↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Recommending new or uncommon items (out-of-vocabulary, or OOV items) is a major challenge in recommender systems. Existing methods often create ‘makeshift’ embeddings for OOV items based solely on content, which leads to suboptimal recommendations due to a gap between content and user behavior. This paper addresses this problem by proposing a novel User Sequence Imagination (USIM) framework.
USIM uses reinforcement learning to ‘imagine’ user sequences that might interact with OOV items. This imagined user behavior helps refine the OOV item embeddings via backpropagation, bridging the gap between content and user behavior. The framework includes a recommendation-focused reward function to guide the learning process. The results demonstrate USIM’s superior performance over existing methods in both simulated and real-world e-commerce settings, showcasing its potential for significantly improving the recommendation of novel items.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on recommender systems, particularly those focused on handling out-of-vocabulary (OOV) items. It introduces a novel framework that significantly improves the recommendation of new or uncommon items, a persistent challenge in the field. The RL-based approach and real-world deployment results offer valuable insights and inspire new research directions, impacting both academic understanding and industrial applications. Its success in a large-scale e-commerce setting provides compelling evidence of its potential for widespread use.
Visual Insights#

The figure compares two different approaches for out-of-vocabulary (OOV) item recommendation. (a) shows the traditional ‘makeshift’ embedding method, which generates embeddings for OOV items using only content features, without considering user behavior. This method is shown to have limitations. (b) presents the proposed User Sequence Imagination (USIM) framework, which first imagines user sequences and then uses these imagined sequences to refine the generated OOV embeddings through backpropagation. The USIM method aims to bridge the gap between content features and behavioral embeddings for improved recommendation performance. The figure illustrates the key difference between these methods, highlighting USIM’s ability to better utilize user interaction data for more effective OOV recommendations.

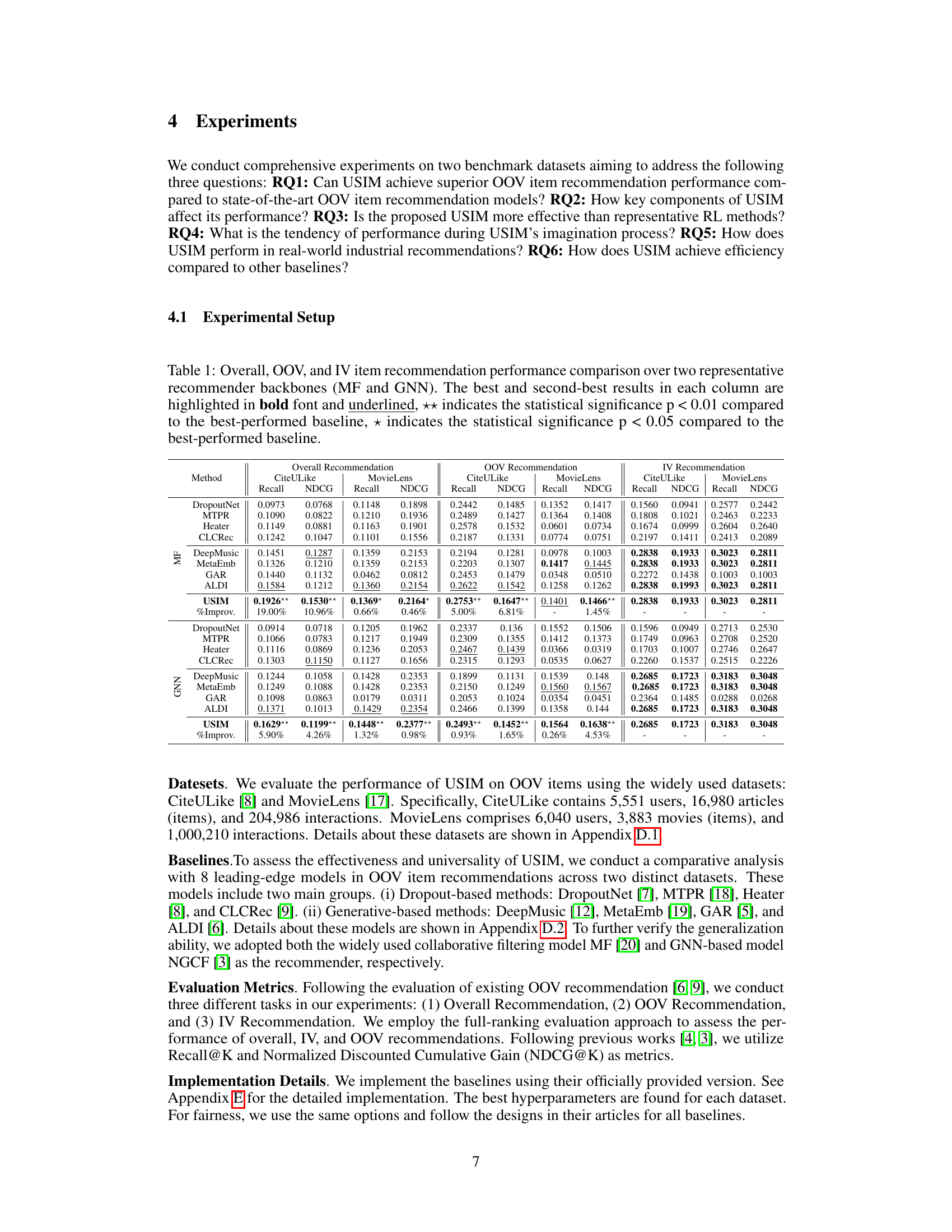
This table presents a comprehensive comparison of the overall, out-of-vocabulary (OOV), and in-vocabulary (IV) item recommendation performance of USIM against several baseline methods. The comparison is done across two different recommender backbones: Matrix Factorization (MF) and Graph Neural Network (GNN). The table highlights the statistical significance of USIM’s performance improvements compared to the best-performing baselines using * and ** notations.
