↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current few-shot semantic segmentation methods struggle with prompt selection, hyperparameter tuning, and efficiency due to overuse of SAM. This leads to low automation and limited generalization. The problem is further compounded by the challenges in aligning the granularity of points and masks generated by SAM.
GF-SAM addresses these issues with a novel graph-based approach. It dynamically selects points using a Positive-Negative Alignment module, clusters masks based on coverage, and employs positive and overshooting gating to filter out false positives. This parameter-free approach significantly improves efficiency and accuracy, surpassing state-of-the-art models across various benchmarks and demonstrating strong generalization capabilities.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach to few-shot semantic segmentation, a crucial task in computer vision. The graph-based method improves efficiency and accuracy over existing methods, making it highly relevant to researchers working on real-time applications and limited-data scenarios. The parameter-free design also makes it easily adaptable to different tasks and domains, which is critical in the rapidly evolving field of foundation models. Finally, this work opens up new avenues for research, by exploring the relationship between point prompts and masks in SAM-based few-shot semantic segmentation, as well as integrating graph analysis techniques into computer vision tasks. This potentially advances our understanding of the alignment between fine-grained and coarse-grained features, offering a significant impact on future research.
Visual Insights#

This figure presents a comparison of the proposed method’s performance against other state-of-the-art methods in few-shot semantic segmentation. Subfigure (a) shows a performance-efficiency comparison, highlighting the superior performance and efficiency of the proposed method across different model sizes. Subfigure (b) demonstrates the generalizability of the approach by showcasing its performance across various datasets.

