↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Most machine learning models struggle with out-of-distribution (OOD) data – data that differs significantly from the training data. Existing research primarily focuses on unimodal data (e.g., images), ignoring the complexity of real-world multimodal scenarios. This limits the robustness and safety of AI systems in critical applications.
The paper addresses this by introducing MultiOOD, the first benchmark for multimodal OOD detection. It highlights the importance of using multiple data types (modalities) for better OOD detection. It then proposes two new methods: the Agree-to-Disagree (A2D) algorithm, which encourages differences in predictions across different modalities for OOD data, and NP-Mix, a novel outlier synthesis technique. These methods significantly improve the performance of existing OOD detection algorithms, demonstrating the effectiveness of a multimodal approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and related fields because it introduces the first-of-its-kind benchmark for multimodal out-of-distribution (OOD) detection, addressing the limitations of existing unimodal benchmarks. It also proposes novel algorithms (A2D and NP-Mix) that significantly improve OOD detection performance, opening new avenues for research in more realistic and robust AI systems.
Visual Insights#
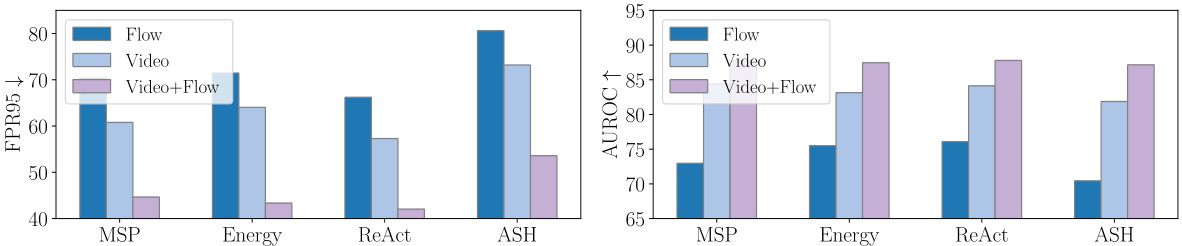
This figure displays the False Positive Rate at 95% true positive rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for different unimodal and multimodal out-of-distribution (OOD) detection methods on the HMDB51 dataset. It demonstrates that using multiple modalities (e.g., video and optical flow) significantly improves OOD detection performance compared to using only a single modality.
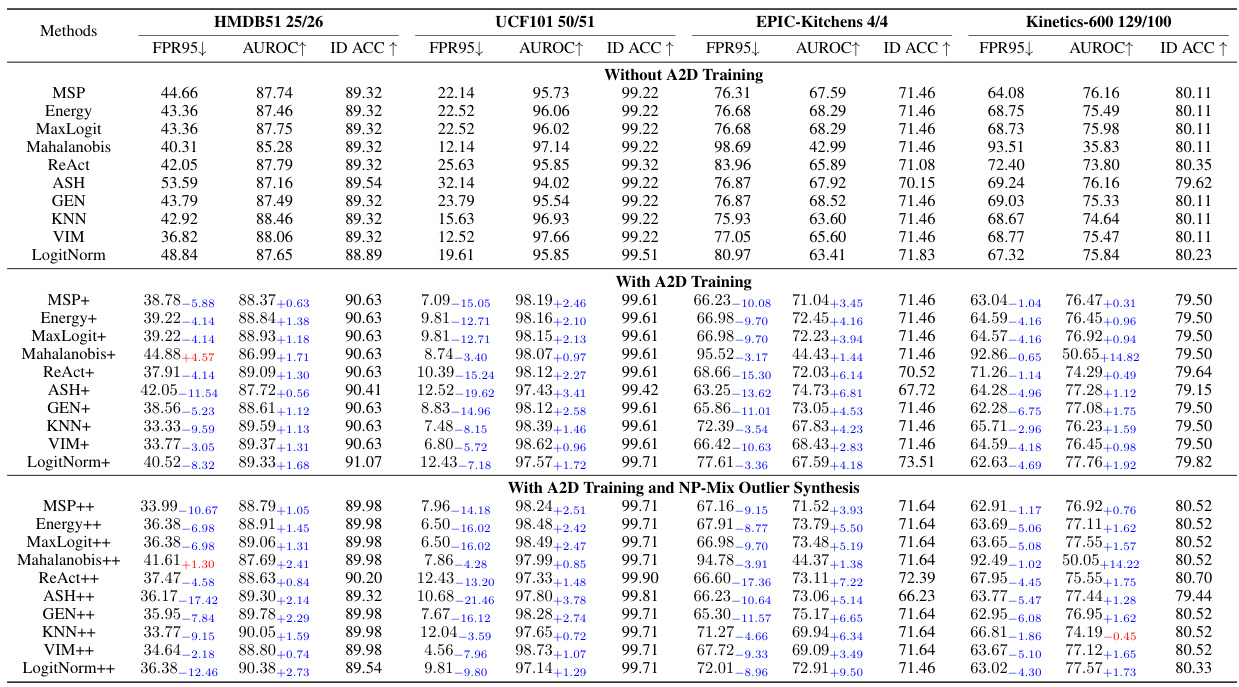
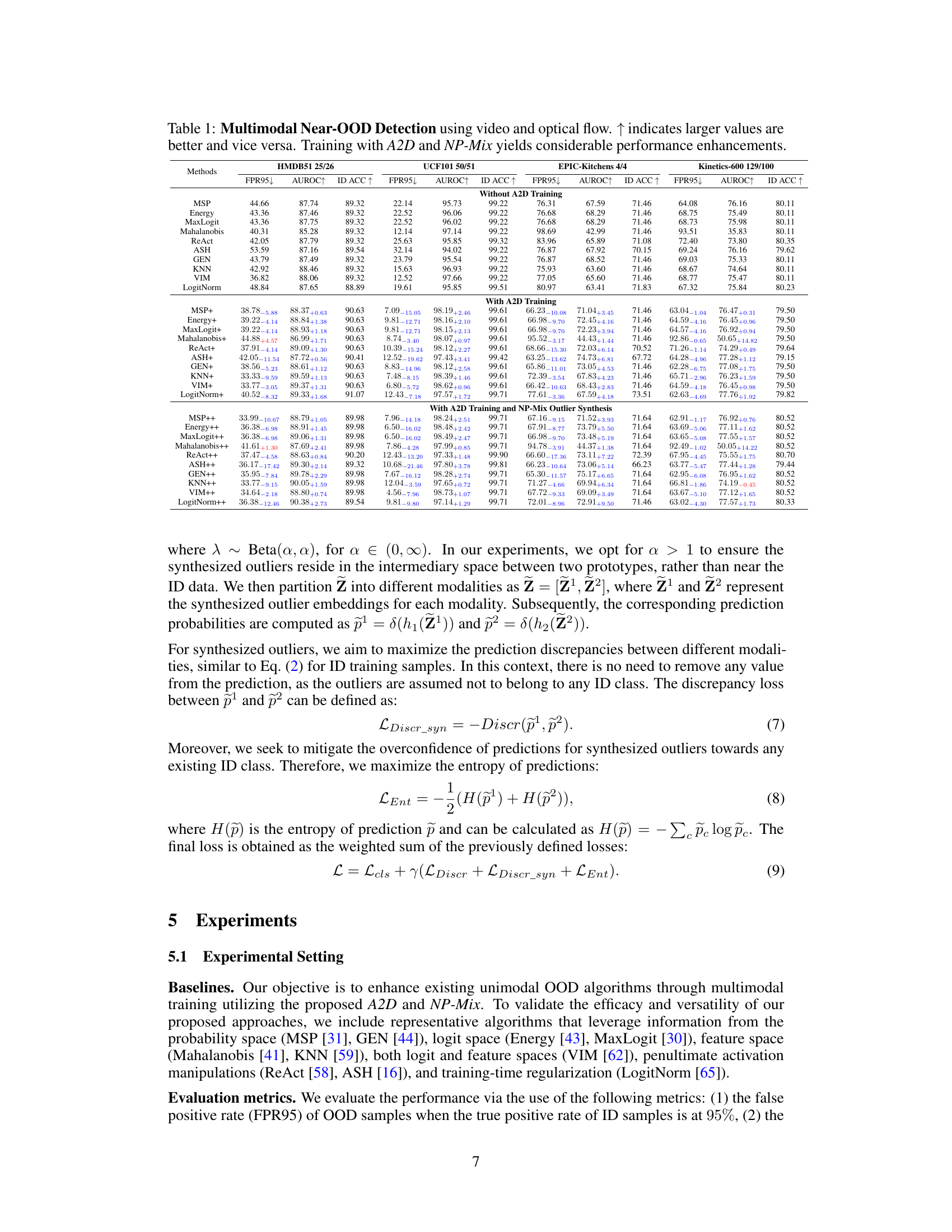
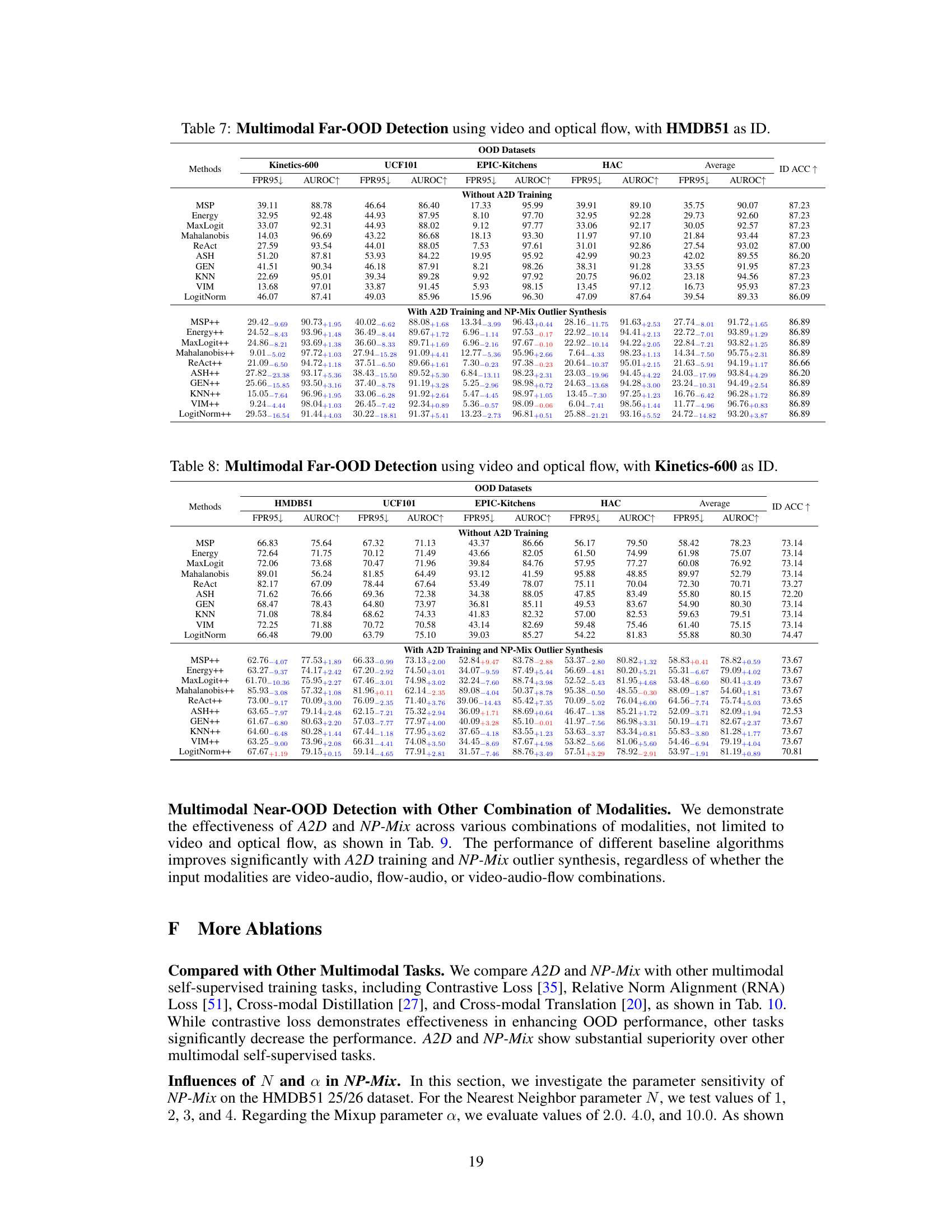
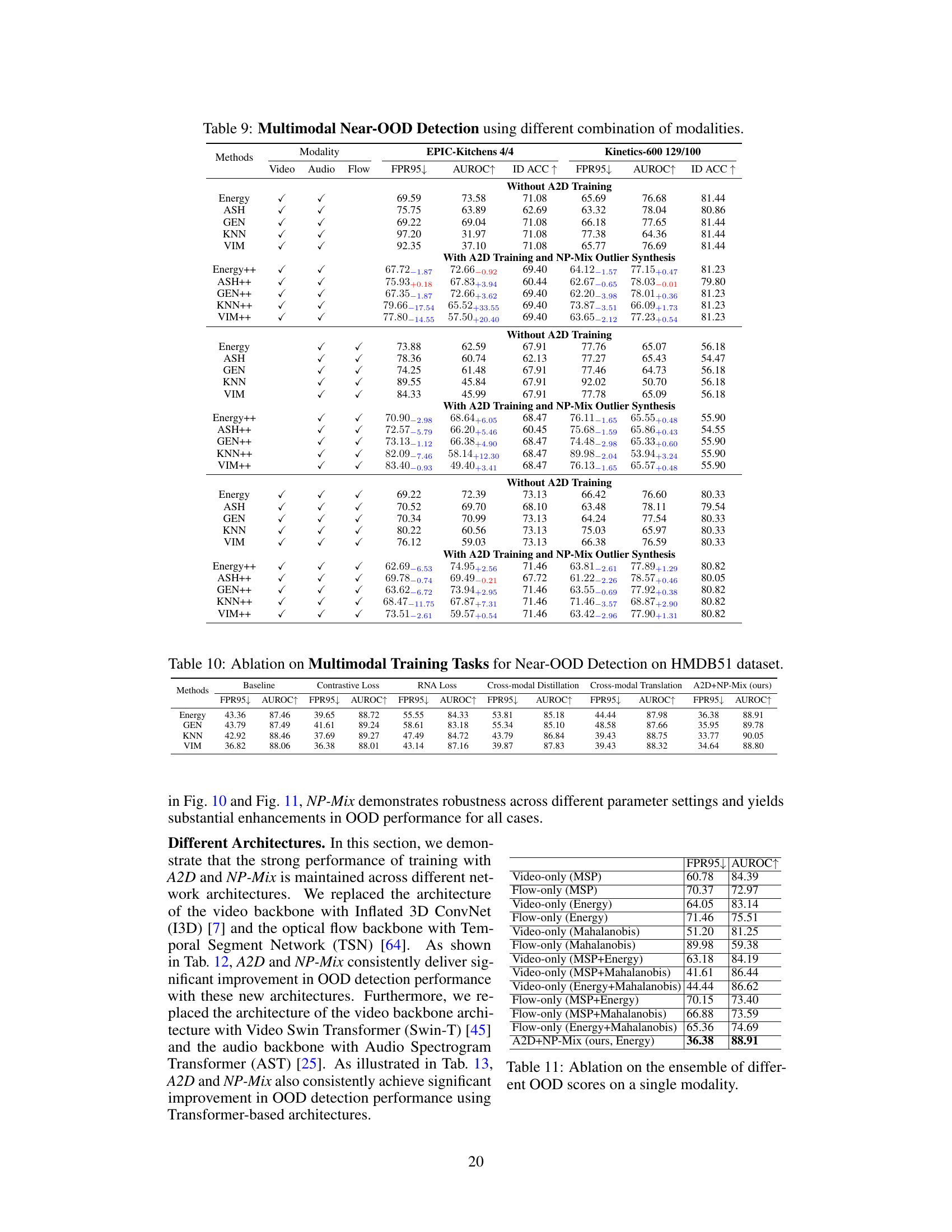
