↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Image pyramids are commonly used in computer vision to extract multi-scale features, but they’re computationally expensive because they use the same large model for all resolutions. This paper addresses this by proposing a novel architecture called Parameter-Inverted Image Pyramid Networks (PIIP). The core idea is to use models of different sizes to process different image resolutions; high-resolution images are handled by smaller models, while lower resolution images are handled by larger models. This approach balances computational efficiency and performance.
PIIP also incorporates a feature interaction mechanism to effectively combine features from different scales. Extensive experiments show that PIIP significantly outperforms existing methods in object detection, segmentation, and classification tasks while drastically reducing computational costs. The approach’s effectiveness is further validated when applied to a large-scale vision foundation model, where it achieved a performance boost with substantial computational savings. This demonstrates the technique’s potential for improving future vision computing tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision due to its significant improvement in efficiency and performance of image pyramid networks. It provides a novel approach to handling multi-scale images, which is a core aspect of many vision tasks, while addressing the significant computational demands of existing methods. The proposed technique also opens new avenues for optimizing large-scale vision models, making it highly relevant to current research trends and future development in the field.
Visual Insights#

This figure illustrates five different approaches to incorporating image pyramids into a neural network for image processing. (a) shows a simple network without multi-scale processing. (b) and (c) depict traditional image pyramid approaches that use the same large model at all resolutions, leading to inefficiency. (d) showcases a parameter-direct approach, where high-resolution images are processed by a large model, also resulting in high computational cost. Finally, (e) presents the proposed Parameter-Inverted Image Pyramid Network (PIIP), which uses smaller models for higher-resolution images and larger models for lower-resolution images, optimizing for computational efficiency without sacrificing performance. The key idea behind PIIP is that features at different resolutions are complementary and can be efficiently fused.
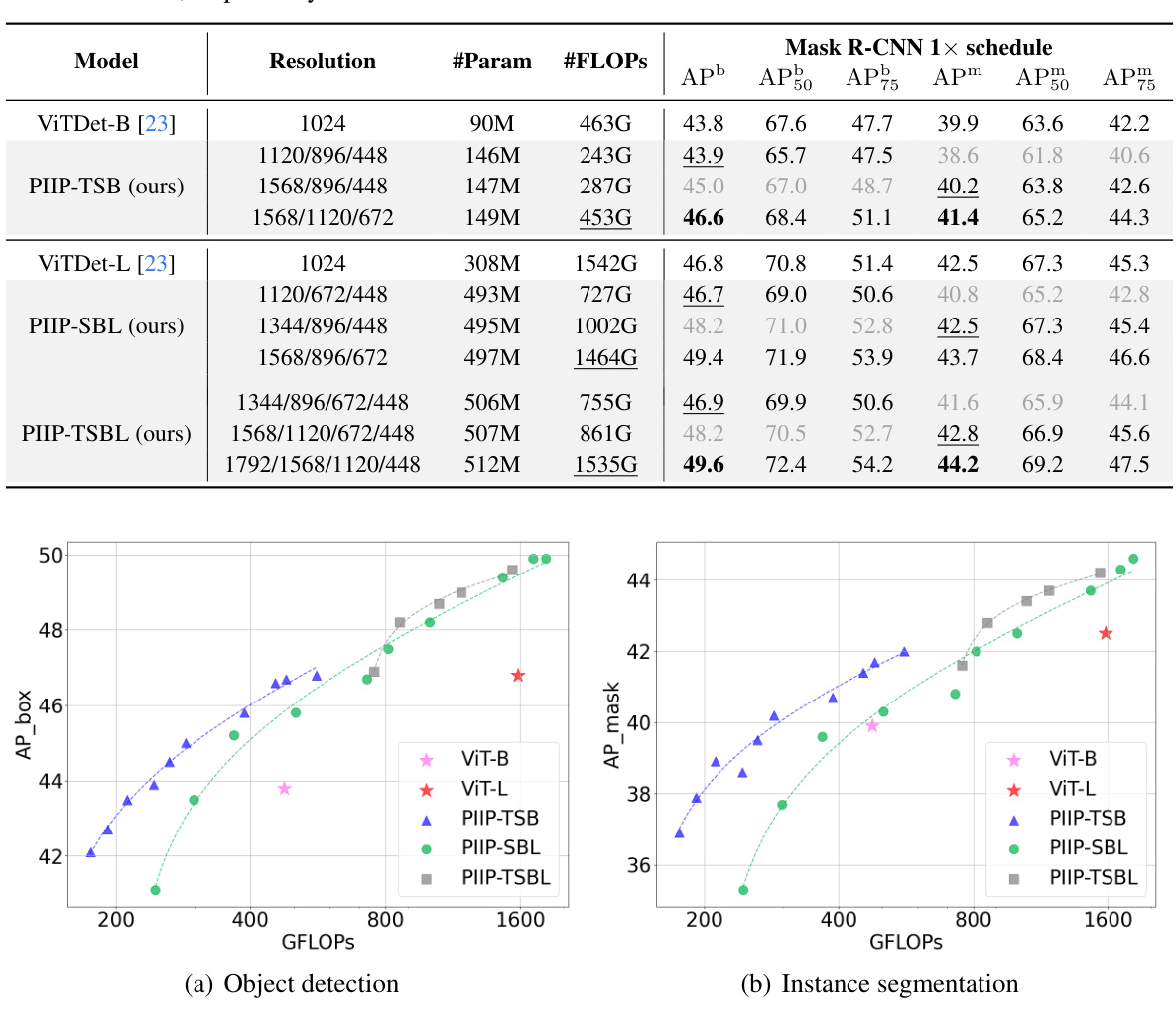
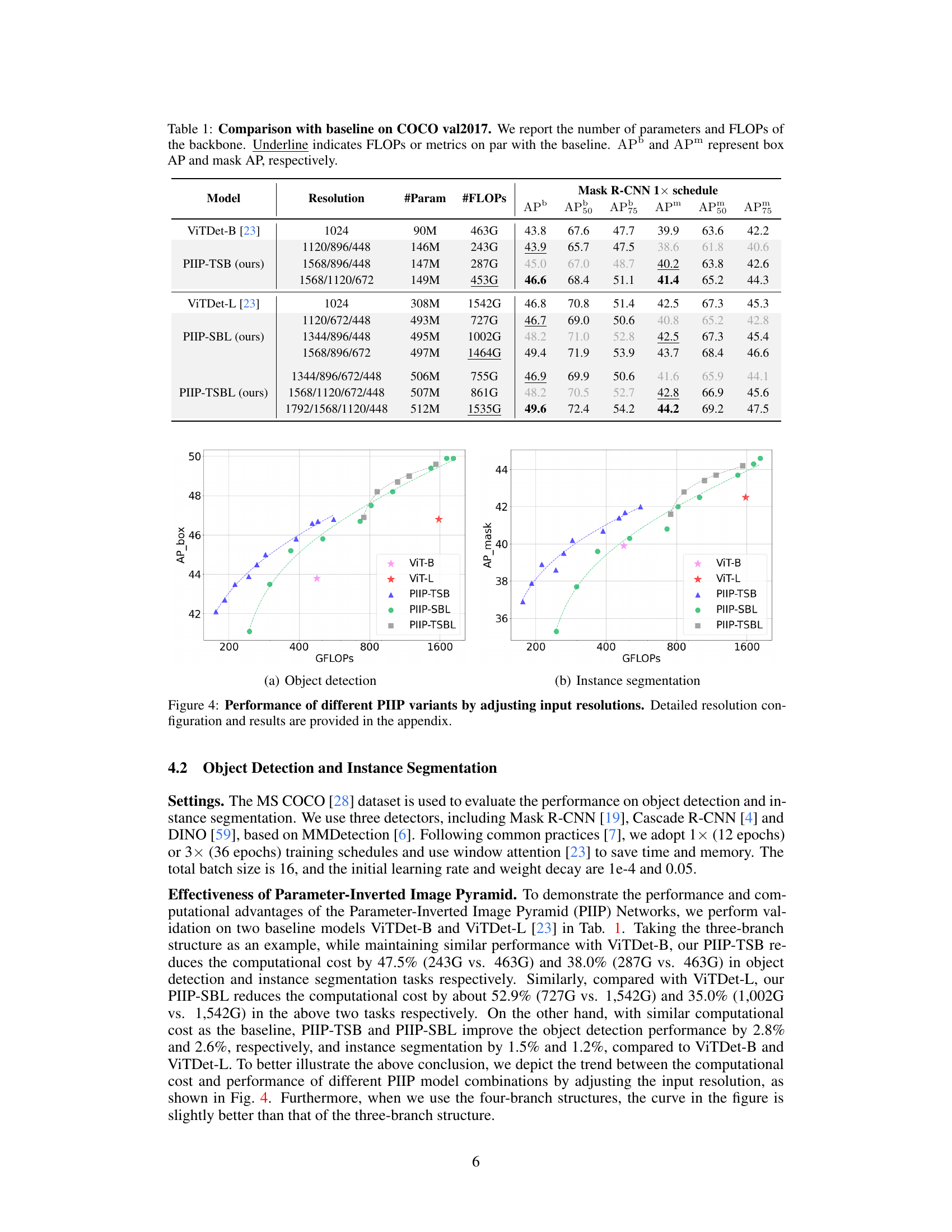
This table compares the performance of the proposed PIIP networks with baseline models (ViTDet-B and ViTDet-L) on the COCO val2017 dataset for object detection and instance segmentation. It shows the number of parameters, FLOPs (floating point operations), and metrics (AP50, APm) for each model. The underlined values indicate where PIIP achieves comparable or better performance than the baseline while using significantly fewer FLOPs, demonstrating the efficiency of the proposed method.
