↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Semi-supervised multi-label learning (SSMLL) faces challenges due to the variance bias problem, where the feature distributions of positive and negative samples are imbalanced. This imbalance can lead to inaccurate model training and suboptimal performance. Existing methods using binary loss functions and negative sampling often struggle to overcome this variance bias.
The paper introduces a novel SSMLL method, S2ML2-BBAM, which tackles this issue head-on. It extends the binary angular margin loss by incorporating Gaussian transformations of feature angles, enabling a better balance in feature distributions for each label. Moreover, an efficient prototype-based negative sampling strategy ensures high-quality negative samples. Experimental results demonstrate that S2ML2-BBAM significantly outperforms existing methods, achieving state-of-the-art results on benchmark datasets. This highlights the effectiveness of the proposed method in addressing the variance bias issue and improving the overall performance of SSMLL.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical issue in semi-supervised multi-label learning (SSMLL) by proposing a novel method to balance the variance bias between positive and negative samples. This is a significant contribution because SSMLL is a rapidly growing field with many real-world applications. The proposed method, S2ML2-BBAM, achieves state-of-the-art performance on benchmark datasets, demonstrating its effectiveness and potential impact. Further research can build upon this work to improve SSMLL methods and extend their applications to various domains.
Visual Insights#

This figure shows the variance difference between feature distributions (VDFD) of positive and negative samples for four different labels (6, 7, 14, and 17) from the VOC2012 dataset. The VDFD is calculated separately for semi-supervised and supervised learning methods. The x-axis represents the training epoch, and the y-axis represents the VDFD value. The figure visually demonstrates the variance bias problem in semi-supervised multi-label learning, where the VDFD is often larger in the semi-supervised setting compared to the supervised setting. This variance bias problem is a key motivation for the proposed Balanced Binary Angular Margin Loss in the paper.
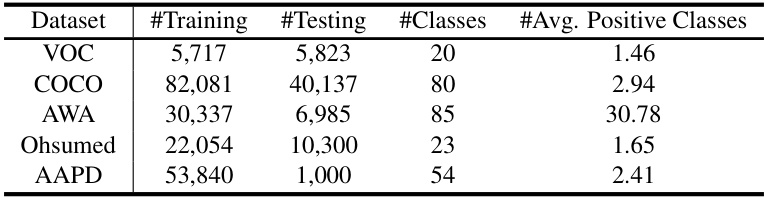
This table presents a summary of the characteristics of five datasets used in the paper’s experiments. For each dataset, it lists the number of training samples, the number of testing samples, the number of classes (labels), and the average number of positive classes per sample. These statistics are essential for understanding the scale and complexity of the multi-label learning tasks.
In-depth insights#
Balanced Angular Loss#
A balanced angular loss function aims to address the class imbalance problem in classification tasks, particularly in scenarios with skewed data distributions. Standard angular loss functions, such as the binary angular margin loss (BAM), may not perform optimally when one class significantly outnumbers another. This imbalance can lead to biased models that favor the majority class and underperform on the minority class. A balanced version seeks to mitigate this by adjusting the loss calculation to give more weight to the under-represented class, thereby encouraging the model to learn more effective discriminative features for all classes, and leading to improved overall accuracy and fairness. The specific implementation of a balanced angular loss might involve techniques like re-weighting samples, focusing on feature angle distributions, or employing other strategies to reduce the impact of skewed data on model performance. Such techniques ultimately aim to balance the sensitivity of the loss function to both positive and negative samples, enhancing the ability of the model to make precise classifications for all classes involved. This approach could leverage techniques such as adaptive margin scaling, data augmentation to address class imbalance issues, or novel sampling strategies, all geared toward improved generalization capabilities and robustness.
SSML Negative Sampling#
In semi-supervised multi-label learning (SSMLL), negative sampling plays a crucial role in addressing class imbalance and improving model performance. Effective negative sampling strategies select informative negative samples that are sufficiently distinct from positive samples, enhancing the discriminative power of the learned model. In SSMLL, the challenge is amplified due to the presence of unlabeled data, which adds uncertainty to the process. A key consideration is balancing the variance bias between positive and negative samples, preventing overfitting to the limited labeled data. Prototype-based negative sampling, where negative samples are selected based on their proximity to positive sample prototypes in a feature space, offers an efficient and effective approach in this setting. The algorithm dynamically updates the negative sample set during training, mitigating the impact of noisy pseudo-labels, often encountered in SSMLL. The optimal balance is crucial, as inadequate sampling can lead to suboptimal performance and inaccurate label predictions.
Variance Bias Effects#
The concept of ‘Variance Bias Effects’ in a machine learning context, particularly within semi-supervised multi-label learning (SSMLL), highlights a critical challenge. Imbalanced feature distributions between positive and negative samples for each label can arise from the use of pseudo-labels, leading to skewed variance. This bias negatively impacts the accuracy and fairness of the trained model, making it deviate from the Bayesian optimal boundary. Addressing this imbalance is crucial for improving SSMLL performance. The core idea revolves around balancing the variance bias by focusing on feature angle distributions rather than directly on sample features, and techniques such as Gaussian distribution transformations and efficient negative sampling methods have been suggested to mitigate the problem and improve model fairness and effectiveness. This is important because variance bias limits generalization, creating models that are too specific to training data and therefore perform poorly on unseen data. The approach of balancing feature angle distributions offers a novel perspective in addressing this issue in SSMLL.
Gaussian Feature Shift#
The concept of “Gaussian Feature Shift” in a research paper likely refers to a method for modeling and addressing changes in feature distributions. Assuming features follow a Gaussian distribution, a shift implies changes in the mean or variance of that distribution. This could arise from various sources such as differences in data collection methods, changes in underlying phenomena, or effects of domain adaptation. Analyzing this shift is crucial as it impacts classifier performance. The paper likely presents techniques to detect, model, or correct for such shifts. This could involve transforming features to align distributions, or incorporating shift parameters into a model. Addressing Gaussian Feature Shift often enhances generalization and robustness of machine learning models, making them less sensitive to discrepancies in data across different sets or time periods. The effectiveness of any proposed approach would likely be evaluated against baselines that don’t account for such shifts. A strong paper will demonstrate improved performance and robustness after correcting for the shift. The methodology might involve statistical testing, visual inspection of distributions or advanced techniques like domain adaptation algorithms. Therefore, “Gaussian Feature Shift” is a key component in achieving better model performance.
S2ML2-BBAM Method#
The S2ML2-BBAM method tackles semi-supervised multi-label learning by addressing the variance bias problem. It extends the Binary Angular Margin (BAM) loss to a balanced version (BBAM), focusing on feature angle distributions. The method assumes these distributions follow Gaussian patterns, iteratively updated during training via transformations aiming for balanced variance. A key innovation is the prototype-based negative sampling, improving the quality of negative samples for each label. By balancing variance through angle distribution adjustments and efficient sampling, S2ML2-BBAM aims to yield superior classification accuracy in semi-supervised multi-label scenarios, surpassing other methods through more accurate pseudo-label generation and boundary optimization.
More visual insights#
More on figures

