↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Generating interesting and challenging problems is a hallmark of human intelligence, driving innovation across various fields. However, automating this creative process remains a challenge, particularly in the context of programming puzzles, where the objective quality of generated problems needs to be measured against various solver models. Existing methods often fall short, failing to consistently produce a range of solvable yet difficult puzzles.
The proposed solution is Autotelic Code Search (ACES). ACES leverages LLMs to generate and label problems based on a set of programming skills, measuring difficulty as the inverse of solver success rates. By iteratively prompting the LLM with diverse examples, ACES generates a wider range of problems than existing baselines, significantly outperforming benchmarks across 11 state-of-the-art code LLMs. This approach establishes a new benchmark for evaluating LLM code generation capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and software engineering. It presents ACES, a novel method for generating diverse and challenging programming puzzles, directly impacting the creation of better benchmarks for evaluating code generation models. This work opens new avenues for research in automated problem generation and adaptive assessment, pushing the boundaries of AI evaluation.
Visual Insights#

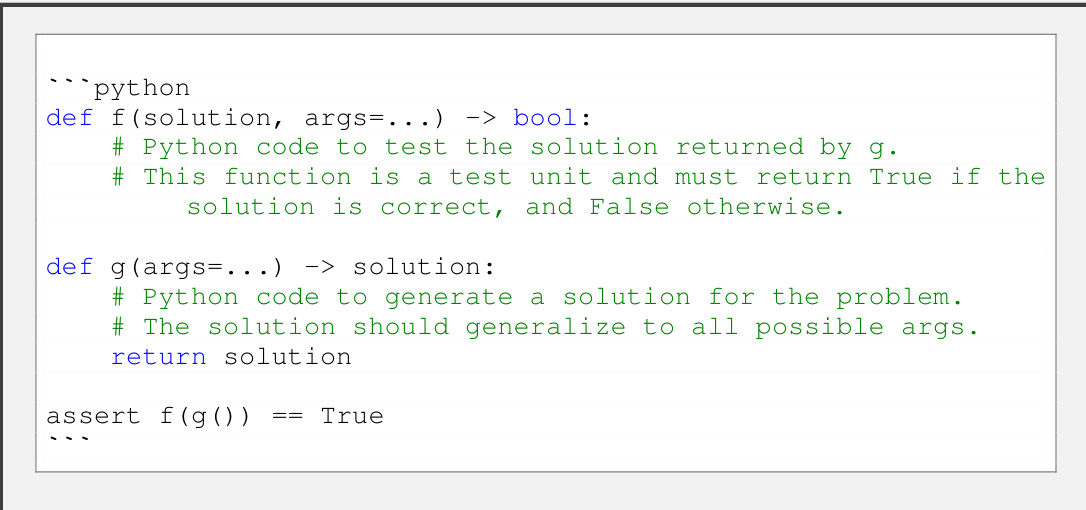
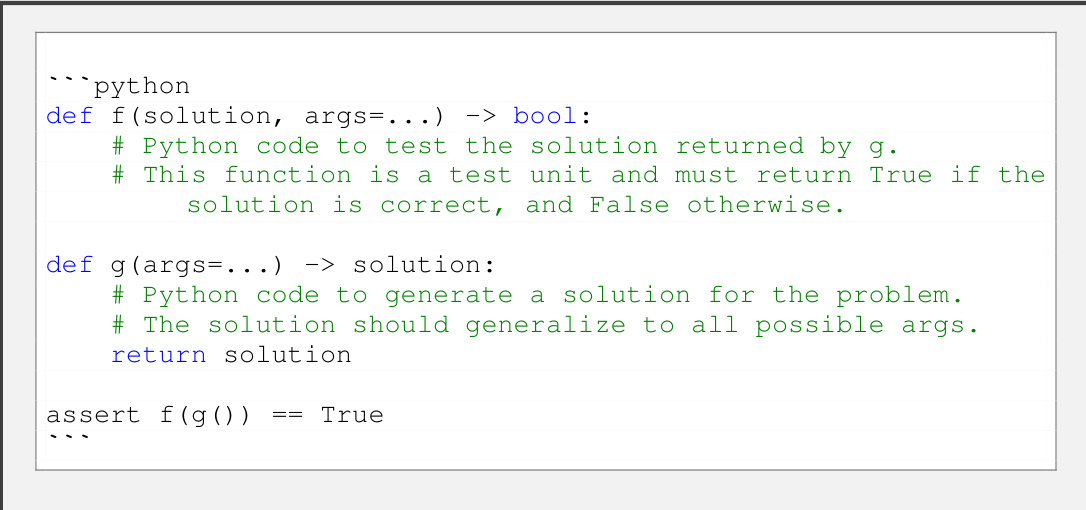
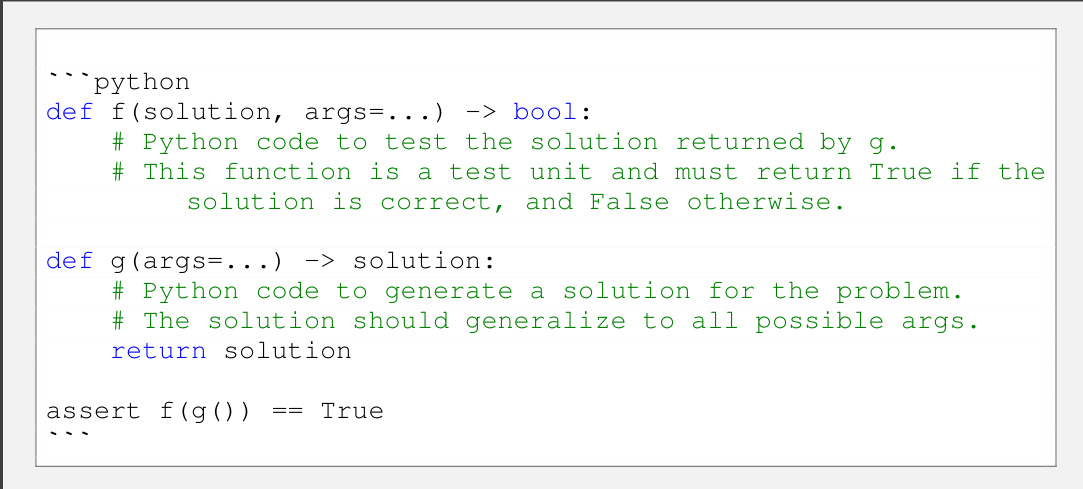
