↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current robot learning methods struggle with the heterogeneity of robotic data, limiting the generalization of learned policies. Each robot and task necessitates its own data collection and training, making the process expensive and prone to overfitting. This paper tackles this challenge by proposing a new approach that leverages the power of pre-training on a vast and diverse set of robotic data.
The proposed solution, Heterogeneous Pre-trained Transformers (HPT), employs a modular architecture. It consists of embodiment-specific “stems” which process sensor inputs from different robots, a shared “trunk” to learn a task-agnostic representation, and task-specific “heads” to map into control actions. HPT leverages both simulated and real-world data, showcasing excellent results on multiple benchmark tasks. The results demonstrate the improved performance and generalization capabilities of HPT, paving the way for more efficient and adaptable robotic systems.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of generalizing robot learning across diverse embodiments and tasks. It introduces a novel pre-training method that significantly improves the efficiency and effectiveness of robotic policy learning, paving the way for more robust and adaptable robots. This work also highlights the importance of scaling laws in robotics, contributing valuable insights to the broader field of AI.
Visual Insights#
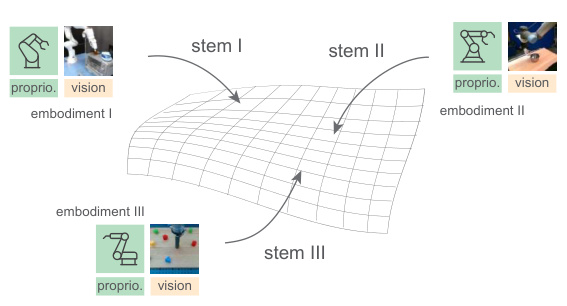
This figure illustrates the core concept of heterogeneous pre-training. Different robot embodiments, each having unique proprioceptive (e.g., joint angles) and visual sensors, are processed by separate ‘stem’ modules. These stems transform the sensor data into a shared representation space, enabling a common ’trunk’ transformer to learn a general policy representation from data across diverse robots and tasks. This pre-trained trunk can then be easily adapted to new robot embodiments simply by adding a new stem module.

This table presents the architectural details of the Heterogeneous Pre-trained Transformers (HPT) models used in the paper. It shows the depth (number of transformer blocks), width (latent dimension size), number of attention heads, and total number of parameters for five different HPT variants: Small, Base, Large, XLarge, and Huge. The table highlights the scaling of model size across these variants, showing a significant increase in parameters from the smallest (HPT-Small) to the largest (HPT-Huge) model.
In-depth insights#
HPT Architecture#
The Heterogeneous Pre-trained Transformers (HPT) architecture is a modular design that efficiently handles the heterogeneity inherent in robotic data. It consists of three key components: embodiment-specific stems, a shared transformer trunk, and task-specific heads. The stems act as tokenizers, transforming diverse sensor inputs (proprioception and vision) from different robot embodiments into a standardized format. This allows the shared trunk to process information from various robots and sensors uniformly, learning an embodiment-agnostic representation. Finally, task-specific heads map the trunk’s output to actions relevant to the particular task. This modular design enables efficient transfer learning, where only the stems and heads need to be adapted when applying the model to new robots or tasks, leveraging the pre-trained knowledge from the shared trunk for improved performance and reduced data requirements. The scalability of HPT is a key strength, allowing it to handle large amounts of heterogeneous data from diverse sources.
Scaling Behaviors#
The scaling behaviors analysis in the research paper is crucial for understanding the model’s performance improvements with increased data and resources. The authors investigate the effects of various scaling factors, including the number of datasets and model size, on the overall performance of the HPT model. Data scaling experiments reveal consistent performance gains with an increase in training data, demonstrating the potential of HPT to benefit from larger, more diverse datasets. Model scaling shows a positive correlation between model size and performance, highlighting the efficiency of the HPT architecture in utilizing increased model capacity. Furthermore, the authors observe positive scaling effects when increasing compute resources, indicating that HPT can effectively leverage more computational power for training and achieve improved accuracy. These findings underscore the model’s scalability and its ability to adapt to diverse and large-scale datasets, paving the way for real-world deployment with enhanced generalization and efficiency.**
Heterogeneous Data#
The concept of “heterogeneous data” in robotics research is crucial because robots operate in diverse and complex environments. This necessitates the integration of data from various sources, including real-world robot interactions, simulations, and even human-demonstration videos. Each source presents unique characteristics in terms of sensor modalities (vision, proprioception, etc.), data formats, and levels of noise or uncertainty. Successfully handling this heterogeneity requires sophisticated methods for data alignment, representation learning, and model generalization. Pre-training models on large-scale heterogeneous datasets is a promising approach to acquire a robust and generalizable policy, capable of adapting to unseen tasks and environments with minimal fine-tuning. However, managing the complexity and scale of heterogeneous datasets and the associated computational cost remain significant challenges. Future research should focus on developing efficient and effective methods for data integration, ensuring data quality and representation, and devising scalable pre-training strategies to fully exploit the potential of heterogeneous data for building truly robust and adaptable robotic systems.