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100). It compares the performance of several baseline OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under three training conditions: without A2D training, with A2D training, and with both A2D training and NP-Mix outlier synthesis. The metrics used to evaluate performance are the false positive rate at 95% true positive rate (FPR95), area under the receiver operating characteristic curve (AUROC), and in-distribution accuracy (ID ACC). The table shows the improvements achieved by incorporating the proposed A2D and NP-Mix techniques into the training process.
In-depth insights#
Multimodal OOD#
Multimodal out-of-distribution (OOD) detection is a crucial area of machine learning research, focusing on enhancing the robustness of models in real-world scenarios. Unlike unimodal approaches that rely on a single data modality (e.g., images), multimodal OOD detection leverages information from multiple sources (e.g., images, text, audio) to improve accuracy and reliability. A key challenge lies in effectively integrating information across different modalities, requiring sophisticated algorithms to handle the complexities of diverse data types and their interdependencies. Multimodal benchmarks are vital for evaluating the performance of such algorithms and identifying areas needing further improvement. The development of effective multimodal OOD detection methods is critical for building safe and reliable AI systems, with significant implications for applications like autonomous driving and medical diagnosis.
A2D Algorithm#
The Agree-to-Disagree (A2D) algorithm, a core contribution of the paper, addresses the problem of modality prediction discrepancy in multimodal out-of-distribution (OOD) detection. It leverages the observation that, while in-distribution (ID) data results in consistent predictions across different modalities, OOD data leads to significant discrepancies. A2D directly encourages this discrepancy during training by enforcing agreement on ground-truth class predictions, while maximizing disagreement on other classes. This approach is designed to enhance the model’s ability to distinguish between ID and OOD samples by amplifying the inherent differences in how various modalities handle OOD data. The effectiveness of A2D is demonstrated by significant improvements in OOD detection metrics compared to baselines, showcasing its value as a novel training strategy for improving the robustness and reliability of multimodal machine learning models in open-world settings. Its success lies in its ability to explicitly leverage the complementary nature of multiple data modalities to improve OOD detection.
