↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current LLM reasoning frameworks struggle with problems involving visual and spatial information. This paper addresses this limitation by proposing Vision-Augmented Prompting (VAP), a novel dual-modality reasoning approach. VAP leverages external drawing tools to synthesize images from textual problem descriptions, enabling LLMs to reason using both verbal and visual-spatial cues. The approach iteratively refines both the image and the reasoning chain, ultimately improving accuracy and robustness.
VAP’s effectiveness is demonstrated across four diverse tasks: solving geometry problems, Sudoku puzzles, time series prediction, and the travelling salesman problem. Extensive experiments show VAP’s superiority over existing LLM-based reasoning frameworks, highlighting the importance of multimodal reasoning in enhancing AI problem-solving. The self-alignment technique ensures the accuracy of the synthesized images and the alignment with the textual reasoning process, thereby improving robustness. Results indicate significant performance gains across all four tasks, showcasing VAP’s potential to advance the field of AI reasoning.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to enhance LLM reasoning by incorporating visual-spatial information, addressing a significant limitation of current LLM-based reasoning frameworks. Its findings demonstrate improved performance across diverse tasks, opening new avenues for research in multimodal reasoning and AI problem-solving. The methodology is clearly explained and could inspire further research into enhancing LLMs with additional modalities.
Visual Insights#

This figure shows an example of how different inputs affect the output of a geometry problem solver. The problem involves determining the number of intersection points between two circles and a line segment. The left side (‘a’) shows the text-only input, where the GPT-4 model gives an ambiguous answer. The right side (‘b’) adds a visual input (a graph showing the two circles and line segment). GPT-4 provides a correct answer with the visual input, which highlights the benefit of vision-augmented prompting.
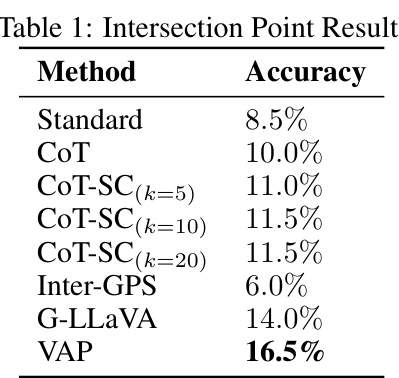
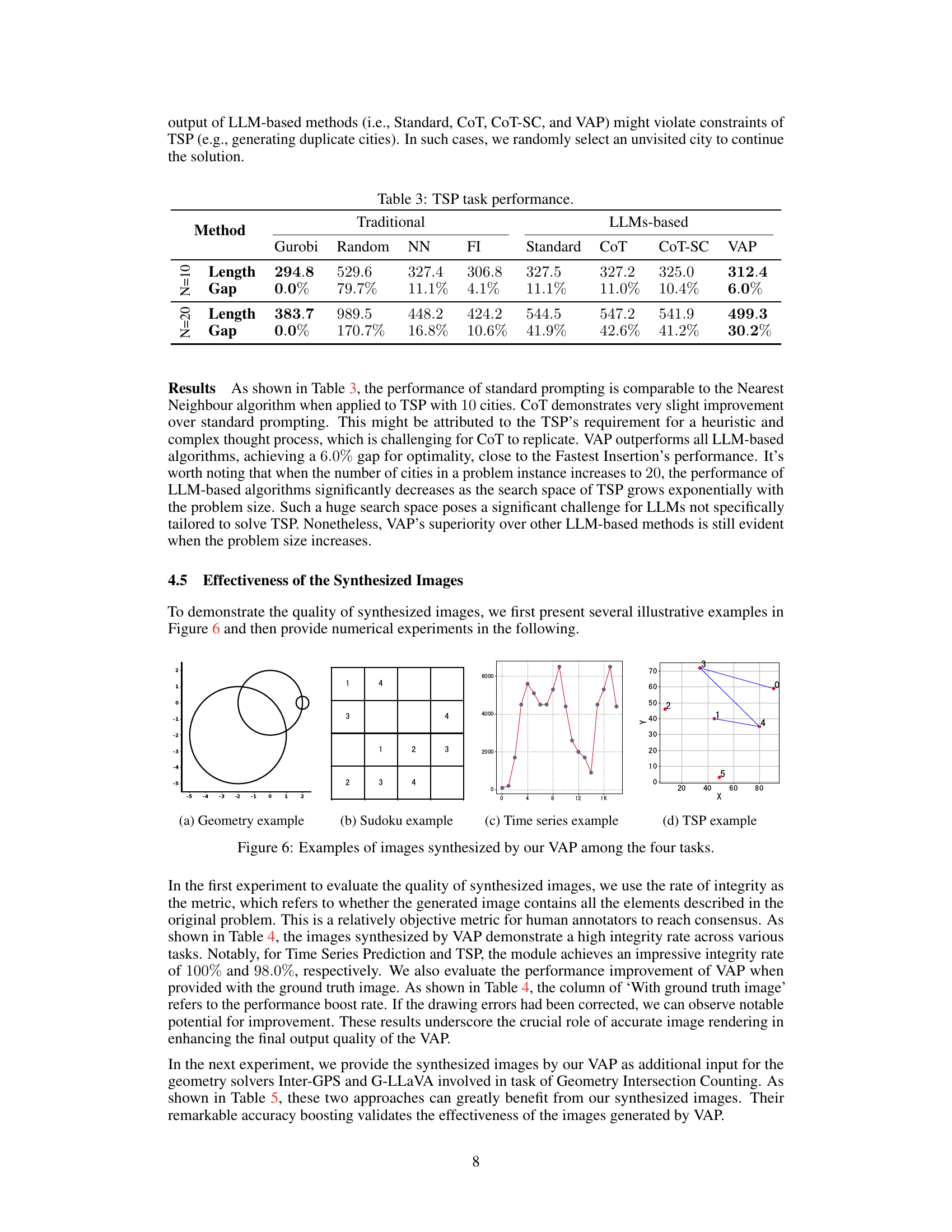
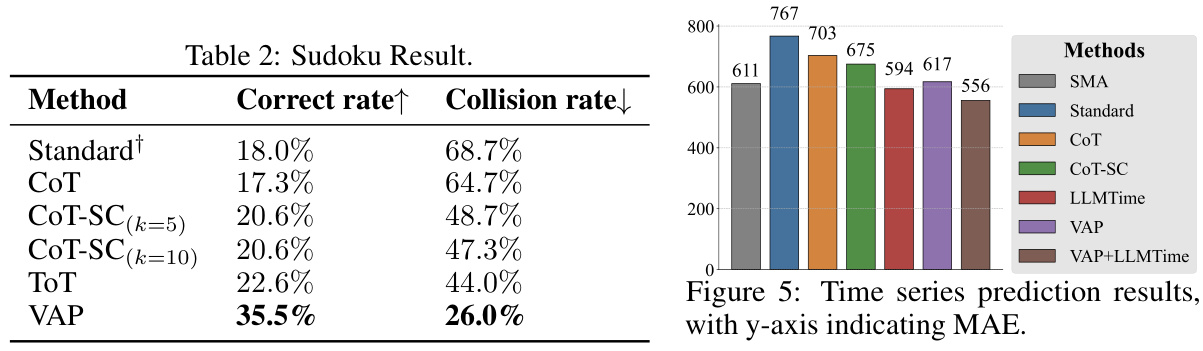
This table presents the accuracy results of different methods on a geometry intersection counting task. The methods compared include standard prompting, chain-of-thought prompting, self-consistent chain-of-thought prompting with varying sample sizes (k=5, 10, 20), task-specific baselines Inter-GPS and G-LLaVA, and the proposed Vision-Augmented Prompting (VAP) method. The accuracy is expressed as a percentage, indicating the success rate of each method in correctly determining the number of intersection points in the geometry problems.