Transfer Learning#
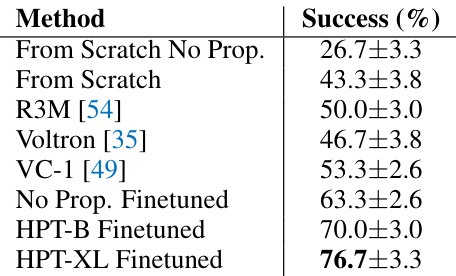
The concept of transfer learning is central to this research, aiming to leverage knowledge gained from heterogeneous pre-training to enhance performance on new, unseen tasks and robots. The paper demonstrates that a large, shared policy network (HPT) pre-trained across diverse robotic datasets can be effectively transferred to novel robotic embodiments and tasks, requiring minimal additional fine-tuning. This is a significant advancement, as it addresses the challenge of data scarcity and embodiment specificity in traditional robotic learning. The success of transfer learning in this context highlights the importance of a robust, task-agnostic representation learned during pre-training. Furthermore, the modular architecture of HPT facilitates straightforward adaptation to new tasks and robots, making it a scalable and practical approach for building generalist robotic policies. However, the study also acknowledges the limitations of transfer learning, particularly in handling significant variations in embodiment and task complexity. Future work should explore how to further enhance transferability and address potential challenges related to real-world robustness and data efficiency.
Future Work#
Future research directions for this work could involve exploring more sophisticated methods for handling the inherent heterogeneity of robotic data, perhaps through the use of more advanced alignment techniques or more robust training objectives. Improving the scalability of the model and training processes would also be beneficial, allowing for the inclusion of even larger and more diverse datasets. Furthermore, investigating alternative approaches to policy learning, such as self-supervised or reinforcement learning methods, could enhance generalization and robustness. A key focus area should be addressing the limitations in real-world deployment by improving the policies’ reliability, particularly in complex scenarios with fine manipulation and long-horizon tasks. Finally, further investigation into the ethical implications of using large-scale robotic datasets and the potential societal impact of the resulting models is crucial. In addition, the investigation of multiple modalities (such as 3D point clouds and language inputs) could further increase the model’s learning capability and ability to generalize to novel tasks and environments.
More visual insights#
More on figures

The figure illustrates the architecture of Heterogeneous Pre-trained Transformers (HPT). It shows a modular design with three main components: Embodiment-specific stems that process proprioceptive and visual inputs, a shared Transformer trunk that learns a task-agnostic representation, and task-specific heads that map the representation to actions. The figure highlights the flexibility and scalability of HPT, showing how it can handle data from multiple embodiments and tasks.
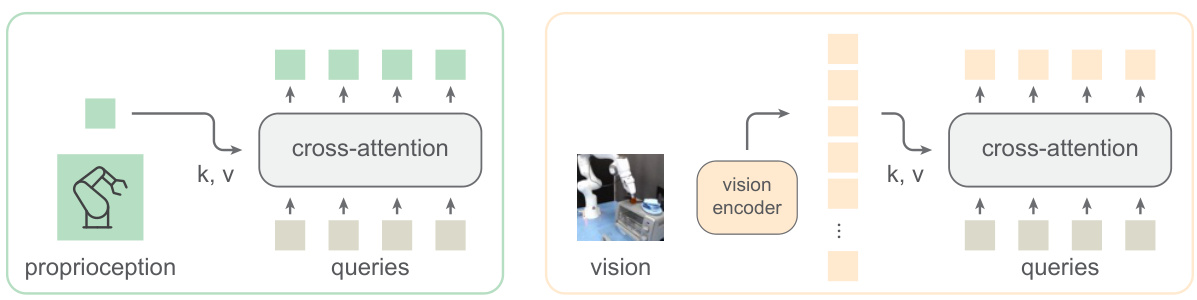
This figure illustrates the stem architecture of the Heterogeneous Pre-trained Transformers (HPT) model. The stem is responsible for processing proprioceptive and visual inputs from different robot embodiments. The proprioceptive tokenizer uses a Multilayer Perceptron (MLP) to transform proprioceptive data into a feature vector, which is then processed using cross-attention with 16 learnable tokens. Similarly, the vision tokenizer uses a pre-trained encoder (like ResNet) to process visual information, also employing cross-attention with 16 fixed tokens. The output is a fixed-length sequence of tokens, regardless of the input sequence length, which allows the model to handle variable-length inputs from diverse sensors.