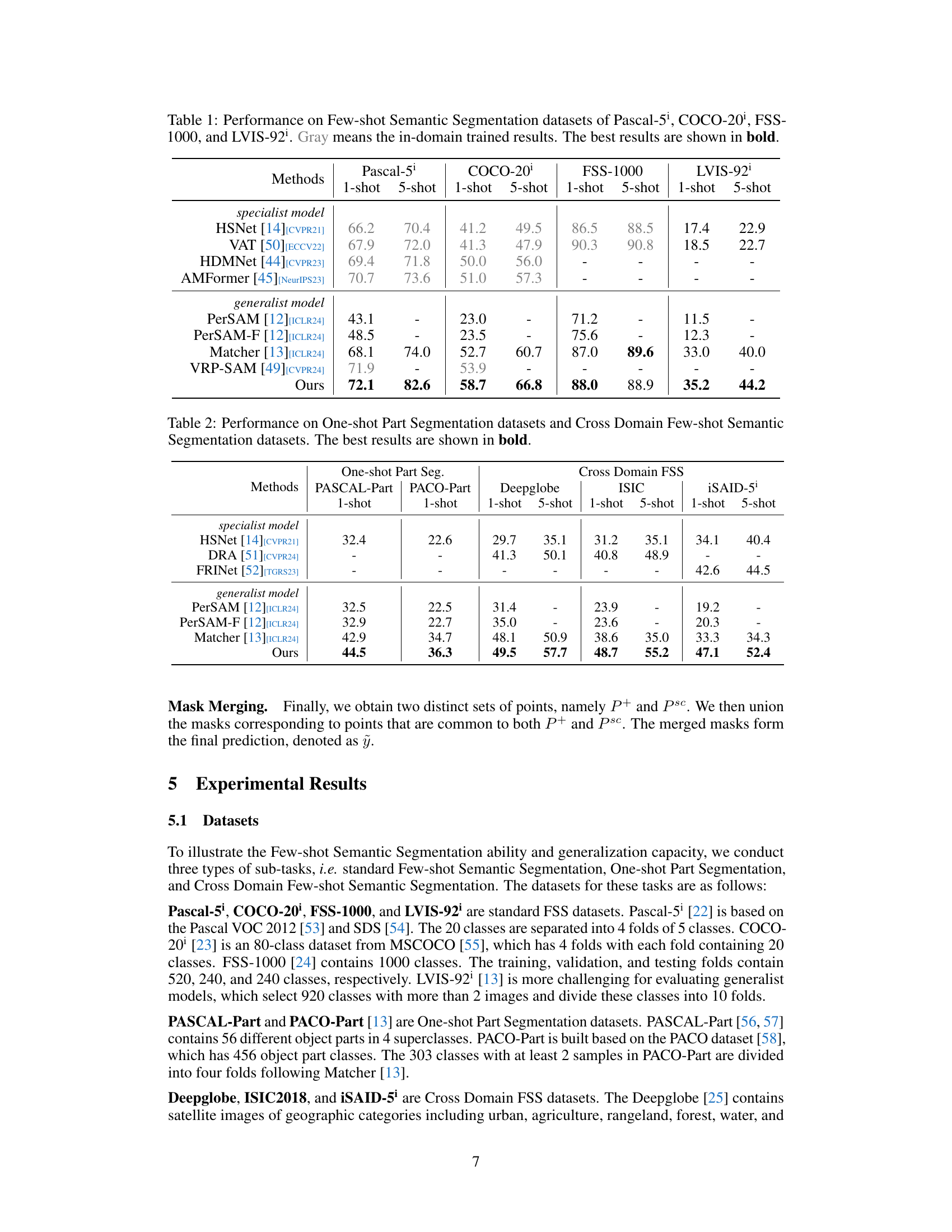
This table presents a comparison of the proposed method’s performance against several state-of-the-art specialist and generalist models on four few-shot semantic segmentation datasets: Pascal-5, COCO-20, FSS-1000, and LVIS-92. The results are shown for both 1-shot and 5-shot settings. The best performance for each dataset and setting is highlighted in bold, and in-domain trained results are indicated in gray. This table highlights the superior performance of the proposed method compared to existing methods across various datasets and settings.
In-depth insights#
Graph FSS#
A hypothetical research paper section titled “Graph FSS” likely explores a novel approach to few-shot semantic segmentation (FSS) using graph-based methods. This suggests moving beyond traditional pixel- or mask-level classification in FSS. The core idea would probably involve representing the relationships between different image segments (masks) as a graph, where nodes might be individual segments and edges represent relationships such as spatial proximity, semantic similarity, or feature correlations. This graph representation could then be used for tasks like prompt selection (identifying the most informative regions for guiding the segmentation model), mask refinement (improving the accuracy of generated masks), and efficient mask aggregation (combining multiple masks into a single, coherent segmentation). Graph-based methods offer the potential for better handling of complex scene layouts, reduced computational cost through efficient graph algorithms, and improved generalization to unseen data compared to traditional FSS methods. The research might explore different graph structures (directed, undirected, weighted), algorithms for graph construction and analysis (e.g., clustering, shortest path), and approaches for integrating the graph-based representations into existing FSS models. The ultimate aim is likely to develop a more robust, efficient, and accurate FSS approach by leveraging the power of graph representations and associated algorithms. The success will hinge on the effectiveness of the chosen graph representation, its suitability for the task, and the efficiency and accuracy of the graph processing techniques employed.
PNA Module#
The PNA (Positive-Negative Alignment) module is a crucial component, dynamically selecting point prompts for mask generation in a novel, graph-based few-shot semantic segmentation approach. Its core function is to intelligently balance the selection of positive and negative point prompts. Unlike existing methods that struggle with suitable prompt selection, the PNA module leverages a pixel-wise correlation analysis between target and reference features. This analysis identifies foreground and background contexts, enabling more effective selection of point prompts by leveraging both positive and negative information; the negative reference is important for preventing overshooting and focusing mask generation. This dynamic selection process is parameter-free, significantly improving efficiency and automation compared to methods with specific hyperparameter settings for different scenarios. The alignment of positive and negative contexts within the PNA module is a key innovation, leading to improved mask quality and a more robust approach to few-shot semantic segmentation.
PMC Module#
The Point-Mask Clustering (PMC) module is a crucial part of the proposed approach, bridging the gap between the fine-grained features of point prompts and the coarse-grained nature of SAM-generated masks. It leverages graph connectivity, constructing a directed graph where nodes represent points and their corresponding masks, and edges indicate mask coverage over points. This graph representation efficiently captures the relationships between points and masks, enabling a hyperparameter-free clustering process. By identifying weakly connected components, the PMC module automatically groups masks and their corresponding points into distinct clusters, aligning the granularity of these two feature types. This clustering facilitates efficient aggregation and filtering of masks, removing redundancies and improving overall accuracy. The graph-based approach is superior to existing methods that rely on heuristic rules or additional hyperparameters for prompt selection and mask merging, thus enhancing both efficiency and performance.
Post-Gating#
The heading ‘Post-Gating’ suggests a crucial stage in a multi-step process, likely refining the results of previous steps. It implies a filtering mechanism, acting as a quality control after initial processing. This could involve removing false positives, enhancing accuracy, or improving efficiency by eliminating redundant or low-confidence results. The graph-based approach mentioned in the paper might facilitate this process by identifying weakly connected components or analyzing mask overlaps. It is reasonable to expect post-gating to improve the final mask predictions by considering contextual information or confidence scores, leading to cleaner, more precise segmentations. The term ‘post’ highlights that this refinement comes after significant computation. Therefore, efficiency is a key concern here, and the method likely leverages the intermediate results and the graph structure to perform this refinement effectively. The process likely involves a two-pronged approach: identifying strong positives and filtering out spurious results. The details might involve thresholding, mask merging, or other decision-making processes leveraging graph connectivity. The overall goal is to produce a superior segmentation result with higher accuracy and less noise.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a research paper, it’s a crucial section demonstrating the model’s design choices and their impact on performance. A well-executed ablation study will isolate each component (e.g., a specific module, a hyperparameter, or a data augmentation technique), removing it while keeping everything else constant. This allows the researchers to quantify the effect of the removed component, providing direct evidence that it is indeed beneficial. The results typically show an increase or decrease in accuracy, demonstrating whether or not a specific element is indeed crucial to the model’s success. A strong ablation study goes beyond simply reporting numbers; it also provides insightful analysis, interpreting the results in terms of the model’s underlying mechanisms such as understanding why certain design choices lead to the observed changes. The quality of an ablation study is judged by the thoroughness of component isolation, the clear presentation of results, and the depth of the analysis provided, all of which together justify the design choices and contribute to the paper’s overall credibility. Finally, a comprehensive ablation study showcases robustness by testing multiple combinations of components, offering a more holistic understanding of the model’s architecture and its sensitivity to various factors.
More visual insights#
More on figures

