↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current embodied AI struggles with fine-grained scene understanding needed for control, especially with methods like CLIP which fail to achieve this. This is because existing methods primarily rely on contrastive learning for vision-language representation. These representations often lack the detail needed for nuanced control tasks.
This research introduces Stable Control Representations (SCR), a novel approach using pre-trained text-to-image diffusion models. SCR leverages the models’ ability to generate images from text prompts, which inherently capture fine-grained visuo-spatial information. The resulting representations significantly outperform existing methods across diverse simulated control tasks, showcasing their versatility and ability to generalize well. The study also systematically deconstructs the key features of the SCR, providing valuable insights into design space for future research.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates the effectiveness of using pre-trained text-to-image diffusion models for learning robust control policies in various simulated environments. It challenges the limitations of contrastive learning methods and proposes a new approach for representation learning, opening exciting avenues for embodied AI research. The findings offer valuable insights into how these models learn and generalize, which can inform the design of more effective learning methods in this field.
Visual Insights#

This figure demonstrates the Stable Control Representations (SCR) method, which leverages pre-trained text-to-image diffusion models to generate language-guided visual representations for robotic control tasks. The left panel illustrates the architecture of SCR, showing how it integrates a CLIP language encoder, a Stable Diffusion model, and a VAE to produce visual representations. The right panel shows a comparative performance analysis of SCR against other state-of-the-art methods across a variety of benchmarks. SCR consistently achieves competitive results, showcasing its effectiveness in complex, open-vocabulary environments.
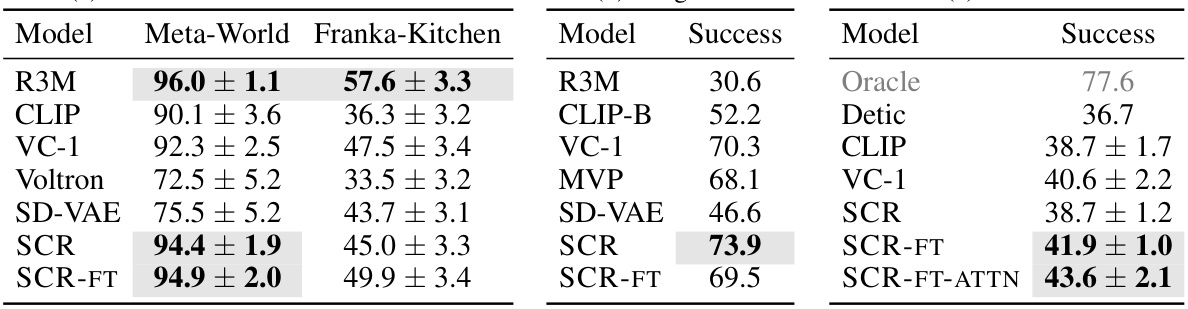
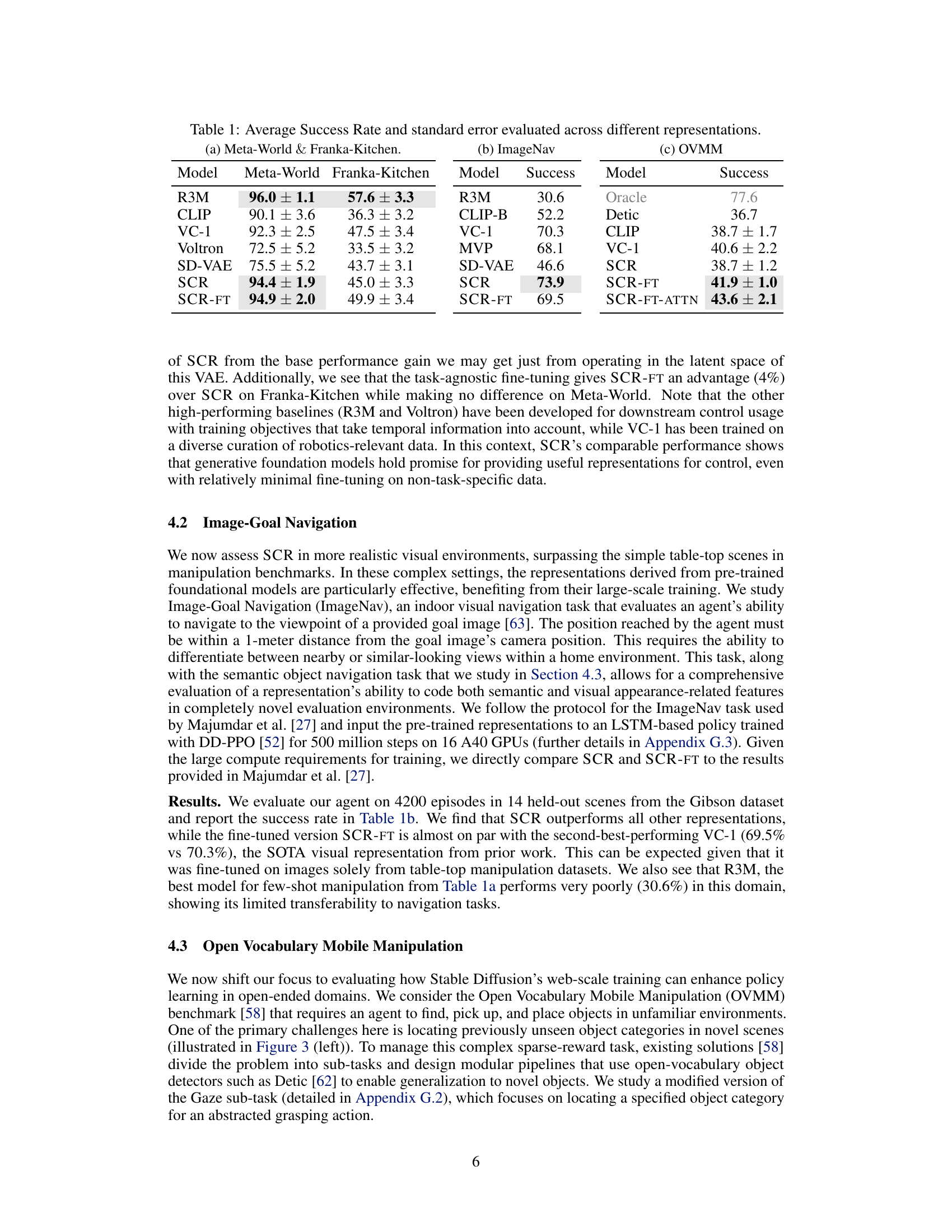
This table presents a comparison of the average success rates achieved by different representation learning methods across three distinct embodied AI benchmarks: Meta-World, Franka-Kitchen, and OVMM. Meta-World and Franka-Kitchen are few-shot imitation learning benchmarks focused on manipulation tasks, while ImageNav and OVMM are reinforcement learning benchmarks focused on navigation tasks. The table shows the mean success rates and standard deviations for each method, allowing for a comprehensive comparison of their performance across different task types. The results show that the Stable Control Representations (SCR) and its variants generally outperform other methods across all benchmarks.
In-depth insights#
Diffusion Control#
