↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
The rise of pretrained-finetuned models leads to a massive number of model weights, posing challenges in storage and deployment. Existing model merging methods struggle with performance degradation or require additional tuning. This is because merging models into a single model may not simulate all the models’ performance.
EMR-MERGING, a novel method, tackles this by first selecting a unified model from all model weights and then creating extremely lightweight task-specific “modulators” (masks and rescalers). These modulators align the direction and magnitude of the unified model with individual task models. This approach is completely tuning-free, requires no extra data or training, and achieves excellent performance across various vision, NLP, and multi-modal models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, tuning-free approach to model merging, a critical area in tackling the challenges of high storage and deployment costs associated with numerous model weights. EMR-MERGING offers significant performance improvements over existing methods without requiring additional data or training, paving the way for more efficient and practical multi-task learning.
Visual Insights#
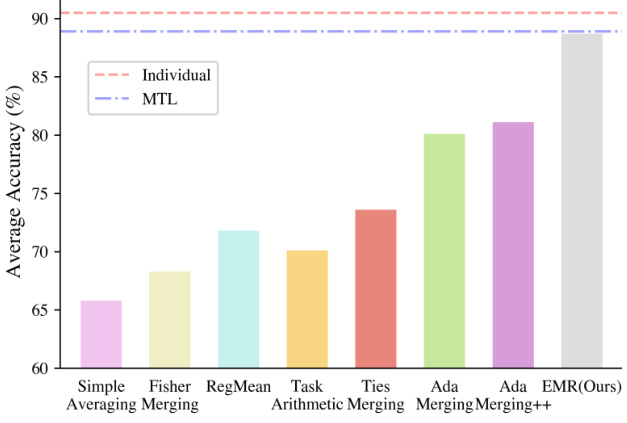
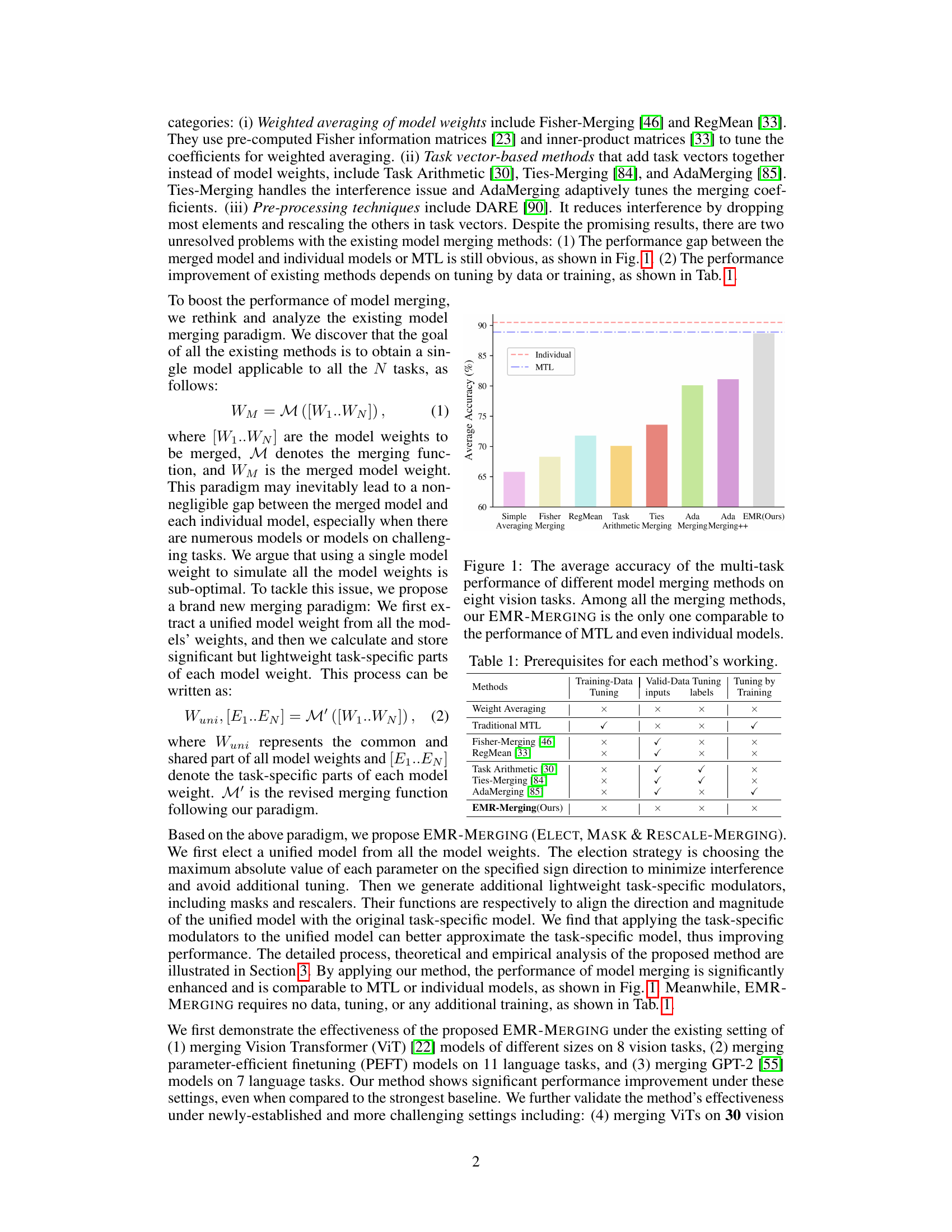
This figure compares the average accuracy across eight vision tasks for various model merging methods. The methods are compared against a traditional multi-task learning (MTL) approach and the performance of individual models trained separately for each task. The figure shows that EMR-MERGING achieves accuracy comparable to both MTL and individual models, significantly outperforming other merging techniques.
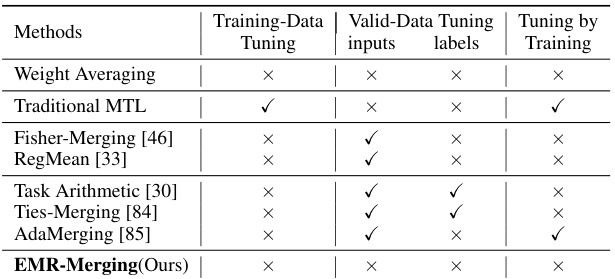
This table summarizes the data and training requirements for various model merging methods. It indicates whether each method requires training data, validation data, tuning of input labels, or tuning through additional training to achieve its results. The table highlights the tuning-free nature of the proposed EMR-Merging method.
In-depth insights#
Model Merging Rethought#
The heading ‘Model Merging Rethought’ suggests a critical re-evaluation of existing model merging techniques. It implies a move beyond simple averaging or weighted averaging of model parameters, acknowledging the limitations of these approaches. The authors likely delve into the underlying principles of model merging, exploring why existing methods often fail to achieve optimal performance, particularly when dealing with multiple models or diverse tasks. This rethinking could involve a novel paradigm, perhaps focusing on identifying shared and task-specific components within the models, rather than treating them as monolithic entities. The approach may emphasize reducing interference between models through techniques like selective merging or task-specific modulators. Ultimately, the aim would be to develop a more effective and efficient approach to model merging that consistently yields significant performance gains, overcoming the challenges of existing methods.
EMR-Merging: A New Paradigm#
The proposed EMR-Merging introduces a novel paradigm shift in model merging by addressing limitations of existing methods. Instead of aiming for a single, unified model, EMR-Merging strategically elects a unified model and supplements it with lightweight task-specific modulators (masks and rescalers). This approach elegantly tackles the challenge of simulating diverse model behaviors with a single representation. The tuning-free nature, eliminating the need for additional data or training, is a significant advantage. By focusing on aligning the direction and magnitude between the unified model and individual models, EMR-Merging achieves high performance across various tasks and model types without relying on computationally expensive techniques or substantial data requirements. This paradigm change represents a potentially significant advancement in model merging, offering a simpler, more efficient, and versatile approach to multi-task learning.
Task-Specific Modulators#
The concept of “Task-Specific Modulators” in the context of model merging is crucial for achieving high performance without fine-tuning. These modulators act as lightweight adapters, dynamically adjusting a unified model’s behavior to match the characteristics of individual task-specific models. Instead of training a separate model for each task, which is computationally expensive, the approach leverages a shared, unified model and task-specific modulators. The design of these modulators is key: they must be sufficiently flexible to capture the unique aspects of each task while remaining lightweight. This design often involves using mechanisms like masks, which selectively activate or deactivate certain parts of the unified model, and rescalers, which adjust the magnitude of parameters. The effectiveness of these modulators hinges on their ability to selectively adapt the unified model to the specific demands of each task without requiring substantial additional training or data, thereby improving efficiency and performance significantly.
Broader Experimentation#
A broader experimentation section in a research paper would significantly enhance its impact by exploring the generalizability and robustness of the proposed method. It should delve into various scenarios beyond the core experiments, testing the model’s performance under diverse conditions and datasets. This could include investigating different model architectures, varying the scale of experiments (number of models merged, dataset size), and testing the method’s resilience to noisy data or adversarial attacks. The section should also consider the computational cost and resource requirements for broader applicability, evaluating efficiency and scalability across different hardware and software platforms. Crucially, this expanded experimentation should address potential limitations and biases revealed in the core experiments, exploring and documenting their impact on the model’s performance. The findings from broader experimentation would paint a more holistic and reliable picture of the method’s capabilities and limitations, leading to more robust conclusions and increased confidence in its overall value.
