↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current image quality assessment (IQA) models struggle with translating relative quality comparisons into continuous scores, especially when dealing with diverse datasets. Different datasets employ varying subjective testing methodologies, leading to inconsistent quality ratings. Existing IQA models also often lack cross-dataset generalizability.
Compare2Score tackles this by using large multimodal models (LMMs) trained with comparative instructions generated by comparing images from the same dataset. This innovative approach enables flexible dataset integration. The model employs a soft comparison method to translate discrete comparative levels into continuous quality scores and leverages maximum a posteriori estimation for optimization. Extensive experiments show Compare2Score surpasses state-of-the-art models, highlighting the effectiveness of its approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image quality assessment (IQA) and large multimodal models (LMMs). It bridges the gap between qualitative comparative judgments and quantitative quality scores, a long-standing challenge in the field. By introducing a novel training method and inference strategy, the research provides a significant step forward in developing more robust and accurate IQA systems. This approach is widely applicable beyond IQA, demonstrating its potential for broader applications within the LMM and computer vision communities. Its findings also open doors for further investigations into zero-shot learning in LMMs.
Visual Insights#

This figure illustrates the challenges of using absolute quality ratings for Image Quality Assessment (IQA). Panel (a) shows that images with the same Mean Opinion Score (MOS) can have vastly different perceived quality depending on the dataset they come from. Panel (b) highlights the problem of different datasets using different scales for rating quality. Panel (c) proposes a solution: using relative comparisons within a dataset, allowing for the flexible combination of multiple IQA datasets to improve model training and generalization.