This figure compares the variance difference between feature distributions (VDFD) of positive and negative samples for the VOC2012 dataset across different methods (CAP, SoftMatch, FlatMatch, and S2ML2-BBAM). The x-axis represents the training epoch, and the y-axis represents the VDFD value. The figure visually demonstrates that the proposed S2ML2-BBAM method effectively reduces the VDFD compared to other methods, indicating improved balance between positive and negative sample distributions.
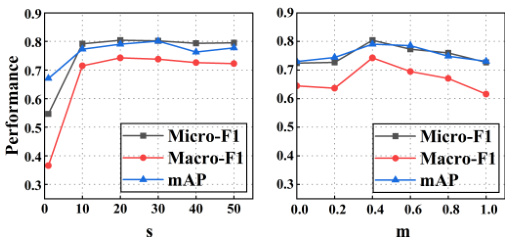
This figure shows the sensitivity analysis of the rescaled norm (s) and magnitude (m) parameters of the cosine margin in the Balanced Binary Angular Margin loss (BBAM) on the VOC2012 dataset with 5% labeled data. The left panel displays how the Micro-F1, Macro-F1, and mAP performance metrics vary as the scaling factor ’s’ changes. The right panel shows the same metrics’ sensitivity to variations in the margin parameter ’m’. The goal is to find the optimal values for s and m that maximize the model’s performance.
More on tables
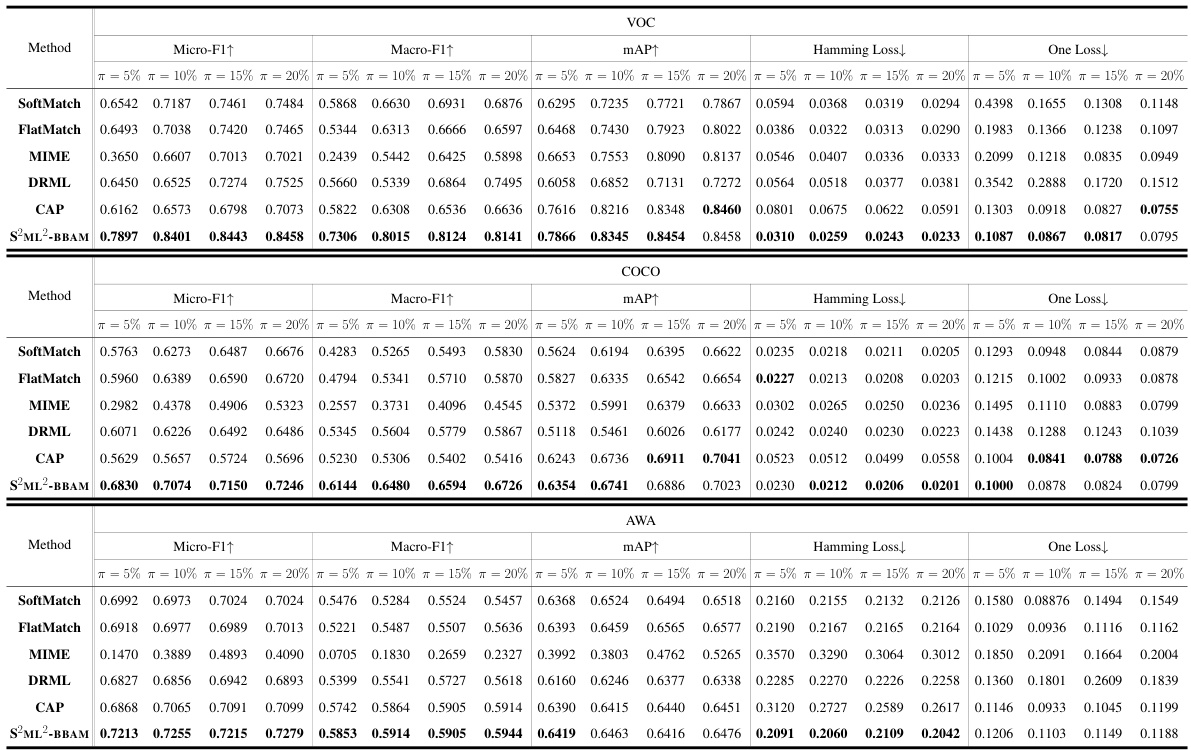
This table presents the performance of different multi-label learning methods on three image datasets (VOC, COCO, AWA). The results are shown for various data proportions (5%, 10%, 15%, 20% of labeled data), and five evaluation metrics are used: Micro-F1, Macro-F1, mAP, Hamming Loss, and One Loss. The best performing method for each metric and data proportion is highlighted in bold.
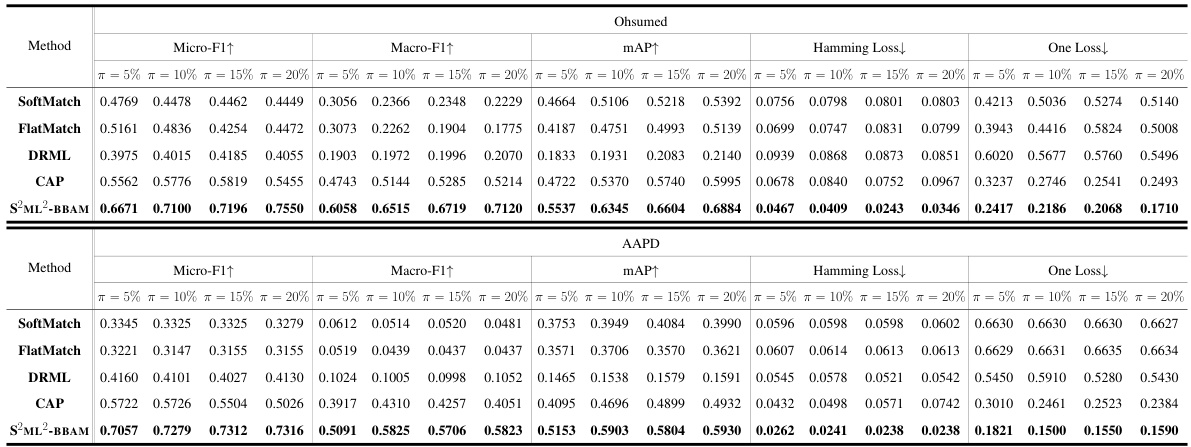
This table presents the performance comparison of different multi-label learning methods on image datasets (VOC, COCO, AWA). The metrics used are Micro-F1, Macro-F1, mAP, Hamming Loss, and One-Loss. Results are shown for different proportions of labeled data (π = 5%, 10%, 15%, 20%). The best-performing method for each metric and data proportion is highlighted in bold.

