↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Vision transformers (VTs) are powerful but computationally expensive. To address this, token sparsification (TS) methods dynamically remove less important information, improving efficiency. However, TS’s dynamism creates a security risk. Adversaries can exploit this by crafting inputs that trigger worst-case performance, maximizing resource consumption. This undermines the model’s availability, impacting real-time applications.
The researchers introduce DeSparsify, a novel adversarial attack targeting TS mechanisms. DeSparsify creates adversarial examples that force the TS method to process all tokens, effectively exhausting resources (GPU memory, processing time, energy). They evaluate DeSparsify on various VTs and TS mechanisms, demonstrating its effectiveness and transferability. They also propose countermeasures to enhance the robustness of TS-based systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it identifies a new vulnerability in vision transformers, a powerful but resource-intensive technology. By demonstrating a novel attack, DeSparsify, it highlights the risks of using token sparsification mechanisms and motivates research towards creating more robust and secure vision transformer models. This directly impacts the safety and reliability of AI systems in various applications, especially in resource-constrained environments.
Visual Insights#

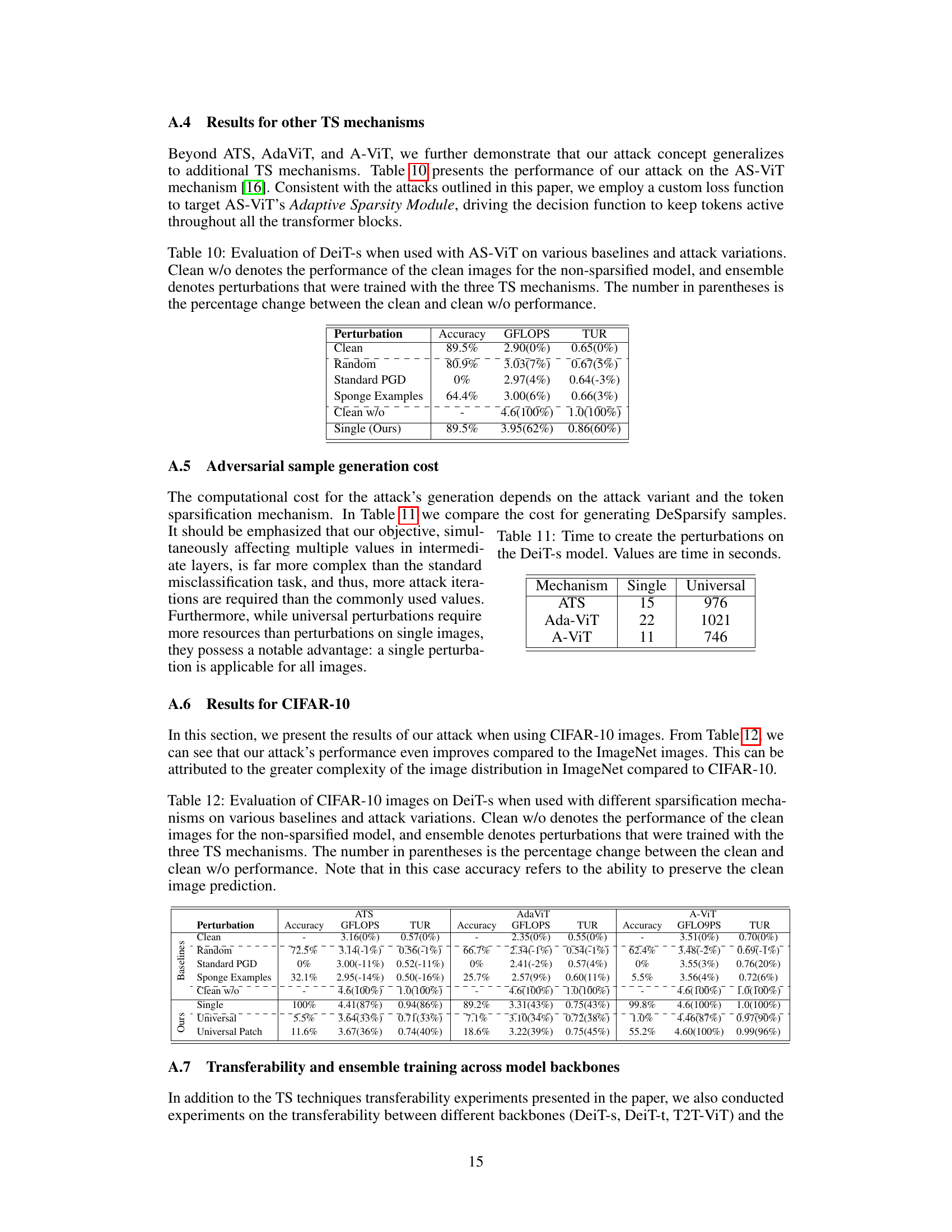
This figure visualizes the token depth distribution across transformer blocks for both clean and adversarial images using three different token sparsification mechanisms: ATS, AdaViT, and A-ViT. The color intensity represents the maximum depth a token reaches before being discarded by the sparsification mechanism. The adversarial image was generated using the single-image attack variant described in section 4.1, designed to trigger worst-case performance by exhausting the system resources. Comparing the clean and adversarial examples shows how the attack impacts token sparsification, which ultimately affects performance.