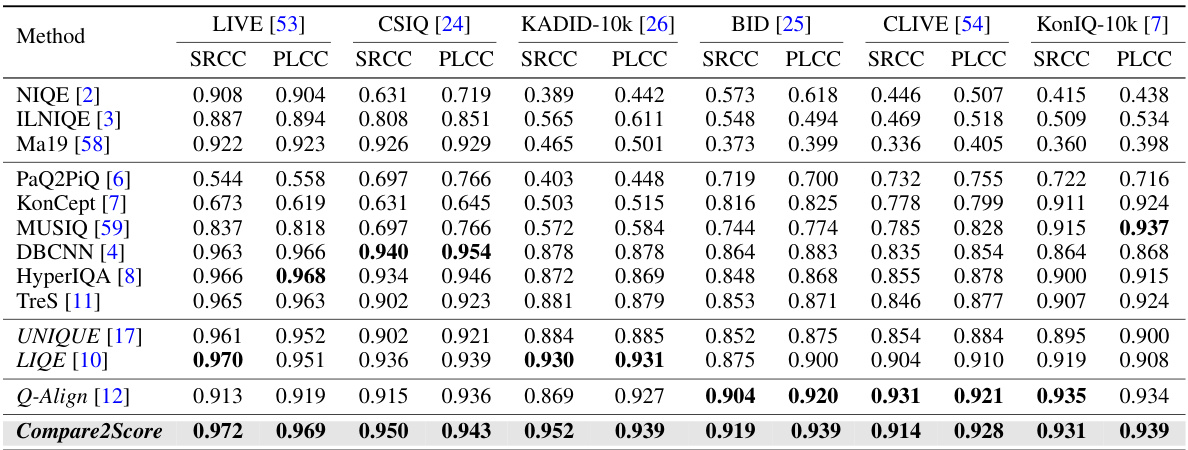
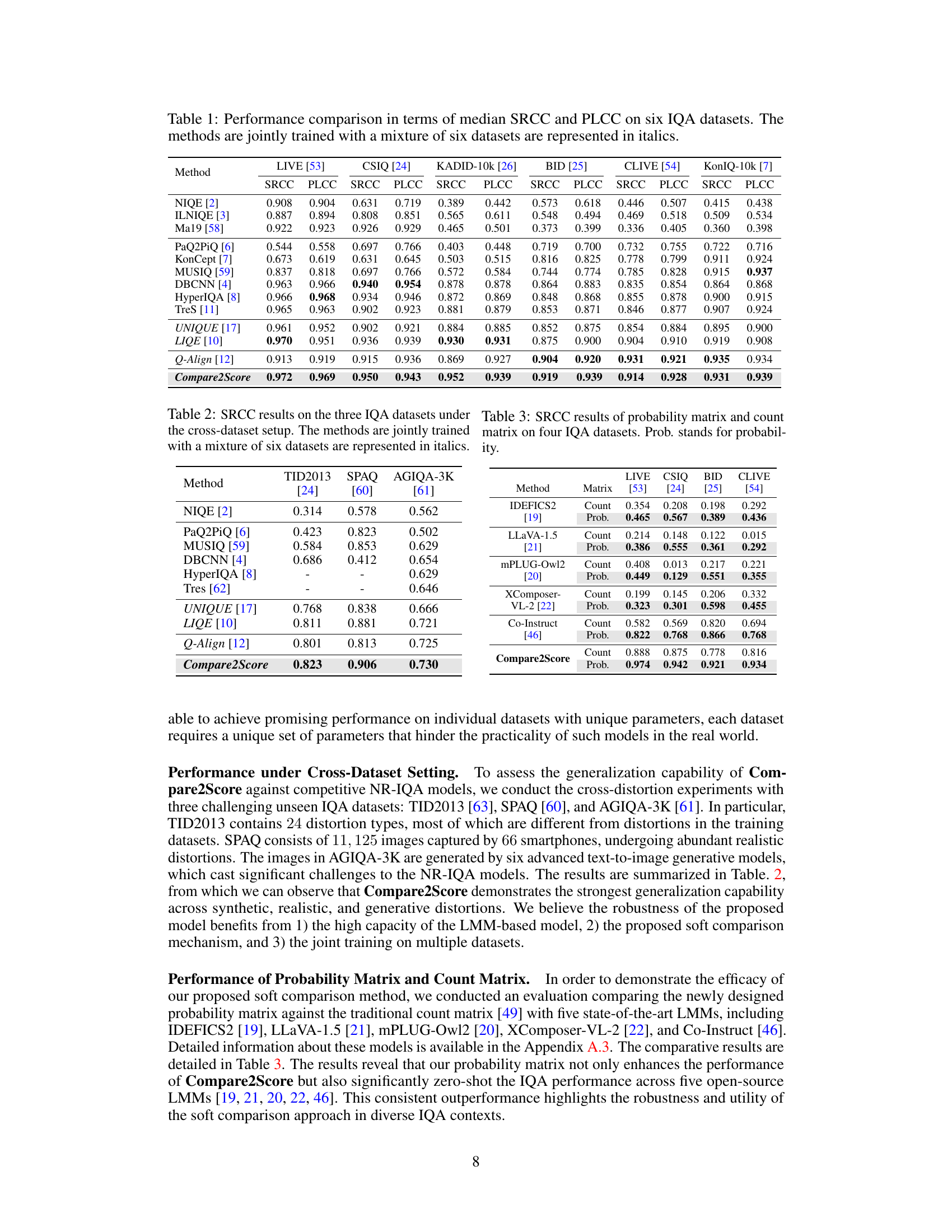
This table presents the performance comparison of various image quality assessment (IQA) methods across six benchmark datasets, using two common metrics: Spearman’s rank correlation coefficient (SRCC) and Pearson linear correlation coefficient (PLCC). The methods are categorized into several types, including opinion-unaware models, learning-to-regress models, learning-to-rank models, and large multimodal model (LMM)-based models. The datasets are categorized into those with synthetic distortions and those with real-world distortions. The table highlights Compare2Score’s superior performance across various datasets and distortion types.
In-depth insights#
LMM-IQA Paradigm#
The “LMM-IQA Paradigm” represents a significant shift in image quality assessment (IQA) by leveraging the power of large multimodal models (LMMs). Traditional IQA methods often struggle with generalization across diverse image distortions and subjective quality ratings. LMMs, however, offer a potential solution by integrating both visual and textual information, enabling them to learn complex relationships between image features and human perceptions of quality. This paradigm allows for more nuanced and context-aware assessments, moving beyond simple numerical scores towards richer, qualitative descriptions. A key advantage is the ability to leverage massive datasets of paired image comparisons, enabling LMMs to learn relative quality judgments rather than relying solely on absolute ratings. This approach fosters better cross-dataset generalization and robustness. While promising, challenges remain in effectively translating qualitative comparative outputs into continuous quality scores and addressing potential biases introduced by the training data. Further research should focus on optimizing inference speed and ensuring fairness and transparency in LMM-based IQA systems. The paradigm shows great potential for improved accuracy and applicability in real-world scenarios, such as automated image quality control and user experience enhancement.