In-depth insights#
OOV Rec. Methods#
Out-of-Vocabulary (OOV) item recommendation methods tackle the challenge of suggesting items lacking historical interaction data. Traditional approaches often create ‘makeshift’ embeddings for OOV items using content features, attempting to bridge the gap between content and behavior. However, this often leads to suboptimal performance. More advanced techniques, such as generative models and dropout methods, aim to generate more realistic embeddings or enhance system robustness. Generative models synthesize embeddings based on content, while dropout-based methods improve robustness by randomly replacing in-vocabulary embeddings with those of OOV items during training. A key limitation is the substantial gap between content and behavior representation, impacting the accuracy of recommendation. The methods’ effectiveness hinges on the quality of generated embeddings and their ability to capture user behavior effectively. Future research should explore refined embedding generation techniques and focus on better integrating content and behavior information to improve OOV recommendation accuracy and user experience.
USIM Framework#
The USIM framework, a novel approach for fine-tuning out-of-vocabulary (OOV) item recommendations, cleverly tackles the challenge of recommending items lacking historical interaction data. Its core innovation lies in imagining user sequences to bridge the gap between content-based OOV item embeddings and behavioral IV item embeddings. By framing this sequence imagination as a reinforcement learning (RL) problem and utilizing a reward function focused on recommendation performance, USIM iteratively refines OOV item embeddings through backpropagation. A key strength is its ability to leverage existing user-item interaction data to guide the refinement process, ensuring the generated OOV embeddings align well with the learned behavioral space. Furthermore, the framework’s incorporation of an exploration set construction methodology and the use of RecPPO optimization further enhances efficiency and exploration. The results obtained demonstrate that USIM significantly outperforms traditional ‘makeshift’ embedding methods, showcasing the potential of imaginative RL-based methods for handling the OOV problem in recommender systems. The RL approach allows for a data-efficient and adaptive process, potentially overcoming limitations of purely generative approaches. However, further investigation into the scalability and generalizability across diverse recommendation domains is necessary for full validation.
