↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Multimodal LLMs (MLLMs) are rapidly advancing, but their effective knowledge editing remains challenging. Current methods like intrinsic and external knowledge editing struggle to balance reliability, generality, and locality. This necessitates a unified approach.
The proposed UniKE method tackles this by unifying both intrinsic and external knowledge as vectorized key-value memories, creating a unified paradigm. It further enhances knowledge collaboration through disentangling knowledge into semantic and truthfulness spaces. UniKE demonstrates significant improvements in reliability, generality, and locality across various benchmarks, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the significant challenges of effectively editing multimodal LLMs, a rapidly developing area with immense potential. By proposing a unified framework and novel method, it paves the way for more reliable, generalizable, and localized multimodal knowledge editing. This research directly contributes to the ongoing effort of enhancing the capabilities of multimodal LLMs and opens new avenues for future investigations.
Visual Insights#
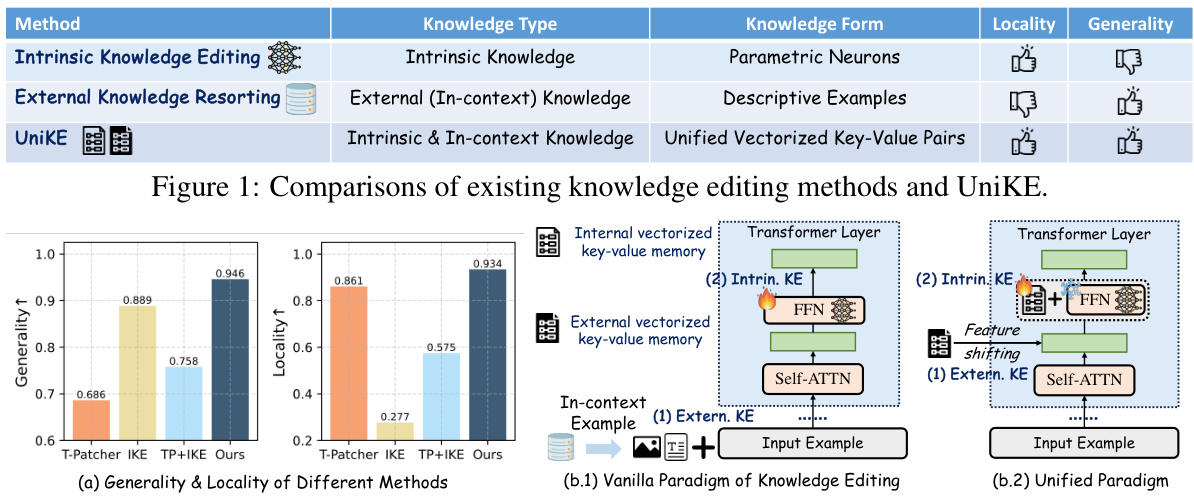
This figure compares three different knowledge editing methods: Intrinsic Knowledge Editing, External Knowledge Resorting, and UniKE (the proposed method). It shows the type of knowledge used (intrinsic, external or both), the form the knowledge takes (parametric neurons, descriptive examples, or unified vectorized key-value pairs), and the resulting locality and generality of each approach. UniKE aims to improve upon the limitations of the other two methods by unifying both intrinsic and external knowledge into a single, unified framework.