NP-Mix Outlier#
The proposed NP-Mix outlier synthesis method addresses limitations of existing outlier generation techniques by exploring broader feature spaces. Instead of creating outliers solely near in-distribution data, NP-Mix leverages nearest neighbor classes. This approach ensures the synthesized outliers capture more diverse characteristics and semantic shifts, ultimately improving the model’s ability to distinguish between in-distribution and out-of-distribution samples. The combination of NP-Mix with the Agree-to-Disagree (A2D) algorithm is particularly effective, enhancing the performance of existing out-of-distribution detection algorithms substantially. By expanding feature space and increasing the discrepancy between modalities on out-of-distribution samples, NP-Mix plays a crucial role in strengthening the robustness of the overall multimodal OOD detection framework. This novel synthesis strategy is a key contribution, offering a more comprehensive and effective approach compared to existing methods.
Benchmarking#
The benchmarking section of a research paper is crucial for establishing the significance and impact of the presented work. A robust benchmark should be carefully designed, including a selection of relevant and diverse datasets that are representative of real-world scenarios. The selection process should be transparent and well-justified, and the methodology used to evaluate the performance of different algorithms on the benchmark should be clearly explained and rigorous. Metrics selected should also be carefully chosen to reflect the key aspects of the problem, and the results should be presented in a clear and comprehensive manner, enabling readers to understand both the strengths and weaknesses of different approaches. Reproducibility is paramount; sufficient details about the experimental setup and data should be provided to allow others to replicate the findings. Finally, a strong benchmark serves as a foundation for future research, enabling researchers to build upon existing work and to develop more advanced and effective algorithms.
