↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Traditional 3D scene creation relies on laborious manual processes. While recent advancements in deep generative models enable realistic image synthesis from text, precise 3D control remains a challenge, especially in multi-object scenarios. Existing methods often lack the 3D understanding needed for intuitive manipulation, hindering their ability to handle complex real-world scenes effectively. Furthermore, using only text as a conditioning input for image generation proves insufficient for achieving the level of precise control desired.
This paper introduces Neural Assets, a novel method that leverages per-object visual representations and 3D pose information to control individual objects within a scene. By training on paired video frames, the model learns disentangled representations for appearance and pose, enabling fine-grained control. The researchers demonstrate state-of-the-art results on both synthetic and real-world datasets, showcasing the method’s ability to handle multi-object editing tasks with high accuracy and efficiency. This approach also enables compositional scene generation, such as transferring objects between different scenes, leading to more flexible and versatile 3D-aware scene editing.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D-aware multi-object scene editing using image diffusion models. Its method, using “Neural Assets,” offers fine-grained control over object poses and appearances, surpassing previous methods in accuracy and flexibility. This work opens avenues for advancements in areas like image editing software, video game development, and virtual reality applications, all of which require sophisticated 3D scene manipulation. The technique’s ability to generalize to real-world scenes is also highly significant, extending potential impact and further research.
