↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Training large video transformers is computationally expensive due to the massive number of input tokens. Existing methods to reduce these tokens either introduce significant overhead, decrease accuracy, or lack content-awareness. This necessitates the use of short videos and low frame rates, limiting the potential of video transformers.
The paper introduces Run-Length Tokenization (RLT), a novel content-aware approach to drastically reduce the number of tokens in video transformers. RLT efficiently identifies and removes repetitive patches before model inference, improving training speed by up to 40% and inference throughput by up to 35% on various datasets, while maintaining comparable accuracy. This allows for training on longer videos and higher frame rates, unlocking significant potential for video understanding research.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly accelerates video transformer training and inference, enabling researchers to work with longer videos and higher frame rates. This addresses a major bottleneck in video processing, opening avenues for improved video understanding models and applications. The content-aware approach of Run-Length Tokenization is particularly valuable, making it applicable to various video datasets without extensive hyperparameter tuning.
Visual Insights#
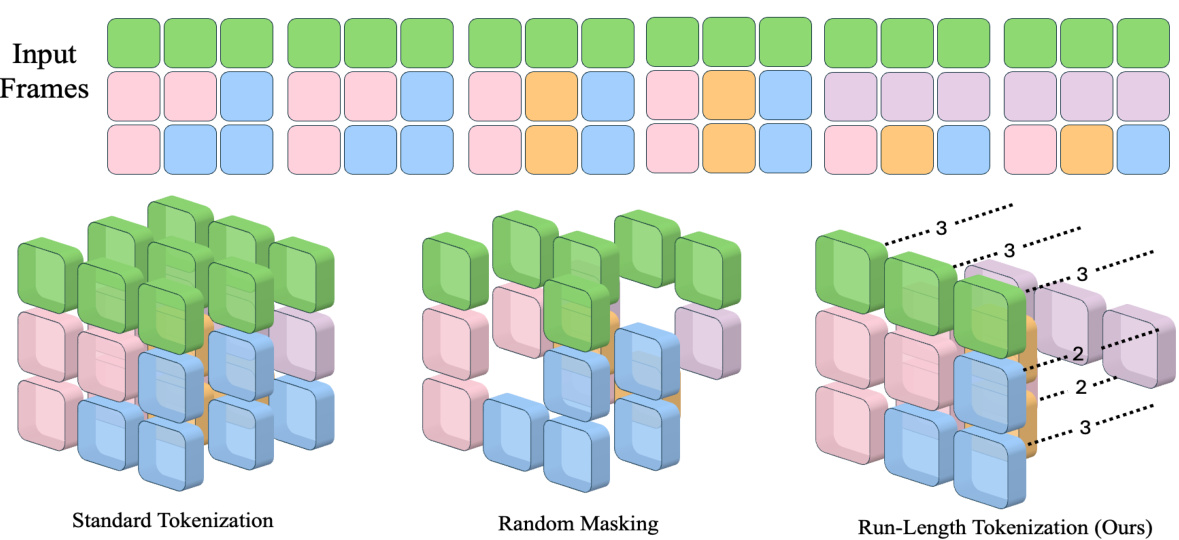
This figure uses a simple example to compare three different video tokenization methods: standard tokenization, random masking, and Run-Length Tokenization (RLT). Standard tokenization divides the video frames into patches of uniform size, creating many tokens, even when many patches are similar. Random masking randomly removes some tokens, but does not address the redundancy in similar patches. RLT, on the other hand, identifies consecutive, similar patches and compresses them into a single token with run-length information. This reduces the number of tokens without sacrificing significant information, making the video transformer training process faster.
