↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Synthetic Aperture Radar (SAR) object detection is hampered by limited public datasets and inaccessible code. Current datasets are small and contain only single-object categories, hindering the development of robust and generalizable models. This limits progress on real-world applications.
The paper introduces SARDet-100K, a large-scale, multi-class SAR object detection dataset compiled from ten existing datasets. It also presents MSFA, a novel pretraining framework to mitigate domain and model transfer challenges between RGB and SAR data. MSFA shows significant performance improvements across various models. The dataset and code are open-source, fostering wider adoption and research in SAR object detection.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the scarcity of large-scale, publicly available datasets and open-source code in SAR object detection. By introducing SARDet-100K and the MSFA framework, it significantly lowers the barrier to entry for researchers and accelerates progress in this vital field. The open-source nature of the contributions facilitates wider adoption and collaborative advancements.
Visual Insights#

The figure demonstrates the benefits of SAR imagery in comparison with traditional optical images. Panel (a) shows examples of RGB and SAR images taken under various conditions (night, cloud, snow, land cover). The SAR images maintain clarity and detail regardless of the weather or lighting. Panel (b) displays a bar graph showing a significant increase in the number of research papers published on SAR detection between 2014 and 2023, indicating growing interest in this area of research.
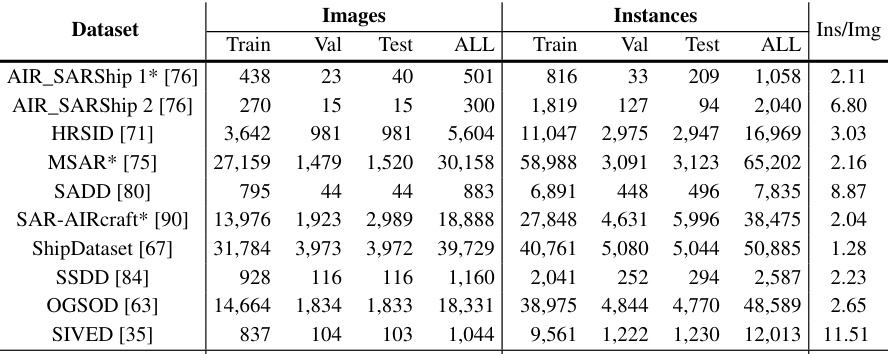
This table presents a statistical summary of the SARDet-100K dataset, broken down by source dataset. It shows the number of images and instances (objects) in the training, validation, and testing sets for each source dataset, as well as the overall dataset. The ‘Ins/Img’ column indicates the average number of instances per image. The asterisk (*) indicates that the original datasets were cropped into 512x512 pixel patches.
In-depth insights#
SAR Object Detection#
Synthetic Aperture Radar (SAR) object detection is a crucial area of research with significant implications for various applications, including defense, environmental monitoring, and disaster relief. The field faces challenges due to the limited availability of large, diverse, publicly accessible datasets and a lack of shared codebase for benchmarking. The inherent properties of SAR imagery such as speckle noise and variations in image quality further complicate the development of robust and accurate detection algorithms. Recent advancements leverage deep learning techniques, but substantial domain and model transfer gaps exist between pretraining on RGB datasets (like ImageNet) and finetuning on SAR images. To overcome these limitations, researchers are exploring novel pretraining strategies, handcrafted feature descriptors, and specialized network architectures. The development of large-scale, multi-class SAR datasets, combined with open-source tools and benchmarks, is essential to accelerate future progress in this field. This will foster collaborative research, promote reproducible results, and ultimately facilitate the wider deployment of accurate and reliable SAR object detection systems.
SARDet-100K Dataset#
The SARDet-100K dataset represents a significant advancement in the field of Synthetic Aperture Radar (SAR) object detection. Its large scale (117k images, 246k instances), encompassing diverse data sources and multiple object classes, directly addresses the limitations of previously available datasets. This comprehensive dataset, reaching COCO-level scale, facilitates more robust model training and evaluation, thus contributing to higher accuracy and generalization capabilities. Open-source availability, coupled with a provided toolkit, encourages wider community participation and accelerates progress in SAR object detection research. The dataset’s creation involved intensive data collection and standardization, highlighting the effort undertaken to ensure data quality and consistency, and making it a valuable resource for the research community.
MSFA Pretraining#
The proposed MSFA (Multi-Stage with Filter Augmentation) pretraining framework is a novel approach to address the challenges of transferring knowledge from RGB datasets to SAR object detection models. It tackles the problem from three perspectives: data input, domain transition, and model migration. By incorporating handcrafted features (like WST) as input, it narrows the gap between the feature spaces of RGB and SAR images. The multi-stage pretraining strategy, using an optical remote sensing dataset as a bridge, aids in gradually transitioning the model from the RGB domain to the SAR domain. Finally, MSFA pretrains the entire detection model rather than just the backbone, resulting in improved generalizability and flexibility across diverse model architectures. This holistic approach significantly enhances SAR object detection performance and highlights the importance of addressing both domain and model transfer challenges simultaneously.