Visual Insights#

This figure demonstrates the capabilities of the Neural Assets model in manipulating objects within images. Starting from a single image, the model allows for several edits including translation, rotation, and scaling of individual objects. Furthermore, it showcases the model’s capacity for compositional generation, enabling the transfer of objects and backgrounds between different images.
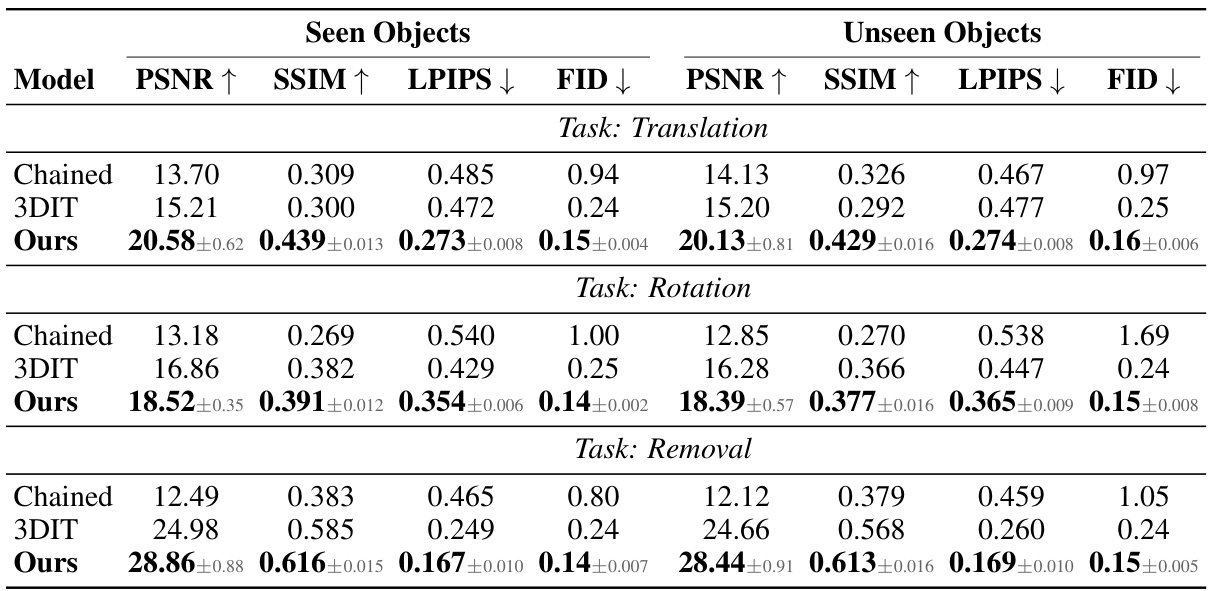
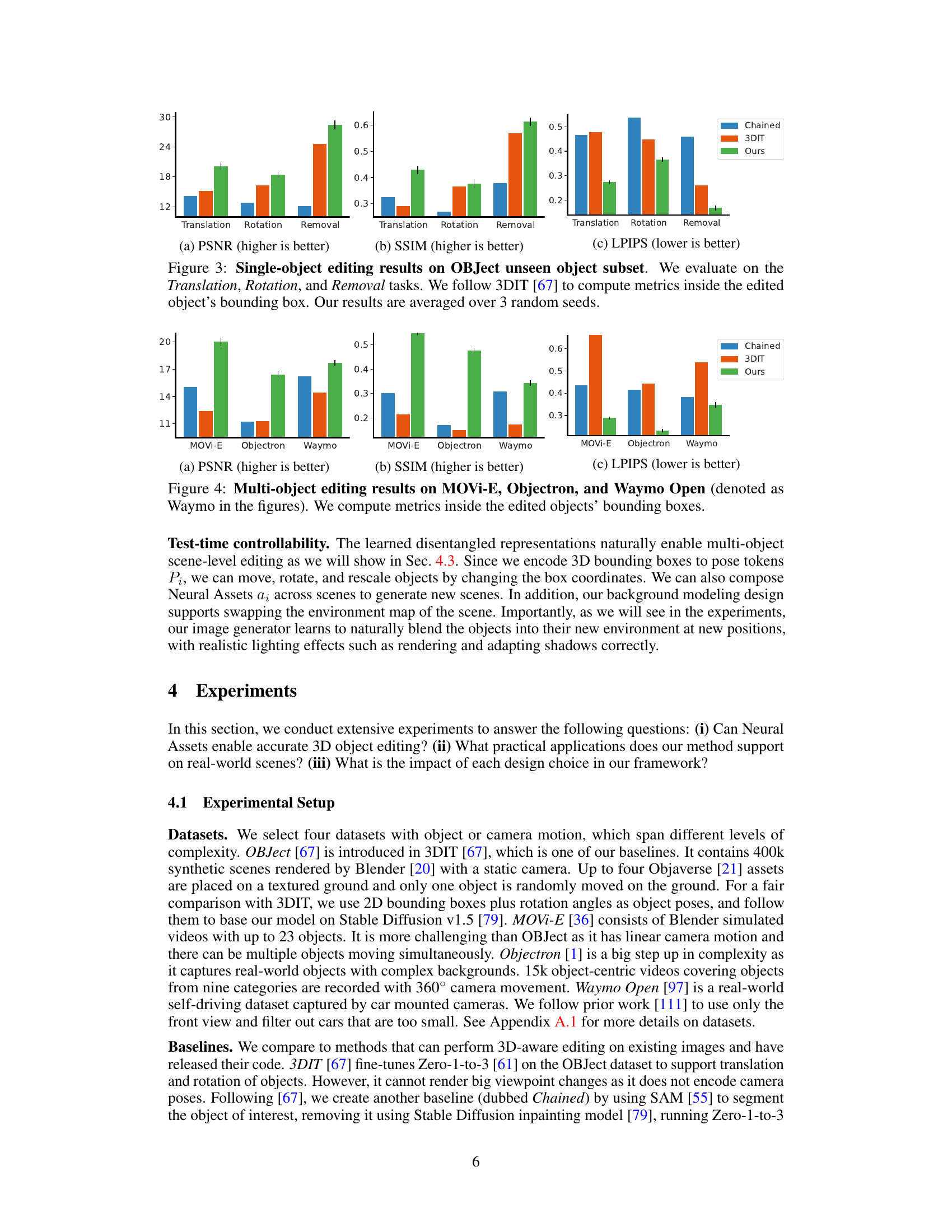
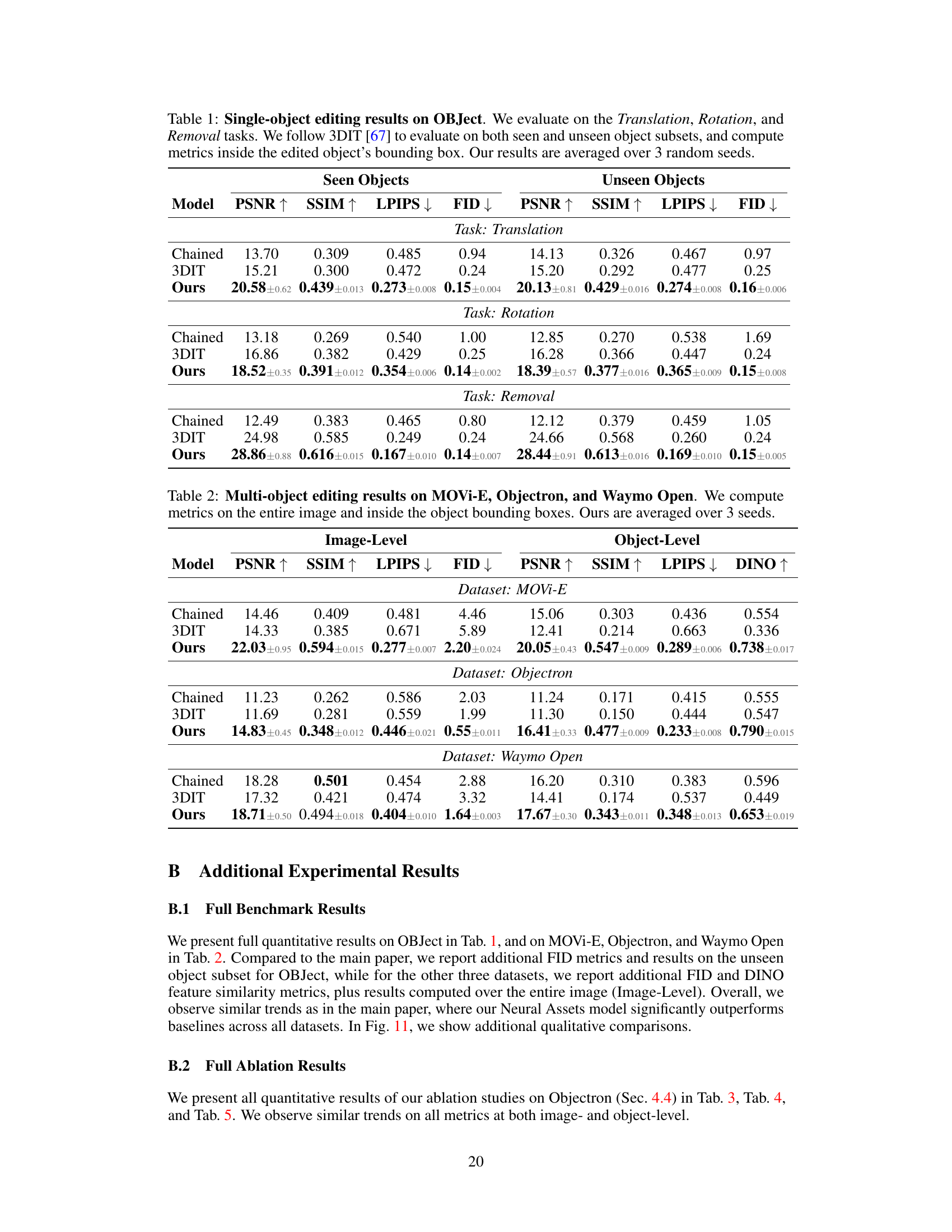
This table presents the quantitative results of single-object editing experiments conducted on the OBJect dataset. The experiments involve three tasks: translation, rotation, and removal of objects. The results are broken down for both ‘seen’ (objects present in the training data) and ‘unseen’ objects (objects not seen during training), showing performance metrics (PSNR, SSIM, LPIPS, FID) within the bounding box of the edited object. The reported values are averages across three random trials.
In-depth insights#
3D Pose Control#
Achieving 3D pose control in image generation presents a significant challenge. Traditional methods often rely on 3D models and rendering, a process that can be computationally expensive and lack flexibility. The use of Neural Assets offers a potential solution, leveraging visual representations of objects along with pose information to disentangle appearance and pose features. This allows for fine-grained control of multiple objects in a scene, even in complex, real-world scenarios. A key advantage is that this approach maintains the text-to-image architecture of existing diffusion models, allowing for seamless integration with pre-trained models. Furthermore, the ability to transfer and recompose Neural Assets across scenes opens exciting avenues for compositional scene generation, going beyond the limitations of simply manipulating objects within a static background. Challenges remain in handling complex object interactions, occlusion, and the inherent ambiguities present in interpreting 3D information from 2D images. However, the combination of object-centric representations and diffusion models offers a promising path towards intuitive and efficient 3D scene manipulation.
Neural Assets#
The concept of “Neural Assets” presents a novel approach to 3D-aware multi-object scene synthesis using image diffusion models. Instead of relying solely on text prompts, Neural Assets disentangle object appearance and 3D pose, creating more precise control. They’re learned by encoding visual features from a reference image and pose information from a target image, enabling the model to reconstruct objects under varying poses. This disentanglement is crucial for achieving fine-grained control over individual object placement and manipulation in a scene. Further, transferability and recomposition of Neural Assets across different scenes demonstrate their generalizability and potential for compositional scene generation. This approach moves beyond previous methods limited by 2D spatial understanding and the need for paired 3D training data, thereby opening possibilities for sophisticated multi-object editing in complex real-world scenes.