This table presents the performance comparison of different multi-label learning (MLL) methods on image datasets (VOC, COCO, AWA). The results are shown for different proportions of labeled data (π = 5%, 10%, 15%, 20%). The metrics used for evaluation include Micro-F1, Macro-F1, mAP, Hamming Loss, and One Loss. The table compares S2ML2-BBAM (the proposed method) with several baseline methods (SoftMatch, FlatMatch, MIME, DRML, CAP). The best results for each metric and data proportion are highlighted in boldface.

This table presents the experimental results of the proposed S2ML2-BBAM model and several baseline methods on three image datasets: VOC, COCO, and AWA. The results are broken down by the percentage of labeled data used (π = 5%, 10%, 15%, 20%) and evaluated using five metrics: Micro-F1, Macro-F1, mAP, Hamming Loss, and One Loss. The best performing model for each metric and dataset is highlighted in boldface, showcasing the relative performance of S2ML2-BBAM compared to existing methods.

This table shows the training time in seconds for each epoch for different methods on the VOC and COCO datasets. It compares the efficiency of S2ML2-BBAM against several baseline methods (SoftMatch, FlatMatch, DRML, CAP). The results show that S2ML2-BBAM is competitive in terms of time efficiency with other SSMLL methods and even faster than SSL methods.
Full paper#



