This figure illustrates the ACES (Autotelic CodE Search) algorithm’s iterative process for generating diverse and challenging programming puzzles. It starts by sampling a target skill combination from a puzzle archive. Then, it uses a large language model (LLM) as a puzzle generator, providing it with similar puzzles as examples. The generated puzzle is then tested by an LLM solver 50 times to assess its difficulty. If solvable (at least once), another LLM labels it with the required skills. The puzzle, its difficulty, and skills are then added to the archive, feeding into the next iteration. This iterative process aims to create a diverse and challenging set of puzzles.
In-depth insights#
Autotelic Code Search#
Autotelic Code Search (ACES) is a novel method for automatically generating diverse and challenging programming puzzles. It leverages the power of large language models (LLMs) in a unique way, iteratively optimizing for both the difficulty and diversity of the generated puzzles. Instead of simply querying an LLM with examples, ACES employs a goal-directed exploration strategy, using a quality-diversity algorithm inspired by Map-Elites. This iterative process refines the LLM’s understanding of what constitutes a challenging puzzle, resulting in problems that are significantly harder to solve than existing benchmarks. The system’s use of LLM-generated semantic descriptors to represent the skills needed for problem solving ensures a more nuanced approach to diversity, moving beyond simply evaluating code length or structure. This focus on skill diversity is crucial in creating a well-rounded and comprehensive set of puzzles, suitable for assessing various programming skills and capabilities of LLM-based problem solvers. The resulting benchmarks are not only more difficult but also provide a more thorough evaluation metric than currently available solutions.