Transfer Learning Gaps#
The heading ‘Transfer Learning Gaps’ highlights a critical challenge in Synthetic Aperture Radar (SAR) object detection: the significant disparity between models pre-trained on natural RGB images (like ImageNet) and those fine-tuned on SAR data. This gap manifests as domain discrepancies (visual differences between RGB and SAR imagery) and model structural differences, impacting the model’s ability to effectively transfer learned features. Bridging this gap is crucial for leveraging the power of transfer learning in SAR object detection, a field currently hampered by limited data. Addressing this necessitates innovative pre-training strategies that mitigate both domain and model discrepancies. This might involve techniques such as domain adaptation, using synthetic SAR data for pre-training, or developing novel architectures better suited to both data types. Successful approaches could dramatically improve the efficiency and performance of SAR object detection models.
Future Work#
The authors acknowledge the limitations of their current work, focusing on supervised learning, and suggest several promising avenues for future research. Expanding into semi-supervised, weakly-supervised, or unsupervised learning techniques would leverage the abundance of unlabeled SAR data. This could significantly improve the robustness and generalizability of SAR object detection models. Furthermore, exploring more intricate and specialized designs within the MSFA framework, beyond the basic structure presented, offers the potential for enhanced performance and capabilities. This could involve investigating more sophisticated methods for bridging domain gaps and integrating a wider variety of handcrafted feature descriptors. Finally, a detailed investigation into the failure modes highlighted in the paper is crucial. Understanding why the model struggles with small objects, dense clusters, or low-quality images is key to building more robust and reliable systems. This involves detailed analyses of the model’s behavior under those specific conditions to guide improvements in both data augmentation strategies and model architectures.
More visual insights#
More on figures

