↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Vision-Language Models (VLMs) are powerful but often struggle with limited training data, hindering their ability to generalize well to new tasks. Existing transductive approaches, designed to leverage unlabeled data for improved accuracy, have had limited success when applied to VLMs. This paper addresses this gap by highlighting the limitations of existing transductive few-shot methods for VLMs and proposing TransCLIP.
TransCLIP is a novel, computationally efficient transductive approach that enhances VLMs. It works as a plug-and-play module to improve zero- and few-shot models, optimizing a new objective function that incorporates a KL divergence penalty integrating text-encoder knowledge. This approach ensures guaranteed convergence and decoupled updates, leading to efficient transduction even with large datasets. Experimental results show that TransCLIP significantly outperforms standard approaches, demonstrating improved generalization capabilities.
Key Takeaways#
Why does it matter?#
This paper is important because it presents TransCLIP, a novel and computationally efficient method for boosting vision-language models using transduction. This offers a plug-and-play module that improves the performance of existing models without extensive retraining. The method’s scalability to large datasets and compatibility with various existing inductive models make it highly relevant to current research trends in VLMs, opening new avenues for enhancing model generalization and efficiency.
Visual Insights#
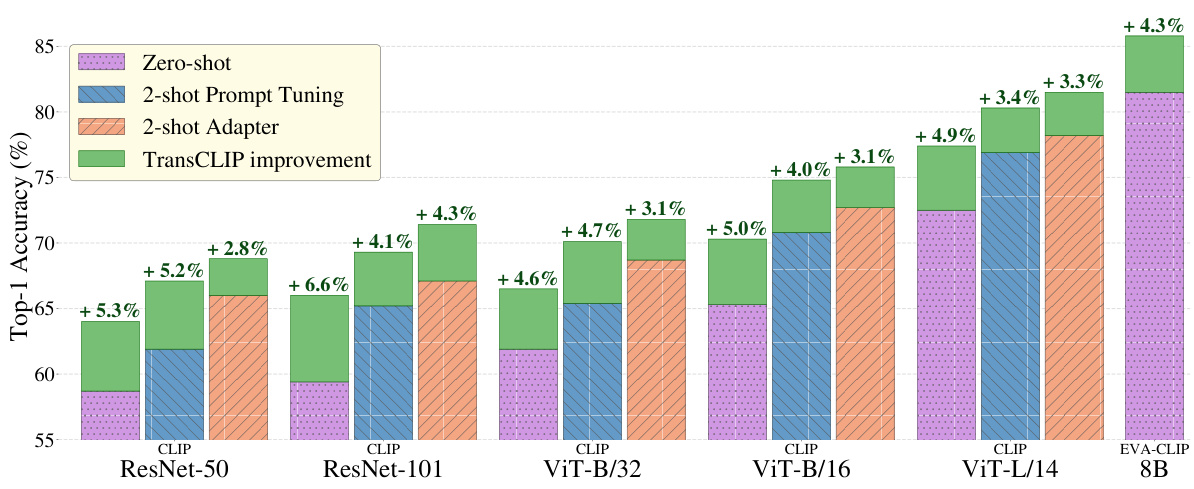
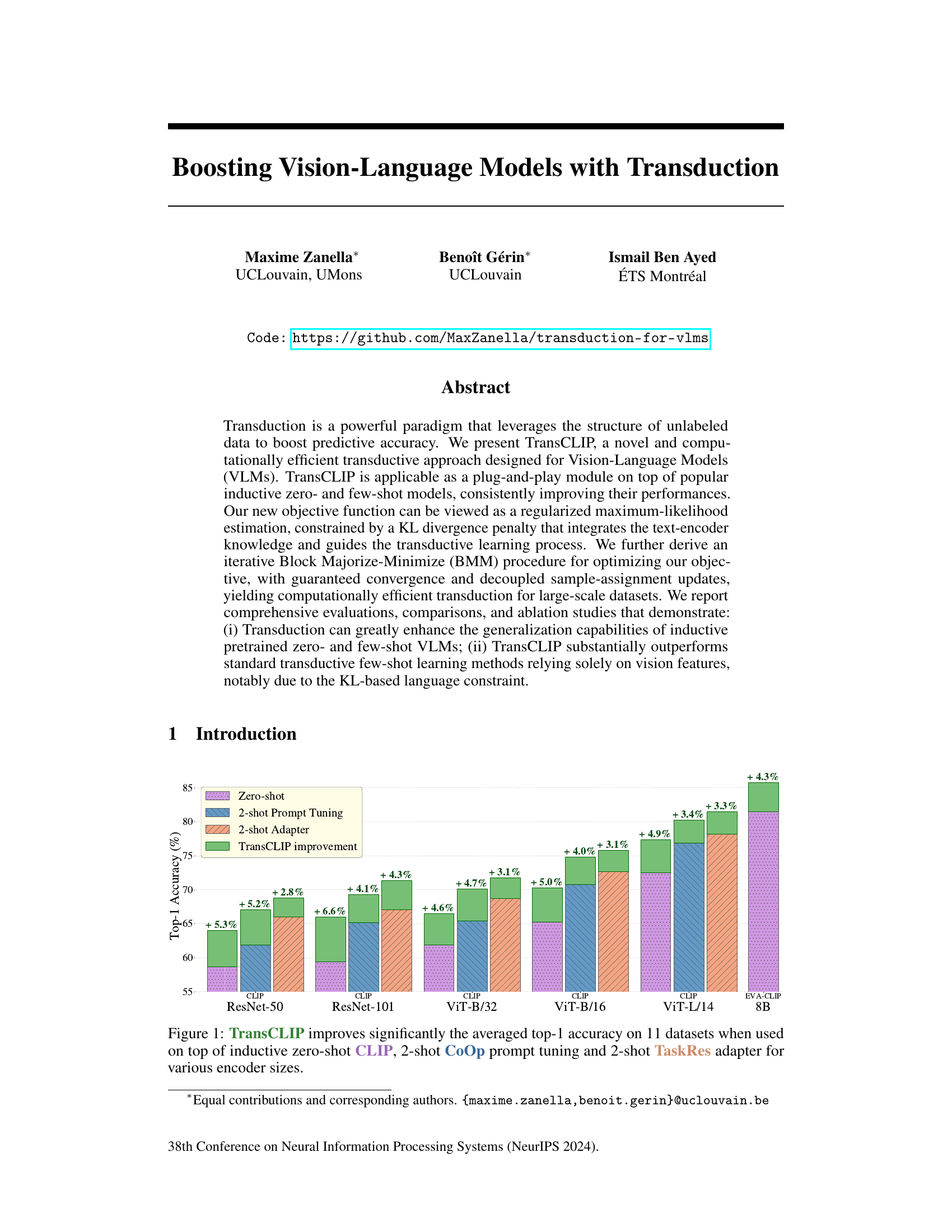
This figure shows a grouped bar chart visualizing the performance improvement achieved by TransCLIP across different vision-language model setups. The chart compares the top-1 accuracy on 11 datasets for three baseline approaches: zero-shot CLIP, 2-shot prompt tuning using CoOp, and 2-shot adapter using TaskRes. Each group of bars represents a different vision encoder size (ResNet-50, ResNet-101, ViT-B/32, ViT-B/16, ViT-L/14, and EVA-CLIP 8B). The green portion of each bar shows the improvement in accuracy obtained by adding TransCLIP to the baseline method. The results demonstrate the consistent improvement provided by TransCLIP across various models and datasets, highlighting its effectiveness as a plug-and-play module.
