↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Existing methods for improving zero-shot vision models rely on labeled data for prompt optimization, which is expensive and time-consuming. Additionally, pre-trained vision-language models often suffer from label bias due to imbalanced training data, leading to suboptimal performance. These limitations motivate the need for a label-free approach.
The proposed Frolic framework addresses these issues by learning distributions over prompt prototypes to capture diverse visual representations and using a confidence-matching technique to fuse these with original model predictions. Furthermore, it corrects label bias using a label-free logit adjustment. Experiments on 16 datasets show that Frolic outperforms state-of-the-art methods, particularly demonstrating significant improvements in zero-shot accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in zero-shot learning and computer vision. It introduces a novel, label-free framework that significantly improves the performance of vision-language models, addressing limitations of existing methods. The training-free and hyperparameter-free nature makes it easily applicable and scalable, while the logit adjustment for bias correction opens new avenues for improving fairness and robustness in model training. This work is highly relevant to current research trends in prompt engineering and bias mitigation, offering a significant step toward more practical and effective zero-shot learning.
Visual Insights#
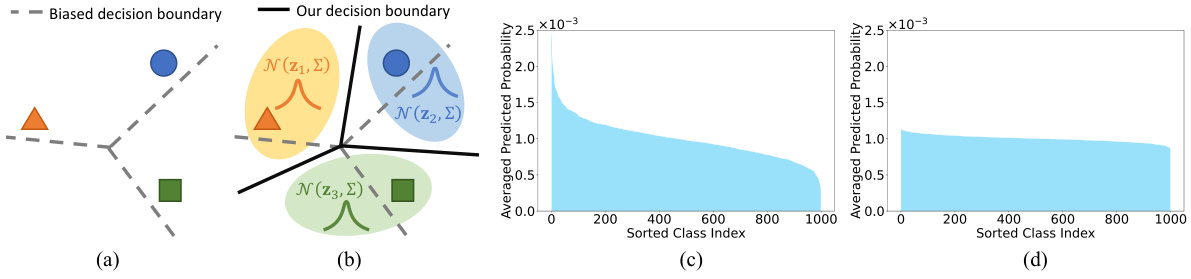
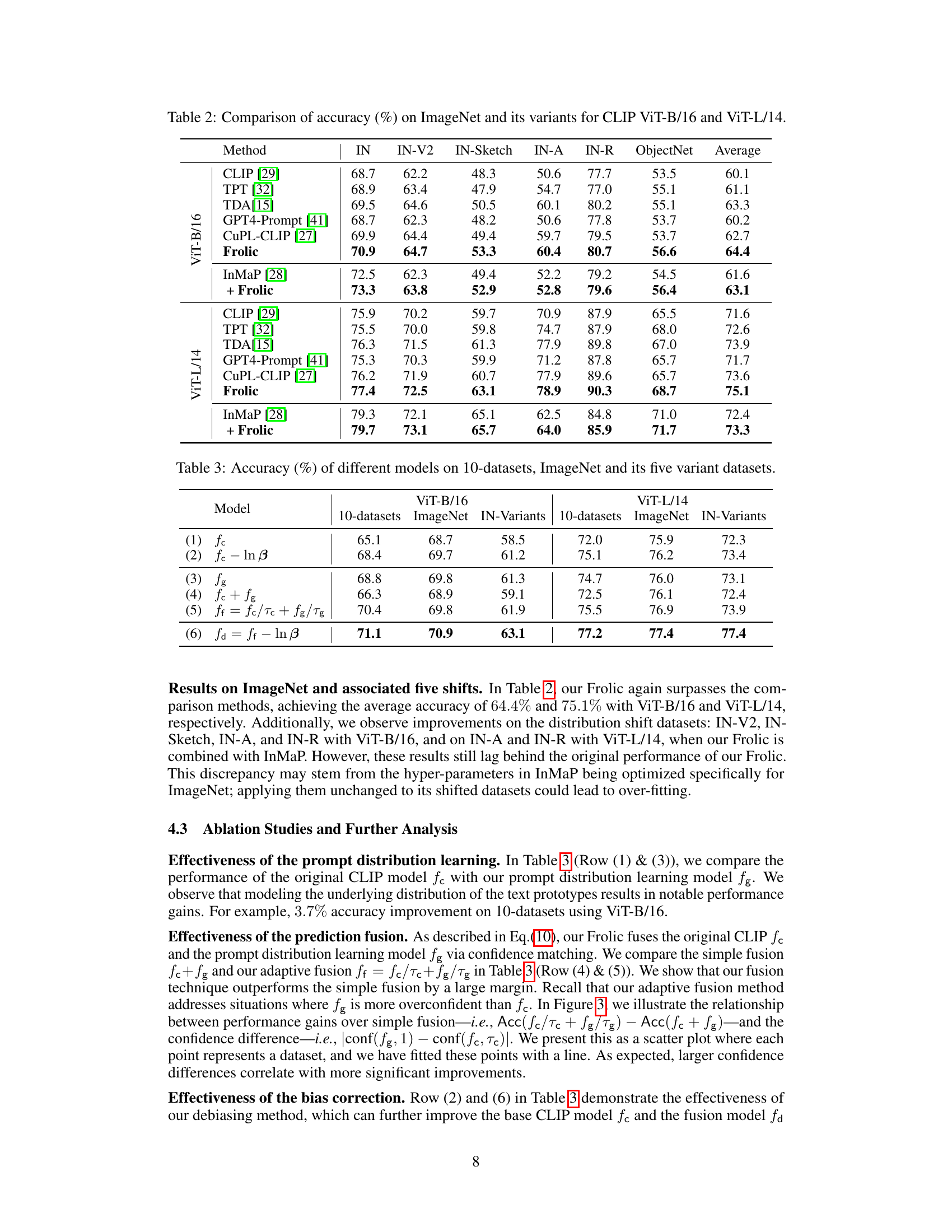
This figure illustrates the core idea of the proposed method, Frolic, which is to learn the distribution of prompt prototypes for each class and correct the label bias of the pre-trained CLIP model. Subfigure (a) shows the decision boundary of existing zero-shot models, which is biased due to