↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Traditional motion deblurring methods often fail in real-world scenarios due to their reliance on large, synthetic datasets which do not reflect real-world conditions. Spike cameras, which capture high-temporal resolution data, offer a promising solution but existing spike-based methods also rely on supervised learning paradigms. This leads to significant performance degradation when applied to real-world scenarios due to data distribution discrepancies.
The paper introduces SpikeReveal (S-SDM), a novel self-supervised framework that leverages the theoretical relationship between blurry images, spike streams and their corresponding sharp images. It consists of a spike-guided deblurring model, a cascaded framework to handle spike noise and resolution mismatches, and a lightweight deblurring network trained using knowledge distillation. Experiments on both synthetic and a new real-world dataset (RSB) show the superior generalization and performance of the proposed self-supervised framework compared to existing supervised methods.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes the first self-supervised framework for spike-guided motion deblurring, addressing the limitations of existing supervised methods that struggle with real-world data. This opens new avenues for research in low-light/high-speed imaging and neuromorphic computing, potentially leading to advancements in robotics, autonomous driving, and other applications requiring robust motion deblurring in challenging conditions.
Visual Insights#
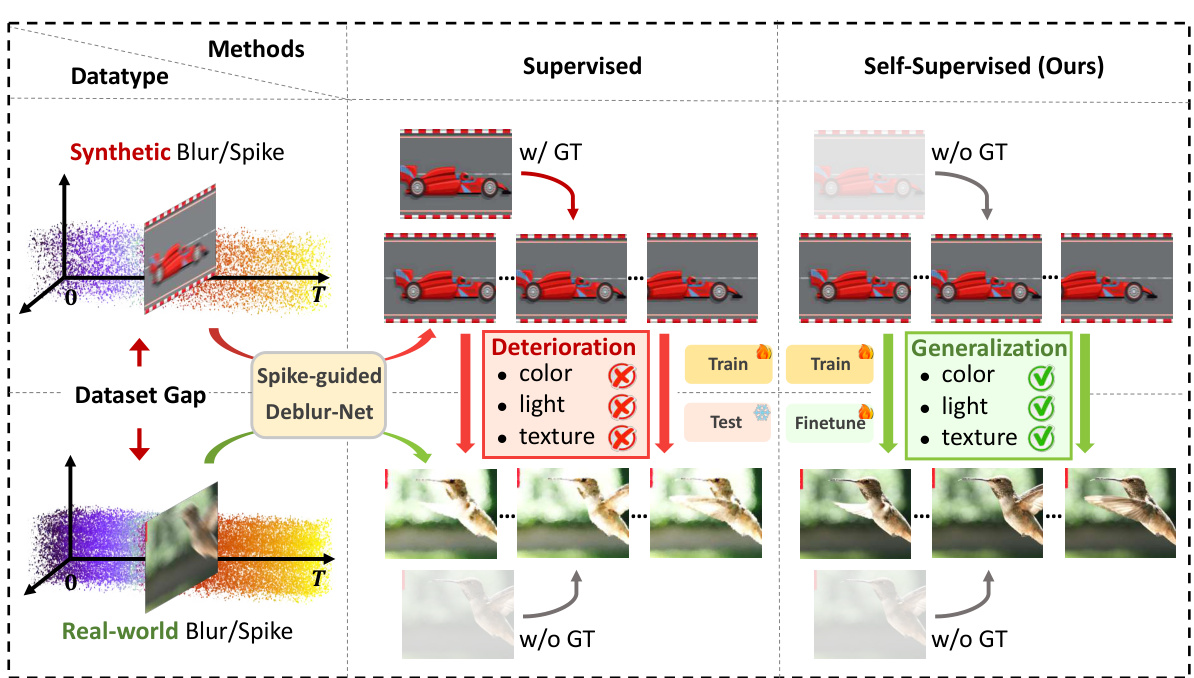
This figure compares supervised and self-supervised methods for spike-guided motion deblurring. It highlights the limitation of supervised learning, which performs well on synthetic data but poorly generalizes to real-world scenarios due to distribution shifts. The self-supervised method (S-SDM), in contrast, leverages a self-supervised training strategy to overcome this limitation, showing successful generalization on real-world data after fine-tuning.
