↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Creating realistic 3D scenes from limited viewpoints is a major challenge in computer vision. Existing methods, such as 3D Gaussian splatting (3DGS), often struggle to produce high-quality results when input views are sparse. This leads to noticeable artifacts and low-fidelity renderings. This limits the use of such techniques in real-world applications where obtaining many images of a scene is challenging.
To tackle this issue, the authors introduce 3DGS-Enhancer. This method uses video diffusion models to improve view consistency in 3DGS. By treating view consistency as a temporal consistency problem within a video sequence, it leverages powerful video diffusion priors to enhance the quality of novel views. The model then integrates these enhanced views with original input views, further refining the 3DGS model. This two-stage approach (diffusion enhancement and 3DGS refinement) results in significantly better performance compared to existing methods, as demonstrated through extensive testing on large datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in novel view synthesis and 3D scene representation. It directly addresses the limitations of existing 3D Gaussian splatting methods, particularly in sparse-view scenarios, offering a significant improvement in rendering quality. The innovative use of 2D video diffusion priors and confidence-aware fine-tuning strategies opens new avenues for research in enhancing the performance of existing 3D reconstruction techniques and generating more realistic 3D representations from limited data.
Visual Insights#

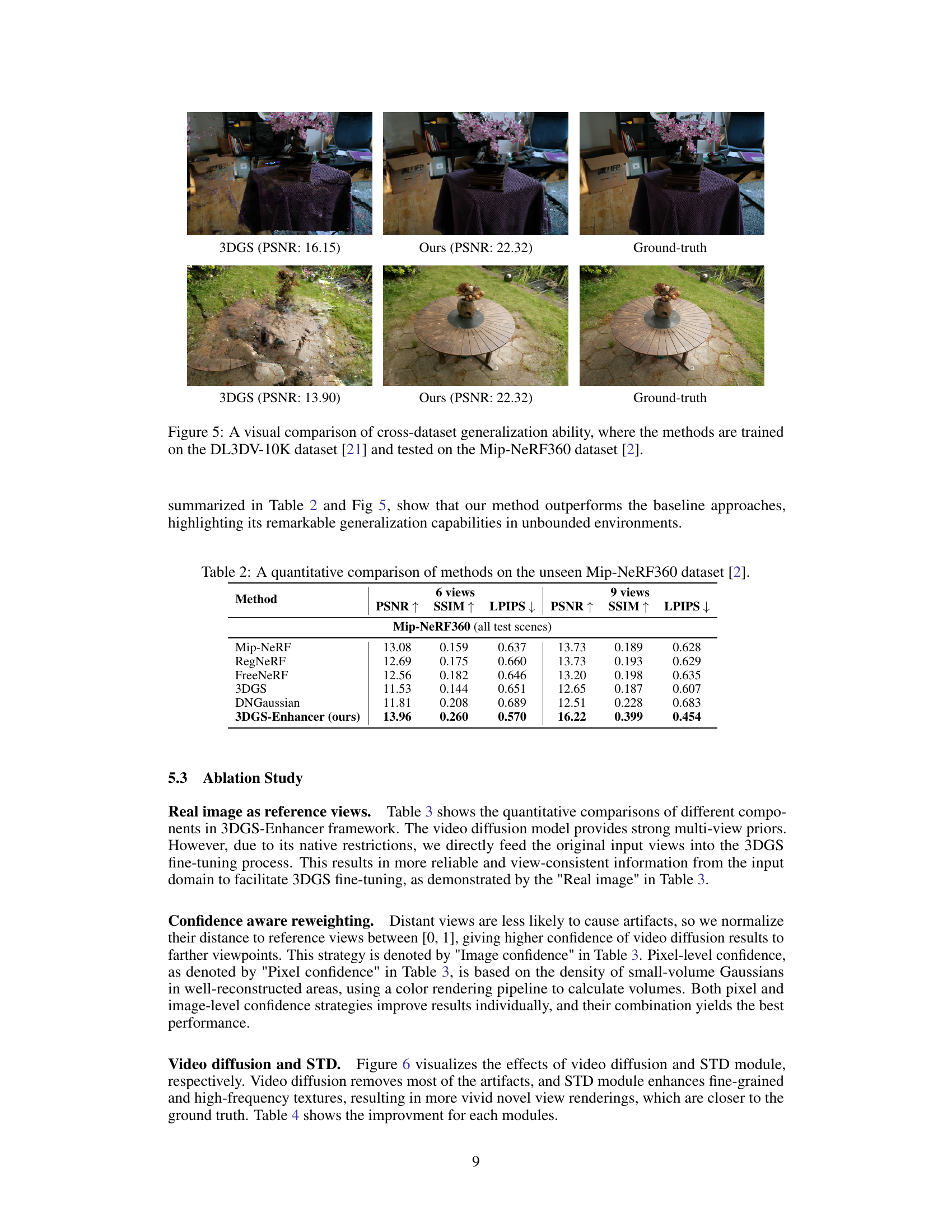
This figure shows a comparison of novel view synthesis results using 3DGS (3D Gaussian splatting) and the proposed 3DGS-Enhancer method. The top row displays a scene with a plant and shelves, while the bottom row shows a scene with a circular structure. In each case, the leftmost image shows the results using the standard 3DGS approach with sparse input views, exhibiting artifacts such as missing details and unrealistic shapes (as indicated by lower PSNR values). The middle image shows the improved reconstruction achieved using 3DGS-Enhancer, demonstrating a significant improvement in quality (higher PSNR values) and visual fidelity. Finally, the rightmost images are the corresponding ground truth images.
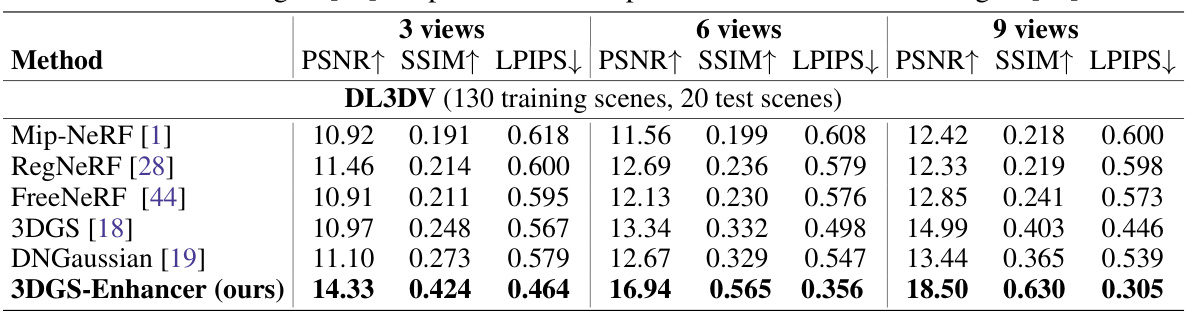
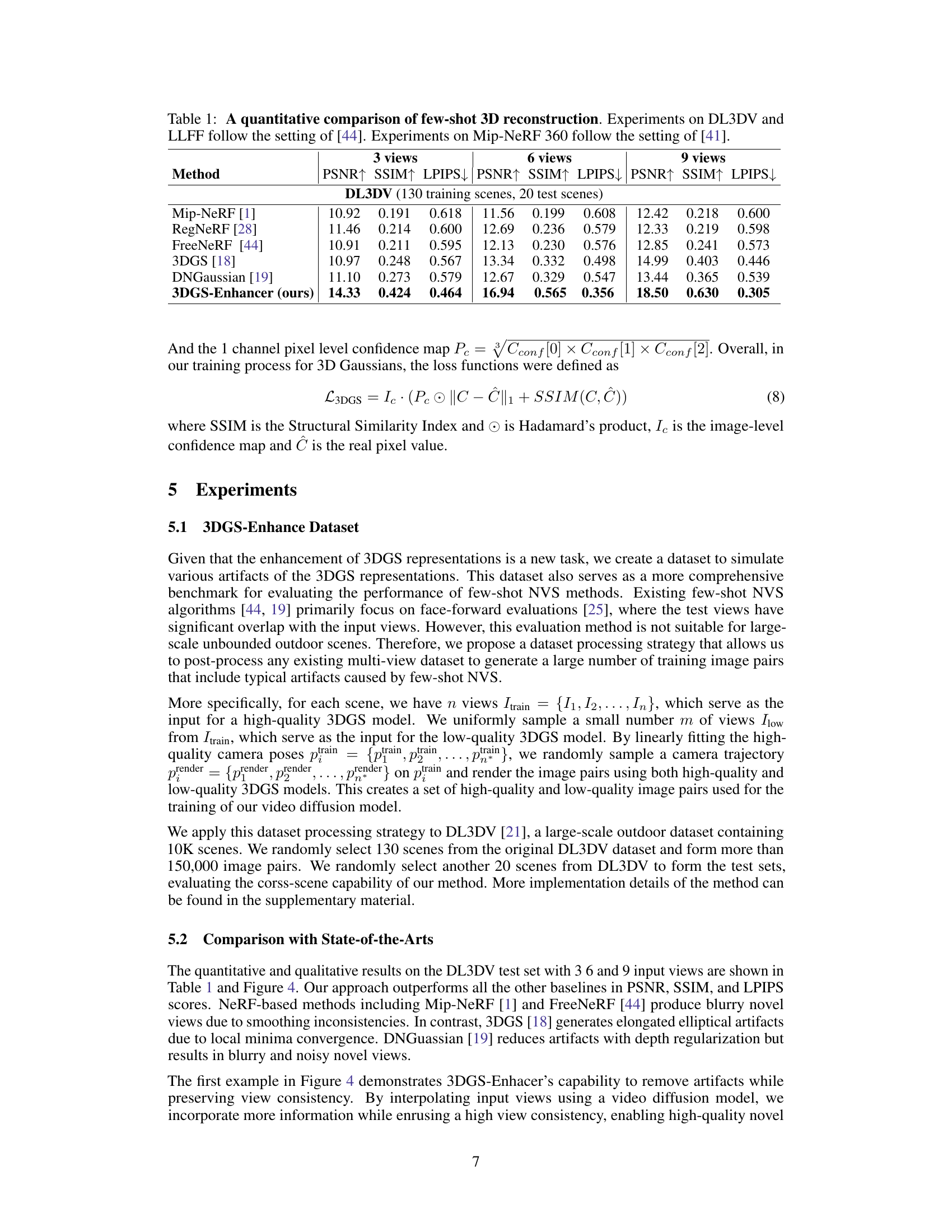
This table presents a quantitative comparison of different few-shot 3D reconstruction methods on three datasets: DL3DV, LLFF, and Mip-NeRF 360. The methods are evaluated based on their performance with varying numbers of input views (3, 6, and 9). The metrics used for evaluation are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The table allows for a comparison of the proposed 3DGS-Enhancer method against several state-of-the-art techniques.
In-depth insights#
3DGS Enhancement#
The core concept of “3DGS Enhancement” revolves around improving the quality and robustness of 3D Gaussian Splatting (3DGS) for novel view synthesis, especially in challenging scenarios with limited input views. The primary goal is to overcome the limitations of standard 3DGS, which often produces artifacts in under-sampled areas. This is achieved by integrating 2D video diffusion priors. The approach reformulates the 3D view consistency problem as a temporal consistency problem within a video generation framework. This clever reformulation leverages the strengths of video diffusion models, known for their proficiency in restoring temporal consistency and generating high-quality images. A spatial-temporal decoder is introduced to effectively merge the enhanced views with the original ones, further refining the 3DGS representation. This entire process is followed by fine-tuning the initial 3DGS model using the enhanced views. The results demonstrate a substantial improvement in PSNR and visual fidelity, highlighting the efficacy of using video diffusion priors in overcoming the challenges of sparse-view 3D reconstruction. The confidence-aware fine-tuning strategy is also a key component, prioritizing the use of reliable information for model improvement.