LLM-based Puzzle Gen#
LLM-based puzzle generation represents a significant advancement in automated problem creation. By leveraging the capabilities of large language models, this approach moves beyond traditional, handcrafted puzzles, enabling the generation of diverse and challenging problems tailored to specific skill sets. The ability to control the difficulty and skill combinations of generated puzzles is crucial, allowing for customized learning experiences or benchmark creation. However, several considerations warrant attention. The reliance on LLMs introduces potential biases and limitations, as the quality of generated puzzles depends on the model’s training data and inherent capabilities. The need for validation and quality control mechanisms to ensure puzzle solvability and appropriateness is paramount. Moreover, the ethical implications of using LLMs for generating assessments should be carefully considered, particularly regarding potential biases and their impact on fairness. Finally, further research is needed to explore the open-ended nature of problem generation, pushing beyond predefined skill sets and investigating the emergence of truly novel problem types and complexities.
Diversity & Difficulty#
The concept of “Diversity & Difficulty” in problem generation is crucial for effective learning and evaluation. Diversity ensures exposure to a wide range of problem types, preventing overspecialization and promoting adaptability. This is particularly important when dealing with AI models, which may otherwise exploit biases or weaknesses in the training data if presented with similar problems. Difficulty, when thoughtfully balanced, fosters progress by progressively challenging the problem solver. This prevents both boredom from solving trivial problems and frustration from unsolvable ones. Finding the optimal balance between diversity and difficulty is critical. Insufficient difficulty may lead to stagnation, while excessive difficulty risks demotivation or misleading conclusions. The authors of the paper cleverly address both aspects, using an iterative, goal-directed approach. This method is designed to intelligently balance the generation of novel, challenging, yet solvable problems, continually assessing and adjusting the difficulty and diversity via feedback loops.
Benchmarking LLMs#
Benchmarking Large Language Models (LLMs) is crucial for evaluating their capabilities and driving progress in the field. Effective benchmarks require careful design, considering factors such as task diversity, difficulty levels, and the types of prompts used. Existing benchmarks like HumanEval often focus on code generation, but more holistic benchmarks that assess various LLM skills such as reasoning, common sense, and factual knowledge are needed. The choice of evaluation metrics is critical, with accuracy often being insufficient for nuanced comparisons. Measures of efficiency, fluency, and bias mitigation also play important roles in a complete evaluation. Ultimately, a combination of quantitative and qualitative assessments provides the most comprehensive picture of LLM performance. Furthermore, benchmarks should adapt over time, reflecting advancements in LLM capabilities and evolving research priorities. Continuous improvement of evaluation methodologies is critical for the responsible and ethical development of these powerful technologies. This requires active collaboration between researchers and practitioners to ensure that benchmarks remain relevant and provide reliable metrics for assessing LLM capabilities.
Future Directions#
Future directions for research in autotelic generative models for programming puzzles could explore several promising avenues. Improving the quality and diversity of generated puzzles is paramount; this might involve incorporating more sophisticated LLM prompting techniques or using reinforcement learning to guide the generation process based on solver performance. Expanding the scope beyond Python to other programming languages or even broader problem domains (e.g., mathematical problems, game design) would significantly broaden the applicability of the approach. Addressing limitations in the current LLM-based skill labeling through human-in-the-loop methods or the development of more robust automated skill detection is crucial for improving both the accuracy and interpretability of the system. Furthermore, investigating the potential for integrating autotelic generation with other AI methods such as automated curriculum learning or open-ended learning agents offers exciting possibilities for creating dynamic, adaptive learning environments. Finally, a thorough investigation into the ethical considerations surrounding automated puzzle generation, particularly concerning bias and the potential for misuse, is essential for responsible development and deployment.