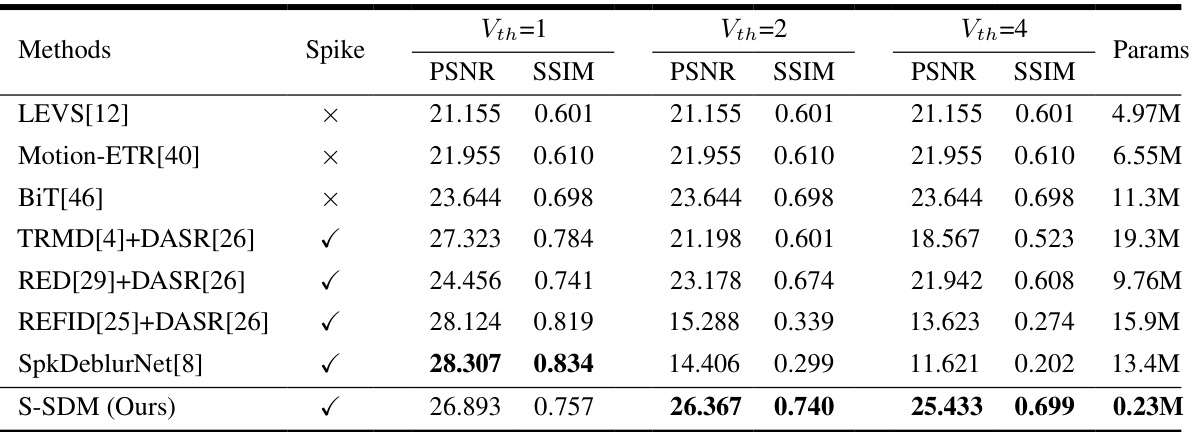
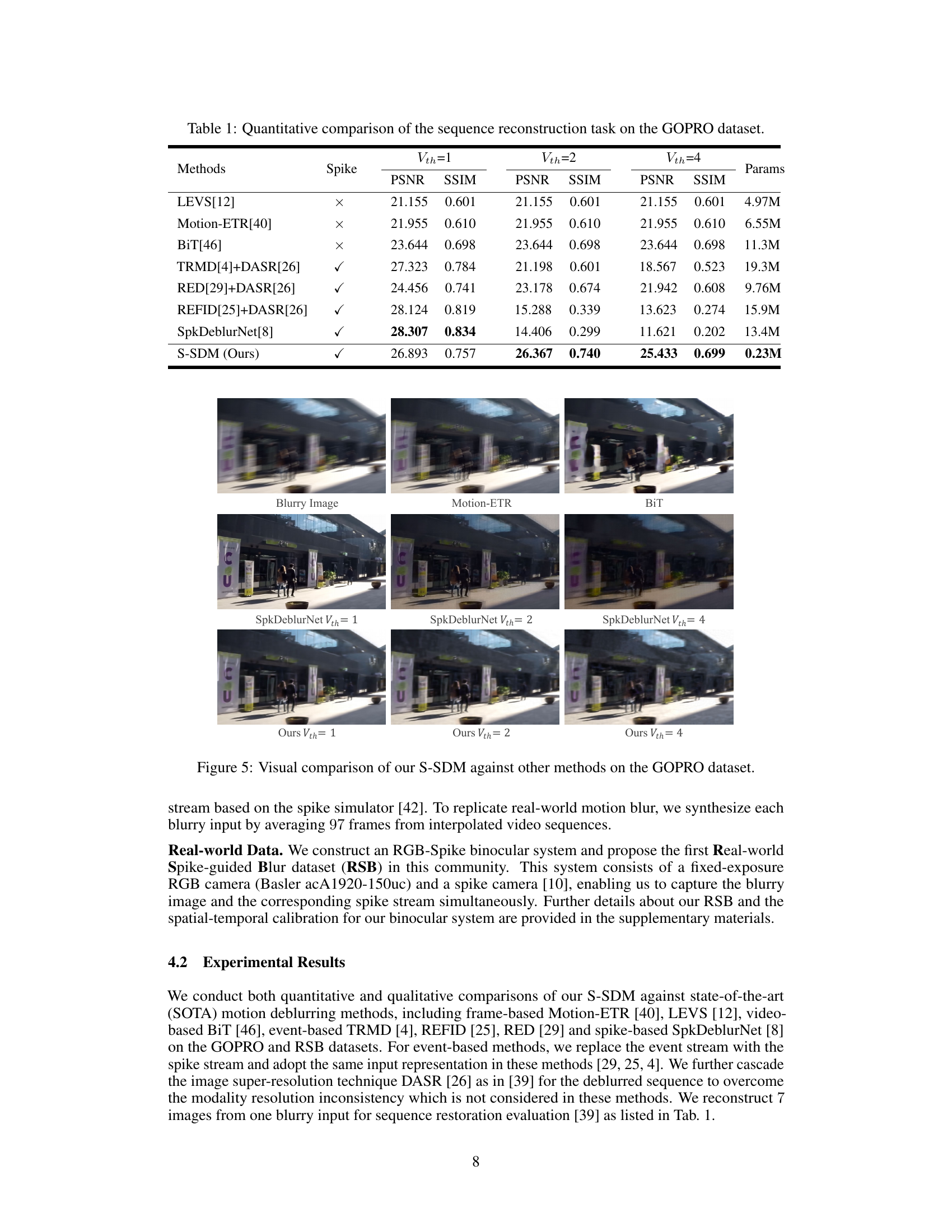
This table presents a quantitative comparison of different methods for sequence reconstruction on the GOPRO dataset. It shows the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) for various methods under different spike thresholds (Vth = 1, 2, 4). The ‘Spike’ column indicates whether the method uses spike information. The ‘Params’ column shows the number of parameters for each method. The results highlight the performance of different deblurring approaches using both conventional and spike-based methods, showing the impact of spike data availability on reconstruction quality.
In-depth insights#
Spike-based Deblurring#
Spike-based deblurring leverages the unique temporal resolution of neuromorphic spike cameras to address limitations of traditional deblurring methods. Spike cameras capture motion information with high temporal precision, providing temporal features that are often lost in traditional blurry images. This information is crucial for disambiguating multiple motion trajectories and enhancing accuracy, especially in dynamic scenes. Existing approaches often rely on supervised learning, which suffers from performance degradation when applied to real-world data. Self-supervised methods offer a promising path to improve robustness and generalizability by eliminating the need for extensive paired data. The core challenge lies in effectively integrating the sparse spatiotemporal information from spike streams with the blurry input for deblurring. Theoretical analysis plays a vital role in establishing theoretical relationships among spikes, blurry images, and their corresponding sharp sequences, which allows for the creation of more effective self-supervised frameworks. A key area of future research is developing innovative self-supervised techniques that effectively handle the challenges posed by noise, resolution mismatch, and data heterogeneity intrinsic to spike data, ultimately paving the way for reliable and high-quality motion deblurring in various real-world applications.
Self-Supervised Learning#