In-depth insights#
Vision-Augmented Prompting#
The concept of “Vision-Augmented Prompting” presents a novel approach to enhance Large Language Model (LLM) reasoning capabilities by integrating visual and spatial information. This dual-modality framework addresses the limitations of current LLM reasoning methods, which primarily focus on textual data and struggle with problems requiring visual interpretation. The core idea is to automatically generate images from textual problem descriptions using external drawing tools, thus creating a richer, multimodal context for the LLM. This allows the LLM to leverage both verbal and visual reasoning, mimicking human cognitive processes more closely. The iterative refinement of the synthesized image through a chain-of-thought process further enhances the accuracy and robustness of the system. This technique showcases a unique synergy between LLMs and external tools. Finally, a self-alignment mechanism ensures that the image is relevant and consistent with the initial problem statement, further improving the overall effectiveness. The approach has shown promising results across diverse tasks, suggesting a significant advancement in LLM reasoning capabilities.
Dual-Modality Reasoning#
Dual-modality reasoning, integrating verbal and visual-spatial information, presents a significant advancement in artificial intelligence. Bridging the gap between these two modalities mirrors human cognitive processes, enabling more comprehensive understanding and problem-solving. Current LLM-based reasoning frameworks primarily focus on the verbal aspect, limiting their capabilities in tasks requiring visual or spatial interpretation. A dual-modality approach leverages the strengths of both modalities, such as the logical reasoning of language models and the visual pattern recognition of image processing. This synergistic combination holds immense potential for tackling complex real-world problems that demand integrated understanding of visual and textual cues. The challenges lie in effectively fusing these distinct data types, designing models that can seamlessly navigate both modalities, and developing evaluation metrics that capture the holistic performance of dual-modality systems. Future research should explore novel architectures and algorithms for efficient and accurate multimodal fusion, as well as the potential ethical implications of deploying such powerful AI systems.
LLM Reasoning Enhancement#
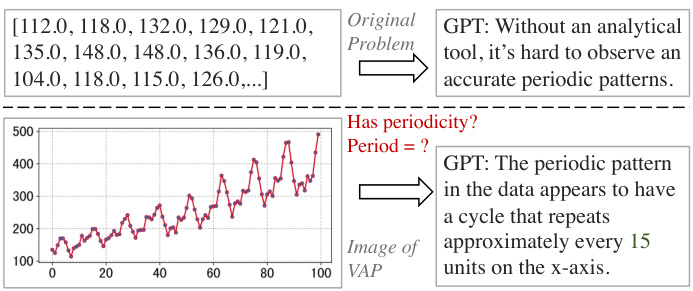
LLM reasoning enhancement is a rapidly evolving field focusing on improving the logical capabilities of large language models. Current methods often involve techniques like chain-of-thought prompting, which encourages LLMs to break down complex problems into smaller, manageable steps. However, a significant limitation of existing approaches is their reliance on purely textual data, neglecting the crucial role of visual and spatial information in human reasoning. Vision-augmented prompting (VAP) is an emerging technique aimed at bridging this gap, by incorporating visual inputs to enrich the context and guide the reasoning process. The integration of visual and spatial information significantly enhances the LLM’s ability to solve complex problems involving geometrical reasoning or image interpretation. This dual-modality approach holds promise for broader reasoning capabilities, but requires careful consideration of image generation and synthesis, and efficient multimodal reasoning frameworks to avoid efficiency bottlenecks. Future research directions include the exploration of diverse multimodal models and the development of effective techniques for seamless integration of verbal and visual reasoning within LLMs.
Multimodal Reasoning#
Multimodal reasoning, a rapidly developing field, aims to integrate information from multiple modalities, such as text, images, audio, and video, to enable more comprehensive and robust understanding and reasoning. This approach mimics human cognition, which naturally processes information from various sources simultaneously. Existing research shows promising results in tasks requiring integrated understanding of visual and textual data, but there are still challenges in effectively fusing diverse data types and handling ambiguity inherent in real-world scenarios. Future research directions should focus on developing more efficient and explainable multimodal models, addressing issues of bias and fairness inherent in multimodal data, and expanding the scope of application to more complex and real-world problems.