Diffusion models, known for their prowess in image generation, offer a compelling avenue for control tasks in robotics and embodied AI. The core idea is to leverage the inherent ability of diffusion models to generate fine-grained and nuanced data representations from text prompts. These representations, rather than being trained explicitly for control, are obtained as intermediate outputs during the denoising process. This approach is particularly appealing because it avoids the need for extensive, task-specific datasets for training. The text conditioning mechanism inherent in diffusion models allows for capturing highly fine-grained visual-spatial information crucial for precise control. However, challenges include careful selection of diffusion model layers and timesteps for extracting useful representations, and effective spatial aggregation methods for combining these features. Fine-tuning strategies to align pre-trained diffusion model representations to the specific needs of downstream robotic control tasks remain an active area of research, aiming to bridge the gap between the models’ general training data and the domain-specific nuances of robotic control.
SCR: Method#
The heading ‘SCR: Method’ suggests a section detailing the Stable Control Representations (SCR) method. A thoughtful analysis would expect a breakdown of the method’s core components: data acquisition and preprocessing (how raw image and text data are obtained and prepared), feature extraction (specific layers from the pre-trained text-to-image diffusion model are used and how they’re combined), representation aggregation (techniques used to combine features from different layers of the diffusion model), and downstream task integration (how the resulting SCR representations are used to train or guide downstream robotic control policies). The description should emphasize the choices made in each step—for example, the rationale for selecting specific U-Net layers, the aggregation techniques used (e.g., concatenation, attention mechanisms), and how the SCRs were incorporated into different control frameworks. A complete explanation would likely include a diagram illustrating the workflow and a discussion of the method’s advantages over existing representation learning methods. Emphasis on addressing the limitations of existing contrastive learning approaches, such as CLIP, and the generalization capabilities of SCR to diverse and unseen environments would be critical. Finally, an explanation of the specific fine-tuning strategies employed would enhance the understanding of the method’s effectiveness and robustness.
Empirical Results#
The empirical results section of a research paper is crucial for validating the claims made in the introduction and abstract. A strong empirical results section will present a comprehensive evaluation of the proposed methods. Robust methodology is key; clearly describing datasets, evaluation metrics, and experimental setup allows for reproducibility. Statistical significance should be reported and properly interpreted. The results should be presented clearly and concisely, often using tables or figures. Comparisons to state-of-the-art methods are essential for demonstrating the contribution’s novelty and effectiveness. Finally, a discussion section should interpret the results, exploring limitations and suggesting avenues for future work. A thoughtful analysis that addresses potential biases, confounding factors and generalizability limitations is also critical.