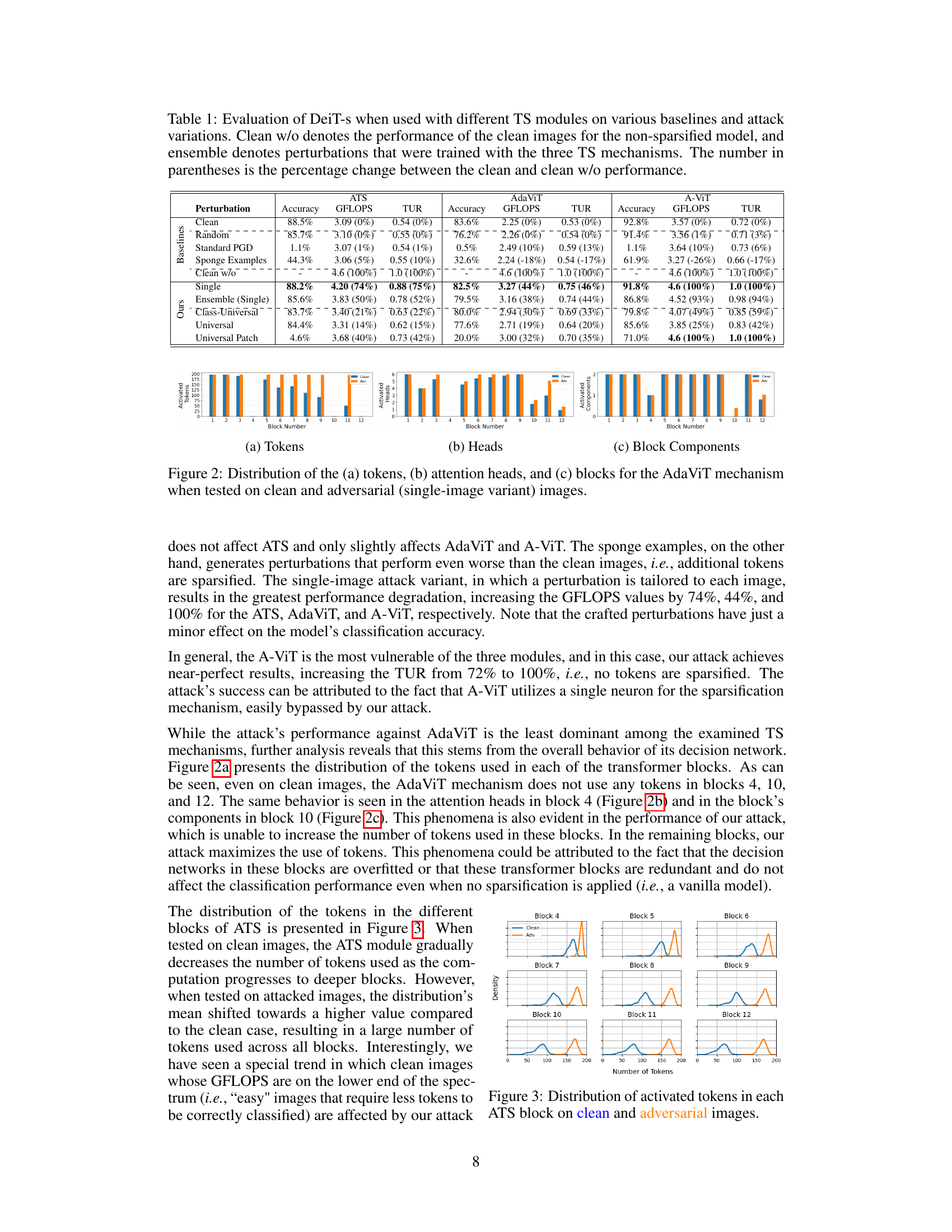
This table presents the results of experiments evaluating the effectiveness of the DeSparsify attack against three different token sparsification (TS) mechanisms: ATS, AdaViT, and A-ViT, when used with the DeiT-s vision transformer model. It compares the performance of various attack methods (single-image, ensemble, class-universal, and universal) against baselines (clean, random, standard PGD, and sponge examples). Metrics include accuracy, GFLOPS, and Token Utilization Ratio (TUR). The table shows the impact of each attack on model performance, including how many tokens were utilized and how much the performance changed compared to the non-sparsified model.
In-depth insights#
Adversarial TS Attacks#
Adversarial attacks against token sparsification (TS) mechanisms in vision transformers are a critical concern. These attacks exploit the inherent dynamism of TS, which adapts to input data, making it vulnerable to carefully crafted adversarial examples. Successful adversarial TS attacks can force the model into worst-case scenarios, dramatically increasing computational cost and resource consumption, potentially leading to denial-of-service conditions. DeSparsify, for instance, is an example attack designed to exhaust system resources. The challenge lies in the design of adversarial examples that force the sparsification mechanism to process all tokens, without significantly altering the model’s original classification, to maintain stealth. This necessitates clever loss functions that balance resource exhaustion with maintaining the original classification. Effective countermeasures are crucial to mitigate this threat; such approaches involve setting upper bounds on token usage or employing more robust sparsification strategies, requiring a balance between efficiency and security.
DeSparsify Attacks#