This figure illustrates the workflow of the proposed approach for few-shot semantic segmentation. It starts by using a backbone network to extract features from both the reference and target images. The Positive-Negative Alignment (PNA) module then leverages these features to select suitable point prompts for the Segment Anything Model (SAM), using both positive (foreground) and negative (background) context. The Point-Mask Clustering (PMC) module then groups the resulting masks from SAM based on their coverage of points, creating natural clusters. Finally, a Post-Gating mechanism refines the results, filtering out false positives to arrive at the final segmentation prediction.

This figure illustrates the Overshooting Gating strategy. The outer ring of points highlights the points that are most similar to their respective clusters. Points with different outside and inside colors do not meet the self-consistency criteria. This gating mechanism helps to filter out false positive masks that extend beyond their intended target regions.

This figure shows a qualitative comparison of the results obtained using different methods on the COCO-20 dataset. The methods compared include Matcher (a state-of-the-art baseline method), a Baseline (the proposed method without the Positive and Overshooting Gating modules), B+PG (the proposed method with Positive Gating), and B+PG+OG (the full proposed method, including both Positive and Overshooting Gating). For each image, the reference image, target image, and the segmentation masks generated by each method are displayed. The comparison visually demonstrates the improvements achieved by incorporating the Positive and Overshooting Gating modules into the proposed approach, particularly in terms of accuracy and robustness. The improved masks generated using the full method (B+PG+OG) show better alignment with the object boundaries and reduce the number of false positives compared to the other methods.

This figure illustrates the workflow of the proposed GF-SAM approach. It starts with a backbone network that extracts features from both reference and target images. The Positive-Negative Alignment module then leverages these features to intelligently select point prompts, considering both positive (foreground) and negative (background) context. These points are then fed to SAM to generate initial masks. The Point-Mask Clustering module groups masks based on their coverage over the points, creating distinct clusters. Finally, a Post-Gating module filters out low-confidence masks and merges the remaining masks to produce the final segmentation output. The whole process is hyperparameter-free.

