↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Many machine learning models struggle with noisy labels, especially when the noise is not consistent across all data points (instance-dependent). Existing methods often assume consistent noise or employ complex multi-stage processes, limiting their effectiveness. This significantly hinders the development of robust and accurate models.
This paper introduces COINNet, a new model that tackles instance-dependent noisy labels by using multiple annotators. It leverages “crowd wisdom” to identify and mitigate the effects of inconsistent noise, achieving superior accuracy. The model is theoretically grounded, providing identifiability guarantees under reasonable conditions, and features an end-to-end one-stage implementation, simplifying training and improving efficiency. Experiments using both synthetic and real datasets show substantial improvements over existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with noisy labels, a pervasive issue in machine learning. It offers a novel, theoretically-grounded approach to address the challenge of instance-dependent outliers, improving model accuracy and generalizability, especially in crowdsourced annotation scenarios. The results are important for both theoretical and practical applications, paving the way for more robust and reliable learning from noisy data.
Visual Insights#
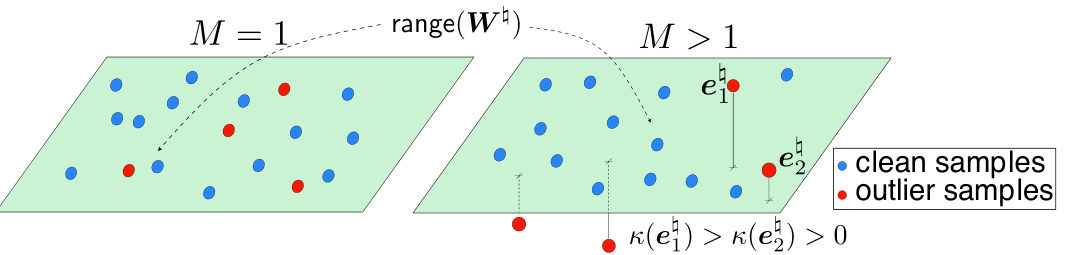
This figure illustrates the core idea of the paper, which is to utilize multiple annotators to distinguish outliers (instance-dependent noise) from normal data points by creating a low-dimensional subspace. When only one annotator is used (M=1), outliers are likely to reside in the subspace spanned by the nominal data, making it hard to identify them. However, when multiple annotators are employed (M>1), the probability of outliers residing outside of the subspace increases, thus making it easier to distinguish outliers from nominal data. The outlier impact score κ(e) is also introduced to quantify how far an outlier is from the subspace.
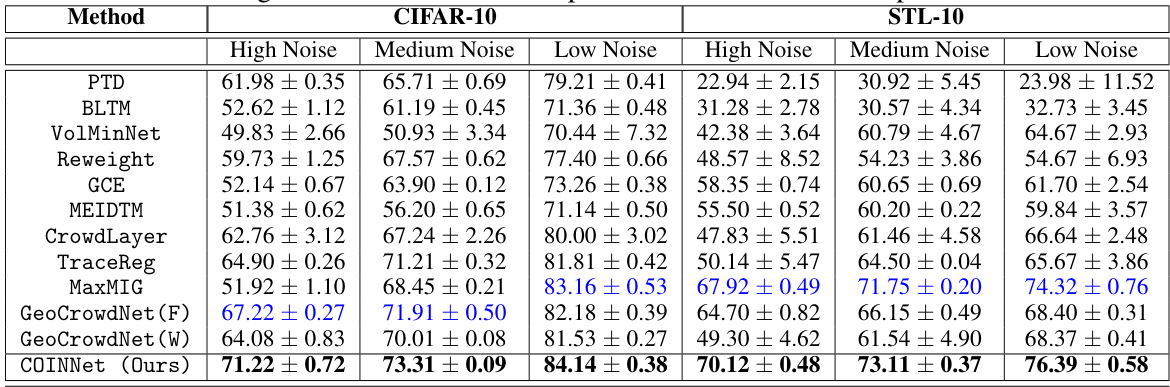
This table presents the average classification accuracy of different methods on CIFAR-10 and STL-10 datasets using machine-generated noisy labels. The results are compared across three noise levels (High, Medium, Low) and several different methods for handling noisy labels. The best-performing method for each scenario is highlighted in bold black, with the second-best highlighted in blue. The table allows for a comparison of the effectiveness of different techniques in handling various levels of label noise in image classification tasks.
In-depth insights#
Noisy Label Learning#
Noisy label learning tackles the challenge of training machine learning models on datasets containing inaccurate or unreliable labels. This is a pervasive problem, impacting model accuracy and generalization. The core issue lies in the discrepancy between the true labels and the observed, noisy ones. Approaches to address this involve robust loss functions, designed to be less sensitive to label errors; techniques for identifying and mitigating noisy labels, potentially through data cleaning or weighting schemes; and methods leveraging multiple annotators to improve data quality via consensus building. A key consideration is the type of noise, whether it’s class-dependent, instance-dependent, or follows other patterns, influencing the choice of mitigation strategy. Identifiability of the true underlying data distribution from the noisy observations is a crucial theoretical concern, with recent work focusing on proving identifiability under various assumptions about the noise model and using crowdsourcing for improved robustness.
Crowd Wisdom#