Limitations and Future#
The EMR-MERGING model, while demonstrating strong performance and a tuning-free approach, has limitations. Memory requirements increase slightly compared to existing methods due to the addition of task-specific modulators. Generalizability is restricted; it’s primarily applicable to models trained via a pretrain-finetune paradigm, not models trained from scratch. The effectiveness in handling a massive number of models, particularly with diverse architectures, needs further investigation. Future work should focus on improving memory efficiency, possibly through compression techniques for modulators, and enhancing generalizability to encompass various model training methodologies. Exploring different modulator designs to minimize memory footprint is also crucial. Ultimately, addressing scalability for increasingly complex multi-modal and multi-task scenarios would broaden applicability and impact. Addressing the inherent bias in the datasets utilized for evaluation is also a crucial future consideration.
More visual insights#
More on figures
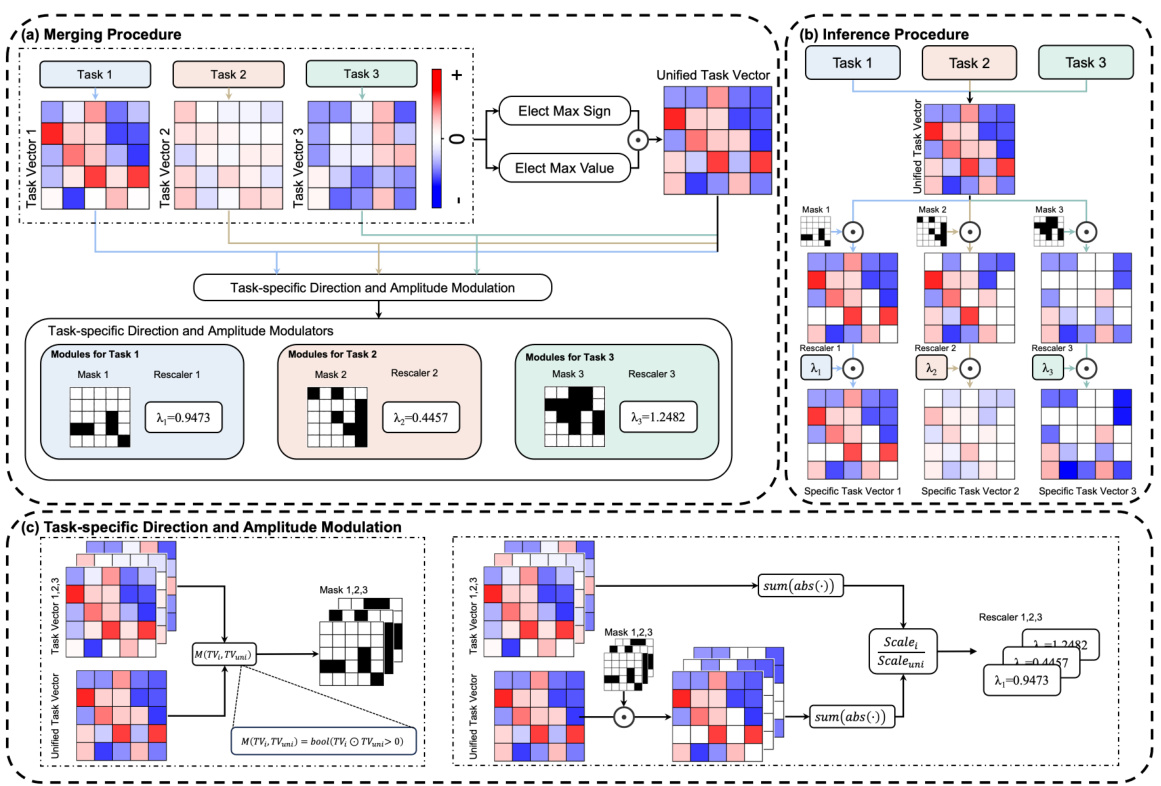
This figure illustrates the framework of EMR-MERGING, a model merging method. Panel (a) shows the merging procedure, where task-specific vectors are combined into a unified task vector. Lightweight task-specific modulators (masks and rescalers) are then generated to adjust the direction and magnitude of the unified vector. Panel (b) details the inference procedure, where a task-specific vector is obtained by applying the appropriate mask and rescaler to the unified task vector. Finally, panel (c) explains how the task-specific direction and amplitude are modulated, illustrating the generation of the task-specific masks and scalers.
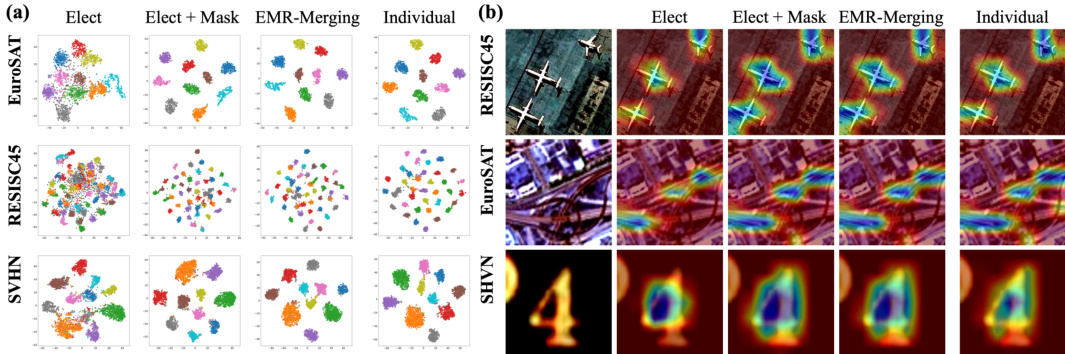
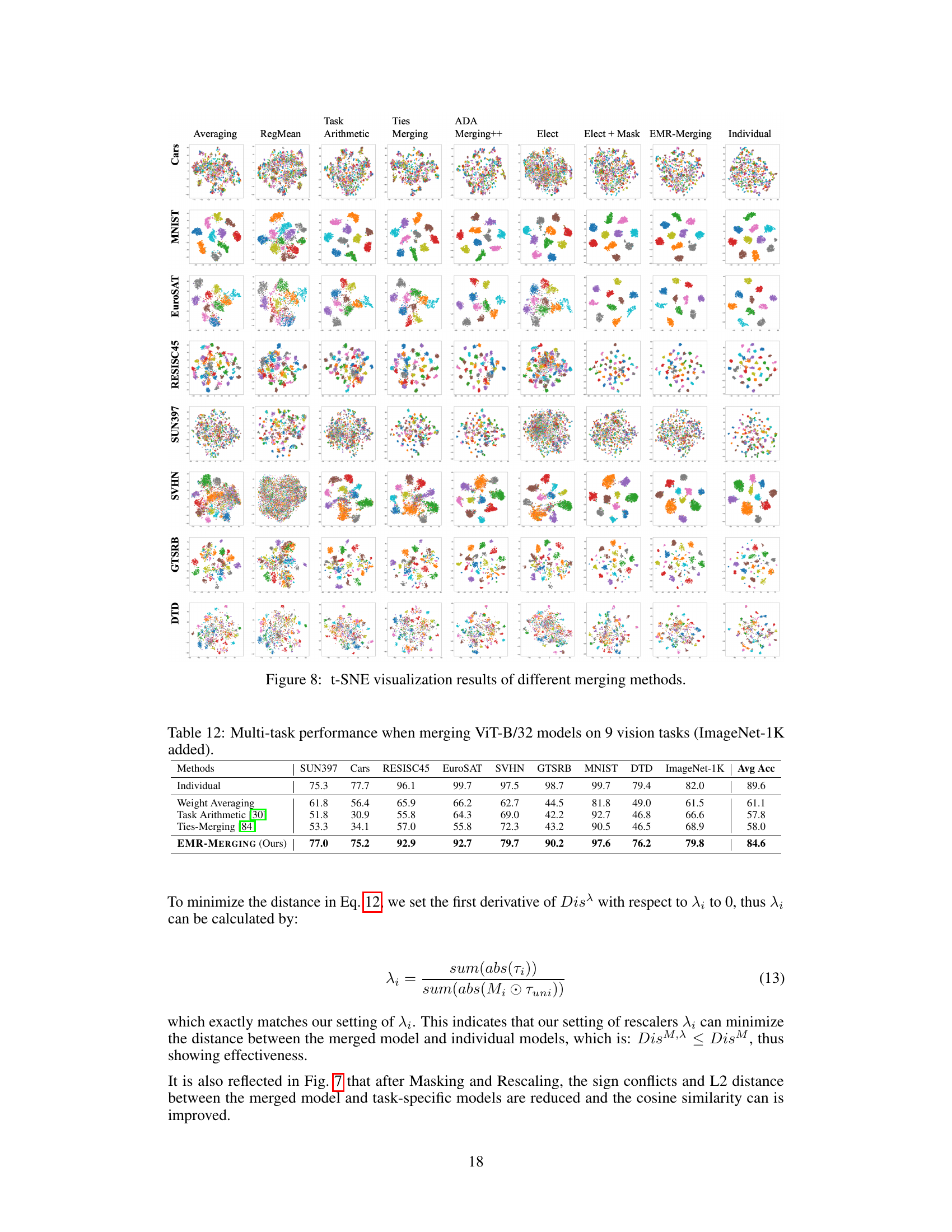
This figure shows the visualization results using t-SNE and Grad-CAM to analyze the effectiveness of each step in the EMR-MERGING procedure. The t-SNE plots show how the data points cluster together at each stage, illustrating how the merged model representations progressively become more similar to the individual model representations. The Grad-CAM heatmaps visualize the regions of the images that contribute most to each model’s prediction, highlighting how the focus of the model shifts as the EMR-MERGING process proceeds. The visualization results visually demonstrate that the EMR-MERGING method effectively approximates the performance of individual models.