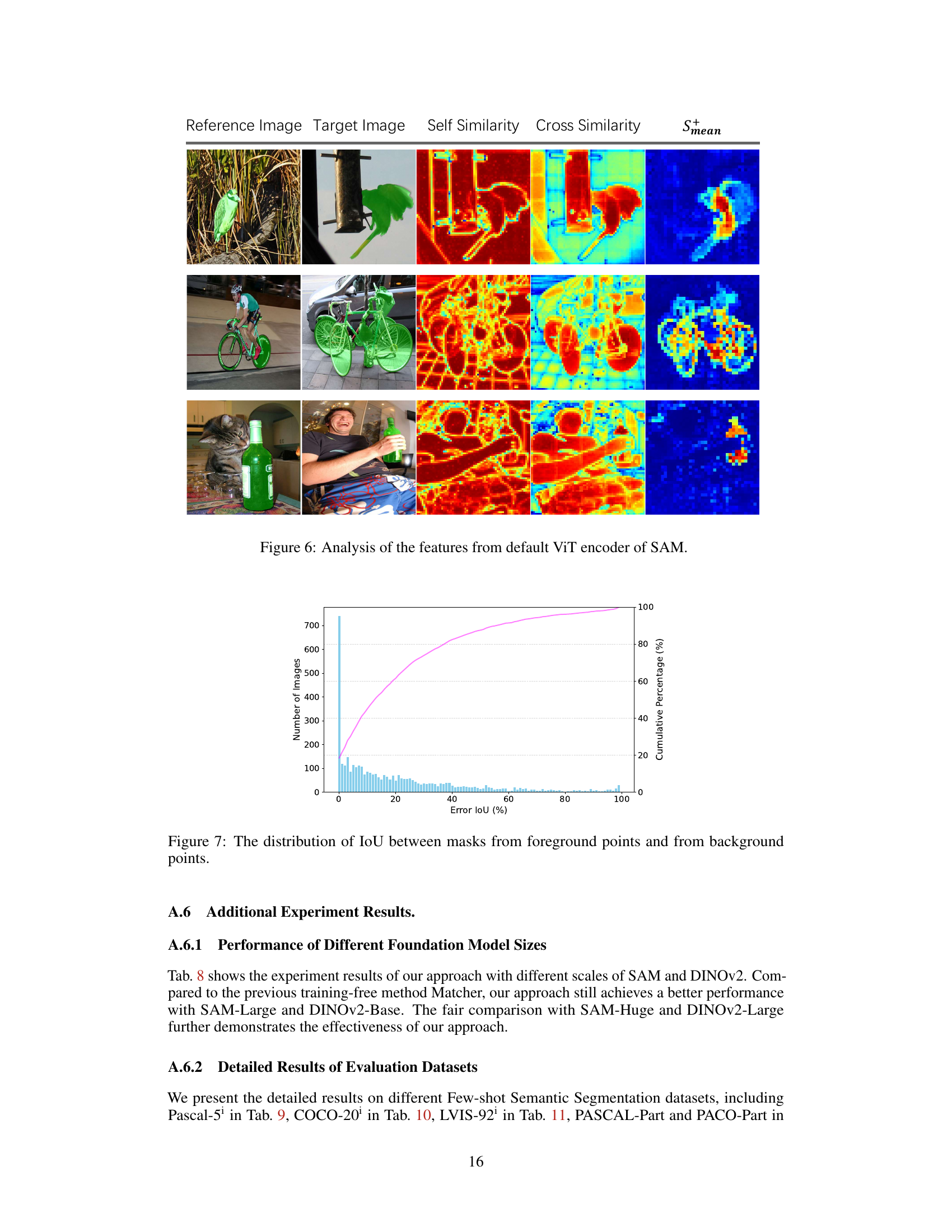
This figure visualizes the features extracted from the default ViT encoder of SAM using the DINOv2 as the objective samples of Pascal-5i dataset. It demonstrates the self-similarity of FSAM, and that the features within each object region are nearly identical, while the features between neighboring different objects are distinct. Although FSAM can accurately identify the regions of objects, its coarse-grained features are not suitable for locating the objects well compared to Smean from DINOv2.

