↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Vision Transformers (ViTs) utilize self-attention, often believed to perform object grouping by attending to similar features. However, the role of attending to dissimilar features remains unclear. This research addresses this gap by investigating how self-attention balances these two aspects and whether singular vectors of query-key interaction reveal semantically meaningful feature interactions.
The researchers use Singular Value Decomposition (SVD) to analyze the query-key interaction matrix of various ViTs, finding that early layers predominantly attend to similar tokens, supporting the perceptual grouping hypothesis. However, later layers show increased attention to dissimilar tokens, suggesting contextualization. The analysis of singular vectors reveals that many interactions are semantically interpretable. This work provides a novel perspective for interpreting self-attention, offering a deeper understanding of how ViTs utilize both local and global information while processing images.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and transformer models. It provides novel insights into the inner workings of self-attention, a core component of vision transformers. The proposed method for analyzing query-key interactions using singular value decomposition offers a new lens for interpreting attention mechanisms and opens avenues for enhancing model explainability and improving the design of future transformer models.
Visual Insights#

This figure shows two examples of semantically interpretable modes obtained from the singular value decomposition of the query-key interaction matrix. Each example shows a pair of singular vectors (query and key) visualized as image channels. The red channel represents the query vector, while the cyan channel represents the key vector. The images illustrate how the model attends to semantically similar features (e.g., parts of an object or related objects). The top row shows an example from a Vision Transformer (ViT), and the bottom row shows an example from a self-supervised vision transformer (DINO).
In-depth insights#
Query-Key Dynamics#