Comparative Training#
Comparative training, in the context of image quality assessment (IQA), is a powerful technique to leverage the benefits of relative comparisons for training large multimodal models (LMMs). Instead of relying solely on absolute quality scores, which can vary across datasets due to different subjective testing methodologies, comparative training focuses on teaching the model to discern relative quality differences. This is achieved by presenting image pairs with comparative labels (e.g., ‘better than’, ‘worse than’, ‘similar to’). This approach enhances model robustness and generalizability because it emphasizes the underlying perceptual relationships between images, rather than relying on potentially inconsistent absolute scores. The use of comparative labels allows for the flexible combination of multiple IQA datasets, mitigating issues related to dataset bias. A key advantage is the ability to train on a larger, more diverse dataset which leads to improved performance across a broader range of distortions and image types. However, the effectiveness of comparative training relies on generating high-quality comparative labels. This process requires careful consideration of appropriate thresholds and metrics for defining different comparative levels to ensure reliable and consistent training. Careful design of the comparative training data is crucial for success. Therefore, this approach is a promising direction for advancing the state-of-the-art in IQA, especially for LMMs.
Soft Comparison#
The concept of “Soft Comparison” in the context of image quality assessment (IQA) offers a significant advancement over traditional methods. Instead of relying on crisp, binary comparisons (e.g., image A is better than image B), a soft comparison approach computes the probability of one image being preferred over another, or even multiple others. This probabilistic approach is particularly useful when dealing with subtle differences in image quality where a simple binary classification might be insufficient or unreliable. By incorporating a probability matrix, the model captures the uncertainty inherent in human perception and avoids the potential pitfalls of making definitive statements about relative quality, especially with the subjective nature of image aesthetics. The integration of soft comparison into a larger model, such as a large multimodal model (LMM), enables the system to generate more nuanced and flexible assessments, which translate better into the continuous quality scores desired for IQA. This flexibility and robustness are crucial in handling diverse image distortions and various subjective preferences in real-world applications. The use of a probability matrix not only provides more accurate scoring but can also lead to more generalizable and robust performance across different IQA datasets.
Cross-dataset Results#
A ‘Cross-dataset Results’ section in a research paper would analyze a model’s performance across multiple, distinct datasets. This is crucial for evaluating generalizability, a key factor for real-world applicability. The results would likely show performance metrics (like accuracy, precision, recall, F1-score) for each dataset, highlighting strengths and weaknesses. Significant variations across datasets would indicate potential limitations or biases in the model, perhaps due to differences in data distributions, image characteristics, or annotation styles. Ideally, the analysis would delve into why performance varies, possibly correlating results with dataset properties. A strong section would also compare the model’s performance to existing state-of-the-art methods on these same cross-datasets, solidifying its contributions and establishing benchmark results. The overall goal is to demonstrate that the model is robust and can effectively handle a variety of unseen data, rather than being overfit to a single, specific dataset.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending the model to handle a wider variety of image distortions and resolutions is crucial for broader applicability. Investigating alternative anchor image selection strategies beyond the current method could improve efficiency and robustness. Analyzing the influence of different LMM architectures on the model’s performance would also be insightful. A thorough exploration of the soft comparison method’s theoretical underpinnings is needed, potentially leading to refinements that enhance accuracy and reduce computational cost. Finally, assessing the model’s generalizability to other multimodal tasks beyond image quality assessment would demonstrate its wider utility and potential.
More visual insights#
More on figures

This figure illustrates the training and inference phases of the Compare2Score model. Panel (a) shows how the large multimodal model (LMM) is fine-tuned using comparative instructions derived from Mean Opinion Scores (MOS) within individual IQA datasets. This approach allows for flexible integration of multiple datasets. Panel (b) depicts the inference process: the trained LMM compares a test image against multiple anchor images to determine the likelihood of the test image being preferred, which is then used to calculate a continuous quality score using Maximum a Posteriori (MAP) estimation.
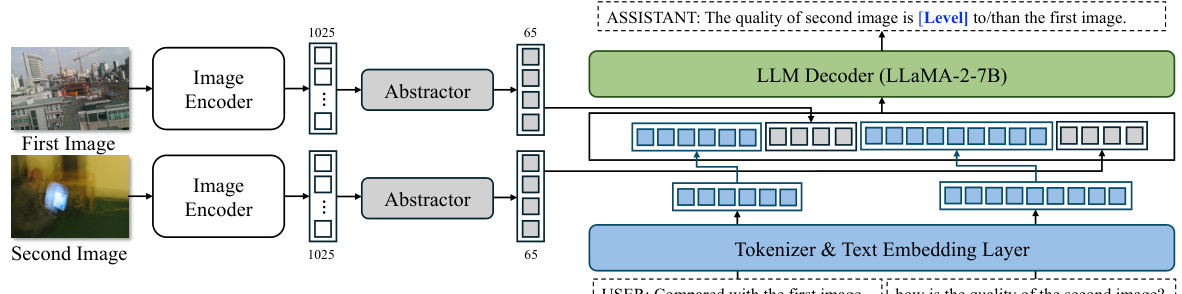
This figure illustrates the architecture of the Compare2Score model. It shows how two images are first processed by an image encoder, then reduced in dimensionality by an abstractor. These reduced representations are combined with textual embeddings, and then processed by a large language model (LLM) decoder. The output of the LLM is the comparison of the image quality relative to the other.
