↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Existing image relighting methods often rely on inverse graphics techniques and physical models, which struggle with complex real-world scenes and error propagation. These models typically require explicit supervision, like ground truth geometry and albedo information. Furthermore, inferring accurate scene properties and lighting conditions remains challenging.
This paper proposes a novel data-driven approach that learns latent representations of intrinsic (scene properties) and extrinsic (lighting) features. The model is trained on paired images and does not require explicit supervision. Importantly, the latent intrinsic representation behaves like an albedo, which is recovered without separate albedo training. The proposed method demonstrated state-of-the-art accuracy and generalization capabilities, showcasing superior performance compared to existing techniques. This approach eliminates the need for complex physical models, detailed surface representations, and prior knowledge of albedo.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and image processing as it introduces a novel data-driven approach to image relighting. It addresses limitations of existing methods by learning latent intrinsic and extrinsic scene properties, thereby improving accuracy and generalization. The emergence of albedo-like estimates from latent variables opens exciting avenues for intrinsic image research and applications.
Visual Insights#

This figure demonstrates the relighting capabilities of the proposed model. The top row shows the input image, the reference image (with different lighting), and the relighted image generated by the model. The bottom row displays the albedo (surface color) estimated by the model. The figure highlights the model’s ability to accurately relight real-world scenes without relying on a physical model of scene properties or light interactions.
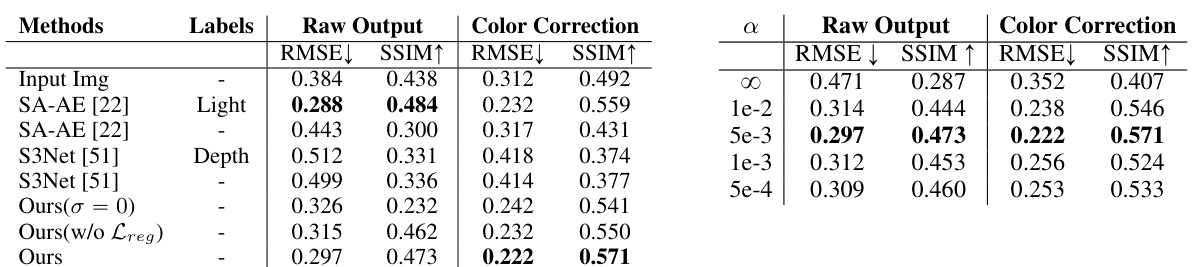
This table presents a quantitative comparison of the proposed relighting method against several state-of-the-art methods. The comparison is based on the multi-illumination dataset [38] and uses RMSE and SSIM metrics to evaluate the quality of raw output and color-corrected relighting results. The results demonstrate that the proposed method significantly outperforms other unsupervised approaches and achieves competitive performance compared to a supervised method. The impact of model warm-up is also analyzed.
In-depth insights#
Latent Intrinsic Models#
Latent intrinsic models represent a powerful paradigm shift in computer vision, particularly within image-relighting tasks. Instead of relying on explicit 3D geometry or complex physical models of surface reflectance, these models leverage the power of deep learning to infer latent representations of scene intrinsics (e.g., albedo) and lighting conditions. This data-driven approach offers several advantages: it bypasses the challenges of accurate geometric reconstruction and material parameter estimation inherent in inverse graphics, significantly improving accuracy and generalizability, especially for complex real-world scenes. By learning disentangled representations of scene properties, latent intrinsic models achieve superior performance in image relighting tasks, as demonstrated by state-of-the-art results. Furthermore, the emergence of meaningful attributes such as albedo directly from the latent space, without explicit supervision, showcases the model’s capacity to capture fundamental scene characteristics. However, limitations exist, notably the reliance on paired training data and potential difficulties in generalization to unseen lighting conditions or scene types. Future work could focus on self-supervised training techniques to mitigate data requirements and the exploration of novel architectures that can effectively handle complex interactions between light and matter. The success of latent intrinsic models highlights the significant potential of deep learning to tackle inverse problems, offering a more robust and generalizable approach compared to traditional physics-based methods.
Data-Driven Relighting#