The concept of ‘Query-Key Dynamics’ in the context of vision transformers centers on understanding how queries and keys interact within the self-attention mechanism. Early layers exhibit a stronger preference for interactions between similar queries and keys, suggesting a focus on perceptual grouping where tokens representing semantically similar features are linked. This is aligned with the idea of the self-attention mechanism performing perceptual grouping in early layers. Later layers, however, demonstrate an increasing emphasis on interactions between dissimilar queries and keys, highlighting the importance of contextualization where tokens acquire context from objects or regions not immediately similar. Singular Value Decomposition (SVD) of the query-key interaction matrix is a powerful tool to analyze this interaction, revealing interpretable semantic relationships between features in both similar and dissimilar pairs.
Singular Value Insights#
The heading ‘Singular Value Insights’ suggests an analysis employing Singular Value Decomposition (SVD) to gain deeper understanding of a system or data. SVD is a powerful dimensionality reduction technique that reveals underlying structures by decomposing a matrix into three constituent matrices: U, Σ, and V. In this context, the insights likely derive from examining the singular vectors (U and V) and singular values (Σ) to identify key features or relationships. Singular vectors represent principal components that capture the most significant variance in the data, revealing crucial patterns and correlations often obscured in the raw data. Analyzing the singular values provides insights into the relative importance of these components, with larger values indicating more dominant features. By interpreting the semantic meaning associated with the singular vectors, one can uncover latent structures and patterns otherwise invisible in a simpler analysis. Therefore, ‘Singular Value Insights’ promises a detailed and nuanced exploration beyond basic statistical analyses, offering a deeper and more interpretable understanding of complex systems or datasets through the lens of SVD.
Semantic Attention Maps#
