↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current 3D object detection methods often serialize 3D voxel data into 1D sequences before feeding them to Transformers. This serialization process sacrifices the spatial proximity of voxels, significantly affecting detection accuracy. While enlarging group sizes can help, it comes with the significant drawback of increased computational cost due to the quadratic complexity of Transformers.
To address these issues, Voxel Mamba introduces a group-free strategy utilizing State Space Models (SSMs). The linear complexity of SSMs makes it feasible to process all voxels as a single sequence, eliminating the need for grouping and preserving spatial proximity. Further enhancing spatial awareness, Voxel Mamba incorporates a novel Dual-scale SSM Block and Implicit Window Partition to handle larger receptive fields and improved local 3D region preservation. Experimental results demonstrate that Voxel Mamba achieves superior accuracy and efficiency compared to other state-of-the-art methods on Waymo Open Dataset and nuScenes.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Voxel Mamba, a novel group-free approach to 3D object detection that significantly improves accuracy and efficiency. This addresses a critical challenge in existing methods by overcoming limitations in handling spatial proximity when serializing 3D data into 1D sequences for processing by Transformers. The efficiency gains make it practical for various applications. The group-free strategy and novel dual-scale SSM block design open exciting new avenues for research in efficient and accurate 3D object detection.
Visual Insights#
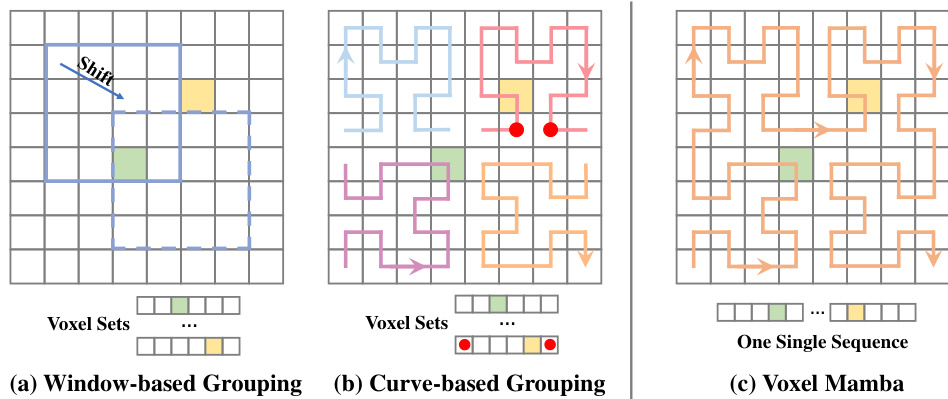
This figure compares three different voxel grouping strategies for 3D object detection in point clouds. (a) shows the traditional window-based grouping, where voxels are grouped into fixed-size windows. (b) illustrates curve-based grouping, which uses a space-filling curve to serialize voxels into sequences, but may still result in spatial proximity loss. (c) presents the proposed Voxel Mamba method, which employs a group-free strategy, serializing all voxels into a single sequence to maintain complete spatial proximity and avoid the complexity limitations of large groups in Transformers.
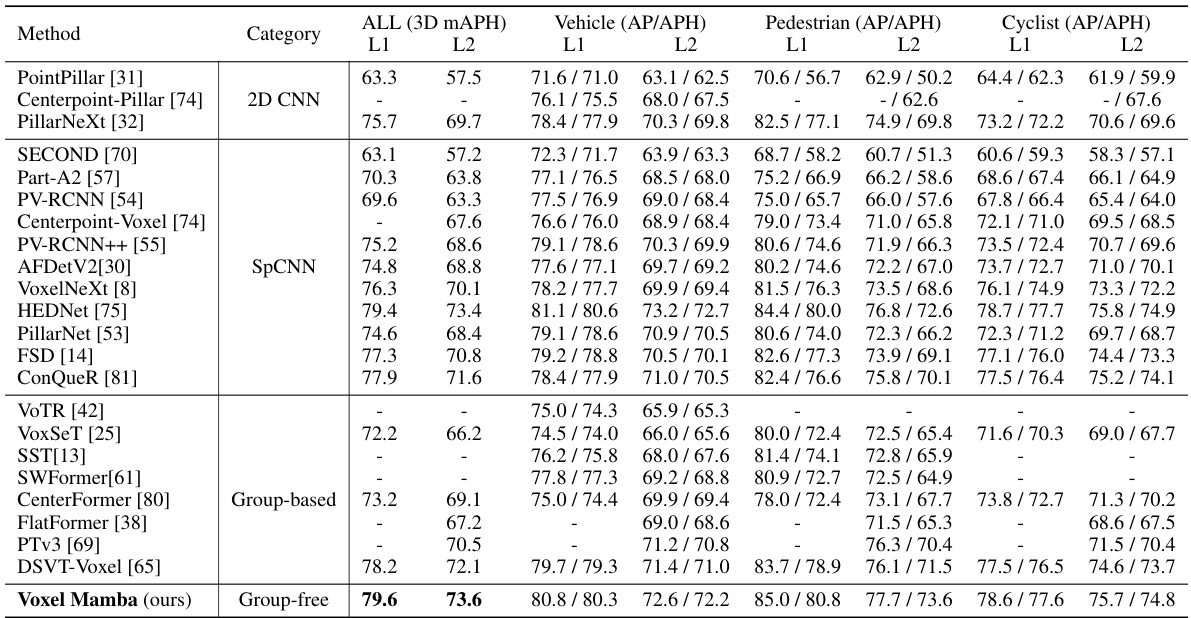
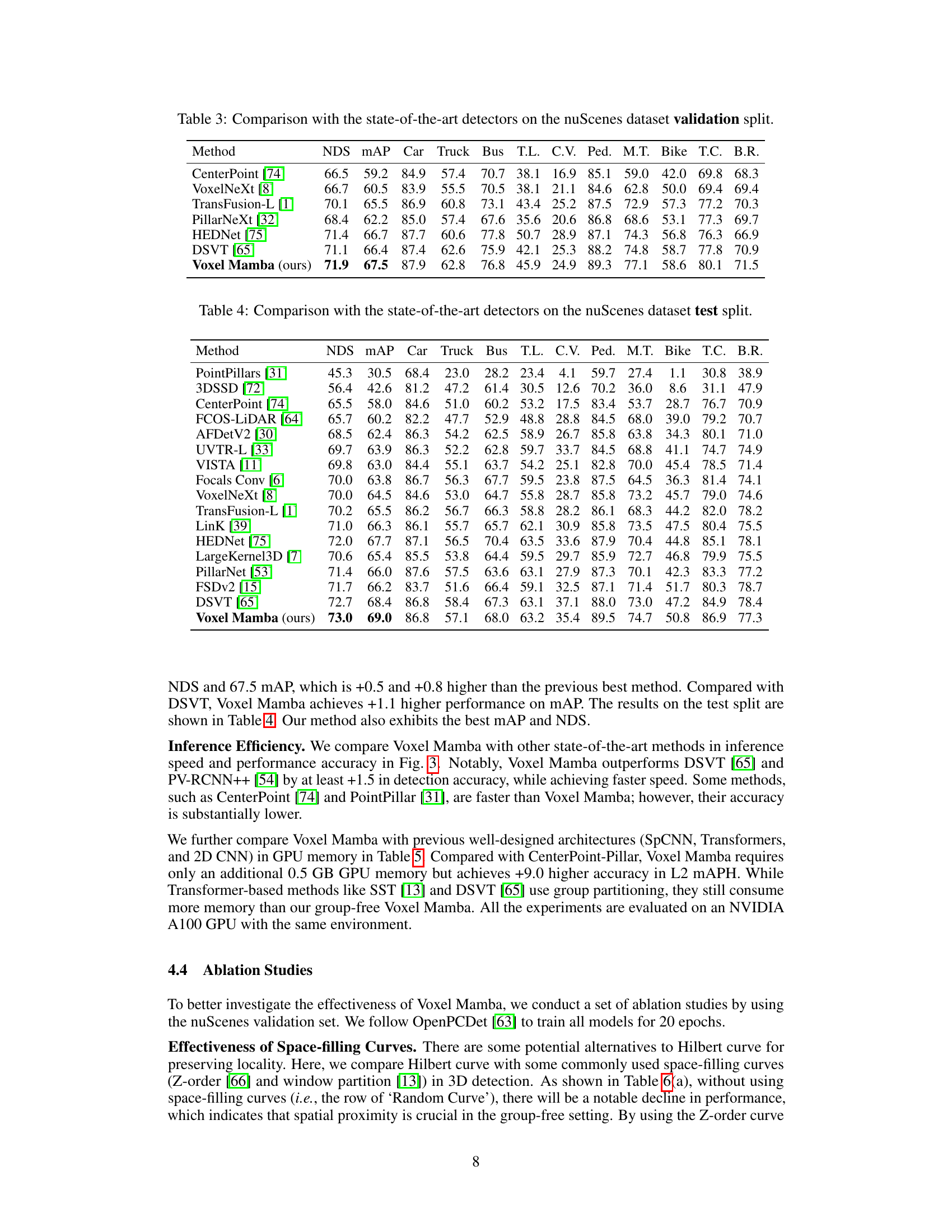
This table presents a comparison of the performance of various 3D object detection methods on the validation set of the Waymo Open Dataset. The comparison focuses on single-frame performance, meaning that each method’s prediction is based on a single frame of data, not multiple frames. The table shows the performance of different methods across three object categories: vehicles, pedestrians, and cyclists. For each category, the results are presented as mean Average Precision (mAP) and mean Average Precision weighted by heading accuracy (mAPH) at two levels (L1 and L2), indicating the confidence of detection and accuracy of the predicted heading direction. The symbol ‘-’ indicates that the result is not available for the corresponding method.