Self-supervised learning is a crucial paradigm shift in machine learning, particularly relevant for scenarios with limited labeled data. It leverages the inherent structure and properties of unlabeled data to create training signals, thereby reducing reliance on expensive and time-consuming human annotation. This is especially valuable in domains like image and video processing, where acquiring large labeled datasets is challenging. The paper’s focus on self-supervised learning for spike-guided motion deblurring highlights the power of this approach to tackle complex, real-world problems. By formulating a model that explores the theoretical relationships between spike streams, blurry images, and their sharp counterparts, the authors sidestep the limitations of traditional supervised methods that struggle with real-world data variability. The success of the proposed self-supervised framework demonstrates the effectiveness of this approach in bridging the gap between synthetic training data and the complexities of real-world scenarios. This paradigm facilitates superior generalization capabilities and potentially unlocks innovative solutions across various domains, opening new avenues for research and development.
Real-world Datasets#
The inclusion of real-world datasets is critical for evaluating the generalizability and robustness of any motion deblurring model. Synthetic datasets, while useful for initial model training and controlled experiments, often fail to capture the complexity and variability inherent in real-world scenes. Real-world data is likely to contain noise, artifacts, and unforeseen variations in lighting, motion blur characteristics, and object appearance. Therefore, a model’s performance on real-world datasets provides a more reliable indicator of its practical value compared to its performance on synthetic data alone. The creation of a real-world dataset, however, presents significant challenges: acquisition of high-speed video and corresponding spike data is costly and technically demanding, requiring specialized equipment and careful synchronization. Furthermore, meticulously annotating real-world data is a significant undertaking. The characteristics of the real-world data used – the diversity of scenarios, the types of motion blur present, and the quality of data – directly impact the analysis. A well-designed real-world dataset will allow a more thorough assessment of model capabilities, leading to more accurate conclusions about the method’s potential for real-world applications.
