↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Many real-world tasks, such as moving large furniture, necessitate cooperative human-object interaction (HOI). Existing solutions struggle due to the scarcity of multi-agent motion capture data and the challenges of training multi-agent systems. This often leads to inefficient training paradigms that are not easily generalized.
CooHOI is a novel two-phase learning approach. First, individual agents learn object manipulation skills via imitation learning. Then, multi-agent reinforcement learning is used, with object dynamics acting as implicit communication between agents during decentralized execution. This efficient approach significantly reduces the need for large motion capture datasets and improves scalability compared to prior methods. The results demonstrate CooHOI’s ability to successfully transport diverse objects using both single and multiple agents.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient framework for multi-agent cooperative object transportation, addressing the limitations of existing methods that rely on extensive motion capture data or struggle with the complexity of multi-agent learning. The framework’s inherent efficiency and adaptability open new avenues for research in multi-agent robotics, particularly in scenarios involving human-robot collaboration and complex object manipulation. This work will be highly relevant to researchers interested in multi-agent reinforcement learning, humanoid robotics, and human-robot interaction.
Visual Insights#

This figure illustrates the CooHOI framework, which enables physically simulated characters to perform multi-agent human-object interaction tasks. It showcases the natural and precise movements of the characters as they cooperate to carry various objects. The framework consists of three key components: individual skill learning, multi-agent transportation and cooperation, and interaction with diverse objects. The image depicts multiple agents working together to move different objects, emphasizing the framework’s ability to handle tasks requiring collaboration and diverse object types.

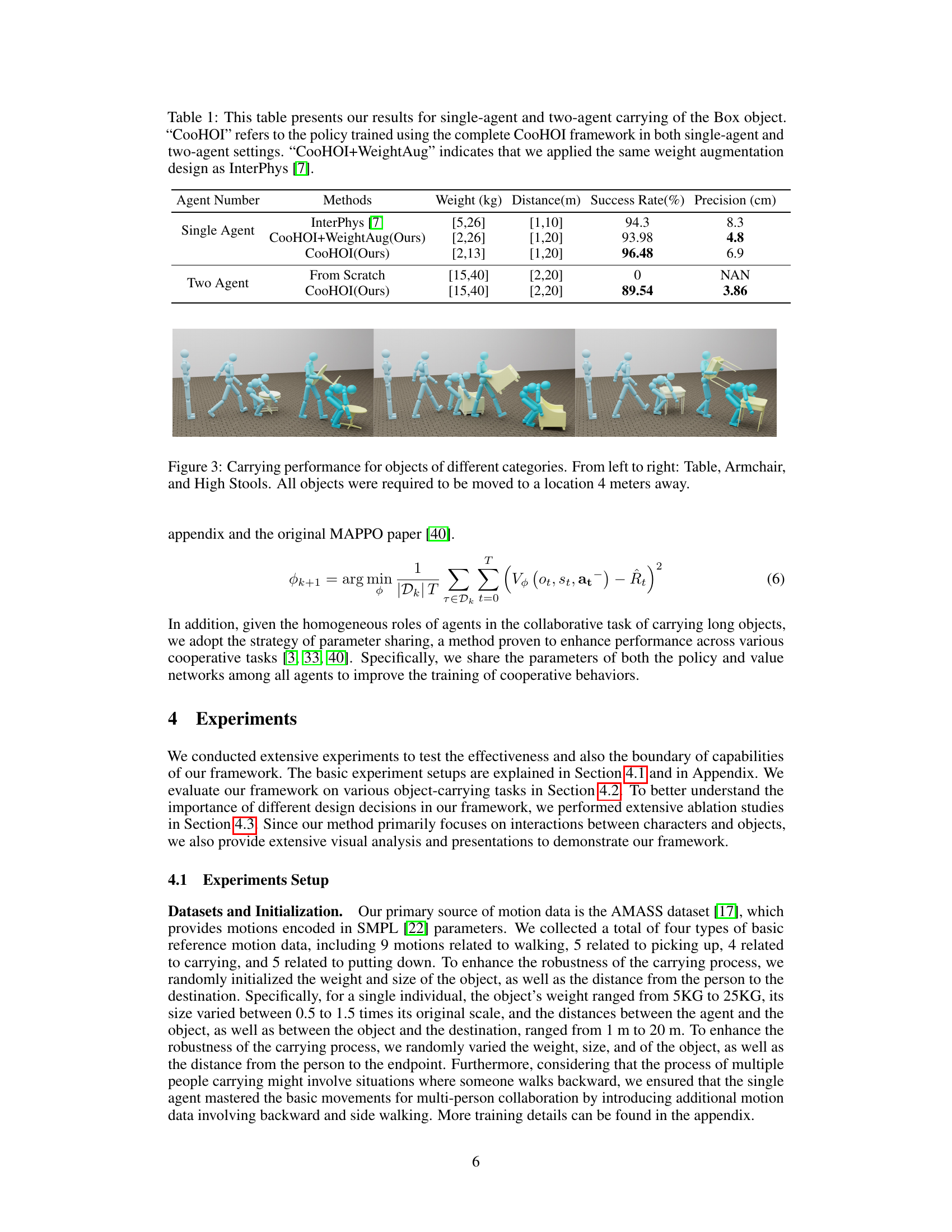
This table presents quantitative results of single-agent and two-agent box-carrying experiments. It compares the performance of the proposed CooHOI method against the baseline InterPhys method, both with and without weight augmentation. The metrics reported include success rate and precision (how closely the final object position matches the target).
In-depth insights#
CooHOI Framework#