Future works#
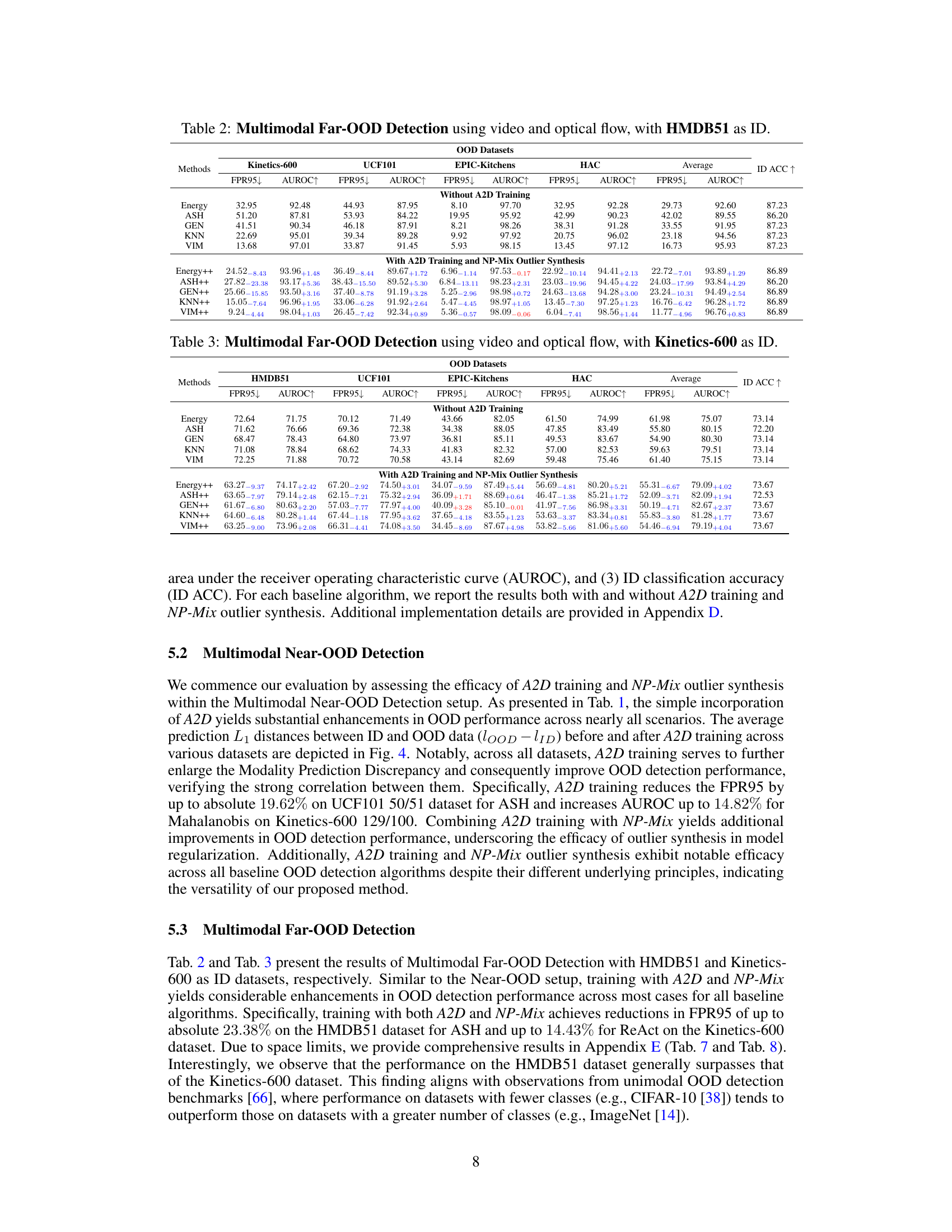
The paper’s conclusion, while mentioning future work, lacks specifics. Extending the MultiOOD benchmark to encompass more diverse modalities and dataset sizes is crucial. Investigating more sophisticated fusion methods beyond simple averaging or concatenation, exploring attention mechanisms or transformer-based approaches, would significantly advance multimodal OOD detection. Developing more robust outlier synthesis methods that better capture the underlying distribution of OOD data is another key area. Additionally, researching the theoretical underpinnings of modality prediction discrepancy and developing algorithms explicitly leveraging this phenomenon would enhance the theoretical rigor and performance. Finally, application to specific real-world scenarios with detailed quantitative analysis would showcase the practical benefits and limitations of the proposed approach.
More visual insights#
More on figures

This figure provides a visual representation of the MultiOOD benchmark, which is a novel dataset designed for evaluating multimodal out-of-distribution (OOD) detection algorithms. The benchmark consists of two main setups: Near-OOD and Far-OOD. Near-OOD uses subsets of existing datasets to create in-distribution and out-of-distribution sets, while Far-OOD utilizes completely distinct datasets as the out-of-distribution data. The image showcases the datasets used in each setup, along with visualizations of the types of modalities (video, optical flow, audio) included and the number of videos and classes per dataset. The chart highlights the diversity in dataset sizes and modality combinations.

This figure illustrates the Modality Prediction Discrepancy phenomenon. It shows softmax prediction probabilities for both video and optical flow modalities for both in-distribution (ID) and out-of-distribution (OOD) data. The left panel (a) displays the predictions for ID data, showing high agreement between the video and flow predictions, indicating a small L1 distance between them. The right panel (b) shows the predictions for OOD data, where the video and flow predictions show significant disagreement and larger L1 distance. This highlights that the discrepancy in predictions between different modalities is negligible for ID data but significant for OOD data. This discrepancy is used as the basis for the Agree-to-Disagree (A2D) algorithm proposed in the paper.

This figure shows the strong correlation between the average L1 distance of prediction probabilities between in-distribution (ID) and out-of-distribution (OOD) data and the OOD detection performance (AUROC). The left panel shows the L1 distances before A2D training, and the right panel shows them after A2D training. The A2D algorithm increases the L1 distances between ID and OOD data, leading to improved OOD detection performance. This visually demonstrates the effectiveness of the A2D algorithm in enhancing the discrepancy between ID and OOD data.

This figure illustrates the proposed framework for multimodal out-of-distribution (OOD) detection. The top half shows the Agree-to-Disagree (A2D) algorithm which aims to maximize the discrepancy in prediction probabilities between modalities for out-of-distribution samples while maintaining agreement for in-distribution samples. The bottom half depicts the Nearest Prototype Mixup (NP-Mix) outlier synthesis method which generates synthetic outliers by mixing prototypes from nearest neighbor classes, thereby exploring broader feature spaces to improve OOD detection performance. Both A2D and NP-Mix work together to enhance the overall accuracy of the multimodal OOD detection system.

This figure shows sample frames from the five action recognition datasets used in the MultiOOD benchmark: EPIC-Kitchens, HAC, HMDB51, UCF101, and Kinetics-600. Each dataset contains videos depicting various human actions, and the images provide a visual representation of the diversity in action types and visual characteristics across the datasets. The diversity is important because it allows for a more robust evaluation of multimodal OOD detection methods.