Computational Efficiency#
A crucial aspect to consider in any machine learning model, especially those dealing with complex tasks like video deblurring, is computational efficiency. The SpikeReveal framework, while demonstrating superior performance, needs a thorough analysis of its computational demands. Factors such as the depth and complexity of the neural networks (Spike-guided Deblurring Model, Denoising Network, Super-Resolution Network, Lightweight Deblurring Network), the number of training iterations, and the size of the input data directly impact computational cost. Optimization techniques used during the design and training phase significantly influence efficiency. For real-time applications, this is paramount. Model compression techniques (e.g., knowledge distillation), which are employed in this paper, and exploring the use of efficient network architectures or hardware acceleration would be important areas of future work to ensure practicality. The self-supervised nature, while offering generalization benefits, requires investigating the computational overhead compared to a supervised approach. A detailed breakdown of FLOPS, training time, and inference time across different hardware would be a substantial addition to enhance the understanding of SpikeReveal’s real-world applicability.
Generalization Limits#
A section titled ‘Generalization Limits’ in a research paper would critically examine the boundaries of a model’s ability to perform well on unseen data. It would likely discuss situations where the model underperforms, exploring reasons for its failure to generalize. This could involve analyzing the impact of training data characteristics, such as size, bias, and diversity, on the model’s ability to adapt to new, different inputs. The analysis would likely delve into the model architecture’s inherent limitations, perhaps highlighting aspects like capacity, expressiveness, and inductive biases that hinder successful generalization. Furthermore, the role of hyperparameters and their sensitivity to the specific training data would be a crucial point, exploring how optimal settings in one context may lead to poor performance in another. Ultimately, identifying these generalization limits is vital for improving future model design and application, allowing researchers to develop more robust and reliable AI systems.
More visual insights#
More on figures
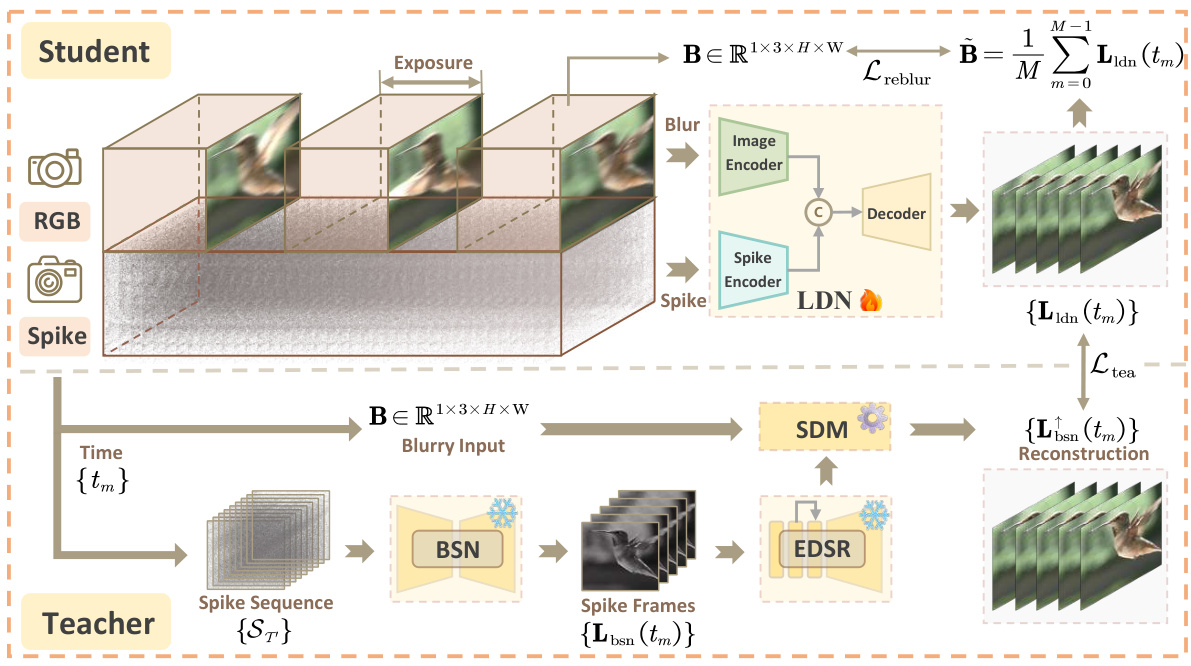
This figure illustrates the overall architecture of the proposed self-supervised framework for spike-guided motion deblurring. It shows two main pipelines: a student network and a teacher network. The teacher network consists of several components including a denoising network (BSN), a super-resolution network (EDSR), and the Spike-guided Deblurring Model (SDM). This network takes blurry images and spike streams as input and produces a sequence of sharp images. The student network, a Lightweight Deblurring Network (LDN), is trained using the results from the teacher network as pseudo labels and aims to achieve a similar performance with a more efficient architecture. The framework leverages knowledge distillation and reblur loss to achieve superior generalization performance.