the imbalanced pre-training data. Subfigure (b) shows how Frolic learns the distributions over prompt prototypes for each class. Subfigures (c) and (d) compare the average probability predictions of the original CLIP and Frolic on ImageNet, respectively, demonstrating that Frolic corrects the label bias and provides more balanced predictions.

This table presents a comparison of the accuracy achieved by different zero-shot vision models on 10 benchmark datasets. The models are evaluated using two different CLIP backbones: ViT-B/16 and ViT-L/14. The table allows for a direct comparison of performance across various methods and backbones, showing the relative effectiveness of each in enhancing zero-shot capabilities.
In-depth insights#
Bias Correction#
The concept of bias correction is crucial in the paper, addressing the inherent biases present in pre-trained vision-language models. The model’s training on imbalanced web-scale data leads to skewed predictions, favoring certain classes over others. The authors ingeniously tackle this by introducing a label-free logit adjustment method. Unlike existing techniques that rely on labeled data or access to the pre-training dataset, their approach corrects label bias using only unlabeled downstream data. This is achieved by estimating a label distribution directly from the unlabeled test data using a clever linear equation system, eliminating the need for hyperparameter tuning or external labeled data, representing a major advance in bias mitigation strategies for zero-shot models. The label-free nature is particularly important, as it enhances the scalability and practicality of the method, making it applicable to numerous scenarios where labeled data may be scarce or expensive to acquire. The effectiveness of this label-free bias correction is demonstrated by significant performance improvements across several benchmark datasets.