This figure shows a pie chart visualizing the distribution of datasets used in the HPT pre-training process across different domains and embodiments. Each slice represents a specific dataset or group of datasets, categorized by their source (real-world teleoperation, simulation, deployed robots, and human videos). The visual representation highlights the diversity and heterogeneity of the data used for pre-training, emphasizing the paper’s focus on scaling learning across different robotics environments and sensor modalities.
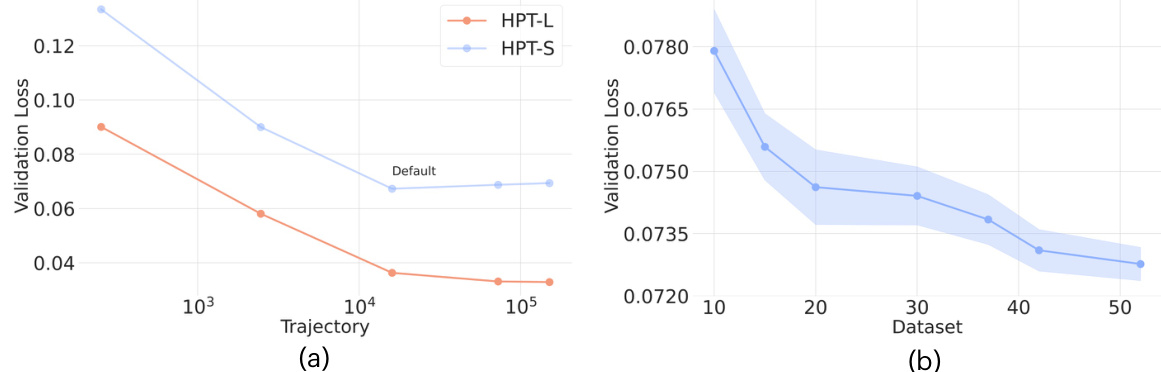
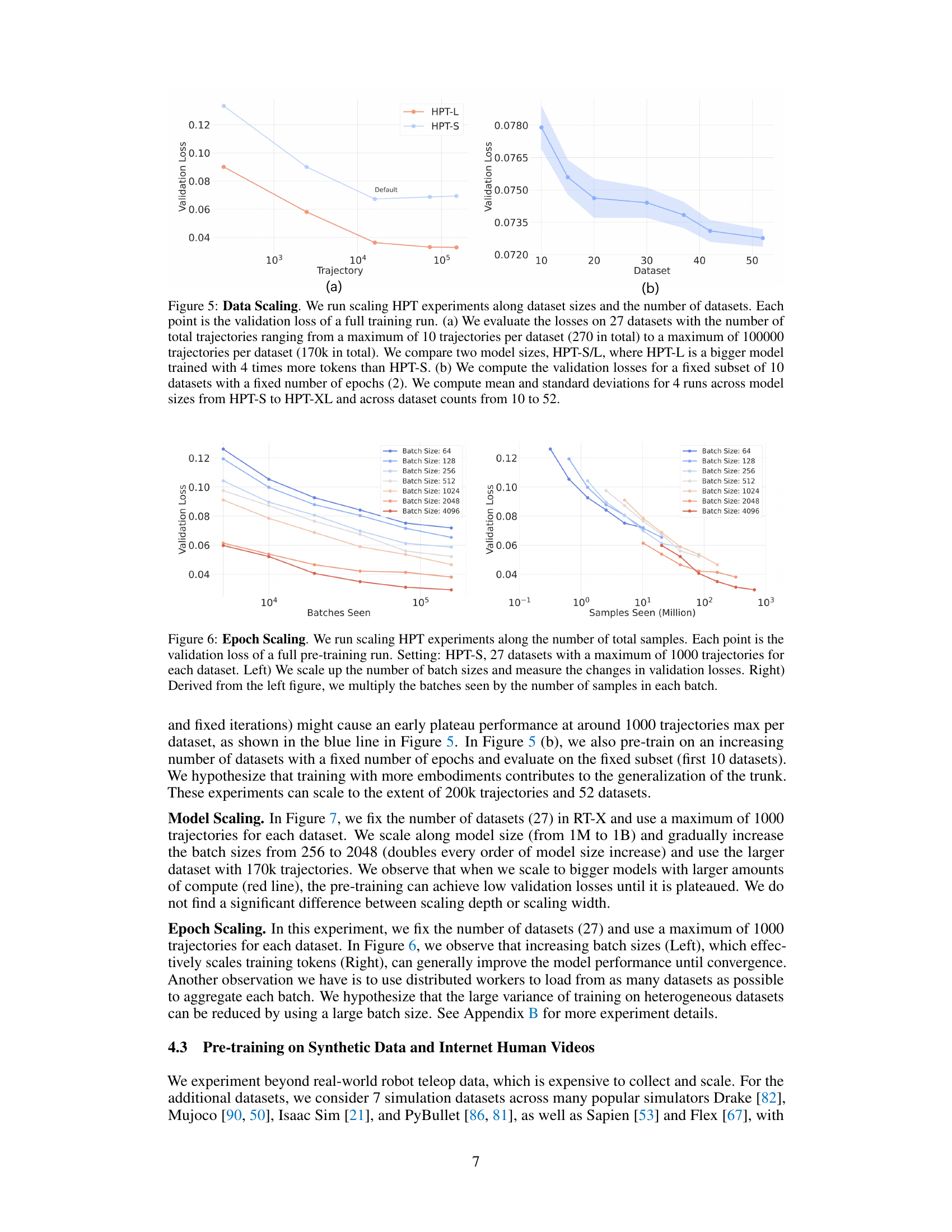
This figure shows the scaling behavior of the Heterogeneous Pre-trained Transformers (HPT) model with respect to the amount of data used during pre-training. Subfigure (a) demonstrates the relationship between the number of trajectories and the validation loss for two different model sizes (HPT-S and HPT-L). Subfigure (b) shows how the validation loss changes as the number of datasets increases, keeping the number of epochs constant.