Semantic attention maps aim to visualize the relationships between different parts of an image by highlighting regions that the model deems semantically related. This differs from standard attention maps, which focus on raw pixel relationships. A key challenge is interpretability: making these maps easily understandable to humans. Successful semantic attention maps would go beyond simple feature matching, demonstrating an understanding of higher-level concepts and object relationships. Effective techniques might incorporate semantic segmentation, identifying objects before calculating relationships, or use of learned embeddings which capture richer semantic information than raw pixel data. Visualizing these maps effectively is crucial: color-coding or other visual cues would be needed to show the strength and type of relationships. The ultimate goal is to create maps that aid in understanding the model’s decision-making process, ultimately improving transparency and trust in AI systems.
ViT Model Variations#
Analyzing variations in Vision Transformer (ViT) models reveals crucial insights into their performance and capabilities. Different architectures, such as variations in patch size, depth, and the use of additional modules (like convolutional layers), significantly impact a model’s ability to capture spatial information and contextual relationships within images. Training objectives also play a pivotal role; supervised methods prioritize classification accuracy, potentially favoring early layers that focus on perceptual grouping. Conversely, self-supervised techniques often incorporate contextualization, leading to a shift in attention towards dissimilar tokens in later layers. Understanding these variations is key to optimizing ViT performance for specific tasks. The choice of architecture and training method should be carefully considered based on the desired balance between local feature extraction and global contextual understanding. Furthermore, exploring how these variations affect the interpretability of the attention mechanism is essential for building more transparent and explainable AI systems. Future research could benefit from focusing on how different architectural choices interact with training objectives to affect final performance and model interpretability.
Future Research#