Data-driven relighting offers a compelling alternative to traditional physics-based methods by leveraging the power of machine learning. Instead of relying on explicit geometric and physical models, it learns complex scene interactions directly from data. This approach leads to several key advantages: robustness to real-world complexities, reduced reliance on precise geometric modeling, and improved generalization to unseen scenes. The use of latent variables for representing intrinsic scene properties (like albedo) and lighting conditions simplifies the learning process and allows for flexible manipulation of light in a post-processing stage. However, challenges remain. The reliance on large, paired datasets can be limiting in terms of scalability and data acquisition. Moreover, the lack of explicit physical model may lead to difficulties in interpreting the model’s outputs and controlling specific lighting effects. Careful attention to data quality and model training is crucial to ensure robustness and accuracy. Future work should focus on addressing these challenges, perhaps through semi-supervised or unsupervised learning techniques, to unlock the full potential of data-driven relighting in diverse applications.
Emergent Albedo#
The concept of “Emergent Albedo” in this context signifies the remarkable phenomenon where a model trained solely for image relighting implicitly learns to extract albedo information without any explicit training data or supervision on albedo. This is a significant departure from traditional inverse graphics methods, which typically necessitate explicit modeling of surface properties. The emergence of albedo as a latent variable within the relighting model highlights the model’s capacity to capture intricate scene characteristics in an unsupervised manner. This approach suggests a new paradigm in intrinsic image decomposition; albedo isn’t explicitly targeted but rather arises as a by-product of the network’s learned representation of scene intrinsics, driven purely by the task of accurately relighting images. This emergent property reduces the need for detailed geometric and surface models, significantly simplifying the learning process and improving generalization. The model implicitly learns to disentangle lighting and surface reflectance from a single input image, demonstrating the power of data-driven approaches to discover complex relationships inherent in visual data. Furthermore, the quality of the extracted albedo, which is competitive with state-of-the-art methods, underscores the efficacy and potential of this emergent property for various image processing applications.
Relighting Generalization#
Relighting generalization, in the context of image processing, refers to a model’s ability to accurately relight unseen scenes or images beyond those in its training data. A high degree of relighting generalization suggests robustness and adaptability of the model, capable of handling variations in scene geometry, surface properties, and lighting conditions not explicitly encountered during training. Data-driven approaches to relighting, which learn latent intrinsic and extrinsic representations, often demonstrate superior generalization compared to physics-based models due to their implicit capture of complex scene interactions. Evaluation metrics such as RMSE and SSIM on held-out datasets are crucial for assessing the generalization performance of a relighting model. Factors like the diversity and size of training data significantly influence generalization capabilities. Furthermore, addressing issues of color constancy and managing error propagation is critical for achieving realistic and high-quality relighted images, which is essential for validating true relighting generalization.
Future Work#
The ‘Future Work’ section of this research paper presents exciting avenues for extending the current data-driven relighting model. Addressing the limitation of requiring paired images is crucial; exploring unsupervised or weakly supervised methods would significantly broaden the model’s applicability. Investigating the extraction of explicit intrinsic information (depth, normals, etc.) from the latent representations is another key area. This would make the model more useful for applications needing detailed geometric information. Developing a more robust framework for handling saturated pixel values in LDR images is also important for improving the model’s real-world performance. Finally, exploring how to extend the model’s success on diverse scenes, especially outdoor environments, while maintaining efficiency, would be a valuable contribution. Achieving these goals would make the model even more powerful and versatile.
More visual insights#
More on figures
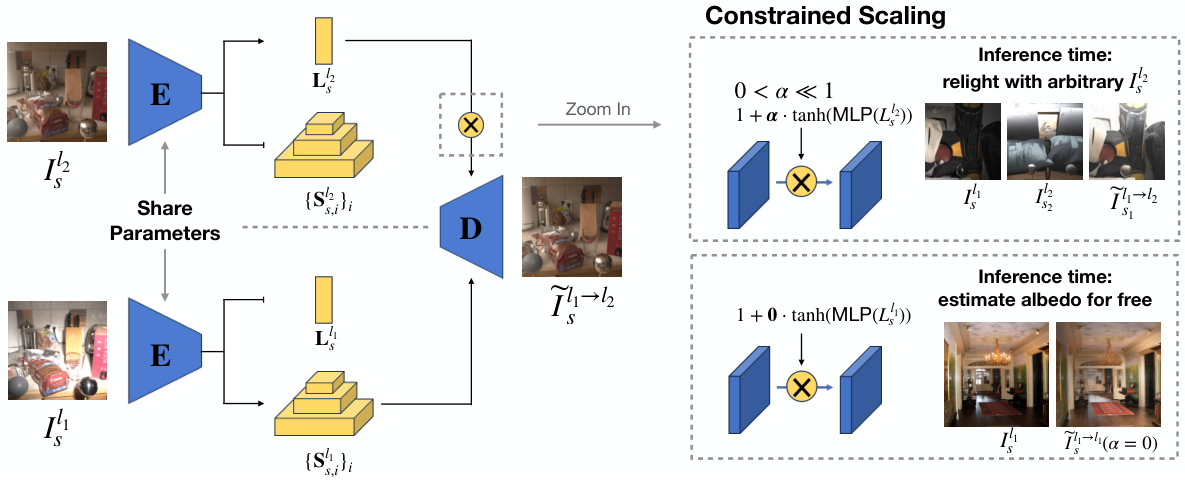
This figure illustrates the architecture of the proposed relighting model, which is an autoencoder. The left half shows how the encoder processes input images to extract both low-dimensional extrinsic (lighting) and intrinsic (scene) features. The right half demonstrates the decoder’s function, particularly the constrained scaling technique that limits the influence of extrinsic features, allowing for both relighting and albedo estimation during inference.