This figure shows the scaling behavior of the Heterogeneous Pre-trained Transformers (HPT) model with respect to the amount of data and model size. The left subplot (a) demonstrates how validation loss decreases as the number of training trajectories increases, comparing two different model sizes. The right subplot (b) shows how validation loss changes as the number of datasets increases, again for different model sizes. The results show that HPT scales well with increasing data and model capacity.
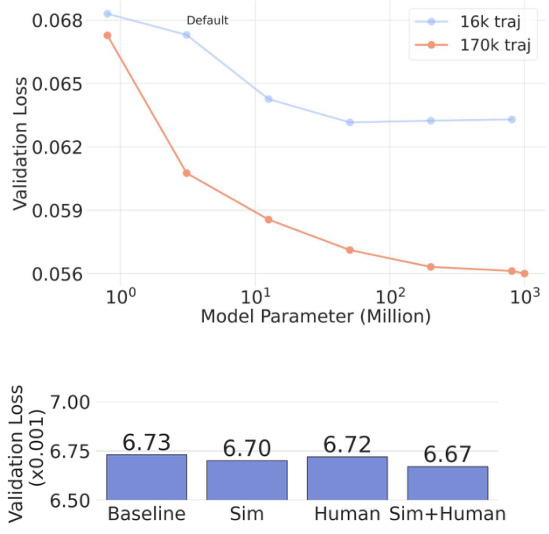
This figure shows the scaling behavior of the Heterogeneous Pre-trained Transformers (HPT) model with respect to both the size of the dataset and the number of datasets used in training. The left subplot (a) demonstrates the impact of increasing the number of trajectories per dataset on the validation loss for two different model sizes (HPT-S and HPT-L). The right subplot (b) shows how the validation loss changes as the number of datasets increases while keeping the number of epochs constant and comparing different model sizes. Overall, the figure highlights the scaling properties of HPT as the amount of training data increases and suggests a beneficial effect of model size and increased diversity of training datasets in improving generalization.

This figure shows several example tasks from different simulation environments used to evaluate the HPT model. The figure visually demonstrates the robot performing different manipulation tasks in various simulated settings. The specific details of the experiments are described in sections 5.1 and A.4 of the paper.

This figure presents the success rates achieved by different models on robot manipulation tasks across various simulation benchmarks. Specifically, it compares the transfer learning performance of models with pre-trained trunks (HPT-B to HPT-XL) against other generalist models (RT-1X, RT-2X, Octo) in the Simpler benchmark. The pre-trained trunks used the ‘Scaled Settings’ from the pre-training phase, highlighting the impact of this pre-training on downstream task performance.