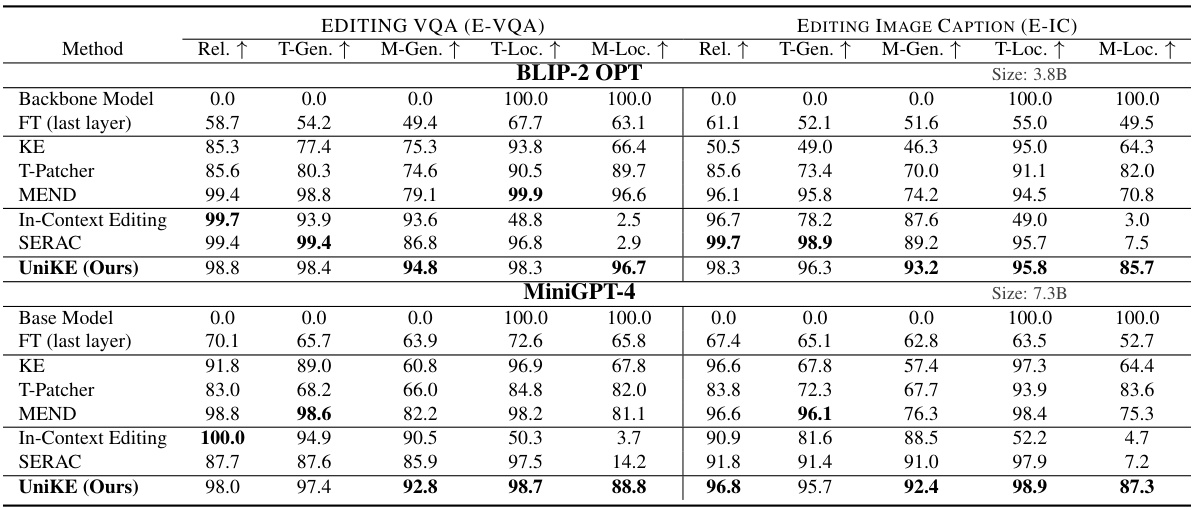
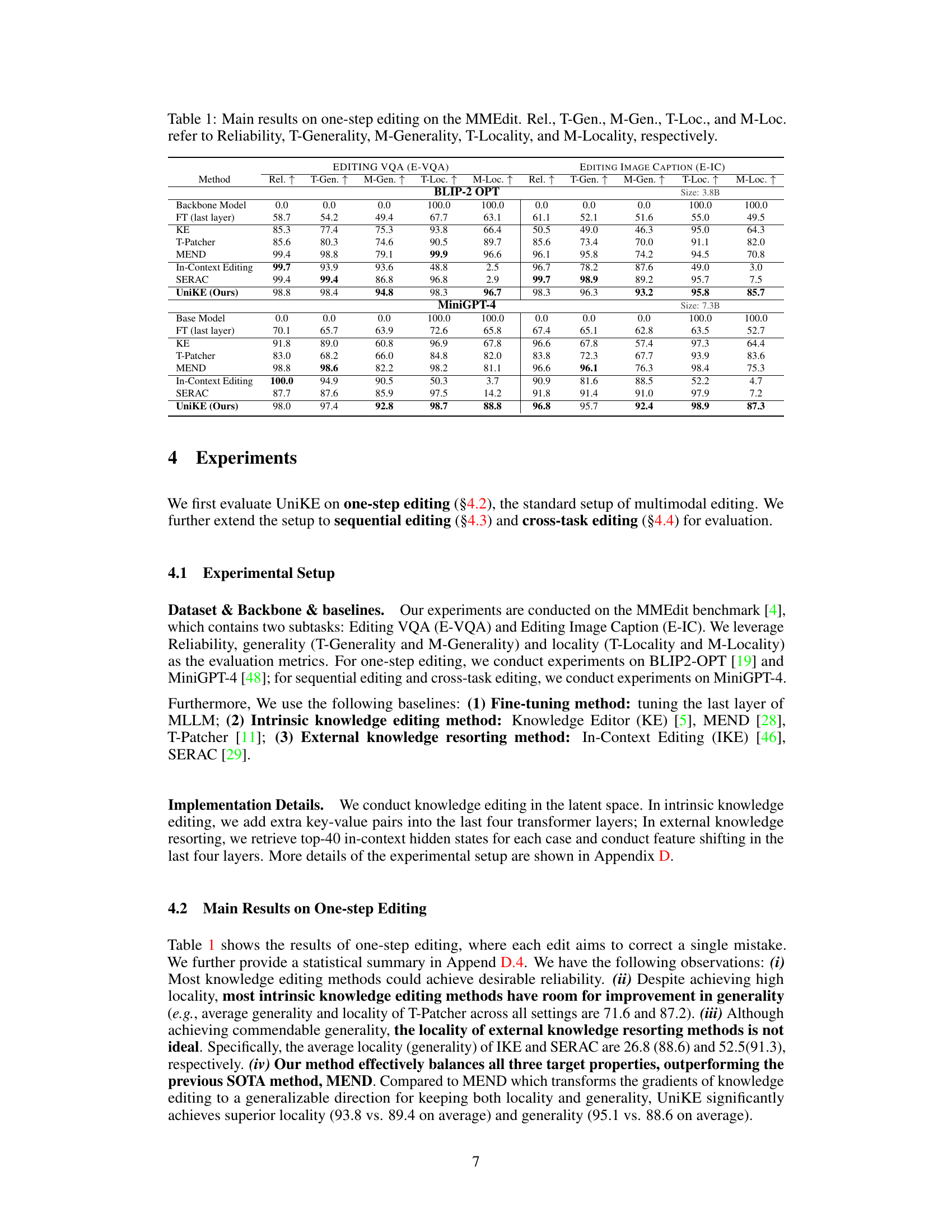
This table presents the performance of different multimodal knowledge editing methods on two tasks: VQA and Image Captioning, using two different backbone models (BLIP-2 OPT and MiniGPT-4). The performance is measured using five metrics: Reliability, Text Generality (T-Gen), Multimodal Generality (M-Gen), Text Locality (T-Loc), and Multimodal Locality (M-Loc). The table allows for a comparison of the proposed UniKE method against several baselines, demonstrating its effectiveness in balancing reliability, generality, and locality.