In-depth insights#
Group-Free Voxel SSM#
A hypothetical ‘Group-Free Voxel SSM’ in 3D object detection from point clouds offers a novel approach to address limitations of existing serialization-based methods. Traditional methods group voxels into sequences, losing spatial context. This proposed method processes the entire 3D voxel space as a single sequence using state space models (SSMs), thus avoiding the quadratic complexity and spatial information loss associated with group-based Transformers. The group-free nature significantly improves efficiency, as it removes the complex grouping operations. Furthermore, techniques like a dual-scale SSM block might enhance spatial proximity by incorporating hierarchical feature representations from multiple resolutions. This potentially allows for the model to learn both local and global features effectively, improving accuracy. Finally, implicit window partition could encode positional information to further enhance spatial awareness within this single sequence. The result may be a computationally efficient and highly accurate 3D object detection system.
Dual-Scale SSM Block#
The proposed Dual-Scale SSM Block (DSB) is a key innovation designed to enhance the spatial proximity of voxels within the Voxel Mamba architecture. It cleverly addresses the inherent limitation of serializing 3D voxel data into a 1D sequence by introducing a hierarchical structure and bidirectional processing. The forward SSM branch processes high-resolution voxel features while the backward branch handles lower-resolution features, derived from a downsampled Bird’s-Eye View (BEV) representation. This dual-scale approach allows the model to integrate both fine-grained details from high-resolution data and broader context from lower-resolution representations, thereby significantly expanding the effective receptive field and improving the overall perception of spatial relationships between voxels in the 3D scene. The incorporation of a residual connection further enhances the information flow and facilitates efficient training of this crucial module, leading to improved model performance and accuracy.
Implicit Windowing#
Implicit windowing, as a concept in point cloud processing, addresses the challenge of balancing local and global context within a computationally efficient framework. Traditional methods often rely on explicit window partitioning, which can limit the model’s ability to capture long-range dependencies and may introduce artificial boundaries. Implicit windowing offers an elegant solution by incorporating positional information implicitly. Instead of explicitly dividing the point cloud into windows, it encodes positional relationships into feature embeddings. This approach allows the network to implicitly attend to local neighborhoods while simultaneously capturing the broader spatial context, resulting in improved feature representations without the computational overhead of explicit partitioning. The key advantage is the ability to retain more spatial information, leading to more robust and accurate object detection compared to methods relying on explicit grouping. However, careful design of the positional encoding is crucial to ensure the effectiveness of this approach. The success hinges on the ability to encode the information rich enough to capture both local and global context without creating artificial boundaries.
3D Object Detection#
3D object detection, a crucial aspect of computer vision, is rapidly evolving. This field focuses on accurately identifying and localizing objects within three-dimensional space, using various data sources like LiDAR point clouds or RGB-D images. Recent advancements leverage deep learning, particularly transformer-based architectures, to address challenges such as sparsity, uneven distribution, and occlusion in the data. Serialization-based methods, although effective, suffer from a loss of spatial information due to the conversion of 3D data into 1D sequences. There is ongoing research into overcoming this limitation through innovative approaches like state space models (SSMs), which offer a group-free alternative, preserving spatial context more effectively. This is a significant area of focus as accurate and efficient 3D object detection underpins many applications, including autonomous driving, robotics, and augmented reality, driving the need for continuous improvement in algorithms and model architectures. The computational cost and deployment challenges remain major obstacles. Ongoing work explores solutions such as optimized implementations and hardware acceleration to address these hurdles.