Diffusion Priors#
The utilization of diffusion priors represents a significant advancement in novel-view synthesis. By leveraging the power of pre-trained diffusion models, the approach moves beyond traditional methods that rely solely on geometric constraints. Diffusion models excel at generating high-quality and consistent images, thus addressing a major limitation in previous techniques that often produced artifacts or inconsistencies in generated views. The integration of diffusion priors effectively reformulates the 3D view consistency problem into a more manageable temporal consistency problem within a video generation framework. This clever approach leverages the inherent temporal coherence of video to improve the quality and consistency of generated images for novel views. This strategy proves particularly beneficial for scenarios with sparse input views, where traditional methods struggle to generate high-quality results. The successful application of diffusion priors demonstrates the strength of combining deep learning models with traditional rendering techniques, leading to significant improvements in visual fidelity and efficiency. The future of novel-view synthesis is likely to see even greater use of diffusion priors and similar generative models.
View Consistency#
View consistency in novel view synthesis is crucial for generating realistic and believable images from multiple input views. The core challenge lies in ensuring that synthesized images align seamlessly with the input views and maintain a coherent 3D structure. Inconsistent views often result in visible artifacts, such as flickering, misalignment, or jarring discontinuities between perspectives, significantly detracting from image quality. Approaches to enhancing view consistency typically involve incorporating geometric constraints, using regularization techniques, or leveraging generative models. Geometric constraints, such as depth maps or surface normals, can guide the synthesis process, but their accuracy and availability are often limited. Regularization methods help to prevent overfitting and ensure smoothness, but they can also blur details or limit the expressiveness of the model. Generative models provide powerful tools for filling in missing information and restoring view consistency, particularly in scenarios with sparse or incomplete input views. However, the success of these methods heavily relies on the model’s ability to learn intricate relationships between different views and accurately generate missing data. Balancing view consistency with other factors, such as image quality, rendering speed and model complexity is another major consideration in the design of novel view synthesis systems.
Dataset Creation#
Creating a dataset for novel view synthesis (NVS) enhancement presents unique challenges. The authors address the scarcity of existing datasets specifically designed for evaluating 3DGS enhancement by implementing a data augmentation strategy. This involves generating pairs of low and high-quality images from sparse and dense view sets. Careful selection of the underlying dataset is crucial, with the choice of DL3DV enabling the generation of a large-scale dataset representing unbounded outdoor scenes. This process is further enhanced by using linear interpolation to create smooth camera trajectories between sparse view sets, thus increasing data variety and mitigating artifacts. The result is a significantly larger, more comprehensive dataset, tailored for evaluating the effectiveness of NVS enhancement methods in realistic scenarios and addressing the shortcomings of existing, more limited datasets. The meticulous approach to data augmentation and trajectory fitting is noteworthy, as it directly addresses the core challenge of sparse-view reconstruction and its associated artifacts. The creation of a specialized dataset for 3DGS enhancement is a valuable contribution, paving the way for more rigorous evaluations of NVS improvement techniques.
Future of 3DGS#
The future of 3D Gaussian splatting (3DGS) looks promising, with potential advancements in several key areas. Improving efficiency remains crucial; current 3DGS methods, while faster than traditional radiance fields, could benefit from further optimizations for real-time applications. Enhanced view consistency, particularly under sparse input views, is another critical area. The integration of advanced techniques, such as video diffusion priors, as explored in the paper, is a significant step toward achieving high-fidelity novel view synthesis. Addressing unbounded scenes remains a challenge. 3DGS currently struggles with scene boundaries. Developing robust methods to accurately render unbounded, intricate environments would be impactful. Data efficiency is also key; current 3DGS methods require extensive training datasets. Research into techniques requiring less data for training would increase the practicality and accessibility of 3DGS. Finally, integrating 3DGS with other techniques such as neural implicit representations could lead to hybrid approaches that leverage the strengths of both. These advancements would lead to wider adoption and more impactful applications of 3DGS in fields like virtual and augmented reality, computer vision, and 3D modeling.
