↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Existing training-free guidance methods for diffusion models often lack theoretical grounding and struggle with complex tasks. This paper introduces Training-Free Guidance (TFG), a novel algorithmic framework that unifies these methods and systematically analyzes their design space. This allows researchers to efficiently search the hyperparameter space for optimal settings.
TFG offers a superior hyperparameter search strategy, significantly improving performance across various tasks and diffusion models. The framework’s comprehensive benchmark, including diverse datasets and tasks, and improved performance demonstrate TFG’s potential for advancing training-free conditional generation. The findings provide a valuable resource for researchers to improve the efficiency and effectiveness of their applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in generative AI, particularly those working with diffusion models. It offers a unified framework for training-free guidance, streamlining existing approaches and enabling efficient exploration of the design space. The comprehensive benchmark across various tasks and models provides valuable insights and guidelines for future research. It also opens up new avenues for investigation, especially in challenging scenarios like fine-grained generation where training-based methods fall short.
Visual Insights#

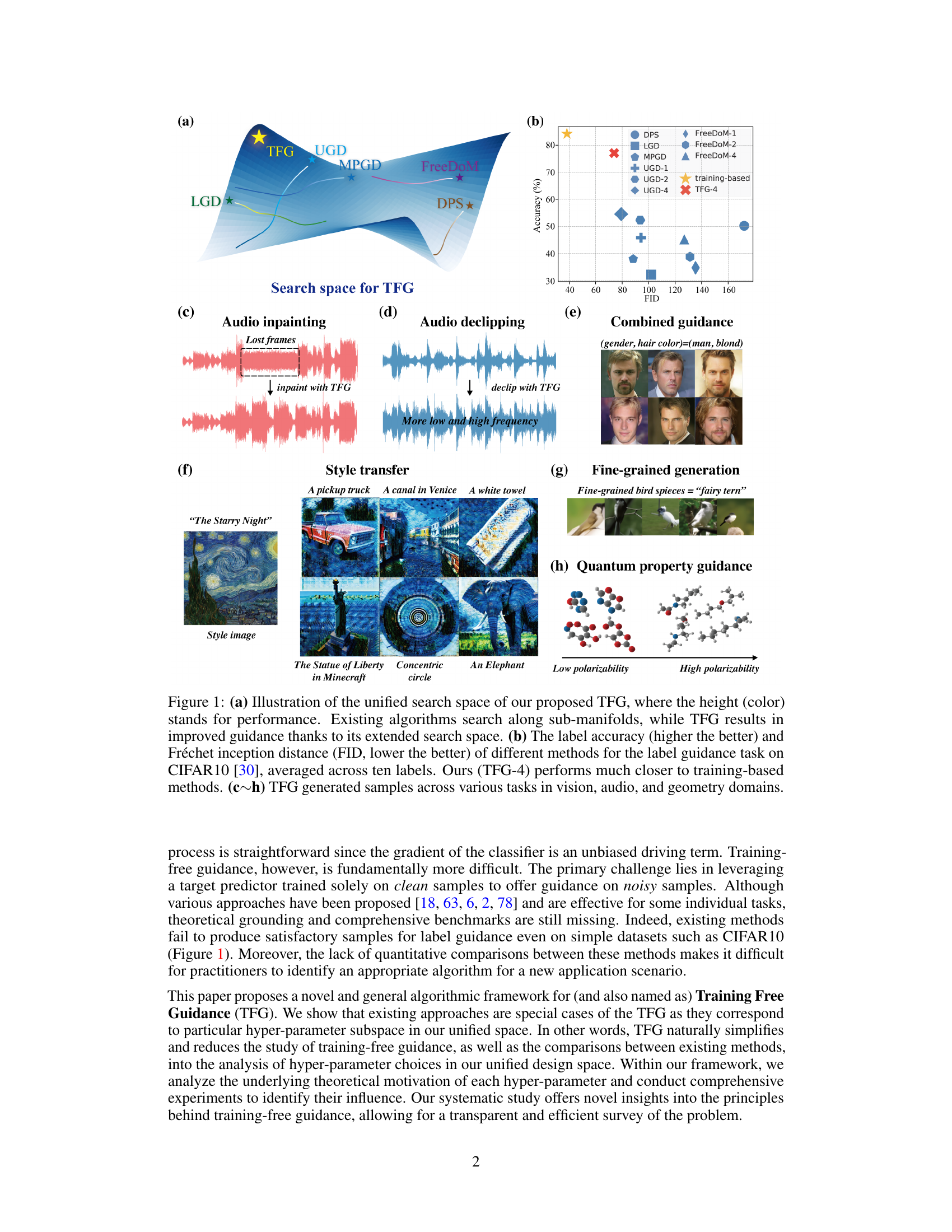
This figure presents the unified search space for the proposed Training-Free Guidance (TFG) framework, highlighting its advantage over existing methods. Subfigure (a) visually shows that TFG explores a larger search space compared to other methods, leading to improved performance. Subfigure (b) demonstrates the superiority of TFG in a label guidance task by comparing label accuracy and Fréchet Inception Distance (FID) with existing methods on CIFAR10. Finally, subfigures (c) through (h) showcase example outputs generated by TFG across different tasks involving vision, audio, and geometric domains, further illustrating its versatility.
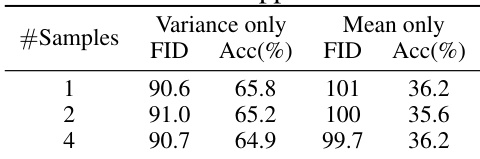
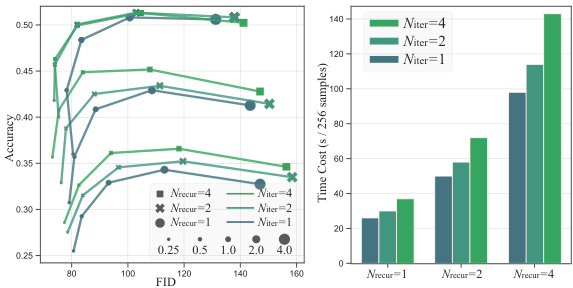
This table presents the results of an experiment to determine the effect of the number of Monte Carlo samples used in estimating the expectation in Line 4 of the TFG algorithm. The experiment is broken down into two parts: Variance only, where the focus is on the variance component, and Mean only, focusing on the mean. The results show that the number of samples has little impact on the performance of the algorithm (as measured by FID and accuracy). This suggests that a smaller number of samples can be used without significantly affecting the outcomes.
In-depth insights#
TFG Framework#
The TFG framework presents a unified approach to training-free guidance for diffusion models, addressing the limitations of existing methods. It unifies diverse existing algorithms under a single, algorithm-agnostic design space, enabling systematic analysis and comparison. This is achieved by introducing a set of hyperparameters that encompass previous methods as special cases, thus simplifying the research landscape. TFG’s strength lies in its ability to systematically search this hyperparameter space, leading to improved performance across a variety of tasks and datasets. The framework’s comprehensive benchmarking across various diffusion models and tasks demonstrates its effectiveness and provides valuable insights into training-free guidance, paving the way for a more efficient and transparent approach to conditional generation.
Hyperparameter Search#
