↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current models for inferring 3D shape from shading often produce single-mode outputs, failing to capture the inherent ambiguities and multistable perceptions experienced by humans. This limitation hinders the development of truly human-like 3D vision systems.
This work presents a novel approach that addresses these shortcomings. By using a small, patch-based denoising diffusion process and incorporating inter-patch consistency constraints, the model successfully generates multimodal distributions of shapes, reflecting the multistable nature of shape perception in ambiguous cases. The model’s relatively low computational cost and impressive generalization capabilities to novel images showcase its potential for practical applications in 3D vision.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and cognitive science. It introduces a novel approach to modeling human perception of ambiguous shapes, offering a more efficient and realistic alternative to traditional methods. This opens new avenues for developing more robust and human-like 3D shape perception systems. Its efficiency, based on a small diffusion process, makes it highly practical for real-world applications.
Visual Insights#

This figure demonstrates the multistable nature of shape from shading. Multiple 3D shapes can produce the same 2D shading image, depending on the lighting conditions. The figure shows an example of a shape that can be interpreted as either convex or concave, illustrating the ambiguity humans experience. It also compares the results of the proposed model with other state-of-the-art methods that generally produce a single shape estimate (unimodal distribution), highlighting the advantage of the proposed model in capturing the multimodal distribution of shape interpretations.