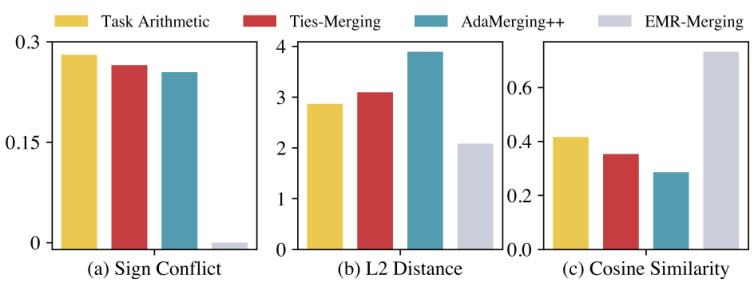
This figure compares the performance of different model merging methods, including AdaMerging++ and the three steps of EMR-MERGING (ELECT, MASK, and RESCALE). The comparison is made across three metrics: sign conflict, L2 distance, and cosine similarity. Each bar represents the average value of the metric calculated between the merged model weights and the weights of individual task-specific models. The results visually demonstrate that EMR-MERGING effectively reduces sign conflicts and L2 distance, while improving cosine similarity compared to existing methods. Appendix F provides more details on the experimental setup and configurations used to generate this figure.
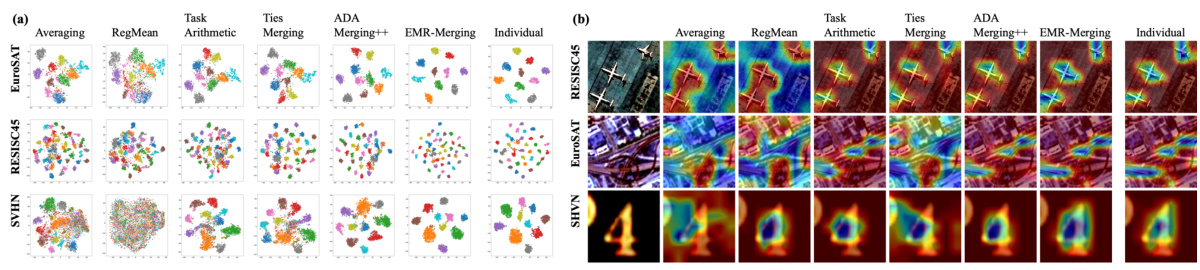
This figure visualizes the results of different model merging methods using t-SNE and Grad-CAM on two image classification tasks (EuroSAT and RESISC45). The t-SNE plots (a) show the clustering of data points in a 2D space, illustrating how well the different merging methods separate the data points for different classes. The Grad-CAM visualizations (b) demonstrate the regions of the input image that are most important for classification for different models and classes. The figure visually compares the performance of several methods, including the proposed EMR-MERGING method. The intention is to show the effectiveness of EMR-MERGING in approximating the performance of individual models compared to other techniques.
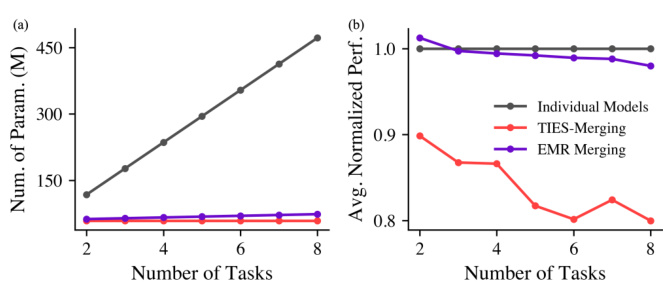
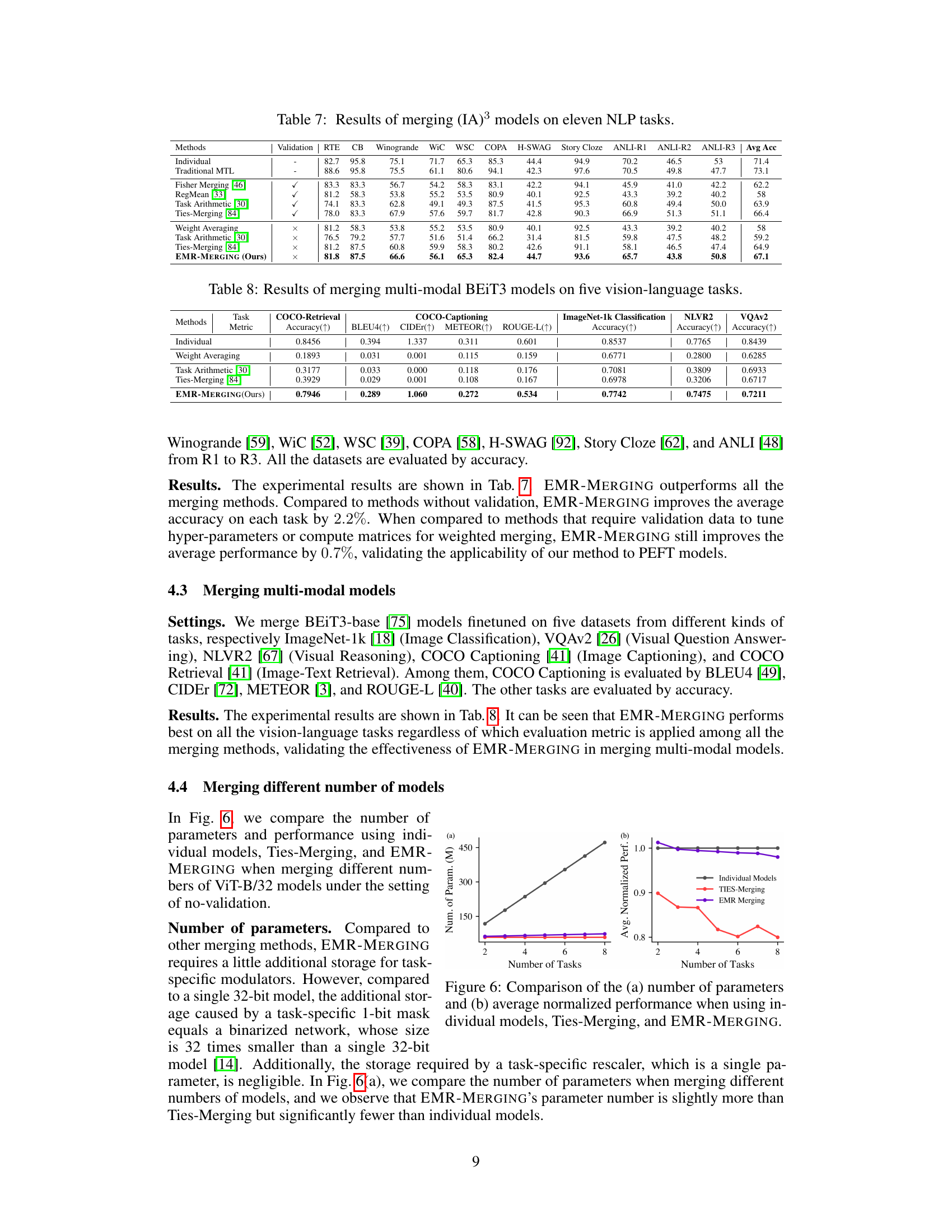
This figure compares the number of parameters and the average normalized performance of three different model merging methods (individual models, Ties-Merging, and EMR-Merging) across a varying number of tasks. The plot on the left shows that the number of parameters for individual models scales linearly with the number of tasks, while the parameter counts for Ties-Merging and EMR-Merging remain relatively constant. The plot on the right shows that the average normalized performance of individual models stays relatively high and constant across all task counts. Conversely, Ties-Merging shows significantly decreasing average performance with an increasing number of tasks, whereas EMR-Merging shows a slight decrease but much better performance compared to Ties-Merging.

This figure illustrates the EMR-MERGING framework, detailing the merging and inference procedures. (a) shows the merging procedure: task-specific vectors are combined into a unified task vector, and then task-specific modulators (masks and rescalers) are generated to adjust the direction and magnitude. (b) depicts the inference process: the unified task vector is modulated by the task-specific modulators to obtain the task-specific vector. (c) provides a detailed explanation of how task-specific direction and amplitude are modulated.