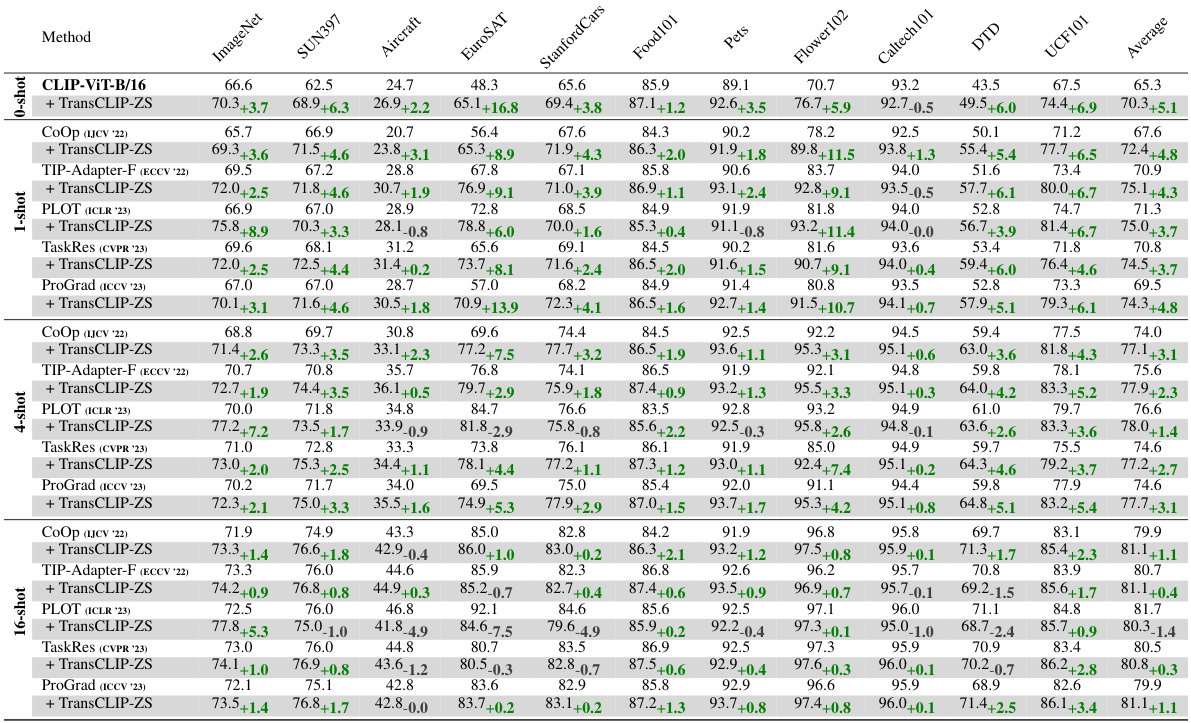
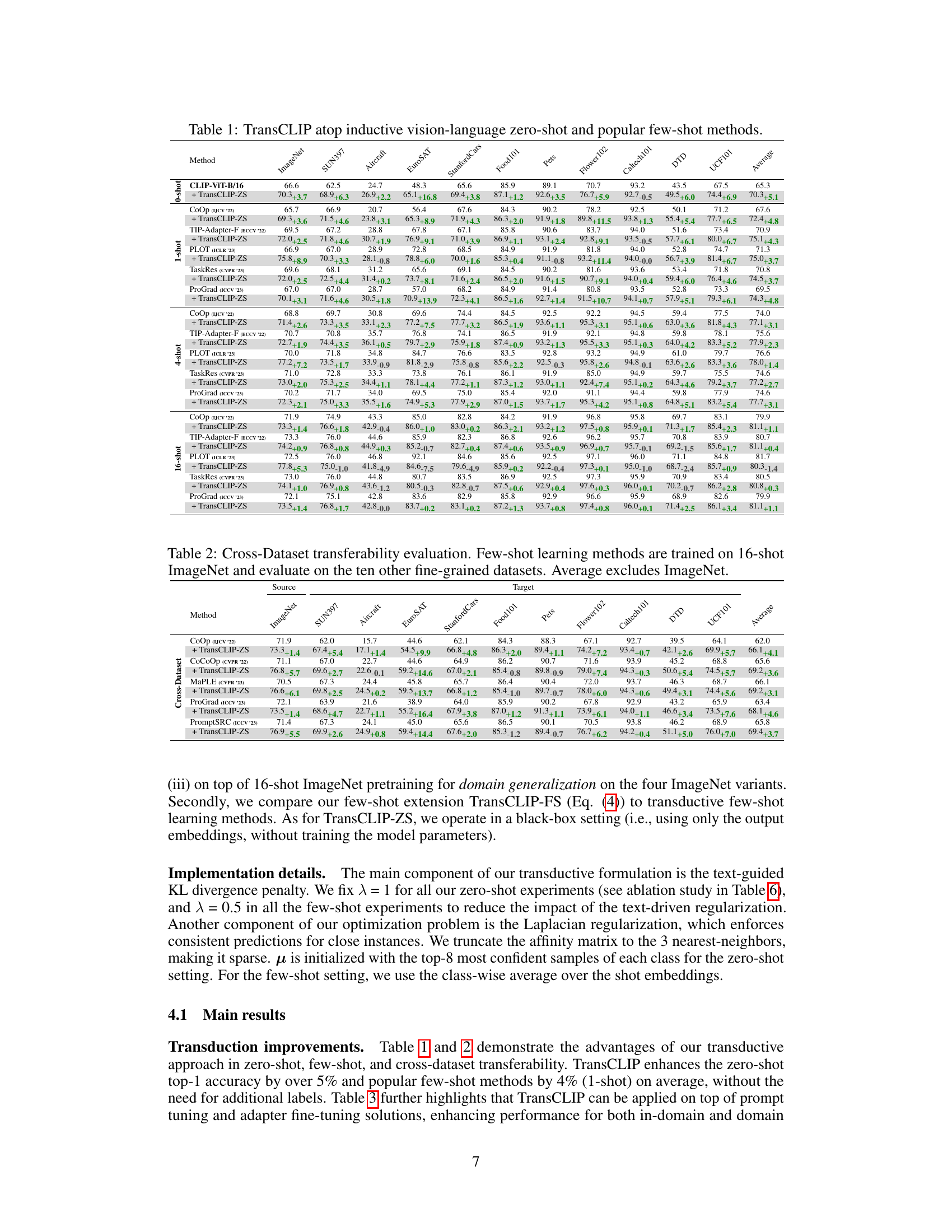
This table presents the results of applying TransCLIP to several vision-language models. It compares the performance of inductive zero-shot and few-shot methods (CLIP, CoOp, TIP-Adapter-F, PLOT, and TaskRes, ProGrad) with and without the TransCLIP module across eleven datasets. The table shows that TransCLIP consistently improves the top-1 accuracy of these methods, highlighting its effectiveness as a plug-and-play module for enhancing the performance of vision-language models.