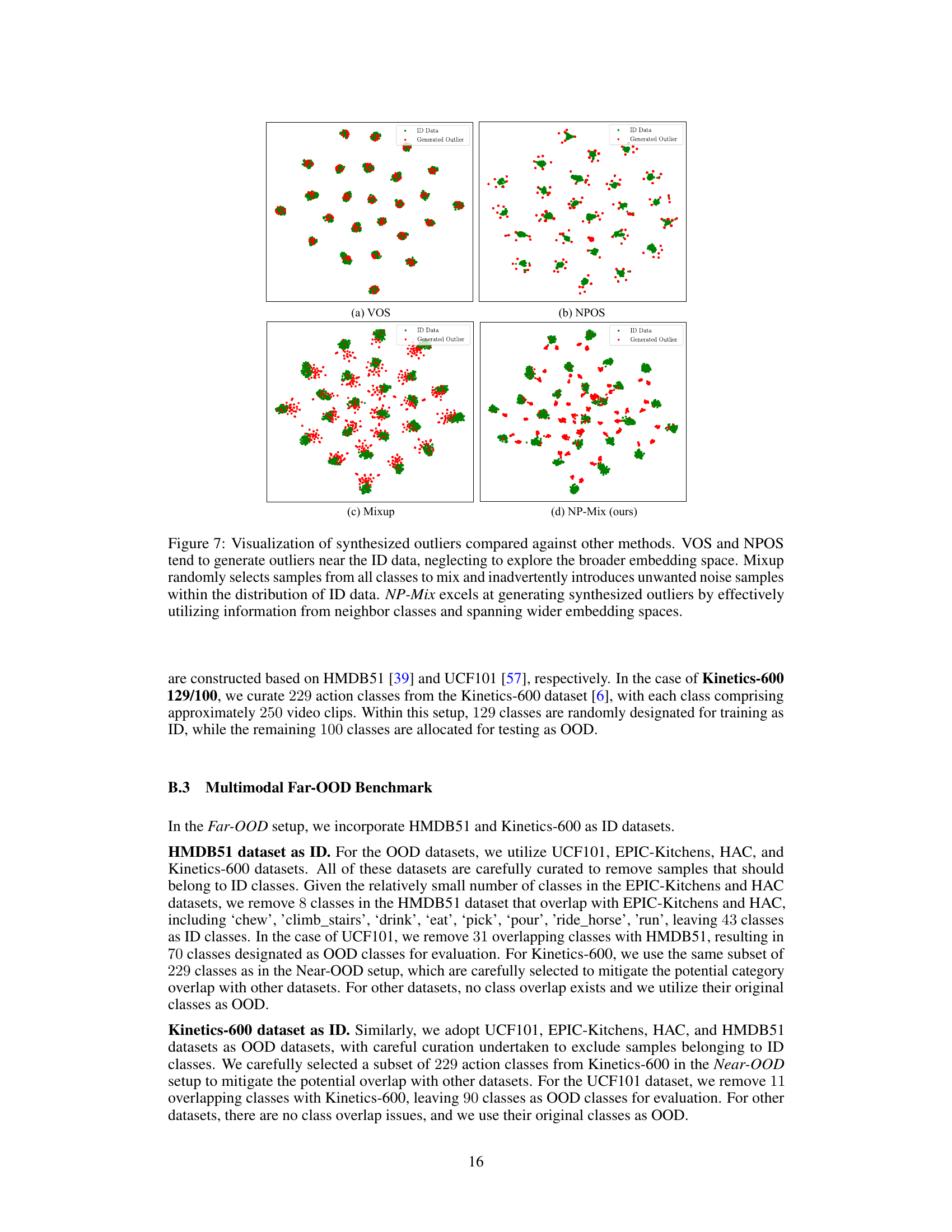
This figure compares the outlier synthesis methods VOS, NPOS, Mixup and NP-Mix. VOS and NPOS tend to generate outliers close to the in-distribution data. Mixup randomly mixes samples from all classes, potentially adding noise. NP-Mix, by contrast, leverages information from nearest neighbor classes to generate outliers that explore a broader feature space.
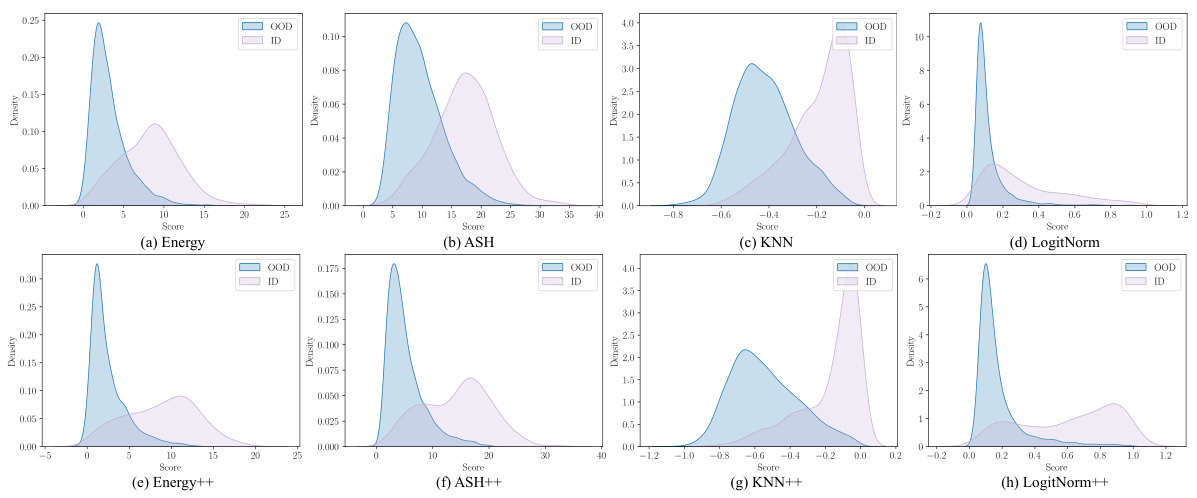
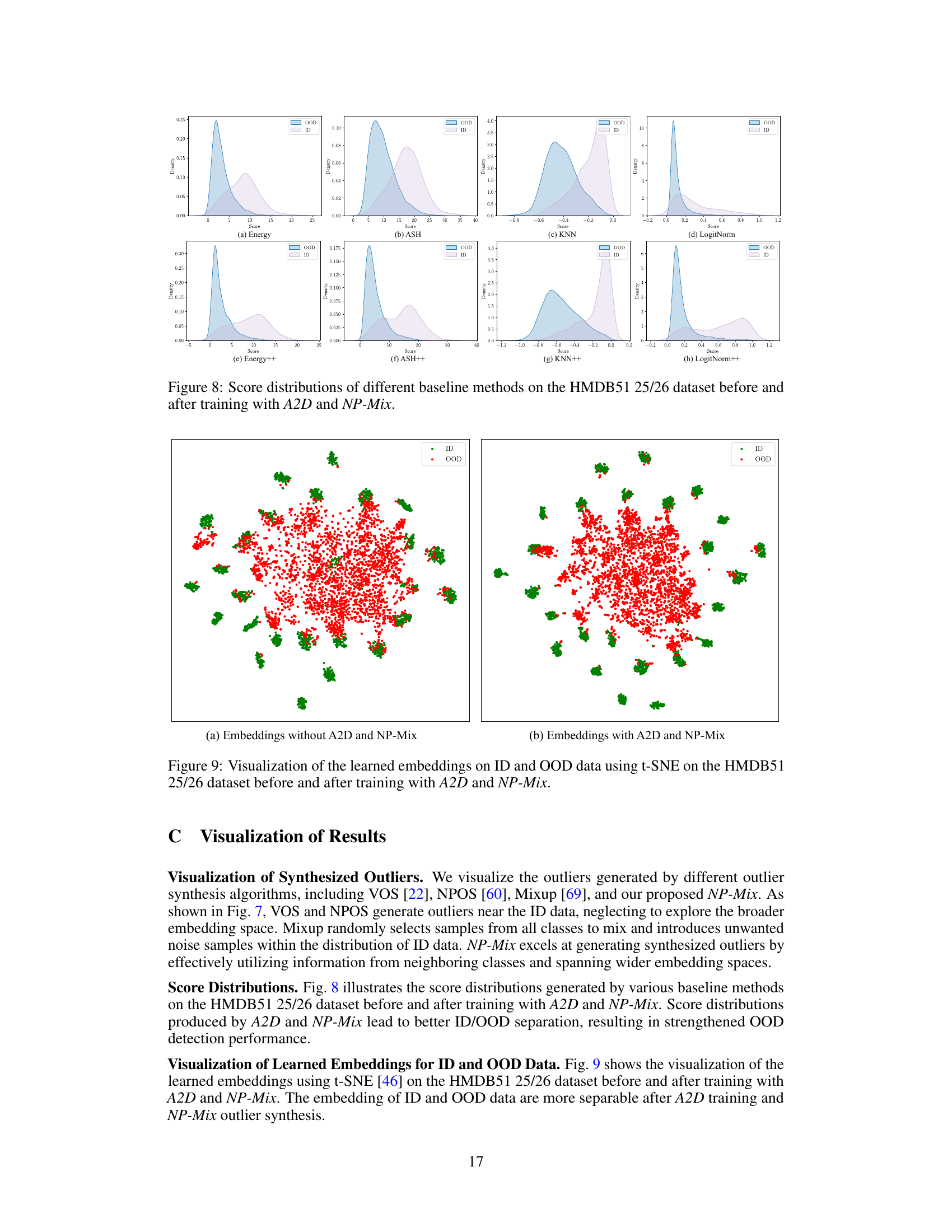
This figure compares the score distributions of in-distribution (ID) and out-of-distribution (OOD) data for several baseline methods (Energy, ASH, KNN, LogitNorm) before and after training with the proposed A2D and NP-Mix techniques. The goal is to show how the A2D and NP-Mix methods improve the separation between ID and OOD data, making it easier to distinguish between them. The improved separation is evident in the plots (e) to (h), where the distributions of ID and OOD scores have less overlap compared to the plots (a) to (d).
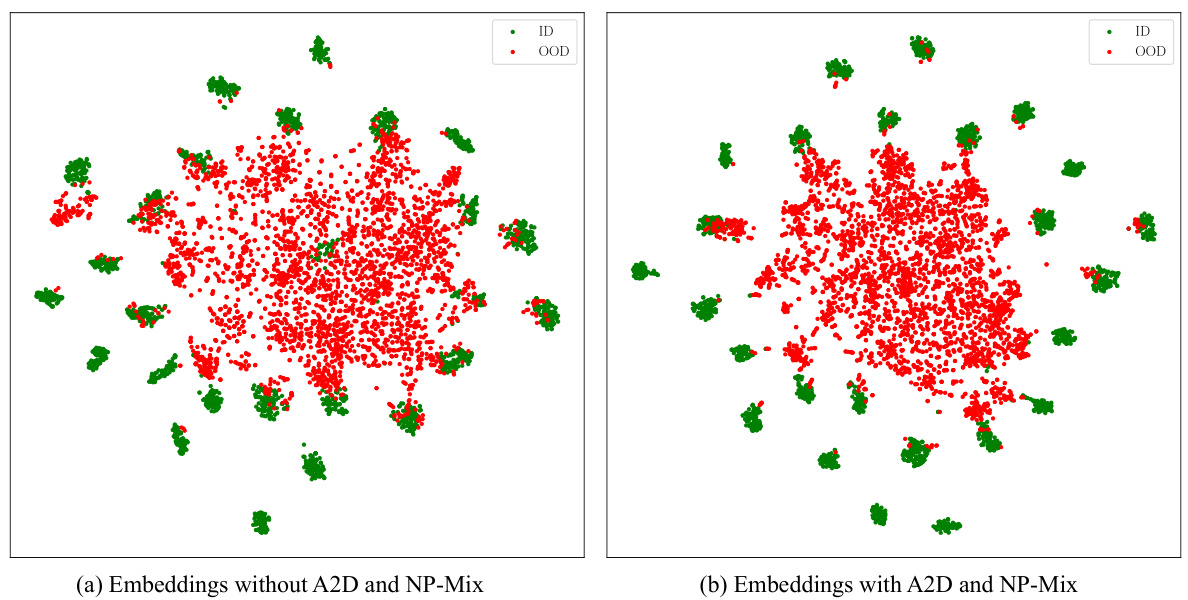
