↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Machine unlearning (MU) aims to remove the influence of specific data points from pre-trained models, enhancing privacy. Existing gradient-based MU methods often struggle with efficiency and retained performance. This paper addresses these limitations.
The paper proposes a unified gradient-based MU approach that decomposes the unlearning process into three components. It then introduces a novel fast-slow parameter update strategy to efficiently embed unlearning updates into a manifold defined by the remaining data geometry, implicitly approximating the Hessian. This innovative approach improves unlearning efficacy and efficiency across various CV tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and privacy, particularly those working with large-scale models. It addresses the critical challenge of machine unlearning, offering a novel, efficient method applicable to various computer vision tasks, and opening up new avenues for research in privacy-preserving machine learning. The proposed method’s practical applicability and theoretical rigor make it highly relevant to current trends in the field.
Visual Insights#

This figure compares the proposed method with previous unlearning methods. It illustrates how conventional methods, using Euclidean metrics, may compromise overall model capabilities during the unlearning process. The proposed method, in contrast, operates within a ‘remain-preserving manifold,’ which implicitly approximates the Hessian, to more effectively remove unwanted information while preserving the model’s performance on the retained data.
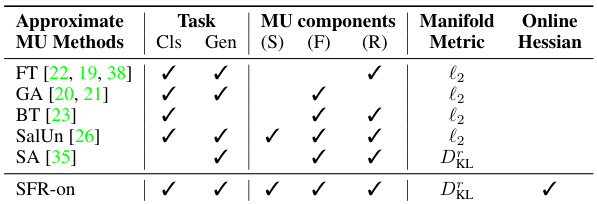
This table compares various approximate machine unlearning (MU) methods, analyzing their components (weight saliency matrix, forgetting part, remaining part) and the manifold metric used. It highlights that only Selective Amnesia (SA) and the proposed SFR-on method consider the remain-preserving manifold, with SFR-on further approximating the up-to-date Hessian.
In-depth insights#
Unified Gradient MU#
A unified gradient-based approach to machine unlearning (MU) offers a promising avenue for enhancing data privacy and model trustworthiness. This approach seeks to consolidate various existing gradient-based methods under a single theoretical framework, potentially simplifying the design and implementation of MU techniques. By focusing on the steepest descent direction within a parameter’s neighborhood, while minimizing the Kullback-Leibler divergence to the ideal unlearned model, it is expected that this method could effectively handle various unlearning scenarios. The key advantage of this approach lies in its potential to unify and improve existing MU methods, addressing some of their limitations such as catastrophic forgetting and computational inefficiency. However, challenges remain, particularly in efficiently approximating the Hessian matrix for large-scale models, which may limit its practical applicability. Further research to tackle this issue and to test across broader datasets and computer vision tasks is critical to realizing the full potential of a unified gradient-based MU approach.
Remain Geometry#
The concept of “Remain Geometry” in the context of machine unlearning is intriguing. It suggests a shift from traditional Euclidean-based methods, which treat all parameters equally, to a manifold-centric approach. This manifold is defined by the remaining data after unlearning, implicitly capturing the intricate relationships between parameters crucial for preserving the model’s performance on the retained data. By embedding unlearning updates within this manifold, the method aims to prevent the forgetting process from negatively impacting the model’s ability to generalize to unseen data that is similar to the data that remains in the dataset. This framework offers a powerful way to address the catastrophic forgetting problem inherent in many machine unlearning techniques. The use of a Hessian approximation to efficiently navigate this manifold is a clever computational optimization, balancing effectiveness with tractability for large-scale models. This is a significant advancement in the field, providing a new perspective on the core challenges of unlearning and paving the way for more robust and efficient methods.
Hessian Approx.#
Approximating the Hessian matrix is crucial for efficient machine unlearning in large-scale models because directly computing it is computationally expensive. The paper explores this challenge, acknowledging the intractability of computing the full Hessian for large neural networks. Instead of exact computation, the authors propose methods for implicit approximation, focusing on efficiently capturing the essential information needed to guide the unlearning process. This approach is vital because the Hessian provides crucial second-order information about the model’s parameter space, helping to optimize the unlearning direction in a way that preserves the performance on the remaining data. The focus on implicit approximation highlights a practical trade-off between computational cost and the accuracy of Hessian estimation, making the unlearning technique applicable to large-scale models where precise Hessian calculations are infeasible. The proposed fast-slow weight update strategy is a particularly interesting method that dynamically approximates this information, overcoming limitations of previous methods that relied on fixed approximations.
Fast-Slow Weights#
The concept of “Fast-Slow Weights” in the context of machine unlearning presents an efficient approach to approximating the computationally expensive Hessian matrix. This method cleverly leverages a two-stage update process: a fast inner loop that quickly identifies a salient unlearning direction and a slow outer loop that refines this direction using a remain-preserving manifold. The fast weights dynamically adjust the forgetting gradient, focusing on parameters crucial for removing unwanted data, while the slow weights ensure that the overall update smoothly aligns the model’s output distribution with that of the retrained model, thereby mitigating catastrophic forgetting. This decoupling allows for efficient iterative updates, contrasting with traditional methods that require computationally intensive second-order Hessian calculations. The framework implicitly approximates the effect of the Hessian modulation, thereby significantly enhancing efficiency while maintaining efficacy, making it suitable for large-scale models.
Future of MU#
The future of machine unlearning (MU) is promising, yet challenging. Significant advancements are needed to address the computational cost of exact MU, making approximate methods more practical for large-scale models. Research should focus on developing more sophisticated and efficient techniques for approximating the output distribution of retrained models after unlearning, potentially using advanced optimization methods beyond gradient descent. Improving Hessian approximations, particularly for large models, is crucial. Exploring manifold learning techniques to better represent the data’s geometric structure in output space could significantly improve algorithm efficiency and performance. Addressing privacy concerns is paramount; therefore, further work is needed to explore metrics beyond accuracy and develop robust evaluations for evaluating privacy-preserving properties. Finally, developing methods to address MU in various modalities, including both image and text generation, along with tackling challenging issues such as concept forgetting, remains a critical research goal.
More visual insights#
More on figures