In-depth insights#
TransCLIP:Method#
The TransCLIP method is a novel transductive approach for vision-language models (VLMs). It functions as a plug-and-play module, enhancing existing zero-shot and few-shot models without requiring retraining. TransCLIP achieves this by introducing a novel objective function, regularized to incorporate text-encoder knowledge. KL divergence plays a crucial role, guiding the transductive learning process while maintaining computational efficiency through a derived iterative BMM procedure. The method’s effectiveness is demonstrated through comprehensive evaluations on multiple datasets, and ablation studies highlight the individual contributions of its core components, such as the text knowledge penalty and efficient sample-assignment updates. The method’s performance is consistently improved by leveraging the underlying structure of unlabeled data, making it a significant advance in improving VLM generalization.
Transduction Benefits#
The concept of transduction, in the context of Vision-Language Models (VLMs), offers compelling advantages. Transductive methods leverage the structure of unlabeled data in the target dataset to enhance model performance, improving generalization capabilities beyond inductive approaches. By integrating information from all test samples simultaneously, transduction can capture relationships and patterns missed by inductive methods that treat each sample independently. This is particularly beneficial for zero- and few-shot learning scenarios where limited labeled data hinders the inductive model’s ability to learn robust representations. Transduction’s strength lies in its capability to refine predictions using the collective information, thereby boosting accuracy, particularly on challenging datasets or tasks. This improved accuracy is further amplified by incorporating text-based knowledge, as demonstrated by the KL-divergence penalty in TransCLIP, ensuring the model’s predictions are not drastically different from the initial zero-shot predictions. The result is a more robust and accurate VLM, even with limited supervision. While computationally more intensive than inductive methods, the improved accuracy and generalization capabilities of transduction often outweigh the computational cost, especially when dealing with large-scale datasets.
Vision-Language Models#
Vision-language models (VLMs) represent a significant advancement in artificial intelligence, aiming to bridge the gap between visual and textual data. VLMs excel at tasks requiring joint understanding of images and text, such as image captioning, visual question answering, and zero-shot image classification. Their success stems from the ability to learn rich, multimodal representations that capture the intricate relationships between visual features and linguistic descriptions. However, challenges persist in areas like bias mitigation and robustness to noisy or adversarial data. Existing VLMs often struggle with out-of-distribution generalization, as their performance degrades when presented with inputs significantly different from those seen during training. Furthermore, the computational cost of training and deploying VLMs can be substantial, which limits their accessibility to researchers and developers with limited resources. Future research should address these shortcomings, focusing on developing more efficient training methods, improving robustness and generalizability, and creating techniques that alleviate biases inherent in the training data, thereby unlocking the full potential of VLMs for diverse real-world applications.
Ablation Studies#
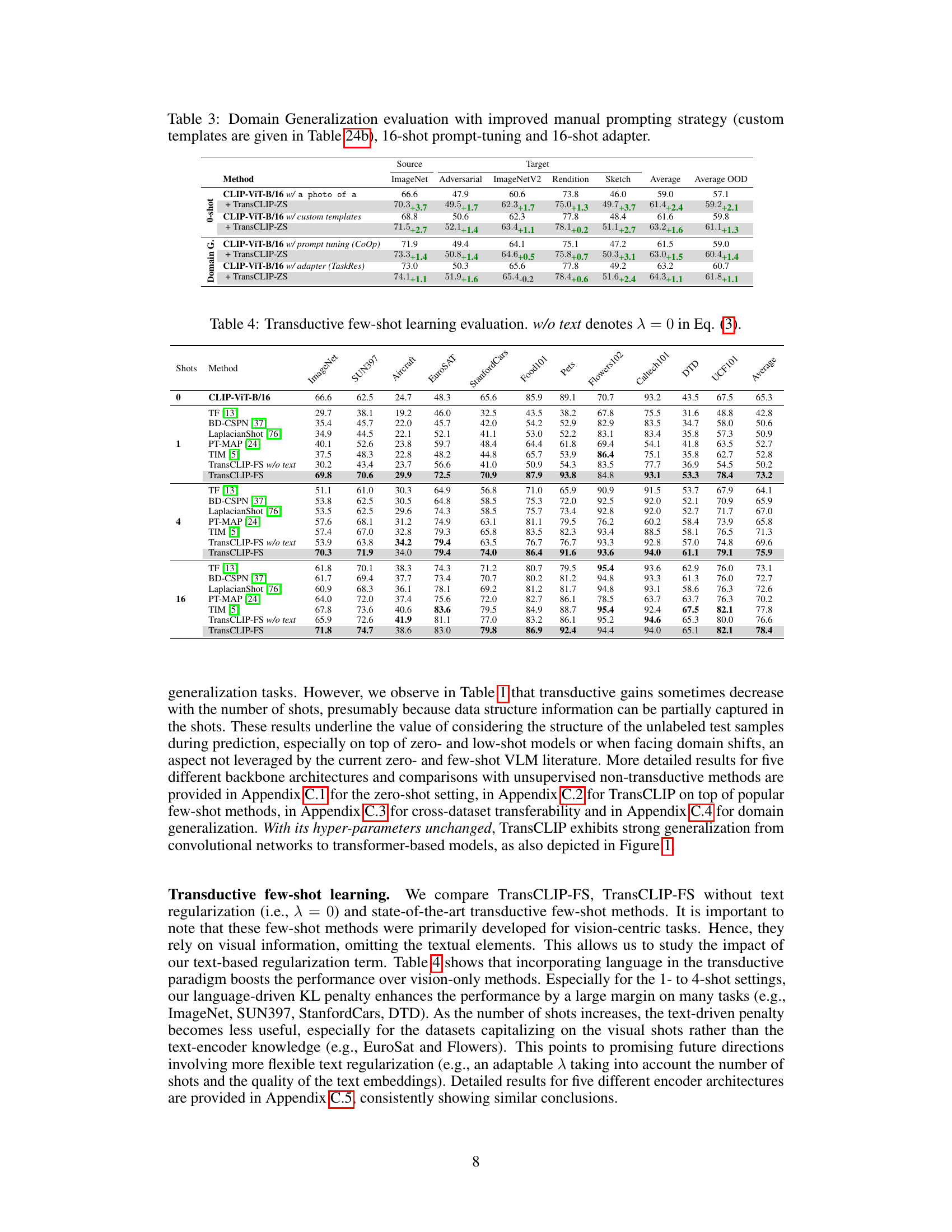
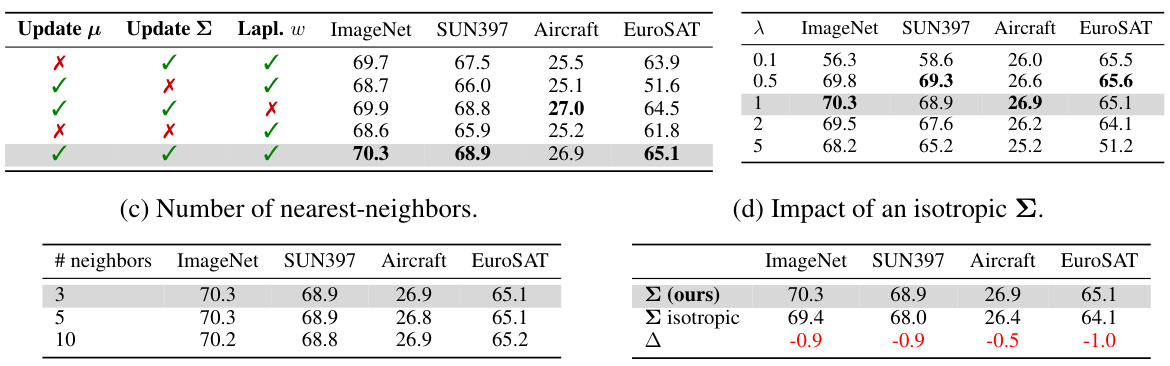
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of the research paper, this would involve progressively disabling parts of the TransCLIP architecture (e.g., the KL divergence penalty, Laplacian regularization, or the GMM-based clustering) to evaluate their impact on performance. The results would reveal which components are essential for TransCLIP’s success and highlight their relative importance. For example, if removing the KL divergence term significantly reduces accuracy, it demonstrates the crucial role of language information in guiding the transduction process. Similarly, ablation studies can help to disentangle the effects of different components, showing whether they work synergistically or independently. Such experiments are valuable for understanding the inner workings of a complex method, aiding future development, and guiding the design of improved or more efficient variants. Careful examination of the ablation study’s results is important for establishing confidence in the robustness and effectiveness of the TransCLIP method. These studies serve to verify that each component is not redundant but contributes significantly to achieving the performance gains.