The concept of “Crowd Wisdom” in the context of noisy label learning is explored by leveraging multiple annotators to mitigate the impact of instance-dependent outliers. The core idea is that diverse annotations from a crowd can reveal patterns distinguishing reliable labels from outliers, even when individual annotators may have biases or limitations. The inherent redundancy and disagreements within the crowd’s labeling can point toward robust, consensus-based estimations of ground truth, improving overall classification performance and robustness. The method’s theoretical underpinnings demonstrate how crowdsourced annotations provide enough information to identify and separate nominal data from outliers, overcoming the limitations of single annotator approaches.
Outlier Detection#
The paper investigates identifiability in noisy label learning, particularly focusing on scenarios with instance-dependent outliers. A key challenge highlighted is the insufficiency of a single annotator for outlier detection; multiple annotators are crucial for effectively identifying the outliers and achieving model identifiability. The authors propose a crowdsourcing strategy that leverages the collective knowledge of multiple annotators to distinguish between nominal data and outliers within a low-dimensional subspace. This approach avoids the limitation of relying solely on sparsity priors, which are proven insufficient when using only one annotator. The proposed method uses a carefully designed loss function to facilitate outlier detection and classifier identification, ultimately enhancing the accuracy and robustness of noisy label learning in the presence of outliers.
Identifiability#
The concept of ‘identifiability’ in the context of noisy label learning is crucial for establishing the reliability and trustworthiness of the learned model. The paper explores the identifiability of a model where instance-dependent confusion matrices introduce outliers. A key finding is that using labels from a single annotator is insufficient to achieve identifiability; the presence of outliers hinders the recovery of the ground-truth classifier. However, the paper demonstrates that a crowdsourcing strategy, employing multiple annotators and a carefully designed loss function, can resolve the identifiability issue under certain reasonable conditions. This approach leverages the inherent properties of crowdsourced annotations to distinguish nominal data from outliers within a lower dimensional subspace, which is pivotal to achieving identifiability and proving generalization guarantees. The identifiability is further enhanced by incorporating column sparsity constraints in the proposed loss function, allowing the algorithm to effectively handle the instance-dependent outliers. This work significantly advances the theoretical understanding and practical applicability of noisy label learning in the presence of outliers.
COINNet#
COINNet, a novel approach to noisy label learning, tackles the challenge of instance-dependent outliers by leveraging crowd wisdom. Unlike previous methods that assume instance-invariant confusion matrices, COINNet explicitly models instance-dependent noise as outliers. The key innovation is a carefully designed loss function that utilizes multiple annotators’ labels, effectively distinguishing nominal data from outliers in a low-dimensional subspace. This one-stage approach, unlike multi-stage methods, avoids error accumulation and achieves better model identifiability. Theoretical guarantees are provided, showing its capacity for outlier detection and ground-truth classifier recovery. Experimental results demonstrate significant accuracy improvements across diverse datasets, outperforming previous state-of-the-art methods, particularly in high-noise scenarios. The end-to-end continuous optimization and the smoothed non-convex regularization make COINNet computationally efficient and practical.
More visual insights#
More on figures