This figure shows the image generation results of different methods on CIFAR-10 class-wise forgetting tasks using DDPM. The top row shows images from the pre-trained model, while the second row shows images after retraining (RT) without the ‘cat’ class. The subsequent rows display the output of the different unlearning methods (SA, SalUn, and SFR-on with different ablation configurations). Each row represents a different method, and within each row, the images are grouped into ‘Forgetting Class’ (‘cat’) and ‘Non-forgetting Classes’ (other classes). The results demonstrate the effectiveness of the proposed SFR-on method in removing the target class (‘cat’) while preserving the quality of the other classes.

This figure shows the results of class-wise forgetting experiments on the ImageNet dataset using the Diffusion Transformer (DiT) model. The goal is to remove images of ‘golden retrievers’ while preserving the quality of other generated images. The figure compares different machine unlearning methods (Pretrain, RT¹, SA, SalUn, and SFR-on). RT¹ is a simulated retrained model due to computational constraints. Each row represents a method, with the first two columns showing generated images of ‘golden retrievers’ (the forgetting class) and the following columns displaying images from other classes (non-forgetting classes). The figure highlights that the SFR-on method effectively removes ‘golden retriever’ images while better maintaining the quality of the other generated images.

This figure compares the proposed method with existing unlearning methods. The proposed method focuses on preserving the capabilities of the model during unlearning, while conventional methods may compromise the general capabilities of the model in order to achieve steepest descent in Euclidean space. The large cost associated with computing the Hessian is addressed by implicitly approximating the unlearning direction.