In-depth insights#
Inverted Pyramid Nets#
Inverted Pyramid Nets represent a significant departure from traditional image pyramid approaches in computer vision. Instead of processing all image resolutions with a single, large model, Inverted Pyramid Nets utilize models of varying sizes, matching smaller networks to higher-resolution images and larger networks to lower-resolution images. This strategy is particularly effective because it leverages the inherent properties of different scales: high-resolution images benefit from simpler models focusing on fine detail, while lower-resolution images gain from the richer contextual information provided by larger, more complex models. This inverse relationship optimizes computational efficiency without compromising performance, resulting in faster inference speeds and reduced resource consumption. The core innovation is to intelligently balance model complexity and image resolution, allowing for a more efficient multi-scale feature extraction process. Furthermore, the incorporation of a feature interaction mechanism allows the network to effectively integrate information from all scales, creating a more comprehensive representation than would be possible with independently processed images. This approach is particularly promising for large vision foundation models, where computational cost is a major bottleneck, demonstrating significant performance gains with considerable computational savings.
Multi-Scale Feature Fusion#
Multi-scale feature fusion is a crucial technique in computer vision for effectively integrating information from different levels of an image pyramid. The core idea is to combine features extracted at various scales (e.g., low, medium, and high resolution) to achieve richer, more robust representations. Different fusion strategies exist, including early fusion (concatenating features before further processing), late fusion (combining features after independent processing), and hierarchical fusion (combining features in a layered manner). The choice of strategy depends on the specific task and the nature of the features involved. Successful multi-scale fusion often necessitates addressing challenges such as feature misalignment across scales and computational efficiency, requiring careful design of fusion modules. Effective fusion modules must appropriately weight and combine information from different scales, taking into account the relative importance of different spatial and semantic contexts. Ultimately, effective multi-scale fusion boosts performance on downstream tasks such as object detection, semantic segmentation, and image classification by leveraging comprehensive feature representations.
Computational Efficiency#
The research paper highlights computational efficiency as a critical design goal. Traditional image pyramid methods are computationally expensive due to processing multiple resolutions using the same large model. The proposed Parameter-Inverted Image Pyramid Networks (PIIP) address this by employing smaller models for higher-resolution images and larger models for lower-resolution images. This parameter inversion strategy strikes a balance between computational cost and performance. Feature interaction mechanisms ensure that different resolution features effectively complement each other, maximizing information integration with minimal redundancy. Experiments demonstrate that PIIP achieves superior performance in various vision tasks while significantly reducing computational costs, even when applied to large-scale foundation models. The paper also analyzes model variations and the number of interactions, offering practical guidelines for designing computationally efficient image pyramid networks. The effectiveness of PIIP is strongly validated through comparative analysis with existing image pyramid techniques and single-branch networks, showcasing its potential as a new direction for future vision computing tasks.