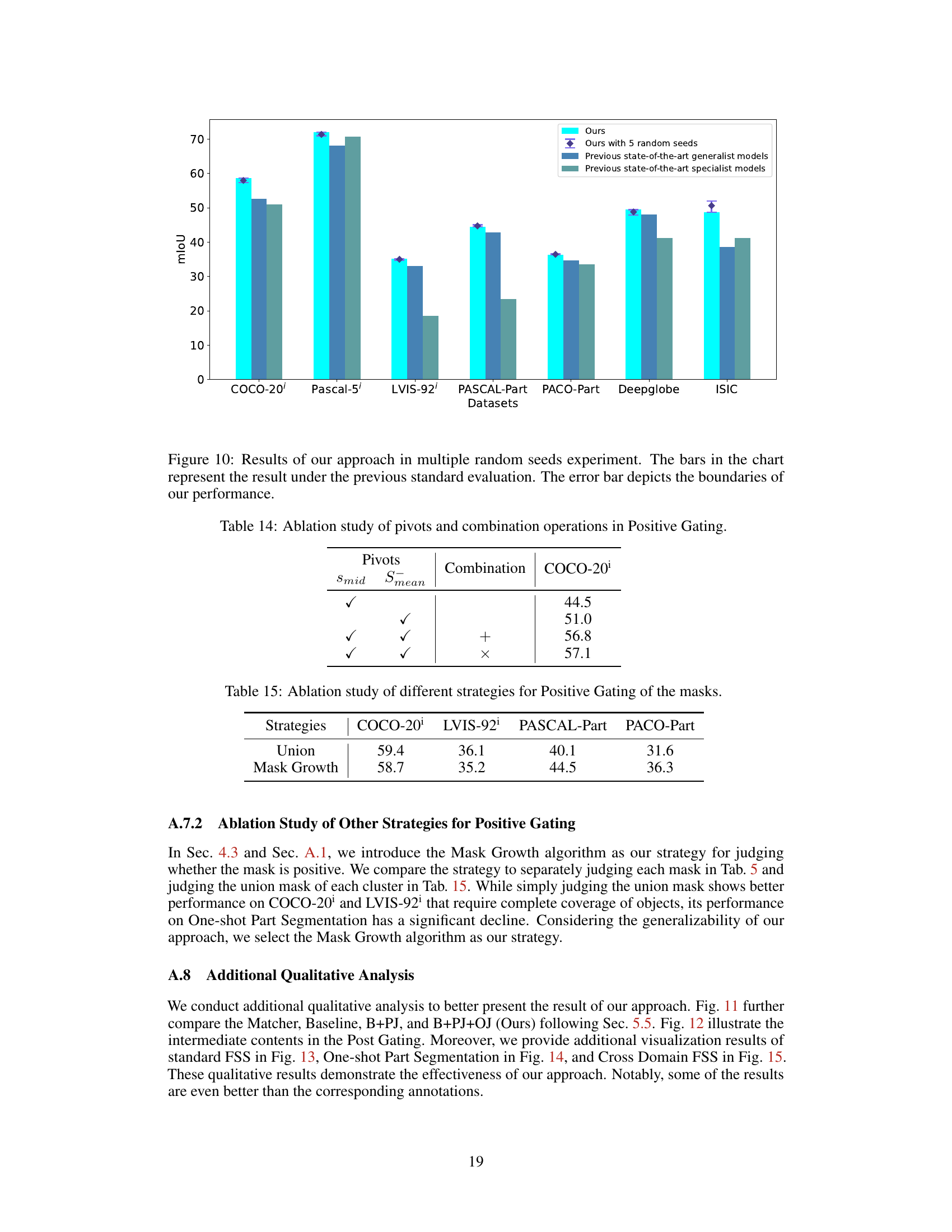
This figure shows the distribution of Intersection over Union (IoU) values between the masks generated from foreground points and those from background points. The x-axis represents the IoU, and the y-axis shows the number of images and the cumulative percentage. The plot illustrates how well the masks generated from the foreground points cover the actual foreground, compared to the overlap with the background regions. A higher concentration of images at higher IoU values indicates better performance in identifying and segmenting foreground objects.

This figure compares the performance of the proposed approach with other state-of-the-art methods in few-shot semantic segmentation. Subfigure (a) shows a performance-efficiency comparison, highlighting the superior efficiency and effectiveness of the proposed approach across different model sizes. Subfigure (b) demonstrates the generalizability of the proposed approach across various datasets.

This figure compares the performance of the proposed method against previous state-of-the-art generalist and specialist models across various datasets using multiple random seeds. The bars show the average mIoU for each dataset, while the error bars indicate the variability of the results across different random seeds. This demonstrates the robustness of the proposed method.