Efficiency & Accuracy#
A research paper’s ‘Efficiency & Accuracy’ section would ideally present a nuanced comparison of different approaches. It should highlight how each method balances computational cost against performance metrics like precision, recall, and F1-score. The discussion would benefit from concrete examples showcasing the trade-offs: a method might boast superior accuracy but require significantly more processing time, rendering it impractical for real-time applications. Conversely, a faster algorithm might sacrifice some accuracy. Benchmarking against state-of-the-art methods is crucial, with clear visualizations (graphs, tables) demonstrating relative performance gains or losses. A deeper dive into the reasons behind the efficiency differences would be valuable, possibly involving architectural comparisons (e.g., depth, complexity, parameter count) or algorithmic analyses (e.g., time complexity). Ultimately, this section aims to guide readers in selecting the optimal method based on their specific needs, balancing accuracy demands with resource constraints.
More visual insights#
More on figures

This figure illustrates the overall architecture of Voxel Mamba, a novel 3D object detection model based on state space models (SSMs). The top panel shows the complete architecture, highlighting the use of multiple Dual-scale SSM Blocks (DSBs), a forward SSM branch and a backward SSM branch to process the voxel sequence. The bottom panel provides a detailed view of the DSB, showing how the forward and backward SSMs operate with downsampling and upsampling operations to integrate high and low-resolution information for improved spatial proximity. The model uses Hilbert Input Layer to serialize voxels from point clouds into a single sequence before feeding into the SSMs.

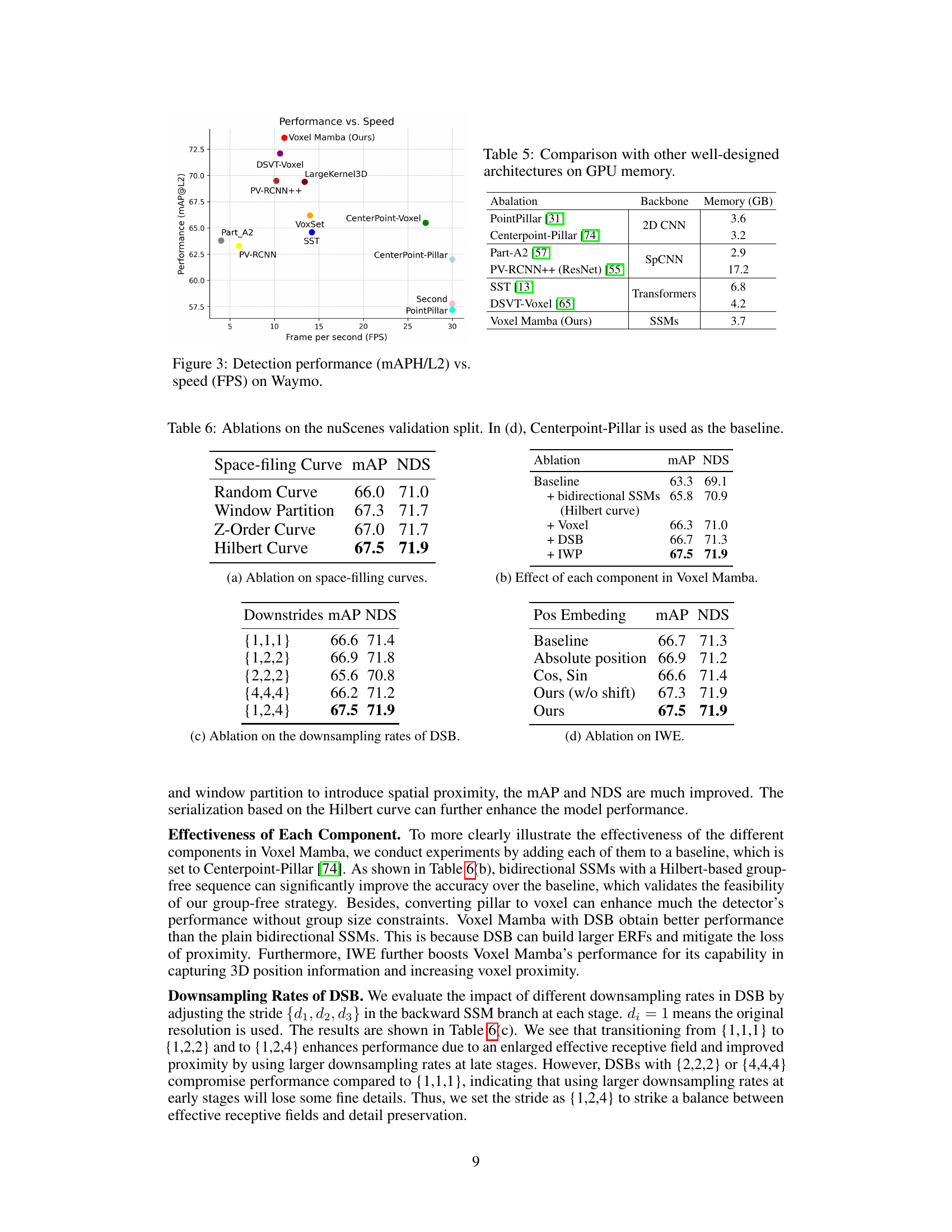
This figure shows a comparison of different 3D object detection methods on the Waymo Open Dataset, plotting their performance (measured by mean Average Precision at level 2, mAPH/L2) against their inference speed (frames per second, FPS). It visually compares the trade-off between accuracy and efficiency for various state-of-the-art methods, including Voxel Mamba, DSVT-Voxel, LargeKernel3D, PV-RCNN++, VoxSet, SST, Part_A2, CenterPoint-Voxel, CenterPoint-Pillar, Second, and PointPillar. The plot helps to understand how Voxel Mamba stands out in terms of both high accuracy and speed compared to other methods.