Ablation Studies#
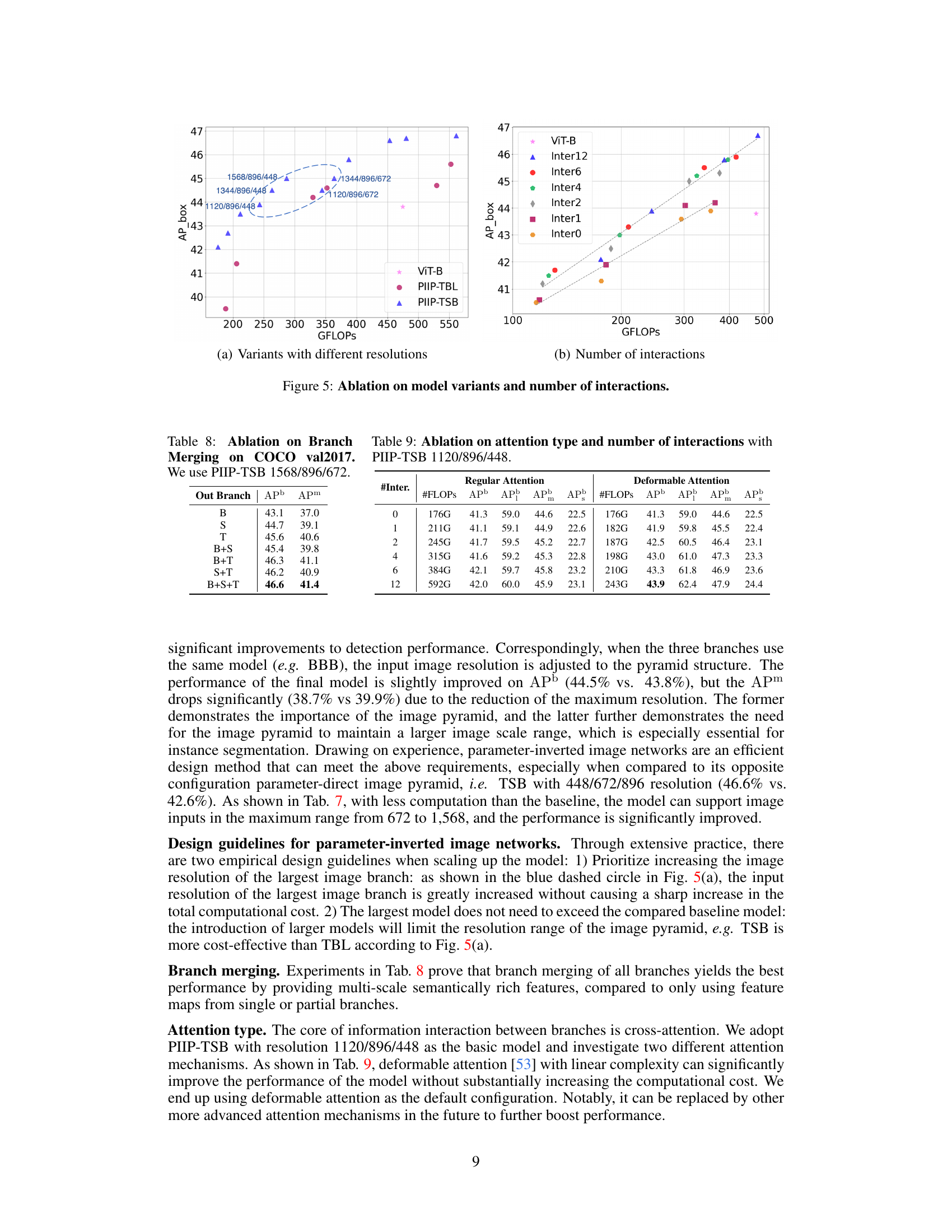
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, this section would meticulously detail experiments showing the impact of removing or altering specific aspects, such as different modules, parameters, or training techniques. A strong ablation study demonstrates a causal relationship between the components and the overall performance. It builds confidence in the design choices by isolating the effects of individual parts and helps to understand their relative importance. Well-designed ablation studies should include multiple variations and clear quantitative results, providing evidence to support the design decisions made in the main model. A compelling ablation study will showcase which parts of the model are essential and which are less important. Furthermore, the results may reveal unexpected interactions between modules, highlighting areas where additional investigation might be fruitful. The ultimate goal of ablation studies is to provide clarity regarding the model’s architecture and its effectiveness.
Future Directions#
Future research directions stemming from this Parameter-Inverted Image Pyramid Network (PIIP) research could explore optimizing the interaction module for even greater multi-scale feature fusion, potentially using more advanced attention mechanisms. Investigating different model architectures beyond the Transformer-based networks used here, perhaps incorporating CNNs or hybrid approaches, would broaden the applicability of PIIP. Furthermore, extending PIIP to handle video data would unlock new possibilities for spatio-temporal feature extraction. A key area for development is reducing memory consumption, as larger models and multiple branches increase memory demands. Finally, thorough research into transfer learning and pre-training strategies specific to the PIIP architecture could unlock its full potential and lead to even more efficient and high-performing vision systems.
More visual insights#
More on figures

This figure illustrates the architecture of the Parameter-Inverted Image Pyramid Network (PIIP). It shows three branches processing images at different resolutions. Higher-resolution images are processed by smaller models, while lower-resolution images are processed by larger models. Interaction units connect the branches, allowing features from different scales to be integrated. A final branch merging step combines the features from all branches to produce the final output. This design balances computational efficiency and performance.
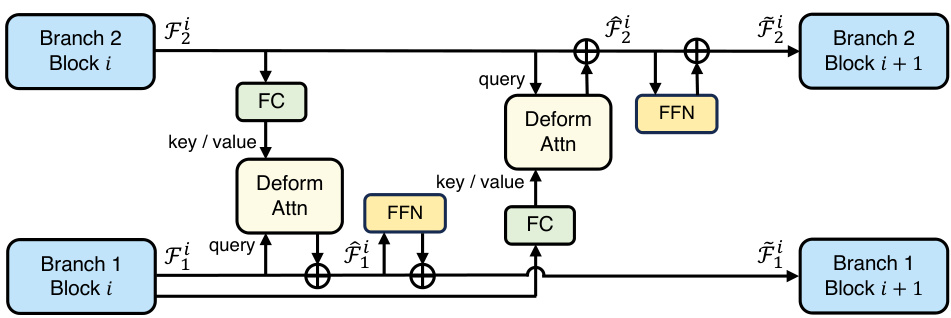
This figure shows the detailed architecture of a cross-branch interaction unit used in the Parameter-Inverted Image Pyramid Networks (PIIP). It details the process of feature fusion between two adjacent branches (Branch 1 and Branch 2) in the PIIP network. Each unit comprises two deformable cross-attention mechanisms and feed-forward networks (FFN). The first cross-attention takes the output (Fᵢ₁) of Branch 1’s i-th block as a query, and the output (Fᵢ₂) of Branch 2’s i-th block as keys and values. A linear layer (FC) projects the dimensions. This process is repeated with a second cross-attention, switching the query and key/value roles between the two branches. Each cross-attention operation is followed by an FFN for channel-wise feature fusion. The resulting features, Fᵢ₁ and Fᵢ₂, are then fed into the subsequent blocks of their respective branches.