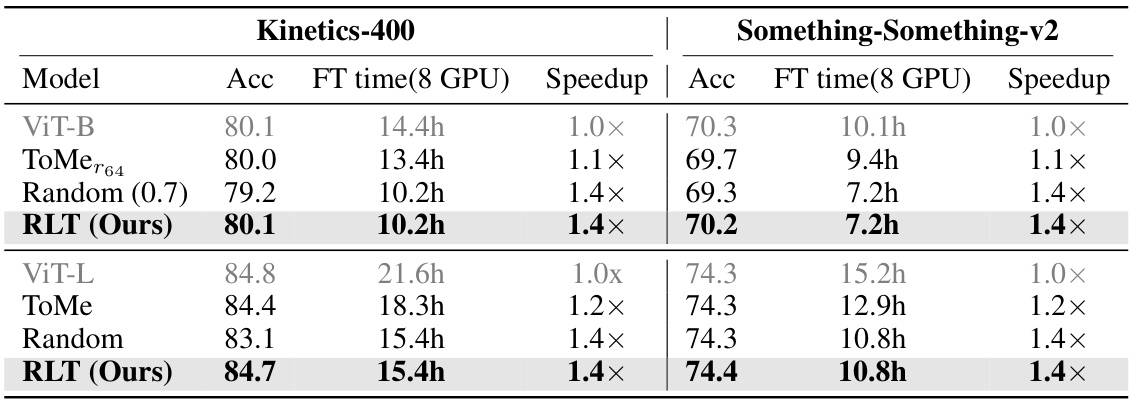
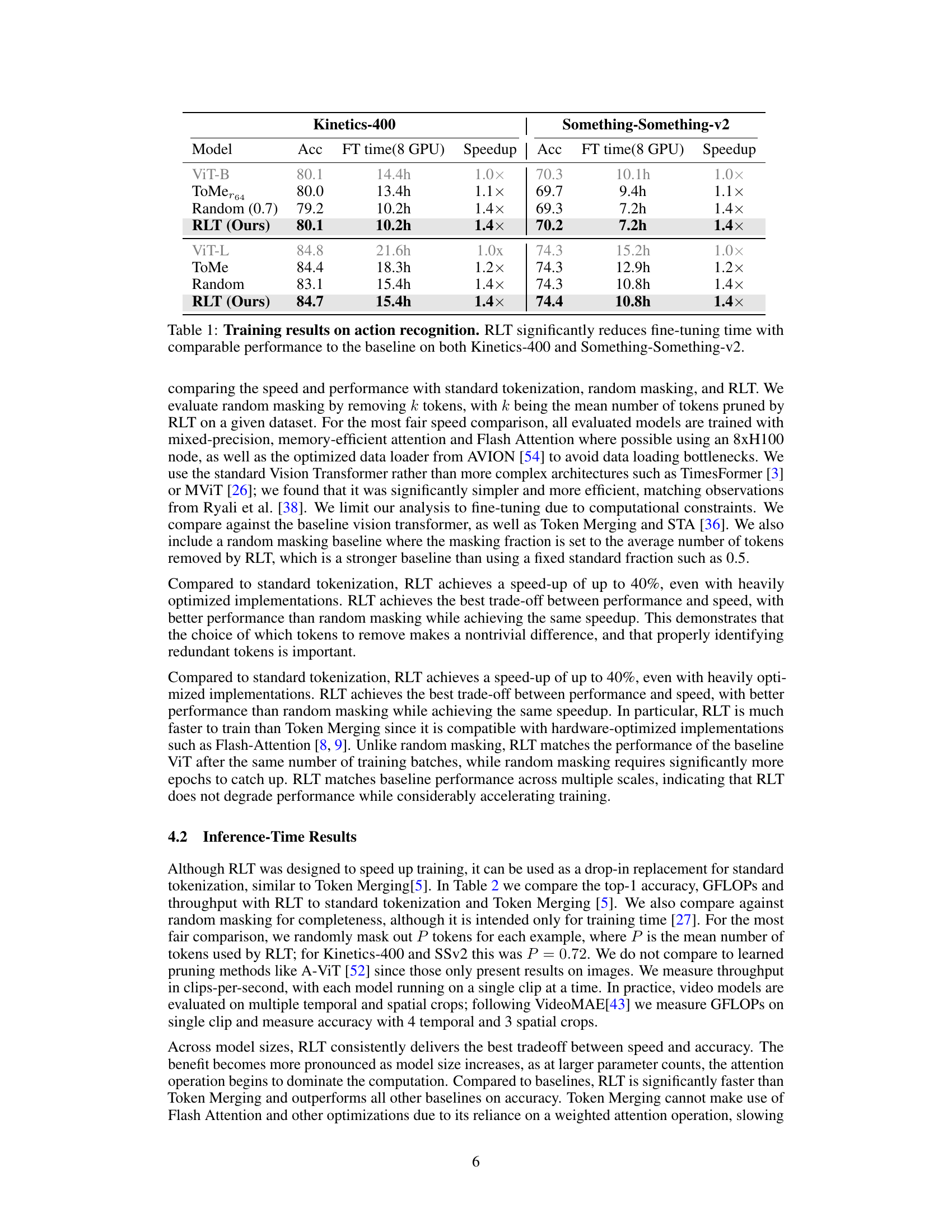
This table presents the results of fine-tuning various video transformers on two action recognition datasets: Kinetics-400 and Something-Something-v2. The models compared are the baseline ViT, ToMe (Token Merging), a random masking baseline, and the proposed RLT method. For each model and dataset, the table shows the achieved accuracy and the fine-tuning time on 8 GPUs. The speedup factor is calculated relative to the baseline ViT. The results demonstrate that RLT achieves comparable accuracy to the baseline while significantly reducing the fine-tuning time.