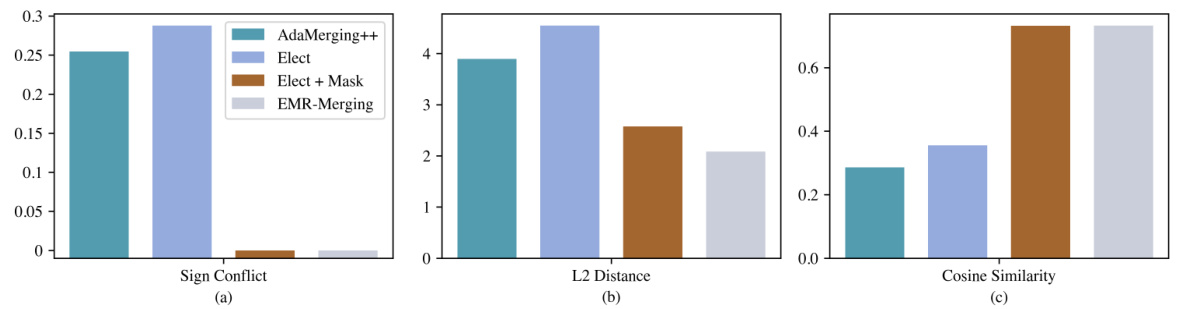
This figure compares three different metrics between merged model weights and task-specific model weights using different model merging methods. The methods compared are AdaMerging++, and the three steps of the proposed EMR-MERGING (ELECT, ELECT+MASK, and EMR-MERGING). The three metrics shown are sign conflicts, L2 distance, and cosine similarity. The figure shows that the EMR-MERGING method significantly reduces sign conflicts and L2 distance while improving cosine similarity, indicating a better alignment with task-specific model weights.
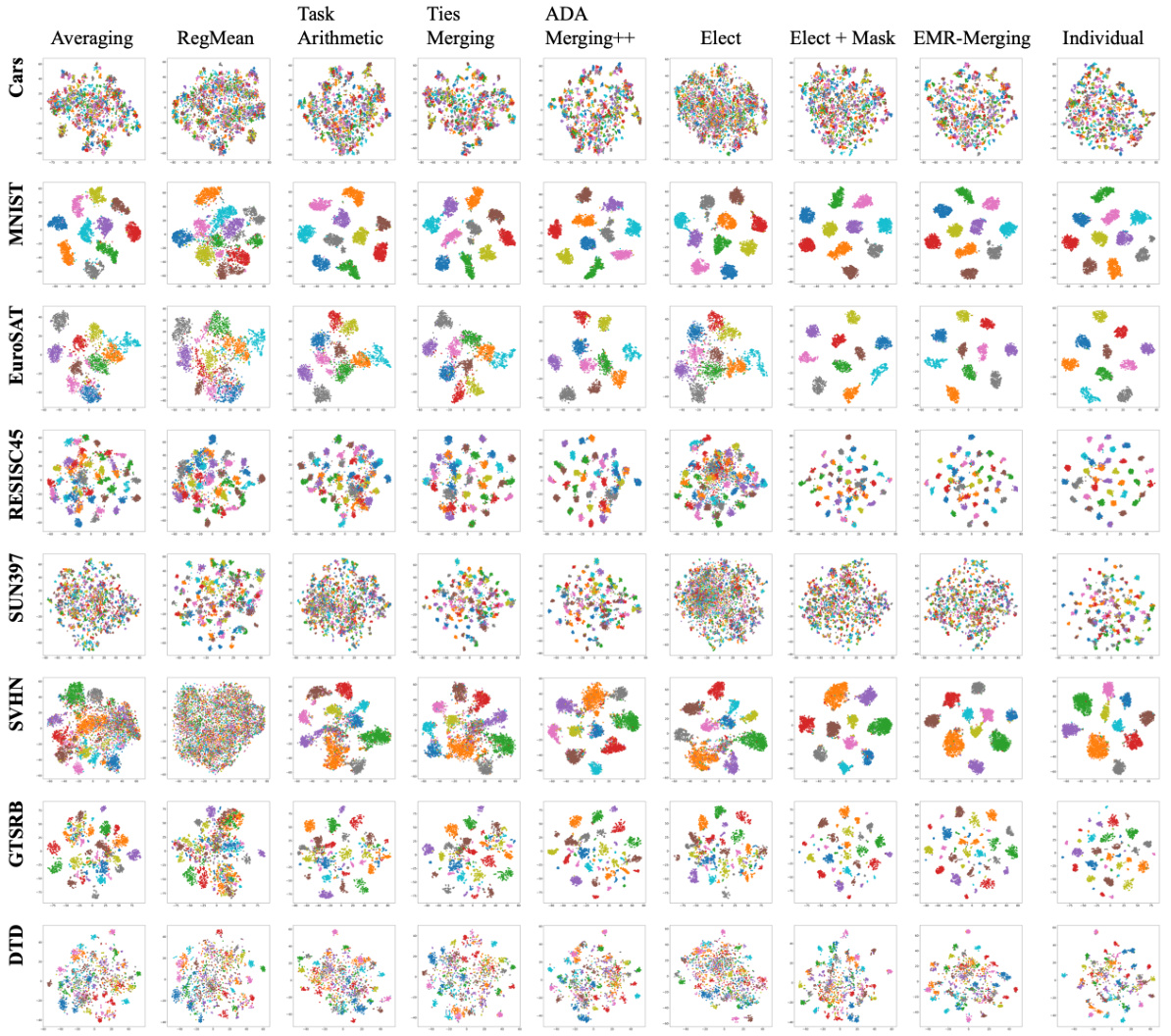
This figure shows the t-SNE visualizations of the different model merging methods applied to eight image classification tasks. Each point represents a data sample, and the colors represent different classes. The figure visualizes how well the different methods are able to merge the feature representations learned by individual models. The visualization helps to understand the similarities and differences in the feature spaces produced by each method. The visualization helps to understand the similarities and differences in the feature spaces produced by each method.
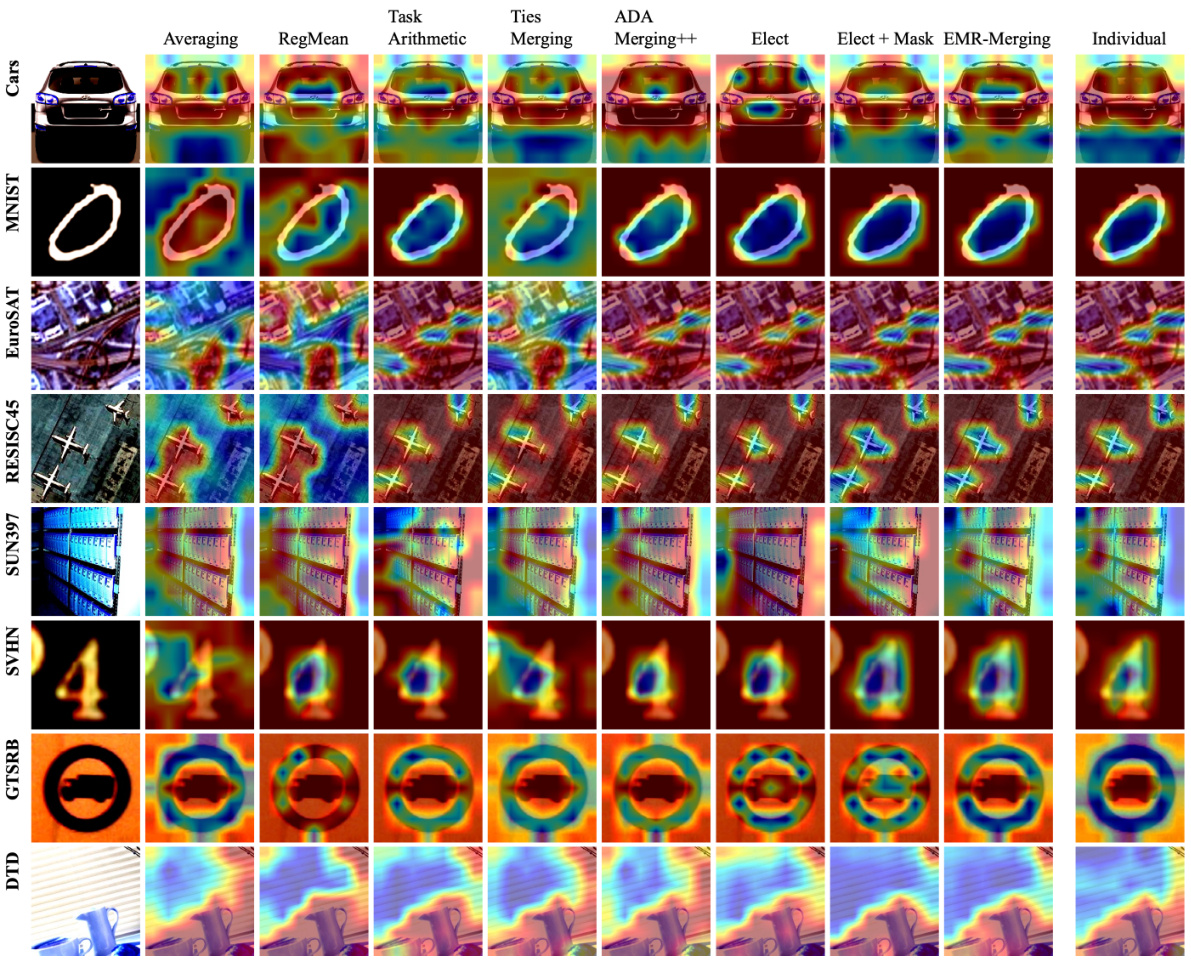
This figure visualizes the results of the EMR-MERGING method using t-SNE and Grad-CAM. t-SNE (t-distributed Stochastic Neighbor Embedding) is a dimensionality reduction technique used to visualize high-dimensional data in a lower-dimensional space (here, 2D). Grad-CAM (Gradient-weighted Class Activation Mapping) is a method to visualize which parts of the image are most important for a given prediction. The figure shows how the different steps in the EMR-MERGING process affect the representation of data points and the activation maps, illustrating the method’s ability to improve the merging of models by approximating task-specific models better. The visualization helps to understand how the method helps the merged model to be closer to each individual model.