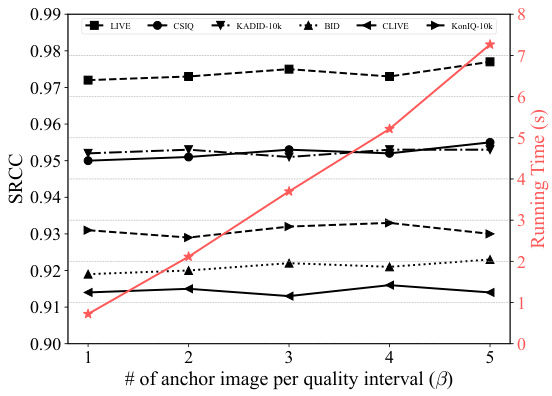
This figure shows the impact of the number of anchor images per quality interval (β) on both the SRCC scores (a measure of ranking correlation) and the inference time of the Compare2Score model across six different IQA datasets. The x-axis represents the number of anchor images (β), and the y-axis shows the SRCC. For each dataset, a separate line plot shows the trend of SRCC values as β varies. A second y-axis is included to show the running time (in seconds) associated with each β value. The plot demonstrates that increasing β beyond a value of 1 does not significantly improve the SRCC scores but substantially increases the running time, indicating that β=1 provides a good balance between accuracy and efficiency.

This figure shows five example anchor images selected from the KonIQ-10k dataset. Each image is labeled with its mean opinion score (MOS) and standard deviation (σ), representing the perceived image quality and variability in subjective ratings. These anchor images represent different levels of visual quality within the dataset, used as references during the soft comparison phase of the Compare2Score framework for quality score inference.

This figure shows five example anchor images selected from the KonIQ-10k dataset. Each image represents a different level of perceived quality, as indicated by its mean opinion score (MOS) and standard deviation (σ). The images are visually diverse, showcasing the range of quality levels the model considers during inference.

This figure shows five example anchor images selected from the AGIQA-3K dataset to represent different levels of perceived image quality. Each image is labeled with its mean opinion score (MOS) and standard deviation (σ), indicating the variability in human ratings for that image’s quality. The images illustrate a range of visual characteristics and demonstrate that the chosen anchors represent a diverse range of qualities within the dataset.
More on tables
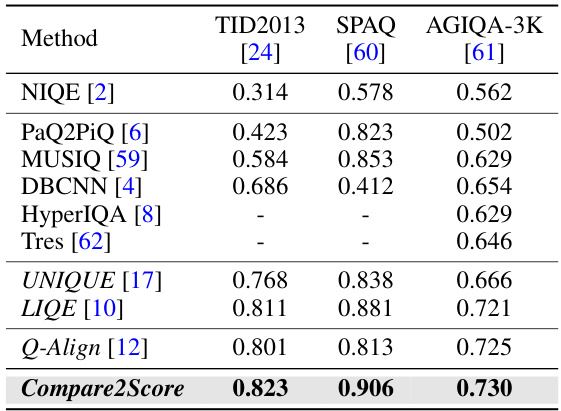
This table presents the Spearman Rank Correlation Coefficients (SRCC) achieved by different image quality assessment (IQA) models on three unseen IQA datasets (TID2013, SPAQ, and AGIQA-3K). The models were pre-trained on a combination of six other IQA datasets. The table shows the cross-dataset generalization ability of the models, indicating how well they perform on datasets with different distortion types and characteristics than those seen during training. Higher SRCC values represent better performance.
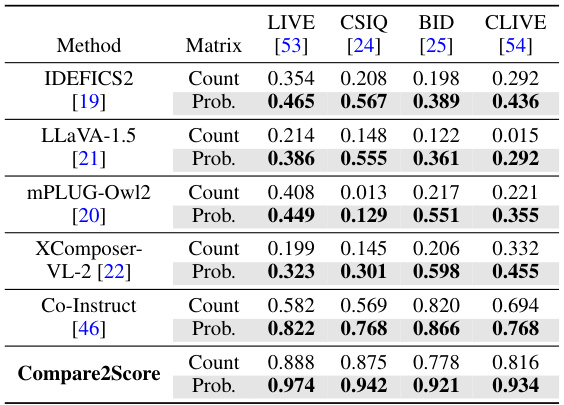
This table compares the performance of using a probability matrix versus a count matrix for image quality assessment. The comparison is done using the Spearman Rank Correlation Coefficient (SRCC) across four different image quality assessment (IQA) datasets. The probability matrix approach is shown to significantly improve performance compared to the traditional count matrix approach.