This figure illustrates the domain gap between natural RGB images and SAR images and how the proposed method bridges this gap. The top half shows a large difference in pixel-level distributions between RGB and SAR data. The bottom half demonstrates that using Wavelet Scattering Transform (WST) features reduces this gap. The figure also depicts a two-stage pretraining strategy where optical remote sensing data acts as an intermediary bridge between natural RGB and SAR datasets.

This figure illustrates the difference between the traditional ImageNet pretraining approach and the proposed Multi-Stage with Filter Augmentation (MSFA) pretraining framework. In the traditional approach, a backbone network is pretrained on ImageNet and then fine-tuned on a SAR dataset for object detection. This process suffers from a domain gap and a model gap. The MSFA framework aims to address these issues by introducing a multi-stage pretraining process: 1) filter augmentation and pretraining on ImageNet, 2) detection model pretraining on an optical remote sensing dataset (acting as a bridge to SAR data), and 3) finetuning the entire detection model on the SAR dataset. This approach helps to reduce the domain gap and model gap, leading to improved performance in SAR object detection.

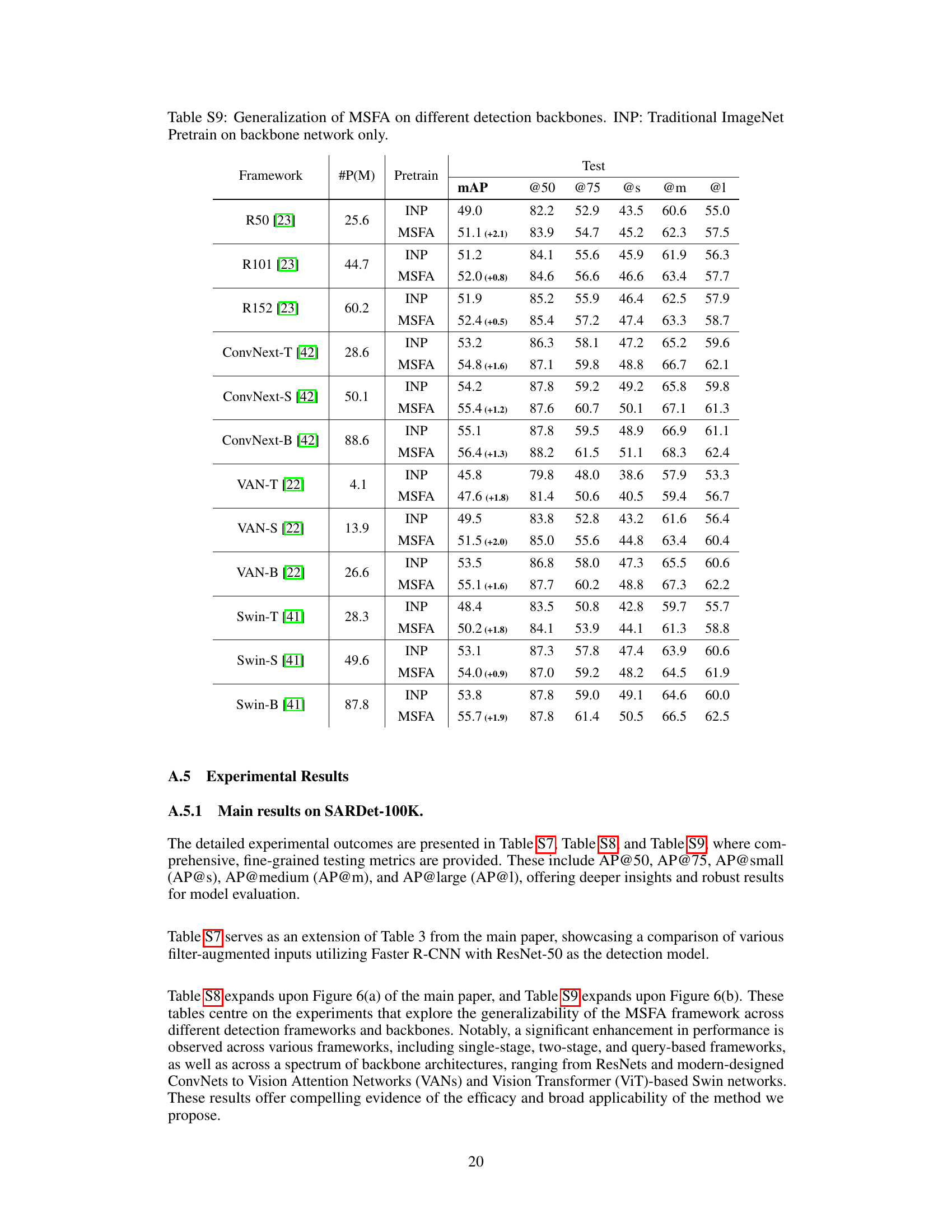
This figure demonstrates the generalizability of the proposed Multi-Stage with Filter Augmentation (MSFA) pretraining framework. Subfigure (a) is a radar chart showing the performance of MSFA across various detection frameworks (Faster R-CNN, Cascade R-CNN, RetinaNet, FCOS, GFL, DETR, Deformable DETR, Sparse R-CNN, and Grid R-CNN), highlighting its consistent improvement over traditional ImageNet pretraining (INP). Subfigure (b) is a line graph illustrating the performance of MSFA with different backbones (ResNet, ConvNext, VAN, Swin Transformer) across varying model sizes (parameter counts), further showcasing the consistent performance gains of MSFA regardless of the chosen backbone architecture.

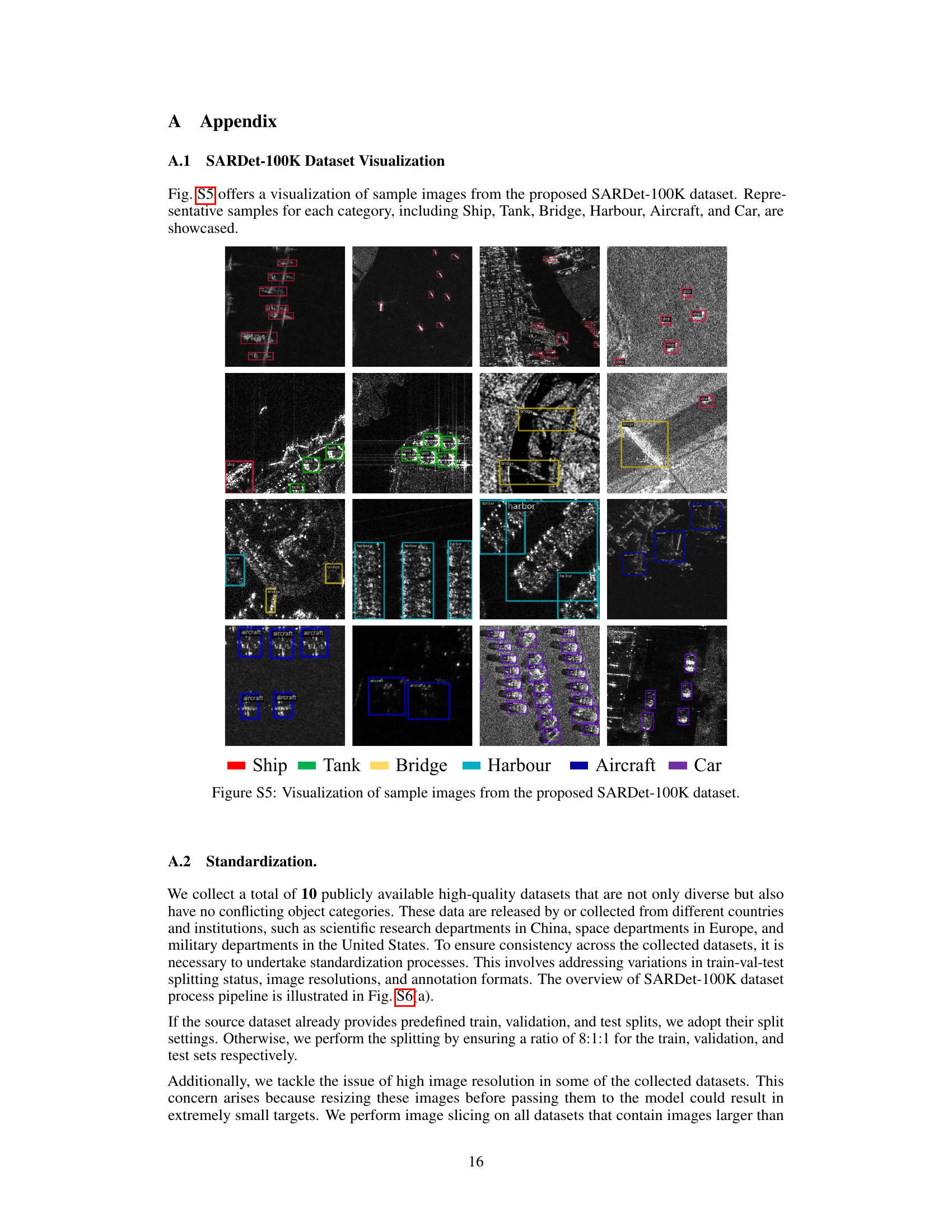
This figure visualizes sample images from the SARDet-100K dataset. It shows representative samples for each of the six object categories: Ship, Tank, Bridge, Harbor, Aircraft, and Car. The images are displayed in a grid format, allowing for a visual comparison of the different object types and their appearances within the dataset. The color-coded bounding boxes highlight the instances of each category.