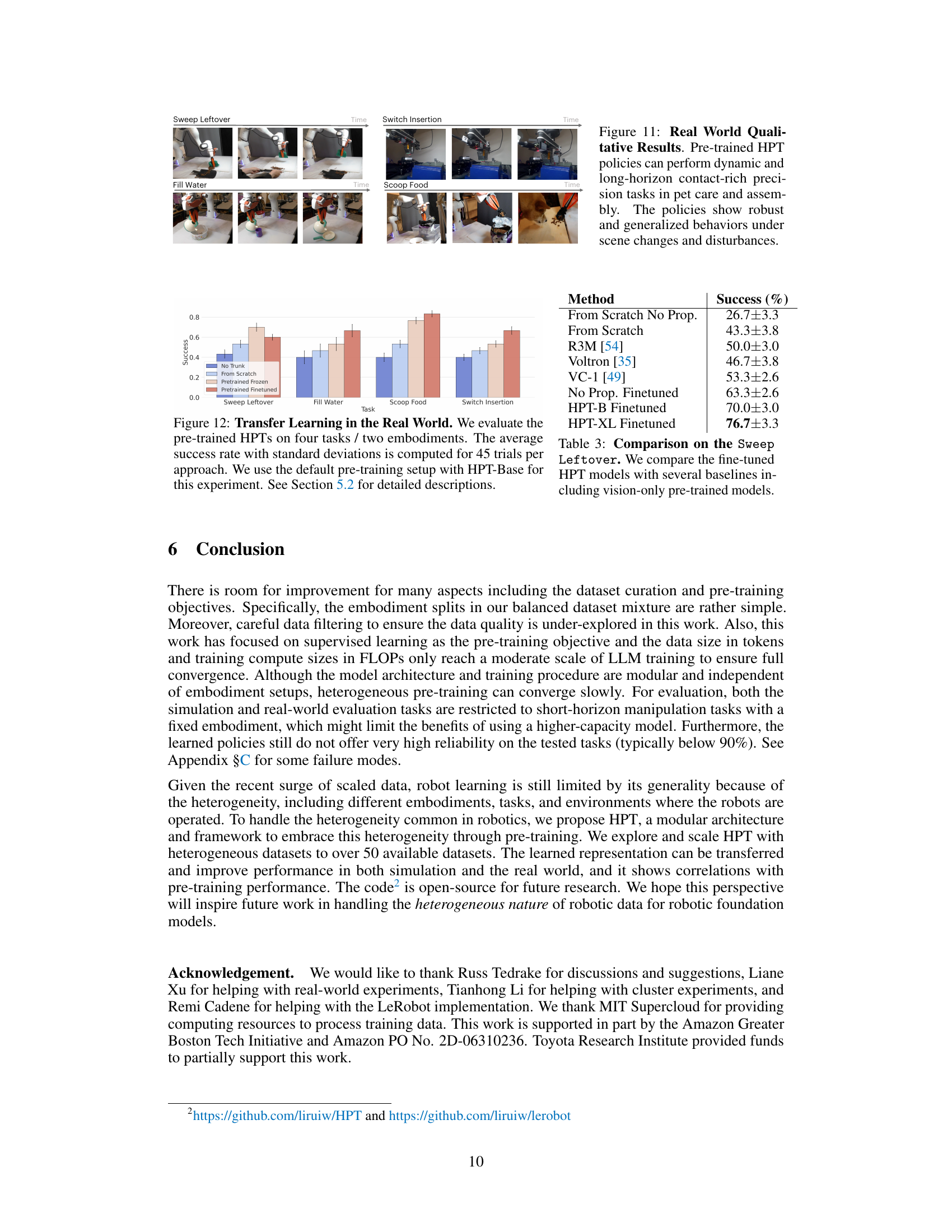
This figure shows the qualitative results of applying pre-trained HPT policies to four real-world tasks: Sweep Leftover, Fill Water, Scoop Food, and Switch Insertion. The image sequence for each task demonstrates the robot’s ability to successfully complete the task despite variations in the environment and object placement. The caption highlights that the policies exhibit robustness and generalization.

This bar chart displays the success rates of four different methods (No Trunk, From Scratch, Pretrained Frozen, Pretrained Finetuned) across four real-world robotic tasks (Sweep Leftover, Fill Water, Scoop Food, Switch Insertion). Each bar represents the average success rate across 45 trials, with error bars indicating the standard deviation. The chart compares the performance of models that use a pre-trained transformer trunk (Pretrained Frozen, Pretrained Finetuned) against models trained from scratch (From Scratch) and models without a trunk (No Trunk). The results demonstrate the effectiveness of pre-training the HPT model for improving real-world robotic task performance.