More visual insights#
More on figures
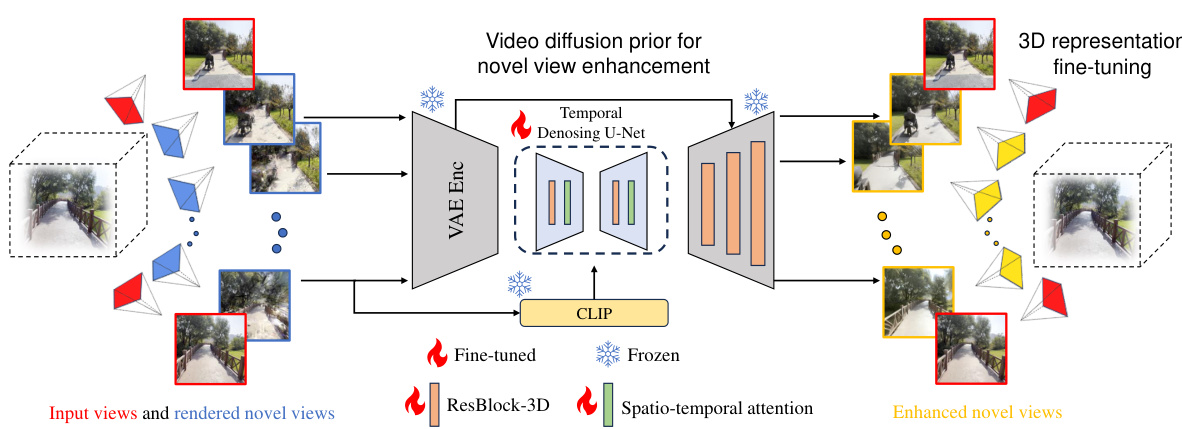
The figure illustrates the 3DGS-Enhancer framework’s workflow. It starts with input views and novel views rendered by a 3DGS model. These views are fed into a Video Diffusion Prior module, which leverages a temporal denoising U-Net and CLIP for enhancement. The enhanced views are then integrated with the original input views using a spatial-temporal decoder. Finally, the combined views fine-tune the 3DGS model, resulting in improved 3D representation and better novel view synthesis.

This figure presents a visual comparison of novel view synthesis results using different methods on scenes from the DL3DV test set, specifically focusing on scenarios with only three input views. It compares the results of Mip-NeRF, FreeNeRF, 3DGS, DNGaussian, and the proposed 3DGS-Enhancer, showcasing the superior visual quality and detail preservation achieved by the 3DGS-Enhancer in comparison to existing methods.

This figure visually compares the performance of different novel view synthesis methods on three example scenes from the DL3DV dataset, using only three input views. It showcases the superior quality of the 3DGS-Enhancer method compared to baselines such as Mip-NeRF, FreeNeRF, 3DGS, and DN-Gaussian. The results highlight 3DGS-Enhancer’s ability to generate sharper, more detailed, and visually more realistic novel views, especially in areas with high-frequency details or challenging viewing conditions.

This figure shows a visual comparison of the results obtained by the proposed 3DGS-Enhancer method and other baselines on the Mip-NeRF360 dataset. The key aspect highlighted is the cross-dataset generalization ability; the model trained on DL3DV-10K is used to generate novel views on unseen data. The results demonstrate how well the model generalizes to different datasets and scene types.