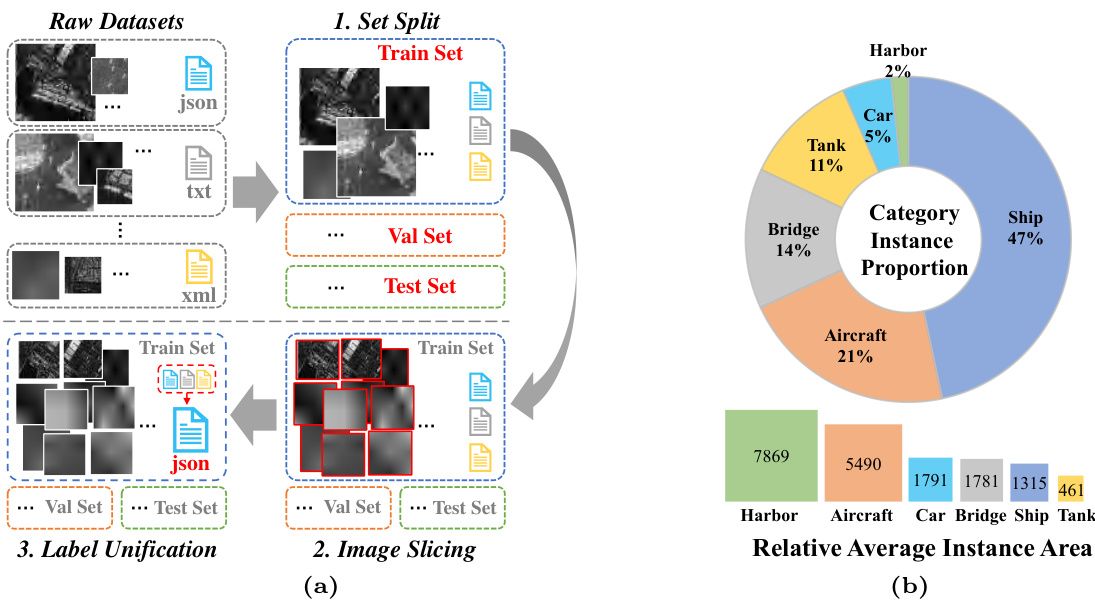
This figure illustrates the SARDet-100K dataset standardization process. Panel (a) shows the steps involved in dataset preparation, including splitting the dataset into training, validation, and testing sets; slicing large images into smaller patches; and unifying label annotations into a consistent format (COCO). Panel (b) displays the proportion of instances for each of the six object categories (Ship, Tank, Bridge, Harbor, Aircraft, and Car) within the dataset, along with the average instance area in pixels for each category, indicating the dataset’s diversity and scale.

This figure visualizes the results of applying six different handcrafted feature extraction methods (HOG, Canny, GRE, Haar, and WST) to two sample SAR images. Each method highlights different aspects of the image, showcasing their unique strengths and the variety of information that can be extracted from SAR data using these traditional techniques. The average pooling helps in easier comparison between features obtained from different methods.
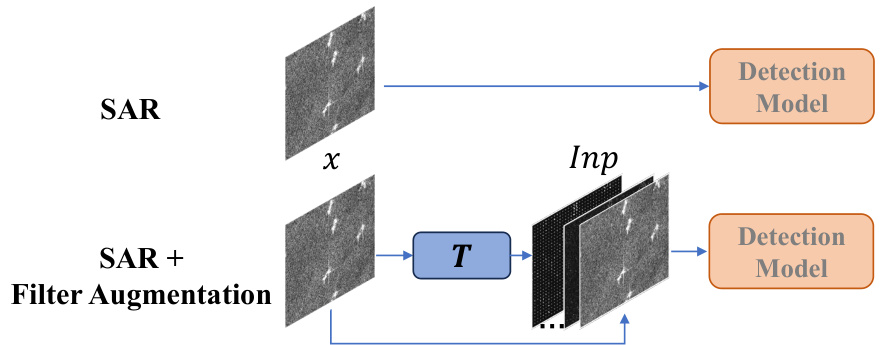
This figure illustrates the difference between the traditional ImageNet pretraining approach and the proposed Multi-Stage with Filter Augmentation (MSFA) pretraining framework. The traditional approach involves pretraining a backbone network on ImageNet and then finetuning the entire detection model on a SAR dataset, leading to domain and model gaps. In contrast, the MSFA framework utilizes a multi-stage pretraining strategy. In the first stage, it uses a filter augmentation approach to modify the input data, addressing the data domain gap. In the second stage, it uses an optical remote sensing detection dataset as a bridge, further reducing the domain gap and improving the model migration. The MSFA approach demonstrates the improved efficacy in bridging domain and model gaps, leading to enhanced performance in SAR object detection.