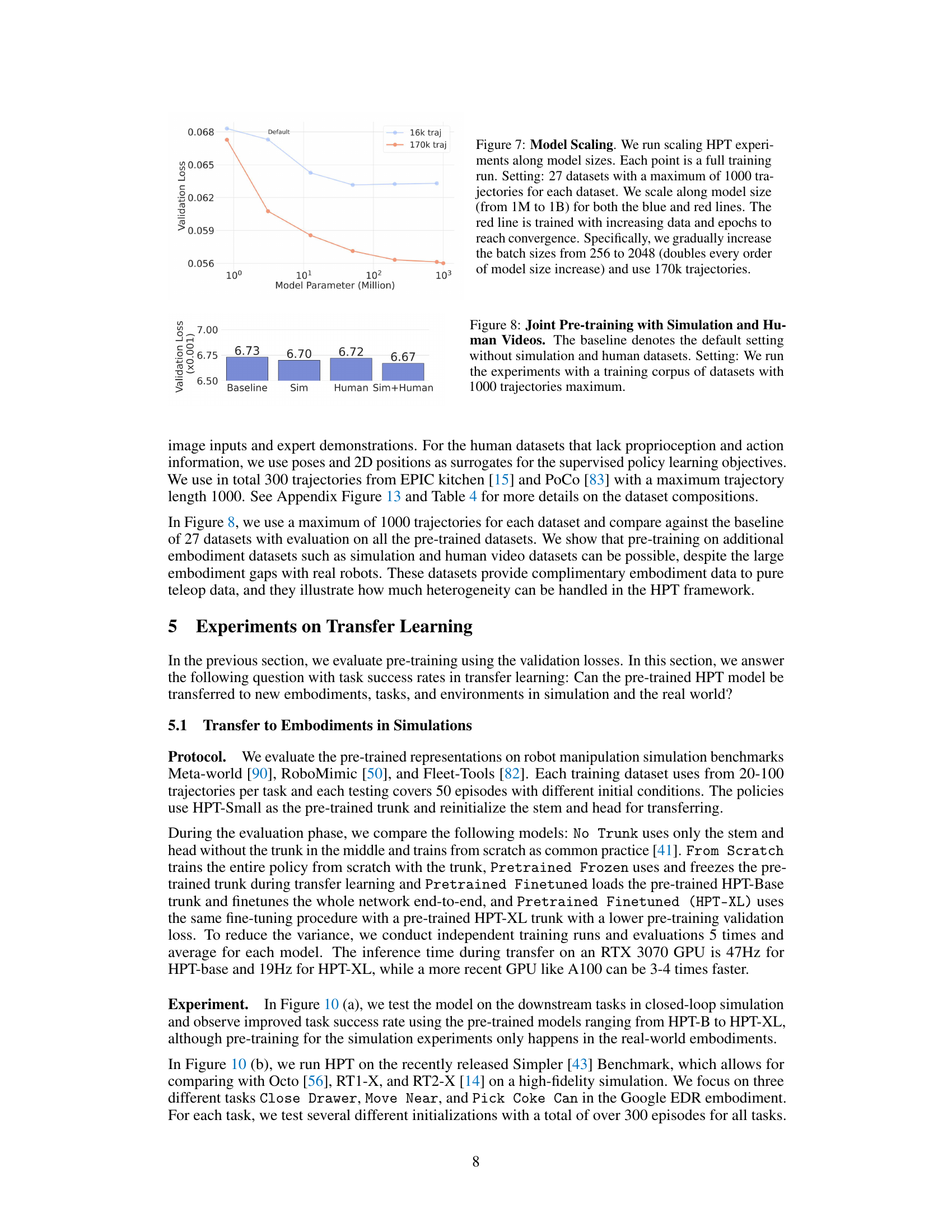
This figure shows the success rates achieved by different models on various robotic manipulation tasks in simulation. Part (a) compares the performance of HPT models of varying sizes (HPT-B to HPT-XL) across four different simulation benchmarks (Fleet-Tools, Hammer, Metaworld, RoboMimic). Part (b) benchmarks HPT-XL against other state-of-the-art generalist models on the Simpler benchmark using the Google GDR robot embodiment. Higher success rates indicate better performance in completing the tasks.
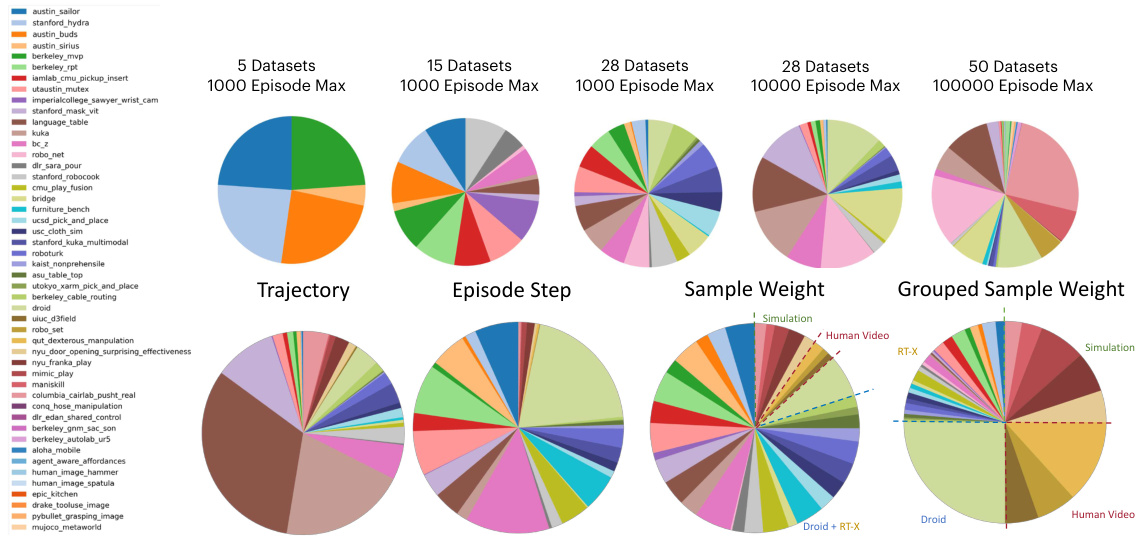
This figure illustrates the heterogeneity of the datasets used in the HPT pre-training. It shows how the datasets are composed of various sources (real robots, simulations, human videos) and how they differ in terms of the number of trajectories, episode steps, sample weights, and grouped sample weights. The pie charts visually represent the proportion of each data source in the overall dataset, highlighting the diversity and scale of the pre-training data.