In-depth insights#
RLT: Core Idea#
The core idea behind Run-Length Tokenization (RLT) is to efficiently reduce the number of input tokens in video transformers by leveraging temporal redundancy. Instead of treating each video frame patch independently, RLT compares consecutive patches and identifies runs of nearly identical patches. These redundant patches are then replaced by a single representative patch and its run-length, significantly reducing the input size without sacrificing too much accuracy. Content-awareness is key; unlike methods that remove a fixed number of tokens, RLT’s reduction is adaptive to the video’s content, achieving substantial compression in static scenes while retaining information in dynamic parts. This approach leads to faster training and inference, making video transformer models more efficient and scalable for longer videos and higher frame rates. The elegance lies in its simplicity and low computational overhead, making it a practical and potentially impactful improvement to existing video tokenization strategies.
RLT: Speed Boost#
The heading “RLT: Speed Boost” suggests a section dedicated to showcasing the speed improvements achieved by the Run-Length Tokenization (RLT) method. A thoughtful analysis would delve into the specifics of these speed gains, examining how RLT reduces computational costs. Key aspects to examine include the reduction in the number of input tokens, potentially through the identification and removal of redundant information, which directly impacts the computational complexity of transformer networks. The analysis should also quantify the speed improvements reported (e.g., percentage increase in throughput, training time reduction), and compare RLT’s performance against baselines (standard tokenization, other token reduction techniques). A deeper dive would explore the trade-off between speed and accuracy, determining if the speed gains come at the cost of significant performance degradation. Finally, it is crucial to analyze if the benefits of RLT are consistent across different datasets and video characteristics (e.g., high-action vs. static videos) and model architectures.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In this context, a thorough ablation study would investigate the impact of removing specific elements of the proposed run-length tokenization (RLT) method. This could include analyzing the impact of removing the length encoding, examining the effect of varying the threshold for identifying redundant patches, and assessing the effectiveness of RLT when combined with other optimization techniques. The results would quantify the importance of each component and demonstrate the overall effectiveness of the RLT strategy in improving the speed and accuracy of video transformers. A well-designed ablation study is crucial for establishing the robustness and efficacy of RLT, clarifying which aspects are essential to its functionality and which can be potentially modified or removed without significant performance degradation. Analyzing the results across different datasets and video characteristics would strengthen the conclusions, revealing if the contributions of the RLT components vary based on specific input properties.
High FPS Videos#
The analysis of high FPS videos in the context of the research paper reveals crucial insights into the efficiency of the proposed Run-Length Tokenization (RLT) method. High frame rates dramatically increase the number of input tokens in video transformers, posing a significant computational challenge. RLT’s effectiveness in mitigating this challenge by reducing token counts is especially pronounced at high FPS. The results demonstrate substantial speed-ups in training and inference for high-FPS videos, significantly outperforming traditional methods. This enhancement in efficiency is attributed to RLT’s ability to identify and remove temporal redundancies which are more prevalent in high-FPS videos with less dynamic content. The study highlights the scalability of RLT, making it a promising technique for handling the increasingly large datasets associated with high-resolution, high-frame rate video data. The content-aware nature of RLT allows it to achieve better compression rates on videos with static or repetitive sequences common in many high FPS recordings, making it a superior technique to generic methods like random masking.