This figure illustrates the overall architecture of the Parameter-Inverted Image Pyramid Networks (PIIP). It shows how multi-resolution branches, each processing images of a different resolution, are used. Smaller models are employed for higher resolution images, balancing computational efficiency. Interaction Units connect the branches, allowing feature fusion between different scales. Finally, a branch merging module integrates the features from all branches into a single output. The figure highlights the efficiency achieved by using different sized pre-trained models for different resolutions, creating an efficient image pyramid.

This figure shows the performance of different interaction directions in the PIIP network. Five different interaction methods were compared, varying the direction of information flow between branches at different resolutions. The results demonstrate that the bidirectional connections between adjacent branches achieve the best balance between computational cost and performance.
More on tables
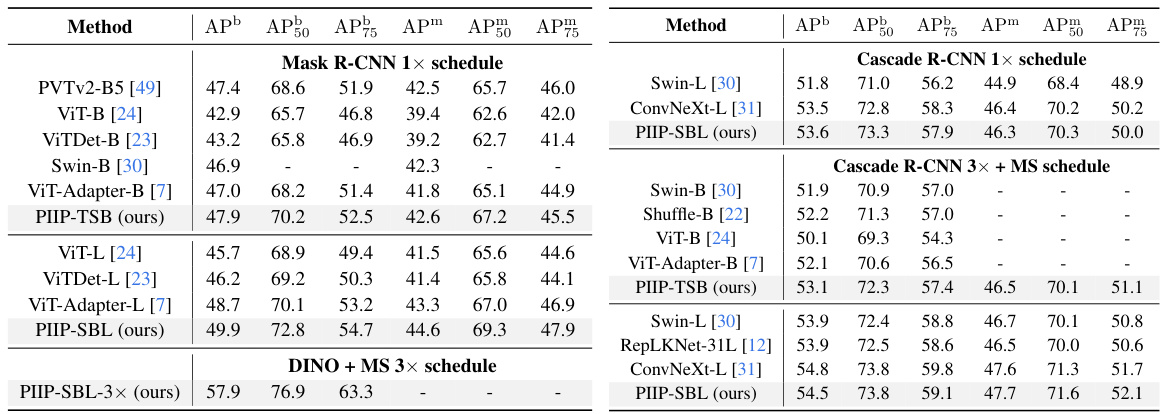
This table compares the proposed PIIP method with baseline methods (ViTDet-B and ViTDet-L) on the COCO val2017 dataset for object detection and instance segmentation. It shows the number of parameters, FLOPs (floating point operations), and performance metrics (AP50, AP75, AP, AP50m, AP75m, APm) for each model. The underlined values highlight results comparable to the baselines, demonstrating the efficiency gains of PIIP with comparable or even improved accuracy.
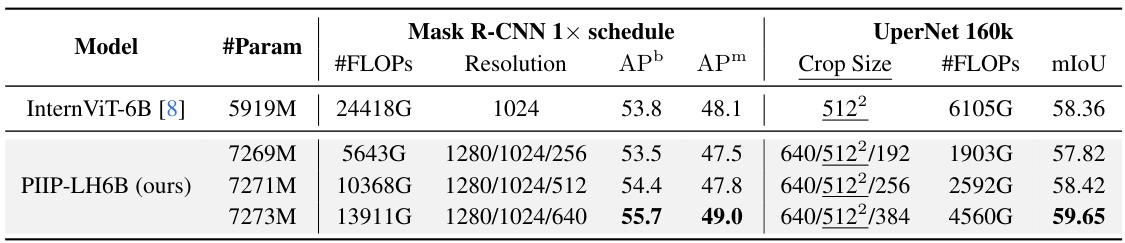
This table presents the results of experiments conducted using the InternViT-6B model. It compares the performance of the original InternViT-6B model with the PIIP-LH6B model (the proposed Parameter-Inverted Image Pyramid network applied to InternViT-6B) across object detection and semantic segmentation tasks. The table shows the number of parameters, FLOPs, resolution, APb (Average Precision for bounding boxes), APm (Average Precision for masks), crop size, and mIoU (mean Intersection over Union). Different configurations of the PIIP-LH6B model are evaluated, each with varying input resolutions, demonstrating its impact on performance and computational cost. The results highlight the improved efficiency and performance of PIIP-LH6B compared to the baseline model.