The CooHOI framework, designed for multi-humanoid object transportation, cleverly tackles the challenges of multi-agent learning and data scarcity. Its two-phase approach is notable: individual skill learning through imitation, followed by policy transfer for collaboration. The framework leverages centralized training with decentralized execution (CTDE) for efficient multi-agent reinforcement learning. Object dynamics act as implicit communication, enabling agents to coordinate effectively without explicit messaging. This approach is a significant step forward, circumventing the need for expensive and limited multi-humanoid motion capture data. The inherent efficiency and scalability of CooHOI make it highly promising for applications in collaborative robotics, particularly for complex tasks requiring teamwork and adaptation to diverse scenarios.
Two-Stage Learning#
A two-stage learning approach in a research paper often signifies a hierarchical or sequential learning process designed to address complex tasks efficiently. The first stage typically focuses on learning fundamental skills or simpler sub-tasks in isolation. This might involve supervised learning from existing data or reinforcement learning in a simplified environment. The second stage builds upon the knowledge acquired in the first stage to tackle the complete, more complex task. This could involve transferring learned skills to a more challenging scenario or integrating individual skills into a collaborative framework for multi-agent learning. Key advantages of this approach include the efficient use of computational resources and the potential to leverage pre-trained models, reducing the training time significantly. However, careful design and considerations are necessary to ensure smooth transition and effective integration between stages. The success of a two-stage learning paradigm hinges on the proper selection of sub-tasks and the effectiveness of knowledge transfer mechanisms. A poorly designed two-stage system might fail to properly combine learned skills and instead produce suboptimal overall performance.
Object Dynamics#
The concept of ‘Object Dynamics’ in robotics research is crucial for achieving natural and efficient human-robot collaboration. Understanding how objects behave under manipulation is essential for robots to predict their movement and adjust their actions accordingly. This involves considering factors such as mass, shape, friction, and external forces. The paper likely investigates how these factors influence the object’s trajectory and stability, potentially using physics engines to simulate realistic object interactions. A key aspect would be the integration of object dynamics into the robot’s control system. This may involve using the object’s dynamic state as part of the robot’s sensory input, informing its actions in real-time. Another important consideration is implicit communication. The paper might explore how changes in object dynamics caused by one robot can convey information to other robots, facilitating collaborative manipulation tasks. Centralized training and decentralized execution (CTDE) could be a method explored to efficiently learn cooperative policies by training a centralized model and then deploying decentralized agents.