Effective hyperparameter search is crucial for the success of the Training-Free Guidance (TFG) framework. The authors intelligently address this by analyzing the structure of the hyperparameter space, demonstrating that certain structures consistently perform better than others, regardless of other parameter settings. This insightful analysis allows for a two-stage search: first, identifying optimal structural parameters, significantly reducing the search space; and second, optimizing scalar parameters within the reduced space. This efficient strategy is validated empirically, proving its superiority to exhaustive grid search and highlighting its suitability for various downstream tasks. The combination of theoretical analysis and a well-defined search procedure is a key strength of the paper, offering a practical and robust approach to tackle the challenge of hyperparameter optimization in training-free conditional generation models.
Benchmark Results#
A ‘Benchmark Results’ section in a research paper would ideally present a comprehensive comparison of the proposed method against existing state-of-the-art techniques. It should go beyond simply reporting performance metrics; a thoughtful analysis is crucial. Quantitative results should be clearly presented, possibly using tables or graphs to compare metrics such as accuracy, precision, recall, F1-score, etc. across different datasets and experimental settings. Beyond raw numbers, qualitative insights are needed, explaining any unexpected results, and highlighting the strengths and weaknesses of each approach in different scenarios. Statistical significance of the results should be addressed, employing methods such as t-tests or ANOVA to determine if observed differences are statistically significant. The discussion should also cover the computational costs of each method, offering a balanced view of performance versus resource usage. Finally, a concise summary should conclude the section, highlighting the key findings and their implications for the field.
Limitations of TFG#
The Training-Free Guidance (TFG) framework, while demonstrating improved performance over existing methods, presents several limitations. Computational cost remains a concern, particularly with increased recurrence and iteration steps, potentially limiting scalability. The search strategy for hyperparameters, although efficient, still necessitates a considerable search space, which might prove insufficient for vastly complex tasks. Theoretical analysis primarily focuses on a simplified setting; a more robust theoretical understanding accounting for practical complexities like noise and dataset biases is necessary. While TFG unifies existing methods, generalizability across diverse downstream tasks isn’t fully guaranteed, as demonstrated by some suboptimal results in niche applications. Furthermore, the reliance on off-the-shelf predictors can impact results, as accuracy and robustness of these predictors directly affect TFG’s performance. Finally, quantitative analysis may not always capture the nuances evident in qualitative assessments, requiring a careful balance of both for a holistic understanding of its capabilities and shortcomings.
Future Research#
Future research directions stemming from this training-free guidance framework for diffusion models are plentiful. Improving the efficiency of the hyperparameter search is crucial; current methods, while effective, are computationally expensive. Exploring alternative search strategies, perhaps leveraging Bayesian optimization or evolutionary algorithms, could drastically reduce the runtime. Another key area involves extending the theoretical analysis to better understand the interaction between different hyperparameters and their impact on various tasks and datasets. This deeper understanding will lead to more robust and predictable guidance. Investigating different types of target predictors beyond classifiers—incorporating loss functions, energy functions, or even learned representations—could significantly broaden the applicability of the framework. Finally, applying this framework to other generative models beyond diffusion models, such as GANs or autoregressive models, would demonstrate its generality and potential for wider impact. A focus on real-world applications with rigorous benchmarking across diverse datasets and tasks is needed to establish the practical value and limitations of training-free guidance.
More visual insights#
More on figures