This figure shows a qualitative comparison of single frame restoration results on the RSB (Real-world Spike Blur) dataset. It compares the performance of several methods, including LEVS, Motion-ETR, BiT, SpkDeblurNet, and the proposed S-SDM method. For each method, the blurry input image and the corresponding restoration are displayed. The green boxes highlight the regions of interest, showcasing the effectiveness of the restoration in terms of detail recovery, color accuracy, and overall image quality. The figure visually demonstrates the superior performance of the S-SDM model compared to others, particularly in resolving fine details and preserving color consistency.
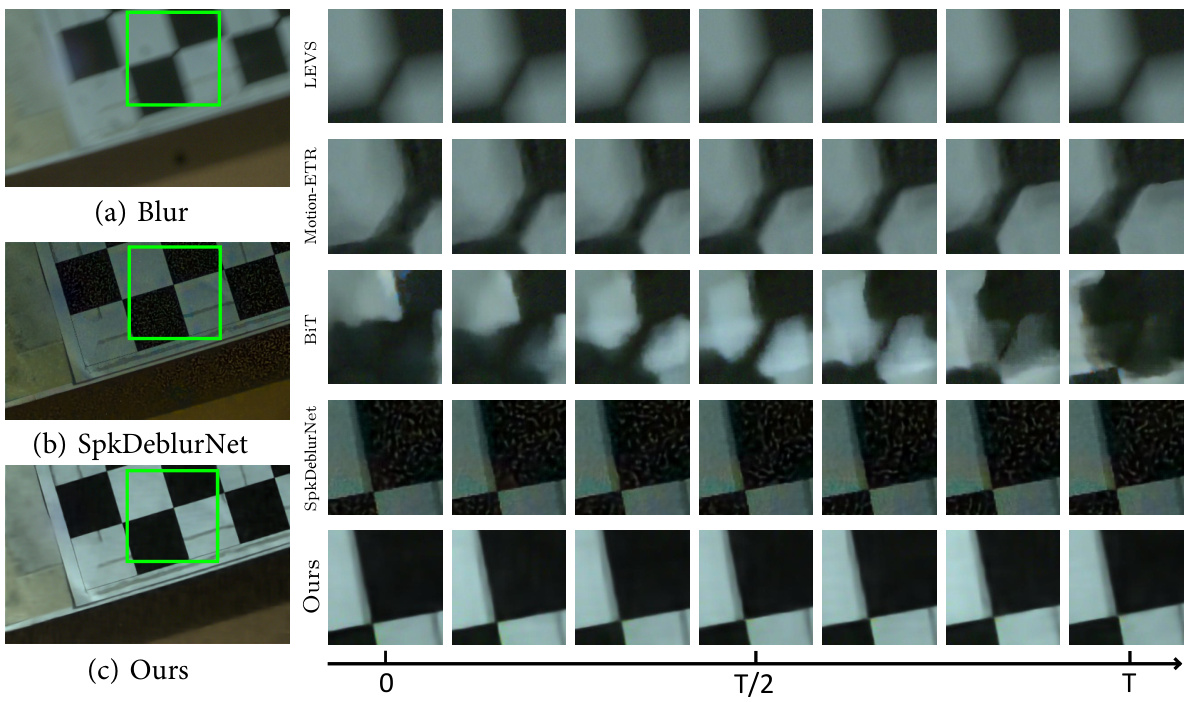
This figure shows a qualitative comparison of the sequence reconstruction results on the RSB dataset (Real-world Spike Blur dataset) for different methods: (a) Blur (original blurry input), (b) SpkDeblurNet, (c) Ours (proposed S-SDM). Each row represents a sequence of reconstructed frames from a single blurry input. The time axis is shown at the bottom of the figure. The figure visually demonstrates the superiority of the proposed S-SDM method in terms of sequence quality and detail preservation compared to the SpkDeblurNet method. The S-SDM method shows smoother and less noisy reconstructions of the sequence frames.