This figure compares the performance of different backbone models (ResNet, VAN, Swin) on three different SAR object detection datasets: SARDet-100K, SSDD, and HRSID. The x-axis represents the number of model parameters (in millions), and the y-axis represents the mean average precision (mAP) at IoU threshold of 0.5. The results show how the model performance changes with the model size and the dataset used. Each backbone is evaluated in conjunction with the Faster-RCNN detection framework. The plot enables readers to compare the relative performance across models and datasets; also observe the saturation effects on smaller datasets, SSDD and HRSID.

This figure demonstrates the improved performance of the proposed MSFA pretraining framework compared to the traditional ImageNet backbone pretraining method. It showcases three scenarios: (a) missing detection, where MSFA correctly identifies objects missed by the ImageNet method; (b) false detection, where MSFA reduces false positive detections compared to ImageNet; and (c) inaccurate localization, where MSFA shows more precise bounding boxes around detected objects than ImageNet. Each scenario provides visual comparisons between Ground Truth (GT), ImageNet (INP), and MSFA, highlighting MSFA’s superior performance in various aspects of SAR object detection.

This figure demonstrates the improved performance of the proposed Multi-Stage with Filter Augmentation (MSFA) pretraining framework compared to traditional ImageNet backbone pretraining. It shows three examples highlighting MSFA’s advantages: (a) fewer missed detections, (b) fewer false detections, and (c) more accurate localization. The ground truth (GT) bounding boxes are compared against the results using ImageNet pretraining (INP) and MSFA. The visualization highlights instances where MSFA either correctly detects objects missed by INP, avoids false positive detections made by INP, or provides significantly better localization.
More on tables
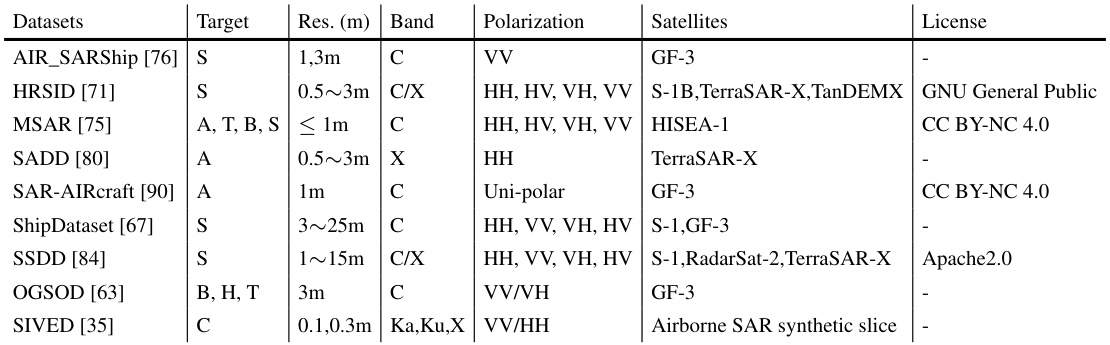
This table lists the ten datasets used to create the SARDet-100K dataset, specifying for each dataset the target categories of objects, the resolution, the frequency band used, the polarization, the satellite or platform used for image acquisition and the license.