More on tables
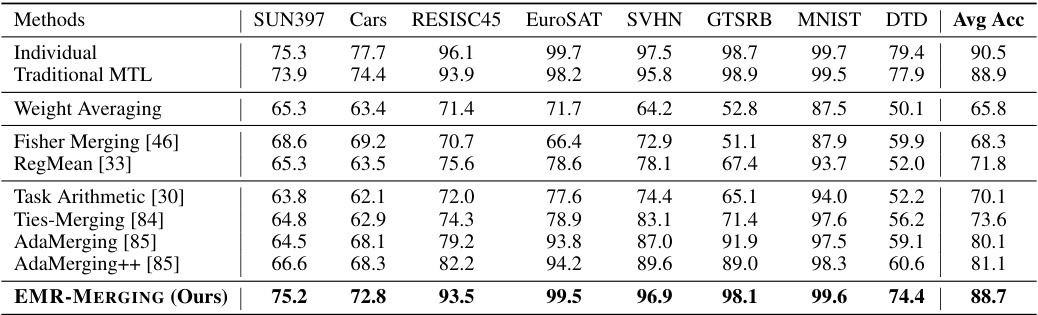
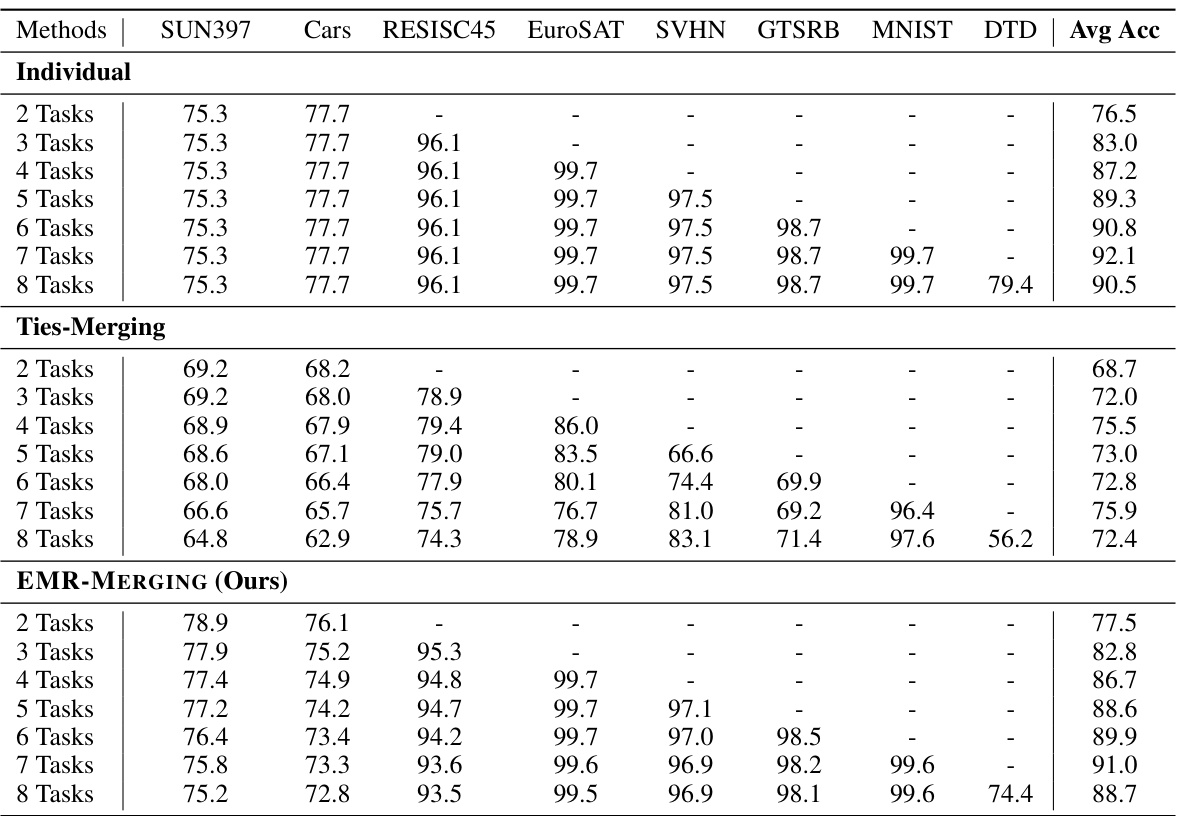
This table presents the multi-task performance results of various model merging methods on eight image classification tasks. The methods compared include Individual models (performance of individual models on each task), Traditional MTL (multi-task learning approach), Weight Averaging, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. The results are shown as average accuracy across the eight tasks (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD). The table demonstrates the superior performance of EMR-MERGING compared to other existing merging methods.
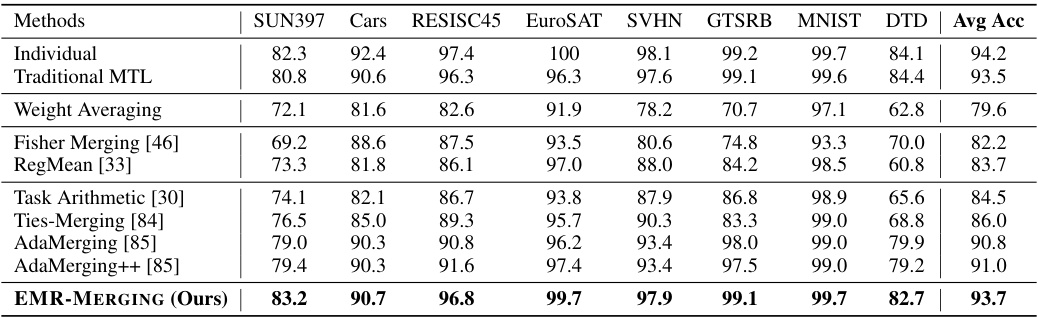
This table presents the multi-task performance results achieved by various model merging methods on eight image classification tasks. The methods compared include traditional MTL (multi-task learning), simple weight averaging, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. The performance of each method is evaluated for each of the eight tasks (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD) and the average accuracy across all eight tasks is reported. This allows for a direct comparison of the effectiveness of different model merging techniques, showing the advantages and disadvantages of each approach in achieving high accuracy in a multi-task setting.
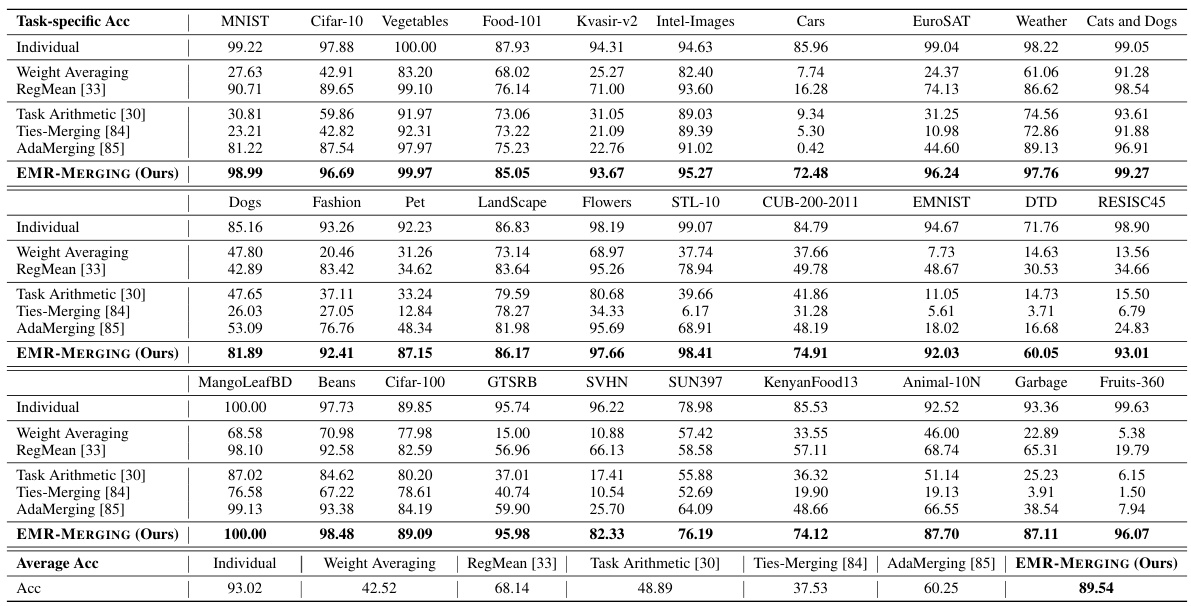
This table presents the task-specific and average performance results when merging 30 ViT-B/16 models on various vision tasks. The table compares the performance of EMR-MERGING against several baseline methods including individual models, weight averaging, RegMean, Task Arithmetic, Ties-Merging, and AdaMerging. The 30 tasks cover diverse image classification challenges such as MNIST, CIFAR-10, and many more specialized image classification tasks. The results are shown as accuracy percentages for each task and the average accuracy across all 30 tasks. This table helps to evaluate the effectiveness of EMR-MERGING in handling a large number of tasks and models.