Future of RLT#
The future of Run-Length Tokenization (RLT) appears bright, given its demonstrated success in accelerating video transformer training and inference. Further research could focus on enhancing its content-awareness, perhaps by incorporating more sophisticated methods for identifying and grouping similar patches beyond simple L1 difference. This might involve exploring advanced similarity metrics or leveraging learned representations. Addressing its limitations regarding camera motion and dense vision tasks is crucial. Developing techniques to handle dynamic scenes and integrating RLT with other token reduction strategies (e.g., pruning, merging) could lead to even greater speedups. Exploring RLT’s applicability to other modalities beyond video, such as 3D point clouds or volumetric data, presents another exciting avenue for investigation. Finally, optimizing RLT’s implementation for specific hardware architectures could maximize its performance gains.
More visual insights#
More on figures
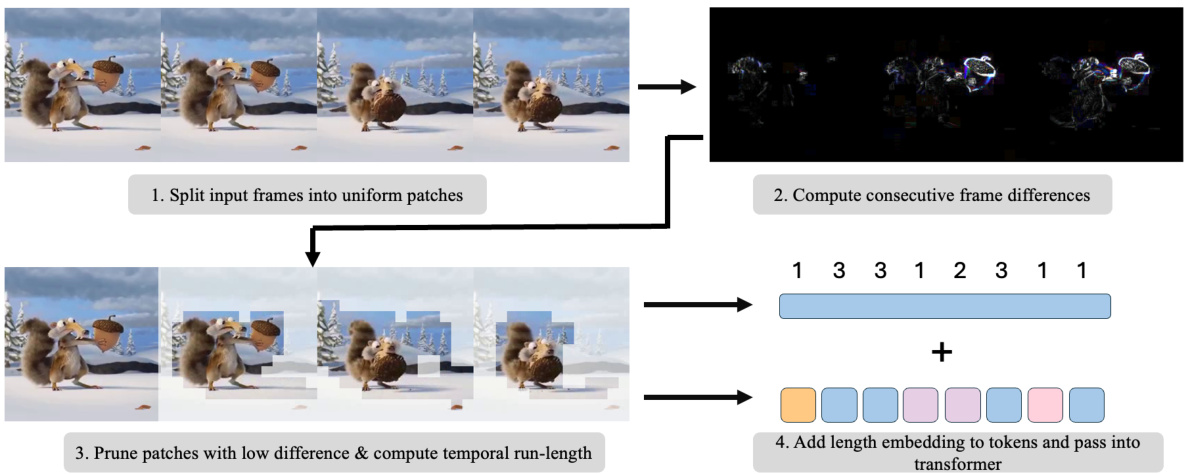
This figure illustrates the Run-Length Tokenization (RLT) process. It starts by splitting input video frames into uniform patches (1). Then, it computes the differences between consecutive frames to identify areas with minimal change (2). Patches with low difference are pruned, and the remaining patches are grouped to calculate their temporal run-length (3). Finally, length embeddings are added to these tokens before passing them into a video transformer (4). This method efficiently reduces the number of input tokens by identifying and removing redundant information.
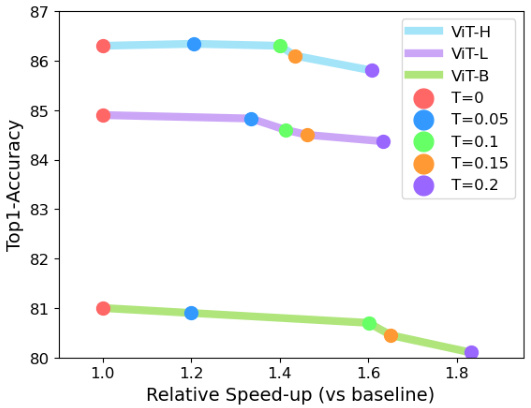
This figure shows the relationship between the relative speedup achieved by using Run-Length Tokenization (RLT) and the Top-1 accuracy of the model on the Kinetics-400 dataset. Different lines represent different model sizes (ViT-B, ViT-L, ViT-H). Each model size is tested with different values of the hyperparameter τ (threshold). The x-axis shows relative speedup compared to the baseline (standard tokenization), and the y-axis represents Top-1 accuracy. The results indicate that RLT achieves a good trade-off between speed and accuracy with lower values of τ, but the accuracy drops significantly when τ is greater than 0.1.