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In the context of a research paper on Stable Control Representations (SCR), an ablation study would likely investigate the impact of different design choices. Key aspects to analyze would be the effects of varying the diffusion timestep during representation extraction, the impact of selecting different layers from the Stable Diffusion model’s U-Net for feature aggregation, and the role of textual prompts in guiding the model. By progressively removing these elements, researchers would evaluate their effects on downstream performance in robotic control tasks and gauge the importance of each component to the overall SCR performance. The results of such a study would demonstrate which design choices are crucial for the robustness and generalization of the learned control policies, providing valuable insights into the optimal configuration of SCR for various robotic control problems. A well-designed ablation study enhances the paper’s robustness and reproducibility by isolating the specific contribution of each component.
Future Work#
Future research could explore several promising directions. Extending the Stable Control Representations framework to other foundation models beyond Stable Diffusion is crucial to determine its generalizability and potential benefits across different architectural choices. A thorough investigation into the impact of different diffusion timesteps and prompt engineering techniques on downstream task performance would refine the representation extraction process. Improving the understanding of how language guidance interacts with visual features in complex tasks remains a key challenge. Exploring alternative spatial aggregation strategies and the use of attention mechanisms could further enhance performance. Benchmarking the approach on more diverse and challenging robotic control tasks is also essential to fully evaluate its capabilities and limitations. Finally, developing more sophisticated methods for handling noisy or incomplete visual inputs will be critical for broader real-world applicability.
More visual insights#
More on figures
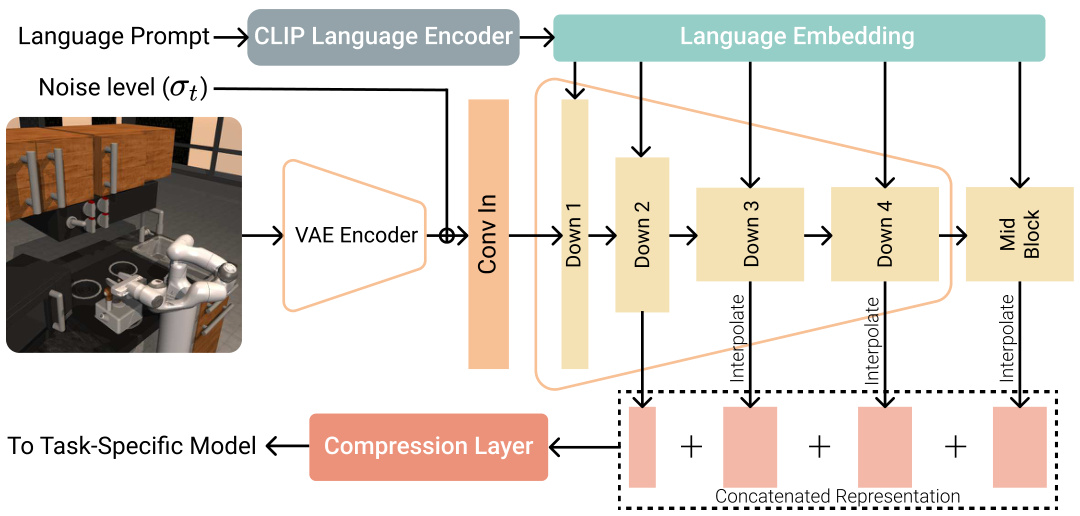
This figure illustrates the process of extracting Stable Control Representations (SCR) from the Stable Diffusion model. An image and text prompt are input. The image is encoded using a VAE, added noise at a specified level (σt), and fed into the U-Net along with the language embedding from a CLIP language encoder. Feature maps from multiple layers (mid and downsampling blocks) of the U-Net are then aggregated to form the final SCR representation.