This figure shows a histogram of outlier indicator values (sn) calculated for each training image in the CIFAR-10N dataset using the proposed COINNet method. The histogram helps to visualize the distribution of these values. The middle and right panels show example images with low and high sn values, respectively, illustrating the types of images that the model identifies as outliers or non-outliers. The images with high sn values tend to exhibit more instance-dependent confusion characteristics, such as background noise and blurring, than those with low sn values.

This figure shows some example images from the ImageNet-15N dataset that are classified by COINNet with low outlier scores (top row) and high outlier scores (bottom row). The images with lower scores are visually easier to recognize than those with higher scores. The images with high sn scores show more instance-dependent confusion characteristics (such as background noise and blurring) compared to those in the middle.
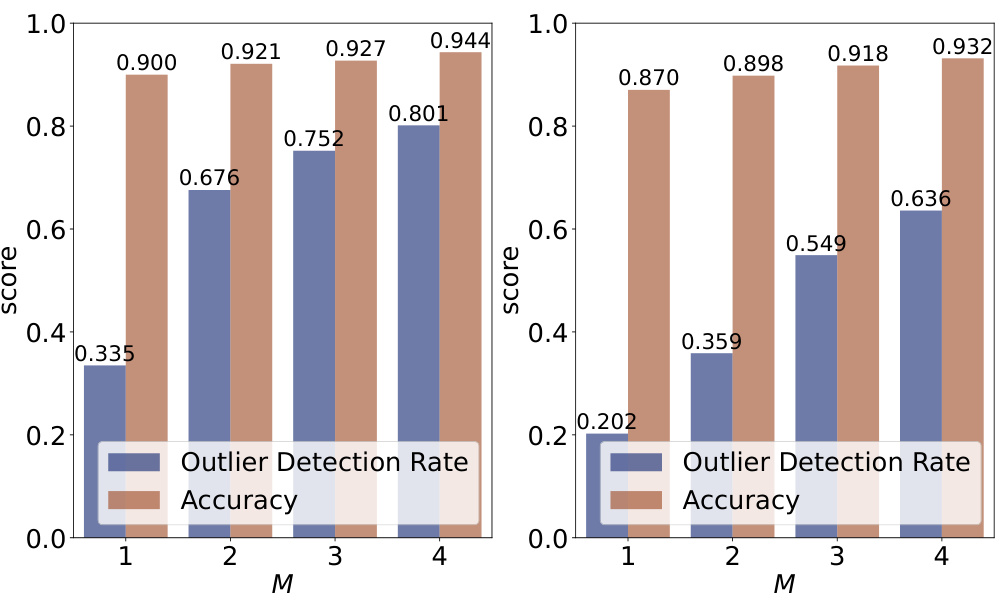
This figure shows the performance of the COINNet model on the CIFAR-10 dataset using synthetic labels with varying numbers of annotators (M). The left panel shows the results for a noise rate (τ) of 0.2 and a sparsity parameter (η) of 0.1, while the right panel presents the results for τ = 0.4 and η = 0.1. The graph plots both the outlier detection rate and the accuracy for each value of M. It illustrates how the model’s performance improves with more annotators, suggesting the benefit of crowdsourcing in dealing with noisy and outlier data.

This figure visualizes the distribution of outlier indicator scores (sn) calculated for each image in the CIFAR-10N dataset during training. The left panel shows a histogram of these scores, illustrating their distribution across the dataset. The middle and right panels display example images with low and high sn scores, respectively. Images with higher sn scores are more likely to exhibit the characteristics of outliers which implies instance-dependent confusion (e.g., noisy backgrounds, blurriness, etc.). Appendix H contains additional examples.