Future research directions stemming from this work could explore several key areas. Extending the singular value decomposition (SVD) analysis to other transformer model architectures and modalities (e.g., language, audio) would broaden the applicability and generalizability of the findings. Investigating the influence of different training objectives and data characteristics on the query-key interactions revealed by SVD is crucial. A deeper investigation into the role of the value matrix in self-attention, beyond the focus on the query-key interaction, would provide a more holistic understanding of the self-attention mechanism. Finally, developing methods to leverage these SVD-derived insights for downstream tasks, such as image segmentation and object recognition, would unlock the practical potential of this research, leading to improved model interpretability and performance.
More visual insights#
More on figures
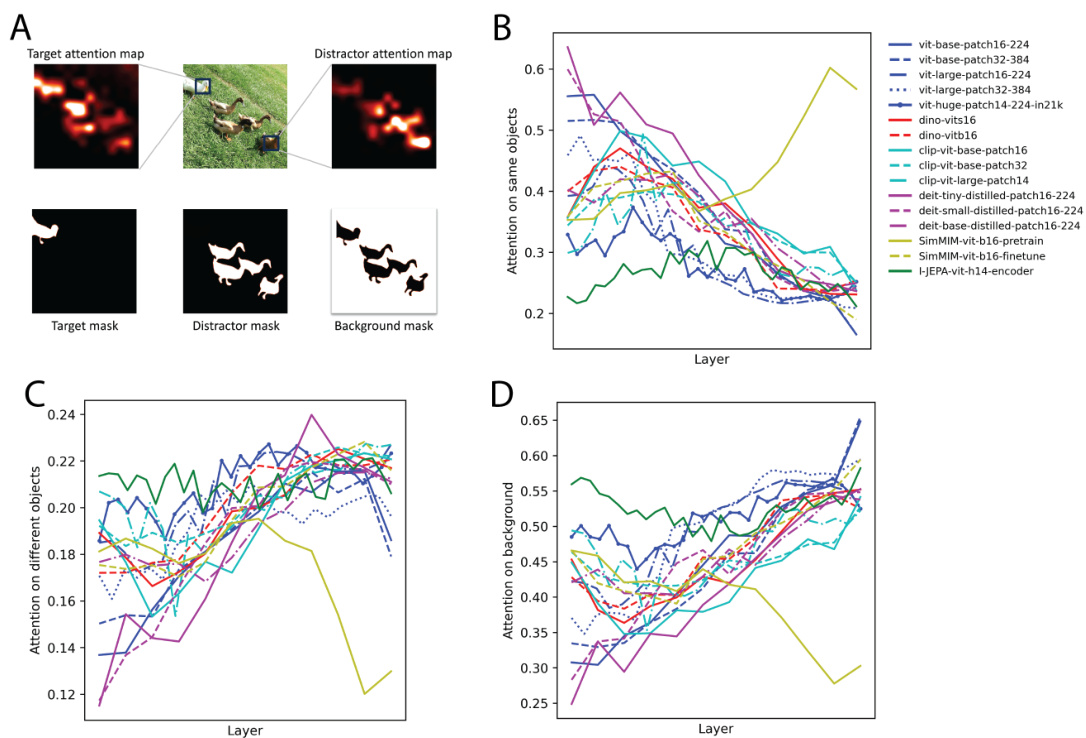
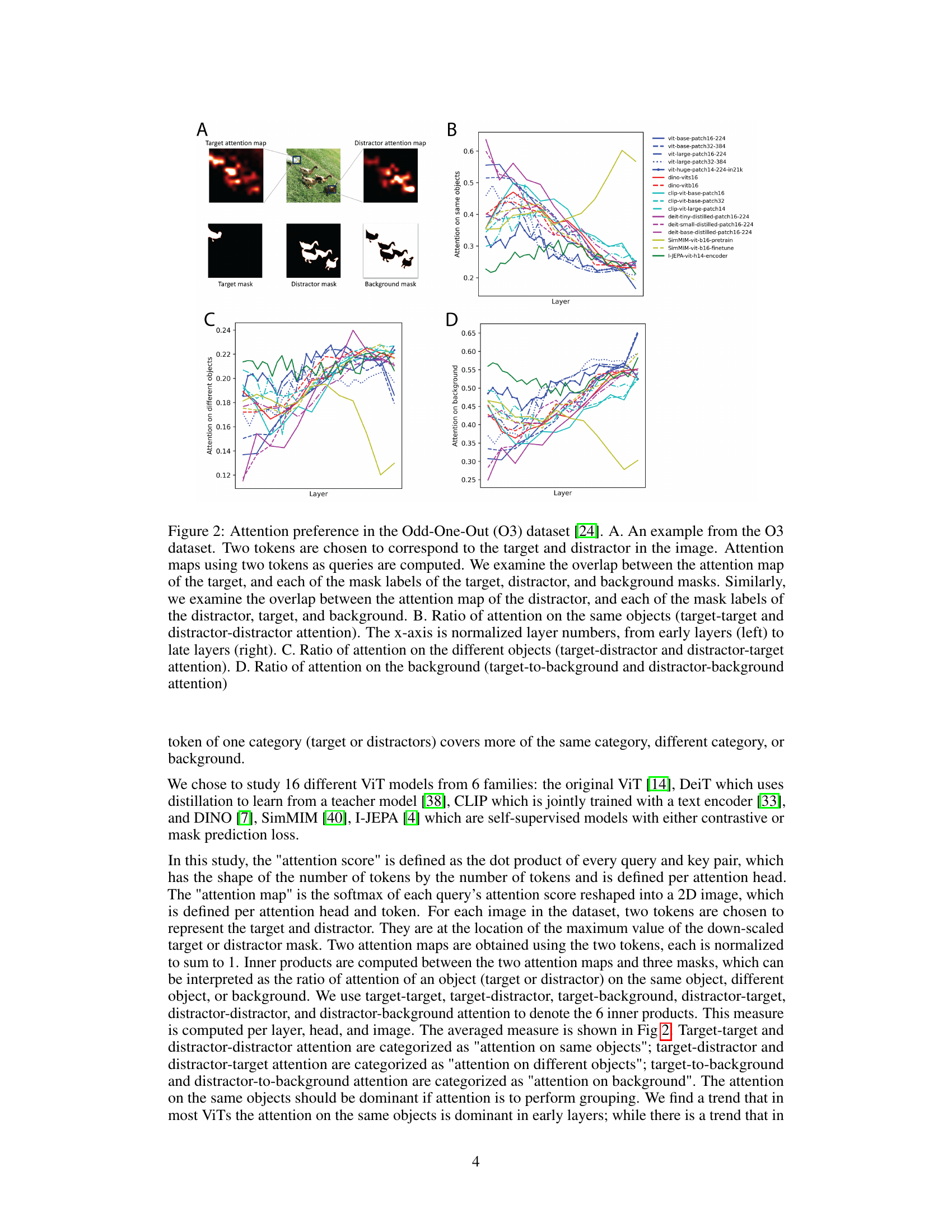
This figure empirically studies whether an image token attends to tokens belonging to the same objects, different objects, or background using the Odd-One-Out dataset. It analyzes attention preference across different ViT models, showing the ratio of attention on the same objects, different objects, and the background for both target and distractor tokens across various layers. This helps visualize whether self-attention focuses more on grouping similar features or contextualizing with dissimilar features at different network depths.
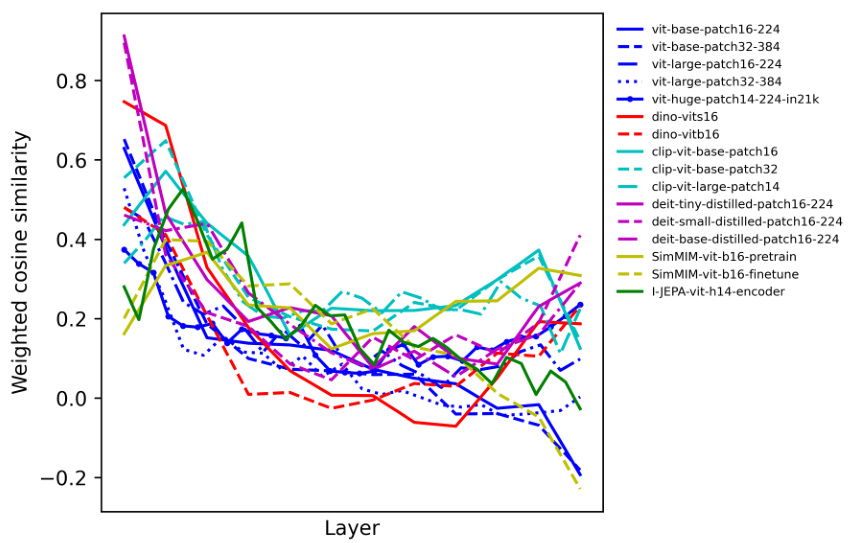
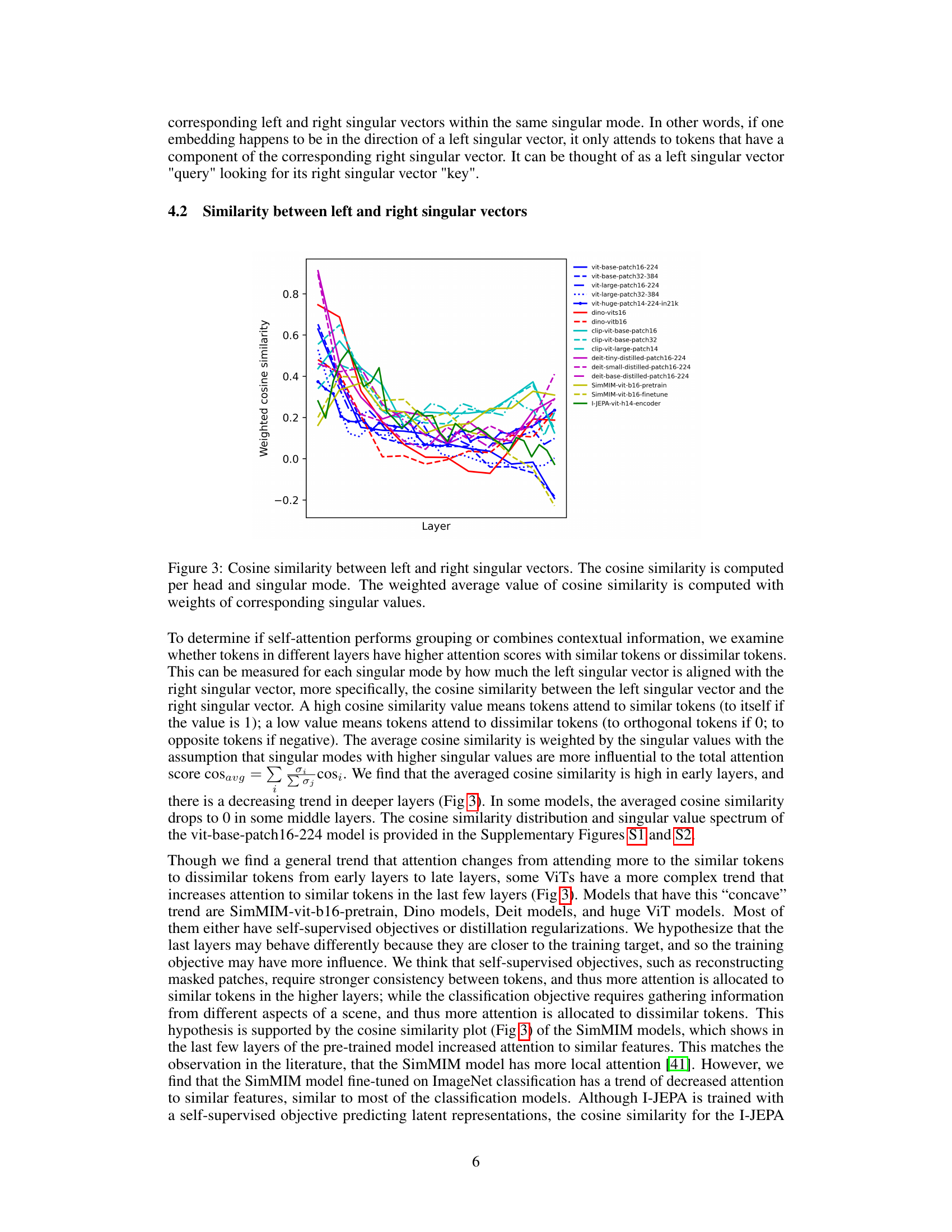
This figure shows the weighted average cosine similarity between left and right singular vectors across different layers of various vision transformer models. The cosine similarity is a measure of how similar the left and right singular vectors are for each singular mode (a pair of singular vectors representing a feature interaction). A high cosine similarity indicates that tokens attend to similar tokens (perceptual grouping), while a low cosine similarity indicates attention to dissimilar tokens (contextualization). The plot shows the trend of cosine similarity across different layers for several ViT models. This visualization is used to analyze whether self-attention in the models prioritizes grouping (similar tokens) or contextualization (dissimilar tokens) at different network depths.