The DeSparsify attack, targeting vision transformers using token sparsification mechanisms, is a novel adversarial attack. It cleverly manipulates input data to exhaust system resources, forcing the model to process all tokens instead of efficiently discarding less relevant ones. This approach achieves stealth by preserving the model’s original classification accuracy, making detection challenging. The attack’s effectiveness is demonstrated across various token sparsification mechanisms, transformer models and attack variants. Countermeasures involving setting upper bounds on token usage and employing robust resource management strategies are proposed to mitigate the attack’s impact. Transferability analysis reveals the attack’s adaptability across different token sparsification mechanisms, highlighting its broad threat potential.
TS Mechanism Analysis#
A thorough ‘TS Mechanism Analysis’ would dissect the inner workings of token sparsification techniques, comparing their strengths and weaknesses. It would investigate how different mechanisms (e.g., ATS, AdaViT, A-ViT) achieve token selection, analyzing their computational costs, accuracy trade-offs, and vulnerability to adversarial attacks. Key aspects to examine would be the sampling strategies, the impact on model performance, the resource consumption (memory, GPU usage), and the level of stealth achievable. The analysis should also explore the transferability of attacks across different mechanisms, highlighting the robustness and limitations of each approach. A crucial component would be identifying potential attack vectors that could exploit the dynamism and input-dependency of these methods. Finally, the analysis should discuss strategies to enhance the robustness of TS mechanisms against adversarial attacks, and provide insights into the most promising and practical countermeasures.