This figure compares three different structures for the hyperparameters p and μ within the TFG framework, across the CIFAR-10 and ImageNet datasets. The structures are ‘increase’, ‘decrease’, and ‘constant’. The x-axis represents the value of p or μ, and the y-axis represents the accuracy or FID. The figure shows that the relative performance of these structures remains consistent across different settings of the other hyperparameters. The results suggest that a suitable structure can be pre-selected and then refined by tuning the remaining hyperparameters, leading to an efficient hyperparameter search strategy.
This figure compares three different structures for the hyperparameters ρ and μ in the TFG framework across CIFAR10 and ImageNet datasets. It analyzes how the choice of these structures affects the model’s performance when other hyperparameters are varied. The results demonstrate that the relative relationships between the structures remain consistent regardless of the values of other hyperparameters. This finding is important because it allows for a more efficient hyperparameter search strategy by first determining appropriate structures and then optimizing the remaining scalar parameters.
This figure demonstrates the unified search space of the proposed Training-Free Guidance (TFG) framework, showing how existing methods are special cases within this space. It compares TFG’s performance to other methods on a label guidance task using CIFAR10, showing TFG’s superior accuracy and lower FID. Finally, it showcases example outputs generated by TFG across a variety of tasks.

This figure provides a comprehensive overview of the Training-Free Guidance (TFG) framework proposed in the paper. Panel (a) visually represents the unified search space of TFG, highlighting its ability to encompass existing methods as special cases. Panel (b) presents a quantitative comparison of TFG against state-of-the-art methods on the CIFAR-10 label guidance task, demonstrating TFG’s superior performance. Panels (c) through (h) showcase illustrative examples of image and audio generation, style transfer, and geometry manipulation tasks performed by TFG, showcasing its versatility and efficacy across various applications.

The figure presents a comparison of the performance of different training-free guidance methods on CIFAR10. The left panel shows a scatter plot comparing accuracy and FID for various methods, with and without a ‘fake’ classifier trained on clean data. The results demonstrate a significant performance gap between training-based and training-free approaches. The right panel illustrates how MPGD generates an image of a ship at various stages of the sampling process. It highlights that training-free guidance methods struggle to generate high-quality images compared to training-based methods.

This figure compares the image generation results of different training-free guidance methods with a training-based method as a baseline on the CIFAR-10 dataset. The task is generating images of dogs. The training-based method produces high-quality, realistic images of dogs. The training-free methods produce less realistic images, but the TFG method significantly outperforms the other training-free methods in terms of image quality and accuracy. This demonstrates the effectiveness of the TFG framework.
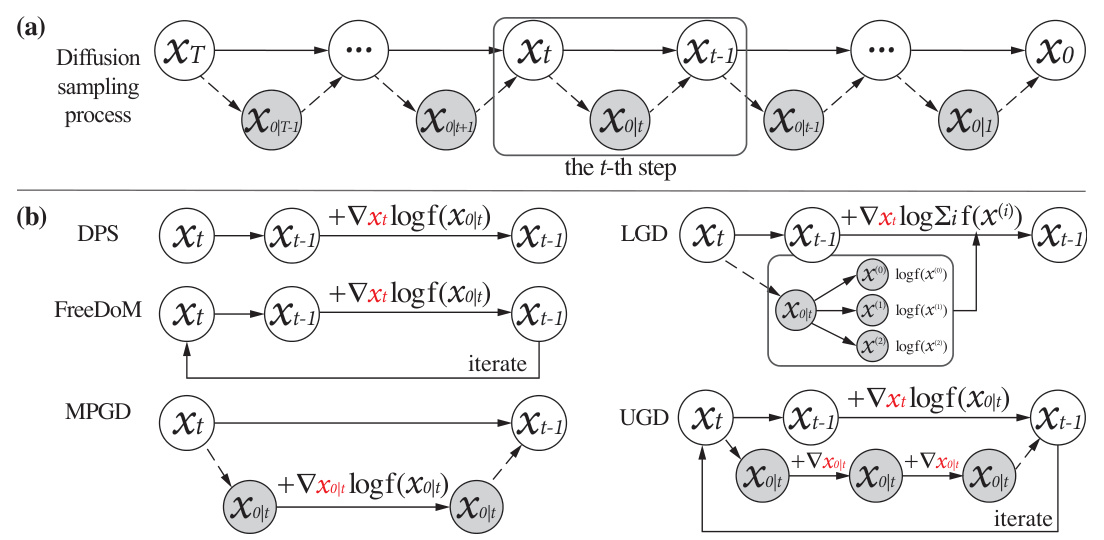
This figure illustrates the reversed diffusion process and how different training-free guidance algorithms modify it at step t. Panel (a) shows the standard diffusion process, sampling from a noisy distribution at time T down to a clean distribution at time 0. Panel (b) details the modifications introduced by different training-free guidance algorithms (DPS, LGD, FreeDoM, MPGD, and UGD). Each algorithm modifies the sampling process by incorporating the gradient of the target predictor function at different points in the process. The arrows and plus signs indicate the added guidance term.