This figure shows example scenes from the Habitat simulator used in the ImageNav and OVMM tasks. The left image displays a photorealistic rendering of an indoor environment used for ImageNav, while the center image shows a top-down view of a simplified environment for OVMM. The right side showcases example objects from the training and validation sets of OVMM, highlighting the variety of objects used in the benchmark. The figure illustrates the different visual complexities of the tasks and the diversity of objects involved in OVMM.

This figure illustrates the architecture for extracting Stable Control Representations (SCR) from a pre-trained Stable Diffusion model. An image and text prompt are input. The image is encoded and noised using a VAE, and then fed into a U-Net along with the text embedding. Feature maps from multiple layers within the U-Net (specifically, mid and downsampling blocks) are concatenated and then passed through an interpolation and compression layer to create the final SCR representation.

This figure shows example scenes from the ImageNav and OVMM benchmark datasets used in the paper. The left image shows a scene from ImageNav, an indoor visual navigation task. The center image displays a scene from OVMM, an open vocabulary mobile manipulation task. The right side of the figure shows various objects used in the OVMM object set, illustrating the diversity of objects present in the dataset’s training and validation sets.

This figure shows the overall approach of the paper (left) and summarizes the performance of the proposed method compared to other state-of-the-art methods on various tasks (right). The left panel depicts the architecture for extracting Stable Control Representations (SCR) from a pre-trained text-to-image diffusion model, using a language encoder and a Stable Diffusion model. The right panel shows that SCR achieves competitive results across different robotic control tasks, demonstrating its versatility and improved performance, especially in open-vocabulary settings.

This figure shows the overall approach of the paper and the results. The left panel illustrates how Stable Control Representations (SCR) are generated using pre-trained text-to-image diffusion models, while the right panel presents a comparison of the performance of SCR against other state-of-the-art methods across multiple embodied control tasks. The results demonstrate that SCR achieves competitive performance on diverse tasks, including those requiring open-vocabulary generalization.

This figure shows the effect of adding different levels of noise to images from three different tasks (Meta-World, OVMM, and Refer Expression) and then denoising them back to their original state. It demonstrates that the sensitivity to noise varies across tasks, with some tasks being more robust to noise than others. This finding has implications for selecting the appropriate noise level during representation extraction.

This figure shows that Stable Diffusion can extract word-level cross-attention maps that accurately localize objects in a scene. Because these maps are category-agnostic, they make downstream policies robust to unseen objects at test time.