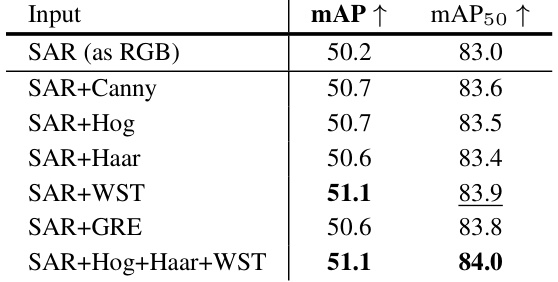
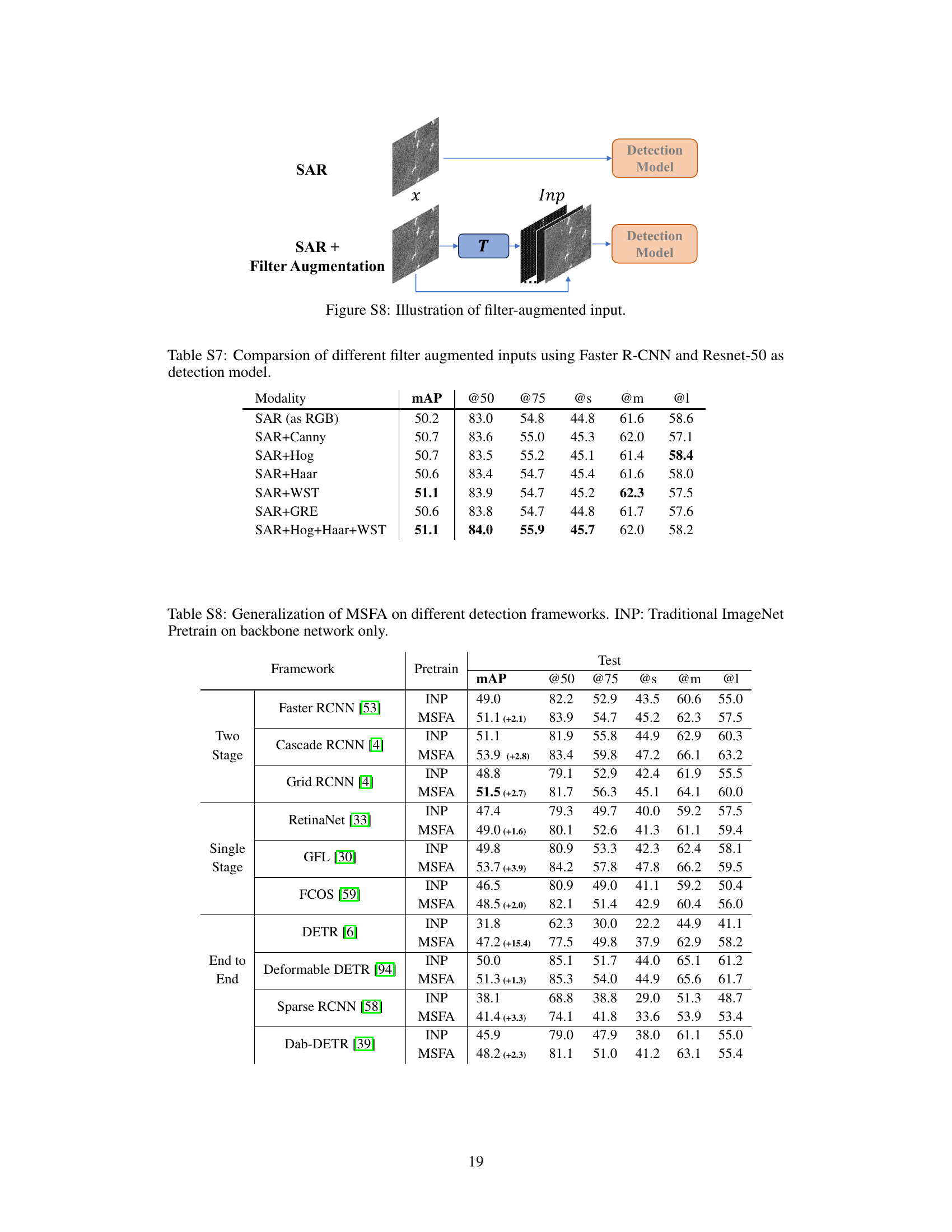
This table presents the results of experiments comparing different handcrafted feature descriptors used as Filter Augmented Inputs in a Faster R-CNN object detection model with a ResNet50 backbone. The table shows mean Average Precision (mAP) and mAP at IoU threshold of 0.5 (mAP50) for each input type: SAR (as RGB), SAR with Canny edge detection, SAR with Histogram of Oriented Gradients (HOG), SAR with Haar-like features, SAR with Wavelet Scattering Transform (WST), SAR with Gradient by Ratio Edge (GRE), and SAR with a combination of HOG, Haar, and WST. The results indicate the impact of the different handcrafted features on the object detection performance.
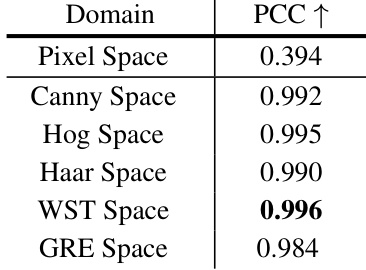
This table presents the Pearson Correlation Coefficients (PCC) between ImageNet and SARDet-100k datasets in different feature spaces: pixel space, Canny space, HOG space, Haar space, WST space, and GRE space. The PCC values indicate the correlation between the feature distributions of the two datasets. A higher PCC value suggests a stronger correlation and better transferability of knowledge from ImageNet to SARDet-100k during pretraining.