Attack Countermeasures#
The section on “Attack Countermeasures” would be crucial for evaluating the paper’s practical impact. It should propose and analyze specific, actionable defenses against the described attacks. Effectiveness needs to be demonstrated, ideally through empirical evaluation showing a reduction in the attack’s success rate. The discussion should also address the trade-offs involved. For example, some countermeasures might improve resilience but reduce model accuracy or efficiency. Therefore, a thoughtful analysis of this balance is important. Real-world feasibility is also key; proposed methods should be practical to implement and deploy in real-world systems, not just theoretically sound. The countermeasures’ generalizability across different vision transformer architectures and token sparsification mechanisms should also be considered. Finally, the paper should discuss any limitations of the proposed defenses and potential avenues for future research in developing more robust countermeasures.
Future Research#
Future research directions stemming from this work on adversarial attacks against token sparsification mechanisms in vision transformers could explore several promising avenues. Developing more robust and transferable attacks is crucial, potentially focusing on the development of a unified loss function capable of targeting all TS mechanisms effectively. Investigating the impact of different network architectures and their inherent vulnerabilities to these attacks is essential. Further research could delve into developing more sophisticated countermeasures beyond simple upper bounds on token usage, perhaps incorporating techniques from anomaly detection or reinforcement learning. It would also be valuable to conduct a comprehensive evaluation across a broader range of vision tasks and datasets, and to investigate the effect of these attacks on real-world deployment scenarios, such as autonomous vehicles or IoT devices. Finally, exploring the intersection of this research with privacy concerns related to these attacks and developing strategies for mitigating privacy risks would be important.
More visual insights#
More on figures
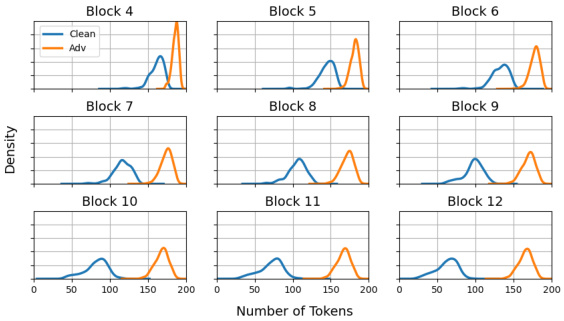
This figure shows the distribution of activated tokens for each of the 9 transformer blocks (block 4 through block 12) in the ATS mechanism. The blue line represents the distribution of tokens used in the clean images, and the orange line represents the distribution of tokens used in the adversarial images created by the DeSparsify attack. The figure shows that the DeSparsify attack increases the number of tokens used in nearly all blocks, especially in the later blocks (block 10 through 12). This illustrates how the attack works to exhaust resources by preventing token sparsification.

This heatmap visualizes the transferability of adversarial examples generated by the DeSparsify attack across different token sparsification mechanisms (ATS, AdaViT, A-ViT). Each cell shows the GFLOPS (giga floating-point operations per second) achieved when a perturbation trained on the mechanism specified by the row is applied to a model using the mechanism specified by the column. The ‘Ensemble’ row shows results when the perturbation is trained on all three mechanisms at once. ‘Clean’ and ‘Clean w/o’ represent performance on clean images with and without sparsification respectively. The darker the color, the more GFLOPS were achieved.
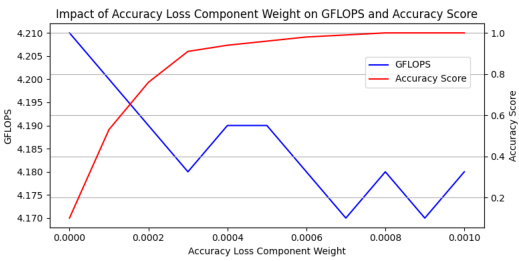
This ablation study shows the impact of the scaling hyperparameter λ (Accuracy Loss Component Weight) on both the GFLOPS (Giga Floating-Point Operations per Second, a measure of computational performance) and the accuracy of the model. The plot shows an optimal λ value exists, balancing model accuracy and increased computational cost induced by the attack. Using too small a λ leads to high computational cost, but low model accuracy, while too large a λ sacrifices some increase in computational cost for good accuracy. The best λ value provides a nearly optimal combination, maximizing computational cost while maintaining good accuracy.