In-depth insights#
Unified Multimodal Edit#
A unified multimodal editing approach presents a significant advancement in handling the complexities of multimodal large language models (MLLMs). Instead of treating intrinsic and extrinsic knowledge editing as separate processes, a unified framework offers several key advantages. By representing both intrinsic (parametric) and extrinsic (in-context) knowledge as vectorized key-value pairs, the approach establishes a consistent semantic level for editing operations, facilitating seamless integration. This unification simplifies the editing process and avoids the inconsistencies that may arise from disparate knowledge representations. Further enhancing the approach is the disentanglement of knowledge representations into semantic and truthfulness spaces. This strategy improves the reliability of edits by ensuring that the newly incorporated knowledge aligns well with existing model semantics and truthfulness, maintaining the model’s overall consistency. The result is a more robust and reliable method for editing MLLMs capable of handling complex multimodal information while preserving crucial properties like generality and locality. This approach demonstrates a powerful paradigm shift in multimodal knowledge editing, opening the way for more efficient, reliable, and nuanced manipulation of these powerful models.
Knowledge Collab#
The concept of ‘Knowledge Collab’ in a multimodal large language model (MLLM) context suggests a paradigm shift towards a unified approach to knowledge editing. Instead of relying solely on intrinsic (modifying internal model parameters) or extrinsic (providing external context) methods, a collaborative framework is proposed, integrating both approaches synergistically. This involves representing both intrinsic and extrinsic knowledge as vectorized key-value pairs at the same semantic level, enabling seamless interaction. Crucially, knowledge disentanglement, separating semantic and truthfulness aspects, further enhances collaboration. This allows for better selection of external knowledge based on semantic