↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Diffusion models excel at image generation but are vulnerable to malicious fine-tuning, leading to the creation of harmful content. Current safety methods like external filters and data cleaning are insufficient to fully mitigate this risk, as they can be easily bypassed. This is a significant concern for the safe deployment of these powerful models.
The paper tackles this by proposing a novel training policy that utilizes contrastive learning and leverages the phenomenon of “catastrophic forgetting.” By increasing the latent space distance between clean and harmful data, the model becomes resistant to malicious fine-tuning. Experiments demonstrate that this method maintains the model’s ability to generate clean images while effectively preventing the creation of harmful ones even after malicious fine-tuning, representing a crucial advance in ensuring safe AI applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on safe AI, particularly in image generation. It directly addresses the critical challenge of malicious fine-tuning in diffusion models, a prevalent concern in ensuring responsible AI development. The proposed methods offer practical solutions and open new avenues for research in safe and robust model training. Its findings have significant implications for the broader AI community, promoting safer and more trustworthy AI systems.
Visual Insights#

This figure compares the image generation results of the baseline model (Stable Diffusion v2.1) and the models trained using the proposed method. The top row showcases harmful images generated by both models before and after malicious fine-tuning. The bottom row displays clean images generated by both models. The results demonstrate that the method effectively prevents the generation of high-quality harmful images, both before and after malicious fine-tuning attempts. While clean image quality is slightly reduced after malicious fine-tuning, it largely remains unaffected.