Multi-Agent RL#
Multi-agent reinforcement learning (MARL) is a complex field dealing with the challenges of coordinating multiple agents in an environment to achieve a shared goal. Key difficulties arise from the partial observability of the environment, where each agent might only have limited information, and the non-stationarity of the environment, as the actions of one agent change the environment faced by others. MARL algorithms must address these challenges effectively to achieve efficient and cooperative behavior. Common approaches include centralized training with decentralized execution (CTDE), where agents train in a centralized manner using global information but act independently during execution, and fully decentralized methods where each agent independently learns its own policy. The choice of algorithm often depends on the specific application and the nature of the interactions between agents, ranging from fully cooperative to competitive settings. Effective communication between agents is crucial in many scenarios, and can be achieved either explicitly using message passing or implicitly through observation of other agents’ actions and the resulting changes in the environment. Developing efficient MARL algorithms for large-scale systems remains an active research area.
Future Works#
Future work could explore several promising avenues. Extending CooHOI to handle more complex object manipulations such as those involving delicate or flexible objects is crucial for broader applicability. This would require incorporating more sophisticated physics models and potentially advanced control techniques. Improving the robustness of the framework to noisy or incomplete observations is also important for real-world deployment. This might involve integrating advanced sensor processing techniques or developing more robust methods for handling uncertainty. Investigating the scalability of CooHOI to larger numbers of agents and more diverse environments is also a key area for future research, as this would allow for tackling even more challenging multi-agent object manipulation tasks. Finally, exploring methods for more explicit communication and coordination between agents could further enhance the efficiency and reliability of the collaborative process. This could involve designing more sophisticated reward functions or exploring alternative communication strategies beyond implicit reliance on object dynamics.
More visual insights#
More on figures
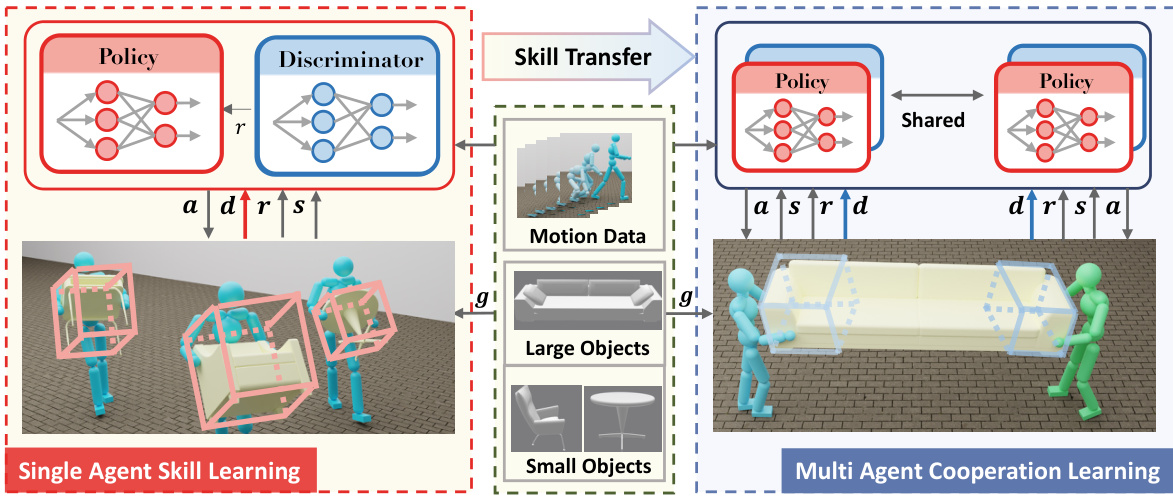
This figure illustrates the CooHOI framework’s two-phase learning process. The first phase focuses on single-agent skill learning using imitation learning from human motion data. This phase trains a policy for a single agent to carry objects naturally, incorporating object dynamics into the observation to understand how their actions affect the object’s movement. The second phase shifts to multi-agent cooperation learning. It shows how the learned single-agent skills are transferred to a collaborative context. The key here is the use of object dynamics as implicit communication, allowing agents to coordinate their actions by observing changes in the object’s motion caused by their teammate’s actions.