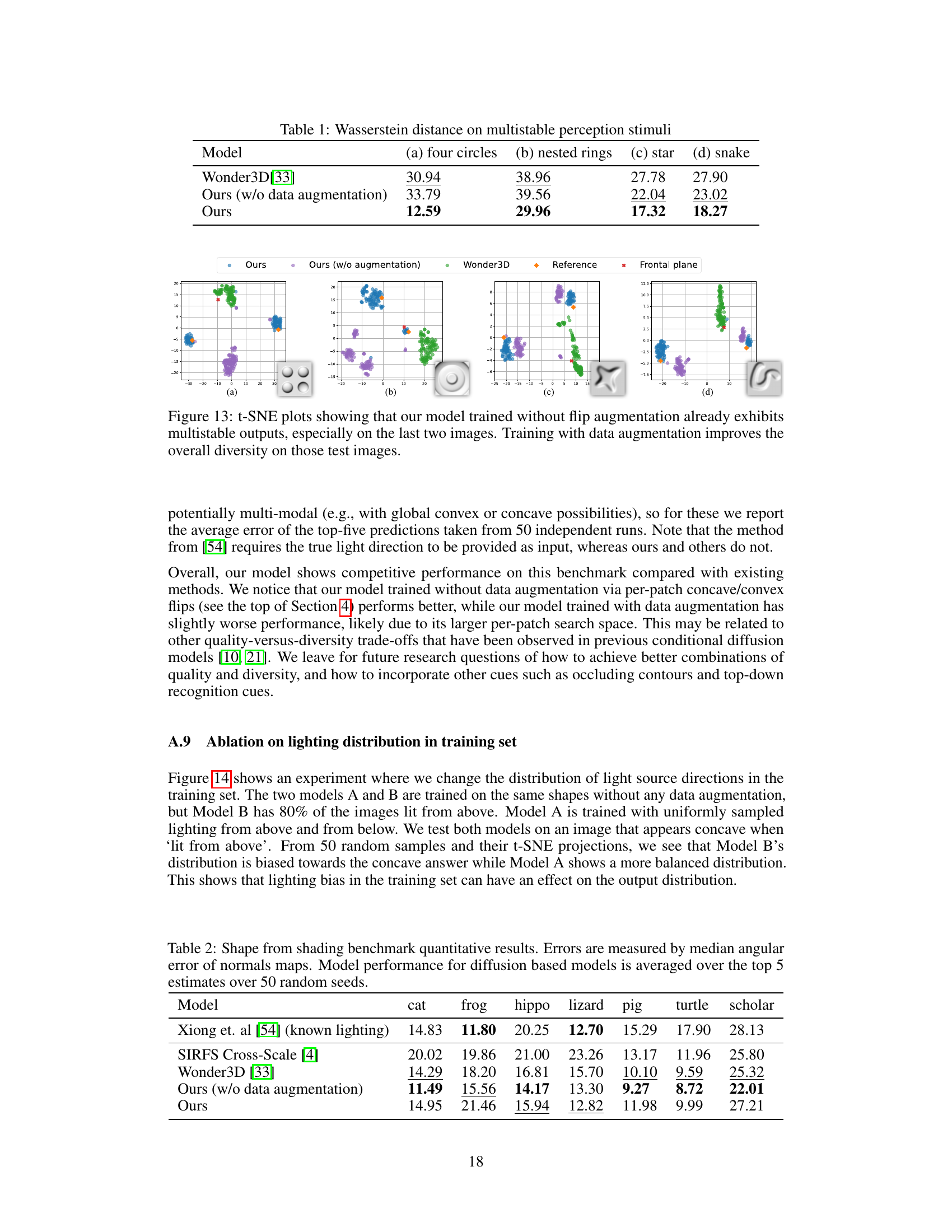
This table presents a comparison of Wasserstein distances achieved by different models on four multistable perception stimuli. The Wasserstein distance is a measure of the dissimilarity between probability distributions, reflecting how well each model captures the multimodality inherent in human perception of ambiguous shapes. Lower values indicate better performance in capturing the multiple possible interpretations.
In-depth insights#
Multistable Perception#
Multistable perception, the phenomenon where the same sensory input can result in multiple distinct interpretations, is a key focus of the paper. The authors leverage this inherent ambiguity in shape from shading, demonstrating how a single image can evoke multiple, valid 3D shape interpretations in human observers. Their model mimics this multistability by generating a multimodal distribution of shape explanations rather than a single, point estimate. This aligns with the human experience, contrasting sharply with deterministic models which often produce a single, often inaccurate, interpretation. The study’s success in replicating multistable perception suggests that incorporating stochasticity and modeling ambiguity is crucial for creating a more accurate and human-like 3D shape perception system. The paper’s patch-wise diffusion process, with its inter-patch consistency constraints and multiscale sampling, is critical to its ability to capture global shape ambiguities in line with human perception, suggesting new avenues for more efficient and human-aligned AI systems.
Patch Diffusion Model#
The core idea behind a hypothetical ‘Patch Diffusion Model’ for shape from shading involves leveraging the strengths of both diffusion models and local patch processing. Instead of processing an entire image at once, the model operates on smaller patches, which reduces computational complexity and allows for parallel processing. Each patch would be treated as an independent unit, learning to generate surface normals using a diffusion process conditioned on the local shading information. Crucially, to avoid fragmented, inconsistent results, inter-patch consistency constraints are essential, potentially incorporating curvature smoothness or integrability to enforce global coherence. This approach is particularly promising for handling multistable shapes since local ambiguities can be resolved by considering relationships between neighboring patches. The model’s ability to generate multimodal distributions of plausible shape interpretations directly addresses inherent ambiguities in shape from shading, aligning with human perception. Multi-scale processing, incorporating information from multiple patch resolutions, would improve robustness and capture shape details across different scales. Ultimately, a well-designed ‘Patch Diffusion Model’ could offer a more efficient and perceptually accurate method for 3D shape reconstruction compared to traditional, deterministic approaches.
Multiscale Sampling#
Multiscale sampling, in the context of this research paper, is a crucial technique enhancing the model’s ability to capture both local and global shape features from a shading image. By processing the image at multiple resolutions (scales), the model overcomes limitations of single-scale approaches that may get stuck in local minima during optimization. The multiscale strategy improves robustness and generalization, facilitating the discovery of multiple, plausible shape interpretations. This is particularly important when dealing with ambiguous images, where multiple shapes could explain the observed shading. The integration of multiscale sampling with guided diffusion sampling allows for a more comprehensive and efficient exploration of the solution space, significantly improving the quality and diversity of the model’s output. The ‘V-cycle’ approach, inspired by Markov random fields, efficiently coordinates the sampling across scales, ensuring global consistency while preserving local detail. This iterative refinement process helps the model converge to more globally coherent solutions, mimicking the human visual system’s ability to perceive multistable shapes.
Lighting Consistency#
The concept of lighting consistency in the context of this research paper is crucial for resolving the inherent ambiguities in shape-from-shading problems. The authors acknowledge that perfectly uniform lighting is an unrealistic assumption. Instead, they propose a novel approach that guides the diffusion process with a weak constraint on lighting consistency. Each patch suggests a dominant light direction, and patches then adapt their concave/convex interpretations based on these nominations. This approach avoids precise lighting estimation, allowing for multiple interpretations while promoting global coherence. The authors show that this weak constraint significantly improves the model’s ability to capture the multistable perception of ambiguous images, aligning more closely with human experience and demonstrating an advantage over deterministic approaches that commit to single interpretations. This subtle yet effective strategy demonstrates a key advancement in the approach, moving beyond simplifying assumptions to create a model that is both efficient and better reflects the complexities of human visual perception.
Future Directions#
Future research could explore several promising avenues. Extending the model to handle more complex lighting conditions and materials is crucial for real-world applicability. The current Lambertian shading assumption, while useful for studying fundamental ambiguities, limits generalization to diverse scenes. Incorporating other cues like texture and reflections, possibly through a multi-modal approach integrating image features with the diffusion model, would enhance robustness and accuracy. Investigating more sophisticated multi-scale optimization techniques beyond the current V-cycle method would improve efficiency and avoid local minima during the sampling process. Exploring alternative architectures for stochastic 3D shape perception, perhaps inspired by human visual processes, could yield more efficient and biologically-plausible models. Finally, a deeper investigation into the interplay between bottom-up (data-driven) and top-down (knowledge-based) processing could lead to a more holistic model of 3D shape perception, better aligned with human capabilities.
More visual insights#
More on figures
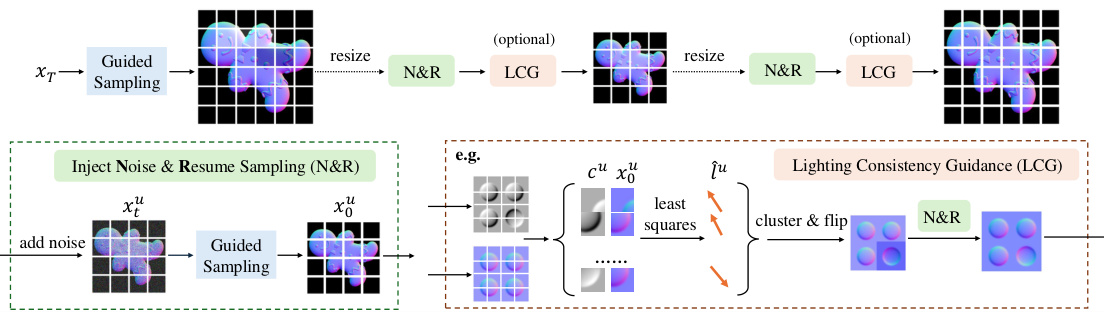
This figure shows a schematic of the proposed multiscale patch diffusion model. (a) Training: The model is trained using cropped patches from synthetic images of everyday objects and their corresponding normal fields. A small diffusion model learns to denoise the normal field given the patch’s intensity and a random sample. (b) Inference: During inference, the model is applied to non-overlapping patches in parallel. Inter-patch consistency constraints are used to guide the diffusion process to minimize curvature smoothness and integrability losses. This multi-scale approach allows the model to capture global ambiguities in the shading image.
This figure illustrates the multiscale sampling process used in the model. A V-cycle approach is used, iteratively refining the predictions at different scales (fine-to-coarse-to-fine). The ‘Inject Noise & Resume Sampling (N&R)’ step injects noise into an earlier timestep and then resumes the sampling process at that scale. Additionally, the ‘Lighting Consistency Guidance (LCG)’ step uses a global constraint on lighting to help coordinate the predictions across patches.