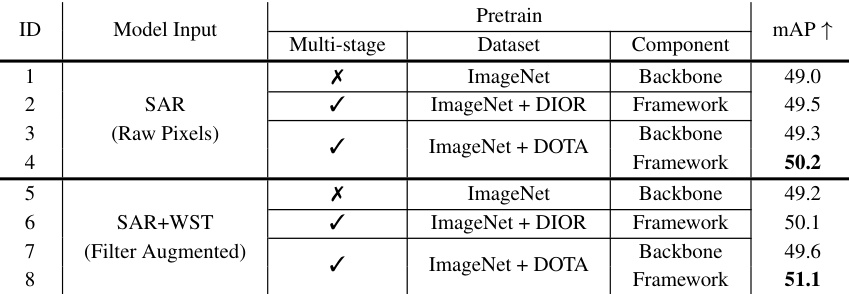
This table compares different pretraining strategies for a Faster-RCNN object detection model using ResNet50 as the backbone. It shows the mean Average Precision (mAP) achieved using different combinations of pretraining datasets (ImageNet, DIOR, DOTA) and whether the entire framework or just the backbone was finetuned. The results highlight the impact of multi-stage pretraining and demonstrate the effectiveness of using the proposed method.
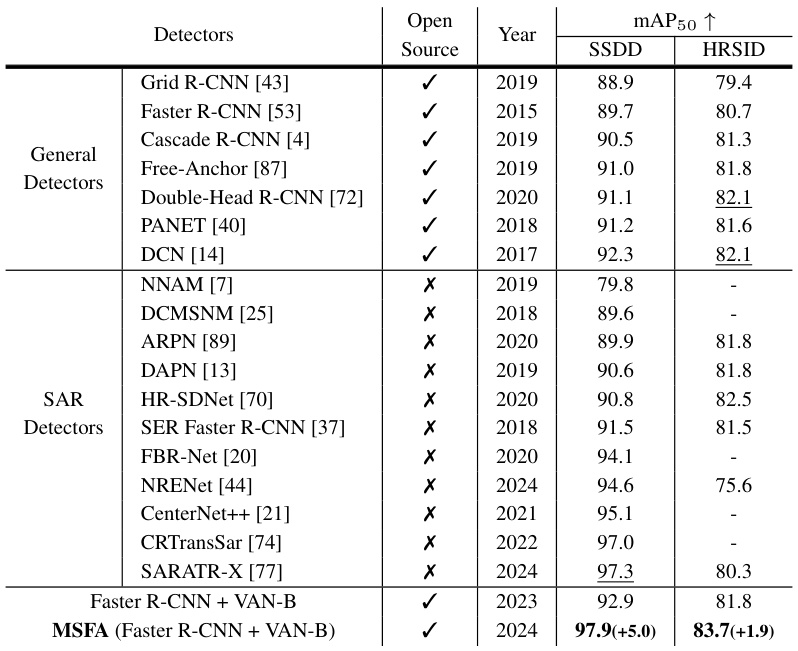
This table compares the performance of the proposed MSFA method against previous state-of-the-art (SOTA) methods on two benchmark datasets for SAR object detection: SSDD and HRSID. It shows the mAP50 scores achieved by each method, indicating the improvement offered by MSFA.

This table presents the mean Average Precision (mAP) and mAP@50 results for different filter augmented inputs using Faster R-CNN and ResNet-50 as the detection model. It shows how the addition of various handcrafted feature descriptors (Canny, HOG, Haar, WST, GRE) impacts performance, demonstrating the benefits of incorporating such features as auxiliary information for the detection task. The results highlight the superior performance of the Wavelet Scattering Transform (WST).

This table compares the performance of different pretraining strategies on the SAR object detection task using Faster-RCNN and ResNet50 as the detection models. It shows the mean Average Precision (mAP) achieved using different combinations of ImageNet and other datasets (DIOR, DOTA) for pretraining the backbone or entire framework, before finetuning on the SARDet-100K dataset. The results highlight the impact of multi-stage pretraining and the choice of which model components to pretrain on overall performance.
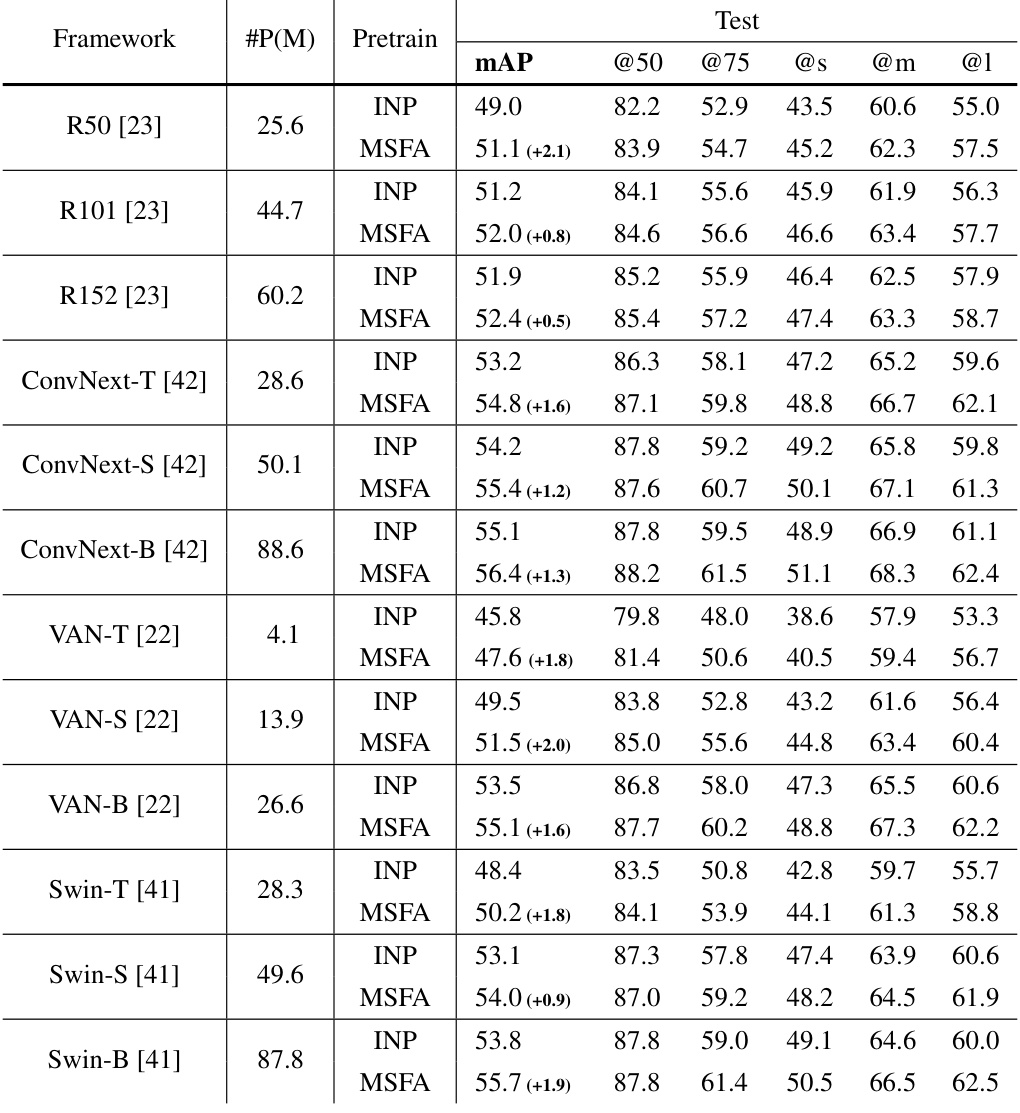
This table compares different pretraining strategies for object detection using Faster-RCNN and ResNet50. It shows the mean Average Precision (mAP) achieved with different pretraining methods such as ImageNet pretraining only, adding DIOR or DOTA datasets and combinations for pretraining, using the SAR dataset only for pretraining, and using Filter Augmented Input in combination with DIOR or DOTA. This allows for a comparison of the impact of different pretraining strategies on the final detection performance.