More visual insights#
More on figures

This figure compares the performance of ACES and its variants against other baselines in terms of both diversity and difficulty of generated programming puzzles. The top row shows the diversity across different metrics: semantic diversity (number of unique skill combinations), embedding diversity using two different embedding models (codet5p and deepseek-coder-1.3b). The bottom row shows the fitness (difficulty) metrics: average fitness over the last 160 generations, QD-score (a quality-diversity measure), and the overall distribution of fitness values across all generated puzzles. The results consistently demonstrate that ACES and its variants generate more diverse and more challenging puzzles than the baselines.

This figure presents a comprehensive comparison of ACES and other baselines across multiple metrics. The top row displays diversity metrics, starting with semantic diversity (a), which measures the unique combinations of programming skills used across the generated puzzles. It then shows embedding diversity using two different models: codet5p (b) and deepseek-coder-1.3b (c). The bottom row focuses on the fitness (difficulty) of the puzzles. (d) shows the average fitness of valid puzzles generated in the last 160 generations, (e) shows the quality-diversity score (a combined metric of diversity and quality), and (f) presents distributions of fitness values across all generated archives. The results demonstrate that ACES variants outperform the baselines in terms of both diversity and difficulty.

This figure displays the results of the experiments comparing ACES with other baselines in terms of diversity and difficulty of the generated puzzles. The first row shows the diversity of generated puzzles in terms of semantic diversity, embedding diversity using two different models (codet5p and deepseek-coder-1.3b). The second row shows the average fitness (difficulty) of the puzzles, the quality-diversity score, and the distribution of fitness values in the archives. The results show that ACES variants consistently outperform other baselines across all metrics.

This figure compares the performance of ACES against other baselines in terms of diversity and difficulty of generated puzzles. The top row shows three different diversity metrics: semantic diversity, embedding diversity using codet5p, and embedding diversity using deepseek-coder-1.3b. The bottom row shows three different fitness metrics: average fitness, QD-score, and distributions of fitness values. The results demonstrate that ACES consistently outperforms other methods across all metrics, indicating its superior ability to generate diverse and challenging puzzles.

This figure compares the performance of ACES against several baseline methods across various metrics related to diversity and difficulty of generated programming puzzles. The top row shows diversity metrics: (a) counts unique skill combinations, (b) uses codet5p embeddings, and (c) uses deepseek-coder-1.3b embeddings. The bottom row shows difficulty metrics: (d) average fitness (difficulty) over the last 160 generated puzzles, (e) Quality Diversity score (a combined diversity and difficulty measure), and (f) distributions of puzzle fitness across the whole generated dataset. The results demonstrate that ACES produces more diverse and more challenging puzzles compared to the baseline methods.
This figure presents a comparison of ACES and its variants against several baselines (ELM, ELM-CVT, StaticGen) in terms of diversity and difficulty of generated programming puzzles. The top row shows diversity metrics: semantic diversity (number of unique skill combinations), embedding diversity using two different embedding models (codet5p and deepseek-coder-1.3b). The bottom row displays fitness metrics: average fitness (difficulty), Quality Diversity (QD) score (a combined measure of diversity and difficulty), and distributions of fitness scores across all generated puzzles. The results demonstrate that ACES variants significantly outperform the baselines in all aspects, generating puzzles that are both more diverse and more challenging.
This figure shows a comparison of ACES and several baseline methods across various metrics related to diversity and difficulty of generated programming puzzles. The first row displays the diversity of generated puzzles, comparing semantic diversity (number of unique skill combinations), and embedding diversity using two different embedding models (codet5p and deepseek-coder-1.3b). The second row focuses on the difficulty (fitness) of the generated puzzles, presenting average fitness, Quality-Diversity (QD) score, and the distributions of fitness scores across all generated puzzles. In all metrics, ACES variants outperform baseline methods, demonstrating their superior ability to produce more diverse and challenging programming puzzles.