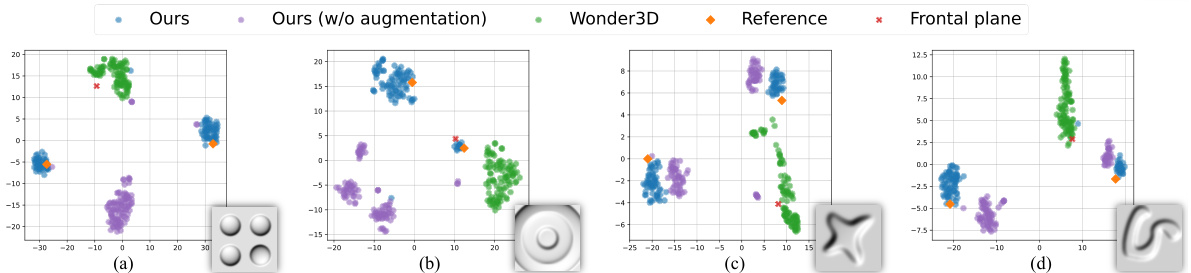
This figure shows ablation studies and a comparison to human perception. The left part demonstrates the importance of each component (random sampling, single-scale spatial consistency, multi-scale spatial consistency, and lighting consistency) in achieving multistable perception. The right part compares depth cross-sections from the model’s convex mode with those reported from human subjects, showing a qualitative similarity.