This figure visualizes the adversarial examples generated by different attack methods. The first column shows the original, clean images. Subsequent columns show examples generated by random noise, standard Projected Gradient Descent (PGD), Shumailov’s sponge attack, and four variants of the DeSparsify attack (single-image, ensemble, universal, and universal patch). This allows comparison of the visual differences between adversarial examples generated by various attacks.
More on tables
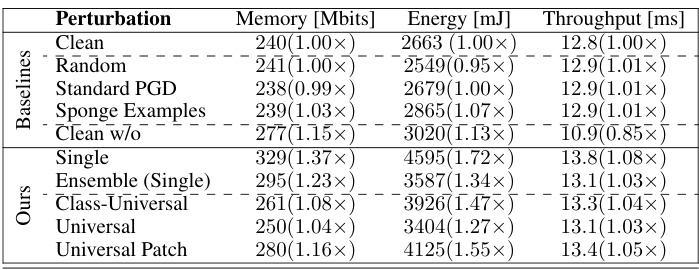
This table presents the results of the different attack methods and baselines, focusing on the impact on GPU hardware metrics. Metrics include Memory (Mbits), Energy (mJ), and Throughput (ms). The results are shown for the ATS token sparsification mechanism, and the values in parentheses indicate the percentage change compared to the clean image performance.
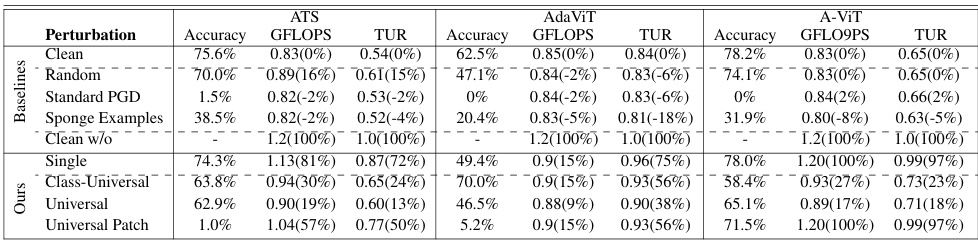
This table presents the results of the DeiT-s model when used with three different token sparsification (TS) mechanisms (ATS, AdaViT, and A-ViT). It compares the performance of various baselines (Clean, Random, Standard PGD, Sponge Examples) and attack variations (Single, Ensemble, Class-Universal, Universal, Universal Patch) on the metrics of Accuracy, GFLOPS, and Token Utilization Ratio (TUR). The ‘Clean w/o’ row shows the performance without token sparsification, providing a baseline for comparison. The numbers in parentheses represent the percentage change in each metric compared to the ‘Clean w/o’ baseline.
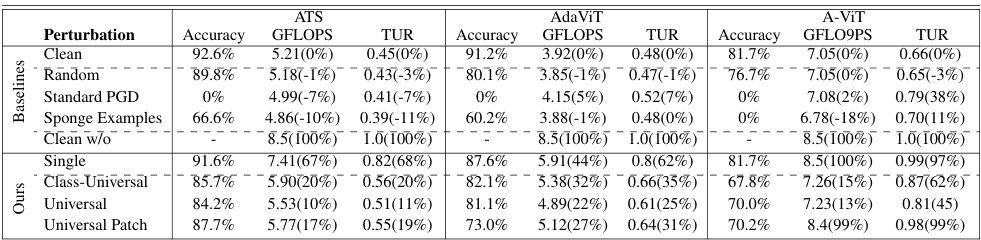
This table presents the results of the DeiT-s model when used with different token sparsification (TS) mechanisms (ATS, AdaViT, A-ViT). It compares the performance of various baselines (clean, random perturbation, standard PGD attack, sponge examples) and different attack variations (single-image, class-universal, universal) of the DeSparsify attack. The metrics used are accuracy, GFLOPS (giga floating-point operations per second), and Token Utilization Ratio (TUR). The numbers in parentheses indicate the percentage change in performance compared to the non-sparsified model.