Multi-Object Editing#
The concept of multi-object editing within the context of image generation using diffusion models presents exciting possibilities and significant challenges. The core idea revolves around precisely manipulating multiple objects within a single scene, controlling individual object poses (position, orientation, scale) independently and simultaneously. This surpasses the limitations of single-object editing, enabling complex scene modifications beyond what’s achievable with text prompts alone. Disentangling object appearance and pose is crucial for effective multi-object editing, as it allows independent control without undesired cross-influences. The success of this approach hinges on the development of robust object representations, which encapsulate both visual characteristics and 3D pose information, facilitating both precise manipulation and compositional scene generation. This technology has significant potential for applications in computer graphics, animation, video editing, and virtual reality, offering more intuitive and efficient workflows for content creation.
Compositional Gen#
Compositional generation, in the context of visual AI models, signifies the ability to combine and manipulate existing visual elements to create novel scenes or images. It moves beyond simple image editing by enabling the construction of complex scenes through the modular arrangement of individual assets. This approach is particularly powerful because it allows for flexible and intuitive control over the composition. Instead of generating images from scratch, the system assembles them from a library of pre-trained components (like objects or backgrounds) that can be recombined and modified. This modularity offers advantages in terms of efficiency and scalability. Furthermore, disentangling object appearance and pose, as seen in the use of Neural Assets, is vital for compositional generation. This disentanglement enables independent control over visual attributes and spatial properties, facilitating the seamless integration of objects from disparate sources into a cohesive scene.
Future Directions#
Future research could explore extending Neural Assets to handle dynamic scenes with non-rigid objects, addressing limitations in current 3D understanding. This involves developing techniques for representing and controlling objects undergoing deformation or articulated motion. Another crucial direction is improving robustness to noisy or incomplete data. Current methods rely on high-quality 3D annotations which are challenging and expensive to obtain. Research on leveraging weaker forms of supervision or self-supervision would significantly broaden applicability. Furthermore, investigating efficient training and inference strategies is paramount to scaling Neural Assets to handle more complex scenes with greater numbers of objects. Exploring alternative model architectures or leveraging more efficient training techniques would make the approach more practical for large-scale applications. Finally, examining generalization to unseen objects and scenes is important. While the paper shows transferability, improving generalizability would further solidify the technique and expand its practical value.
More visual insights#
More on figures
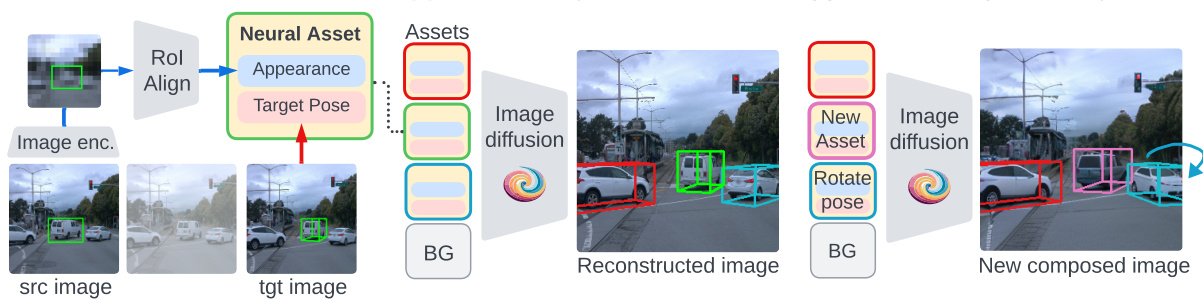
This figure illustrates the Neural Assets framework. Panel (a) shows how Neural Assets are created by combining appearance and pose features extracted from paired video frames. Panel (b) depicts the training process, where a diffusion model learns to reconstruct a target image based on the Neural Assets and a background token. Finally, panel (c) demonstrates inference, where Neural Assets are manipulated to control object pose and composition in a generated image.
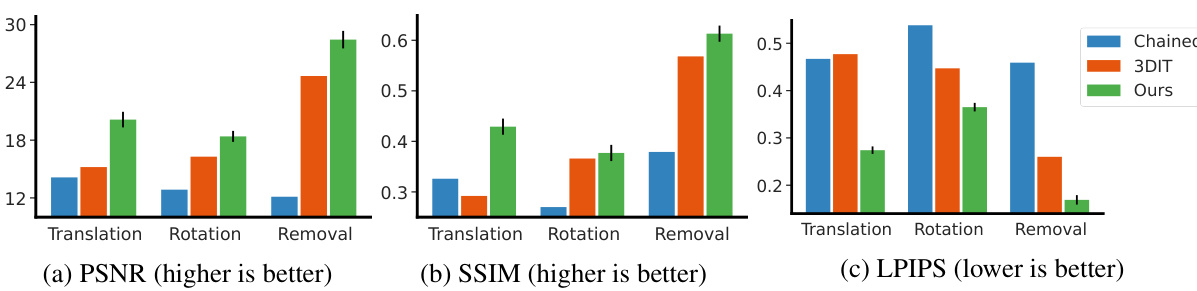
The figure shows the quantitative results of single-object editing on the unseen object subset of the OBJect dataset. Three editing tasks are evaluated: translation, rotation, and removal. Performance is measured using PSNR, SSIM, and LPIPS, calculated within the bounding box of the edited object. The results show that the proposed method outperforms the baselines (Chained and 3DIT) on all three tasks.