This figure compares the image generation quality of different methods on the CIFAR10 dataset, focusing on the ‘dog’ class. It visually demonstrates the performance gap between training-based methods and training-free methods for conditional image generation. The training-based method serves as the ground truth, showcasing high-quality images that accurately reflect the target class (dog). The training-free methods, such as FreeDoM and others, generate images with lower quality and faithfulness to the target. Crucially, the Training-Free Guidance (TFG) method introduced in the paper significantly improves upon these other training-free methods, generating images closer in quality and accuracy to the training-based method.

This figure shows a qualitative comparison of different training-free guidance methods applied to the Gaussian deblurring task. The top row displays the noisy input images. The subsequent rows illustrate the results obtained using various methods: DPS, LGD, MPGD, FreeDoM, UGD, and TFG. The comparison highlights TFG’s ability to produce clean images without the background noise present in FreeDoM and UGD’s outputs. TFG also demonstrates superior fidelity in capturing image features compared to DPS and richer detail compared to LGD. The parameter Nrecur is set to 1 for all methods shown.

This figure is a qualitative comparison of different methods for generating images of dogs from the CIFAR-10 dataset. The top row shows examples generated using a training-based method, which serves as a benchmark for high-quality results. The subsequent rows demonstrate the performance of several training-free guidance methods: FreeDoM, UGD, and TFG. The figure highlights that while training-free methods struggle to match the quality of the training-based approach, the TFG approach produces notably better-quality images compared to the other training-free methods.

This figure presents a visual comparison of different training-free guidance methods applied to the Gaussian deblurring task. The top row shows the noisy input images. The subsequent rows show the results from applying DPS, LGD, MPGD, FreeDoM, UGD, and TFG. The caption highlights TFG’s superior performance in removing noise and preserving image details compared to other methods. The number of recurrences (Nrecur) is set to 1 for all methods.

This figure compares different training-free guidance methods on an ImageNet label guidance task with the target label as ‘Kuvasz’. Each method’s generated images are shown in a grid, illustrating the quality and variety of samples produced. The suffix number (e.g., -4) indicates the number of recurrence steps used in the algorithms. The figure highlights that TFG outperforms other methods, generating more valid samples of Kuvasz dogs, demonstrating the effectiveness of the proposed approach. The consistent seed ensures fair comparison and eliminates bias from different random initializations.

This figure compares the results of six different training-free guidance methods on a combined guidance task, specifically targeting the generation of images of young men. The methods compared are DPS, LGD, MPGD, FreeDoM, UGD, and the authors’ proposed TFG. Each method’s output is displayed as a grid of generated images, showcasing the visual quality and fidelity of the generated images. The caption highlights that TFG outperforms the other methods in terms of both fidelity and validity, achieving higher quality and more accurate results for the specified target.

This figure compares the results of different training-free guidance methods on an ImageNet label guidance task, specifically targeting the ‘Kuvasz’ dog breed (label 222). It displays generated images from six different methods: DPS, LGD, MPGD, FreeDoM-4, UGD-4, and TFG-4. The number after FreeDoM, UGD, and TFG indicates the number of recurrence steps (Nrecur) used. Importantly, all images were generated using the same random seed to eliminate the effects of randomness in the generation process and ensure a fair comparison. The figure highlights that TFG produces the most realistic and accurate images of Kuvasz dogs compared to the other methods.

This figure illustrates the unified search space of the proposed Training-Free Guidance (TFG) framework. Panel (a) shows that existing methods explore only a subset of the possible hyperparameter space, while TFG explores the entire space. Panel (b) compares the performance of TFG to existing methods on a label guidance task. The remaining panels (c-h) showcase example outputs from TFG across several diverse tasks.