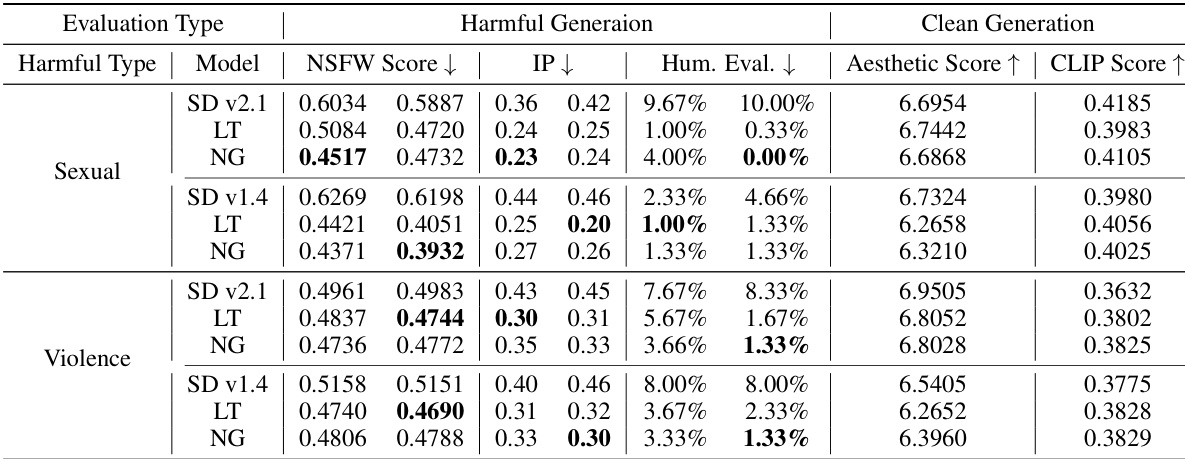
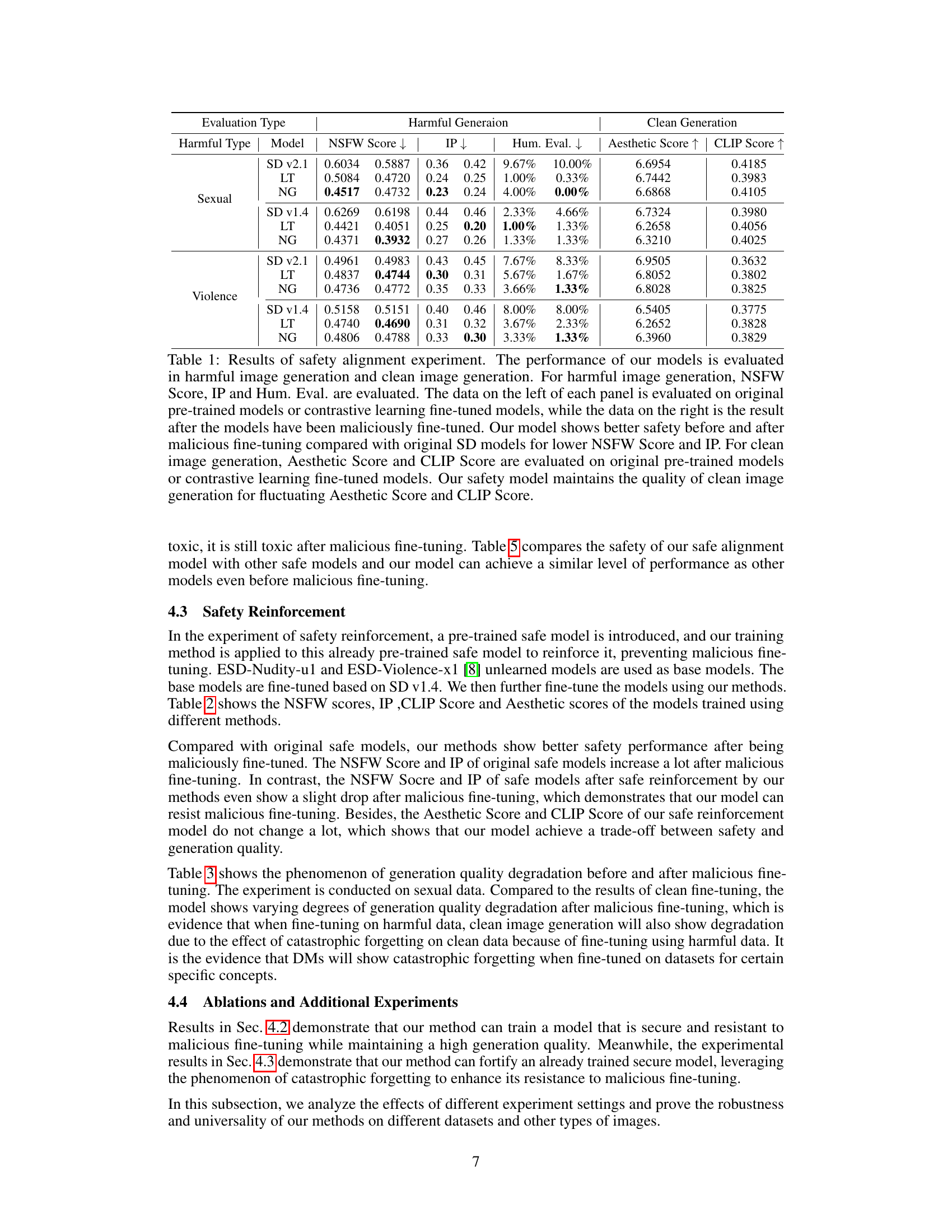
This table presents a quantitative evaluation of the safety alignment of diffusion models using different methods (baseline, latent transformation (LT), and noise guidance (NG)). It compares the performance before and after malicious fine-tuning, considering metrics like NSFW score (lower is better), inappropriate rate (IP, lower is better), human evaluation (lower is better), aesthetic score (higher is better), and CLIP score (higher is better). The results show the effectiveness of the proposed methods (LT and NG) in improving safety and maintaining clean image quality against malicious fine-tuning.
In-depth insights#
Catastrophic Forgetting#
The concept of catastrophic forgetting, a phenomenon where a model trained on a previous task suffers significant performance degradation when fine-tuned on a new task, is thoughtfully explored. The paper leverages this phenomenon in a unique way, not to mitigate it, but to enhance the safety of diffusion models. By treating the generation of harmful images as a ’new task’ and clean images as the ‘old task’, the authors cleverly exploit forgetting. The core idea is to increase the latent-space distance between clean and harmful data distributions during training, using contrastive learning to further this separation. This strategic manipulation makes fine-tuning the model towards harmful image generation significantly more difficult. This approach shifts the focus from external filters, which are easily bypassed, to an inherent, internal mechanism. Furthermore, the method is shown to be robust against various adversarial fine-tuning techniques, suggesting a potentially significant advancement in building safer, more secure AI models.