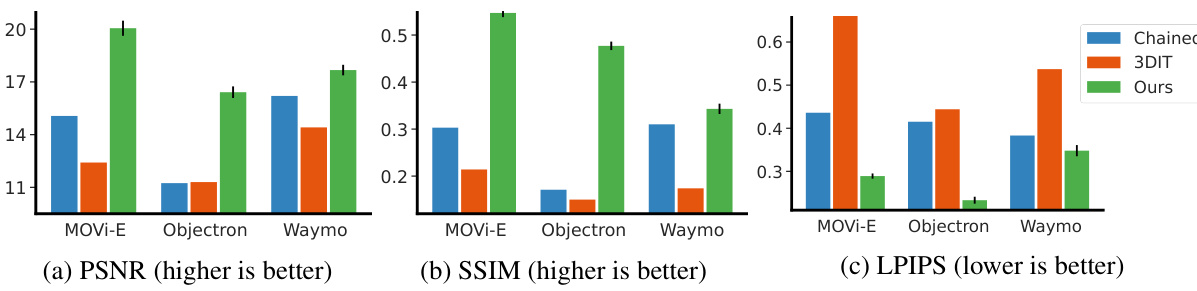
The figure shows a comparison of multi-object editing results on three datasets: MOVi-E, Objectron, and Waymo Open. The results are evaluated using PSNR, SSIM, and LPIPS metrics, which are calculated within the bounding boxes of the edited objects to isolate the editing quality from the surrounding image context. The figure visually demonstrates the superior performance of the proposed ‘Ours’ method compared to two baselines (‘Chained’ and ‘3DIT’).

This figure shows examples of 3D-aware image editing using Neural Assets. It demonstrates the ability to manipulate individual objects within a scene by translating, rotating, rescaling, replacing, or changing the background. The figure highlights the model’s capacity for fine-grained control and compositional generation.

This figure shows examples of object translation and rotation on the Waymo Open dataset. The results demonstrate that by manipulating the 3D bounding boxes provided as input, the model can successfully translate and rotate objects within the scene. The green boxes highlight the objects before and after the transformation. To see the changes more clearly, videos of these edits are available on the project’s webpage.

This figure shows several image editing results using the proposed Neural Asset method on the Waymo Open dataset. The top row demonstrates the model’s ability to reconstruct the original image, remove objects, segment objects, replace objects, and recompose objects from different scenes. The bottom row shows similar edits on another image. The results illustrate the versatility and control offered by the Neural Asset approach for complex scene manipulation.