RL-Based Tuning#
RL-based tuning, in the context of recommendation systems, represents a powerful paradigm shift. Instead of relying solely on traditional optimization methods like gradient descent, which often struggle with complex, high-dimensional spaces, RL introduces an agent-based approach. This agent interacts with the environment (the recommendation system) by taking actions (e.g., adjusting model parameters, selecting items). The agent receives rewards or penalties based on the system’s performance after each action. This feedback loop allows the agent to learn an optimal policy for tuning the system, effectively navigating the vast and intricate space of possible configurations. The key advantage lies in the ability to learn complex relationships and non-linear interactions that might be missed by simpler gradient-based techniques. This makes RL particularly well-suited for challenges such as cold-start recommendations, where limited data makes traditional methods unreliable, or for situations involving dynamic user behavior and contextual information, which RL can efficiently incorporate. However, RL-based approaches also introduce complexities, including the design of the reward function, the choice of RL algorithm, and the computational cost of training. The choice of reward function is crucial, as a poorly designed reward could lead to suboptimal or even detrimental learning. Selecting an appropriate RL algorithm necessitates careful consideration of the problem’s specifics and computational resources. Consequently, a comprehensive analysis of various algorithms, a well-defined reward signal, and effective exploration strategies are paramount to successful implementation.
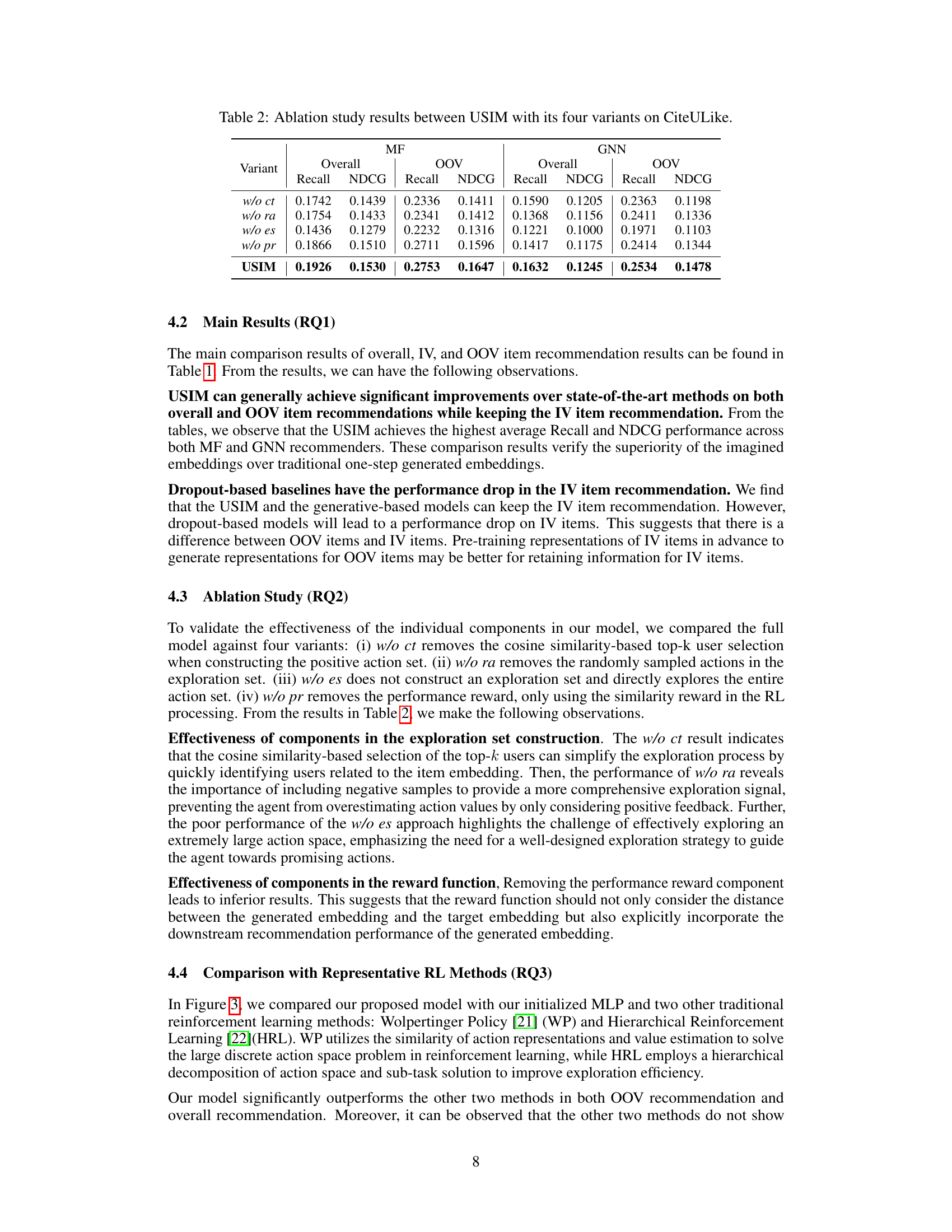
Ablation Study#
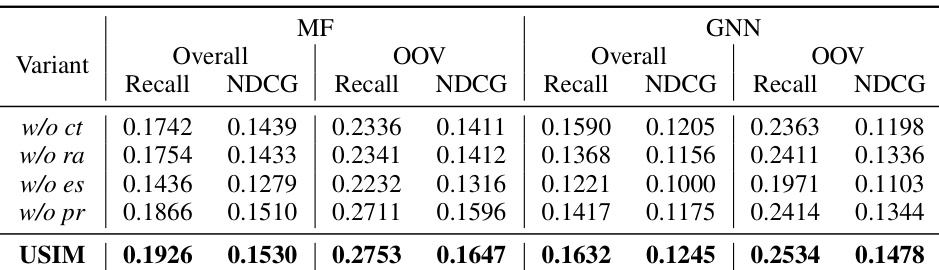
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a recommendation system, this might involve removing parts of the User Sequence Imagination (USIM) framework, such as the exploration set construction, reward function, or specific components of the RL pipeline. By observing the impact of each removal on the system’s overall and OOV (out-of-vocabulary) item recommendation performance, one can quantify the importance of each module. A well-designed ablation study isolates the effects of individual components, ruling out confounding factors and providing strong evidence for the effectiveness of USIM’s design choices. The results would ideally demonstrate that each component contributes positively to the final performance, with the complete system outperforming any ablated version. Careful selection of ablation targets is critical. Removing key components in a piecemeal manner can reveal the relative importance of different parts of the model architecture. This nuanced analysis helps build a robust understanding of why the method works well and pinpoint areas for future improvements or optimization.
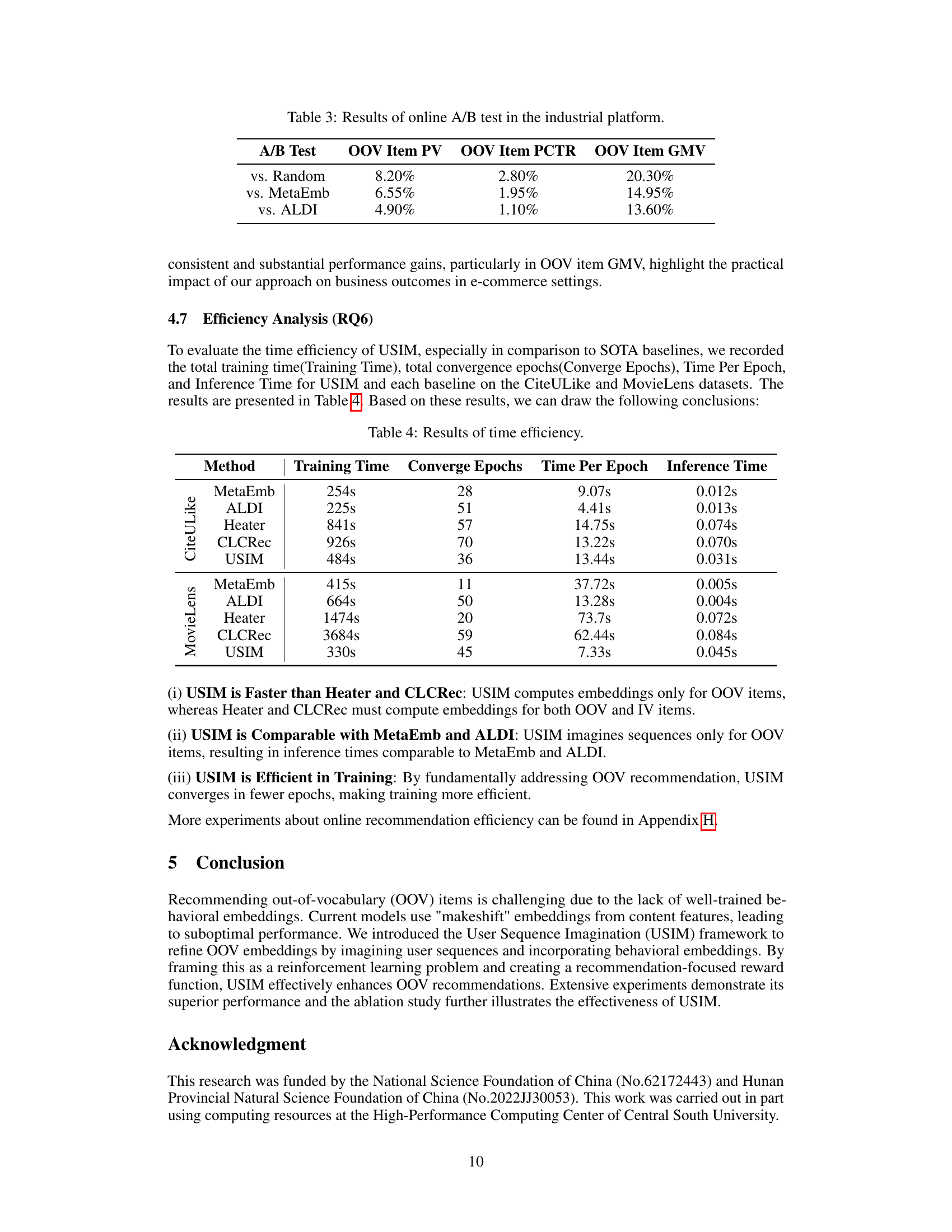
Real-World Impact#
The research paper presents a novel approach to the challenging problem of out-of-vocabulary (OOV) item recommendation. The model, User Sequence Imagination (USIM), demonstrates significant real-world impact by enhancing recommendation quality and efficiency for millions of OOV items on a large e-commerce platform. USIM’s deployment showcases its scalability and robustness in handling real-world data with billions of user-item interactions. By optimizing OOV item embeddings through imagined user sequences and a reinforcement learning framework, the approach achieves substantial improvements in overall recommendation performance, not just for OOV items but for in-vocabulary items as well. The practical effectiveness of USIM is validated through online A/B testing, highlighting significant gains in key metrics like page views, click-through rates, and gross merchandise value. This underscores USIM’s ability to translate theoretical advancements into tangible business benefits. Its unique approach of generating realistic OOV item embeddings through the imagination of user sequences addresses a limitation of existing methods, paving the way for better handling of the ever-increasing amount of newly-generated content. The detailed experimental analysis and discussion of both advantages and limitations contribute to a more comprehensive understanding of the proposed technique and its broader impact on recommender systems.