relevance (preserving locality) and for guiding the integration of intrinsic knowledge toward generalizable truthfulness (improving generality). The core idea is that by leveraging the strengths of each approach, while mitigating their individual weaknesses, more robust and effective multimodal knowledge editing can be achieved.
MMEdit Experiments#
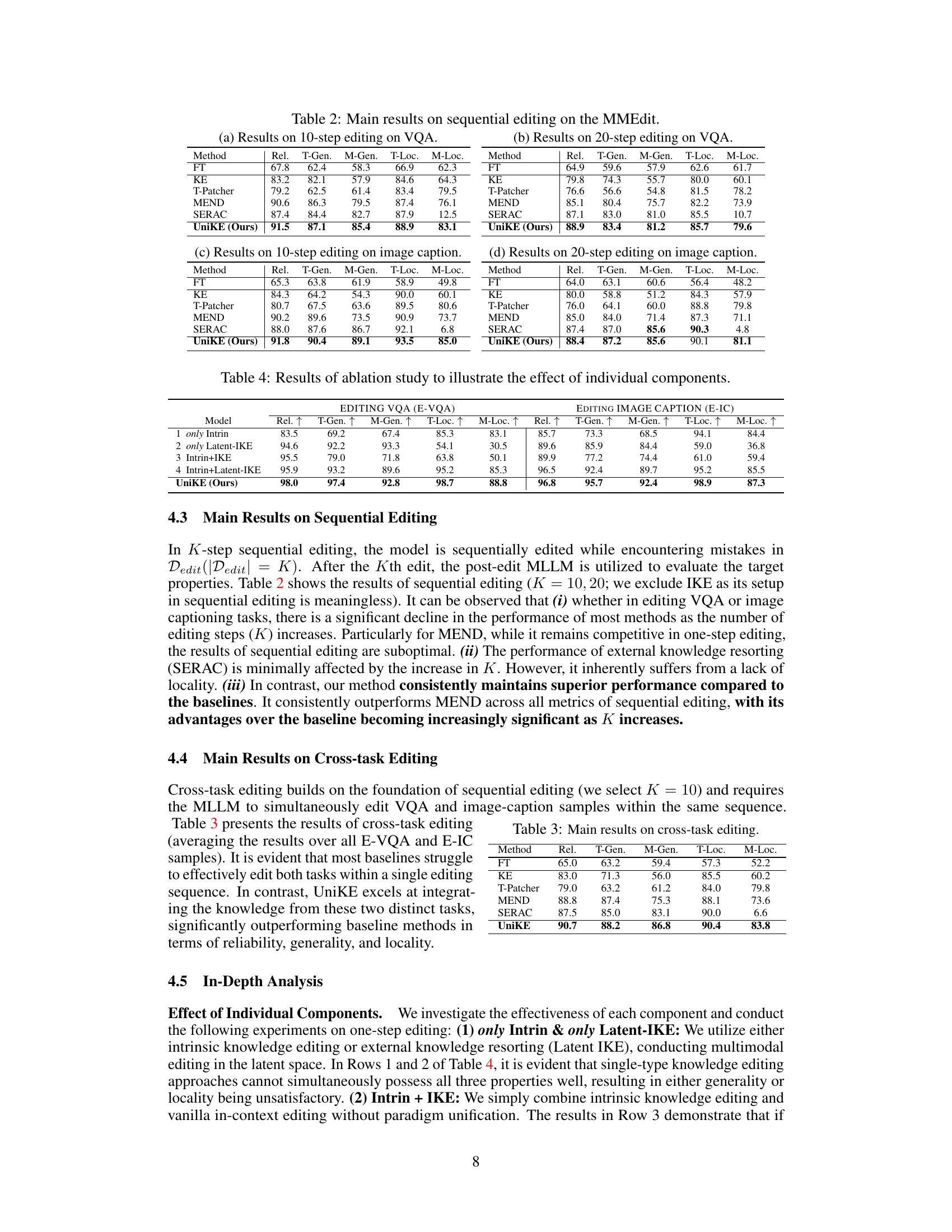
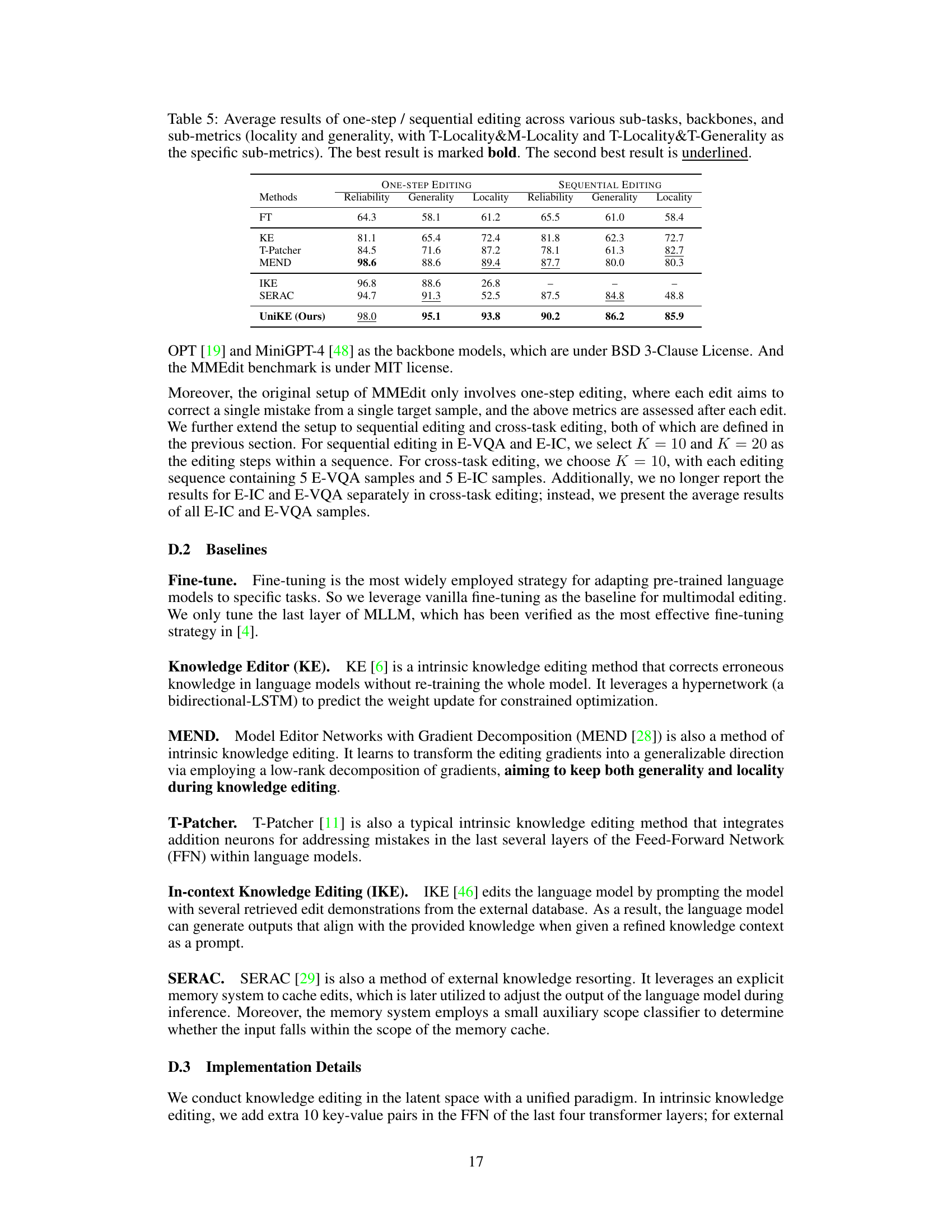
A hypothetical ‘MMEdit Experiments’ section in a research paper would likely detail the empirical evaluation of a multimodal editing method. This would involve selecting appropriate benchmark datasets with diverse multimodal data (e.g., image-caption pairs, question-answer sets with images). Key performance metrics would need to be defined, likely focusing on reliability (accuracy of edits), generality (how well edits generalize to unseen data), and locality (whether edits affect unrelated parts of the model). The experimental setup would describe the chosen baselines (e.g., fine-tuning, other editing methods), evaluation protocols, and the specific implementation details of the proposed method. Results would be presented, possibly using tables and charts, comparing the new approach against the baselines across different metrics and datasets. Statistical significance testing (e.g., p-values) would be essential to demonstrate the method’s superiority. The discussion would interpret the results, addressing any unexpected findings and explaining the strengths and weaknesses observed. Finally, ablation studies could investigate the impact of specific components of the proposed method.
Sequential Editing#
The concept of “Sequential Editing” in the context of multimodal large language models (MLLMs) introduces a crucial advancement over traditional one-step editing methods. Instead of correcting single errors one at a time, sequential editing addresses multiple errors in a series. This approach more realistically reflects real-world scenarios where errors accumulate and require iterative correction. The key challenge lies in maintaining model