This figure compares the results of different training-free guidance methods on a style transfer task, using Van Gogh’s ‘The Starry Night’ as the target style. The figure shows that TFG generates images with the most faithful reproduction of the target style compared to other methods (DPS, LGD, MPGD, FreeDoM, UGD). While MPGD produces reasonably good results, TFG significantly outperforms it in terms of style similarity. The other methods fail to capture the target style effectively.

This figure compares different training-free guidance methods on a style transfer task. The target style is Van Gogh’s ‘The Starry Night’. The figure shows that TFG (Training-Free Guidance) generates images that are most faithful to the target style, outperforming methods like DPS, LGD, FreeDoM, and UGD, while MPGD also performs well but is still inferior to TFG. Nrecur, a hyperparameter representing recurrence, is set to 1 for all methods.

This figure shows a qualitative comparison of different training-free guidance methods for generating molecules with a specific polarizability (α). Each row represents a different method (TFG, DPS, LGD, FreeDoM, MPGD, UGD), and each column shows generated molecules for increasing target polarizability values. The figure demonstrates that TFG is superior at producing valid molecules that closely match the target polarizability, unlike other methods which frequently fail to generate valid molecules or achieve the target property.
More on tables

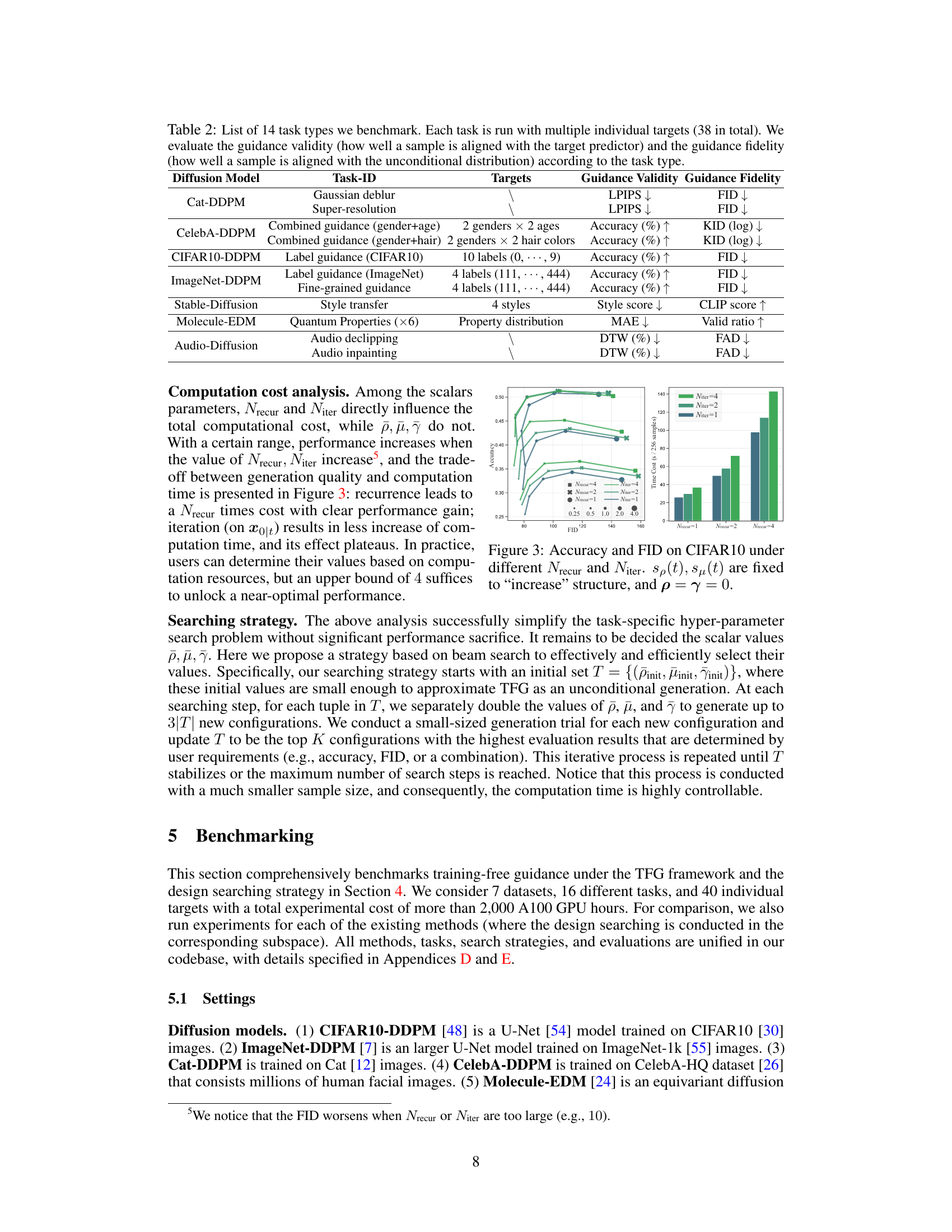
This table presents a comprehensive list of the 14 different tasks used to benchmark the training-free guidance methods proposed in the paper. Each task involves multiple individual targets (a total of 38). For each task, the table specifies the diffusion model used, the type of guidance (e.g., Gaussian deblurring, label guidance), and the metrics employed to evaluate both the validity (alignment with the target) and fidelity (alignment with the original distribution) of the generated samples. This table provides a clear overview of the range of tasks and evaluation criteria used in the study.
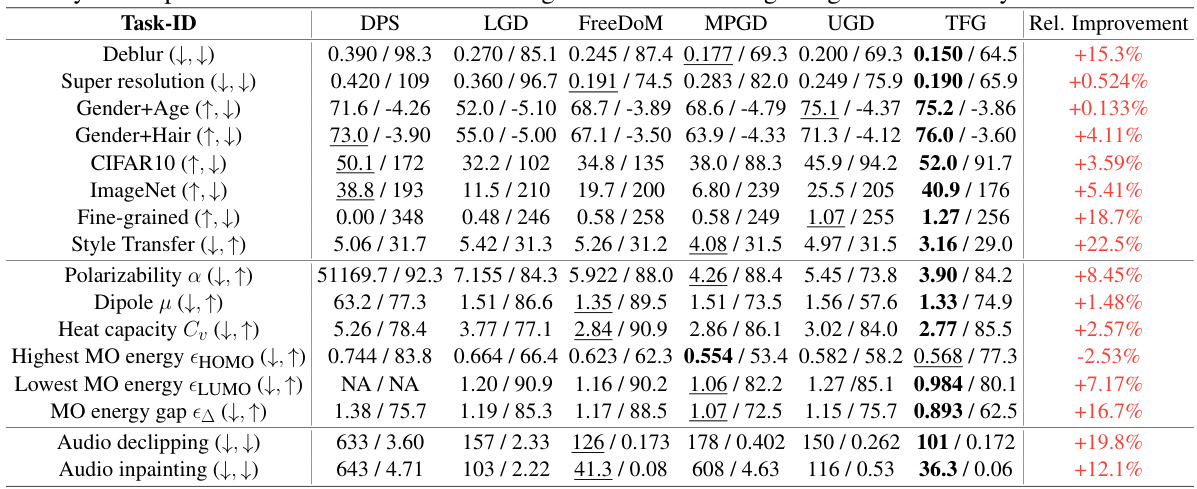
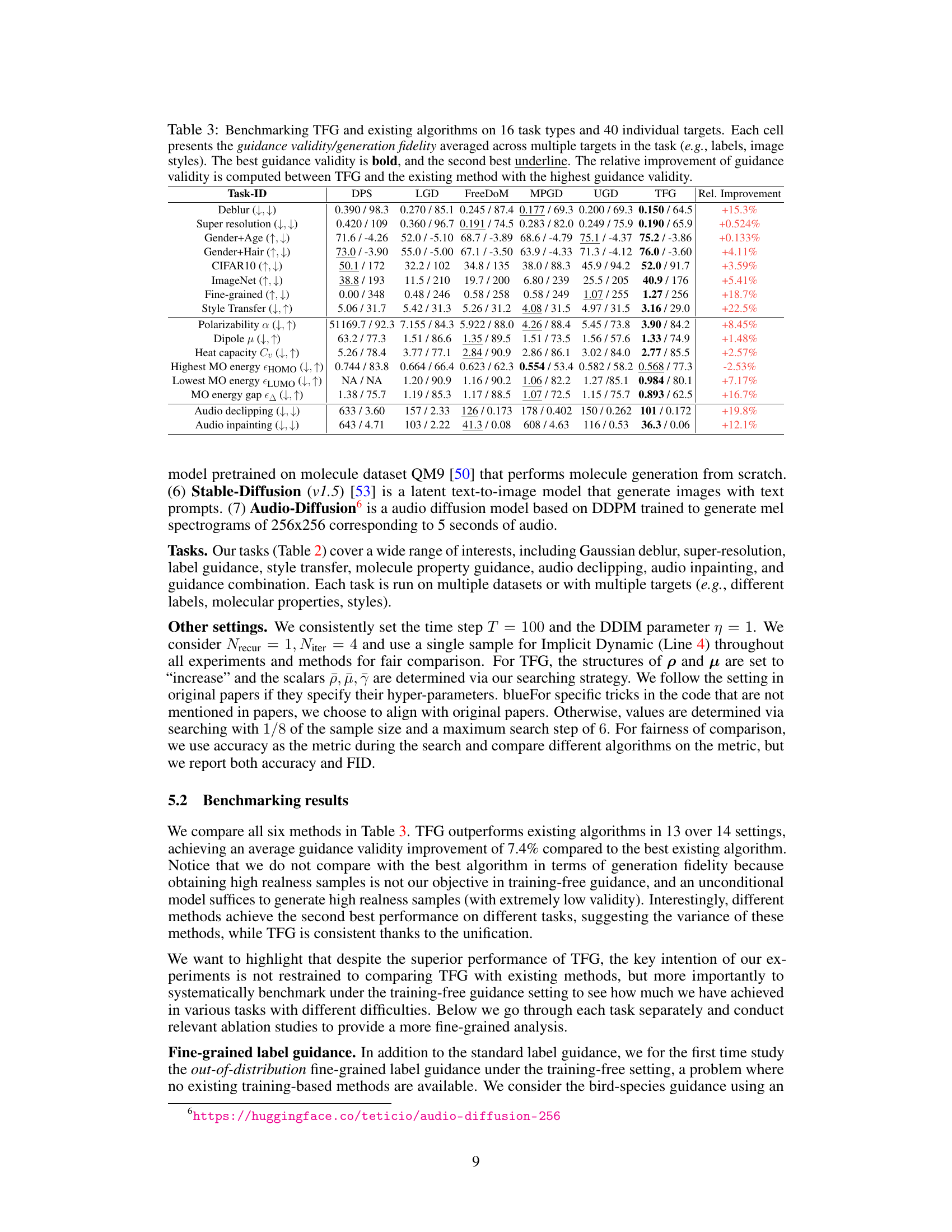
This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against five existing training-free guidance methods across 16 diverse tasks and a total of 40 individual targets. Each task involves multiple targets (e.g., different labels or image styles), and the table shows the average guidance validity (how well the generated samples