This figure compares the proposed method with existing unlearning methods. The focus is on removing the concept of ’nudity’ from diffusion models. Existing methods use Euclidean geometry and may compromise overall model capabilities. In contrast, the proposed approach leverages the remaining geometry (manifold) of the data to more efficiently and effectively unlearn the target concept while preserving the performance on other concepts.
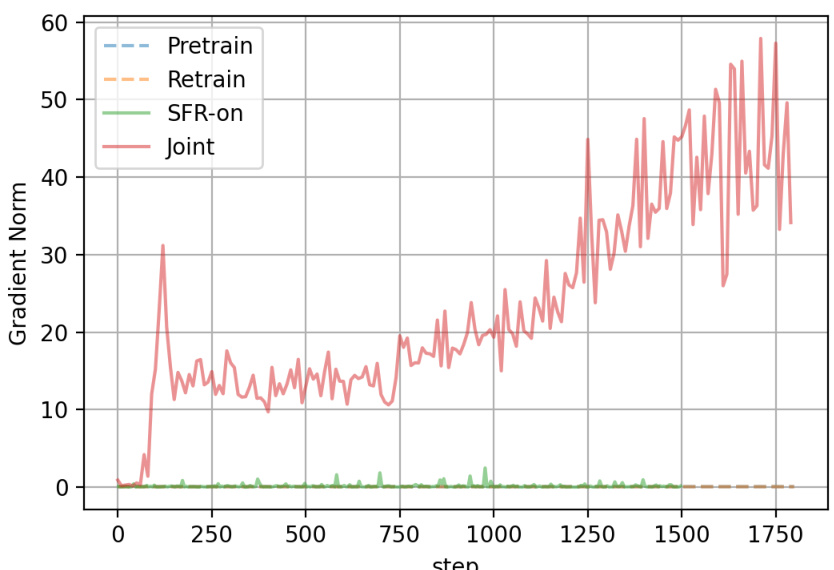
This figure shows the performance of the proposed SFR-on method compared to the retraining baseline (RT) on the CIFAR-10 dataset using ResNet-18. The experiment focuses on the effect of the temperature scalar λ, which controls the smoothness of the adaptive coefficients in the weighted forgetting gradient ascent part of the algorithm. The plot shows four key metrics: Forgetting Accuracy (FA), Remaining Accuracy (RA), Testing Accuracy (TA), and Kullback-Leibler Divergence (DKL). Each metric is plotted against different values of λ. The goal is to find a λ value that minimizes the DKL (i.e., the difference between the model’s output distribution and that of the retrained model), while simultaneously maintaining high FA, RA, and TA. Points closer to the Retraining baseline and with lower DKL values are preferred as they signify a more effective unlearning process.
The figure illustrates the difference between the proposed method and previous unlearning methods. Previous methods focus on finding the steepest descent in Euclidean space, potentially sacrificing overall model performance. The proposed method, however, aims for a remain-preserving manifold approach to achieve efficient unlearning while preserving capabilities. This is achieved via implicit online Hessian approximation.