This figure shows images from the Open Vocabulary Mobile Manipulation (OVMM) benchmark along with their corresponding attention maps generated by the fine-tuned Stable Diffusion model. The attention maps highlight the model’s focus during object localization. Five examples demonstrate failures due to various factors like visual ambiguity and misidentification of objects, while one example demonstrates a successful localization.
More on tables

This table presents an ablation study on the design choices for Stable Control Representations (SCR) using the Franka-Kitchen benchmark. It investigates the effects of three design parameters: (a) Denoising timestep: Examines the impact of different levels of noise applied to the input images before the representation is extracted. (b) Layers selection: Evaluates different combinations of layers from the U-Net (used for generating representations) that are concatenated to form the final representation. (c) Input text prompt: Tests whether providing text descriptions affects the performance. Three cases are tested: no prompt, relevant prompts, and irrelevant prompts.

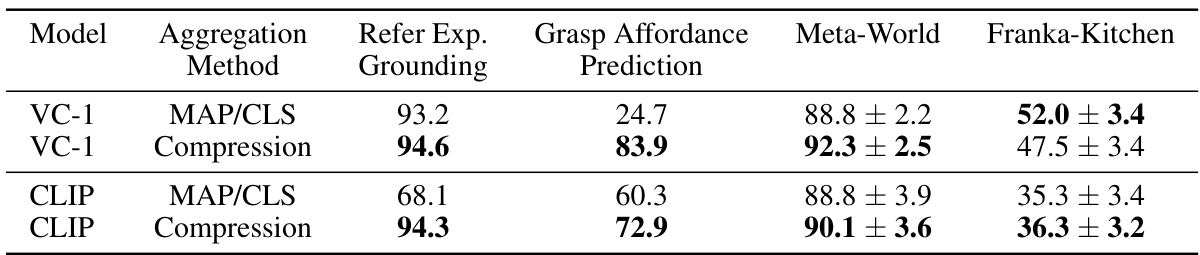
This table presents ablation studies on the impact of layer selection on the performance of CLIP and SCR models on two different benchmark tasks: Franka-Kitchen and Meta-World. For CLIP, different combinations of layers from the model are tested on Franka-Kitchen to assess their relative effectiveness. For SCR, different combinations of layers are tested on Meta-World, along with variations in the noise level applied to the input. The results showcase the effect of different layer combinations and noise levels on the overall success rate of the models.

This table presents the average success rates and standard errors for different representation learning methods across three robotic control tasks: Meta-World, ImageNav, and OVMM. For each task and method, the average success rate and standard error are reported. This table allows for a comparison of the performance of different representation learning methods across various tasks, highlighting the strengths and weaknesses of each approach.
This table presents a comparison of the average success rates across three different robotic control tasks (Meta-World, Franka-Kitchen, and OVMM) using various visual representation learning methods. The success rate is the percentage of times the agent successfully completes the task. The table shows that Stable Control Representations (SCR) and its fine-tuned variant (SCR-FT) achieve high success rates across all three tasks, often outperforming state-of-the-art baselines (like R3M, CLIP, and VC-1). The standard error is included to show the variability in performance.

This table shows the average success rate and standard error for the Franka-Kitchen task after fine-tuning the CLIP model. It compares the performance of the original CLIP model to the CLIP model after fine-tuning. The results indicate a slight decrease in performance after fine-tuning.

This table presents the average success rates and standard errors for different representation learning methods across three robotic control tasks: Meta-World, Franka-Kitchen, and OVMM. The results show how each method performed on these different tasks, allowing for a comparison of their effectiveness. The table is divided into three subsections, each corresponding to a specific task and showing the success rate and standard deviation for different models on that task.
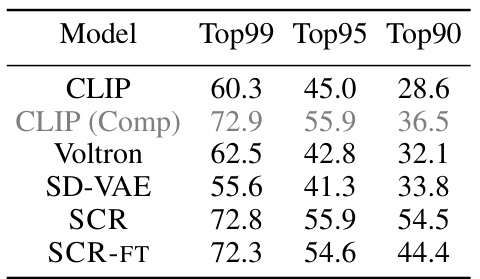
This table presents the average success rate and standard error for different visual representation learning methods across three distinct embodied AI tasks: Meta-World, ImageNav, and OVMM. Meta-World and Franka-Kitchen are few-shot imitation learning benchmarks for manipulation tasks. ImageNav is an indoor visual navigation task, and OVMM is an open-vocabulary mobile manipulation benchmark. The table allows for a comparison of the performance of Stable Control Representations (SCR) and its variants against other state-of-the-art methods, highlighting SCR’s competitive performance and generalization capabilities.