This figure compares the effective receptive fields (ERFs) of three different methods for 3D object detection: Voxel Mamba (group-free), a group-based bidirectional Mamba, and DSVT (window-based). The ERF visualizations illustrate the extent to which each method can effectively capture contextual information from the point cloud data. Voxel Mamba’s larger ERF is highlighted, showing its advantage in capturing more comprehensive local regions in 3D space compared to the other two methods.
More on tables
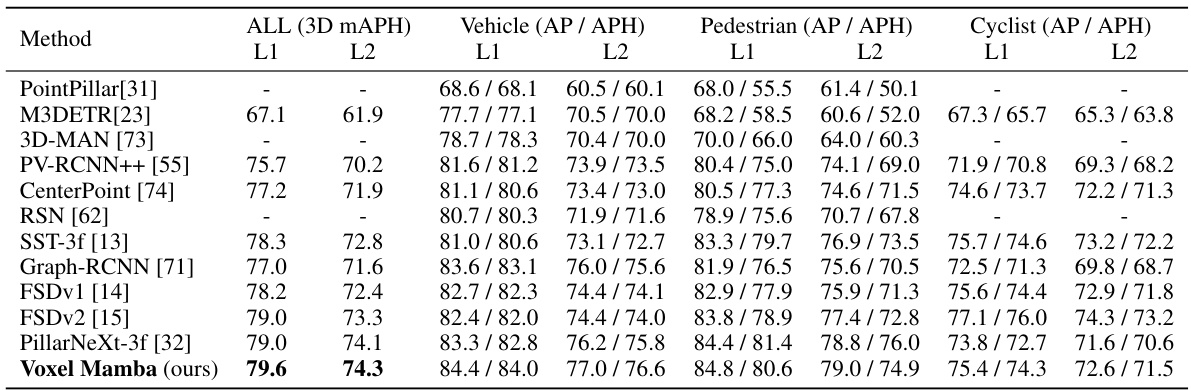
This table compares the performance of Voxel Mamba against other state-of-the-art 3D object detection methods on the Waymo Open Dataset test set. The metrics used are Level 1 and Level 2 mean average precision (mAP) and mean average precision with heading accuracy (mAPH) for all object categories (ALL), vehicles, pedestrians, and cyclists. The ‘3f’ designation indicates results obtained using a three-frame model, representing temporal context.
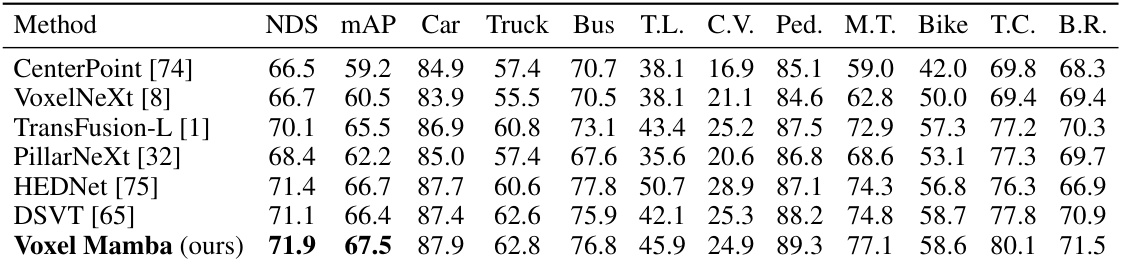
This table compares the performance of Voxel Mamba with other state-of-the-art 3D object detection methods on the nuScenes validation dataset. The metrics used include NDS (NuScenes Detection Score), mAP (mean Average Precision), and per-category AP (Average Precision) for various object classes (Car, Truck, Bus, Train, Trailer, Cyclist, Pedestrian, Motorcycle, Bicycle, Construction Vehicle, Barrier). It showcases the competitive performance of Voxel Mamba in terms of overall accuracy and class-specific performance.

