↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Deep Neural Networks (DNNs) excel on clean images but struggle with corrupted ones. Existing methods to improve robustness, such as incorporating specific corruptions into data augmentation, can harm performance on clean images and other types of distortions. This creates a challenge for deploying DNNs in real-world applications where perturbed inputs are common.
The paper introduces Data Augmentation via Multiplicative Perturbation (DAMP), a new training method. DAMP enhances model robustness by introducing random multiplicative weight perturbations during training. It shows that input perturbations can be simulated by such weight space perturbations. This method is computationally efficient and improves generalization without sacrificing clean image performance. Experiments on CIFAR-10/100, TinyImageNet, and ImageNet show significant improvements in robustness across different architectures and corruption types. Notably, DAMP trains Vision Transformer (ViT) on ImageNet without extensive data augmentations, achieving comparable results to ResNet50.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on robustness in deep learning models. It introduces a novel training method (DAMP) that significantly improves model generalization and accuracy when facing various image corruptions without extensive data augmentations. The proposed method offers a new avenue for research focusing on enhancing the reliability and effectiveness of DNNs in real-world applications, where models invariably encounter noisy or corrupted inputs.
Visual Insights#
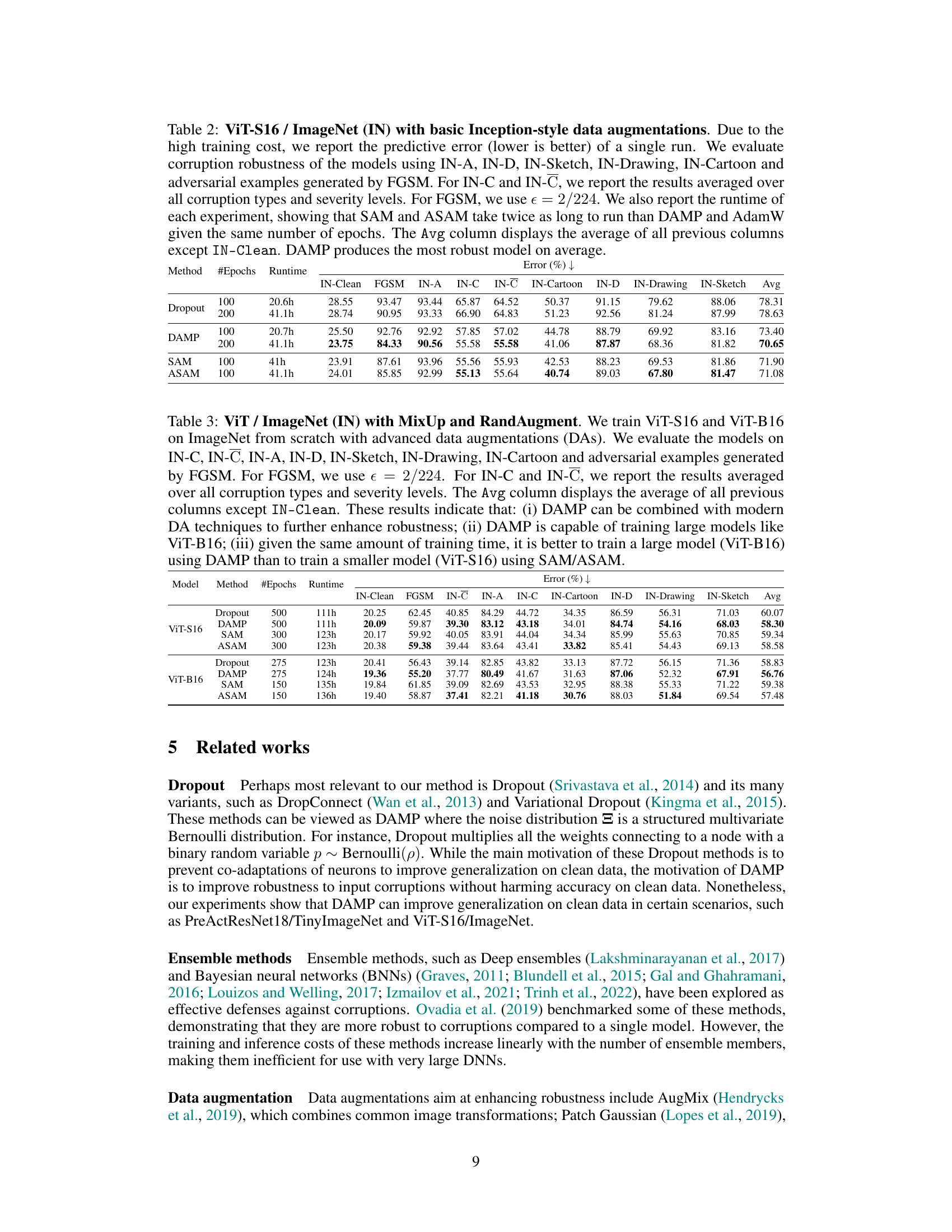
This figure illustrates the equivalence between input corruptions and multiplicative weight perturbations (MWPs). It shows three scenarios: (a) a pre-activation neuron with a covariate shift in the input; (b) the same neuron where the covariate shift is mimicked by an equivalent MWP; (c) the same neuron with random MWPs injected during training to make the DNN robust to covariate shifts. The Hadamard product is used to represent element-wise multiplication.