Prompt Learning#
Prompt learning, within the context of vision-language models, is a powerful technique to significantly enhance zero-shot performance. It focuses on crafting effective text prompts that guide the model to better understand and classify images. The core idea is to leverage the model’s inherent ability to align visual and textual representations, moving beyond simple, generic descriptions. Methods range from hand-crafted prompts, relying on human expertise, to automatic prompt generation using language models, which offers scalability but potential variability in quality. Furthermore, learning prompts directly from downstream data via optimization methods can tailor prompts for specific datasets but necessitate labeled data, thereby increasing the annotation cost. A key advancement is learning distributions of prompts instead of single prototypes. This captures the natural variability in visual representations and improves robustness and generalization. Label-free prompt distribution learning represents a major step forward, enabling the learning of diverse prompts without needing labeled data, dramatically reducing the cost and effort while enhancing performance. Overall, prompt learning techniques are constantly evolving, pushing the boundaries of zero-shot capabilities for vision-language models.
Zero-Shot Boost#
A hypothetical research paper section titled ‘Zero-Shot Boost’ would likely explore methods for significantly enhancing the performance of zero-shot learning models. This would involve in-depth analysis of current limitations, such as the reliance on pre-trained models and their inherent biases. The core of the section would likely detail novel techniques to improve zero-shot capabilities. These techniques might involve innovative prompting strategies, perhaps learning optimal prompts from unlabeled data, or developing new ways to fuse or calibrate the outputs of multiple models. Another key aspect might be addressing the label bias problem, perhaps through bias correction methods that don’t require labeled data for downstream tasks. The section would then present experimental results demonstrating the effectiveness of the proposed ‘Zero-Shot Boost’ methods, comparing them to existing state-of-the-art zero-shot techniques across various benchmark datasets. Finally, a discussion of limitations and future research directions would conclude this section, potentially highlighting the scalability and generalizability of the proposed methods.
Distribution Shifts#
Analyzing distribution shifts in the context of a research paper reveals crucial insights into model generalization and robustness. Distribution shifts refer to discrepancies between the training data distribution and real-world data encountered during deployment. A robust model should ideally generalize well across various distributions. The paper likely explores how distribution shifts impact zero-shot vision models, specifically focusing on the performance degradation when the test data differs significantly from the training data. This might involve analyzing performance across multiple datasets with varying characteristics and image distributions (e.g., ImageNet variants, domain-specific datasets). The research could also investigate techniques to mitigate the adverse effects of distribution shifts, including data augmentation, domain adaptation, and prompt engineering strategies to improve model adaptability and robustness. Understanding the types and extent of distribution shifts encountered is paramount to assessing the generalizability of zero-shot vision models and guiding the development of more reliable and robust solutions.
Label-Free VLM#
A label-free VLM approach presents a significant advancement in vision-language models (VLMs). Eliminating the need for labeled data during training dramatically reduces the cost and effort associated with data annotation, a major bottleneck in VLM development. This paradigm shift allows for leveraging larger, more diverse datasets that are readily available, thus potentially improving model generalization and robustness. The label-free methodology focuses on learning effective visual representations directly from unlabeled visual data, often by exploiting inherent relationships between visual and textual data in the pre-trained VLM or using techniques like unsupervised clustering or distribution learning. While the absence of explicit labels might lead to some loss of precision compared to supervised methods, the potential gains in scalability and data diversity are substantial. This approach is particularly attractive for addressing issues of data bias and imbalance as it opens the door to utilizing massive, naturally occurring datasets that may have less curation or inherent biases. A key challenge remains to develop effective training strategies to compensate for the lack of explicit supervision while maintaining high performance. However, this label-free approach is key to expanding the potential of VLMs for applications where labeled data is scarce or expensive to acquire.
More visual insights#
More on figures
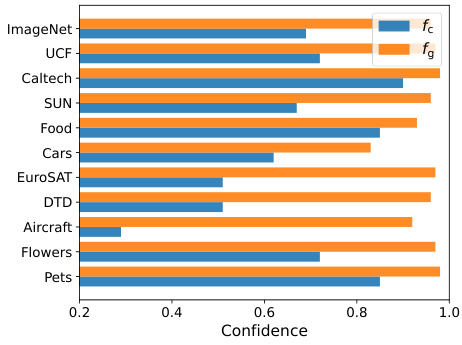
This figure shows a bar chart comparing the average confidence scores of two models, fc and fg, across various datasets. The confidence score represents the model’s certainty in its predictions. The chart visually demonstrates that model fg generally exhibits higher confidence scores than model fc across all the datasets shown.