This table presents a comparison of the proposed Voxel Mamba model’s performance against several state-of-the-art 3D object detection methods on the nuScenes test dataset. The metrics used for comparison include the nuScenes Detection Score (NDS) and mean Average Precision (mAP), broken down by object category (Car, Truck, Bus, Trailer, Construction Vehicle, Pedestrian, Motorcycle, Bicycle, Traffic Cone, Barrier). The table highlights Voxel Mamba’s competitive performance, showcasing its improved accuracy compared to existing methods.
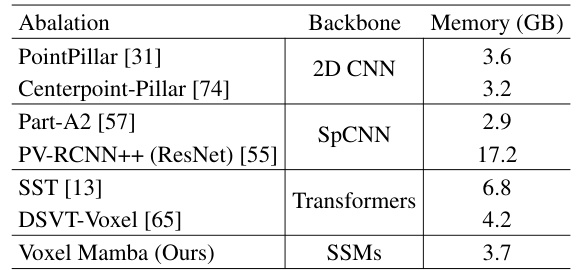
This table compares the GPU memory usage of Voxel Mamba with other state-of-the-art 3D object detection methods. It shows that Voxel Mamba, using SSMs, is more memory-efficient than methods based on Transformers or SpCNN, while achieving comparable or better accuracy.
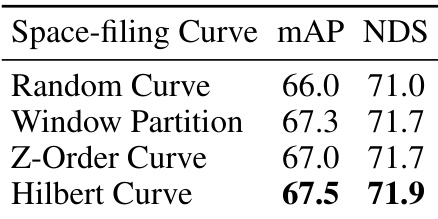
This table presents the ablation study results conducted on the nuScenes validation dataset. It explores the impact of different components and design choices of the proposed Voxel Mamba model on its performance, as measured by mAP and NDS. Specifically, it investigates the effects of different space-filling curves, the dual-scale SSM block (DSB) with varying downsampling rates, the implicit window partition (IWP), and positional embeddings on model accuracy. The table allows for a detailed comparison of the contributions of each component towards the overall performance gains.

This table presents the ablation study results on the nuScenes validation dataset. It shows the impact of each component of the proposed Voxel Mamba model on the mAP and NDS metrics. The baseline is Centerpoint-Pillar, and the components added sequentially are bidirectional SSMs (with Hilbert curve), Voxel, DSB (Dual-scale SSM Block), and IWP (Implicit Window Partition). The table demonstrates how each addition improves performance.
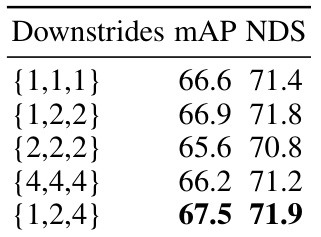
This ablation study investigates the impact of different components and hyperparameters of the Voxel Mamba model on the nuScenes dataset. Specifically, it evaluates the effects of different space-filling curves, downsampling rates in the Dual-scale SSM Block (DSB), the Implicit Window Partition (IWP), and positional embeddings. The results, presented as mAP and NDS scores, demonstrate the contributions of each component and the optimal hyperparameter settings for improved performance.
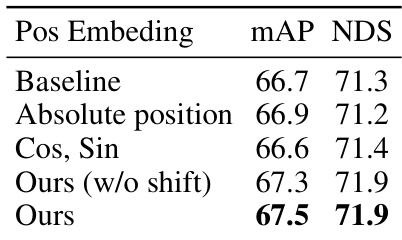
This table presents ablation study results on the nuScenes validation dataset. It investigates the impact of different components and hyperparameters of the proposed Voxel Mamba model on its performance, measured by mAP and NDS. The ablation experiments cover various aspects: space-filling curves, components of Voxel Mamba (bidirectional SSMs, voxel representation, DSB, and IWP), downsampling rates of DSB, and positional embedding methods. The baseline used in part (d) is CenterPoint-Pillar.
Full paper#