Future Work#
The paper’s conclusion suggests several avenues for future research. Improving the text-guided KL divergence term is a priority, perhaps by incorporating adaptive class-wise weighting to handle unreliable text prompts. This would enhance robustness and address situations where textual descriptions are less informative. Further investigation is warranted to explore why transductive gains sometimes diminish with increasing numbers of shots. Exploring the interplay between data structure and shot learning could lead to more effective methods in few-shot scenarios. Finally, the authors highlight the need for more extensive analysis of biases inherent to text embeddings and how these biases might influence the performance of the method. The potential for applying TransCLIP to even larger models is also a promising area for future exploration.
More visual insights#
More on tables
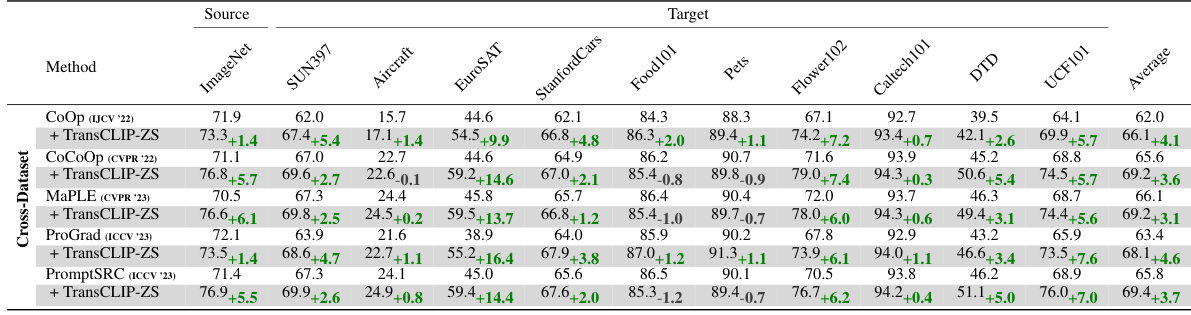
This table presents the results of applying TransCLIP (a novel transductive approach) on top of several existing inductive zero-shot and few-shot methods for vision-language models. It shows the top-1 accuracy achieved on 11 datasets (ImageNet and 10 fine-grained datasets) when TransCLIP is used as a plug-and-play module. The results are broken down by the base inductive method used (CLIP, COOP, TIP-Adapter-F, PLOT, and TaskRes) and the number of shots (0, 1, 4, 16) used in few-shot settings. The table demonstrates how TransCLIP improves the accuracy of existing methods across different datasets and shot settings.

This table presents the results of using TransCLIP on top of various inductive vision-language models. It shows the improvement in top-1 accuracy achieved by TransCLIP when added to different zero-shot and few-shot methods. The table compares performance across multiple datasets, using several different encoder sizes (ResNet-50, ResNet-101, ViT-B/32, ViT-B/16, EVA-CLIP 8B) and different few-shot methods (CoOp prompt tuning, TIP-Adapter-F, PLOT, TaskRes, ProGrad). The ‘Average’ column provides the average accuracy across the eleven datasets shown.

This table presents the results of applying TransCLIP to several popular inductive zero-shot and few-shot methods. It demonstrates the improvement in top-1 accuracy achieved by adding TransCLIP as a plug-and-play module. The table shows results across multiple datasets and different encoder sizes, highlighting the consistent performance gains provided by the TransCLIP method.
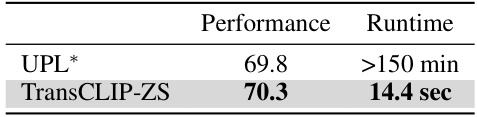
This table compares the performance and runtime of TransCLIP-ZS against UPL*, a transductive adaptation of an unsupervised prompt learning method, in a zero-shot setting. It highlights TransCLIP-ZS’s significant speed advantage while maintaining comparable performance.
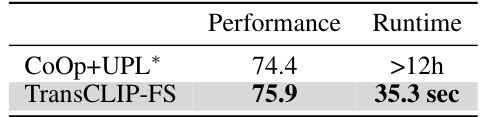
This table compares the performance and runtime of TransCLIP-ZS and TransCLIP-FS against CoOp+UPL*. TransCLIP shows significant performance gains with substantially faster runtime. The comparison highlights the efficiency advantage of TransCLIP.
This table presents the results of applying TransCLIP, a novel transductive approach, on top of several inductive zero-shot and few-shot vision-language models. It shows the top-1 accuracy achieved on 11 datasets (ImageNet, SUN397, Aircraft, EuroSAT, StanfordCars, Food101, Pets, Flower102, Caltech101, DTD, UCF101) for different vision encoders (ResNet-50, ResNet-101, ViT-B/32, ViT-B/16, EVA-CLIP) and different few-shot learning methods (zero-shot, CoOp, TIP-Adapter-F, PLOT, TaskRes, ProGrad). The table demonstrates the consistent improvements in accuracy obtained by adding TransCLIP as a plug-and-play module, showcasing its effectiveness in enhancing the performance of various VLMs.