reliability, generality (the ability to generalize to similar, yet not identical, inputs), and locality (avoiding unintended changes to unrelated parts of the model) throughout the sequence of edits. A successful sequential editing technique needs a robust mechanism to prevent cascading errors and maintain the desired model properties. The evaluation of such a method must carefully consider the cumulative effects of multiple edits and assess the long-term performance of the model after a sequence of corrections. The success of sequential editing is a strong indicator of the true robustness and practical applicability of the underlying knowledge editing framework for MLLMs.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending the unified multimodal editing framework to encompass a wider range of modalities, beyond the visual and textual data considered, is crucial. This includes exploring the integration of audio, haptic, and other sensory inputs, potentially requiring innovative methods for knowledge representation and collaboration across diverse modalities. Another important area is investigating the robustness and scalability of the proposed method to larger, more complex multimodal LLMs. The current research focused on relatively smaller models; assessing performance with significantly larger parameter sizes is needed to determine the practicality and limitations of the approach. Developing more sophisticated knowledge disentanglement techniques is also warranted. The current contrastive learning approach offers a promising start, but further research into more nuanced representations of semantic and truthfulness aspects could improve editing precision and prevent unintended consequences. Furthermore, research into efficient algorithms and hardware acceleration techniques for multimodal knowledge editing is essential for its widespread adoption. Finally, thorough investigations into the ethical implications of multimodal knowledge editing, including potential biases and misuse, should be undertaken to ensure responsible development and deployment of this powerful technology.