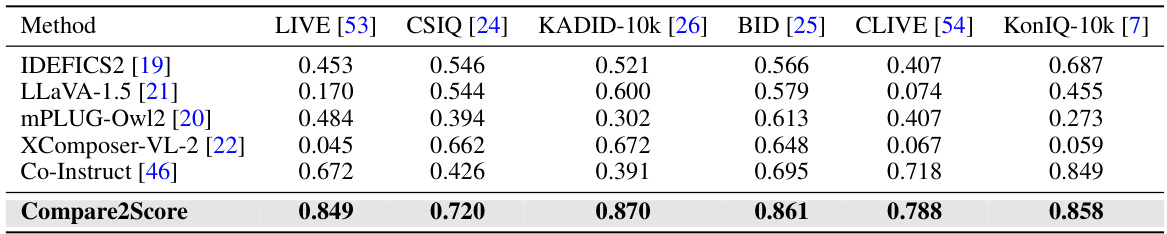
This table presents a comparison of the prediction accuracy achieved by Compare2Score and several other models across six different image quality assessment (IQA) datasets. The datasets vary in terms of the types of image distortions included (synthetic and real-world distortions). The accuracy metric likely represents a correlation coefficient (e.g., Pearson or Spearman) measuring the agreement between the model’s predictions and human judgments. The best performing model for each dataset is shown in boldface. The table demonstrates Compare2Score’s superior performance compared to other LMM models.
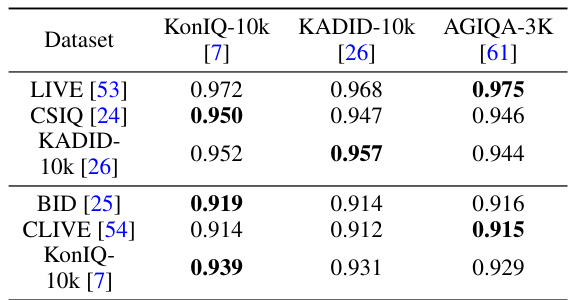
This table presents the Spearman’s rank correlation coefficient (SRCC) results for the Compare2Score model. The results show the model’s performance on six different image quality assessment (IQA) datasets (LIVE, CSIQ, KADID-10k, BID, CLIVE, and KonIQ-10k). Importantly, the anchor images used for comparison were sourced from three different datasets (KonIQ-10k, KADID-10k, and AGIQA-3K) to evaluate the model’s robustness and generalization capabilities across various IQA datasets and distortion types.

This table shows the impact of different anchor image selection methods on the performance of the Compare2Score model. It compares the SRCC (Spearman Rank Correlation Coefficient) scores achieved using three different methods: random selection, maximum variance selection, and the proposed minimum variance selection method. The results are presented for six different IQA (Image Quality Assessment) datasets: LIVE [53], CSIQ [24], KADID-10k [26], BID [25], CLIVE [54], and KonIQ-10k [7]. The table demonstrates the effectiveness of the proposed minimum variance anchor selection method compared to the other two approaches.
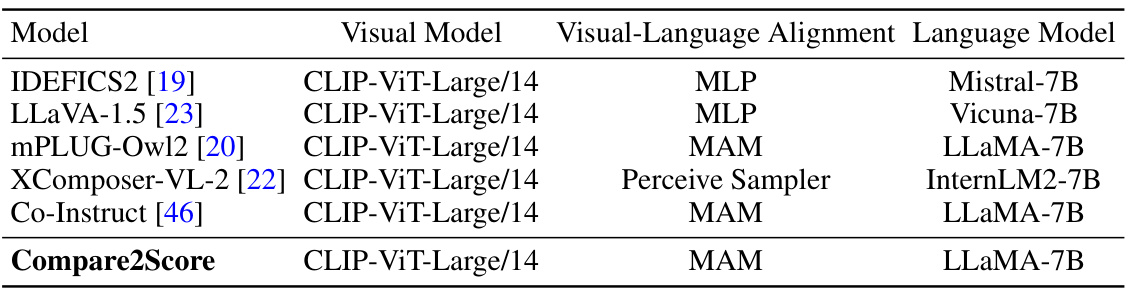
This table compares different Large Multimodal Models (LMMs) used in the paper. It shows the visual model, visual-language alignment method, and language model used in each model. The models compared are several existing open-source models and the proposed Compare2Score model. The table highlights the architectural differences in the models, showing the components that process visual information, how visual and textual information are combined, and which language model generates the final output.
Full paper#