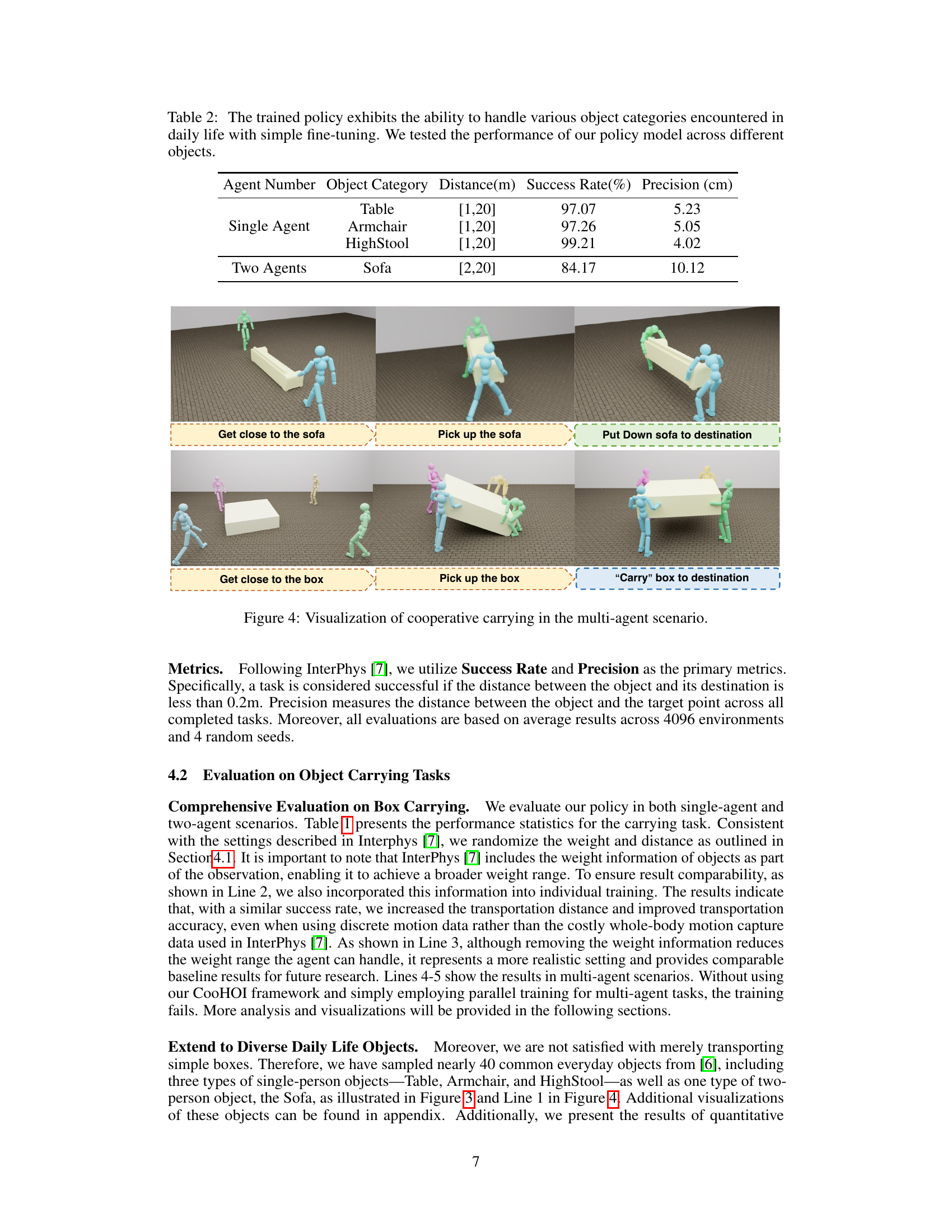
This figure visualizes the steps involved in a cooperative object carrying task using multiple agents. It shows the process from approaching the object, lifting it collaboratively, carrying it to the destination, and finally setting it down. The images highlight the coordination and cooperation between the agents to successfully transport a relatively large object.