More visual insights#
More on figures
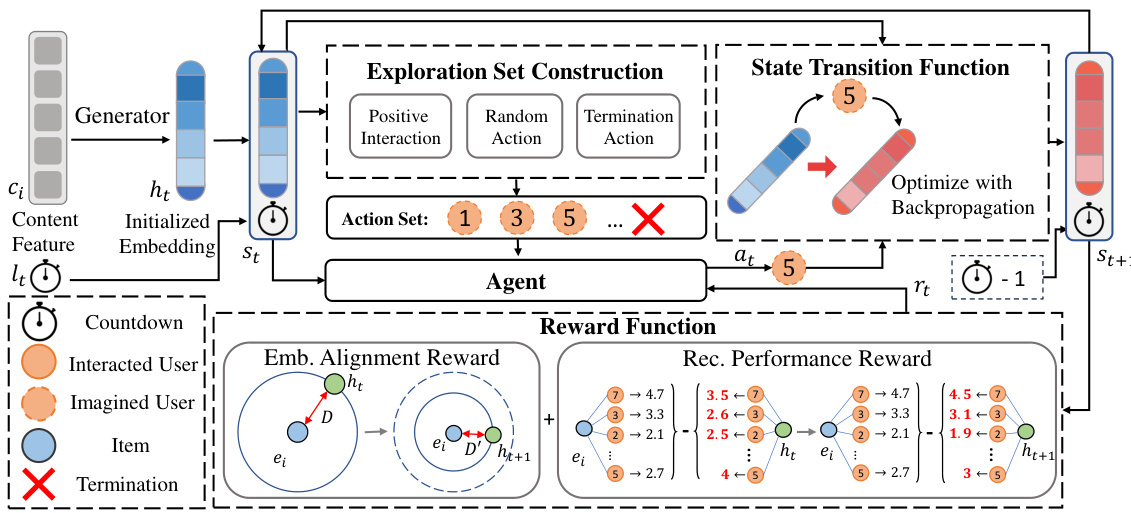
The figure illustrates the USIM framework, showing how it fine-tunes generated OOV item embeddings through sequential user interaction imagination. The process is guided by three key components: exploration set construction (selecting users for interaction simulation), state transition (updating the item embedding based on imagined user interactions), and a reward function (guiding the optimization process using embedding alignment and recommendation performance rewards). The diagram visually represents the interactions between these components, using different shapes and colors to represent users, items, embeddings, and actions.

This figure compares the performance of USIM against three other reinforcement learning methods (MLP, WP, and HRL) for both overall and OOV recommendation tasks using the CiteULike dataset. It visually demonstrates the superiority of USIM in terms of NDCG@K scores, showcasing its effectiveness in improving recommendation quality, especially for OOV items.

This figure analyzes the performance of three different user selection methods for the USIM model on the CiteULike dataset. The three methods are: (1) selecting users with highest cosine similarity to the current state, (2) randomly selecting from the top 20 most relevant users, and (3) completely random user selection. The graphs show NDCG scores for OOV and overall recommendation performance across different steps of the optimization process (x-axis represents the step, and y-axis represents the NDCG score). This visualization helps in understanding how different user selection methods affect the efficacy of the embedding optimization process within the USIM framework.

This figure presents a hyperparameter analysis for the matrix factorization (MF) backbone on the CiteULike dataset. It shows the impact of four key hyperparameters (k, N, p, λ) on both overall and out-of-vocabulary (OOV) recommendation performance as measured by NDCG. Each subplot displays the NDCG scores for varying values of a single hyperparameter, holding others constant. The analysis helps to determine the optimal settings for these hyperparameters, balancing overall recommendation quality with the specific needs of OOV item recommendations.

This figure shows the result of hyperparameter analysis on the GNN backbone using the CiteULike dataset. It presents the impact of four hyperparameters (k, N, p, λ) on both overall and OOV recommendation performance, as measured by NDCG. Each subplot displays the NDCG scores for varying values of a single hyperparameter, while holding others constant. The plots illustrate how these hyperparameters influence the model’s ability to recommend both in-vocabulary and out-of-vocabulary items.