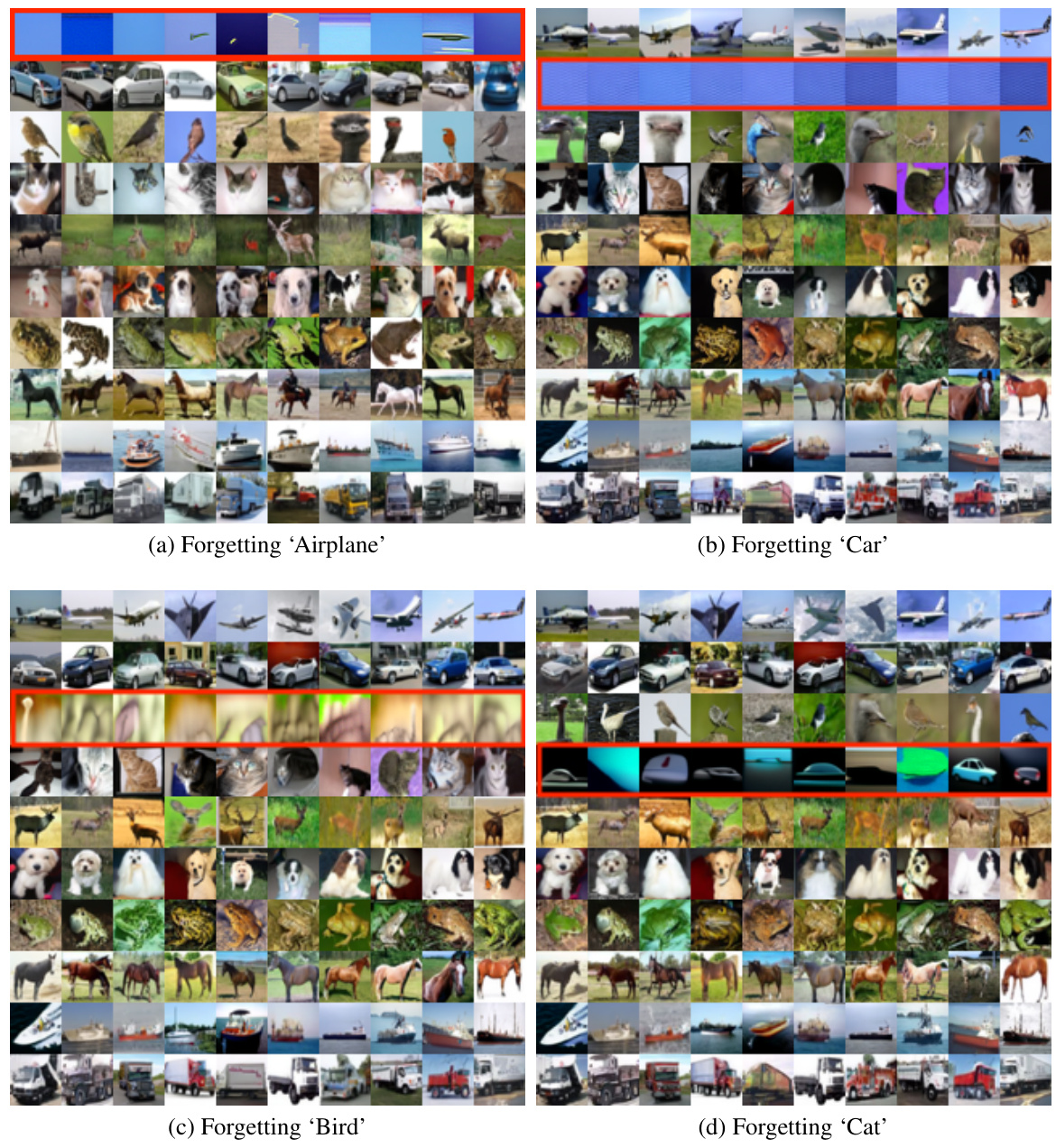
This figure shows several examples of class-wise unlearning results using classifier-free guidance diffusion probabilistic models (DDPMs) on the CIFAR-10 dataset. Each sub-figure represents a different class to be forgotten (‘Airplane’, ‘Car’, ‘Bird’, ‘Cat’, ‘Deer’, ‘Dog’, ‘Frog’, ‘Horse’, ‘Ship’, ‘Truck’). The images in the top and bottom rows represent successfully generated images after unlearning, while the central rows show the images of the target forgotten class. The red color highlights the failed generation of the forgotten classes.

This figure shows the results of class-wise forgetting experiments using classifier-free guidance diffusion probabilistic models on the CIFAR-10 dataset. Each sub-figure presents the results for a different class being forgotten. The images generated by the model after unlearning are shown, with images of the forgotten class highlighted in red. This illustrates the model’s ability (or lack thereof) to effectively remove the specified class from its generation capabilities while maintaining the generation of other classes.