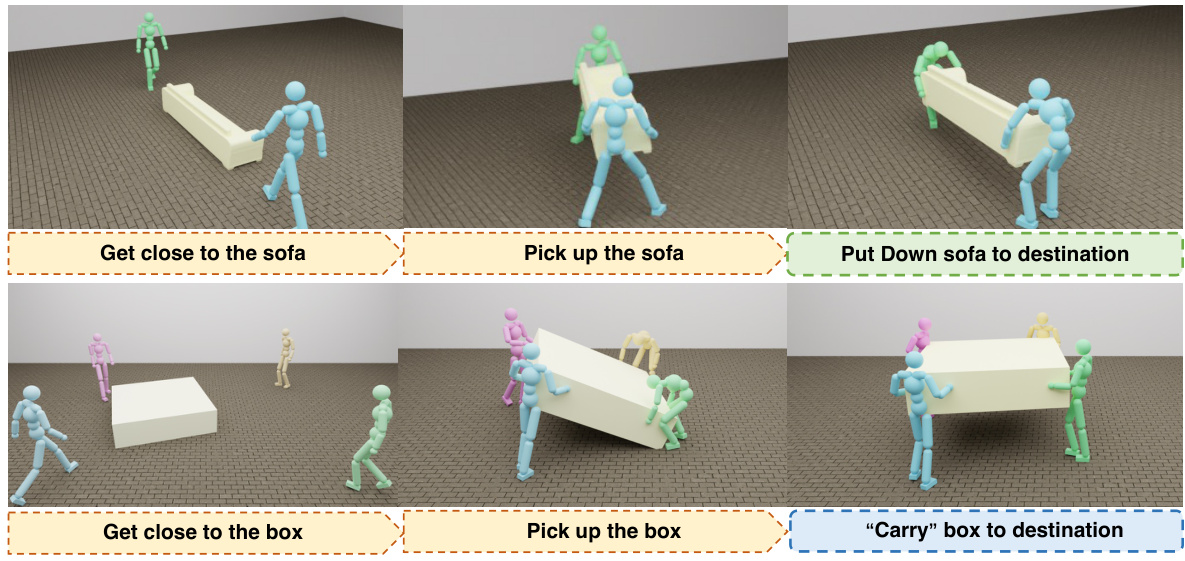
This figure shows a visualization of the cooperative object carrying task performed by multiple agents in two different scenarios: carrying a sofa and carrying a box. The images depict the stages involved in the task, starting from the agents approaching the object, to lifting and carrying it collaboratively to the destination. The visualization clearly shows the coordination between agents involved in the task.
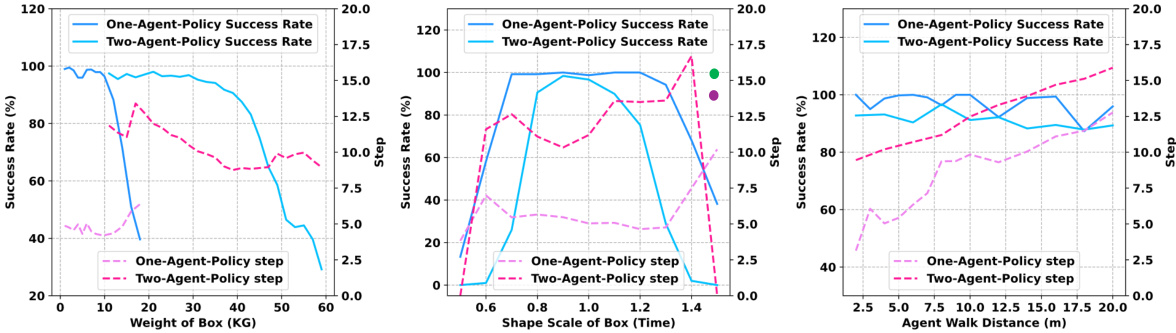
This figure presents ablation study results for single-agent and two-agent box-carrying tasks. Three graphs show the impact of object weight, shape scale, and agent walking distance on both success rate and the average number of steps to complete the task. The results highlight the trade-offs in performance related to the varied factors. The second graph also shows the impact of scaling the object’s width, showcasing the effectiveness of the proposed approach when maintaining aspect ratio.