This figure compares the results of the proposed relighting model with other state-of-the-art methods. It shows that the proposed model is superior in accurately rendering scenes under different lighting conditions, especially when using unpaired reference images. A close-up view of a chrome ball highlights the model’s ability to accurately preserve fine details and specular reflections.

This figure demonstrates the ability of the model to smoothly interpolate between different lighting conditions. The leftmost and rightmost images are from the multi-illumination dataset, representing real-world scenes under different lighting. The intermediate images are generated by linearly interpolating the latent extrinsic representations (which capture the lighting information) and then decoding the result. The visualization showcases the model’s ability to generate realistic and continuous changes in lighting.

This figure compares the performance of the proposed method against other state-of-the-art relighting methods. It showcases the superior quality of relighted images produced by the proposed model, particularly highlighting its ability to accurately render scenes with intricate details like reflections on a chrome ball and maintain overall scene consistency. The right half zooms in on these details for a closer comparison.

This figure shows a comparison of the proposed relighting model against other state-of-the-art methods. The top row shows input images, reference images, and results from the proposed method and other methods. The bottom row focuses on a detailed comparison, zooming in on the specular highlights of a chrome ball to illustrate the model’s superior accuracy in detail preservation. The caption highlights the strengths of the proposed method over existing techniques and points out the weaknesses of the compared models.

This figure compares the albedo estimations from the proposed model and a supervised method (Intrinsic Diffusion) on the IIW dataset. The proposed method effectively removes lighting effects and produces color-consistent results, while the supervised method shows color drift due to domain shift. Naive flattening is also compared, which shows its ineffectiveness in reducing lighting effects.

This figure compares the performance of the proposed relighting model against other state-of-the-art methods. It shows examples of relighting results on various scenes with different lighting conditions. The results highlight the superior performance of the proposed model in accurately estimating and rendering lighting and scene details, even when using unpaired reference images. A close-up of a chrome ball in one of the scenes demonstrates the superior detail preservation capability of the method.

This figure compares the image relighting results of the proposed method with other state-of-the-art methods. It shows that the proposed method produces more accurate and realistic relighted images, especially when dealing with complex scenes and unpaired reference images. The close-up of the chrome ball highlights the superior detail preservation achieved by the proposed method.
Full paper#



















