↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Generative models produce realistic data, potentially contaminating web-scale datasets and influencing future model training. Prior research has explored iterative retraining, but lacked a framework for curated data, which is commonly observed in real-world scenarios, such as user-curated outputs from text-to-image generators. This leads to concerns regarding model stability and potential bias amplification.
This paper introduces a theoretical framework for understanding the impact of curated synthetic data on iterative generative model training. The authors show that the expected reward is maximized if data is curated by a reward model and provide theoretical results on the procedure’s stability when real data is included, addressing previous concerns about model collapse. Illustrative experiments support the theory, emphasizing the amplification of biases within the reward model.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the growing issue of synthetic data contamination in large datasets, a significant problem for training future generative models. The study’s theoretical framework and empirical findings provide valuable insights into how data curation affects model behavior, which is essential for researchers developing robust and unbiased generative models. Understanding data curation’s impact also opens doors for new research on bias mitigation and preference optimization in generative AI, further enhancing the field.
Visual Insights#

This figure illustrates the process of data curation in the context of generative models. It shows a user providing a prompt to an AI image generator (Midjourney). The generator produces four images in response. The user selects one of these images to upscale (increase resolution), effectively curating the generated data. Only the upscaled image is then included in the final dataset, which is used for training future generative models. This example demonstrates how human preferences influence the selection of data that is ultimately used for model training.
In-depth insights#
Curated Data’s Impact#
The concept of “Curated Data’s Impact” in the context of generative models is multifaceted. Curation, the human selection of preferred outputs from a generative model, introduces a feedback loop that implicitly optimizes for human preferences. This can lead to significant improvements in model performance, but also has significant drawbacks. The curation process often amplifies biases present in the reward model or the human curators themselves. This can result in models that perpetuate harmful stereotypes or generate outputs that cater to a limited, possibly unrepresentative, set of preferences. Furthermore, curated data may decrease diversity and creativity. While iterative retraining with curated data may converge towards an optimal distribution, it potentially does so at the cost of exploration and unexpected outcomes. Therefore, a nuanced approach to data curation is required, balancing the benefits of improved model performance with the risks of bias amplification and reduced diversity. Careful consideration of the underlying reward function, human biases, and the potential for negative consequences is vital for the responsible development and deployment of generative models.
Iterative Retraining#
Iterative retraining, a process of repeatedly training a generative model on its own generated data, presents both exciting possibilities and significant challenges. Early research highlighted the risk of model collapse, where the model loses diversity and generates only low-quality outputs. However, this paper introduces a novel approach involving data curation. By curating the synthetic data, selecting only high-quality samples based on human preferences or other reward models, the researchers demonstrate that iterative retraining can lead to improved model performance and alignment with desired characteristics. The theoretical analysis provides strong support for these claims, showing how curation implicitly acts as a preference optimization mechanism, increasing the expected reward at each iteration. Incorporating real data alongside curated synthetic data further stabilizes the training process, reducing the risk of collapse and maintaining diversity. Experiments on both synthetic and real-world datasets (CIFAR10) confirm these findings, showcasing both the effectiveness and limitations of the approach, such as the emergence of biases if the curation process is biased. The study’s contributions offer a valuable perspective on the potential of iterative retraining to improve generative models, while emphasizing the necessity of carefully considering the impact of data curation to avoid issues like model collapse and bias amplification.
Reward Optimization#
Reward optimization, a core concept in reinforcement learning, plays a crucial role in aligning artificial agents’ behavior with desired outcomes. In the context of generative models, reward optimization is particularly important for guiding the model towards generating outputs that satisfy human preferences or specific objectives. Effective reward design is critical, as poorly designed rewards can lead to unintended behaviors or model failure. The study of reward functions must account for the complexities of preference elicitation and the potential for reward hacking or manipulation. Data curation, an integral aspect of reward optimization in this domain, involves selecting high-quality samples to improve reward signal and prevent model collapse. Theoretical analysis of iterative retraining, a process involving using model-generated data to refine model parameters, is crucial in evaluating reward optimization strategies and ensuring model stability. Empirical evaluation through experiments with diverse datasets provides a critical check on the effectiveness of reward optimization methods.