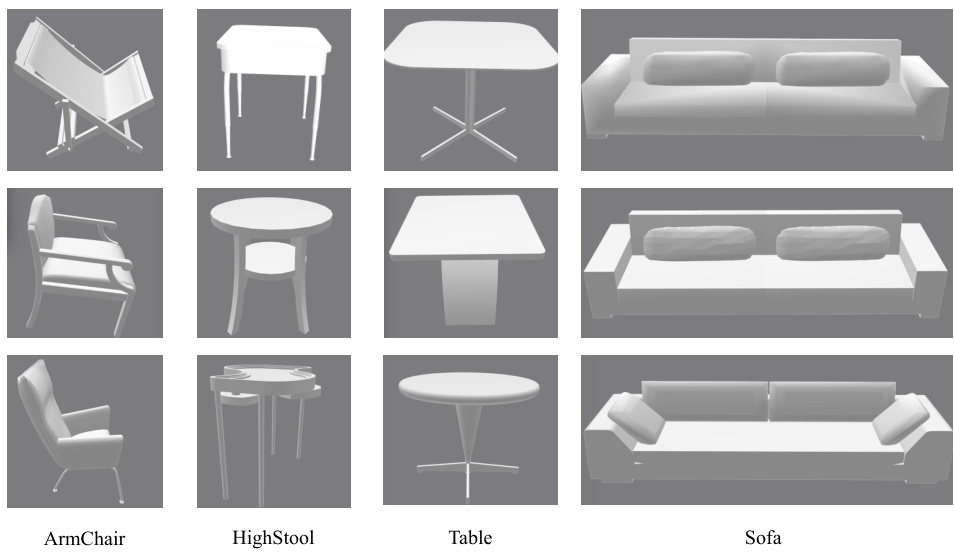
This figure shows different views of four object categories used in the experiments: Armchair, High Stool, Table, and Sofa. Each object category has three different instances, giving a total of twelve different object visualizations.
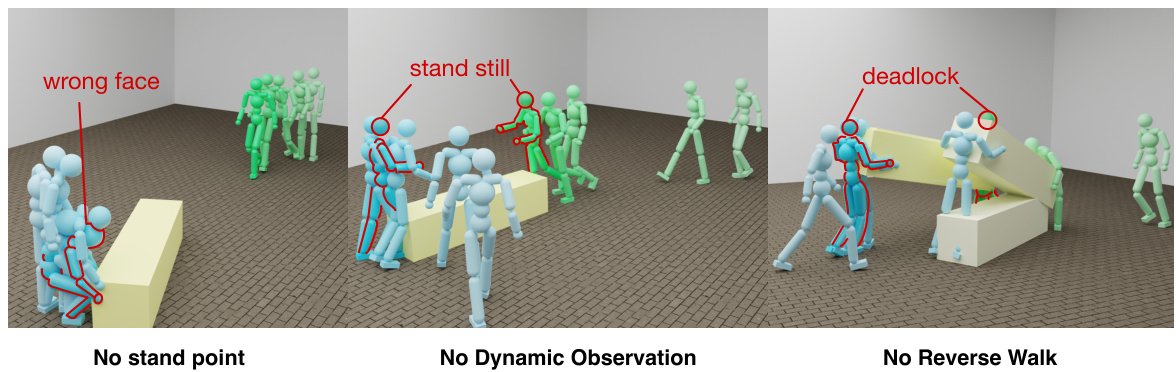
This figure shows three failure cases of the two-agent cooperative object transport task. The leftmost image shows the failure case when the stand point is not provided, where the agent goes to the wrong side of the box and fails to carry it. The middle image shows the failure case when the dynamics information is not used for observation, in which the agent cannot move. The rightmost image shows the failure case when the backward motion is not learned by the single agent, where the two agents cannot carry the object together.