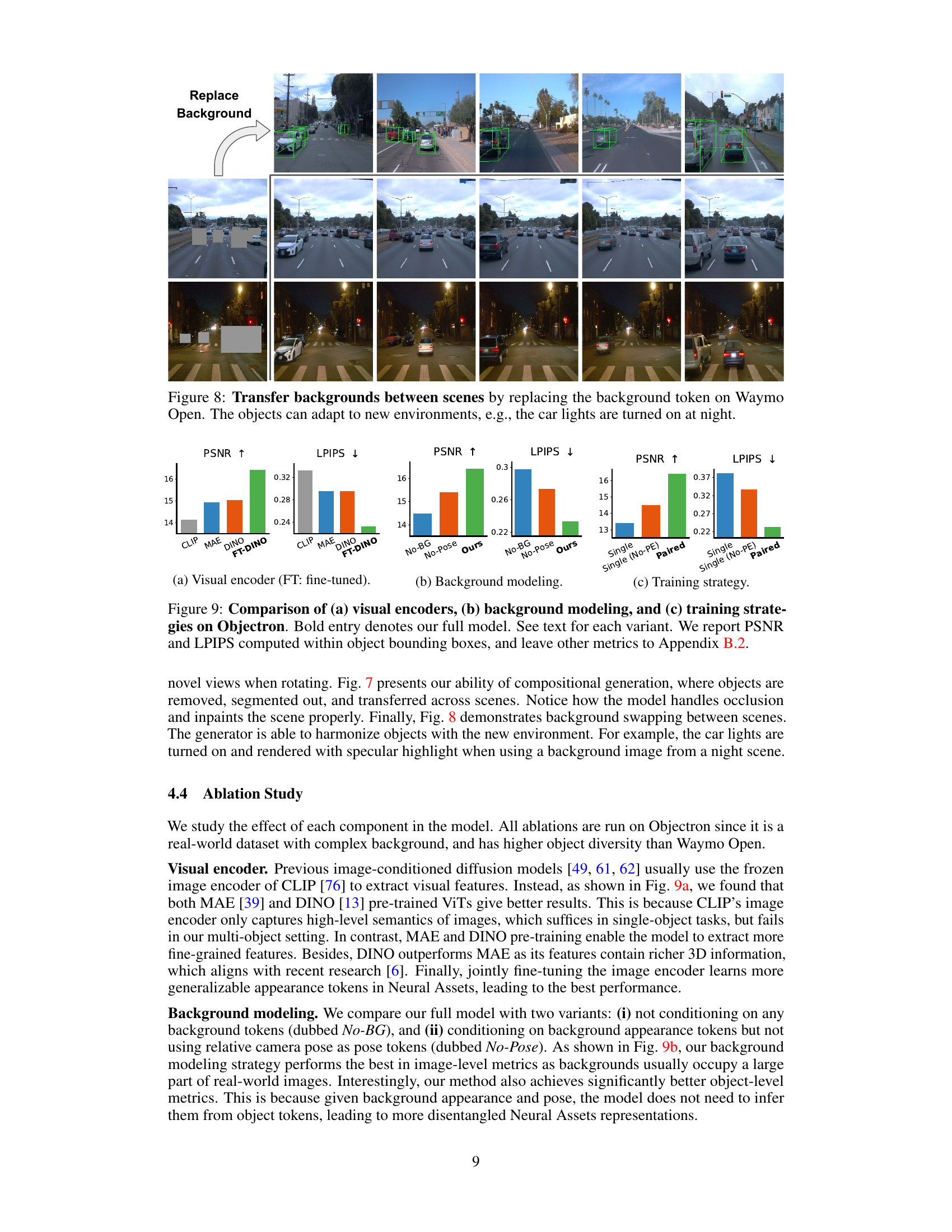
This figure demonstrates the capability of the model to transfer backgrounds between different scenes. By replacing the background token, the objects in the foreground seamlessly integrate into the new background, adapting to lighting and other environmental changes. The example shows how car headlights are correctly rendered when a nighttime background is applied.
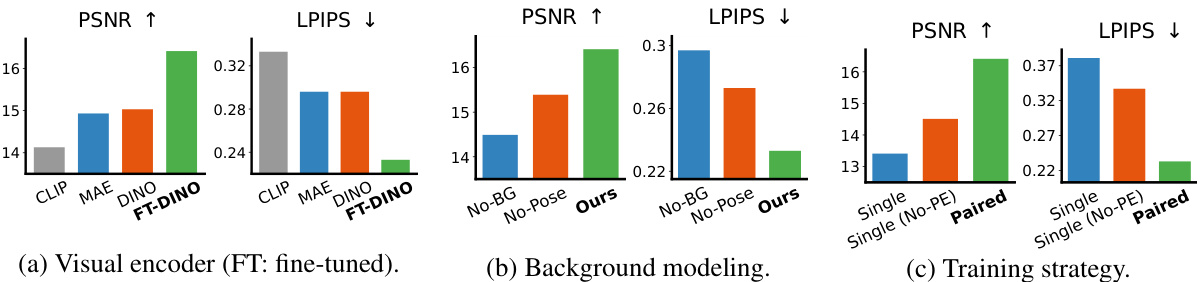
This figure shows the ablation study results on the Objectron dataset. It compares different components of the Neural Assets model: visual encoders (CLIP, MAE, DINO, and fine-tuned DINO), background modeling (with and without background, with and without pose), and training strategies (single frame, single frame without positional encoding, and paired frames). The results, measured using PSNR and LPIPS within object bounding boxes, demonstrate the effectiveness of the chosen components in the full model.

This figure shows two failure cases of the Neural Assets model. The first case demonstrates symmetry ambiguity where rotating an object by 180 degrees causes a flipped appearance (e.g., a cup’s handle). The second case illustrates camera-object motion entanglement, where moving a foreground object also results in background movement. These limitations suggest the need for training data with greater diversity to improve model robustness.