This figure compares the performance of ACES against several baseline methods across multiple metrics. The top row shows diversity metrics: semantic diversity (number of unique skill combinations), and embedding diversity (using two different embedding models). The bottom row shows fitness metrics: average fitness (difficulty), quality diversity score (QD-score, a combined measure of diversity and difficulty), and distributions of fitness scores across the generated puzzles. The results demonstrate that ACES generates more diverse and more challenging puzzles than baselines methods.

This figure compares the performance of ACES and its variants against several baselines in terms of puzzle diversity and difficulty. The first row shows diversity metrics across different methods: semantic diversity (the number of unique skill combinations), embedding diversity (using codet5p and deepseek-coder-1.3b models), showing ACES variants generate more diverse puzzles than baseline methods. The second row illustrates the fitness (difficulty) of generated puzzles: average fitness (difficulty score), quality-diversity score, and the fitness distribution across the archives. Again, ACES variants demonstrate superior performance, producing more challenging and diverse puzzles.
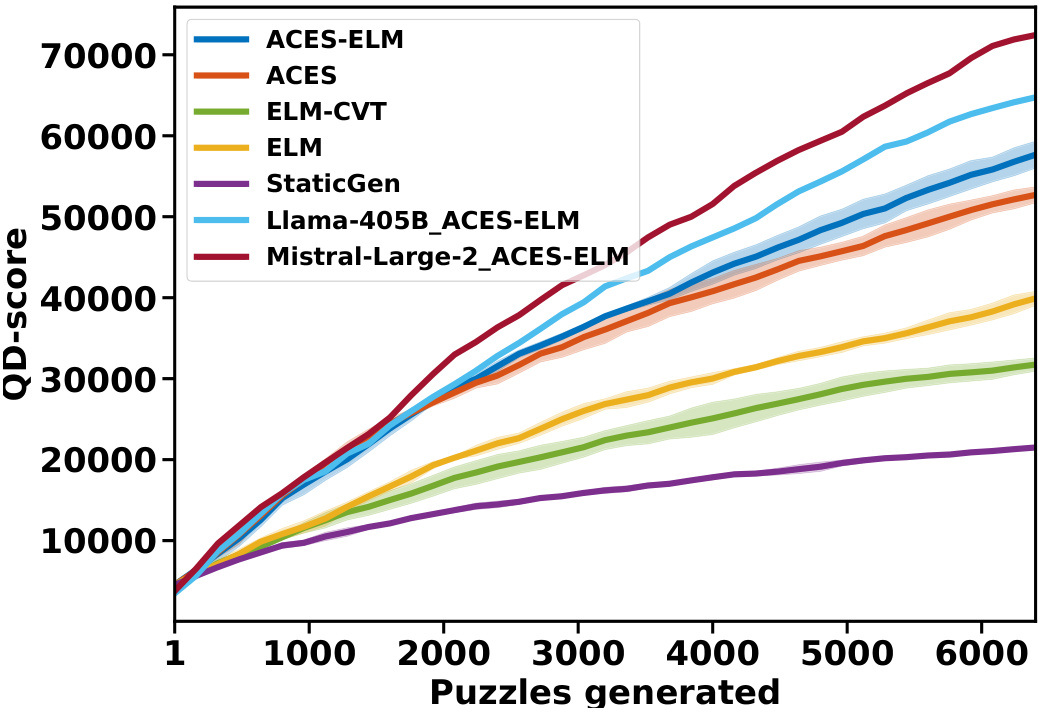
The figure shows the evolution of the quality-diversity (QD) score over the number of puzzles generated for different algorithms. ACES-ELM consistently outperforms other methods, demonstrating its superior ability to generate diverse and high-quality puzzles. The inclusion of larger LLMs (Llama-405B and Mistral Large-2) in the ACES-ELM algorithm further enhances its performance, showcasing the scalability of the method. The shaded regions represent the standard deviation across multiple runs, indicating the algorithm’s robustness.