This figure presents a comparison of the proposed method’s performance against state-of-the-art approaches in few-shot semantic segmentation. Subfigure (a) shows a performance-efficiency trade-off comparison, highlighting the proposed method’s superior efficiency at various model sizes. Subfigure (b) demonstrates the generalizability of the proposed approach across multiple datasets.

This figure shows a qualitative comparison of the proposed method (B+PG+OG) against Matcher, Baseline (B), and Baseline+Positive Gating (B+PG) on the COCO-20 dataset. Each row presents a reference image, a target image, and the segmentation masks generated by each method. The goal is to visually demonstrate the improvement in segmentation accuracy and the effectiveness of the proposed Positive Gating and Overshooting Gating modules in reducing false positives and refining mask boundaries. The blue masks in the reference image shows the ground truth for that image.

This figure provides a qualitative visualization of the intermediate steps within the proposed Positive-Negative Alignment (PNA) and Post-Gating modules. It shows how the method dynamically selects point prompts by analyzing correlations between target and reference features, then clusters points and masks based on mask coverage. The green and red points highlight whether points pass the positive and overshooting gating stages respectively, demonstrating the filtering of false positive masks.

This figure shows a qualitative comparison of the results obtained using the proposed method on three different datasets: Pascal-5, FSS-1000, and LVIS-92. For each dataset, it displays the reference image, the target image, and the segmentation result produced by the model. The qualitative analysis demonstrates the effectiveness of the proposed approach in handling various scenarios and datasets, illustrating its capacity to accurately and precisely segment objects across different domains and levels of complexity.

This figure provides a qualitative comparison of the results obtained using different methods on the COCO-20 dataset. The methods compared are Matcher, Baseline, B+PG (Baseline + Positive Gating), and B+PG+OG (Baseline + Positive Gating + Overshooting Gating). Each row shows a reference image, a target image, and the segmentation masks produced by each of the four methods. The figure aims to visually demonstrate the effectiveness of the proposed approach (B+PG+OG) compared to the other methods.