This figure shows a qualitative comparison of the results obtained by three different methods (Chained, 3DIT, and Ours) on three different datasets (MOVi-E, Objectron, and Waymo Open) for the task of multi-object editing. Each row corresponds to one dataset, and shows the source image, the results of each method, and the target image. The green boxes in the images highlight the objects that are being edited. The results show that the proposed method (Ours) outperforms the baselines by maintaining better object identity and consistency, resulting in a more realistic image.

This figure demonstrates the capabilities of the Neural Asset model for 3D-aware multi-object scene editing. Starting from a source image with identified object bounding boxes, the model can precisely manipulate individual objects by translating, rotating, and rescaling them. Furthermore, it showcases the model’s ability to perform compositional generation, enabling the transfer of objects or background elements between different images.

This figure shows the results of replacing the background token on the Objectron dataset. The model successfully adapts the foreground objects to new backgrounds, demonstrating an understanding of scene context and lighting. The consistent object appearances and lighting effects in the generated images showcases the effectiveness of the Neural Asset framework in handling multi-object scenes.
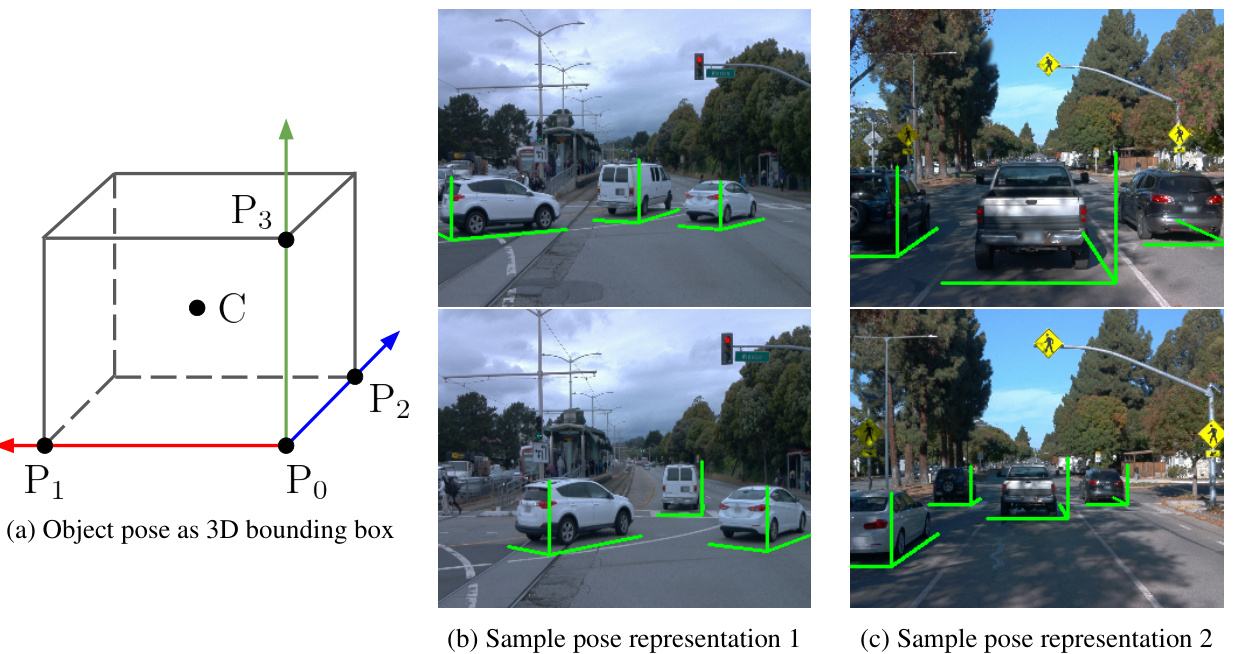
This figure illustrates how the 3D pose of an object is represented using its projected corners in the image plane. The four projected corners (P0, P1, P2, P3) form a local coordinate system for the object, capturing its position, orientation, and scale in the scene. The example images (b and c) show how this representation translates to real-world scenes, where the green lines denote the projected corners and the object’s pose.