This figure compares the performance of the proposed model with several state-of-the-art methods on various synthetic test surfaces with ambiguous shapes (convex/concave). The results demonstrate that the proposed model produces more accurate and diverse reconstructions compared to existing methods, highlighting its ability to capture the multistability of shape perception.
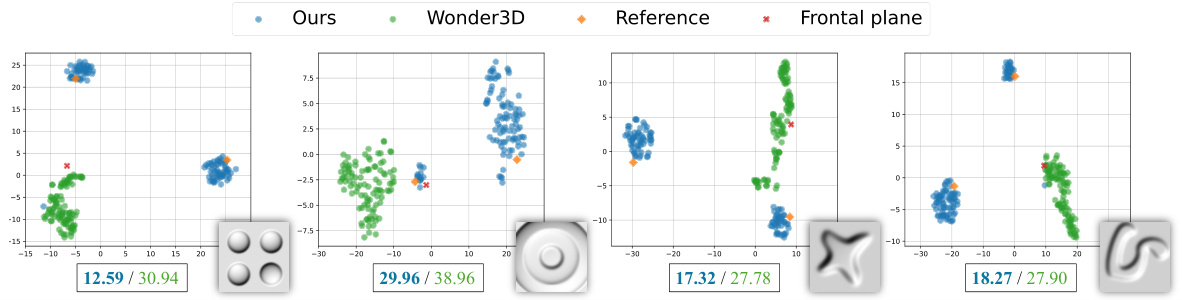
This figure compares the performance of the proposed model and Wonder3D in generating normal field samples for ambiguous shapes. t-SNE plots visualize the distribution of 100 samples from each model, alongside the two theoretically possible normal distributions (under directional lighting) and a flat surface. The Wasserstein distance, a measure of the difference between the sample distributions and the reference distribution, is reported for each model. The results show that the proposed model is more accurate and encompasses both possible interpretations, while Wonder3D’s samples are less diverse and less accurate.

This figure shows the results of applying the model to real-world ambiguous images. (a) demonstrates the impact of enforcing lighting consistency on the multistability of the ‘plates’ image. (b) showcases the model’s generalization ability to various lighting conditions and surface properties (matte vs. glossy) by producing plausible multistable interpretations for real-world images.

The figure shows qualitative and quantitative results of the proposed model on real images from the web and from a shape from shading dataset [54]. The left part shows reconstructed normals and depth maps for a real image with comparisons against ground truth. The right part shows the median angular error between model predictions and ground truth normals for multiple images and compares this error against existing methods.

This figure presents ablation studies and a comparison of the model’s output to human perception. The left side shows the effect of removing individual components of the model (multi-scale sampling, spatial consistency, lighting consistency). The right side shows depth cross-sections from the model’s output compared to cross-sections from human perception studies, highlighting the similarity of relief-like variations.

This figure compares the performance of the proposed model against other state-of-the-art methods on synthetic test images. Each row shows a different test image and its corresponding depth map generated by each method. The ‘Reference’ column shows the ground truth shapes used to render the input images. The results highlight the superior accuracy and diversity of the proposed model in capturing various reconstructions compared to existing methods.
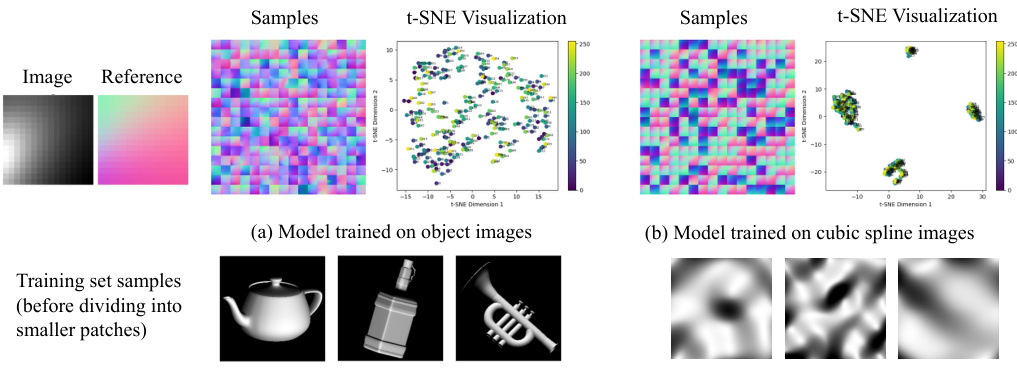
This figure compares the results of applying the model to a small image of a perfectly quadratic surface, once trained on images of everyday objects and once trained on images of cubic spline surfaces. When trained on the spline surfaces, the results tightly cluster around the four theoretically possible interpretations of such an image (convex, concave, and two saddle shapes). When trained on everyday objects, the model produces more diverse results, showing the influence of the training data on the model’s ability to interpret ambiguous shading.