This figure shows a visual comparison of the proposed S-SDM method against several other state-of-the-art methods for motion deblurring on the GOPRO dataset. The comparison is made across different spike thresholds (Vth = 1, 2, 4), highlighting the performance differences under varying levels of spike noise and density. The results illustrate the effectiveness of S-SDM in producing visually sharper and more consistent results compared to other methods, particularly when dealing with higher spike thresholds (more noise).

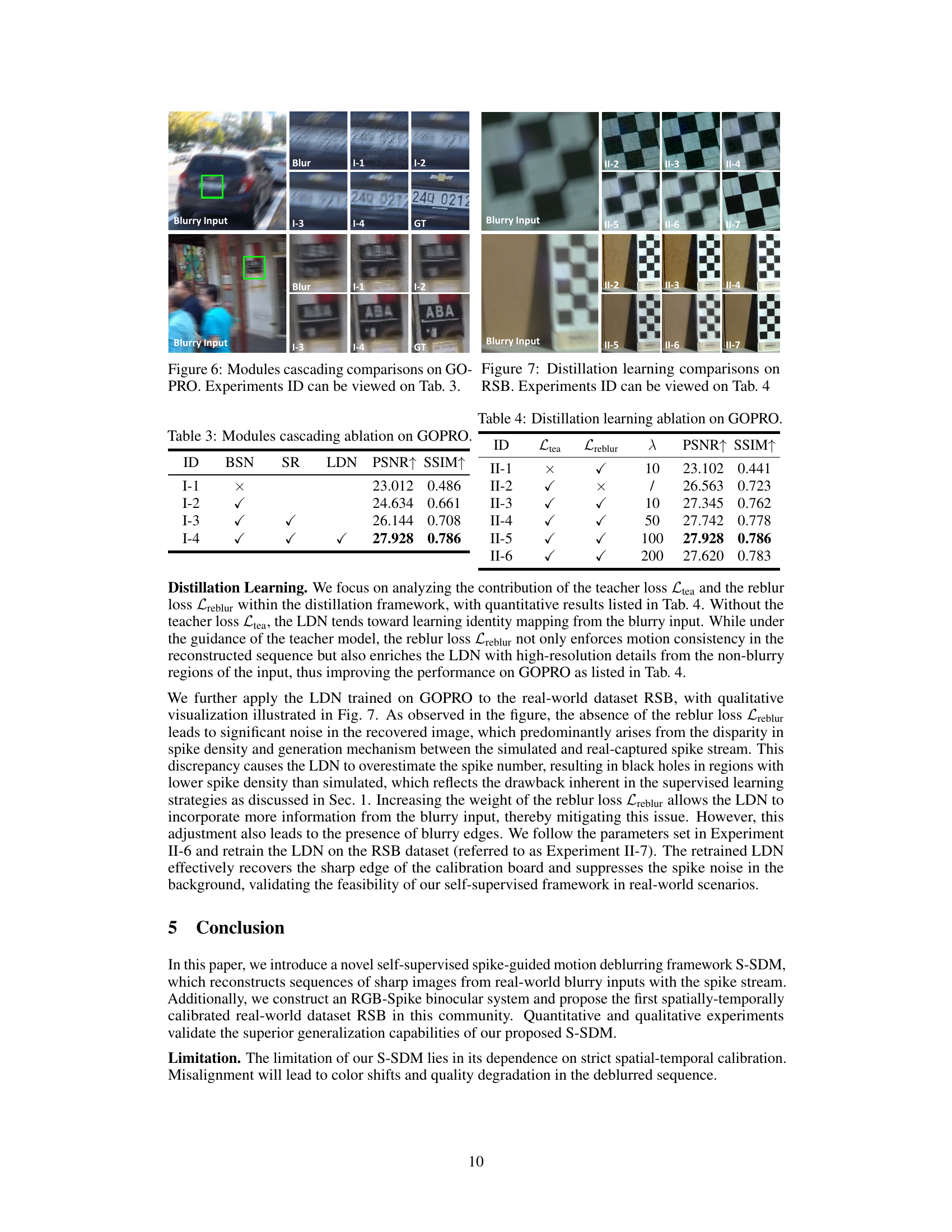
This figure shows a qualitative comparison of the results obtained by cascading different modules in the proposed self-supervised framework. It compares the results of using only the SDM (Spike-guided Deblurring Model) against those including the denoising network (BSN), super-resolution network (SR), and finally, the lightweight deblurring network (LDN). The results demonstrate the improvement in image quality and detail preservation with the addition of each module. The experiment IDs refer to a table in the paper (Table 3) providing the quantitative details of the comparisons.