This figure shows four examples of how the Run-Length Tokenization (RLT) method identifies and removes redundant image patches in video sequences. The patches that are removed due to redundancy are shown in gray. The top example shows a video sequence with a mostly static background, where RLT effectively removes the redundant background patches and only retains the changing elements. The bottom examples show varying levels of motion in the video sequences; RLT removes fewer patches where there is significant motion.

This figure shows the effect of the hyperparameter tau (τ) on the performance of Run-Length Tokenization (RLT). Different rows represent different values of τ, ranging from 0 to 0.2. Each row displays a sequence of video frames, with the grayed-out patches indicating those removed by RLT at that particular τ value. At low τ values, only the most obviously redundant patches are removed, preserving most information. As τ increases, more and more patches are removed, leading to more aggressive compression but potentially losing more information, particularly when subtle movements are present.

This figure shows example visualizations of how the Run-Length Tokenization (RLT) method works. The grayed-out sections represent tokens that have been compressed due to redundancy (unchanging content across frames). The top example highlights how RLT effectively removes redundant background tokens while preserving dynamic elements. The bottom example shows a scenario with significant camera or subject motion, resulting in less compression because fewer tokens are considered redundant.
More on tables
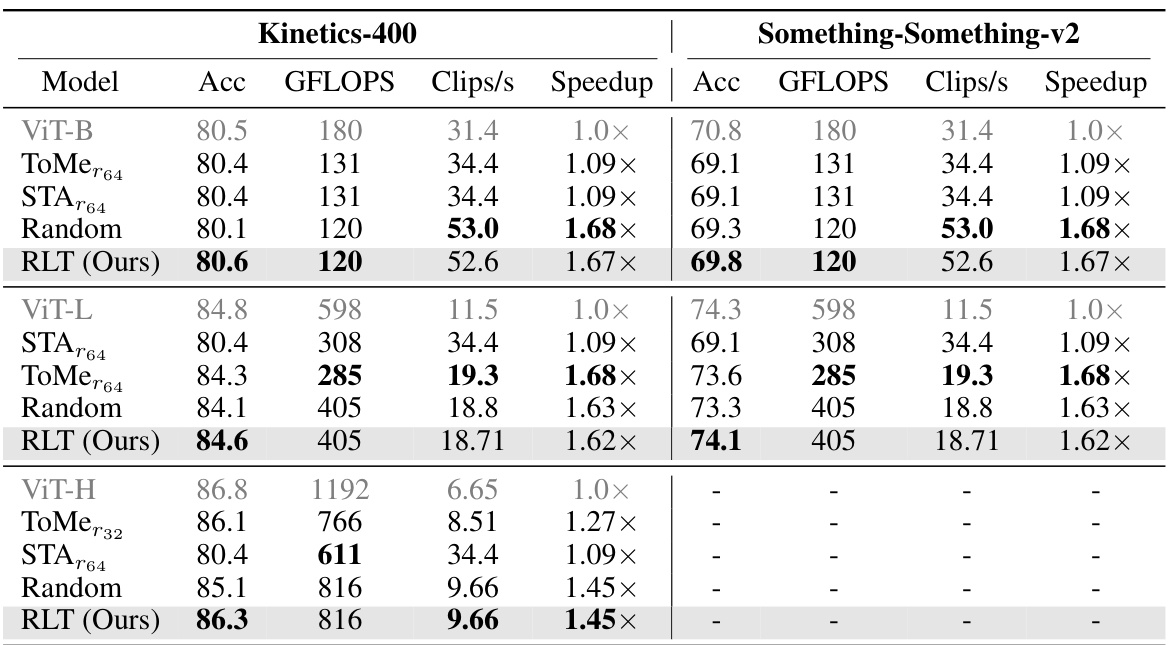
This table presents the inference-time results of different video transformer models on Kinetics-400 and Something-Something-v2 datasets. It compares the top-1 accuracy, GFLOPs (floating-point operations), clips per second (throughput), and speedup relative to the baseline ViT model for standard tokenization, Token Merging, STA, Random Masking, and the proposed RLT method. The results show that RLT achieves a good balance between accuracy and speed, outperforming other methods in many cases.