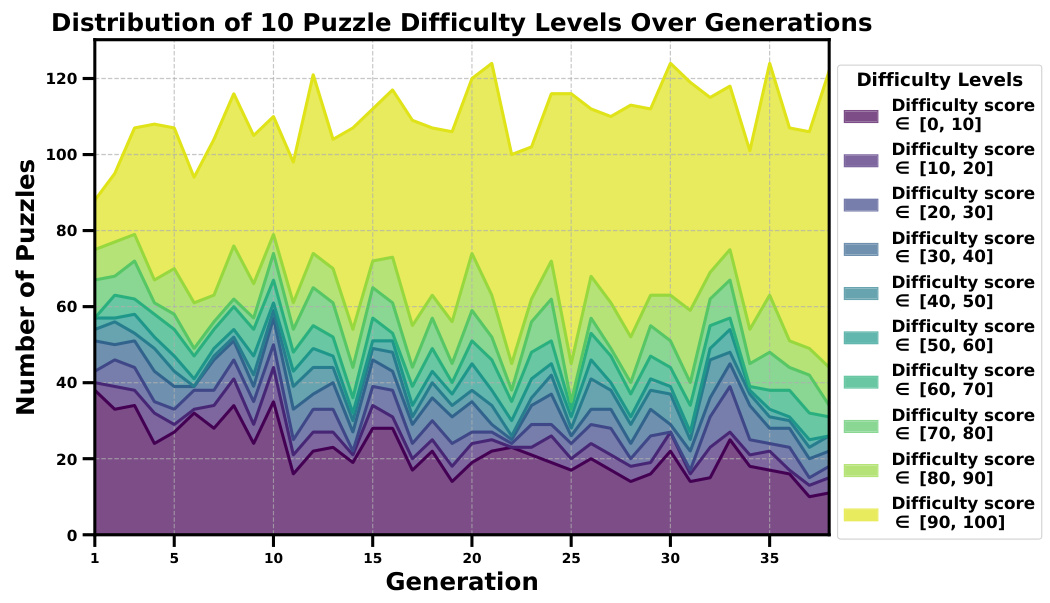
This figure shows the distribution of puzzle difficulties over 40 generations of the ACES algorithm. The y-axis represents the number of puzzles, and the x-axis represents the generation number. The area chart displays the distribution of puzzles across ten difficulty deciles (0-10, 10-20,…, 90-100). The chart visualizes how the difficulty distribution of generated puzzles changes over time during the ACES algorithm’s iterative process. This allows for an analysis of whether the algorithm successfully generates more challenging puzzles across generations.
This figure demonstrates the superior performance of ACES (Autotelic CodE Search) and its variant ACES-ELM compared to other baselines (ELM, ELM-CVT, StaticGen) in generating diverse and challenging programming puzzles. The top row shows the diversity metrics across different methods: semantic diversity (number of unique skill combinations), and embedding diversity using two different embedding models (codet5p and deepseek-coder-1.3b). The bottom row displays fitness metrics: average fitness, quality-diversity (QD) score, and the distribution of fitness values across all generated puzzles. In all aspects, ACES and ACES-ELM outperform the baselines.
This figure compares the performance of ACES against several baseline methods in generating programming puzzles. The top row shows the diversity of generated puzzles across different metrics: semantic diversity (number of unique skill combinations), and embedding diversity in two different embedding spaces (codet5p and deepseek-coder-1.3b). The bottom row shows the quality of generated puzzles, measured by average fitness (difficulty), quality diversity score (QD-score), and the distribution of fitness values across the entire set of generated puzzles. The results demonstrate that ACES and its variants significantly outperform the baselines in terms of both the diversity and the difficulty of the generated puzzles.