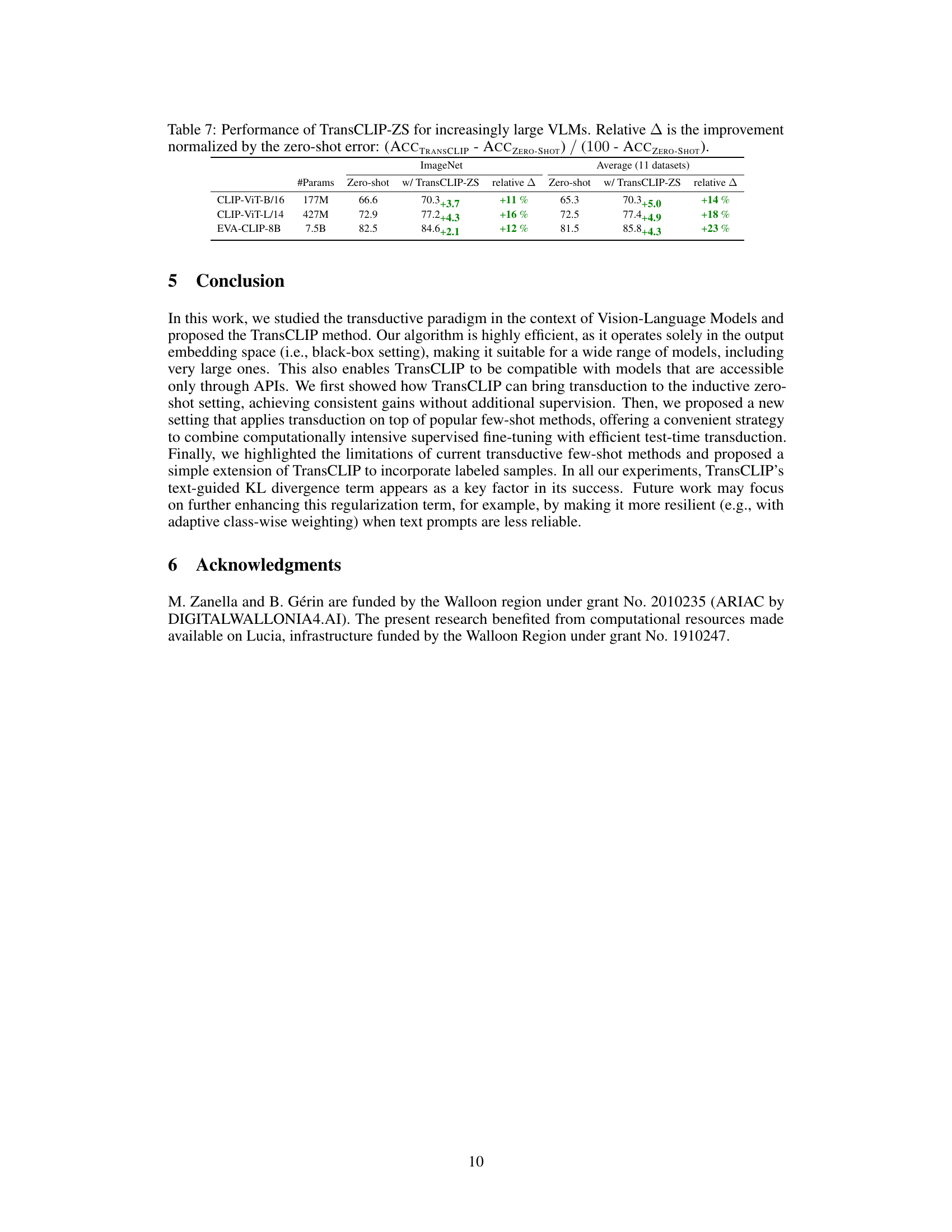
This table shows the performance of TransCLIP-ZS on three different sizes of vision-language models (VLMs) on ImageNet and an average of 11 datasets. It demonstrates the effectiveness of TransCLIP-ZS across various model scales by showing the increase in top-1 accuracy and the relative improvement compared to the original zero-shot performance. Larger models generally exhibit a larger absolute improvement, but the relative improvement is roughly consistent.

This table presents the performance improvement achieved by applying TransCLIP (a novel transductive approach) on top of various inductive zero-shot and few-shot learning methods. It showcases the improvements in Top-1 accuracy across 11 different datasets when TransCLIP is added as a plug-and-play module. The results are broken down by the number of shots used (zero-shot, 1-shot, 4-shot, and 16-shot) and the base inductive method used (CLIP with various vision encoders, COOP, TIP-Adapter-F, PLOT, and TaskRes). The table demonstrates the consistent improvement TransCLIP provides across different datasets and inductive methods.

This table presents a comparison of the performance of TransCLIP when used in conjunction with several inductive vision-language models. It shows the top-1 accuracy achieved by different zero-shot and few-shot methods (CLIP, CoOp, TIP-Adapter-F, PLOT, and TaskRes) on 11 image classification datasets, both with and without the addition of TransCLIP as a module. The results demonstrate the consistent improvement in accuracy that TransCLIP provides across various models and datasets.

This table presents the results of using TransCLIP on top of several inductive vision-language models. It compares the performance of zero-shot and few-shot (1, 4, and 16-shot) methods on ImageNet and ten other fine-grained datasets, showcasing the improvement achieved by adding TransCLIP. The methods compared are CLIP, CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad, highlighting TransCLIP’s consistent improvement across various base models and settings.
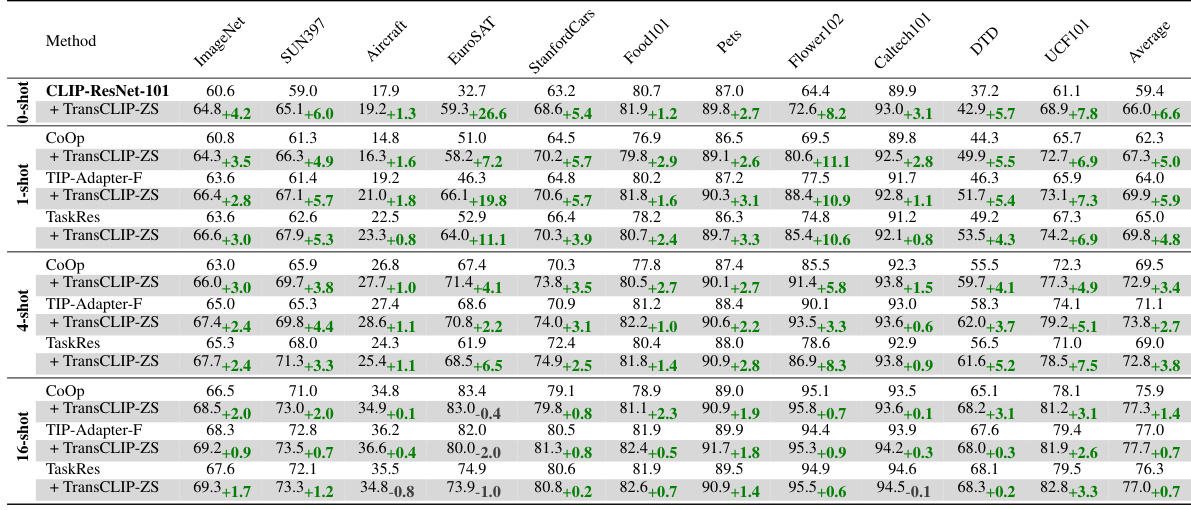
This table presents the results of applying TransCLIP to various vision-language models, both zero-shot and few-shot learning methods, across 11 datasets. It shows the improvement in top-1 accuracy achieved by adding TransCLIP as a plug-and-play module. The table compares the performance of several popular inductive models (CLIP, CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad) with and without TransCLIP, demonstrating consistent performance improvements across different model architectures and learning scenarios.