This figure shows a qualitative comparison of the results obtained using the proposed method on two different datasets: Deepglobe and iSAID-5. For each dataset, several example images are shown. Each example includes three columns: the reference image, the target image, and the segmentation result generated by the model. The qualitative analysis demonstrates the model’s ability to accurately segment objects across different domains, including satellite imagery (Deepglobe) and aerial imagery (iSAID-5).
More on tables
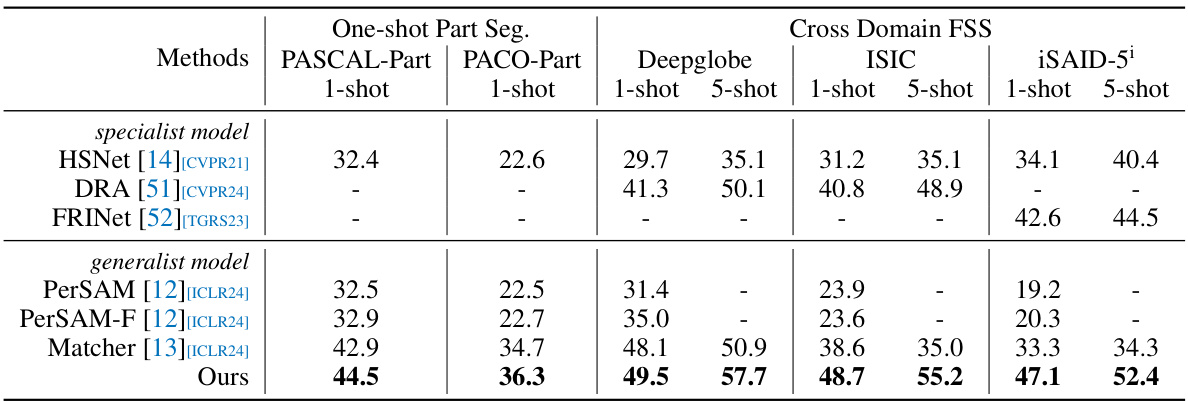
This table presents the performance comparison of different methods on one-shot part segmentation tasks (PASCAL-Part and PACO-Part) and cross-domain few-shot semantic segmentation tasks (Deepglobe, ISIC, and iSAID-5’). The results highlight the proposed method’s superior performance across various datasets and its ability to generalize across different domains. Specialist models are compared against generalist models, and the best results (mIoU) are shown in bold. The table showcases the effectiveness of the proposed approach in various challenging scenarios.
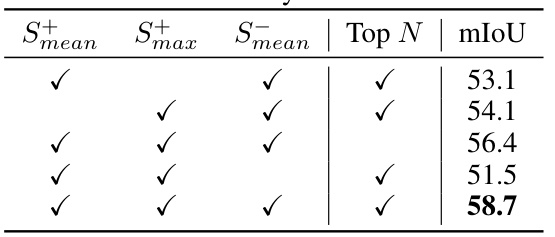
This table presents the ablation study of different point selection strategies. It shows the impact of using different similarity maps (Smean, Smax, Smean) and the parameter-free selection of top N points on the performance (mIoU). The results demonstrate that combining Smean and Smax, and selecting the top N points based on similarity improves the performance.
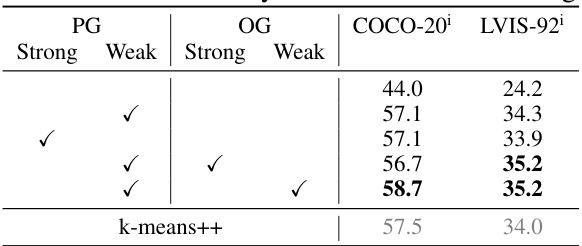
This table presents the ablation study results for the Point-Mask Clustering (PMC) and Post-Gating modules. It shows the performance (mIoU) on COCO-20 and LVIS-92 datasets with different configurations of the modules, specifically evaluating the impact of using strong or weak connectivity in the graph, and the inclusion of positive and overshooting gating. The results highlight the contribution of each component to the overall performance.
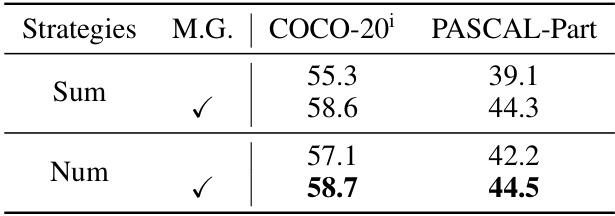
This table presents the ablation study results of the positive gating strategy on each cluster, using the Mask Growth algorithm. It compares different strategies (‘Sum’ and ‘Num’) in terms of their impact on the model’s performance, measured by mIoU on COCO-20 and PASCAL-Part datasets. The ‘M.G.’ column indicates whether the Mask Growth algorithm was used. The results show that the ‘Num’ strategy generally outperforms the ‘Sum’ strategy, suggesting its effectiveness in enhancing the model’s accuracy.
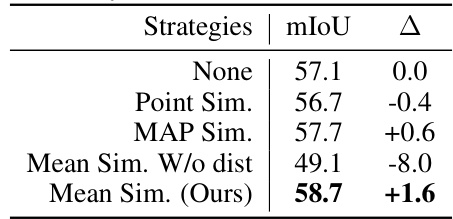
This table presents an ablation study on different strategies for self-consistency measurement in the proposed method. It compares the mean Intersection over Union (mIoU) achieved using different strategies: None (baseline), Point Similarity, Mask Average Pooling (MAP) Similarity, Mean Similarity without distance consideration, and Mean Similarity (Ours, the proposed method). The results show that using Mean Similarity with the proposed distance consideration achieves the best performance, outperforming the baseline by 1.6% mIoU.

This table presents the performance of the proposed approach and the Matcher baseline using different sizes of the SAM and DINOv2 models. The results are reported in terms of mean Intersection over Union (mIoU) on three benchmark datasets: COCO-20, FSS-1000, and LVIS-92. The table shows that the performance improves with larger model sizes for both SAM and DINOv2, and that the proposed approach consistently outperforms the Matcher baseline across all model sizes and datasets.

This table presents a detailed breakdown of the performance of different methods on the Pascal-5i dataset. It shows the mean Intersection over Union (mIoU) for each of the four folds within the dataset for both 1-shot and 5-shot scenarios. The methods compared include AMFormer, Matcher, and the proposed ‘Ours’ method. This granular level of detail allows for a deeper understanding of the model’s performance consistency across different subsets of the dataset.