Ablation Study and Limits#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper, this would involve disabling or removing specific modules (e.g., the image synthesis module, iterative reasoning, or self-alignment) and evaluating the resulting performance. This helps to determine the relative importance of each component and isolate the impact of design choices. Limitations, often discussed alongside ablation studies, address shortcomings of the work. These might include methodological limitations (e.g., dataset bias, limited scope of tasks tested), as well as broader impacts related to the practical application of the research (e.g., computational cost, ethical concerns). A comprehensive analysis identifies the strengths and weaknesses of the proposed approach, highlighting its efficacy while acknowledging areas needing future work. Careful consideration of limitations is crucial for responsible research, promoting a balanced and accurate understanding of the technology’s potential and its shortcomings.
More visual insights#
More on figures
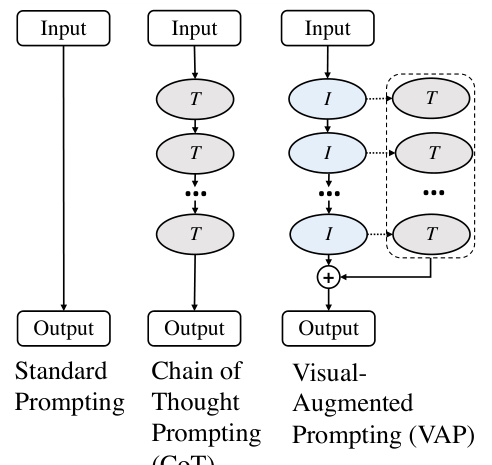
This figure compares three different prompting methods: standard prompting, chain-of-thought prompting, and the proposed vision-augmented prompting (VAP). Standard prompting provides the model with the input and expects a direct answer. Chain-of-thought prompting guides the model through a series of intermediate reasoning steps. VAP extends the chain-of-thought approach by incorporating visual information, using an image synthesized from the input text, to enhance the model’s reasoning process and ultimately arrive at a better answer.

This figure showcases the results of solving a geometry problem using two different input methods: text-only and text with image. The text-only input resulted in an ambiguous answer, while the text-with-image input produced the correct, precise answer. This highlights the benefit of incorporating visual information into the problem-solving process, analogous to how humans often use diagrams to aid in solving geometry problems.
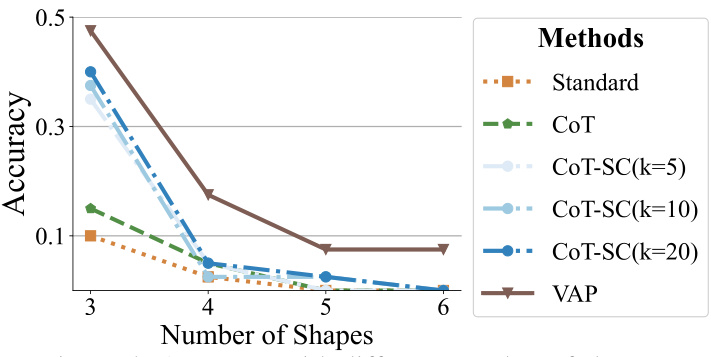
The figure shows the accuracy of different methods (Standard Prompting, Chain of Thought Prompting, Self-Consistent Chain of Thought Prompting with different sample sizes (k=5, 10, 20), and Vision-Augmented Prompting (VAP)) on the Geometry Intersection Counting task across varying numbers of shapes. The x-axis represents the number of shapes involved in the problem, and the y-axis indicates the accuracy achieved by each method. The plot reveals that VAP consistently outperforms other baselines, especially as the problem complexity increases with the number of shapes.
This figure shows a geometry problem solved using two different input methods. The first uses only text to describe the problem; GPT-4’s answer is vague and incomplete. The second includes both text and an automatically generated image; in this case, GPT-4’s answer is correct and precise. This illustrates the benefit of augmenting the prompt with visual information to improve the accuracy of LLM reasoning.