This figure shows examples of semantically interpretable singular modes from the DINO-vitb16 model. Each mode is represented by a pair of singular vectors (query and key), visualized in red and cyan channels respectively. The images shown are those that maximize the attention score for each mode. The caption also explains the naming convention for the singular modes and provides the cosine similarity between the left and right singular vectors for each mode.

This figure visualizes how different singular modes of the dino-vitb16 model process a single dog image from the ImageNet dataset. It shows the top 6 modes (ranked by their contribution to the attention score) for selected layers and heads. Each mode is represented by a set of images, showcasing how the model attends to different features within the image based on these modes. To see a more complete visualization of the modes, refer to Supplementary Figure S17.

This figure shows the attention preference of different ViT models on the Odd-One-Out dataset. It examines how attention is distributed between same-object tokens, different-object tokens, and background tokens across various layers of the model. Subplots (B), (C), and (D) present the ratio of attention for each of these categories across different layers, illustrating the change in attention preference from early layers to later layers.
This figure shows the cosine similarity between left and right singular vectors in various ViT models across different layers. The cosine similarity is calculated for each singular mode and then averaged across heads, weighting the average by the corresponding singular values. High cosine similarity indicates that tokens mostly attend to other similar tokens (grouping), while low cosine similarity suggests tokens attend more to dissimilar tokens (contextualization). The plot shows the trend in different ViT models. In many models, there is a decrease in cosine similarity from earlier layers to later layers. Some self-supervised models show a different trend, having higher cosine similarity in the last few layers.