align with the desired properties) and generation fidelity (how realistic the generated samples appear) for each method. The best performing method for each task is highlighted in bold, indicating the superior performance of TFG across various scenarios.
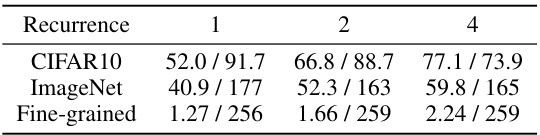
This table presents the accuracy and FID (Fréchet Inception Distance) scores achieved by the Training-Free Guidance (TFG) method on three different datasets (CIFAR10, ImageNet, and Fine-grained) for label guidance task. The results are shown for different numbers of recurrence steps (Nrecur = 1, 2, and 4). It demonstrates the impact of recurrence on the performance of the TFG method in improving both the accuracy of label classification and reducing the FID (a measure of image quality). Higher accuracy and lower FID indicate better performance.
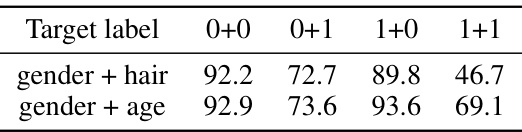
This table presents the accuracy of multi-label guidance on the CelebA dataset. It shows the accuracy of generating images with specific combinations of gender and hair color (or age). Noteworthy is that the accuracy is lower for less frequent combinations, demonstrating an implicit bias in the data and the model despite overall high performance compared to unconditional generation.