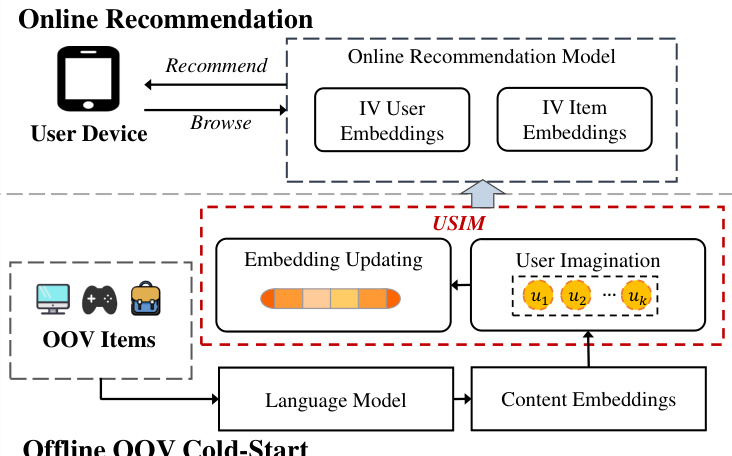
This figure illustrates the online implementation of the USIM framework. When a new out-of-vocabulary (OOV) item is uploaded, its content features (name, description etc.) are embedded by a Language Model. The USIM module then imagines a user sequence and refines the OOV item’s embedding. Finally, the refined embeddings are integrated into the Online Recommendation Model to recommend the OOV item to users, alongside existing in-vocabulary (IV) items. The process highlights the interplay between offline pre-processing (embedding updating via USIM) and online real-time recommendations.
More on tables
This table presents a comparison of the overall, out-of-vocabulary (OOV), and in-vocabulary (IV) item recommendation performance of the proposed USIM model against several baseline models. The comparison is done across two different recommender backbones: Matrix Factorization (MF) and Graph Neural Network (GNN). The table shows Recall@K and NDCG@K metrics for each model and category (overall, OOV, IV), highlighting statistically significant improvements achieved by USIM.

This table presents a comparison of the overall, out-of-vocabulary (OOV), and in-vocabulary (IV) item recommendation performance of the proposed USIM model against several baselines. The comparison is done using two different recommender backbones: Matrix Factorization (MF) and Graph Neural Network (GNN). The results are shown in terms of Recall@K and NDCG@K metrics, and statistical significance is indicated using asterisks.
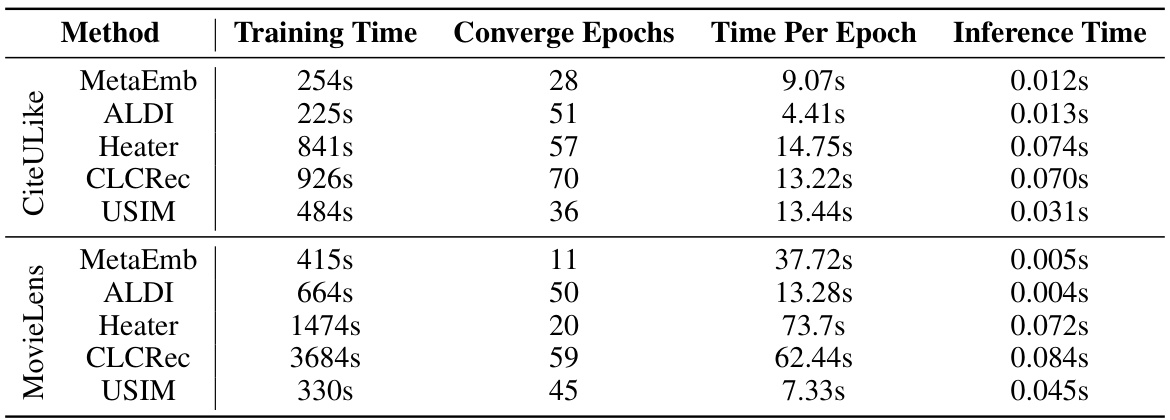
This table presents a comprehensive comparison of the overall, out-of-vocabulary (OOV), and in-vocabulary (IV) item recommendation performance of the proposed USIM model against various baselines. The comparison is conducted using two different recommendation backbones: Matrix Factorization (MF) and Graph Neural Network Collaborative Filtering (GNN). The table highlights the best-performing models for each metric (Recall@K and NDCG@K) and indicates statistical significance using asterisks.

This table presents a comparison of the overall, out-of-vocabulary (OOV), and in-vocabulary (IV) item recommendation performance of the proposed USIM model and several baseline methods. The comparison is done using two different recommender backbones: Matrix Factorization (MF) and Graph Neural Network (GNN). The table shows Recall@K and NDCG@K metrics for each method and dataset, highlighting statistically significant improvements of USIM over the baselines.
Full paper#