This figure empirically studies whether an image token attends to tokens belonging to the same objects, different objects, or background. It uses the Odd-One-Out (O3) dataset, which contains images with a group of similar objects (distractors) and a distinct singleton object (target). The figure shows attention maps for target and distractor tokens, analyzing the overlap between attention maps and mask labels for each category (target, distractor, background). Subplots then show the ratios of attention on same objects, different objects, and background across different layers in various ViT models.

This figure shows the weighted average cosine similarity between the left and right singular vectors across different layers of various Vision Transformer (ViT) models. The x-axis represents the layer number, and the y-axis represents the weighted average cosine similarity. Each line represents a different ViT model. High cosine similarity indicates that tokens attend to similar tokens (perceptual grouping), while low cosine similarity suggests attention to dissimilar tokens (contextualization). The figure helps to visualize the trend of self-attention shifting from grouping in early layers to contextualization in later layers, although variations exist across different models and training objectives.
This figure empirically studies whether an image token attends to tokens belonging to the same object, different objects, or background. It uses the Odd-One-Out (O3) dataset, showing example images (A) and then plotting the ratio of attention on the same objects (B), different objects (C), and background (D) across different ViT layers for multiple model types. The x-axis represents normalized layer number, progressing from early to late layers.

This figure shows two examples of semantically interpretable modes obtained from the singular value decomposition of the query-key interaction matrix. Each mode consists of a pair of singular vectors (one for the query and one for the key). The images depict the projection values of the embeddings onto these singular vectors. The red channel represents the query projection, while the cyan channel represents the key projection. The top row shows an example from a ViT model, while the bottom row shows an example from a DINO model, both illustrating how these singular vector pairs reveal interpretable semantic relationships between image features.

This figure visualizes the top 6 singular modes (ranked by their contribution to the attention score) from different layers and heads of the dino-vitb16 model applied to a single dog image from ImageNet. For each mode, the figure shows the query and key maps, highlighting the interaction between features represented by left and right singular vectors. This provides insights into how the model attends to features at various levels (low-level in early layers, higher-level in later layers). Supplementary Figure S17 provides a more detailed visualization for this example.

This figure shows the attention preference of ViT models in the Odd-One-Out dataset. Subfigure A shows an example image from the dataset. Subfigures B, C, and D show the ratio of attention on the same objects, different objects, and background, respectively, across different layers of the ViT models.

This figure showcases examples of optimal attention images from the ImageNet validation set for singular modes in the dino-vitb16 model. Each example highlights the interaction between query and key maps (represented by red and cyan channels) projected onto the left and right singular vectors of a specific singular mode. The white area shows overlap between the query and key maps. The figure provides a visual representation of how these singular modes relate semantically to image features and the cosine similarity between the left and right singular vectors of each mode is included.

This figure visualizes the results of applying singular value decomposition to a single dog image using the dino-vitb16 model. It displays the top 6 singular modes (ranked by contribution to the attention score) across different layers and heads within the model. Each mode’s visualization helps understand the interactions between features within the model. Supplementary Figure S17 provides more visualizations.

This figure visualizes how different singular modes of the dino-vitb16 model attend to different parts of an example dog image from the ImageNet dataset. It shows the top 6 modes from various layers and heads, ordered by their contribution to the total attention score. Each mode highlights specific interactions between features, visualized through red and cyan channels representing query and key maps. The supplementary material (Figure S17) offers more detailed visualizations.