This table shows the detailed performance of different methods on the COCO-20 dataset for both 1-shot and 5-shot settings. The results are broken down by fold (fold0-fold3) to provide a more granular view of performance. It compares the proposed method against AMFormer and Matcher, illustrating its superior performance across different folds and scenarios.
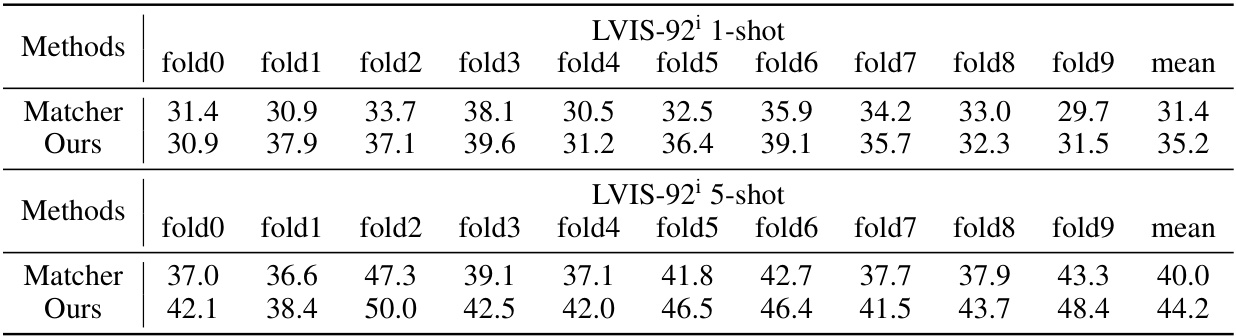
This table presents a comparison of different methods on four few-shot semantic segmentation datasets: Pascal-5, COCO-20, FSS-1000, and LVIS-92. For each dataset, it shows the performance (1-shot and 5-shot) of various methods, distinguishing between specialist and generalist models. The best performance for each setting is highlighted in bold. Gray values indicate in-domain training.

This table presents the performance comparison of different methods on One-shot Part Segmentation tasks (PASCAL-Part and PACO-Part) and Cross-Domain Few-shot Semantic Segmentation tasks (Deepglobe, ISIC, and iSAID-5). It shows the mean Intersection over Union (mIoU) for each dataset and each method, highlighting the best performing methods in bold. The table demonstrates the generalization capabilities of the proposed approach across various datasets and segmentation tasks.
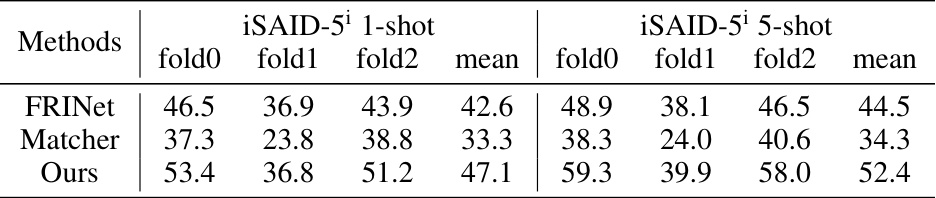
This table presents the detailed performance results of the proposed approach on the iSAID-5¹ dataset. It breaks down the mean Intersection over Union (mIoU) scores across three folds for both 1-shot and 5-shot semantic segmentation scenarios, allowing for a comprehensive evaluation of the model’s performance in different settings.

This table presents an ablation study on the different strategies used in the Positive Gating module within the proposed approach. It explores the impact of using either the median of the mean negative similarity map (S_mid) or the mean negative similarity map itself (S_mean) as pivots for determining the positive masks. It also investigates the effect of combining these two pivots using both addition (+) and multiplication (×) operations. The results are shown for the COCO-20 dataset, indicating which combination yields the best performance.

This table presents the ablation study of different strategies used for positive gating in the proposed method. It compares the performance (mIoU) on four different datasets (COCO-20, LVIS-92, PASCAL-Part, and PACO-Part) using two strategies: ‘Union’ and ‘Mask Growth’. The ‘Union’ strategy simply judges the union mask, while the ‘Mask Growth’ strategy utilizes a more sophisticated algorithm.
Full paper#