This figure shows the visualization of the learned embeddings using t-SNE on the HMDB51 25/26 dataset. Subfigure (a) shows the embeddings before training with the A2D and NP-Mix methods, while subfigure (b) displays the embeddings after training with these methods. The visualization helps illustrate the impact of A2D and NP-Mix on the separability of in-distribution (ID) and out-of-distribution (OOD) data in the learned feature space. The better separation in (b) suggests that A2D and NP-Mix improve the model’s ability to distinguish between ID and OOD samples.
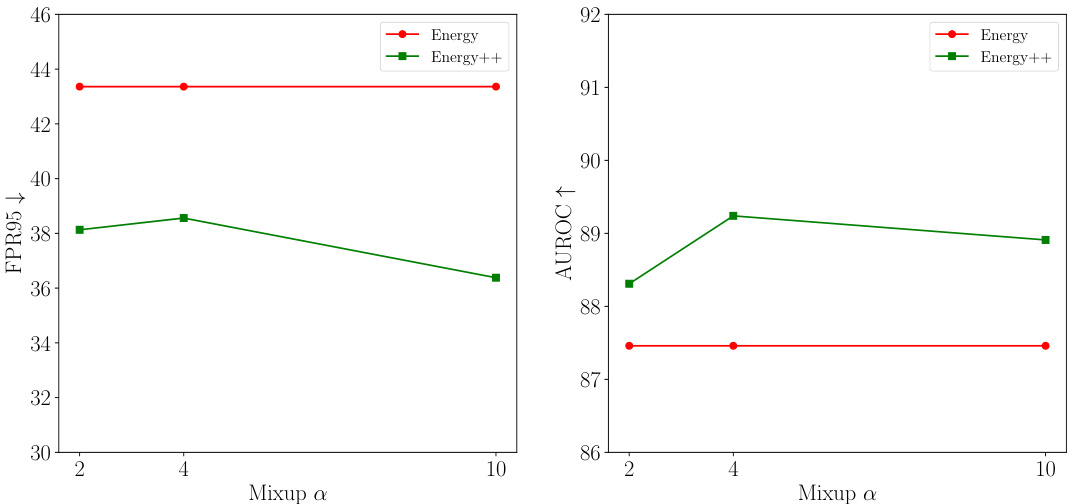
This figure shows the impact of the hyperparameter α in the NP-Mix outlier synthesis method on the out-of-distribution (OOD) detection performance. Two metrics are plotted against different values of α: the False Positive Rate at 95% true positive rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC). The results show that the optimal value of α depends on the specific OOD algorithm and dataset used but in the case of Energy and Energy++, performance is relatively stable.