This figure shows the relationship between the accuracy gains achieved by using the adaptive fusion technique (compared to simple fusion) and the difference in confidence between the Gaussian model (fg) and the original CLIP model (fc). A linear regression line is fitted to the data points, demonstrating a positive correlation: larger confidence differences between the two models generally lead to greater improvements in accuracy by using the adaptive fusion strategy.
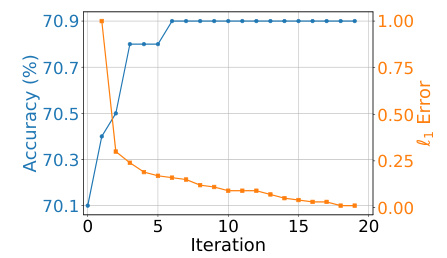
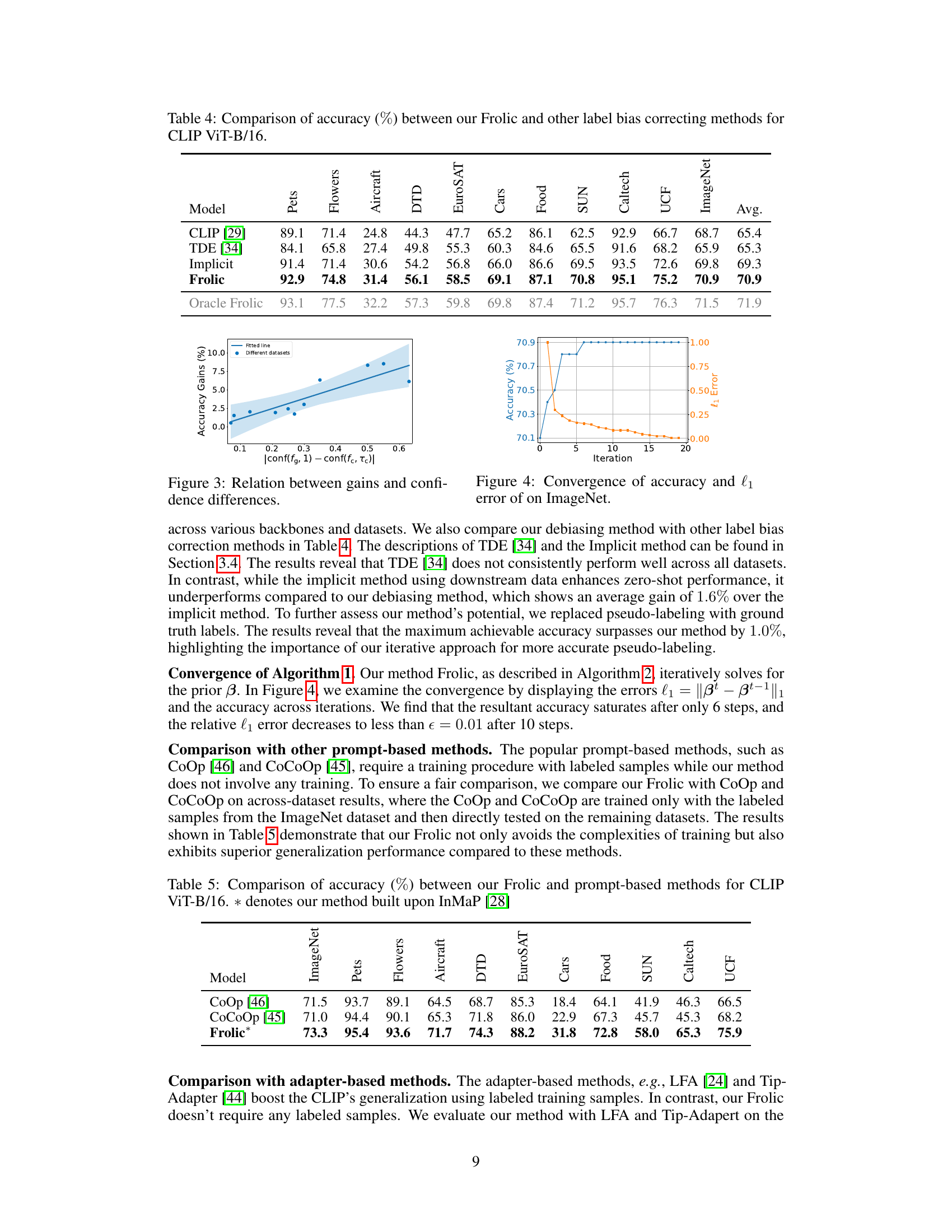
This figure shows the convergence behavior of the accuracy and the ℓ1 error during the iterative process of Algorithm 2 for estimating β on the ImageNet dataset. The x-axis represents the iteration number, the left y-axis shows the accuracy in percentage, and the right y-axis displays the ℓ1 error. The plot demonstrates that the accuracy quickly increases and stabilizes after around 6 iterations, while the ℓ1 error steadily decreases to a value below the defined threshold (ε = 0.01) within 10 iterations. This visualizes the convergence of Algorithm 2, highlighting its efficiency in estimating β.