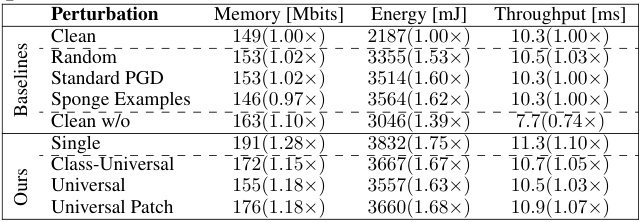
This table presents the results of the attacks and baselines against the ATS token sparsification mechanism in terms of GPU hardware metrics. It shows the memory usage, energy consumption, and throughput for clean images, random perturbations, standard PGD attacks, sponge examples, and the different DeSparsify attack variations (single-image, class-universal, universal, and universal patch). The numbers in parentheses indicate the percentage change compared to the clean images.

This table presents the results of the attacks and baselines in terms of GPU hardware metrics (Memory, Energy, and Throughput) for the Adaptive Token Sampling (ATS) token sparsification mechanism. The metrics are shown for a clean image, random perturbation, standard PGD attack, sponge examples, a clean image without token sparsification, and the different DeSparsify attack variants (single, class-universal, universal, and universal patch). The numbers in parentheses indicate the percentage change compared to the clean image’s performance. It showcases the impact of DeSparsify on GPU resource consumption.

This table presents a comparison of the performance of the DeiT-s model (a vision transformer model) when using different token sparsification (TS) mechanisms (ATS, AdaViT, A-ViT). It compares the performance of different baselines (clean images, random perturbations, standard PGD attack, sponge examples) and different attack variations (single-image, ensemble, class-universal, and universal attacks) against the TS mechanisms. The metrics evaluated include accuracy, GFLOPS (Giga Floating-Point Operations per Second), and token utilization ratio (TUR). The numbers in parentheses show the percentage change in performance compared to a non-sparsified model.

This table presents a comprehensive evaluation of the DeiT-s model’s performance when utilizing different token sparsification (TS) mechanisms. It compares the performance of various baselines (clean images, random perturbations, standard PGD attack, and sponge examples) against different attack variations (single-image, ensemble, class-universal, and universal). The table shows accuracy, GFLOPS (giga-floating-point operations per second), and token utilization ratio (TUR) for each scenario. The numbers in parentheses represent the percentage change in performance compared to the non-sparsified model (Clean w/o).
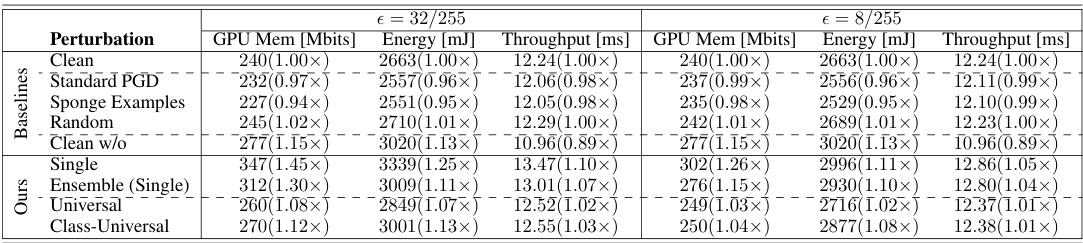
This table presents a comprehensive evaluation of the DeiT-s model’s performance under various conditions using three different token sparsification (TS) mechanisms: ATS, AdaViT, and A-ViT. It compares the performance of the clean images (with and without sparsification), random perturbation, standard PGD attack, sponge examples, and the proposed DeSparsify attack (single-image, ensemble, class-universal, and universal variants). The metrics evaluated include accuracy, GFLOPS, token utilization ratio (TUR), and the percentage change in performance compared to the non-sparsified model.