This table presents the results of the ResNet50 model trained on ImageNet dataset under different methods, including DAMP, Dropout, SAM, and ASAM. The performance is evaluated on clean images and various corrupted versions of ImageNet (IN-C, IN-C, IN-A, IN-D, IN-Sketch, IN-Drawing, IN-Cartoon) and adversarial examples generated by FGSM. Lower error rates indicate better performance.
In-depth insights#
Weight Space Perturbation#
The concept of “Weight Space Perturbation” in the context of improving robustness in deep neural networks (DNNs) is a powerful idea. Instead of directly perturbing input data for augmentation, it focuses on altering the network’s internal parameters (weights) during training. This approach is significant because it addresses the problem of input data corruption in a more fundamental way. By introducing carefully designed noise or perturbations to the weights, the DNN becomes less sensitive to variations in the input. This approach is particularly valuable when dealing with unforeseen or diverse corruptions. Multiplicative weight perturbations, in contrast to additive methods, are especially interesting because they can better model certain types of corruption, like those affecting the magnitude of image features. Furthermore, it is computationally efficient and can be implemented seamlessly into standard training procedures, leading to no significant increase in training time. The connection between such methods and techniques like sharpness-aware minimization highlights the link between weight space regularization and the development of robust DNNs. Thus, the exploration of weight space perturbations provides a promising avenue towards enhancing the generalization ability and robustness of DNNs.
DAMP Training Method#
The Data Augmentation via Multiplicative Perturbation (DAMP) training method offers a novel approach to enhancing the robustness of deep neural networks (DNNs) against various corruptions without sacrificing accuracy on clean images. Instead of directly incorporating corruptions into the training data, DAMP leverages the observation that input perturbations can be mimicked by multiplicative perturbations in the weight space. This insight is key because it shifts the focus from data augmentation to weight-space manipulation during training. By introducing random multiplicative weight perturbations during training, DAMP effectively optimizes the DNN under a distribution of perturbed weights, leading to improved generalization across a broader range of input conditions, including those with corruptions. This is a significant improvement over conventional methods of incorporating corruptions directly into the training data, which can compromise performance on clean images. The computational efficiency of DAMP is comparable to standard stochastic gradient descent (SGD), making it a practical and scalable solution for training robust DNNs. The method’s effectiveness has been demonstrated through experiments on various datasets and architectures, showcasing its versatility and wide applicability.
ASAM’s Adversarial Link#
The heading ‘ASAM’s Adversarial Link’ suggests an exploration of the connection between Adaptive Sharpness-Aware Minimization (ASAM) and adversarial training methods. ASAM, designed to enhance generalization by encouraging flat minima in the loss landscape, shares a conceptual link with adversarial training. Adversarial training’s goal is to make the model robust against small input perturbations, often crafted to be adversarial examples. The adversarial examples force the model to learn more robust features. The paper likely demonstrates that the weight perturbations used in ASAM bear resemblance to those employed in adversarial training techniques. This connection is significant because it suggests that ASAM’s robustness to generalization might be partly due to its implicit adversarial nature. ASAM’s weight perturbations, though not explicitly targeted to find adversarial examples, might inadvertently accomplish a similar effect by forcing the network to be less sensitive to weight space fluctuations. This underlying link between ASAM and adversarial training would be an important contribution because it potentially explains the success of ASAM through a different, possibly more powerful, lens.