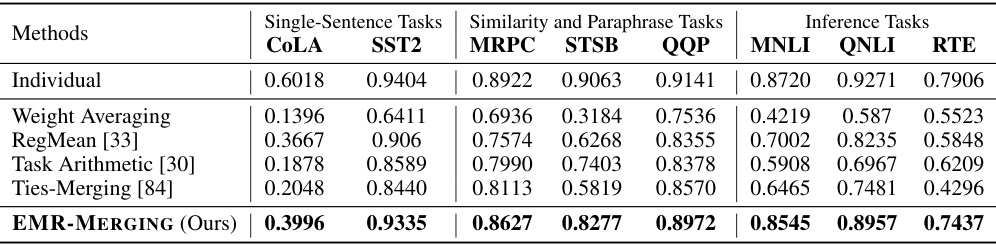
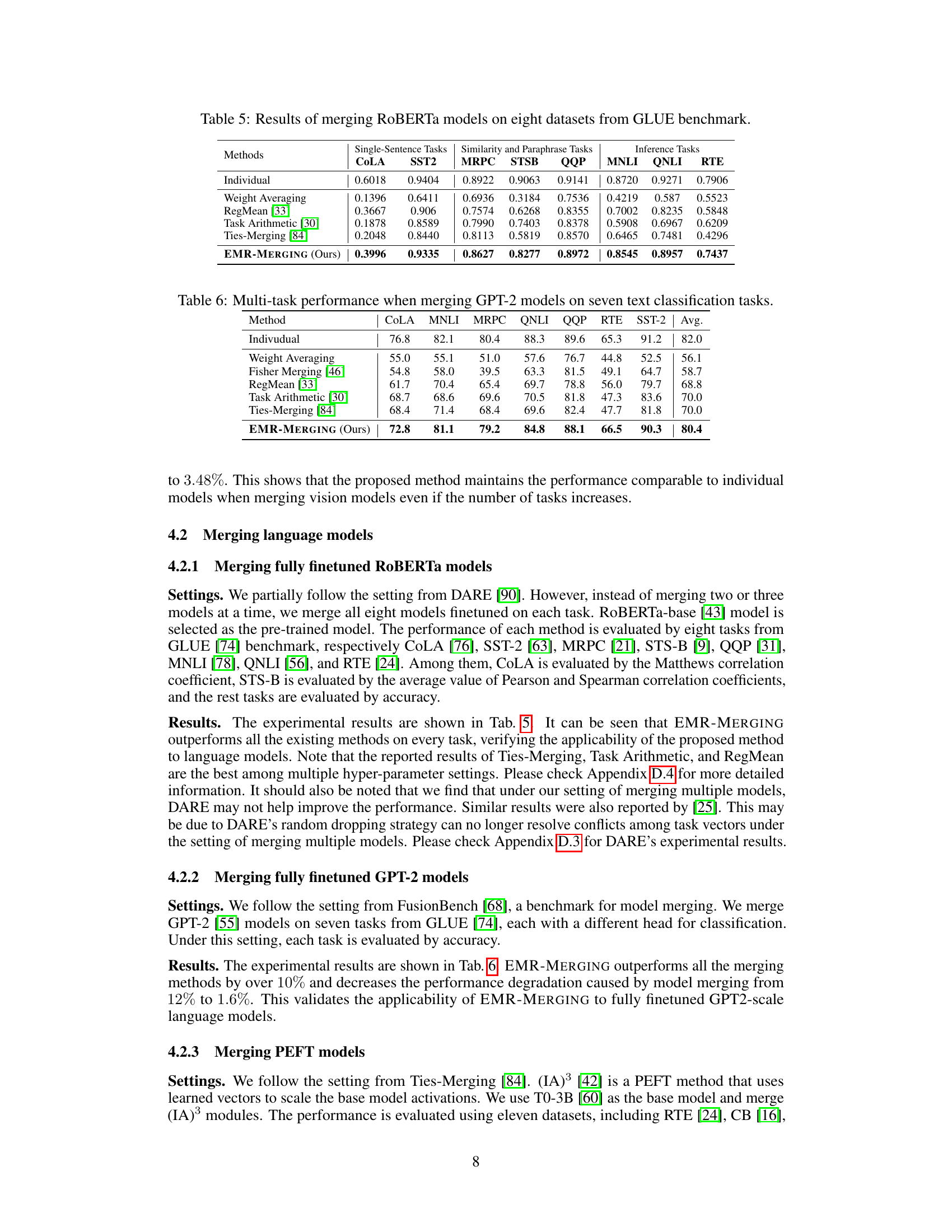
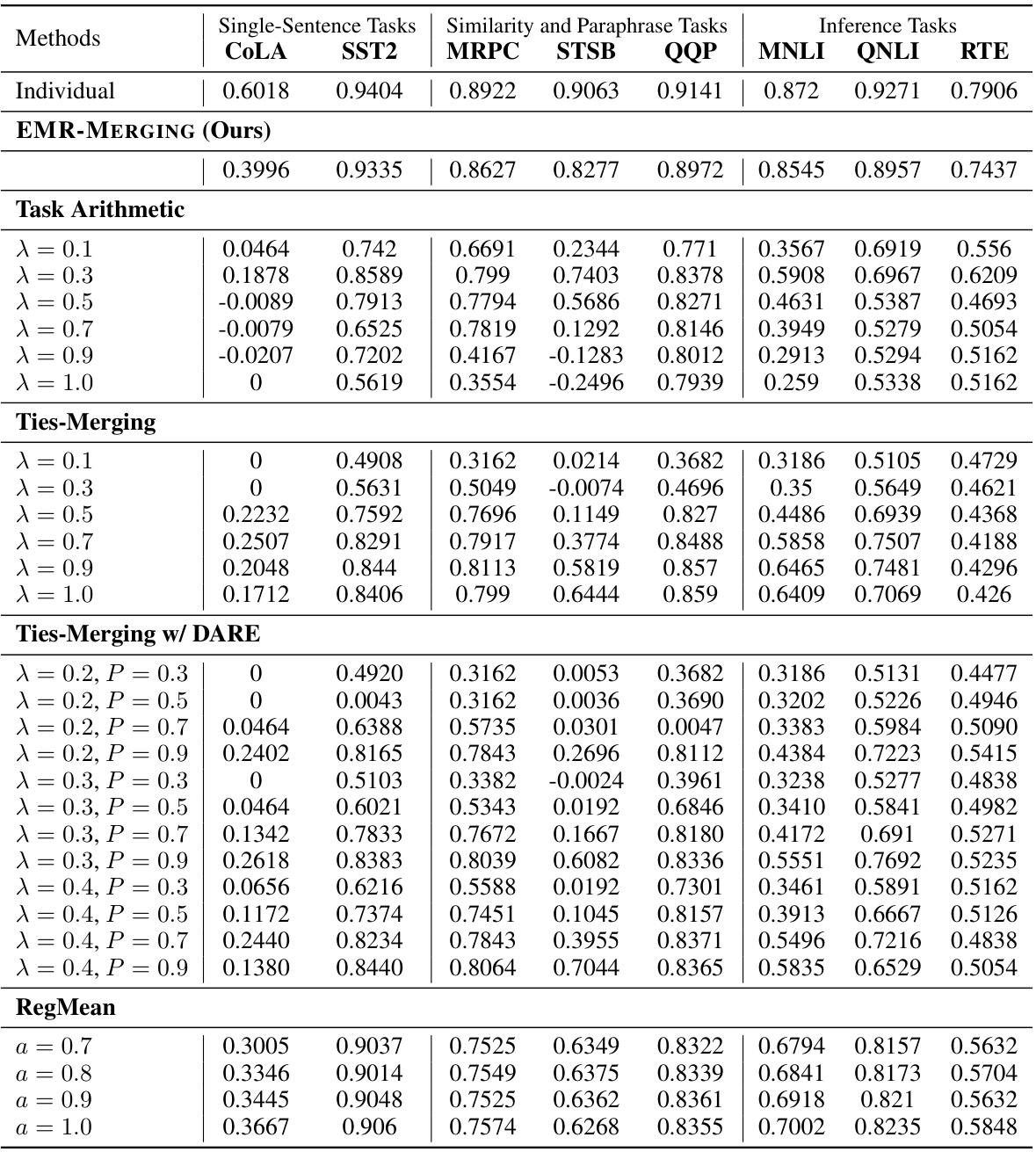
This table presents the multi-task performance results of different model merging methods on eight datasets from the GLUE benchmark. The methods compared include Individual models, Weight Averaging, RegMean [33], Task Arithmetic [30], Ties-Merging [84], and EMR-MERGING (Ours). The table shows the performance of each method on each of the eight GLUE tasks, providing a comprehensive comparison of the effectiveness of different model merging techniques.