Contrastive Learning#
Contrastive learning, in the context of this research, is a crucial technique for enhancing the safety and robustness of diffusion models against malicious fine-tuning. The core idea is to maximize the distance between the latent representations of clean and harmful data. By doing so, the model is less likely to generate harmful images after it has been fine-tuned with malicious data, because the model effectively “forgets” the harmful data distribution. This forgetting leverages the phenomenon of catastrophic forgetting. The implementation involves training the model to distinguish between clean and harmful data in the latent space, often using a loss function that encourages similar data points to be clustered together while dissimilar ones are pushed apart. This approach can be combined with other safety mechanisms, such as latent transformations or noise guidance, to further strengthen the model’s resilience against malicious attacks. Contrastive learning thus plays a pivotal role in creating a safer and more robust text-to-image generation model, addressing limitations of external filters and demonstrating a novel approach to model safety in the face of adversarial attacks.
Safe Diffusion Models#
Safe diffusion models are a crucial area of research because of the potential for misuse of diffusion models to generate harmful content. Current approaches often involve post-processing filters, which are easily bypassed. More robust methods focus on modifying the model itself, such as through data filtering or model unlearning techniques, to reduce the generation of harmful outputs. However, these can still be vulnerable to malicious fine-tuning, where an attacker modifies a pre-trained model to produce undesired results. Catastrophic forgetting is an interesting avenue of research, leveraging the model’s tendency to forget previous training data, thereby making it difficult for malicious fine-tuning to succeed. This requires careful design of training strategies to ensure that the model retains its ability to produce safe images while effectively ‘forgetting’ harmful ones. This is achieved by techniques like contrastive learning to maximize the separation between clean and harmful data distributions within the model’s latent space. Future work should focus on improving the robustness of these methods against sophisticated attacks and exploring other techniques to further enhance the safety and reliability of diffusion models.
Malicious Fine-tuning#
Malicious fine-tuning is a significant concern in the field of diffusion models. Adversaries can exploit the model’s ability to learn from new data by fine-tuning it on a dataset of harmful images, thereby subverting its intended purpose and causing it to generate unsafe or undesirable content. This attack vector undermines the safety mechanisms often built into these models, rendering them vulnerable despite safeguards. The paper explores the problem of malicious fine-tuning as a critical challenge for the safety and reliability of diffusion models. It investigates methods to protect models against such attacks using contrastive learning to leverage the phenomenon of catastrophic forgetting. The goal is to significantly increase the distance between the latent space representations of clean and harmful data, making it difficult for the model to ‘remember’ and generate harmful content even after malicious fine-tuning. This approach aims for a robust defense that maintains the model’s ability to generate clean images while significantly reducing its susceptibility to malicious attacks.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the catastrophic forgetting approach to other model architectures, beyond diffusion models, is crucial to broaden its applicability. Investigating alternative methods for inducing forgetting, perhaps through novel regularization techniques or architectural modifications, could enhance its effectiveness and robustness. The impact of different noise distributions and latent space transformations on model safety should be further analyzed, particularly for complex, real-world scenarios. Addressing the challenges of maintaining clean image generation while enhancing safety is paramount; future work could incorporate generative adversarial network (GAN) or other methods to improve the overall image quality. Finally, a thorough investigation into the limitations of the method, and how to overcome them, is necessary; this involves developing effective defenses against sophisticated adversarial attacks designed to bypass catastrophic forgetting.