Corruption Robustness#
The research paper explores methods for enhancing the robustness of deep neural networks (DNNs) against corrupted inputs. A core concept is Data Augmentation via Multiplicative Perturbations (DAMP), a training technique that introduces random multiplicative weight perturbations. This approach contrasts with traditional methods that directly incorporate specific corruptions into the training data, which can sometimes negatively impact performance on clean images. The study demonstrates that DAMP effectively improves robustness across a wide range of corruptions, including those not explicitly seen during training, without sacrificing accuracy on clean data. A key finding highlights the equivalence between input and weight-space perturbations, facilitating the effectiveness of this weight-perturbation approach. Comparisons with other techniques like ASAM (Adaptive Sharpness-Aware Minimization) and standard data augmentation methods showcase DAMP’s competitive performance, often surpassing those methods, particularly given the training time efficiency. The results highlight DAMP’s potential for enhancing model generalization, making it a valuable technique for creating more robust and reliable DNNs in real-world applications.
Future Research#
Future research directions stemming from this work on multiplicative weight perturbations (MWPs) for improving robustness in deep neural networks (DNNs) are plentiful. Extending the theoretical analysis beyond simple feedforward networks to encompass modern architectures with components like normalization layers and attention mechanisms is crucial. This would enhance the applicability and understanding of DAMP’s effectiveness. Investigating alternative noise distributions beyond Gaussian noise, such as those inspired by adversarial examples or specific corruption types, could further boost robustness. Exploring the interaction between MWPs and other data augmentation techniques to create more powerful and efficient training strategies represents another promising avenue. The impact of MWPs on different optimization algorithms and their scaling properties with network size warrant deeper investigation. Finally, applying DAMP to other machine learning domains beyond computer vision, such as natural language processing and reinforcement learning, would significantly broaden the method’s impact and uncover potential benefits in diverse applications.
More visual insights#
More on figures
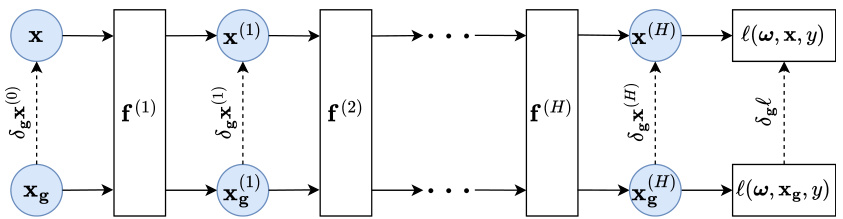
This figure illustrates how an input corruption affects the output of a deep neural network (DNN). It shows that a corruption applied to the input (x) propagates through each layer of the network, causing a shift in the output of each layer and ultimately a shift in the final loss function. This visualizes why the performance of a DNN often degrades when presented with corrupted inputs.