The figure shows a histogram of the outlier indicator values (sn) calculated for each image in the CIFAR-10N dataset during training. The outlier indicator, sn, is a measure of how much the instance-dependent confusion matrix deviates from the instance-independent confusion matrix for each data point. The histogram shows the distribution of sn values across all training images, indicating the proportion of data points that are considered outliers (high sn values). The middle and right sections of the figure display example images with low and high sn values, respectively, illustrating the visual characteristics of inliers and outliers. Further examples are available in the Appendix.
More on tables
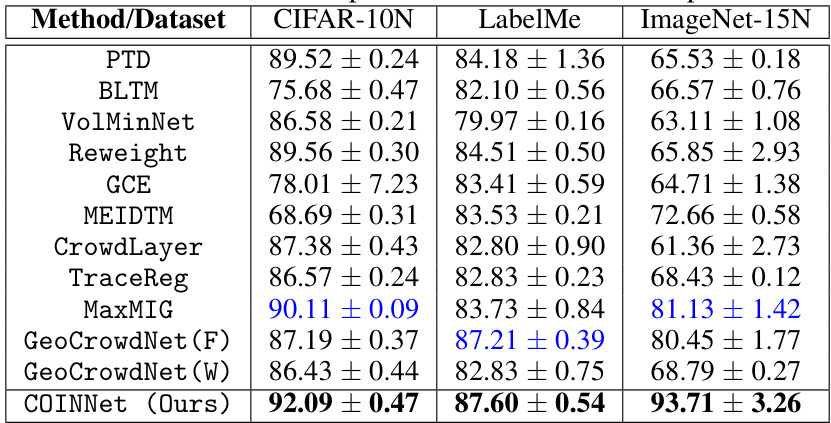
This table presents the average classification accuracy achieved by different methods on three real-world datasets (CIFAR-10N, LabelMe, and ImageNet-15N). The datasets were annotated by human annotators, introducing real-world noise. The table compares the performance of the proposed COINNet method against various baselines, including instance-dependent and instance-independent methods, and noise-robust loss function-based methods. The results show the superior performance of COINNet, highlighting its robustness to noisy labels from human annotators.
This table presents the average classification accuracy of different methods on CIFAR-10 and STL-10 datasets using machine annotations under different noise levels (high, medium, low). It compares the proposed COINNet method against several baselines, including existing crowdsourcing methods and instance-dependent noisy learning approaches. The results are presented for different noise levels to demonstrate the robustness of each method under varying amounts of label noise. Bold black font highlights the best performing method for each scenario, while blue indicates the second-best.
This table presents the average test accuracy of different noisy label learning methods on CIFAR-10 and STL-10 datasets using machine-generated noisy labels. The results are categorized by different noise levels (High, Medium, Low) and show the performance of the proposed COINNet method against several baselines. The best performing method for each scenario is highlighted in bold black, while the second-best is shown in blue. The table allows for a comparison of the proposed COINNet model against various existing noisy label learning techniques under different levels of label noise.
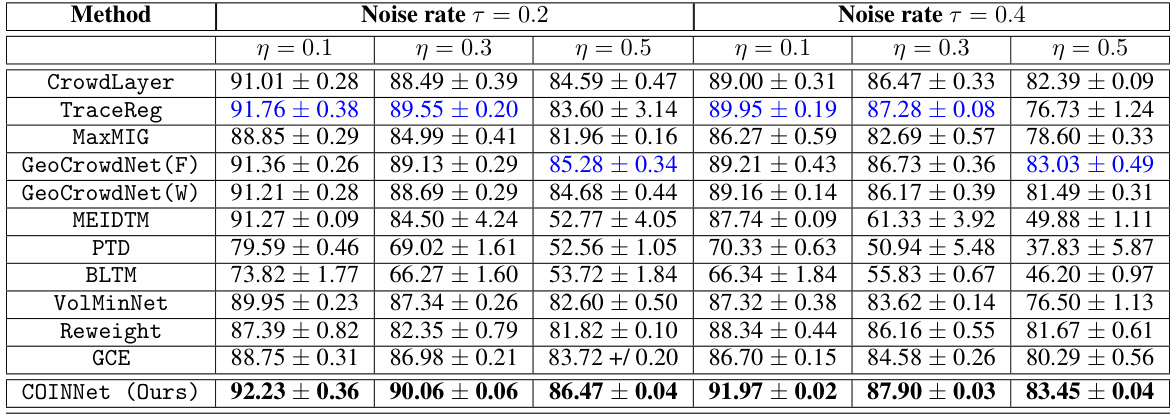
This table presents the average classification accuracy of different methods on CIFAR-10 and STL-10 datasets under three different noise levels (high, medium, low). The methods compared include several end-to-end crowdsourcing methods, instance-dependent noisy learning approaches, and noise-robust loss function-based approaches. The table highlights the superior performance of COINNet (the proposed method) across various scenarios. For the baselines trained using single annotators, majority voting was used to obtain the final labels.