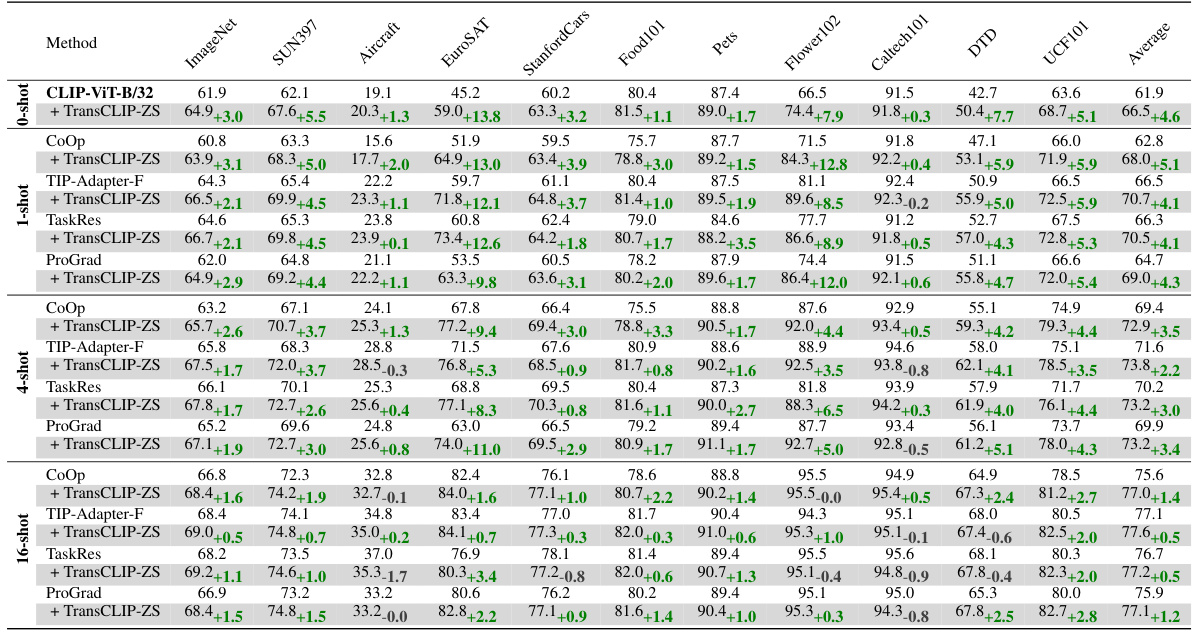
This table presents the results of applying TransCLIP to various inductive zero-shot and few-shot vision-language models. It shows the top-1 accuracy achieved on 11 different datasets (ImageNet, SUN397, Aircraft, EuroSAT, StanfordCars, Food101, Pets, Flower102, Caltech101, DTD, UCF101) for different model sizes (ViT-B/16) and different adaptation approaches (zero-shot, 1-shot, 4-shot). The table compares the performance of the base models with TransCLIP-ZS (zero-shot TransCLIP) applied to them. This demonstrates the improvement TransCLIP provides.
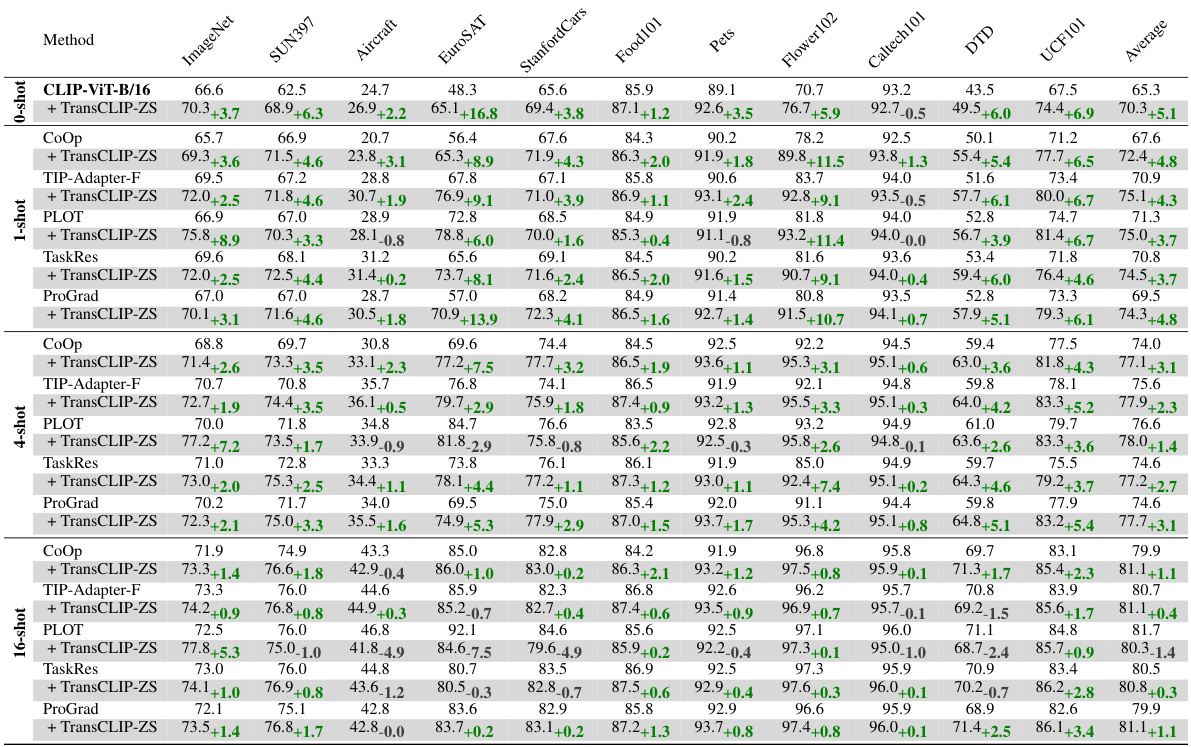
This table presents the results of TransCLIP when used on top of several inductive zero-shot and few-shot methods. It compares the top-1 accuracy across eleven datasets (ImageNet, SUN397, Aircraft, EuroSAT, Cars, Food101, Pets, Flowers101, Caltech101, DTD, UCF101) for various vision encoders (ResNet-50, ResNet-101, ViT-B/32, ViT-B/16, EVA-CLIP). The comparison is done for different shot settings (zero-shot, 1-shot, 4-shot, and 16-shot). Each row shows the baseline accuracy of a specific method and the improvement provided by adding TransCLIP. This allows evaluating the efficacy of TransCLIP in boosting various existing VLM methods.

This table presents the results of using TransCLIP (a novel transductive approach) on top of several inductive zero-shot and few-shot methods for vision-language models. It shows the top-1 accuracy achieved on 11 different datasets, comparing the performance of the baseline methods alone and with the addition of TransCLIP-ZS. The baseline methods include CLIP (zero-shot), CoOp (1-shot and 4-shot), TIP-Adapter-F (1-shot and 4-shot), PLOT (1-shot and 4-shot), and TaskRes (1-shot and 4-shot) using several different vision encoders.