Bias Amplification#
Bias amplification in generative models is a critical concern, especially within self-consuming loops where synthetic data is iteratively re-used for training. Curated data, while seemingly improving model quality by reflecting user preferences, can inadvertently exacerbate existing biases. The curation process, often involving human selection based on implicit reward models, amplifies the representation of preferred features. This leads to a skewed distribution of data that overemphasizes certain attributes while suppressing others, thereby amplifying pre-existing biases in the training data. Theoretically, the iterative retraining on curated synthetic data maximizes expected reward but risks model collapse, reduced diversity, and increased bias. Empirically, experiments on image datasets demonstrate this bias amplification. Using confidence scores as a reward disproportionately increases the representation of high-confidence classes. Mitigation strategies must focus on diverse and representative datasets, carefully designed reward functions that avoid bias, and methods for detecting and correcting bias within the iterative training process.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending the theoretical framework to encompass more complex reward models, such as those incorporating multiple reward signals or non-transitive preferences, would significantly enhance its practical applicability. Investigating the impact of different curation strategies on model bias and stability is crucial, given the real-world implications of amplified biases in large language models. Furthermore, empirical analysis on a broader range of datasets and generative models is necessary to validate the theoretical findings and their generalizability. Finally, exploring the integration of data curation techniques with existing model alignment methods, such as reinforcement learning from human feedback, holds significant potential for improving the safety and ethical considerations associated with advanced generative models.
More visual insights#
More on figures

This figure shows the results of an experiment on the CIFAR-10 dataset. The left panel displays the proportion of ‘Airplane’ class images and the proportion of all other classes over 10 retraining iterations. The right panel shows the average reward over the same iterations. The experiment used curated synthetic data, where samples were filtered based on a reward function related to the probability of the classifier for the airplane class. As predicted by Theorem 2.3, the proportion of airplane images increases while the proportion of other classes decreases. The average reward also increases over iterations, as expected.
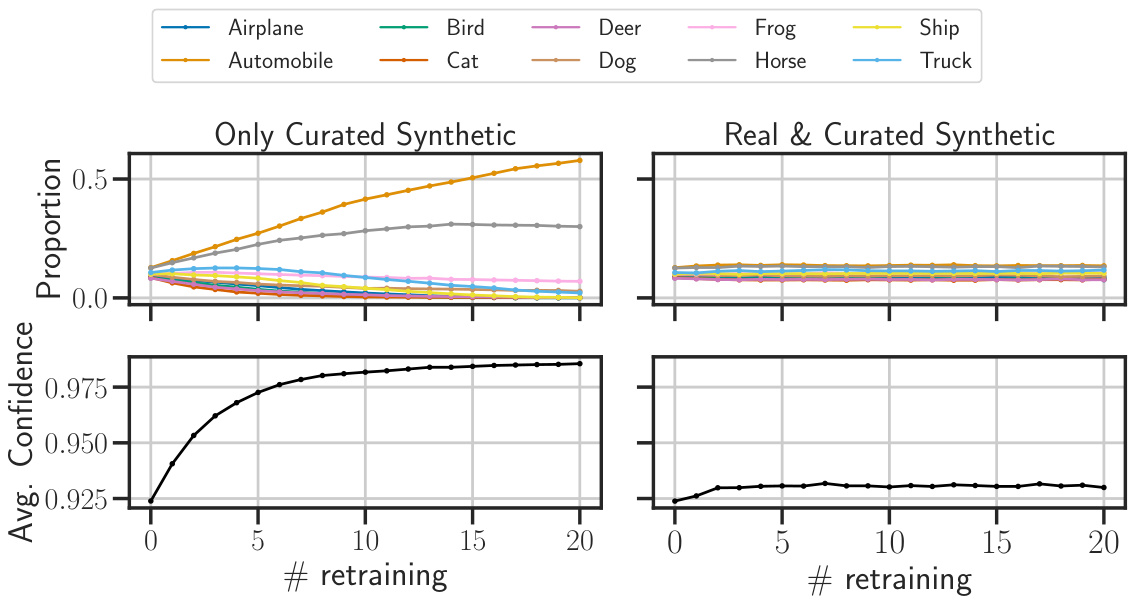
This figure shows the results of experiments on the CIFAR-10 dataset. Two scenarios are compared: one where only curated synthetic data is used for retraining, and another where a mixture of real and curated synthetic data is used. The left-hand side plots show how the proportion of each image class changes over multiple retraining steps when using only curated synthetic data. There is a clear bias amplification where some classes dominate the model’s output. The right-hand side plots show the same experiment but using a mixture of real and curated synthetic data. In this setting, the class proportions remain more stable and the increase of the average reward shows the benefits of this approach.