This figure shows an example of a geometry problem solved using two different input methods: text-only and text with a synthesized image. The text-only input leads to an ambiguous answer, while the image-augmented input results in an accurate answer. This highlights the benefit of incorporating visual information into problem-solving, especially for geometry problems.

This figure shows an example of how using visual input in addition to textual input can improve the accuracy of solving a geometry problem. The example problem is to determine the number of intersection points between two circles and a line segment. The image on the left (a) shows the problem described purely with text. The GPT-4 model produces an ambiguous answer. The image on the right (b) shows the same problem, but this time with an accompanying image generated by the model. GPT-4’s answer is now accurate and precise because it can leverage the visual cues in the image.

This figure shows an example of solving a geometry problem using two different input methods: text-only and text with a corresponding image. The text-only input resulted in an ambiguous answer from GPT-4, while the input with the image resulted in a more accurate and complete answer. This highlights the benefit of incorporating visual information for improved reasoning.
This figure shows an example of a geometry problem solved using both text-only input and text input with a corresponding image. The text describes a geometry problem involving circles and a line. The left image shows the text-only input, producing an ambiguous answer. The right image includes a synthesized diagram from the description, allowing the model (GPT-4) to answer correctly. This illustrates how visual information enhances problem solving and is analogous to human cognitive reasoning.
This figure demonstrates how the addition of visual input improves the accuracy of LLM-based reasoning. The same geometry problem is presented: finding the number of intersections between a circle, another circle, and a line. When only textual input is given, GPT-4 provides an ambiguous and incomplete answer. However, when the same problem is presented with both text and a corresponding image, GPT-4 provides the correct answer, highlighting the value of integrating visual and spatial information for improved reasoning accuracy.
More on tables

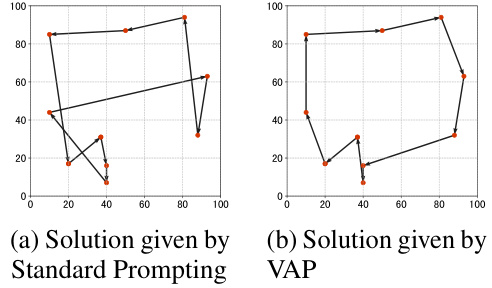
This table presents the performance of different methods on the Traveling Salesman Problem (TSP) with 10 and 20 cities. It compares traditional TSP solvers (Gurobi, Random, Nearest Neighbor, and Fastest Insertion) against LLM-based approaches (Standard Prompting, Chain-of-Thought, CoT with Self-Consistency, and Vision-Augmented Prompting). The metrics used for comparison are the average path length and the optimality gap (percentage difference from the optimal solution). The results show that VAP outperforms other LLM-based methods, achieving a smaller optimality gap, particularly when the number of cities increases.

This table presents the integrity of images synthesized by the Vision-Augmented Prompting (VAP) framework across four different tasks: Geometry Intersection Counting, Sudoku Puzzle, Time Series Prediction, and Travelling Salesman Problem. The ‘Integrity’ column shows the percentage of successfully generated images that correctly represent the described problem. The ‘With Ground Truth Image’ column shows the percentage improvement in accuracy when the ground truth image is used instead of the VAP-generated image. This demonstrates the impact of image accuracy on the overall performance of the VAP framework.

This table presents the results of an ablation study conducted to evaluate the impact of each component (high-level planning, iterative reasoning, and self-alignment) of the Vision-Augmented Prompting (VAP) framework on four different reasoning tasks: Geometry Intersection Counting, Sudoku Puzzle, Time Series Prediction, and Travelling Salesman Problem. The results show the performance of the full VAP model and the performance when each component is removed. It helps to understand the contribution of each module to the overall performance of the VAP system.