This figure shows the results of class-wise forgetting experiments on ImageNet using the Diffusion Transformer (DiT). The goal is to remove the ‘Golden Retriever’ class from the model’s generated images. The figure compares several baselines to the proposed SFR-on method. Because training a fully retrained model (RT) on ImageNet is computationally expensive, the authors used a proxy for RT (RT¹) that replaces the Golden Retriever class with random embeddings. The figure demonstrates that SFR-on is able to effectively remove the Golden Retriever class while maintaining the quality of images in other classes, performing better than baselines such as Saliency-based unlearning (SalUn) and Selective Amnesia (SA).

This figure shows the results of a class-wise forgetting experiment on the ImageNet dataset using the Diffusion Transformer (DiT) model. The goal is to remove the ‘golden retriever’ class from the model’s output while preserving the quality of images generated for other classes. The figure compares several baselines with the proposed SFR-on method. The results demonstrate that SFR-on effectively removes the target class (‘golden retriever’) while maintaining the generation quality for the other classes. Because a full retraining (RT) is computationally expensive, the researchers used a simulated RT (RT¹) where random latent embeddings were used instead of retraining the model. The figure demonstrates the advantage of SFR-on over the baseline methods.
More on tables

This table summarizes the performance of several machine unlearning methods on two image classification tasks: CIFAR-10 using ResNet-18 and TinyImageNet using Swin-T. It compares the proposed SFR-on method against six baselines and the retraining (RT) approach, measuring forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), average disparity (Avg.D) from RT, Kullback-Leibler divergence (DKL) from RT, and runtime efficiency (RTE). The table shows that SFR-on achieves the best performance.

This table presents the results of class-wise forgetting experiments on CIFAR-10 using a Denoising Diffusion Probabilistic Model (DDPM) and on ImageNet using a Diffusion Transformer (DiT). For each forgetting class, the table shows the Forgetting Accuracy (FA) and Fréchet Inception Distance (FID) metrics. The best performing method (lowest FA and FID) is highlighted in bold for each class. The number of steps needed for unlearning is also shown. This helps illustrate the performance of different methods in effectively removing the influence of specific classes from the model while maintaining the overall quality of generated images for other classes.

This table presents a performance comparison of several machine unlearning (MU) methods on two image classification datasets: CIFAR-10 and TinyImageNet. The methods are evaluated using various metrics, including forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), KL divergence to the retrained model (DKL), and runtime efficiency (RTE). The table highlights the effectiveness and efficiency of the proposed SFR-on method by showing its superior performance compared to existing methods. Ablation studies are also included, demonstrating the importance of the various components of the SFR-on method.

This table summarizes the performance of various machine unlearning methods on two image classification tasks. It compares the performance of the proposed SFR-on method against several baselines (including retraining, FT, GA, RL, SalUn, BT, SCRUB) across key metrics: forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), KL divergence to Retraining (DKL), and runtime efficiency (RTE). The table uses CIFAR-10 with ResNet-18 and TinyImageNet with Swin-T datasets, evaluating the unlearning of 10% of randomly selected samples. Performance discrepancies from the retraining model are highlighted to show the effectiveness of each method.

This table presents the results of class-wise forgetting experiments conducted on CIFAR-10 using a diffusion probabilistic model (DDPM) and on ImageNet using a diffusion transformer (DiT). The table shows the forgetting accuracy (FA) and Fréchet Inception Distance (FID) for several methods, highlighting the best performance in bold for each forgetting class. The results illustrate the effectiveness of different methods in removing specific classes from the models while maintaining the overall image quality.

This table summarizes the performance of several machine unlearning (MU) methods on two image classification datasets: CIFAR-10 and TinyImageNet. It compares the performance of these methods to a retrained model (RT), considered the gold standard. Metrics include forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), average disparity (Avg.D) from RT, Kullback-Leibler divergence (DKL) to RT, and runtime efficiency (RTE). The table highlights the effectiveness of the proposed method (SFR-on) by showing its performance is closer to the RT gold standard than other methods.