This table presents the average classification accuracy achieved by the proposed COINNet model and several baseline methods on the CIFAR-10 and STL-10 datasets. The results are categorized by three different noise levels (High, Medium, Low) and show the performance of the COINNet model with various hyperparameter settings (µ1 and µ2). The table demonstrates the model’s performance across different noise conditions, highlighting its robustness and effectiveness in noisy settings.

This table presents the average classification accuracy achieved by different methods on the CIFAR-10 dataset using synthetic annotators. The results are averaged over three random trials. The table shows the performance of COINNet under different parameter settings (μ1 and μ2) and noise rates (τ = 0.2 and τ = 0.4) with different levels of instance-dependent noise (η).
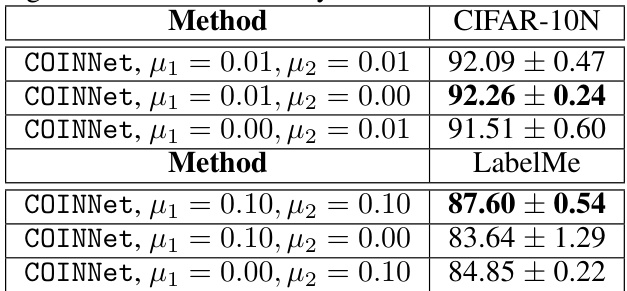
This table presents the average classification accuracy of the proposed COINNet model and several baseline methods on three real-world datasets: CIFAR-10N, LabelMe, and ImageNet-15N. The results are averaged over three random trials. Different hyperparameter settings (μ₁ and μ₂) for COINNet are explored, demonstrating the model’s robustness across various parameter configurations. The table highlights COINNet’s superior performance compared to other methods on these challenging real-world noisy label datasets.

This table presents the average classification accuracy of three different methods (MaxMIG, GeoCrowdNet (F), and COINNet) on the CIFAR-10 dataset under varying missing rates (0.1, 0.2, 0.3, 0.4, and 0.5). The experiment uses synthetic annotators with a fixed noise rate (τ = 0.2) and a proportion of outliers (η = 0.3). The results show COINNet’s superior performance across all missing rates, highlighting its robustness to missing data.

This table presents the average classification accuracy of three different methods (MaxMIG, GeoCrowdNet (F), and COINNet) on the CIFAR-10 dataset with varying missing rates (0.1 to 0.5). The experiment was conducted using synthetic annotators with a fixed noise rate (τ = 0.2) and outlier ratio (η = 0.5). The results are averages over three random trials.

This table shows the average classification accuracy on the CIFAR-10 dataset when each image is labeled by only one randomly selected synthetic annotator out of three. The results are displayed for two different noise levels (τ = 0.2, η = 0.3 and τ = 0.2, η = 0.5), and for three different methods: MaxMIG, GeoCrowdNet (F), and COINNet (Ours). The table demonstrates that COINNet outperforms the other two methods across both noise levels, indicating its robustness to noisy labels generated by a single annotator.

This table presents the average classification accuracy of different methods on three real-world datasets (CIFAR-10N, LabelMe, and ImageNet-15N) with human-provided noisy labels. The results are compared across multiple methods, including several baselines and the proposed COINNet approach. Bold black font indicates the best performing method for each dataset, while blue font indicates the second-best. The table showcases the performance of COINNet compared to other methods under real-world noisy annotation scenarios.

This table presents the average classification accuracy for three different initialization strategies for the confusion matrices (Am’s) in the COINNet model. The strategies are: initializing with an identity matrix, initializing using the GeoCrowdNet (F) after training 10 epochs and the setting used in the current experiments (close to an identity matrix). The results are for high, medium and low noise level scenarios from using machine annotations, averaged over three random trials.
Full paper#