This figure shows examples of semantic singular modes in the deit-base-distilled-patch16-224 model. Each row represents a specific singular mode, identified by layer, head, and mode number (e.g., L0 H0 M3). The leftmost column shows the cosine similarity between the left and right singular vectors for that mode. The remaining columns display the top 8 images from the ImageNet validation set that maximize the attention score for that singular mode. The red and cyan channels in these images indicate the projection of the image embeddings onto the left and right singular vectors respectively. This visualization helps to understand the semantic information captured by each singular mode, revealing how specific features in the query and key maps interact to produce attention.

This figure displays examples of semantically interpretable singular modes from the DeiT-base-distilled-patch16-224 model. Each row represents a singular mode, identified by its layer, head, and mode number. For each mode, the figure shows the top 8 images from the ImageNet validation set that maximize the attention score for that mode. The red and cyan channels in each image visualization represent the projection values of the embedding onto the left and right singular vectors of the mode, respectively. These visualizations help in understanding how different parts of the image are attended to in various layers of the model.

This figure shows examples of semantic singular modes in the DeiT-base-distilled-patch16-224 model, specifically focusing on part 3 of the examples. Each mode is represented visually, highlighting the interactions between query and key embeddings. The color channels (red and cyan) represent projections onto left and right singular vectors, showing how different parts of an image (or even different images) relate within the model’s attention mechanism.

This figure shows examples of optimal attention images for several singular modes in the dino-vitb16 model. Each mode is represented by a pair of singular vectors (left and right), visualized in red and cyan channels respectively in the images shown. These channels show the projection of image embeddings onto those vectors. The white areas highlight overlap between query and key maps. The caption also provides a naming scheme to identify the layer, head, and mode of each example and its cosine similarity score.

This figure visualizes examples of optimal attention images from the ImageNet validation set for singular modes in the dino-vitb16 model. Each example shows the query and key maps (red and cyan channels, respectively) corresponding to a specific singular mode (layer, head, and mode number indicated). The white area represents the overlap between the query and key maps. The value below each example represents the cosine similarity between the left and right singular vectors of that mode, indicating the alignment between the query and key.

This figure shows examples of semantic singular modes in the clip-vit-base-patch16 model. Each row represents a singular mode and contains multiple images. The red and cyan channels highlight the projection of the image embeddings onto the left and right singular vectors, respectively. The arrangement illustrates the interactions between query and key feature vectors, particularly highlighting the semantic relationships between image regions captured by each mode. The overall figure showcases various types of feature interactions present within the model, ranging from low-level features to higher-level object relationships, thereby demonstrating the varying semantic properties encoded within the different singular modes across various layers and heads.

This figure visualizes the results of applying singular value decomposition to self-attention in a vision transformer model. It shows how different singular modes (combinations of left and right singular vectors) capture different aspects of an image. In this case, an example dog image is used and the top six modes are displayed to show how different parts of the image and its relation with other parts are represented in the model. Early layers capture low level properties, and deeper layers capture higher level semantics. Supplementary Figure S17 offers more examples.

Figure 2 empirically studies whether an image token attends to tokens belonging to the same object, different objects, or the background. It uses the Odd-One-Out (O3) dataset, which contains images with a group of similar objects (distractors) and a distinct singleton object (target). The figure shows the attention preference in different ViT models by computing the attention score (overlap) between attention maps of target/distractor tokens and mask labels of target, distractor and background. Subplots B, C, and D show the ratios of attention on the same objects, different objects, and background respectively, across different layers of the model.

This figure shows two examples of semantically interpretable modes obtained from the singular value decomposition of the query-key interaction matrix. Each mode is represented by a pair of singular vectors (one for query and one for key). The images are color-coded to show the projection of image embeddings onto these singular vectors, revealing how different image features interact through the query-key mechanism in Vision Transformers (ViTs). The top row shows an example from a ViT model, and the bottom row shows an example from a DINO model, highlighting the versatility of the proposed method across different ViT architectures.
Full paper#