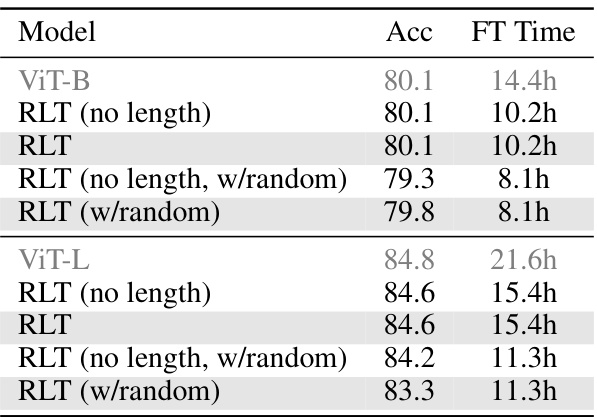
This table presents the training results of different models on two action recognition datasets: Kinetics-400 and Something-Something-v2. It compares the standard ViT model against variations using Run-Length Tokenization (RLT), with and without random masking. The table shows the accuracy achieved and the fine-tuning time for each model on both datasets. RLT demonstrates significant time reduction with comparable accuracy.
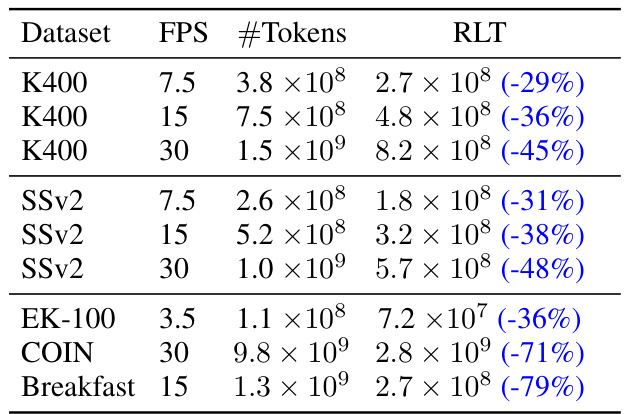
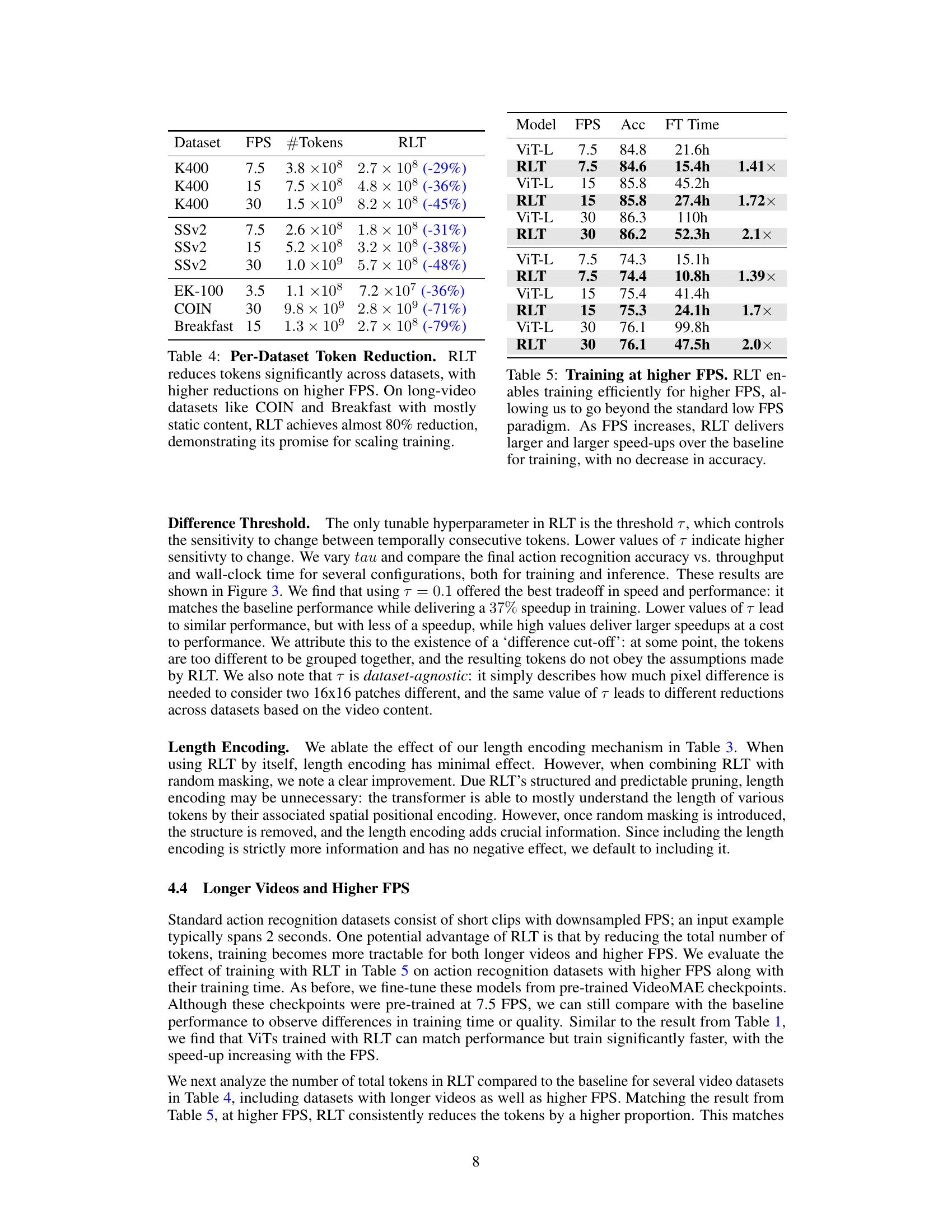
This table shows the number of tokens before and after applying the Run-Length Tokenization (RLT) method on various datasets at different frame rates (FPS). The percentage reduction in tokens achieved by RLT is also presented, highlighting its effectiveness in reducing