The figure shows the impact of the hyperparameter α in the NP-Mix outlier synthesis method on the out-of-distribution (OOD) detection performance. The left plot displays the false positive rate (FPR95) while the right plot shows the area under the receiver operating characteristic curve (AUROC). Both plots show the results for different values of α (2, 4, 10) for the baseline Energy method and the Energy++ method (which incorporates A2D and NP-Mix). The results show that the optimal value of α depends on the specific OOD detection method used.

This figure displays the performance of different OOD detection methods on the HMDB51 dataset using various modalities (Flow, Video, and Video+Flow). The bars represent the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC). The results show that multimodal OOD detection significantly outperforms unimodal methods, demonstrating the benefits of incorporating multiple modalities for improved OOD detection performance.

This figure shows the results of Multimodal Near-OOD detection experiments on the HMDB51 25/26 dataset using three different random seeds. The results are presented for four different OOD detection methods (Energy, GEN, KNN, VIM). The bold foreground points represent the average performance across the three seeds, while the fainter background points represent the individual results from each seed. The figure allows for the visual comparison of the performance consistency and variability across different random seeds for each method. It highlights the impact of using A2D and NP-Mix on the OOD detection performance.
More on tables
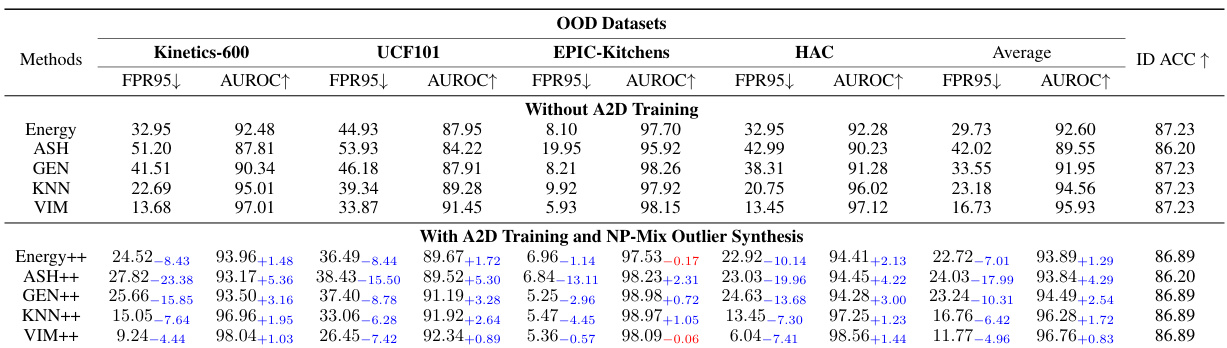
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets: HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, and Kinetics-600 129/100. It compares the performance of several OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under three conditions: without A2D training, with A2D training, and with both A2D training and NP-Mix outlier synthesis. The metrics used for evaluation are FPR95 (False Positive Rate at 95% True Positive Rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID ACC (In-Distribution Accuracy). The results show that the proposed A2D and NP-Mix methods significantly improve the performance of existing unimodal OOD algorithms.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets. It compares the performance of several OOD detection methods with and without the proposed Agree-to-Disagree (A2D) algorithm and a novel outlier synthesis method called NP-Mix. The metrics used for evaluation are False Positive Rate at 95% true positive rate (FPR95), Area Under the Receiver Operating Characteristic curve (AUROC), and In-distribution accuracy (ID ACC). Lower FPR95 and higher AUROC values indicate better performance. The table highlights significant performance improvements achieved by incorporating A2D and NP-Mix.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets: HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, and Kinetics-600 129/100. It compares the performance of several existing unimodal OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) before and after training with the proposed A2D and NP-Mix methods. The table shows the False Positive Rate at 95% true positive rate (FPR95), Area Under the Receiver Operating Characteristic curve (AUROC), and In-distribution accuracy (ID ACC) for each method and dataset, highlighting the significant improvements achieved by using the proposed A2D and NP-Mix training techniques.

This table presents the ablation study on different distance functions used in the Agree-to-Disagree algorithm for Near-OOD detection on the HMDB51 dataset. It shows the performance of different methods (Energy, GEN, KNN, VIM) using different distance functions (L1, L2, Wasserstein, Hellinger). The results are presented in terms of FPR95 (False Positive Rate at 95% true positive rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Lower FPR95 and higher AUROC indicate better performance.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data. It compares various OOD detection methods’ performance across four different datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100) with and without the proposed Agree-to-Disagree (A2D) training algorithm and Nearest-Neighbor Mixup (NP-Mix) outlier synthesis. The metrics reported are False Positive Rate at 95% true positive rate (FPR95), Area Under the Receiver Operating Characteristic curve (AUROC), and In-distribution Accuracy (ID ACC). Lower FPR95 and higher AUROC values indicate better performance. The table highlights how the proposed A2D and NP-Mix significantly improve the performance of the existing unimodal OOD detection algorithms.
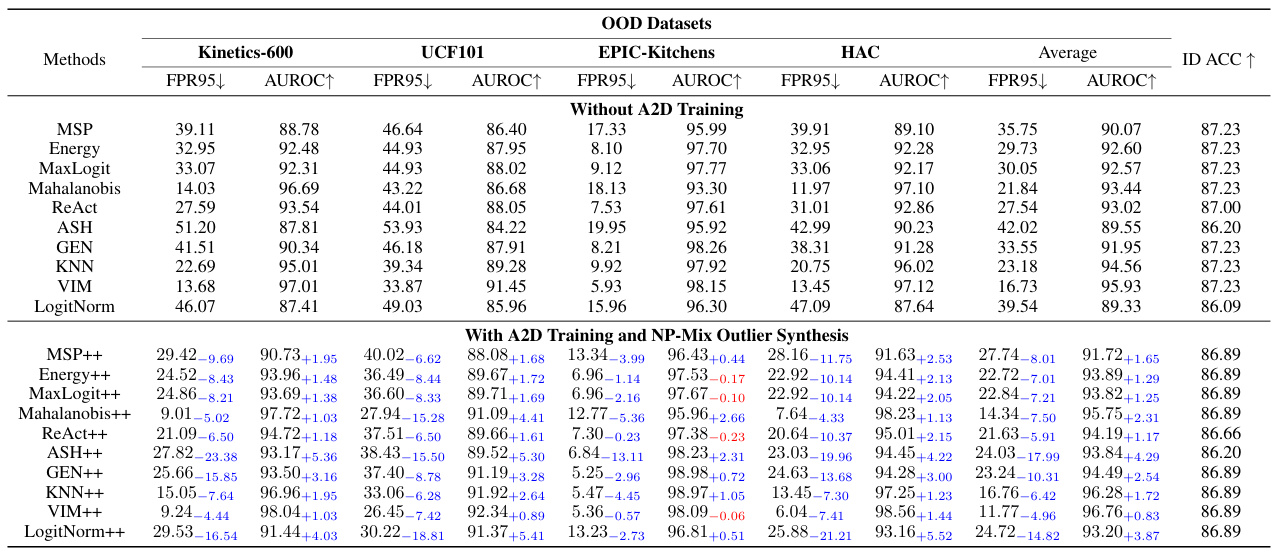
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100). It compares the performance of several OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under two conditions: without A2D and NP-Mix training and with A2D and NP-Mix training. The metrics used for evaluation are FPR95 (False Positive Rate at 95% true positive rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID ACC (In-distribution Accuracy). The table highlights the significant improvements in OOD detection performance achieved by incorporating the A2D and NP-Mix techniques.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four different datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100). It compares the performance of various OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) with and without the proposed Agree-to-Disagree (A2D) training algorithm and Nearest-Neighbor Mixup (NP-Mix) outlier synthesis method. The table shows the False Positive Rate at 95% true positive rate (FPR95), Area Under the ROC Curve (AUROC), and In-distribution accuracy (ID ACC). Lower FPR95 and higher AUROC values indicate better performance.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four different datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, and Kinetics-600 129/100). It compares the performance of several unimodal OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) with and without the proposed A2D training algorithm and NP-Mix outlier synthesis method. The table shows the false positive rate at 95% true positive rate (FPR95), the area under the receiver operating characteristic curve (AUROC), and the in-distribution accuracy (ID ACC) for each method and dataset. The results demonstrate that the proposed A2D and NP-Mix significantly improve the performance of existing unimodal OOD detection methods.