More on tables
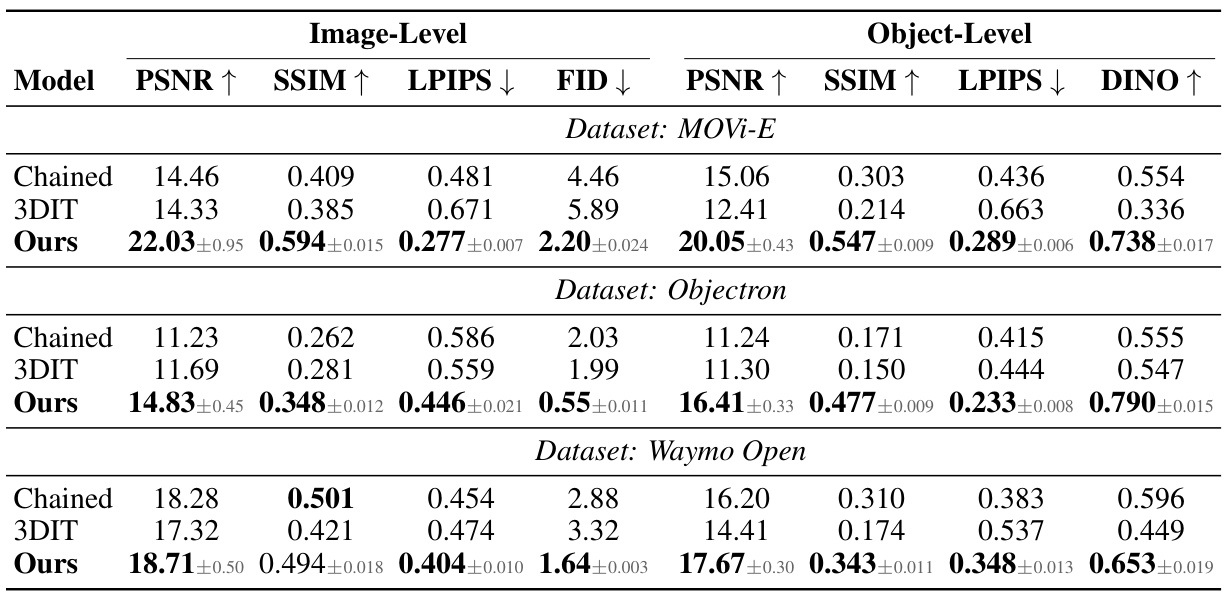
This table presents the quantitative results of multi-object editing experiments on three datasets: MOVi-E, Objectron, and Waymo Open. It compares the performance of the proposed Neural Assets model against two baselines, Chained and 3DIT, across various metrics: PSNR, SSIM, LPIPS, FID, and DINO. The metrics are evaluated both at the image level (considering the entire image) and at the object level (focusing solely on the edited objects). The results highlight the superior performance of the Neural Assets model in multi-object editing tasks.
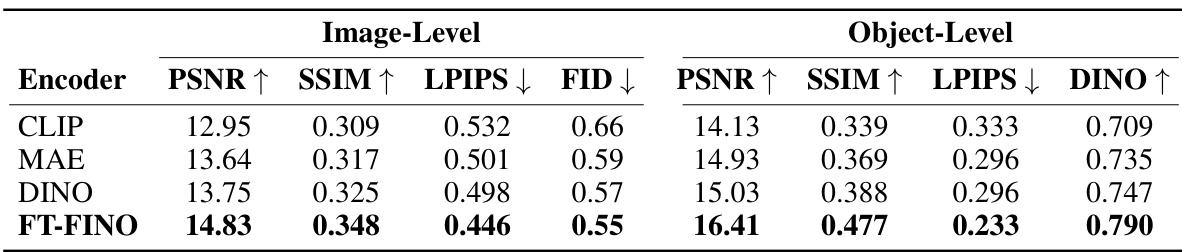
This table presents the ablation study results on the Objectron dataset, focusing on the impact of different visual encoders on the model’s performance. It compares the performance using CLIP, MAE, DINO, and a fine-tuned DINO (FT-DINO) as visual encoders. The metrics used to evaluate the model include PSNR, SSIM, LPIPS, FID (image-level), and PSNR, SSIM, LPIPS, and DINO (object-level). The results show the effectiveness of using a fine-tuned DINO as the visual encoder compared to the others.

This table presents the ablation study result on the background modeling of the proposed method. It compares the performance of three variants: (1) No-BG (no background modeling), (2) No-Pose (background modeling without relative camera pose), and (3) Ours (full model with background modeling and relative camera pose). The metrics used are PSNR, SSIM, LPIPS, FID at the Image level and PSNR, SSIM, LPIPS, and DINO at the Object level.

This table presents the ablation study of different training strategies on the Objectron dataset. It compares the performance of training with single frames versus paired frames (source and target frames from videos) for learning Neural Assets. It also includes a variant where positional encoding is removed from the ViT image encoder. The metrics used are PSNR, SSIM, LPIPS, FID (image-level), and PSNR, SSIM, LPIPS, and DINO (object-level). The results show that paired frame training significantly improves performance compared to single frame training, demonstrating the importance of learning disentangled appearance and pose features.
Full paper#