This figure shows the results of an experiment on a mixture of Gaussian dataset using iterative retraining with and without real data. The top row shows the results when only curated synthetic data is used at each retraining step, while the bottom row shows the results when a mixture of real and curated synthetic data is used. The images show the model’s learned distribution at different iterations.
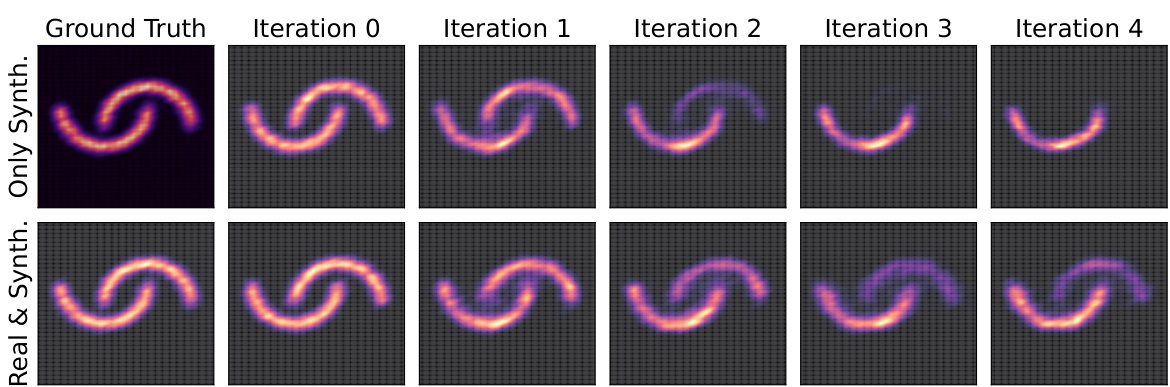
This figure shows the results of an experiment on a ’two moons’ dataset using iterative retraining with and without curated synthetic data. The top row displays the results when only curated synthetic data is used for retraining, demonstrating the model’s tendency to collapse towards high-reward regions. The bottom row shows the results when a mixture of real and curated synthetic data is used. This demonstrates that adding real data helps maintain the diversity and stability of the model, preventing collapse.