This figure shows a qualitative comparison of single frame restoration results on the RSB dataset. It compares the blurry input image with results from several different methods: LEVS Motion-ETR, BiT, SpkDeblurNet, and the authors’ proposed method. Each row represents a different blurry input image and shows its restoration via the different methods, allowing for a visual comparison of the image quality achieved by each.
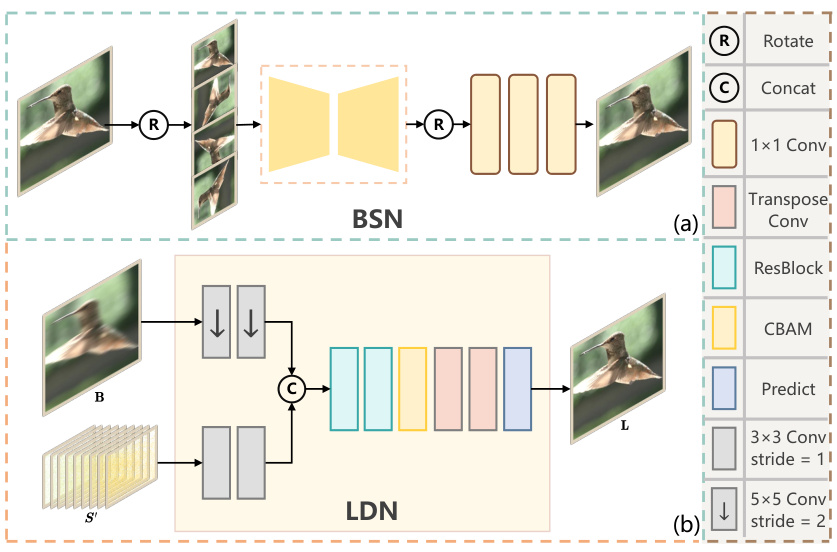
This figure shows the overall framework of the proposed self-supervised approach. It consists of two main parts: a teacher model and a student model. The teacher model uses a cascade of networks (BSN, EDSR, and SDM) to process the blurry input image and spike stream to produce a high-quality deblurred sequence. The student model (LDN) then learns to mimic the teacher’s behavior, but with a more efficient architecture. Knowledge distillation and reblur loss are used to train the student model, leading to a faster and more effective deblurring process.

This figure compares supervised and self-supervised methods for spike-guided motion deblurring. It shows that supervised methods perform well on synthetic data but poorly on real-world data due to the domain gap. In contrast, the self-supervised S-SDM method is robust to this domain gap.

This figure shows a qualitative comparison of single-frame restoration results on the RSB dataset. Different methods (LEVS, Motion-ETR, BIT, SpkDeblurNet, and the proposed method) are compared side-by-side for five different scenes (Board-L, Board-M, Board-H, Face, and Earphone) under varying lighting conditions. The goal is to visually demonstrate the performance of each method in recovering sharp details from blurry images. The differences in color accuracy, noise reduction, and overall sharpness are evident in the comparison.

This figure compares the single-frame restoration results of different methods on the RSB dataset under various lighting conditions. The methods compared include LEVS, Motion-ETR, BiT, SpkDeblurNet, and the proposed method. The comparison highlights the ability of each method to accurately restore details and color under different lighting.

This figure compares the performance of the proposed self-supervised spike-guided deblurring model (S-SDM) against other state-of-the-art methods on the GOPRO dataset. The comparison is shown for three different spike thresholds (Vth = 1, 2, 4). The results highlight the superior generalization ability of S-SDM, particularly under varied conditions of spike density. It showcases how S-SDM maintains a high level of performance across different spike thresholds, unlike other methods which show considerable performance degradation when the spike density changes.