This figure presents the results of transfer learning experiments using the Heterogeneous Pre-trained Transformers (HPT) model on various robotic manipulation simulation benchmarks. Part (a) shows the success rates achieved by different sized HPT models (HPT-B to HPT-XL) across four different simulation environments. Part (b) compares the performance of HPT-XL against other generalist robotic models on a more recent benchmark, using the Google GDR embodiment. All pre-trained trunks utilized data from the ‘Scaled Settings’ as described in the paper and success rates are based on 150 rollouts for each method.
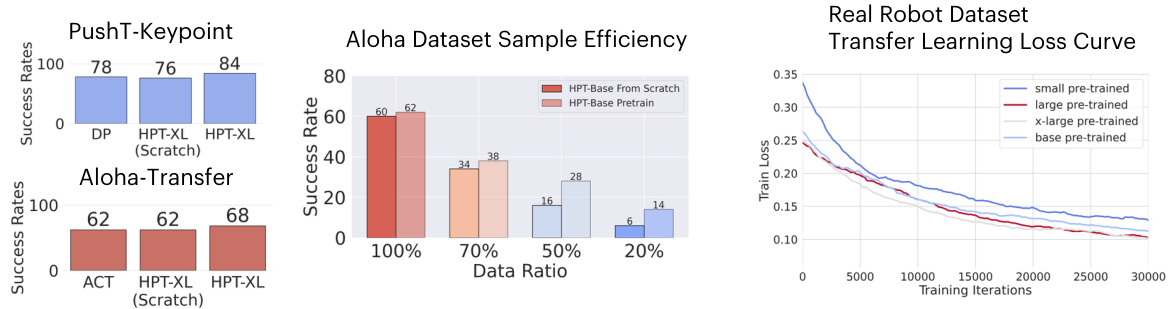
This figure displays the results of transfer learning experiments using pre-trained Heterogeneous Pre-trained Transformers (HPT) models on various robot manipulation simulation benchmarks. Part (a) shows the success rates of HPT models of different sizes (HPT-B, HPT-XL) on several benchmarks, comparing them against baselines of training from scratch. Part (b) shows a comparison with other state-of-the-art generalist models on the Simpler benchmark using the Google GDR robot embodiment.

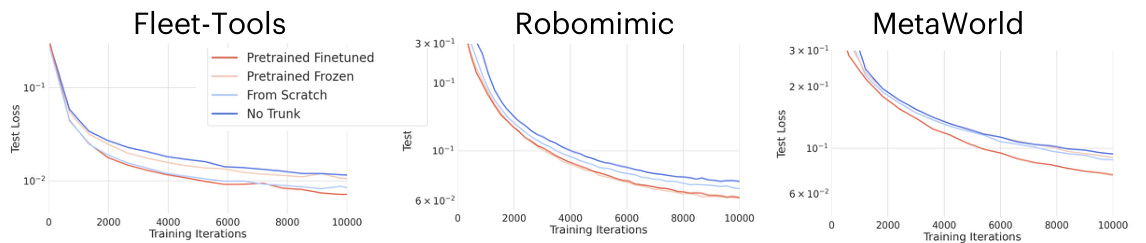
This figure presents an ablation study on the HPT stem, investigating the impact of removing proprioception, vision stems, and vision encoders from the model. The results, presented in validation loss, show that removing either proprioception or vision data significantly impairs performance, highlighting the importance of both modalities for effective pre-training.

This figure shows real-world qualitative results of the pre-trained HPT policies on four different tasks: Sweep Leftover, Fill Water, Scoop Food, and Switch Insertion. The results demonstrate the policies’ ability to perform dynamic and long-horizon contact-rich precision tasks despite scene changes and disturbances, highlighting the robustness and generalization capabilities of the pre-trained HPT models.
More on tables

This table shows the dataset configuration used for pre-training the Heterogeneous Pre-trained Transformers (HPT) model. It compares two settings: ‘Default’ and ‘Scaled’. The ‘Default’ setting uses 27 datasets from the RT-X dataset with a total of 16,000 trajectories (with a maximum of 1000 trajectories per dataset). The ‘Scaled’ setting uses a significantly larger dataset, comprising 52 datasets with 270,000 trajectories in total. The table also provides the number of samples and the batch size used for training in each setting.