More visual insights#
More on figures
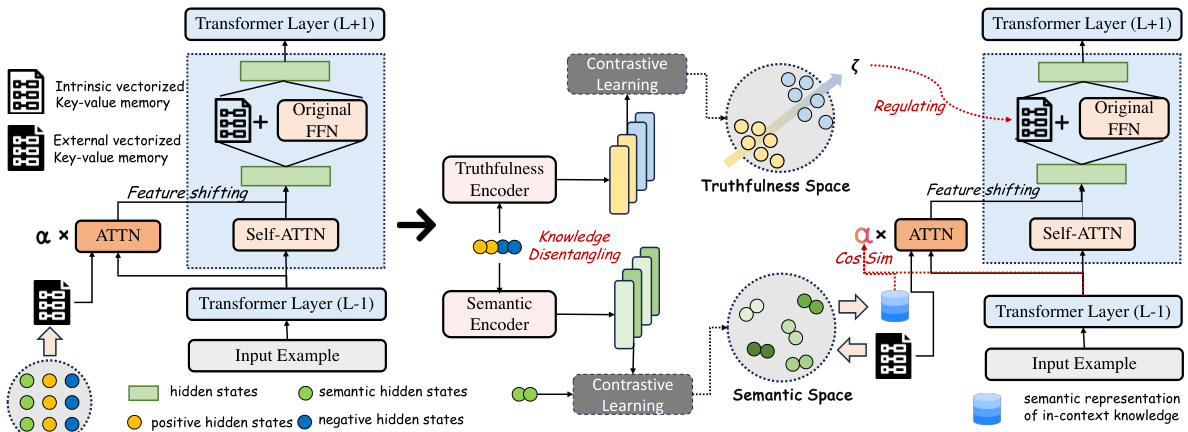
This figure illustrates the UniKE framework. (a) shows the unified view of multimodal knowledge editing, representing both intrinsic and external knowledge as vectorized key-value memories. The intrinsic knowledge is integrated into the internal key-value memory (FFN), while external knowledge is incorporated as external key-value memory through feature shifting in self-attention. (b) details the knowledge collaboration enhancement. It disentangles knowledge representations into semantic and truthfulness spaces using contrastive learning. This allows the model to leverage the strengths of both intrinsic and external knowledge editing synergistically, improving generality and locality.
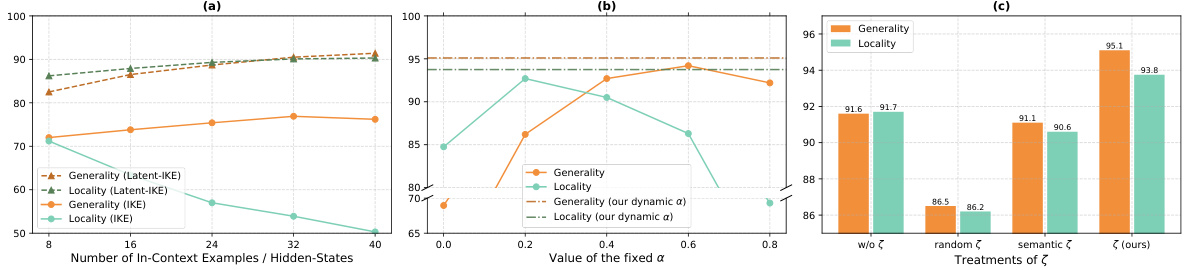
This figure analyzes the impact of different components of UniKE on its performance. (a) compares the performance of IKE and Latent-IKE (both combined with intrinsic knowledge editing) using various numbers of in-context examples/hidden states. (b) evaluates the effect of using a fixed versus a dynamic α (scaling factor controlling the inclusion magnitude of in-context knowledge). (c) shows the results with different treatments of ζ (editing direction derived from the truthfulness space), demonstrating how each component contributes to the overall effectiveness of the method.