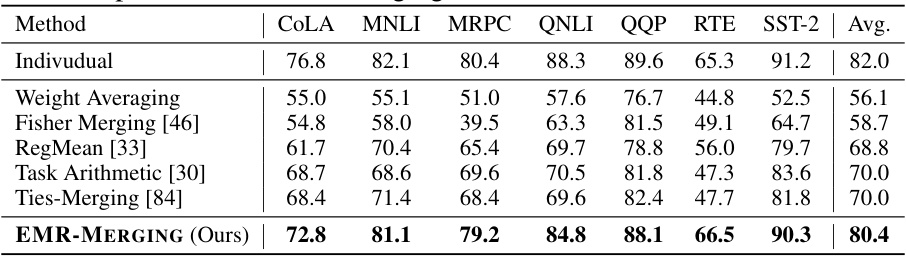
This table presents the multi-task performance results of several model merging methods, including the proposed EMR-MERGING, when applied to seven text classification tasks using GPT-2 models. It compares the average accuracy across the seven tasks for each method, showing the performance of EMR-MERGING against baselines such as Weight Averaging, Fisher Merging, RegMean, Task Arithmetic, and Ties-Merging. The ‘Individual’ row indicates the average performance of individual, task-specific GPT-2 models, serving as an upper bound for comparison.
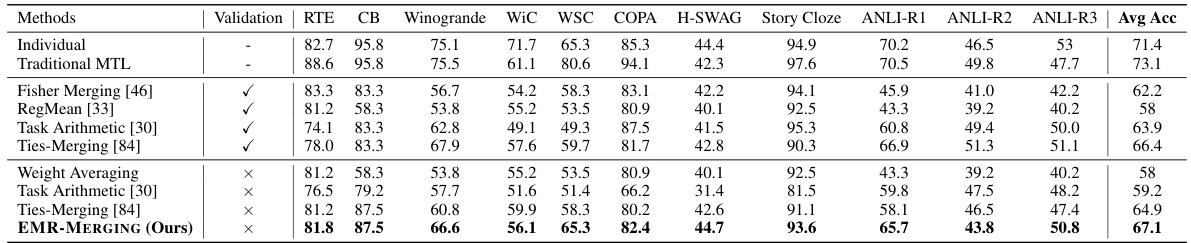
This table presents the results of applying EMR-MERGING and other model merging methods on eleven NLP tasks using (IA)³ models. It compares the average accuracy across these tasks for various methods, including individual model performance, traditional multi-task learning (MTL), and other merging techniques. The table highlights the performance improvement achieved by EMR-MERGING compared to existing methods. The ‘Validation’ column indicates whether a validation set was used for hyperparameter tuning.

This table presents the results of applying EMR-MERGING and other model merging methods on five vision-language tasks using multi-modal BEiT3 models. The tasks are COCO-Retrieval, COCO-Captioning, ImageNet-1k Classification, NLVR2, and VQAv2. Performance is measured using Accuracy, BLEU4, CIDEr, METEOR, and ROUGE-L, depending on the specific task. The table allows comparison of EMR-MERGING against traditional methods like Weight Averaging, Task Arithmetic, and Ties-Merging to demonstrate its effectiveness in multi-modal model merging scenarios.
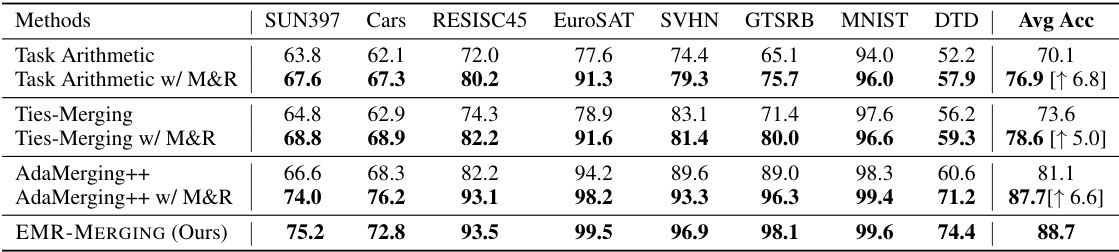
This table presents the multi-task performance results achieved by various model merging methods on eight image classification tasks. The methods compared include Individual models (using a single model per task), Traditional Multi-Task Learning (MTL), Weight Averaging, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. The performance is measured by the average accuracy across the eight tasks. This demonstrates the comparative performance of different merging techniques, highlighting the effectiveness of EMR-MERGING.

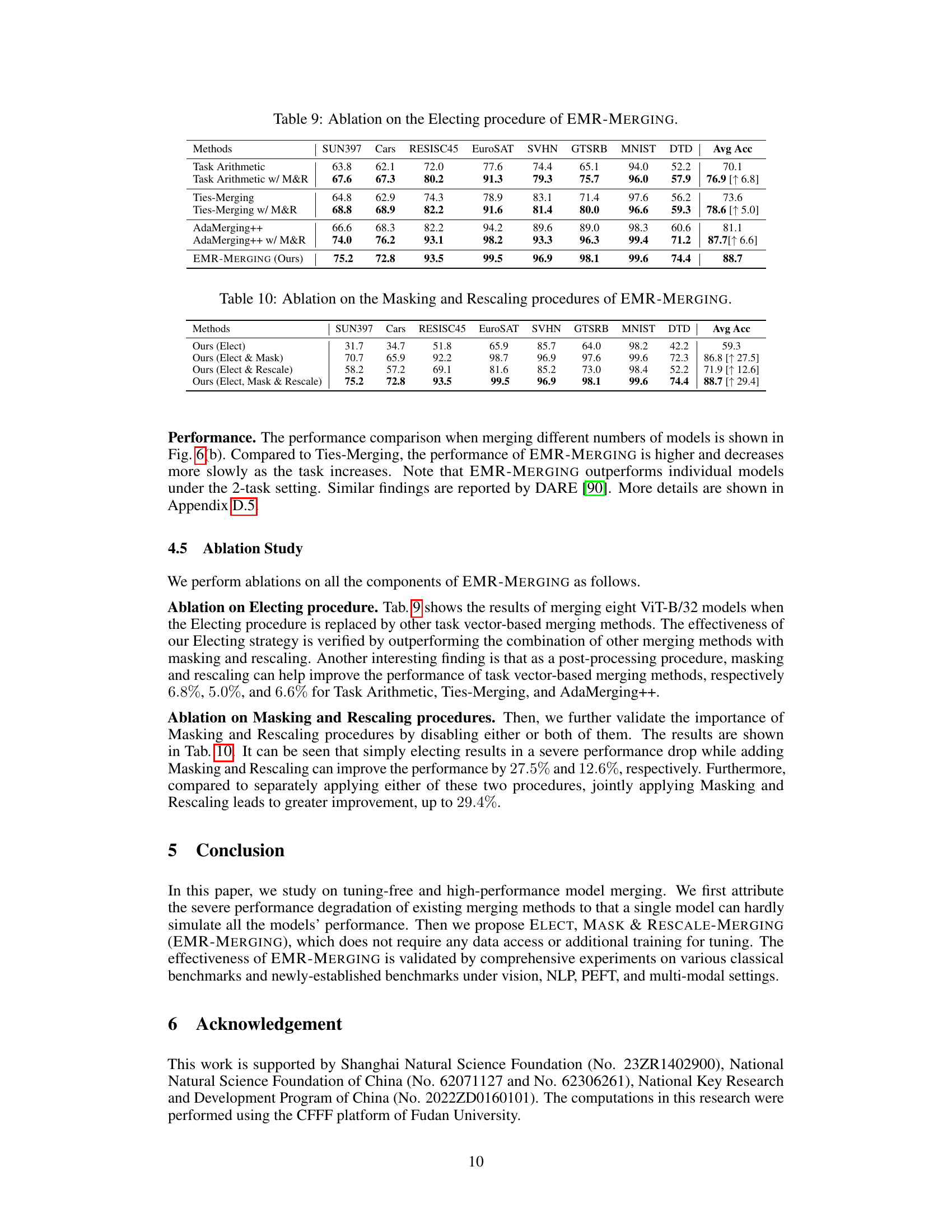
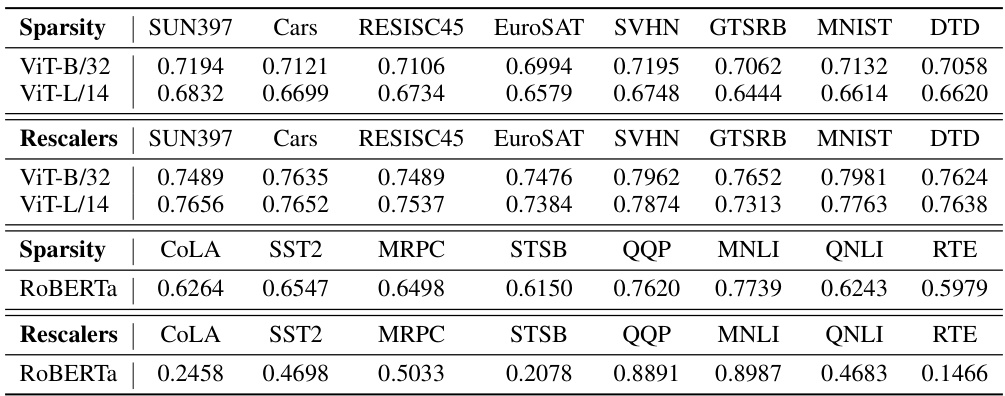
This table presents the ablation study results on the Masking and Rescaling procedures within the EMR-MERGING model. It shows the average accuracy across eight image classification datasets (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD) when only the Electing procedure is used, when Electing and Masking are combined, when Electing and Rescaling are combined, and when all three procedures (Electing, Masking, and Rescaling) are used together. The improvement in average accuracy is shown in brackets for each combination compared to the baseline using only the Electing procedure. This demonstrates the importance of each component in achieving the high performance of EMR-MERGING.