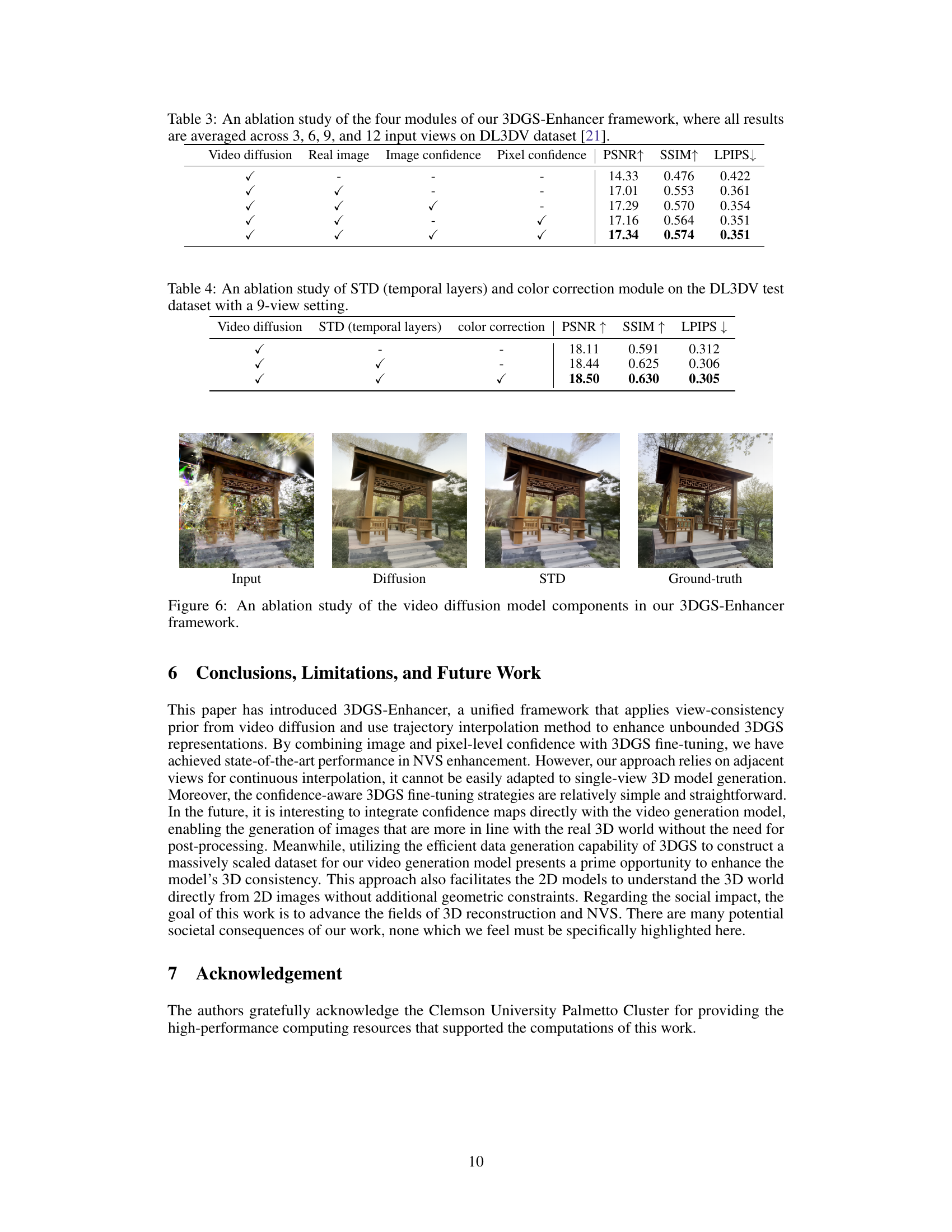
This figure shows the ablation study of the video diffusion model components in the 3DGS-Enhancer framework. It visually compares the results of using only the video diffusion model, the spatial-temporal decoder (STD), both combined, and the ground truth. The input image shows significant artifacts. The video diffusion model improves the results but still shows some artifacts. The STD further enhances the image quality and reduces artifacts. The ground truth image is shown for comparison.
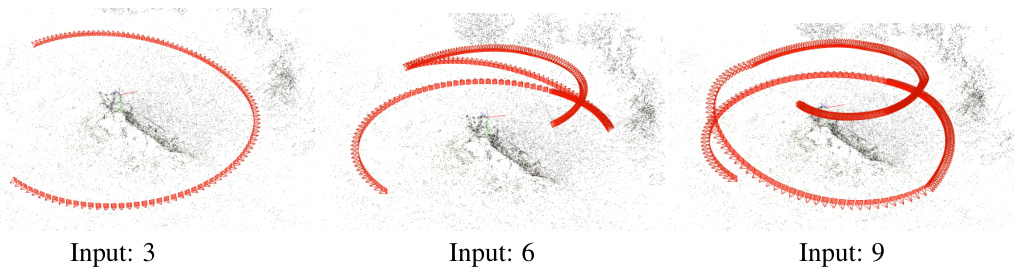
This figure shows how the camera trajectories are fitted for different numbers of input views (3, 6, and 9). The fitting process is crucial for generating smooth and consistent image sequences for the video diffusion model training. The trajectories are fitted using either the high-quality input views (for simple trajectories) or the low-quality input views (for complex trajectories) to ensure reasonable artifact distributions in the rendered images.