This table presents the results of applying TransCLIP, a novel transductive approach, on top of various inductive zero-shot and few-shot methods for vision-language models. It shows the top-1 accuracy achieved on 11 datasets (ImageNet and 10 fine-grained datasets) when TransCLIP is used as a plug-and-play module. The table compares the performance of different base models (CLIP, CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad) both with and without TransCLIP. The results demonstrate the consistent performance improvements achieved by incorporating TransCLIP across different base models and datasets.

This table presents the results of using TransCLIP on top of various inductive vision-language models for zero-shot and few-shot image classification. It demonstrates the improvement in top-1 accuracy achieved by TransCLIP across multiple datasets and different model architectures (CLIP with various vision encoders and several few-shot methods). The table allows for a comparison of TransCLIP’s performance enhancement in both zero-shot and few-shot scenarios, highlighting its effectiveness as a plug-and-play module.

This table presents the results of using TransCLIP on top of several inductive vision-language models for zero-shot and few-shot learning. It shows the improvement in top-1 accuracy achieved by TransCLIP across multiple datasets and various model architectures (CLIP with different backbones and popular few-shot methods such as COOP, TIP-Adapter-F, PLOT, TaskRes, and ProGrad). The table highlights the consistent improvement offered by TransCLIP, enhancing the performance of both zero-shot and few-shot settings.

This table presents the results of applying TransCLIP, a novel transductive approach, to improve the performance of several inductive vision-language models on 11 datasets. The table compares the top-1 accuracy of several base zero-shot and few-shot methods (CLIP, CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad) against the results obtained after incorporating TransCLIP. The improvement in accuracy is shown for each method and dataset, demonstrating the effectiveness of the TransCLIP module in enhancing generalization capabilities across various models and tasks.
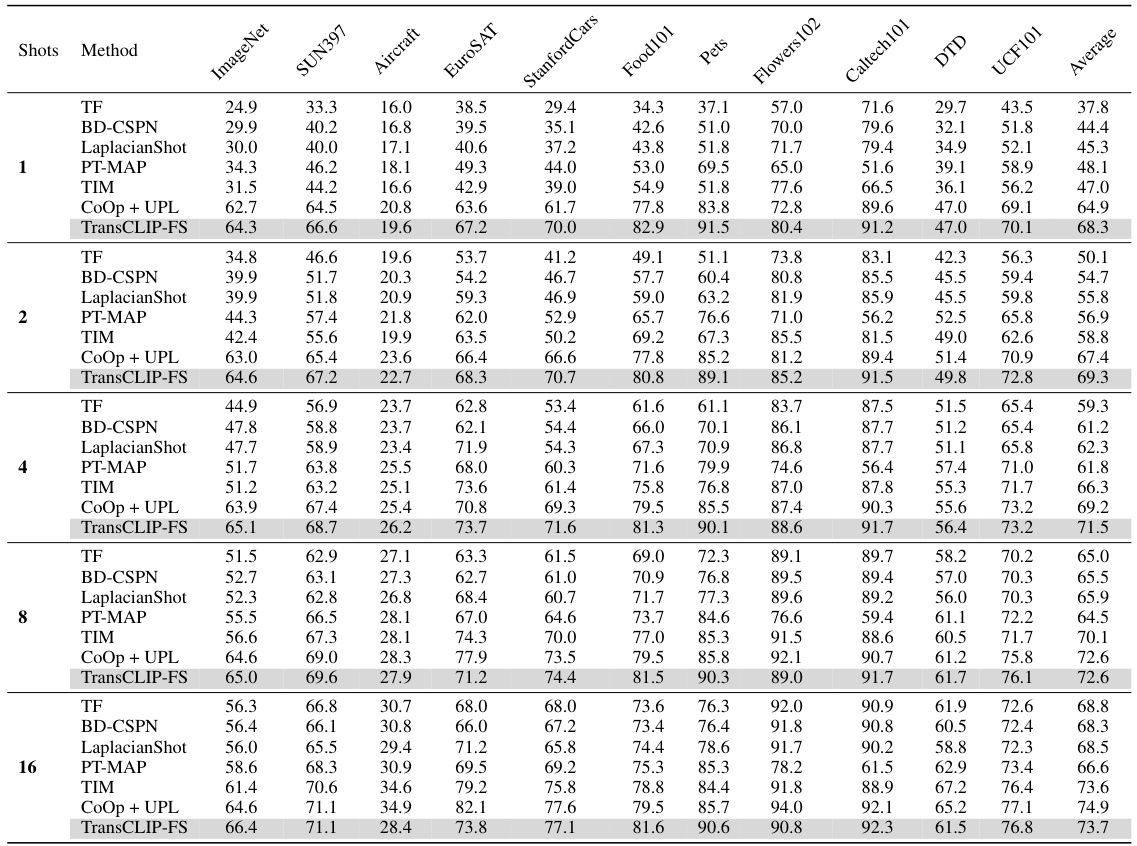
This table presents the performance comparison of TransCLIP with various inductive zero-shot and few-shot methods across eleven image classification datasets. The results are shown as top-1 accuracy and are broken down by the number of shots (0-shot, 1-shot, 4-shot, and 16-shot) used for the few-shot methods. The table allows for a clear comparison of how the proposed TransCLIP method enhances the performance of existing inductive baselines across different scenarios.
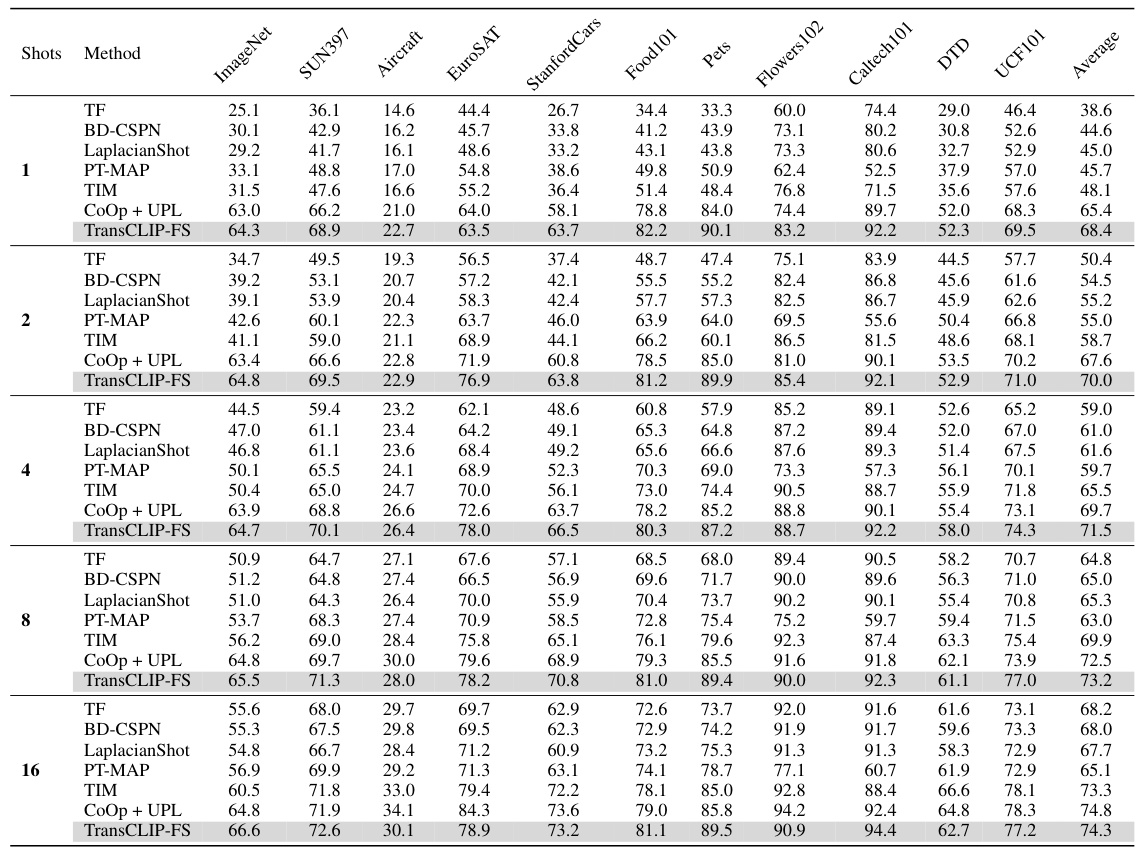
This table presents the results of applying TransCLIP (a novel transductive approach) on top of various inductive zero-shot and few-shot vision-language models. It shows the improvements in top-1 accuracy achieved by TransCLIP across multiple datasets (ImageNet, SUN397, Aircraft, EuroSAT, StanfordCars, Food101, Pets, Flower102, Caltech101, DTD, UCF101) and various model architectures (CLIP with different vision encoders and popular few-shot adaptation methods like CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad). The table highlights TransCLIP’s consistent ability to boost the performance of existing methods, demonstrating its effectiveness as a plug-and-play module.