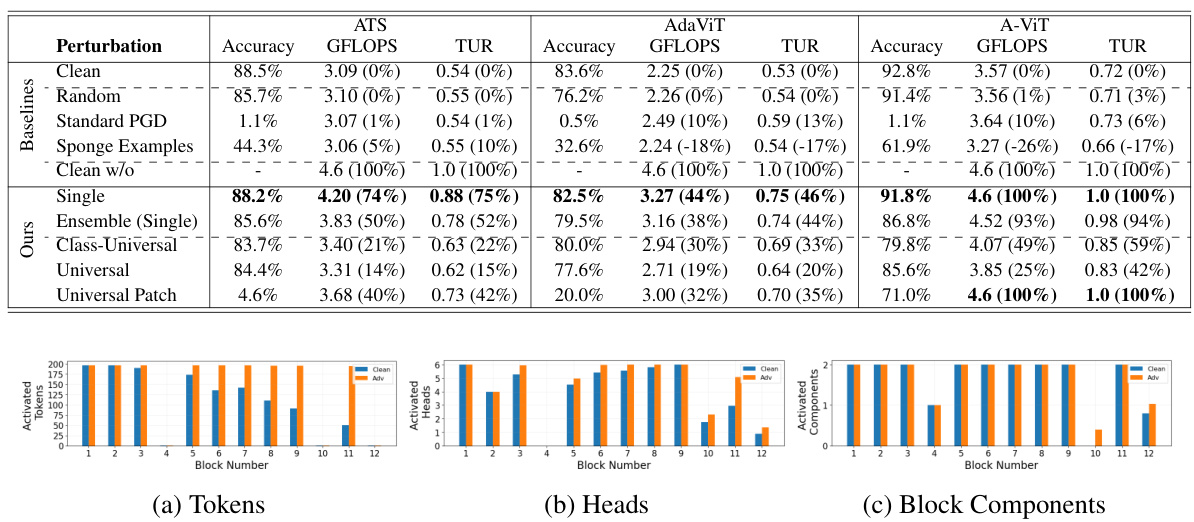
This table presents the results of the DeSparsify attack against the AS-ViT token sparsification mechanism. It compares the performance of various attack methods (random, standard PGD, sponge examples, and DeSparsify) against a baseline of clean images and a non-sparsified model. The metrics used are accuracy, GFLOPS (Giga Floating-Point Operations per Second), and TUR (Token Utilization Ratio). The ensemble results show performance when an adversarial perturbation is trained against multiple token sparsification mechanisms.

This table shows the time it took to generate adversarial examples using different attack strategies for the DeiT-s model. The ‘Single’ column represents the time to generate a separate perturbation for each image, whereas the ‘Universal’ column indicates the time taken to create a single perturbation applicable to all images.

This table presents the results of an experiment evaluating the effectiveness of different attacks and baselines against three token sparsification (TS) mechanisms: ATS, AdaViT, and A-ViT. The experiment uses the DeiT-s model. The table shows the accuracy, Giga Floating-Point Operations per Second (GFLOPS), and Token Utilization Ratio (TUR) for each mechanism under different conditions. These conditions include a clean image, random perturbation, standard PGD attack, sponge examples, and various versions of the DeSparsify attack (single-image, ensemble, class-universal, and universal). The ‘Clean w/o’ row represents the performance of the un-sparsified model, providing a baseline for comparison. The numbers in parentheses indicate the percentage change in performance compared to the un-sparsified model.
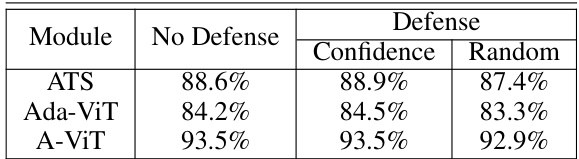
This table presents the accuracy results for clean images using the DeiT-s model, comparing the performance without any defense mechanism against two different defense strategies: a confidence-based policy and a random policy. The confidence-based policy selects tokens to meet the threshold based on significance scores, while the random policy randomly chooses tokens. The results show the impact of these defense strategies on the model’s accuracy when facing adversarial attacks.

This table presents the results of Giga Floating-Point Operations Per Second (GFLOPS) for adversarial images (single-image variant) tested on DeiT-s with and without the proposed defense. The proposed defense sets an upper bound to the number of tokens used in each transformer block, and there are two defense policies evaluated: random and confidence-based. The table shows the GFLOPS for each of three token sparsification mechanisms (ATS, Ada-ViT, A-ViT) under the no defense condition, the confidence-based defense, and the random defense. The results demonstrate the effectiveness of the proposed defense in mitigating the impact of the attack.
Full paper#