This figure shows a qualitative comparison of the proposed S-SDM method against other state-of-the-art methods for motion deblurring on the GOPRO dataset. Different spike thresholds (Vth = 1, 2, 4) were used to simulate varying spike densities. The results demonstrate the superior performance of S-SDM in recovering sharp, high-quality images, particularly when dealing with varying levels of spike noise, compared to other methods such as Motion-ETR, BiT, and SpkDeblurNet.

This figure presents a qualitative comparison of single-frame restoration results on the RSB (Real-world Spike Blur) dataset. It compares the performance of the proposed method (Ours) against three other methods: Blur (the original blurry image), LEVS Motion-ETR, and SpkDeblurNet. The figure shows that the proposed method produces visually superior results in terms of sharpness, color accuracy, and overall detail preservation compared to the alternative approaches, particularly in capturing fine details of real-world scenes.

This figure compares the performance of supervised and self-supervised methods for spike-guided motion deblurring. Supervised methods perform well on synthetic data but poorly generalize to real-world data due to domain mismatch. The self-supervised method (S-SDM) consistently performs better across both datasets by eliminating the need for ground truth in training.
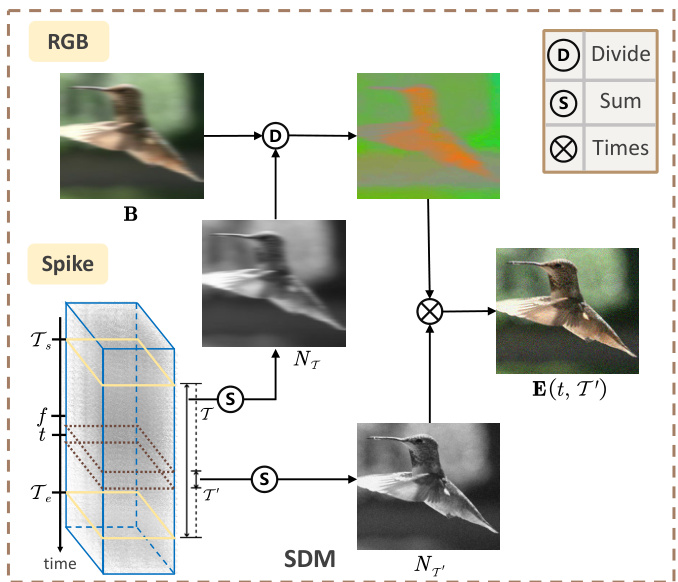
This figure illustrates the proposed self-supervised framework for spike-guided motion deblurring. It shows a teacher-student model setup. The teacher model uses a cascade of networks including a Blind Spot Network (BSN), Super Resolution Network (SR), and Spike-guided Deblurring Model (SDM). The output of the teacher is used to generate pseudo-labels to train a lightweight deblurring network (LDN), which acts as the student. The LDN learns to directly map blurry input and spike streams to sharp images, enabling faster and more efficient deblurring.
More on tables

This table presents a quantitative comparison of the performance of the Scale-aware Network (SAN) used in the GEM model [39] and the Lightweight Deblurring Network (LDN) proposed by the authors. The comparison focuses on the PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), the number of parameters (Params), and the number of floating-point operations (Flops) for both networks. The results show that the authors’ LDN achieves higher PSNR and SSIM scores with significantly fewer parameters and FLOPs, demonstrating its superior efficiency.

This table presents a quantitative comparison of different methods for sequence reconstruction on the GOPRO dataset. It compares various methods (LEVS, Motion-ETR, BiT, TRMD+DASR, RED+DASR, REFID+DASR, SpkDeblurNet, and the proposed S-SDM) across three different spike thresholds (Vth=1, Vth=2, Vth=4). For each method and threshold, the table provides the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and the number of parameters (Params) used. The inclusion of spike data (indicated by a checkmark) and the number of parameters highlight the efficiency and effectiveness of different methods.

This table presents a quantitative comparison of single-frame image restoration results on the RSB (Real-world Spike Blur) dataset. Five different methods are compared: LEVS [12], Motion-ETR [40], BiT [46], SpkDeblurNet [8], and the proposed S-SDM. The evaluation metric used is LIQE (Language-Image Quality Evaluator), which ranges from 1 to 5, with higher scores indicating better quality. The table shows the LIQE scores for each method across five different image categories within the RSB dataset (Board-L, Board-M, Board-H, Face, and Earphone), along with an average LIQE score across all categories.
Full paper#