More on tables
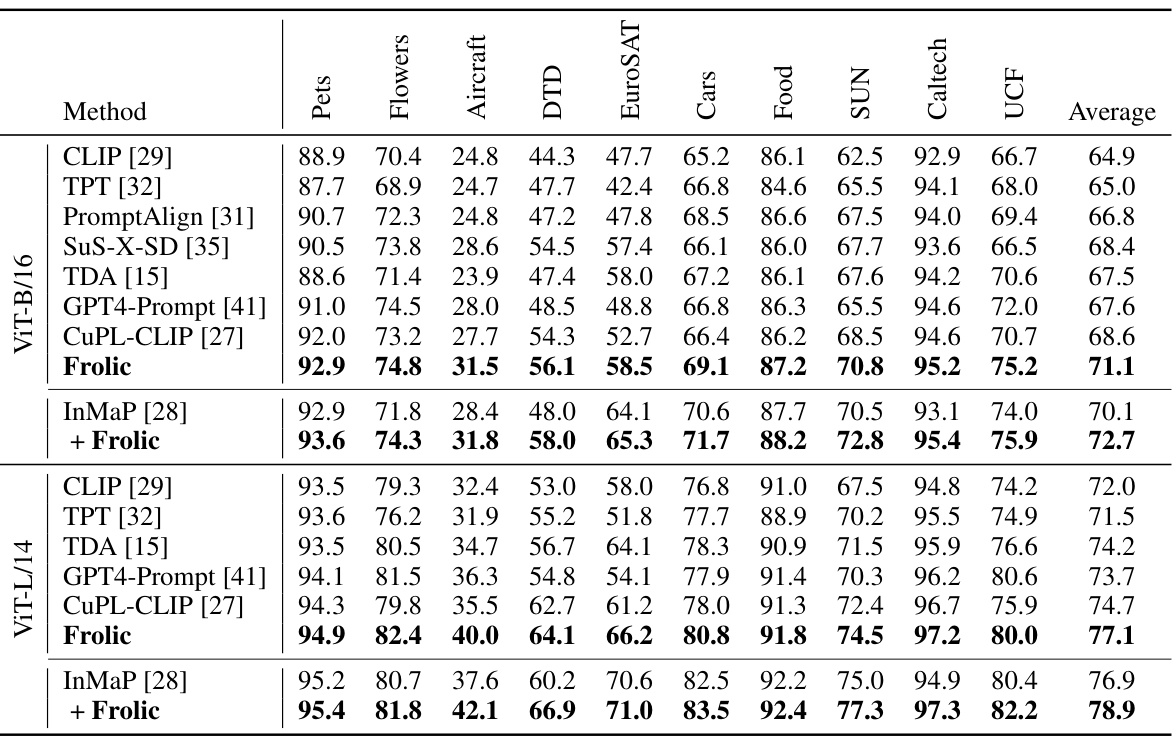
This table presents a comparison of the accuracy achieved by various zero-shot vision models on ten image classification datasets. The models are tested using two different versions of the CLIP architecture: ViT-B/16 and ViT-L/14. The table allows for a direct comparison of model performance across different datasets and CLIP versions. The table includes both baseline methods and the proposed ‘Frolic’ method, enabling an assessment of the performance improvement.