This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against five existing training-free guidance methods across 16 diverse tasks and a total of 40 individual targets. The tasks cover various domains, such as image processing, audio processing, and molecular design. For each task and target, the table shows the guidance validity (how well the generated samples align with the desired properties) and guidance fidelity (how well the generated samples reflect the underlying data distribution). The best performing method for each task is highlighted in bold, while the second-best is underlined. Additionally, the relative improvement achieved by TFG compared to the best-performing existing method is also provided, demonstrating the superiority of the TFG framework.

This table presents a comprehensive benchmark comparing the performance of the proposed TFG method against five existing training-free guidance algorithms across 16 different tasks and a total of 40 individual targets. The tasks encompass diverse domains including image processing, audio processing, and molecular generation. For each task and target, the table shows the guidance validity (how well the generated samples align with the desired properties) and generation fidelity (how realistic the generated samples are). The best performing method for each task is highlighted in bold, showcasing TFG’s superior performance across the different tasks and demonstrating its ability to achieve consistently good results. The relative improvement of TFG over the best baseline method is also provided for each task.
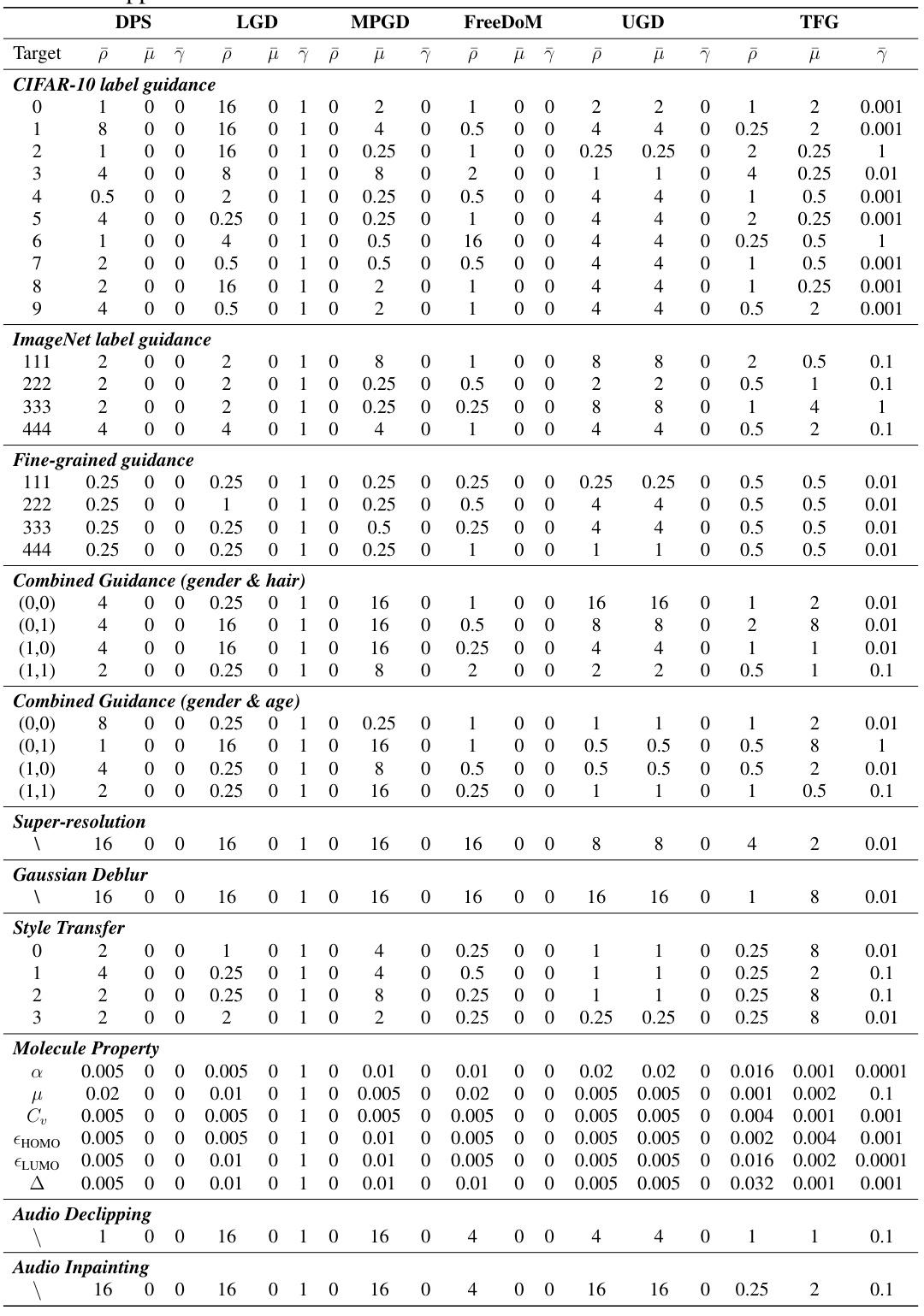
This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against five existing training-free guidance methods across sixteen diverse tasks and forty target properties. The results show the average guidance validity and fidelity for each method on each task, highlighting TFG’s superior performance and relative improvement over existing methods. Guidance validity refers to how well the generated samples align with the intended target, while fidelity measures how well the samples match the unconditional data distribution.

This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against five existing training-free guidance methods across 16 diverse tasks and a total of 40 individual targets. For each task and target, the table shows the guidance validity (how well the generated samples align with the desired properties) and guidance fidelity (how well the samples align with the unconditional data distribution). The best and second-best results for each task are highlighted, and the relative improvement achieved by TFG over the best-performing existing method is also indicated.

This table presents a comprehensive benchmark comparing the Training-Free Guidance (TFG) framework with existing methods across 16 different tasks and 40 individual targets. For each task and target, the table shows the guidance validity (how well the generated samples align with the target) and the guidance fidelity (how well the samples align with the unconditional distribution). The best performing method for validity is highlighted in bold, and the second best is underlined. Finally, it calculates the percentage improvement achieved by TFG over the best-performing existing method for each task.

This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against existing methods across 16 diverse tasks and 40 specific targets. The results are shown as guidance validity (how well the generated samples align with the desired properties) and generation fidelity (how realistic the generated samples appear). For each task, the best-performing method is highlighted in bold, while the second-best is underlined. The relative improvement column quantifies TFG’s advantage over the best existing method for each task.
This table presents a comprehensive benchmark comparing the performance of the proposed Training-Free Guidance (TFG) framework against existing methods across 16 different tasks and a total of 40 individual targets. For each task and target, the table shows the guidance validity (how well the generated samples align with the target property) and guidance fidelity (how well the generated samples resemble the true data distribution). The best and second-best performance for each cell is highlighted, along with the relative percentage improvement achieved by TFG over the best-performing existing method. The table offers a quantitative comparison of TFG’s effectiveness across diverse applications.
Full paper#