This table presents a comparison of the average success rates achieved by different representation learning methods across three distinct embodied AI benchmark tasks: Meta-World, Franka-Kitchen, and OVMM. Each method’s performance is shown separately for each task. The table also shows the standard error associated with each average success rate, indicating the uncertainty in the results. The results are divided into three subtables, one for each group of tasks.
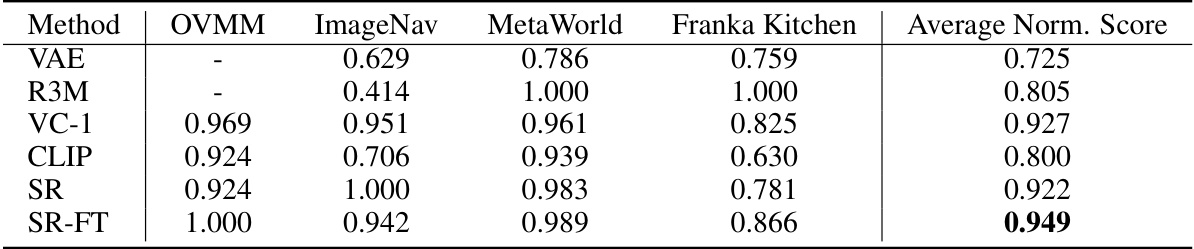
This table presents a comparison of the average success rates achieved by different representation learning methods across three embodied AI benchmark tasks: Meta-World, ImageNav, and OVMM. The table is broken down into three subtables: (a) shows results for Meta-World and Franka Kitchen, (b) for ImageNav and (c) for OVMM. For each task and method, the average success rate and its standard error are reported, allowing for a quantitative comparison of the different approaches’ performance across various robotic control tasks. Note that different metrics are used to calculate the success rate of each task, hence the values should be interpreted in their own contexts.
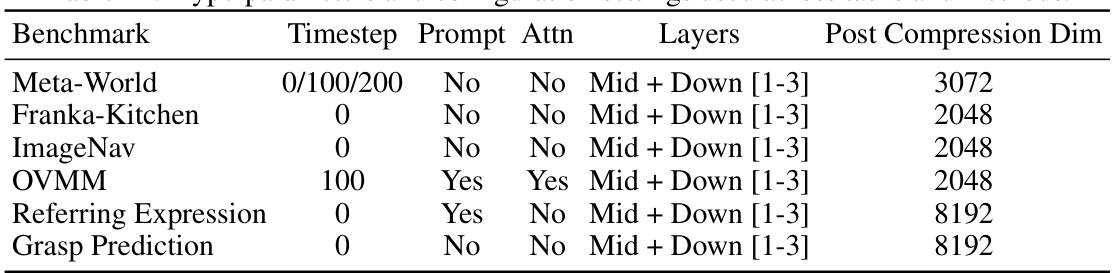
This table presents the average success rate and standard error for different vision-language representation models across three embodied AI benchmarks: Meta-World, Franka-Kitchen, and OVMM. The results show the performance of Stable Control Representations (SCR) and its variants compared to several baseline models, including CLIP, R3M, VC-1, and Voltron. It highlights the competitive performance of SCR across diverse tasks, including manipulation and navigation, demonstrating its versatility in learning control policies.

This table presents the average success rates and standard errors for different vision-language representations across three distinct embodied AI benchmarks: Meta-World and Franka-Kitchen (few-shot imitation learning), ImageNav (reinforcement learning-based indoor navigation), and OVMM (reinforcement learning-based open-vocabulary mobile manipulation). The results showcase the performance of Stable Control Representations (SCR) and its variants compared to various baselines, demonstrating the efficacy of diffusion-model-based representations for control tasks.
Full paper#