This table presents the results of Multimodal Near-OOD detection experiments using video and optical flow data on four datasets: HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, and Kinetics-600 129/100. Several unimodal OOD detection methods are evaluated, both with and without the proposed A2D and NP-Mix training techniques. The table shows FPR95 (False Positive Rate at 95% true positive rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID ACC (in-distribution classification accuracy) for each method and dataset. The results demonstrate the significant improvement in OOD detection performance achieved by incorporating A2D and NP-Mix.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100). It compares the performance of several baseline OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under different training scenarios: without A2D and NP-Mix, with A2D training only, and with both A2D training and NP-Mix outlier synthesis. The metrics used for evaluation are False Positive Rate at 95% true positive rate (FPR95), Area Under the ROC Curve (AUROC), and In-distribution accuracy (ID ACC). Lower FPR95 and higher AUROC and ID ACC indicate better performance. The results show that the proposed A2D and NP-Mix methods significantly improve the performance of existing unimodal OOD detection algorithms.

This table presents the results of an ablation study on the ensemble of different OOD scores on different modalities. The study aims to demonstrate the importance of studying the multimodal OOD detection problem by comparing the performance of ensembles of unimodal OOD methods with the proposed multimodal approach. The results show that combining more modalities consistently improves performance, but there is still a large gap compared to the proposed solution, which underscores the importance of investigating the multimodal OOD detection problem.
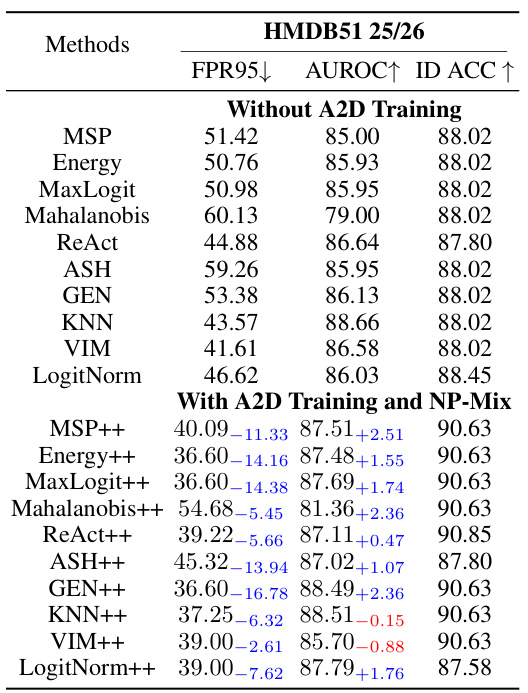
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100). It compares the performance of several OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under different training conditions: without A2D and NP-Mix, with A2D training only, and with both A2D training and NP-Mix outlier synthesis. The metrics used for evaluation are False Positive Rate at 95% true positive rate (FPR95), Area Under the ROC Curve (AUROC), and In-distribution accuracy (ID ACC). Lower FPR95 and higher AUROC are better. The table highlights the significant performance improvements achieved by incorporating A2D and NP-Mix into the training process.

This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments on four datasets (HMDB51 25/26, UCF101 50/51, EPIC-Kitchens 4/4, Kinetics-600 129/100) using video and optical flow modalities. It compares the performance of several OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) under three training conditions: without A2D training, with A2D training, and with both A2D training and NP-Mix outlier synthesis. The metrics used are FPR95 (False Positive Rate at 95% True Positive Rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID ACC (In-Distribution Accuracy). The table highlights the significant improvements in OOD detection performance achieved by using A2D and NP-Mix.
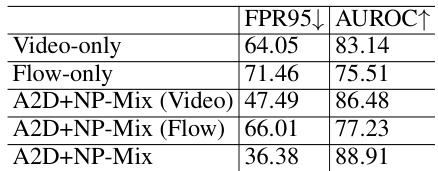
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data on four different datasets. It compares the performance of several existing unimodal OOD detection methods (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) before and after training with the proposed Agree-to-Disagree (A2D) algorithm and Nearest-Neighbor-based Mixup (NP-Mix) outlier synthesis method. The metrics used for evaluation are False Positive Rate at 95% true positive rate (FPR95), Area Under the Receiver Operating Characteristic curve (AUROC), and In-distribution accuracy (ID ACC). Lower FPR95 and higher AUROC values indicate better performance. The results demonstrate that using the proposed A2D and NP-Mix methods significantly improves the performance of all the baseline OOD detection algorithms.
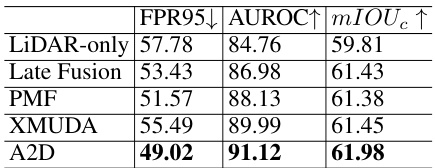
This table presents the results of multimodal near-out-of-distribution (OOD) detection experiments using video and optical flow data. It compares the performance of several existing unimodal OOD detection algorithms (MSP, Energy, MaxLogit, Mahalanobis, ReAct, ASH, GEN, KNN, VIM, LogitNorm) with and without the proposed Agree-to-Disagree (A2D) algorithm and Nearest-Neighbor Mixup (NP-Mix) outlier synthesis method. The metrics used for evaluation are False Positive Rate at 95% true positive rate (FPR95), Area Under the Receiver Operating Characteristic curve (AUROC), and In-distribution Accuracy (ID ACC). The results demonstrate the effectiveness of A2D and NP-Mix in significantly improving the performance of the baselines.
Full paper#