This table provides a detailed breakdown of the datasets used in the HPT pre-training. It lists each dataset, the number of trajectories and samples within each dataset, and the percentage each dataset contributes to the total number of trajectories and samples. The datasets are categorized into four groups: real-world robot teleoperation datasets from Open-X, simulation datasets, human video datasets, and in-the-wild deployed robot datasets. This breakdown shows the heterogeneity of the data used for pre-training, highlighting the variety of sources and the diverse nature of the robotic data included.

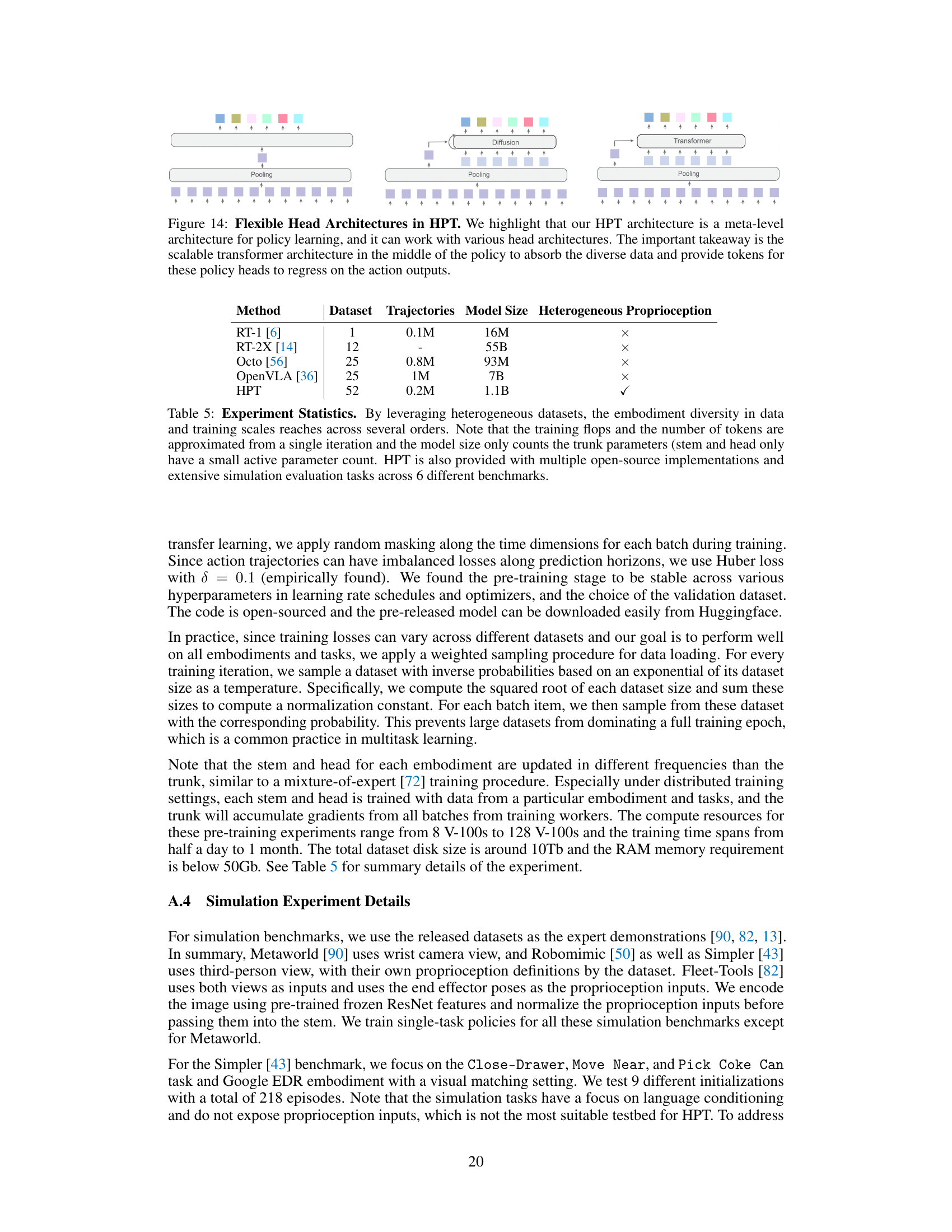
This table summarizes the key statistics and characteristics of the experiments conducted in the paper, comparing HPT’s performance against other methods. It highlights the significant increase in data diversity and scale achieved by HPT, contrasting its use of 52 datasets with other methods utilizing far fewer. The table also shows the disparity in model sizes employed, with HPT’s 1.1B parameters exceeding those of its counterparts. Finally, it notes the availability of multiple open-source implementations and the extensive evaluation performed across six benchmark tasks.
Full paper#