This figure compares the results of different shape-from-shading models on two ambiguous images. The first row shows images from Kunsberg and Zucker (2021) that can be interpreted as either convex or concave shapes. The second row displays an image from Nartker et al. (2017) of small bumps, which also has multiple possible interpretations. For each image, the figure shows the normal maps produced by the authors’ model (Ours), Wonder3D, SIRFS, Derender3D, Marigold, and Depth Anything. The different models produce varied interpretations, showcasing the ambiguity inherent in shape-from-shading and demonstrating the authors’ model’s ability to capture multiple interpretations.

This figure compares the results of different shape reconstruction models on various synthetic images with directional lighting. Each image has an ambiguous interpretation (convex or concave). The ‘Reference’ column shows the ground truth shapes used to render the images, illustrating the ambiguity. The ‘Ours’ column showcases the model’s reconstructions, highlighting its ability to generate multiple interpretations, accurately representing the multimodal nature of human perception in ambiguous situations. In contrast, other models produce less accurate and less diverse output, often failing to capture the full range of possibilities.
This figure compares the results of applying the proposed model to a 16x16 image of an exactly quadratic surface under directional lighting. Two training scenarios are shown: one using images of spline surfaces, and another using images of everyday objects. The t-SNE visualizations show that when trained on spline surfaces, the model’s outputs cluster around four distinct mathematical interpretations (convex, concave, and two saddle shapes), aligning with theoretical predictions. However, when trained on everyday objects, the outputs exhibit greater diversity, suggesting that the model’s learned representation is more nuanced and less constrained by this specific mathematical case.