computational cost, especially for longer videos with many static frames. Notice that the token reduction is more significant at higher FPS and on datasets with significant amounts of static content.
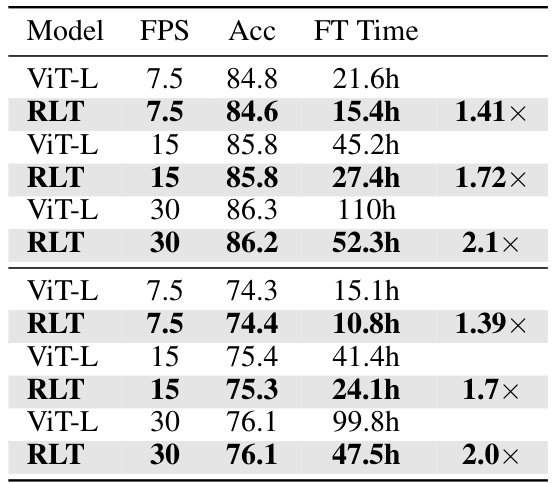
This table presents the results of training video transformers on two action recognition datasets: Kinetics-400 and Something-Something-v2. It compares the performance and training time of four different models: the baseline ViT-B and ViT-L, and versions of these models that incorporate the proposed Run-Length Tokenization (RLT) method. The table shows that RLT significantly reduces the training time (wall-clock time) without a significant drop in accuracy, demonstrating the method’s effectiveness in accelerating the training process of video transformers.
Full paper#