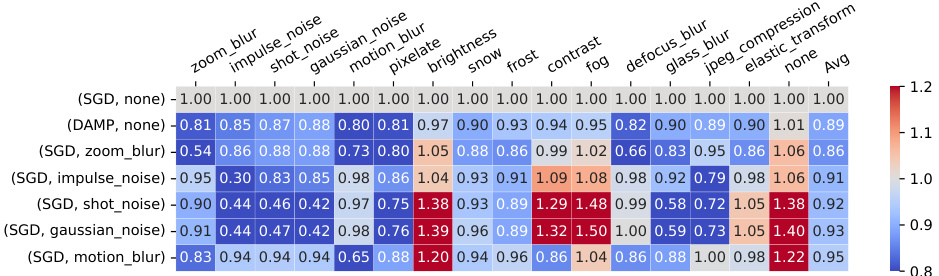
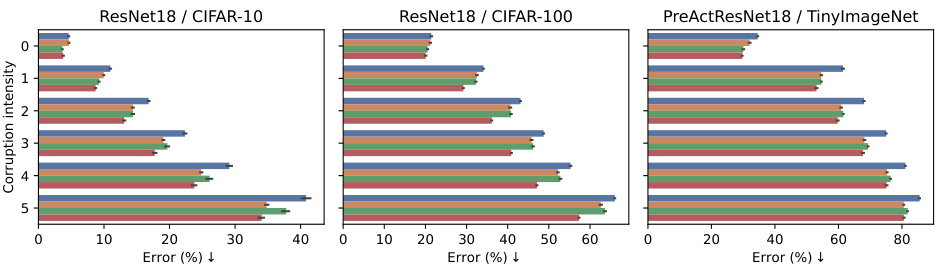
This figure shows the results of ResNet18 trained on CIFAR-100 dataset with different methods. Each row represents a method and a corruption used during training. Each column shows the performance under a specific corruption during testing. The heatmap visualizes the corruption error (CE), where lower values are better. The figure demonstrates that DAMP consistently improves robustness against various corruptions without compromising accuracy on clean images.
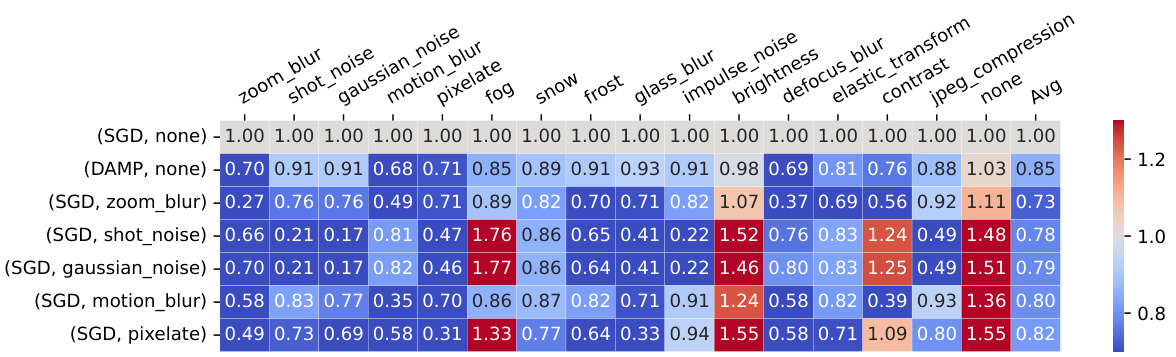
This figure shows the comparison of Corruption error (CE) for different corruption types using different training methods. The heatmap shows that DAMP consistently improves robustness to all corruption types while maintaining clean image accuracy, unlike using corruptions directly in training.
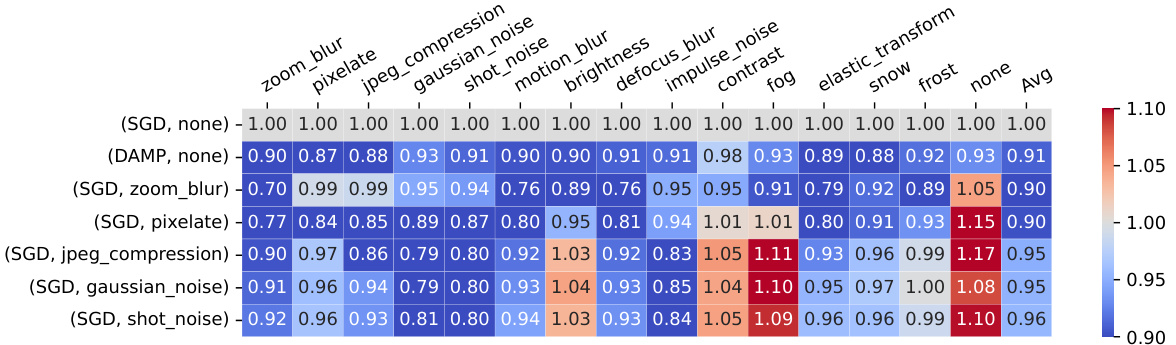
The figure shows a heatmap comparing the corruption error (CE) of ResNet18 models trained on CIFAR-100 using different methods. The methods include standard SGD without any corruption and DAMP with different corruption types as data augmentation. The heatmap visualizes the CE for different combinations of training method and corruption type versus various test corruption types. Lower values in the heatmap indicate better robustness. The figure demonstrates that DAMP improves robustness to various corruption types without compromising accuracy on clean images.