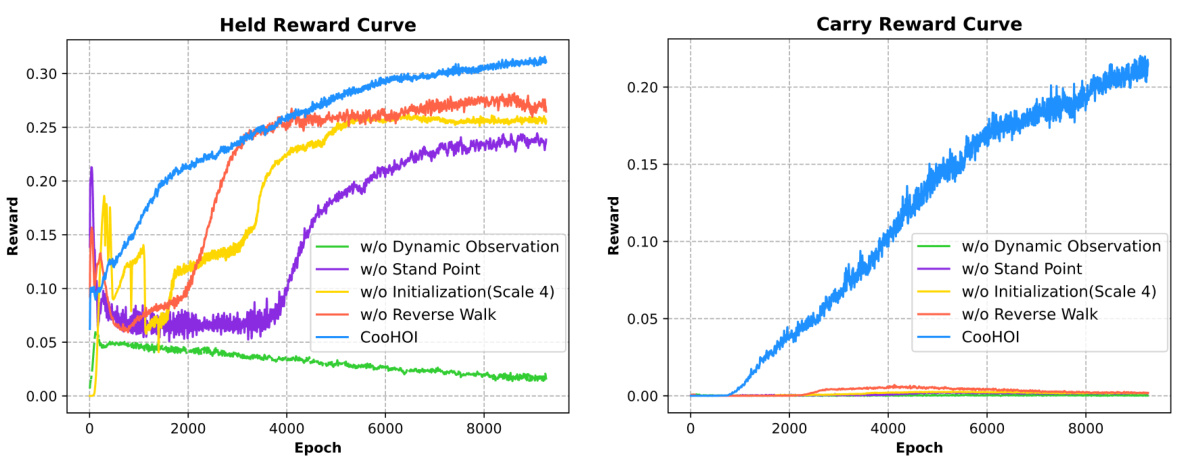
This figure shows the training curves for both ‘carry reward’ and ‘held reward’ during the two-agent training phase of the CooHOI framework. It compares the performance of the complete CooHOI model to several ablation studies where key components (dynamic observation, stand point, initialization method, and reverse walk) are removed. The results demonstrate the impact of these components on the learning process and the overall success of cooperative object carrying.
More on tables
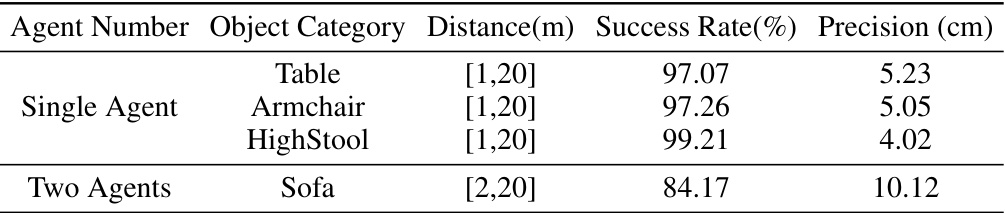
This table presents the success rate and precision of the trained policy model on different object categories (Table, Armchair, HighStool, and Sofa) for both single-agent and two-agent carrying tasks. The distance to the destination is also specified for each scenario. The results demonstrate the generalizability of the model across various object types and agent numbers.
This table compares the performance of different methods for single-agent and two-agent object carrying tasks. The methods include InterPhys [7], CooHOI with and without weight augmentation, and a baseline model trained from scratch. Results are evaluated using weight of objects, distance to destination, success rate, and precision. The table demonstrates that the CooHOI framework achieves high success rates and precision, especially when weight augmentation is used, outperforming the baseline and demonstrating adaptability to multi-agent scenarios.
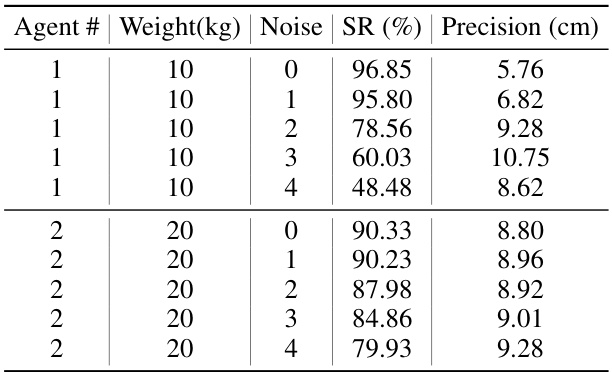
This table presents the quantitative results of single-agent and two-agent box-carrying experiments. It compares the performance of the proposed CooHOI method against the baseline InterPhys method, showing success rates and precision (distance error) under varying conditions (weight and distance to target). The table also includes results using a modified CooHOI method with weight augmentation.
Full paper#