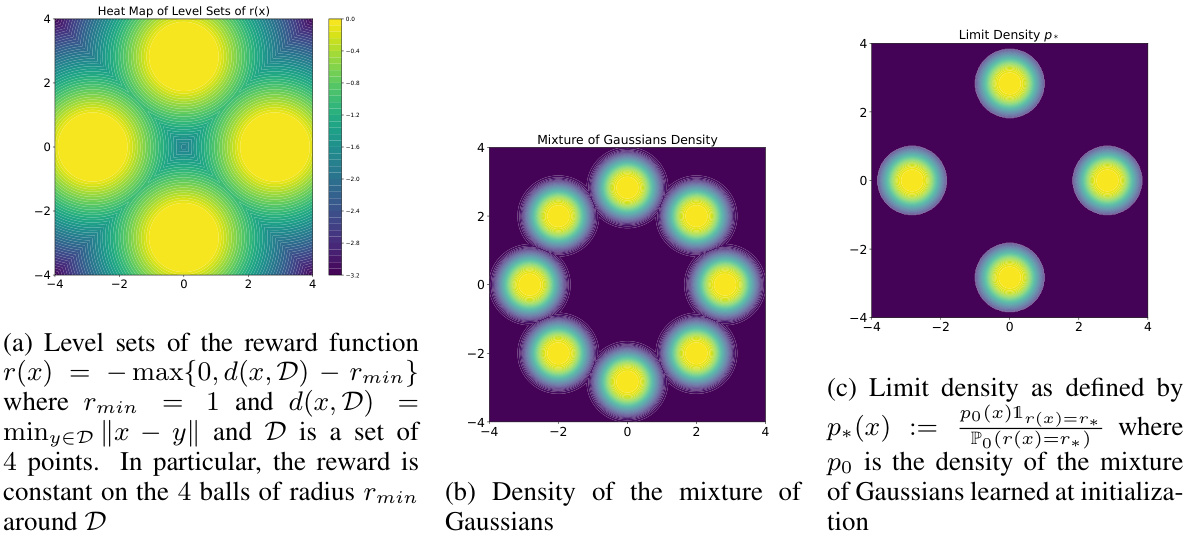
This figure shows three heatmaps. The first heatmap (a) visualizes the level sets of the reward function used in the experiments, which is defined as the negative distance to the closest center of a mixture of Gaussians, clipped to be non-negative. The second heatmap (b) shows the density of the initial mixture of Gaussians distribution used for training. The third heatmap (c) displays the theoretical limit density, as predicted by the theorems in the paper, which is obtained by re-weighting the initial density to maximize the expected reward, focusing on the level sets of the reward function. The figure illustrates the convergence of the iterative retraining process to a distribution concentrated on the highest reward regions.

This figure shows the results of an experiment using the ’two moons’ dataset. The top row illustrates the iterative retraining process using only curated synthetic data, showing a progressive collapse towards a single mode. The bottom row displays the same process, but with real data re-injected at each step, demonstrating increased stability and the preservation of both modes.
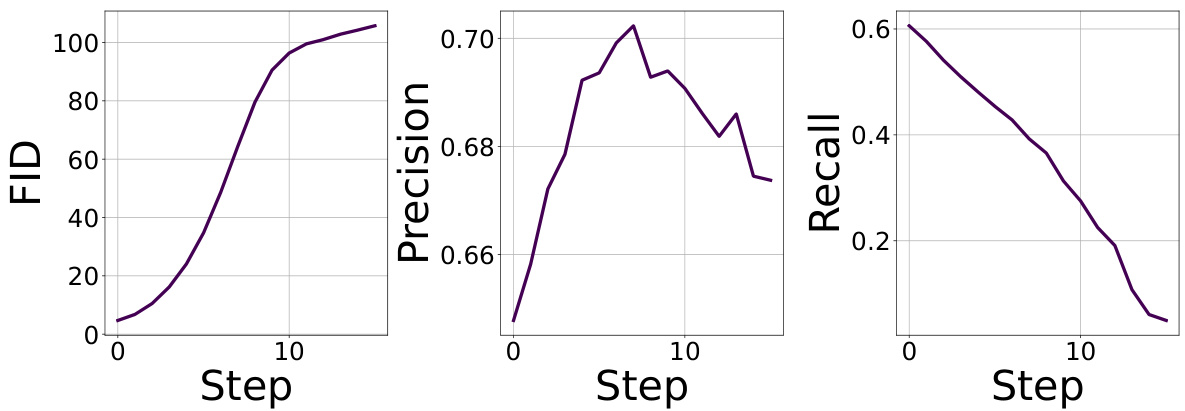
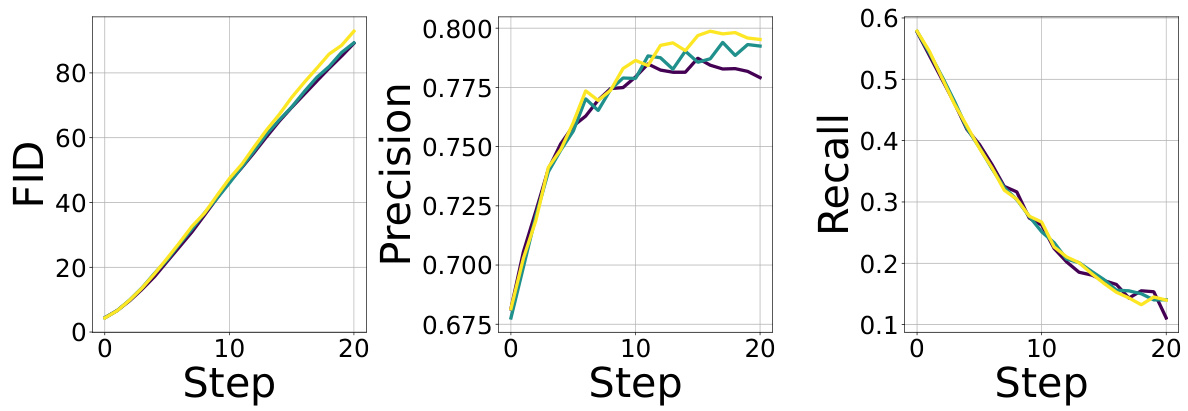
This figure shows the Fréchet Inception Distance (FID), precision, and recall scores across multiple retraining steps when a filtering process is applied to the synthetic data. The reward function used in the filtering process is defined as r(x) = γ · q0(x), where γ = 5, and q0(x) is the probability assigned to class 0 by a classifier. The figure illustrates the impact of the retraining process on the generated data’s quality. High FID indicates poor image quality and low FID indicates higher similarity to real images. Precision and recall show how effectively the filtering selects samples corresponding to the chosen reward function.