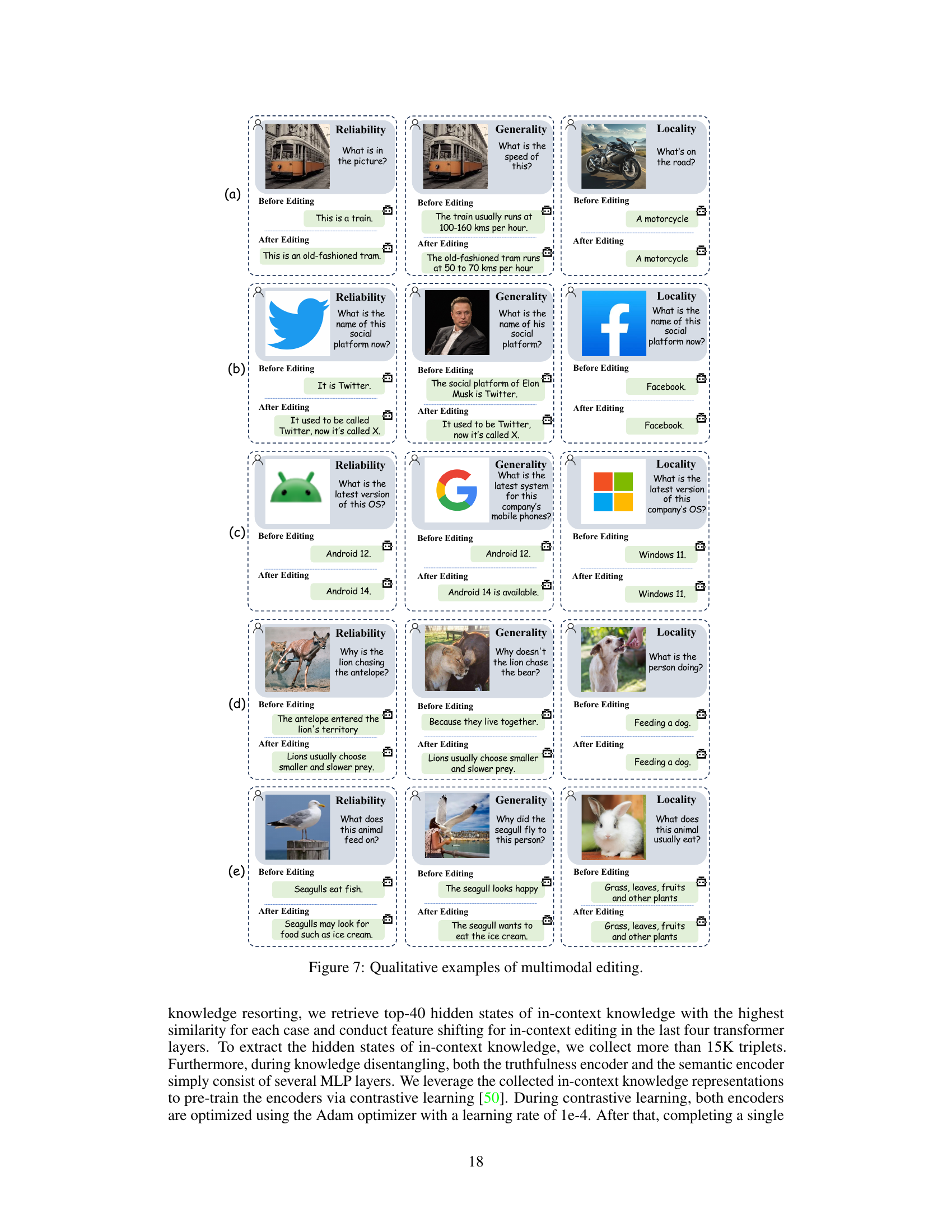
This figure visualizes the disentangled knowledge representations in semantic and truthfulness spaces using t-SNE for dimensionality reduction. (a) shows distinct clustering of positive and negative hidden states within the truthfulness space while similar distributions in the semantic space. (b) provides a qualitative example demonstrating how UniKE performs multimodal editing by correcting factual errors and generalizing to similar scenarios while maintaining accuracy for irrelevant examples. It showcases UniKE’s ability to maintain reliability, generality, and locality during editing.

This figure illustrates the UniKE framework. (a) shows the unified view of multimodal knowledge editing, where both intrinsic and extrinsic knowledge are represented as vectorized key-value pairs. (b) details how UniKE disentangles knowledge representations into semantic and truthfulness spaces to enhance collaboration between intrinsic and extrinsic editing methods. This disentanglement allows for a more controlled and effective editing process, improving the reliability, generality, and locality of the resulting model.

This figure compares three different approaches to knowledge editing: intrinsic knowledge editing, external knowledge resorting, and UniKE. Intrinsic knowledge editing modifies the model’s parameters directly. External knowledge resorting leverages external knowledge sources (e.g., in-context learning) to influence the model’s output. UniKE, proposed in this paper, aims to unify both methods, combining their strengths to provide reliable, general, and localized editing. The figure displays the different types of knowledge used by each method, how the knowledge is represented (parametric neurons or unified vectorized key-value pairs), and their resulting impact on locality and generality.