This table summarizes the performance of several machine unlearning (MU) methods on two image classification datasets: CIFAR-10 and TinyImageNet. It compares the performance of the proposed method (SFR-on) against several baseline methods, including retraining (RT). Metrics used include forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), average disparity from RT (Avg.D), Kullback-Leibler divergence to RT (DKL), and runtime efficiency (RTE). The table shows that SFR-on achieves results closest to RT, indicating more effective unlearning.

This table compares the performance of several machine unlearning (MU) methods on two image classification tasks. It shows the forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), average disparity from the retraining model (Avg.D), Kullback-Leibler divergence to retraining (DKL), and runtime efficiency (RTE) for each method. The table includes results for retraining (RT) as a baseline and highlights the performance of the proposed SFR-on method in relation to existing techniques.
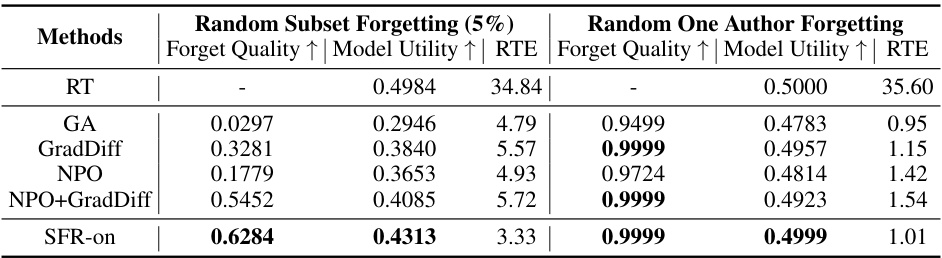
This table presents the results of class-wise forgetting experiments conducted on two different datasets: CIFAR-10 using a diffusion probabilistic model (DDPM) and ImageNet using a diffusion transformer (DiT). For each dataset and model, several methods were used to perform unlearning of specific classes. The table shows the forgetting accuracy (FA) and Fréchet Inception Distance (FID) for each method and each class. The best performing methods for each class are highlighted in bold for both FA and FID metrics. This allows for a comparison of various unlearning methods in terms of their effectiveness in forgetting specific classes while maintaining performance on other classes.

This table compares the performance of several machine unlearning (MU) methods on two image classification datasets: CIFAR-10 and TinyImageNet. It shows the forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack success rate (MIA), average disparity (Avg.D) from the Retrained model (RT), Kullback-Leibler divergence (DKL) to RT, and run-time efficiency (RTE) for each method. The table helps assess the effectiveness and efficiency of different MU methods.

This table summarizes the performance of different machine unlearning methods on two image classification datasets: CIFAR-10 and TinyImageNet. It compares several baselines, including fine-tuning (FT), gradient ascent (GA), random labeling (RL), saliency-based unlearning (SalUn), bad teacher (BT), and SCRUB, against the proposed method (SFR-on) and an ablation study of its components. Key metrics include forgetting accuracy (FA), remaining accuracy (RA), test accuracy (TA), membership inference attack success rate (MIA), Kullback-Leibler divergence (DKL) to the retrained model (RT), and runtime efficiency (RTE). The table highlights how close each method’s performance comes to that of the ideal RT model and shows the runtime efficiency of each approach.

This table summarizes the performance of several machine unlearning (MU) methods on two image classification tasks. It compares the proposed SFR-on method against six baseline methods and the retraining approach (RT) which serves as the gold standard. Metrics include forgetting accuracy (FA), remaining accuracy (RA), testing accuracy (TA), membership inference attack (MIA), average disparity from RT, KL divergence from RT, and runtime efficiency (RTE). Higher FA, RA, and TA are better while lower MIA, Avg.D, and DKL are better. RTE refers to the runtime in minutes.
Full paper#



