This table presents a statistical summary of the SARDet-100K dataset. It shows the number of images and instances for each of the datasets included, as well as the number of instances per image. The table also notes that the original datasets were cropped into 512x512 patches before inclusion in SARDet-100K. Abbreviations used include ‘Ins’ for instances and ‘Img’ for images.

This table compares the performance of different pretraining strategies for a Faster-RCNN object detection model using a ResNet50 backbone. It contrasts using only ImageNet pretraining versus a multi-stage approach that includes pretraining on both ImageNet and additional datasets (DIOR or DOTA), with and without filter augmentation. The results show mAP (mean Average Precision) values for each strategy, highlighting the benefits of the multi-stage pretraining method.

This table details the hyperparameters used for different training stages in the SAR object detection experiments. It shows the optimizer (AdamW), batch size (B.S.), learning rate (L.R.), and number of epochs for classification pretraining (Cls. Pretrain) on ImageNet, detection pretraining (Det. Pretrain) on DOTA and DIOR datasets, and detection finetuning (Det. Finetune) on SARDet-100k, SSDD, and HRSID datasets. It also includes hyperparameters for DETR, Deformable-DETR, Dab-DETR, and Sparse-RCNN.
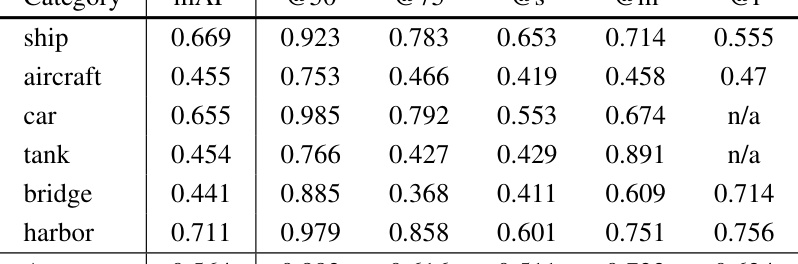
This table presents a detailed breakdown of the performance of the ConvNext-B model with MSFA (Multi-Stage with Filter Augmentation) pretraining. It shows the mean Average Precision (mAP) and Average Precision (AP) at different Intersection over Union (IoU) thresholds (0.5, 0.75, small, medium, large) for each object category in the SAR object detection task. The categories include ship, aircraft, car, tank, bridge, and harbor. The results highlight the model’s performance variations across different object types and sizes, indicating strengths and weaknesses in the model’s ability to accurately detect specific classes within the SAR images.
Full paper#