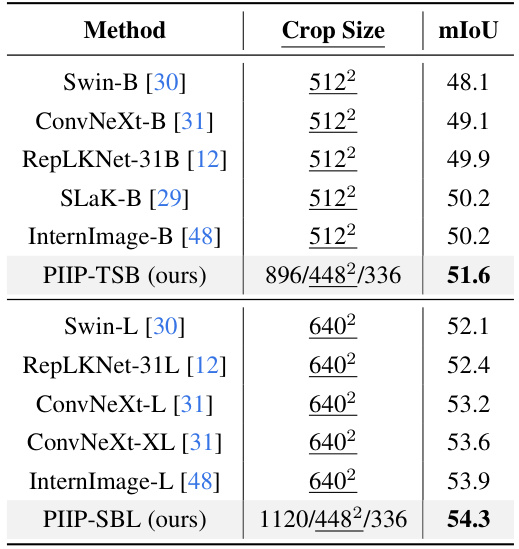
This table compares the performance of different semantic segmentation models on the ADE20K dataset using the UperNet framework. The models compared include Swin-B, ConvNeXt-B, RepLKNet-31B, SLaK-B, InternImage-B, PIIP-TSB, Swin-L, RepLKNet-31L, ConvNeXt-L, ConvNeXt-XL, InternImage-L, and PIIP-SBL. The table shows the mIoU (mean Intersection over Union) achieved by each model and the crop size used for each model. The results demonstrate the performance of the PIIP models compared to state-of-the-art baselines.
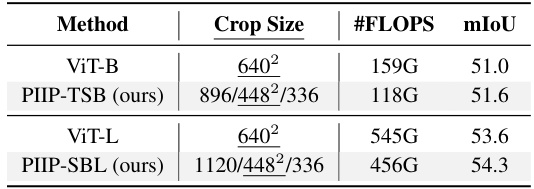
This table presents a comparison of semantic segmentation performance on the ADE20K dataset using the UperNet model. It compares different backbone networks, including Swin-B, ConvNeXt-B, RepLKNet-31B, SLaK-B, and InternImage-B, against the proposed PIIP-TSB and PIIP-SBL methods. The table shows the crop size used for each model, the number of FLOPs (floating point operations), and the mIoU (mean Intersection over Union) score achieved, demonstrating the efficiency and performance gains of PIIP.

This table presents a comparison of image classification performance on the ImageNet dataset between different models. It shows the resolution, number of FLOPs (floating point operations), and top-1 accuracy for each model. The baseline model’s results are shown for comparison, and the underlined values indicate models that achieve comparable performance while potentially using fewer FLOPs (indicating better computational efficiency).

This table compares the performance of the proposed Parameter-Inverted Image Pyramid Networks (PIIP) with baseline models (ViTDet-B and ViTDet-L) on the COCO val2017 dataset for object detection and instance segmentation tasks. It shows the number of parameters, FLOPs (floating-point operations), and the average precision (AP) metrics for both box and mask predictions for different models. The results demonstrate that PIIP achieves comparable or better performance with significantly reduced computational cost compared to the baselines.
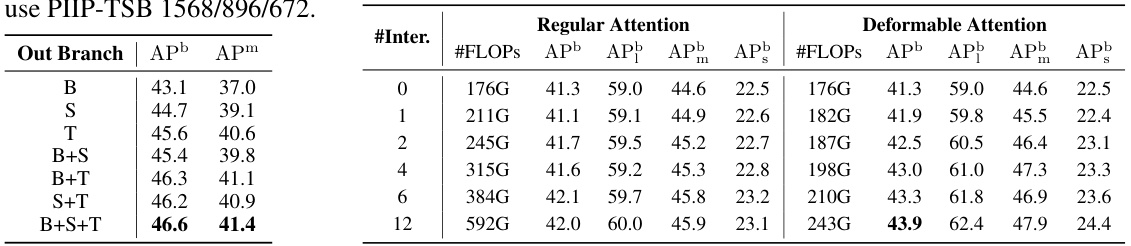
This ablation study investigates the impact of different attention mechanisms (regular vs. deformable) and varying numbers of cross-branch interactions on the performance of the PIIP-TSB model with a specific resolution configuration (1120/896/448). The table shows the FLOPs, APb (average precision for bounding boxes), APm (average precision for masks), AP50, and AP75 metrics for each configuration, allowing for comparison of performance and computational cost.

This table compares the performance of the proposed PIIP network with baseline models (ViTDet-B and ViTDet-L) on the COCO val2017 dataset for object detection and instance segmentation tasks. It shows the number of parameters, FLOPs (floating point operations), box AP (average precision), and mask AP for each model. The results demonstrate PIIP’s superior performance and computational efficiency compared to the baselines.