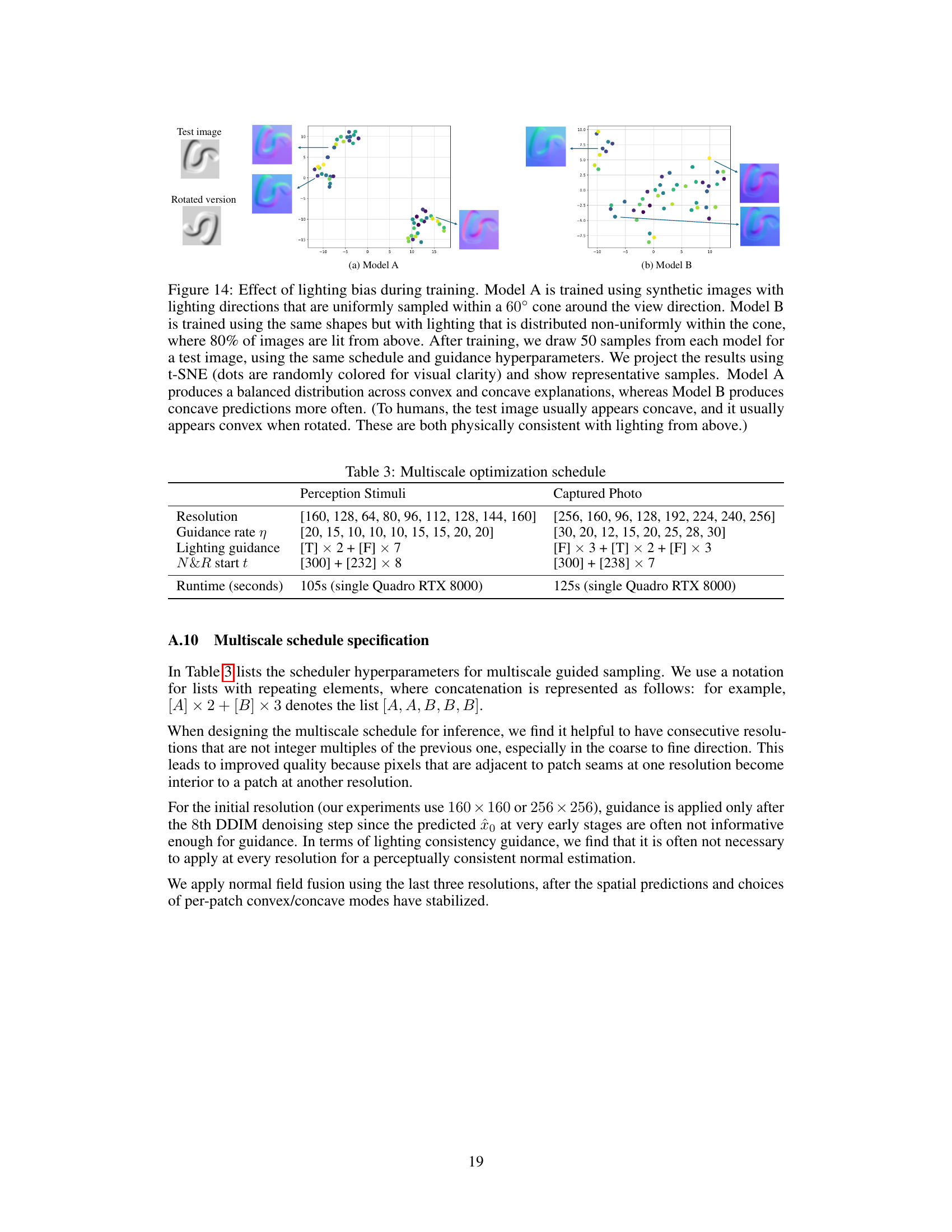
This figure shows the ablation study on lighting distribution in the training set. Two models are trained with different lighting distributions: Model A with uniform lighting and Model B with 80% of images lit from above. The t-SNE plots and samples demonstrate how the lighting bias in the training data affects the model’s ability to generate both convex and concave interpretations of ambiguous shapes. Model A produces a more balanced distribution, while Model B shows a bias towards concave interpretations, highlighting the influence of training data on model behavior.
More on tables

This table presents a quantitative comparison of different shape from shading models on a benchmark dataset. The models are evaluated based on the median angular error of their normal field predictions. The error is calculated as the angle between the predicted normal and the ground truth normal at each pixel. The results are averaged across the top 5 predictions from 50 independent model runs for the diffusion-based models, reflecting the inherent stochasticity of these approaches.

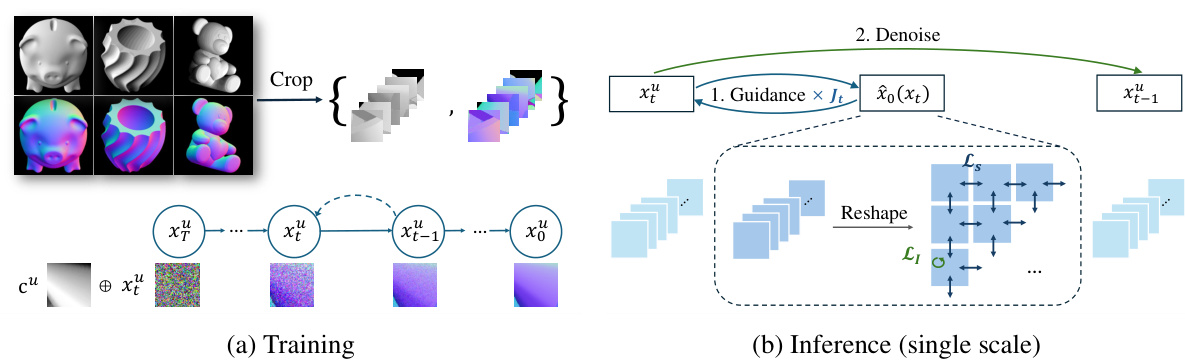
This table presents the multiscale optimization schedule used in the paper’s experiments. It details the resolution, guidance rate, lighting guidance application, noise injection and resume sampling (N&R) starting timestep, and runtime for both perception stimuli and captured photo experiments. The schedule involves a sequence of resolutions, with parameters adjusted for each resolution to improve the optimization process and balance speed and quality. The use of V-cycle, noise injection, and guidance are explained in the paper.
Full paper#