This figure shows the results of experiments on the CIFAR-10 dataset. The left panel shows the effect of retraining a model solely on curated synthetic data, where the reward is based on classifier confidence. This leads to an increase in the average reward but also to a skewed distribution of classes, indicating bias amplification. The right panel demonstrates the effect of retraining on a mixture of real and curated synthetic data. Here, increased stability is observed alongside continued reward augmentation, suggesting that the inclusion of real data mitigates the negative effects of bias amplification observed when using only synthetic data.

This figure shows the FID, precision, and recall scores over 20 retraining steps on the CIFAR-10 dataset. The reward function used for filtering is based on the confidence of a classifier, and real data is re-injected at each step. The results show that the FID remains stable, precision increases and recall remains relatively stable, demonstrating the positive impact of re-injecting real data on stability, in contrast to the instability that can occur when only using curated synthetic data.

This figure shows the results of three independent runs of an experiment on the CIFAR-10 dataset. The experiment involved iteratively retraining a generative model using a filtering process based on classifier confidence as a reward. The top row of plots displays the proportion of each class over multiple retraining iterations for each run. The bottom row shows the average confidence (reward) for the model over the same iterations for each run. The results across the three runs demonstrate high consistency, supporting the study’s claims despite only presenting one run in the main body due to high computational cost.

This figure illustrates the process of data curation in generative models. A user provides a prompt (e.g., a whimsical image description). The model generates four different images based on the prompt. The user then selects only one of these images, often upscaling it to a higher resolution, before it is added to a training dataset. This curation process implicitly reflects user preferences and influences the model’s future generations.
Full paper#



