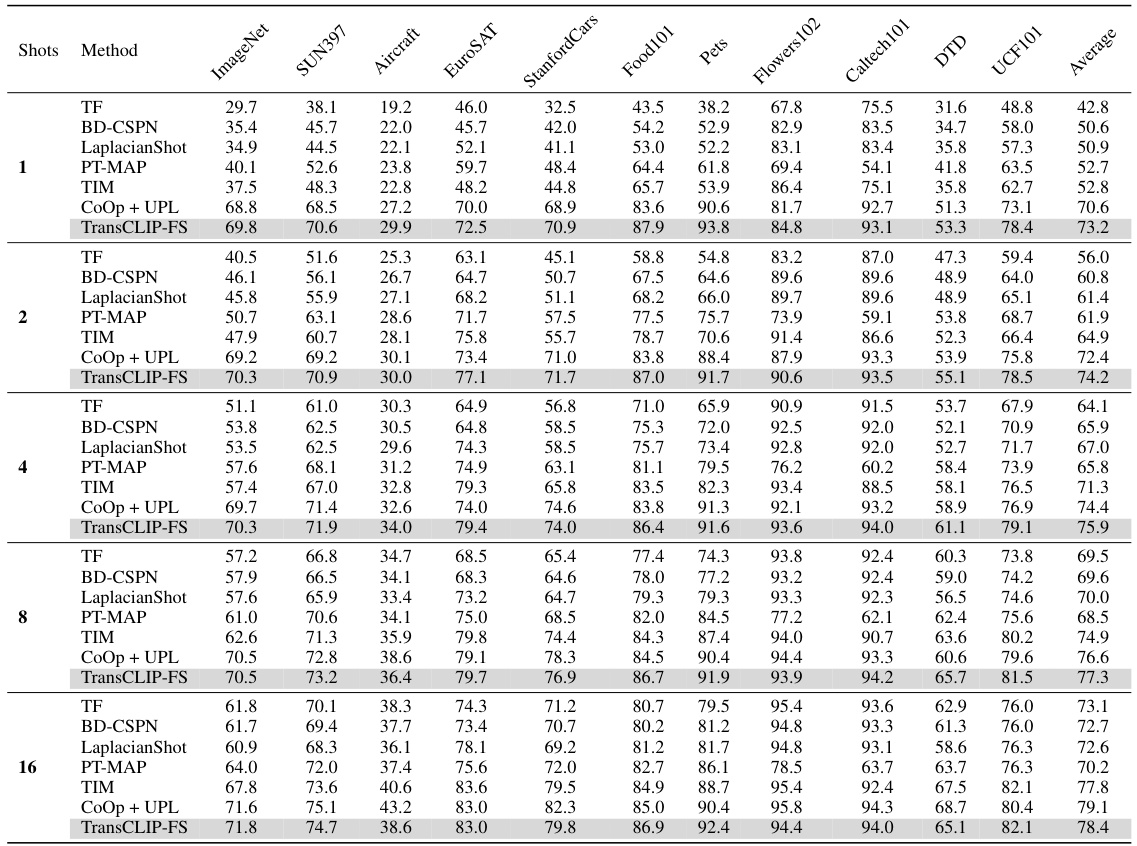
This table presents the results of applying TransCLIP to improve the performance of several inductive vision-language models on eleven datasets. The table compares zero-shot and few-shot methods (1-shot, 4-shot, and 16-shot) with and without TransCLIP. It demonstrates the consistent improvement in top-1 accuracy achieved by adding TransCLIP as a plug-and-play module on top of existing methods. The various vision encoder sizes used are also shown.

This table presents the results of TransCLIP applied on top of several inductive zero-shot and few-shot methods. It compares the Top-1 accuracy across 11 datasets (ImageNet, SUN397, Aircraft, EuroSAT, StanfordCars, Food101, Pets, Flower102, Caltech101, DTD, UCF101) for each method with and without TransCLIP. The methods considered include CLIP, COOP, TIP-Adapter-F, PLOT, and TaskRes. The results show how TransCLIP improves accuracy across these methods and different datasets.

This table shows the top-1 accuracy achieved by the unsupervised prompt learning method (UPL*) on the ImageNet dataset. The results are presented for different numbers of top-confidence pseudo-labels (8, 16, and 32) drawn from the test set. The table compares the performance of ResNet-50 and ViT-B/16 architectures. The purpose is to evaluate the effect of the number of pseudo-labels on the accuracy of the UPL* method.
This table presents the results of applying TransCLIP (a novel transductive approach) on top of several popular inductive vision-language models, including zero-shot and few-shot methods. It demonstrates the consistent improvement in top-1 accuracy achieved by TransCLIP across various models and shot settings, showcasing its effectiveness as a plug-and-play module for enhancing VLM performance. The table shows top-1 accuracy for each dataset on different learning settings (Zero-shot, 1-shot, 4-shot, 16-shot).

This table presents the results of TransCLIP when used on top of several inductive zero-shot and few-shot methods. It shows the top-1 accuracy achieved on 11 different datasets (ImageNet, SUN397, Aircraft, EuroSAT, StanfordCars, Food101, Pets, Flower102, Caltech101, DTD, UCF101) for each method, both with and without the addition of TransCLIP. The few-shot methods included are CoOp, TIP-Adapter-F, PLOT, TaskRes, and ProGrad, each tested with 0-shot, 1-shot, 4-shot, and 16-shot settings. The table demonstrates TransCLIP’s consistent improvement across different base methods and shot settings.
Full paper#