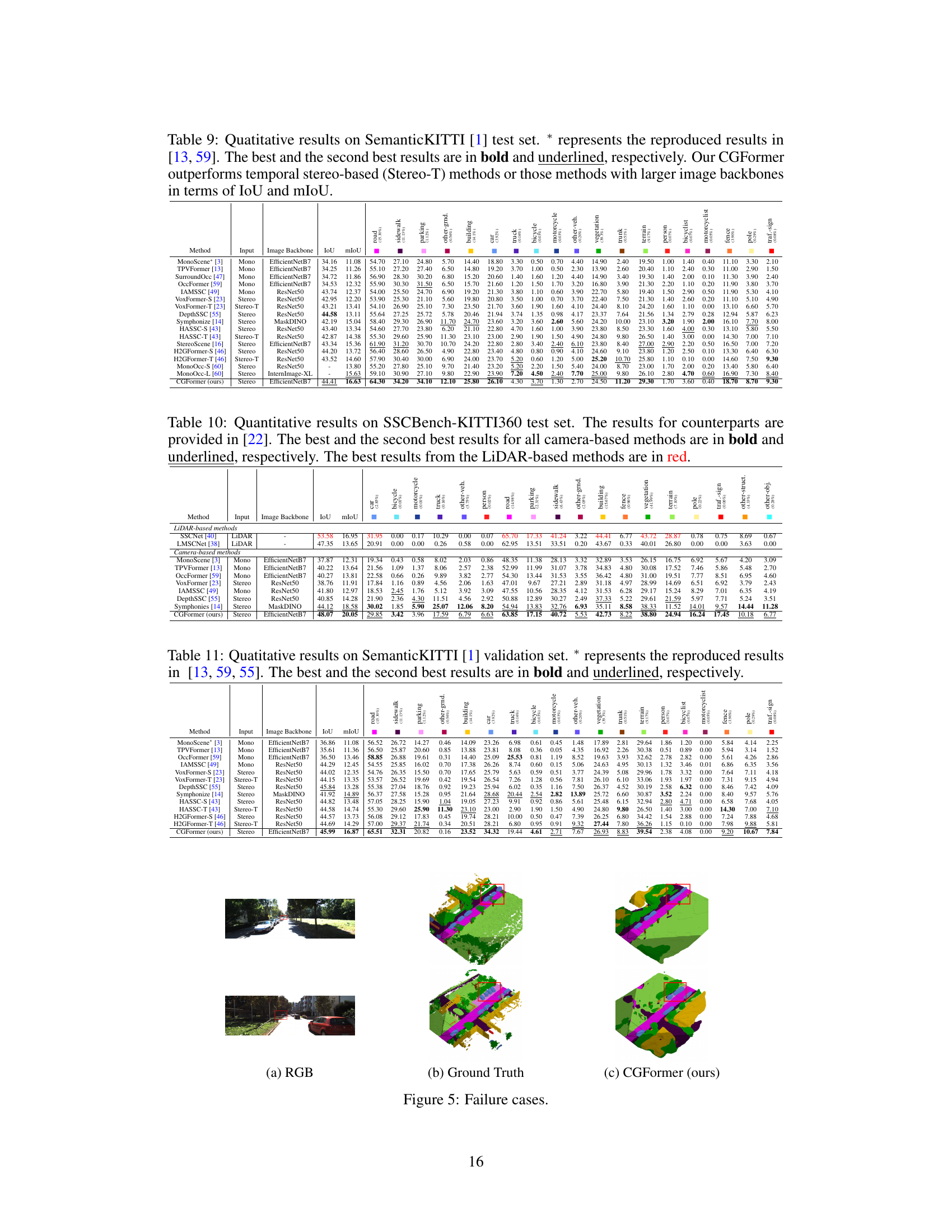
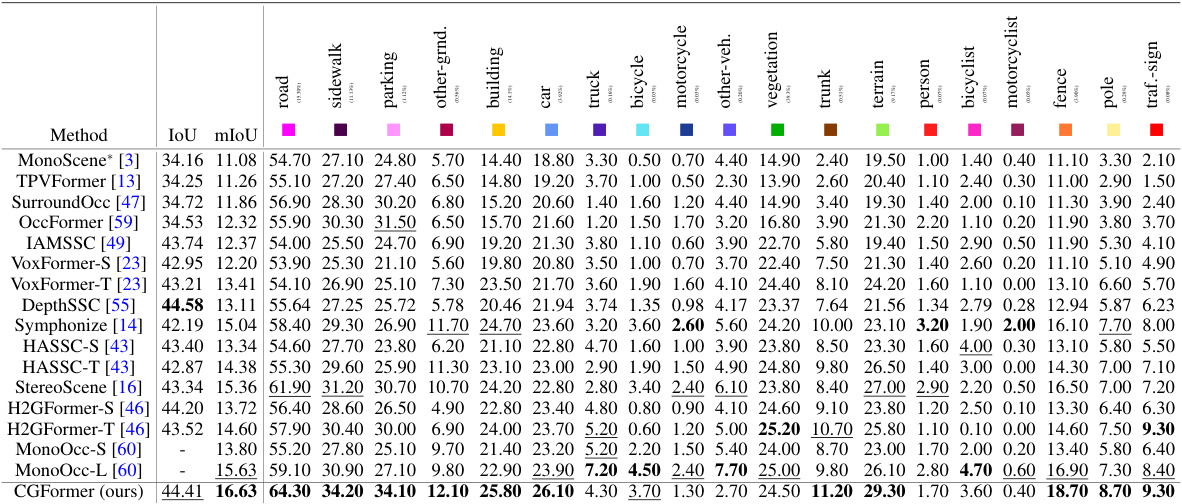
This table presents quantitative results on the SemanticKITTI test set, comparing the performance of CGFormer against other state-of-the-art methods. The results are measured using the Intersection over Union (IoU) metric for each of the 20 semantic classes present in the dataset, along with the mean IoU (mIoU). The best and second-best results for each class are highlighted. The asterisk (*) indicates that some results are reproduced from other publications.
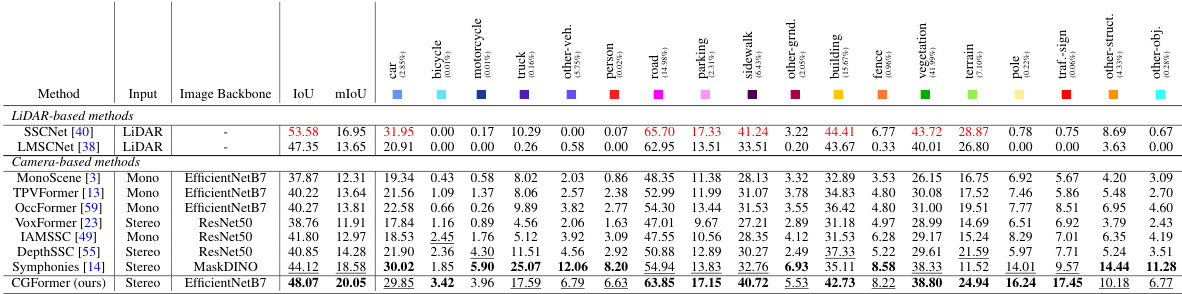
This table presents quantitative results of the proposed CGFormer model and other state-of-the-art methods on the SemanticKITTI test set. The results are evaluated using Intersection over Union (IoU) and mean IoU (mIoU) metrics for 19 semantic classes and one free class. The best and second-best results for each class are highlighted, showcasing CGFormer’s performance compared to other methods.
Full paper#