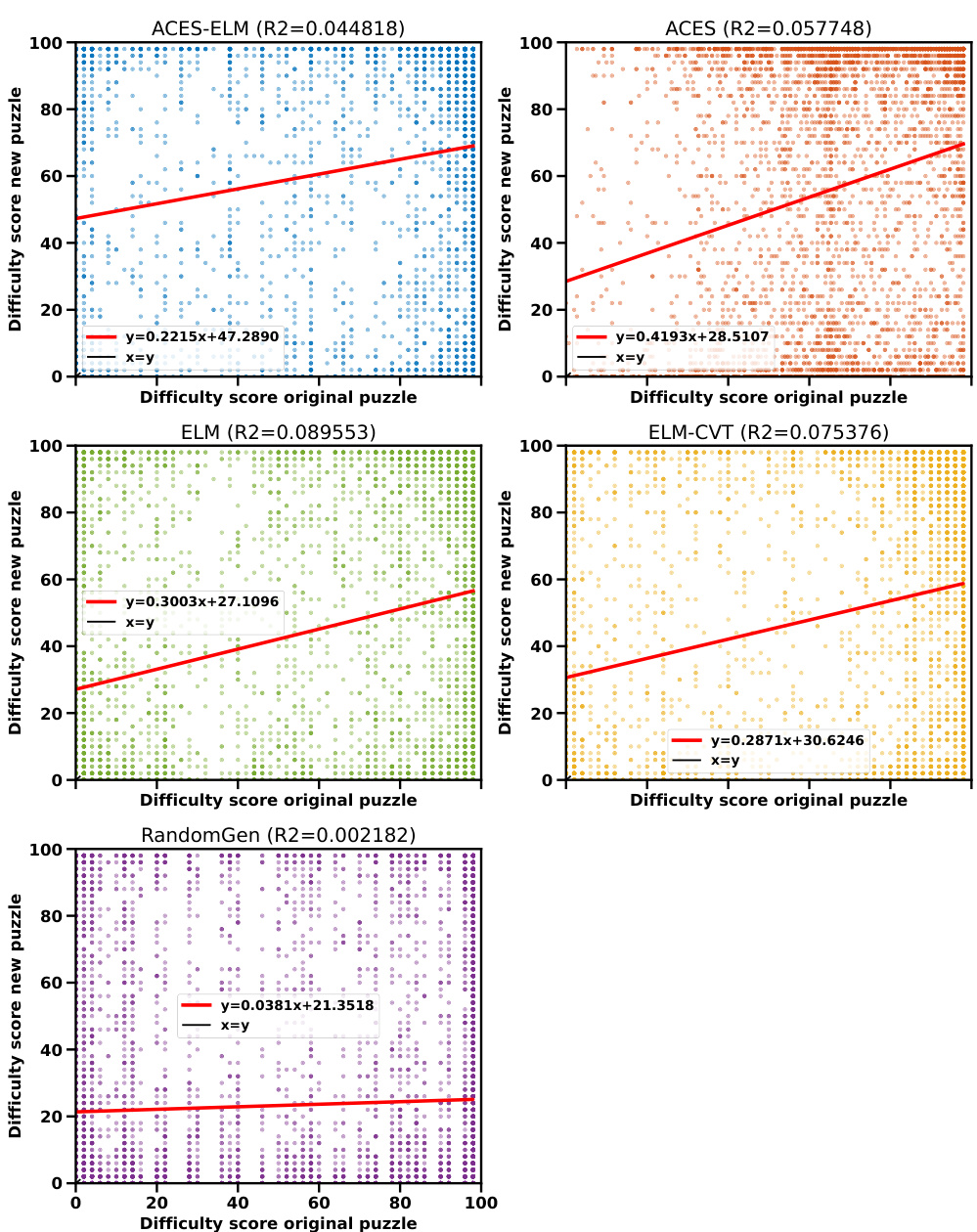
This figure displays the correlation between the difficulty scores of puzzles used as few-shot examples and the difficulty scores of the puzzles generated based on those examples, for different algorithms (ACES-ELM, ACES, ELM, ELM-CVT, and RandomGen). Each plot shows a scatter plot with a linear regression line. The R-squared value (R2) for each regression line indicates the goodness of fit, showing how well the linear model explains the variance in the data. The x-axis represents the difficulty score of the original puzzles, and the y-axis represents the difficulty score of the newly generated puzzles. The diagonal line represents a perfect correlation (x=y). Deviations from the diagonal line suggest that the algorithms don’t perfectly preserve difficulty when generating new puzzles from old ones. The R2 values suggest that the degree of correlation varies across the algorithms, with some showing a stronger relationship between original and generated puzzle difficulties than others.