This figure presents a visual comparison of novel view synthesis results generated by different methods on four scenes from the DL3DV dataset. Each row shows a scene with three input views (leftmost column) and the results from Mip-NeRF, FreeNeRF, 3DGS, DNGaussian, and the proposed 3DGS-Enhancer method (from left to right, except for the ground truth which is in the rightmost column). The goal is to showcase how the proposed method compares in visual quality to other state-of-the-art methods, especially in terms of resolving artifacts and maintaining high-fidelity details.
More on tables
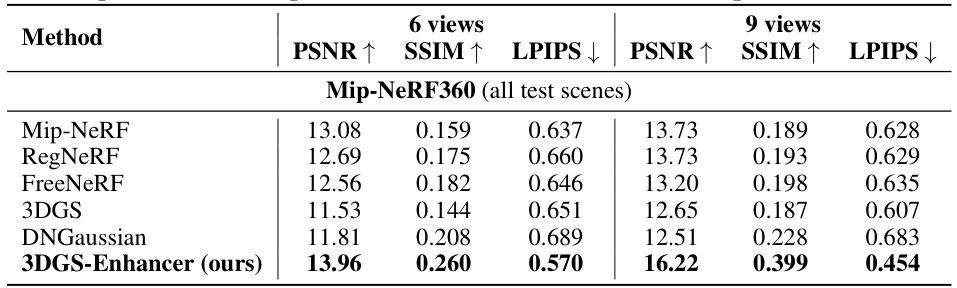
This table presents a quantitative comparison of different novel view synthesis methods on the Mip-NeRF360 dataset. The methods are evaluated using PSNR, SSIM, and LPIPS metrics for both 6 and 9 input views. The results demonstrate the performance of the proposed 3DGS-Enhancer method compared to several baselines, highlighting its cross-dataset generalization capabilities.

This table presents the results of an ablation study conducted on the 3DGS-Enhancer framework. The study evaluates the impact of four different modules: video diffusion, real image, image confidence, and pixel confidence. The results are averaged across 3, 6, 9, and 12 input views using the DL3DV dataset. The table shows the PSNR, SSIM, and LPIPS scores for each configuration to demonstrate how each module contributes to the overall performance of the framework.

This table presents the ablation study of the spatial-temporal decoder (STD) and color correction module within the 3DGS-Enhancer framework. It shows the impact of temporal layers and color correction on the PSNR, SSIM, and LPIPS metrics using the DL3DV test dataset with 9 input views. It demonstrates the individual and combined effects of these components on image quality.
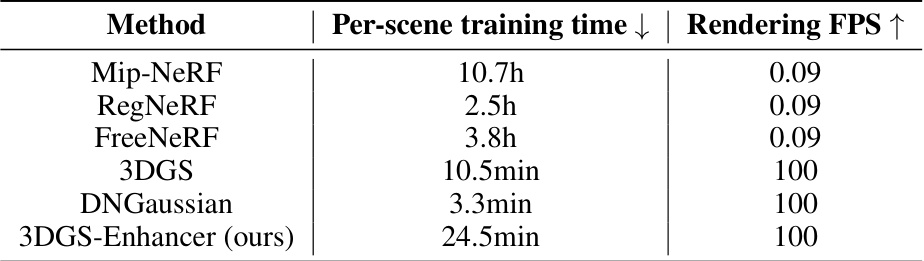
This table compares the per-scene training time and rendering FPS (frames per second) of different novel-view synthesis methods. It highlights the trade-off between training time and rendering speed. The authors’ method (3DGS-Enhancer) achieves a good balance, offering relatively fast rendering while maintaining reasonable training times.
Full paper#