This table presents a comparison of the accuracy achieved by different zero-shot vision models on ten image classification datasets. The models compared include various state-of-the-art methods and the proposed Frolic method. Results are shown for two different CLIP backbones, ViT-B/16 and ViT-L/14, highlighting the performance variations across different model architectures. The table demonstrates the relative improvement achieved by Frolic compared to existing methods.
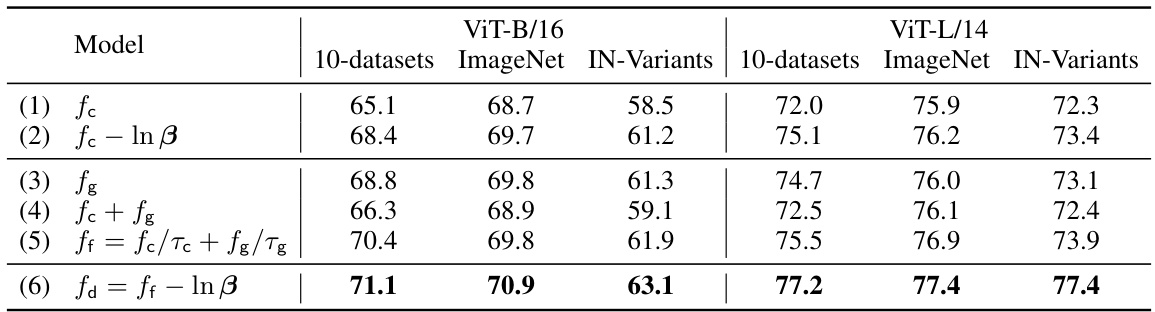
This table presents the accuracy achieved by various models (including the proposed Frolic model and its variants) across different datasets. The datasets include a set of 10 commonly used image classification benchmarks (10-datasets), the ImageNet dataset, and five variants of ImageNet representing different image distribution shifts (IN-Variants). Each model’s performance is evaluated using two different backbone architectures: ViT-B/16 and ViT-L/14. The rows represent different versions of the model, showing the impact of each component (prompt distribution learning, bias correction, fusion technique).
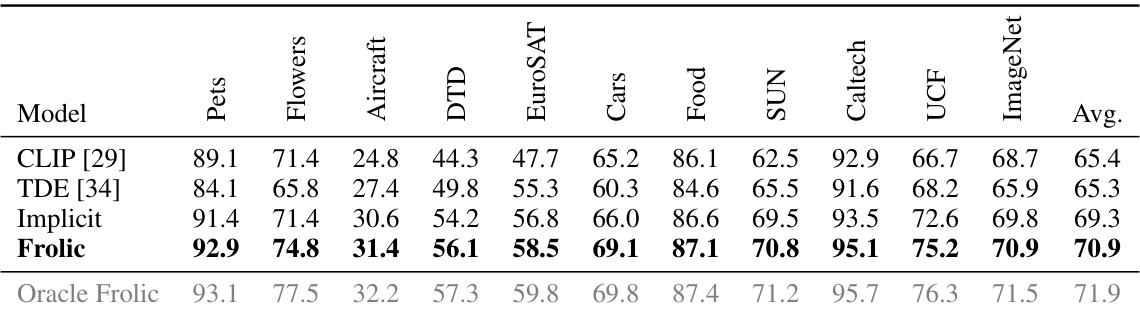
This table compares the accuracy of different zero-shot vision models on ten benchmark datasets using two different CLIP backbones: ViT-B/16 and ViT-L/14. The models compared include the baseline CLIP, several prompt engineering and bias correction methods, and the proposed Frolic method. The table highlights Frolic’s superior performance across various datasets compared to other state-of-the-art techniques, showcasing the effectiveness of its label-free prompt distribution learning and bias correction approach.