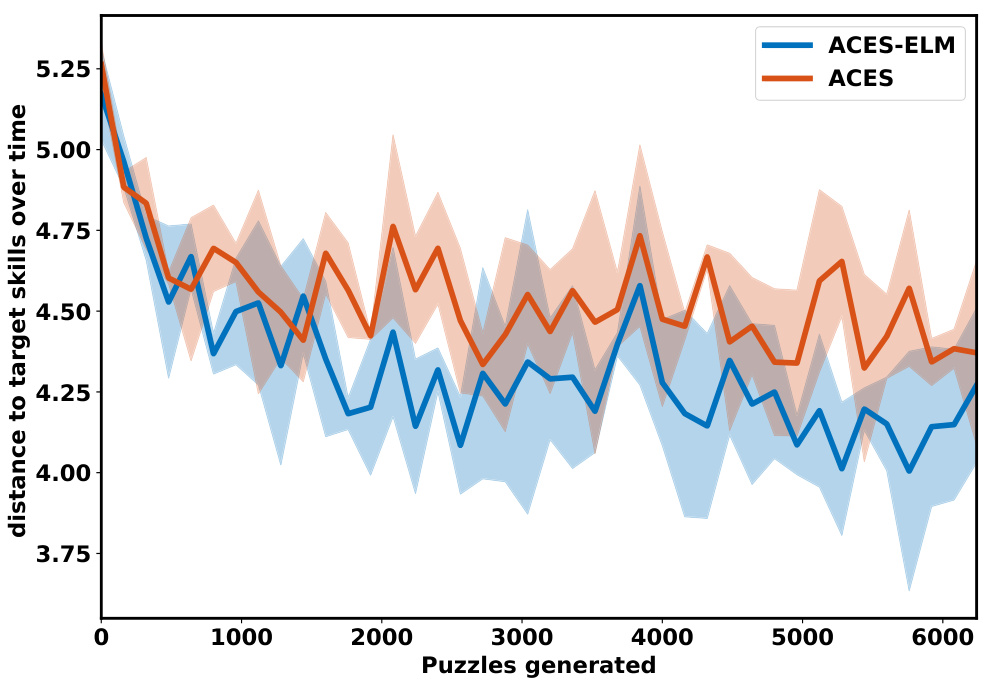
The figure shows the evolution of the distance to target skills over time for two different algorithms: ACES-ELM and ACES. The x-axis represents the number of puzzles generated, and the y-axis represents the distance to the target skills. The shaded area represents the standard deviation. The figure shows that both algorithms are able to reduce the distance to the target skills over time, but ACES-ELM is able to reduce the distance more quickly than ACES. This suggests that ACES-ELM is a more efficient algorithm for generating diverse and challenging programming puzzles.

This figure compares the performance of ACES and several baseline methods across various metrics related to diversity and difficulty of generated programming puzzles. The top row shows different measures of diversity: semantic diversity (number of unique skill combinations), and embedding diversity (using two different embedding models). The bottom row shows metrics related to difficulty: average fitness (a measure of difficulty inversely related to success rate), Quality Diversity score (a combined measure of diversity and difficulty), and distributions of fitness scores. The results indicate that ACES consistently outperforms baseline methods in both diversity and difficulty.
Full paper#



