The figure shows a heatmap visualizing the corruption error (CE) of ResNet18 models trained on CIFAR-100 dataset using different methods. The rows represent training methods and corruptions, while the columns represent test corruptions. Lower CE values indicate better robustness. DAMP consistently shows lower CE across all test corruptions compared to other methods, indicating improved robustness without compromising accuracy on clean images.
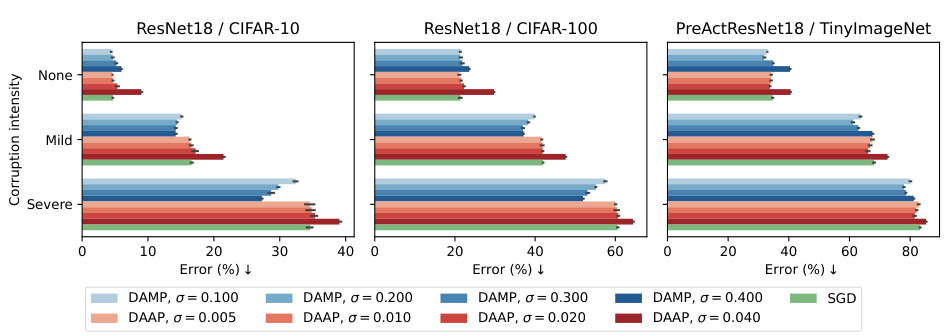
This figure compares the performance of DAMP and DAAP on three datasets (CIFAR-10, CIFAR-100, and TinyImageNet) under different corruption levels. The results show that DAMP, which uses multiplicative weight perturbations, consistently outperforms DAAP (additive weight perturbations) in terms of robustness to image corruptions across various severity levels. The figure highlights the effectiveness of multiplicative perturbations for improving model robustness.
More on tables

This table presents the results of the ResNet50 model trained on ImageNet, comparing DAMP’s performance against baseline methods (Dropout, SAM, ASAM). It shows the error rates on clean images and several corrupted versions of ImageNet (IN-A, IN-C, IN-D, IN-Sketch, IN-Drawing, IN-Cartoon). It also includes results for FGSM adversarial examples. Lower error rates indicate better performance.
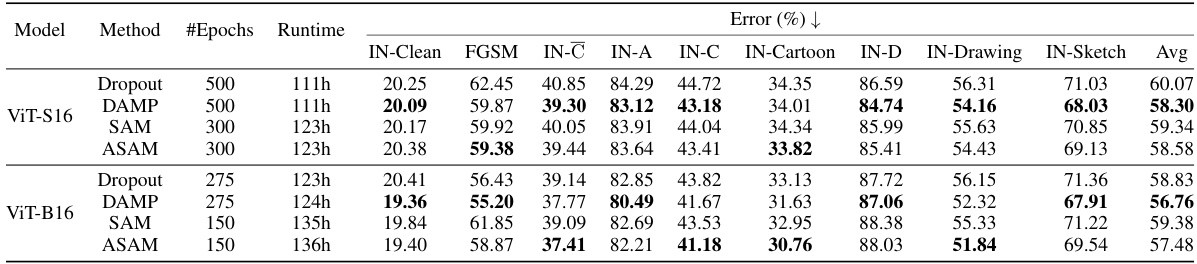
This table presents the comparison of different methods (Dropout, DAMP, SAM, ASAM) on their performance on ImageNet dataset using ResNet50 model. The predictive error is measured on various corruptions (IN-C, IN-A, IN-D, IN-Sketch, IN-Drawing, IN-Cartoon, FGSM) and on clean images. The average error across all corruption types is also reported.
Full paper#