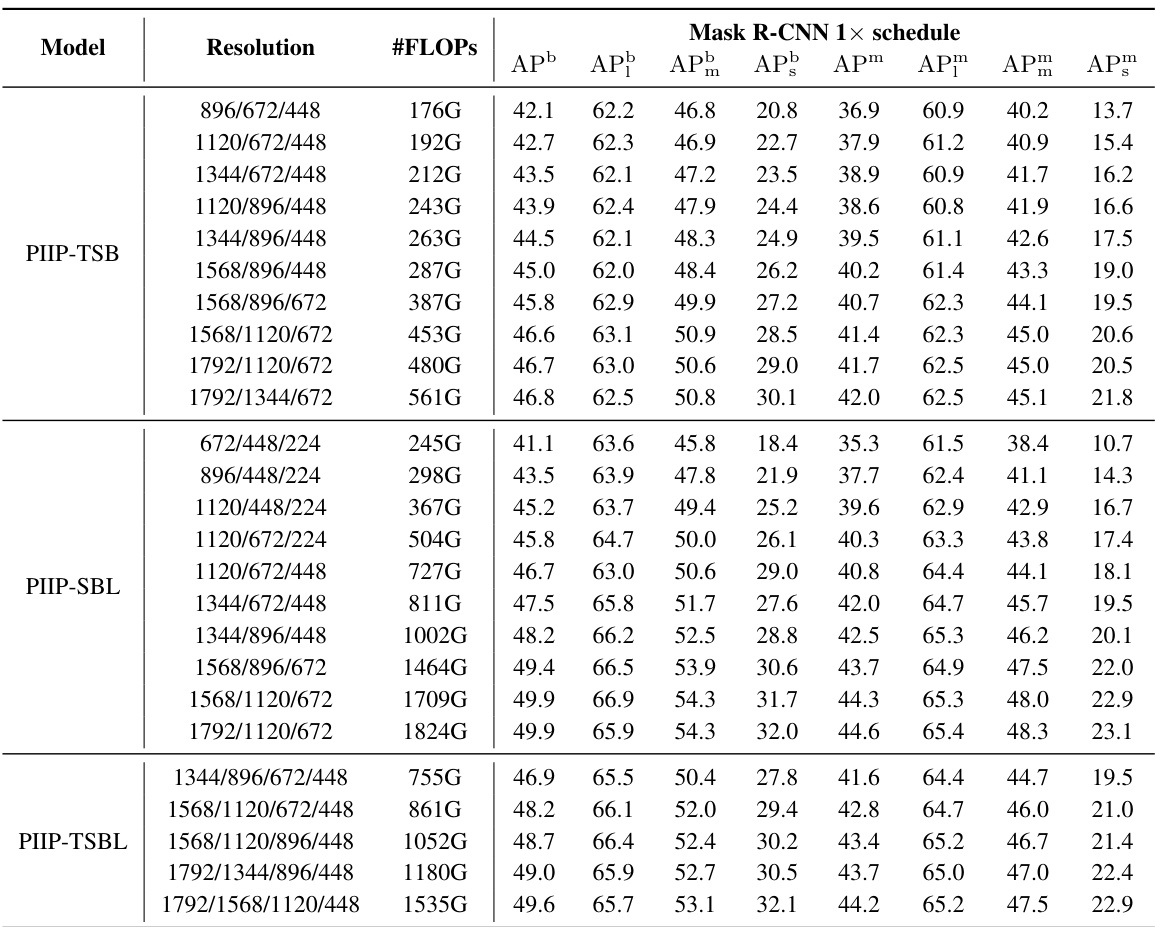
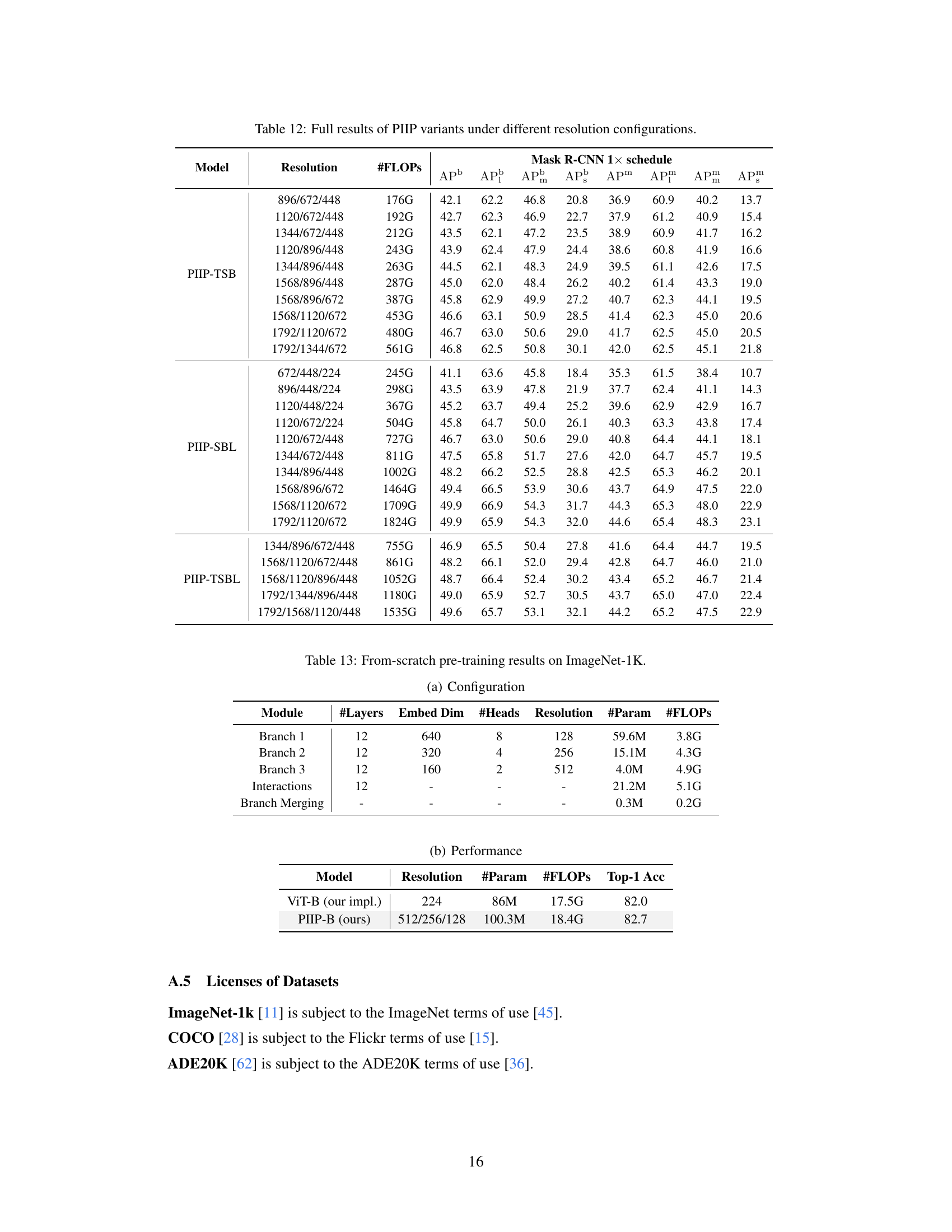
This table presents the complete results of experiments using different variations of the Parameter-Inverted Image Pyramid (PIIP) network with varying input resolutions. The performance metrics (APb, AP, APm) for object detection and instance segmentation are shown for various combinations of ViT model sizes and image resolutions using the Mask R-CNN evaluation protocol. Different PIIP configurations (PIIP-TSB, PIIP-SBL, PIIP-TSBL) are included, indicating different numbers of branches and the specific ViT models (T, S, B, L) used in each branch.
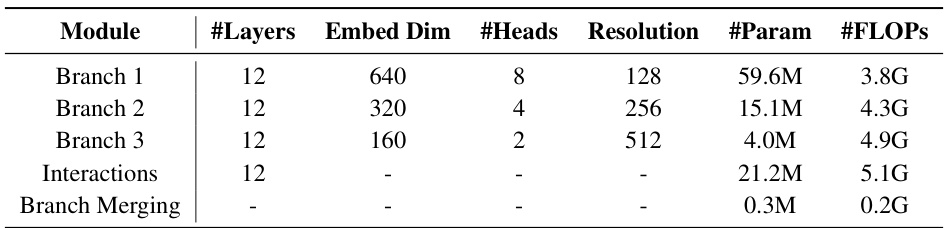
This table presents the architecture configuration and performance of a three-branch PIIP network trained from scratch on ImageNet-1K. It details the number of layers, embedding dimension, number of heads, resolution, number of parameters, and FLOPs for each branch (Branch 1, Branch 2, Branch 3), the interaction modules, and the branch merging module. The table also shows the resulting Top-1 accuracy. This configuration differs from experiments in the main paper where pretrained models were used.

This table shows the results of training a from-scratch model PIIP-B (Parameter-Inverted Image Pyramid) on the ImageNet-1K dataset. It compares the performance of PIIP-B with ViT-B (Vision Transformer). The table presents the model configuration, including the number of layers, embedding dimension, number of heads, resolution, number of parameters, number of FLOPs (floating-point operations), and top-1 accuracy. PIIP-B demonstrates a competitive performance compared to ViT-B while showcasing the effectiveness of the parameter-inverted image pyramid approach in from-scratch pre-training.
Full paper#