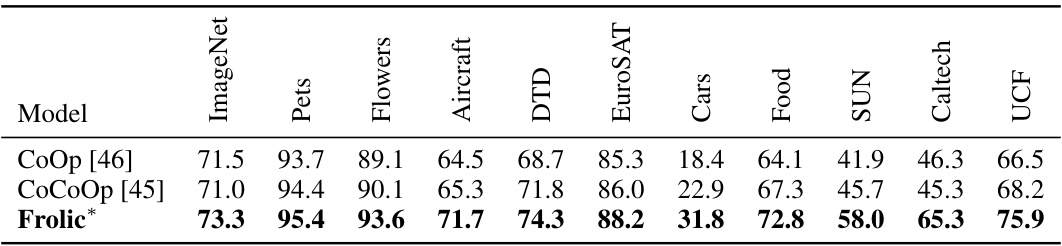
This table compares the accuracy of the proposed method, Frolic, against other prompt-based methods (CoOp and CoCoOp) using CLIP ViT-B/16. The accuracy is reported for various datasets, showing that Frolic outperforms other methods. The asterisk indicates that Frolic uses InMaP.

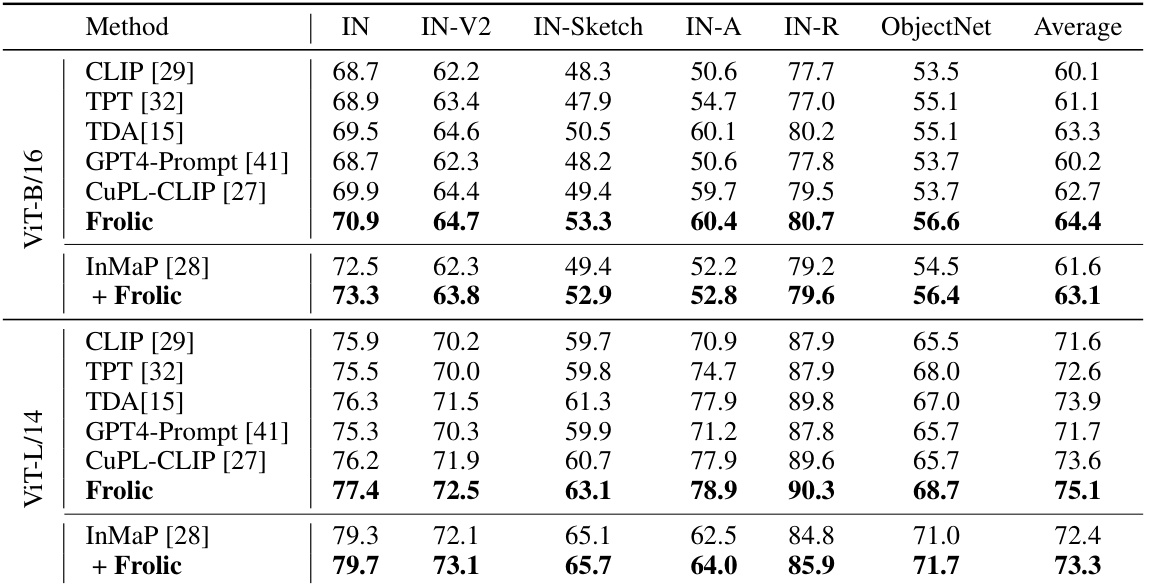
This table compares the accuracy of Frolic against two other adapter-based distribution methods (LFA and Tip-Adapter) using CLIP ViT-B/16 on ImageNet and its variants. It shows the accuracy (%) achieved by each method on the ImageNet dataset and four of its distribution shifts (IN-A, IN-V2, IN-R, IN-Sketch). The average accuracy across these five datasets is also provided.

This table compares the running time and accuracy of different models on the ImageNet dataset using the ViT-B/16 architecture. The models compared are CLIP, TPT, TDA, and Frolic. Frolic shows a significant improvement in accuracy over other methods while maintaining a reasonable runtime compared to TDA. CLIP has the fastest runtime, but also the lowest accuracy.
Full paper#