More on tables
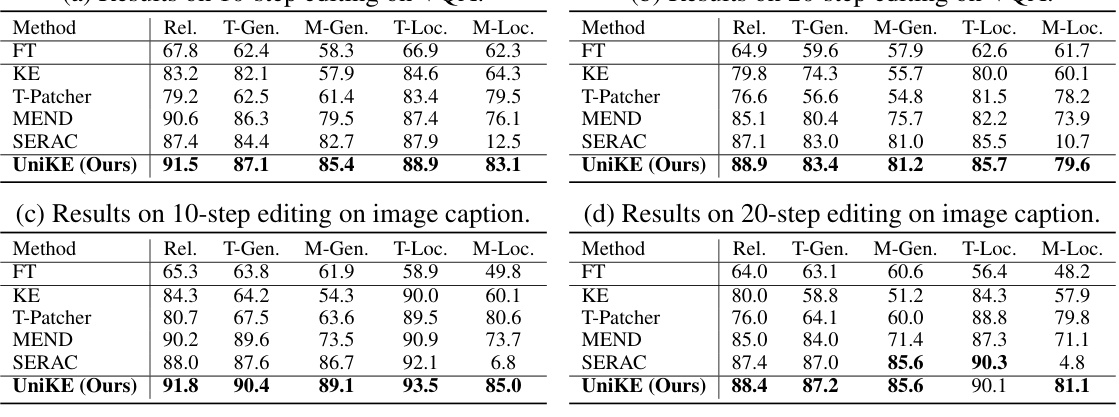
This table presents the performance of different methods on the MMEdit benchmark for one-step multimodal editing. It shows the reliability, generality (text and multimodal), and locality (text and multimodal) of each method across two different backbones (BLIP-2 OPT and MiniGPT-4) and two tasks (VQA and image captioning). The results are used to compare UniKE against several baseline methods, including fine-tuning, intrinsic knowledge editing approaches (KE, T-Patcher, MEND), and external knowledge resorting (In-Context Editing, SERAC).

This ablation study analyzes the individual components of the UniKE model to understand their contributions to the overall performance. It compares UniKE’s full model against versions with only intrinsic knowledge editing, only external knowledge resorting (using latent IKE), intrinsic editing combined with standard IKE, and intrinsic editing combined with latent IKE. The results show how each component impacts the reliability, generality, and locality of the multimodal editing process, demonstrating the synergistic effects of UniKE’s unified framework and knowledge disentanglement.
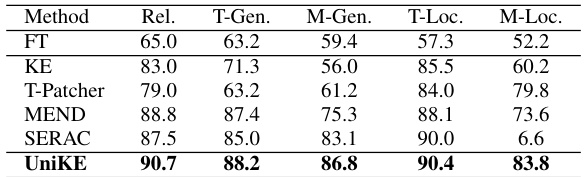
This table presents the results of cross-task editing experiments, where the model is required to edit both VQA and image captioning samples within the same sequence. The metrics used are Reliability, T-Generality, M-Generality, T-Locality, and M-Locality. The results show the performance of different methods across these two tasks simultaneously, highlighting UniKE’s effectiveness in integrating knowledge from distinct tasks.
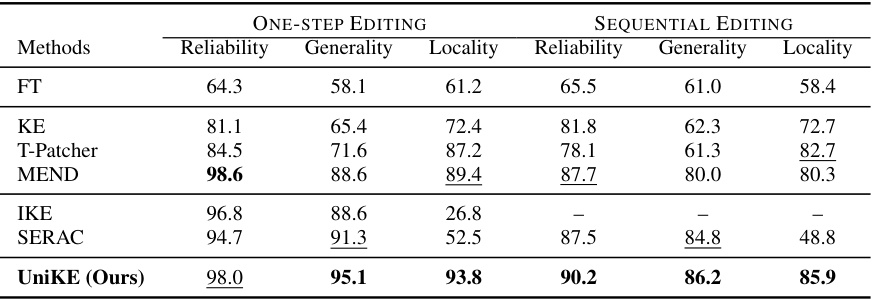
This table presents the main results of the one-step multimodal editing experiments conducted on the MMEdit benchmark. It compares the performance of several methods, including the proposed UniKE, across two different backbones (BLIP-2 OPT and MiniGPT-4). The performance is evaluated using five metrics: Reliability (how accurately the editing changes the model’s output), T-Generality (generality on text-based aspects), M-Generality (generality on multimodal aspects), T-Locality (locality on text-based aspects), and M-Locality (locality on multimodal aspects). Higher scores indicate better performance.
Full paper#