This table presents a comparison of the multi-task performance of different model merging methods on eight image classification tasks. The methods compared include: Individual (using individual models for each task), Traditional MTL (multi-task learning), Weight Averaging, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. The performance is measured by the average accuracy across the eight tasks (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD). This allows for a quantitative assessment of how well each merging method combines multiple models into a single model that performs well across multiple tasks compared to training a single model on all tasks simultaneously (MTL).

This table presents the multi-task performance results of different model merging methods on nine image classification datasets. The methods compared include Individual models (using a single model per task), Weight Averaging, Task Arithmetic [30], Ties-Merging [84], and the proposed EMR-MERGING method. The datasets used are SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD, and ImageNet-1K. The table shows the accuracy achieved by each method on each dataset, along with the average accuracy across all nine datasets. The results demonstrate the superior performance of EMR-MERGING in comparison to the existing methods.
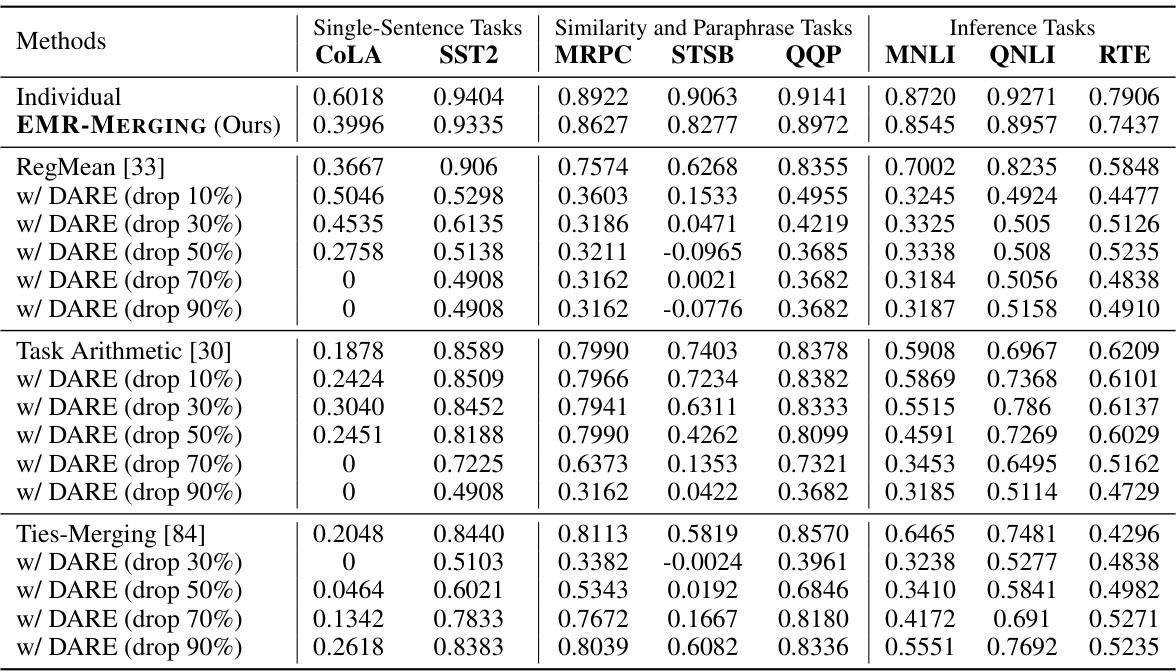
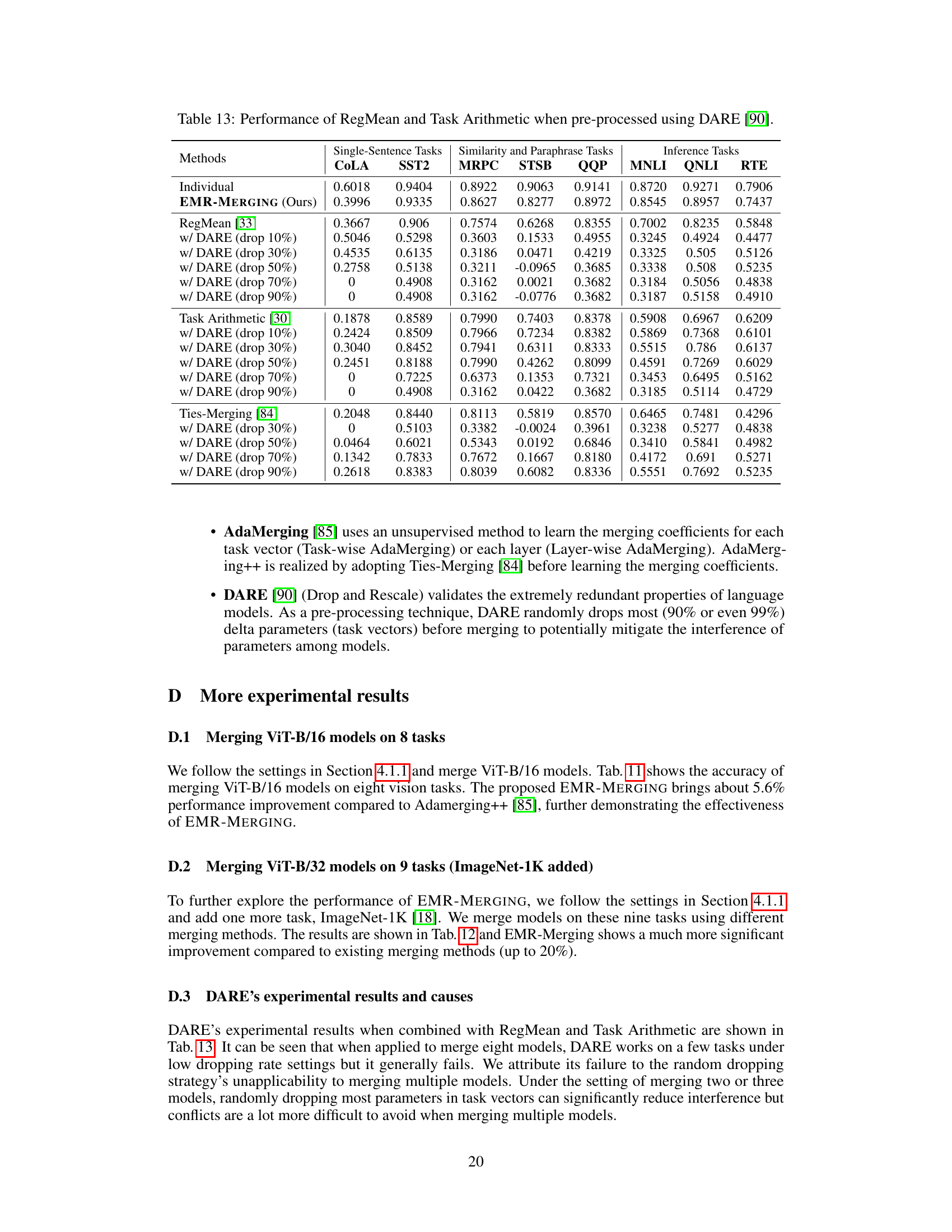
This table presents the performance of RegMean and Task Arithmetic methods on the GLUE benchmark when their input task vectors are pre-processed using the DARE method. DARE is a pre-processing technique that randomly drops a percentage of elements in the task vector before merging, aiming to reduce interference. The table shows how the performance of the two methods changes with varying percentages (10%, 30%, 50%, 70%, 90%) of elements dropped by DARE. The results are compared against the performance of the original RegMean and Task Arithmetic methods without DARE pre-processing and the performance of an individual model for each task (Individual). This table highlights the impact of DARE pre-processing on the performance of these two model merging techniques.
This table presents the multi-task performance results of various model merging methods on eight image classification tasks using Vision Transformer (ViT)-B/32 models. The methods compared include individual models, traditional multi-task learning (MTL), weight averaging, Fisher merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. The performance metric is average accuracy across the eight tasks. The table allows for a comparison of the proposed method against existing techniques and establishes its effectiveness in improving multi-task capabilities without requiring additional tuning or data.
This table presents the multi-task performance results of various model merging methods on eight image classification tasks. The methods compared include individual model performance, traditional multi-task learning (MTL), simple averaging of weights, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and the proposed EMR-MERGING. Each method’s accuracy is reported for each of the eight tasks (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD), along with an average accuracy across all eight tasks. This allows for a comparison of the effectiveness of different model merging techniques in achieving multi-task capabilities.
This table presents the multi-task performance results achieved using various model merging methods on eight image classification tasks. The methods compared include Individual models (performance of each model individually), Traditional MTL (multi-task learning), Weight Averaging, Fisher Merging, RegMean, Task Arithmetic, Ties-Merging, AdaMerging, AdaMerging++, and EMR-MERGING (the proposed method). The performance is measured by average accuracy across the eight tasks (SUN397, Cars, RESISC45, EuroSAT, SVHN, GTSRB, MNIST, DTD). The table demonstrates the relative performance of EMR-MERGING compared to existing state-of-the-art model merging techniques.
Full paper#