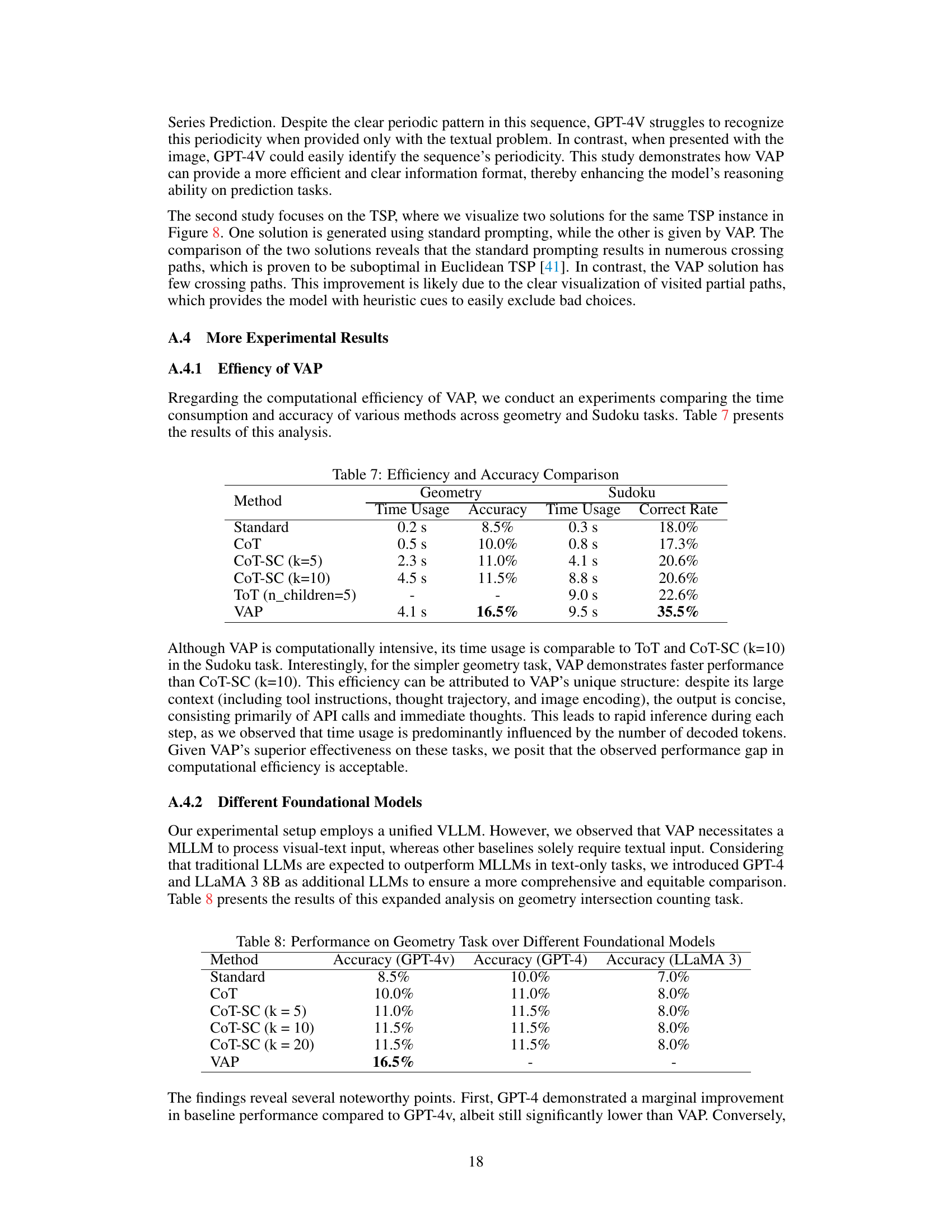
This table presents a comparison of the time usage and accuracy of various methods across geometry and Sudoku tasks. It shows that while VAP has a higher time usage than some baselines, it significantly improves accuracy in both tasks. The table highlights the trade-off between computational cost and accuracy.

This table compares the accuracy of different reasoning methods (Standard, CoT, CoT-SC, VAP) on a geometry intersection counting task using three different foundational LLMs (GPT-4v, GPT-4, LLaMA 3). It shows that VAP consistently outperforms other methods across all three LLMs.
Full paper#