More visual insights#
More on figures
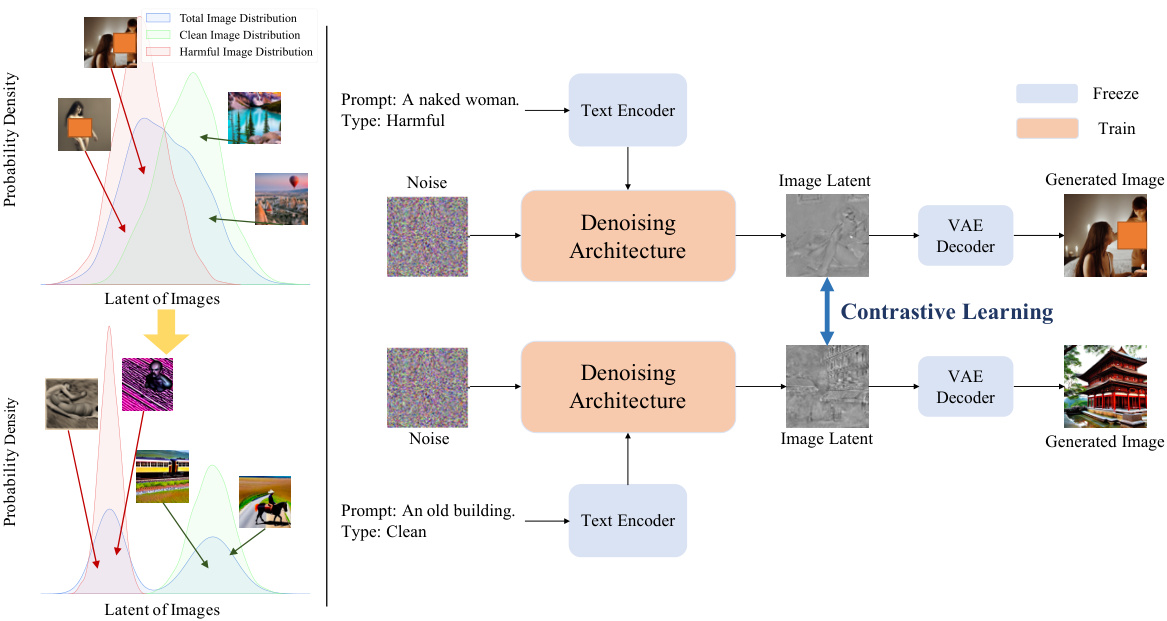
This figure illustrates the core idea of the proposed method. The left panel shows how the method leverages catastrophic forgetting by widening the distribution between clean and harmful data in the latent space. The right panel shows how contrastive learning is used to achieve this separation, training the model to distinguish between clean and harmful data distributions. The goal is to make generating harmful images a more difficult task for the model, effectively preventing malicious fine-tuning from degrading the model’s safety.
This figure compares the image generation results of the baseline Stable Diffusion v2.1 model and models trained using the proposed method. The top row shows harmful images generated by both models, illustrating the degradation in quality caused by the malicious fine-tuning that the proposed method mitigates. The bottom row shows clean images generated by both models before and after malicious fine-tuning, demonstrating the method’s success in preserving the model’s ability to generate clean images even after malicious fine-tuning.
This figure compares image generation results from the Stable Diffusion v2.1 baseline model and the model trained using the proposed method. The top row displays harmful images generated by both models; the bottom row shows clean images generated by both. The results illustrate the effectiveness of the proposed method in maintaining clean image generation quality while preventing the generation of harmful images even after malicious fine-tuning. The method’s safety alignment prevents the model from generating harmful images initially, and it resists the malicious fine-tuning attempts which only produce low-quality images.

This figure shows the results of the proposed method compared to the baseline model (Stable Diffusion v2.1). The top row displays images generated by the baseline model, illustrating the generation of harmful content before and after malicious fine-tuning. The bottom row shows images generated by the proposed method, demonstrating the method’s ability to maintain the generation quality of clean images while preventing the generation of harmful images, even after malicious fine-tuning. The difference in image quality between the baseline and proposed method highlights the effectiveness of the proposed approach.

This figure compares image generation results from the baseline Stable Diffusion v2.1 model and the models trained using the proposed method. The top row shows examples of harmful images generated by both models, illustrating that the proposed method successfully degrades the quality of harmful images even after malicious fine-tuning, indicating improved safety. The bottom row shows clean images generated by both models, showcasing that the proposed method maintains the generation quality of clean images, even with a slight decrease in color and texture detail after malicious fine-tuning. The orange boxes were added for publication purposes and are not part of the original figure.
More on tables
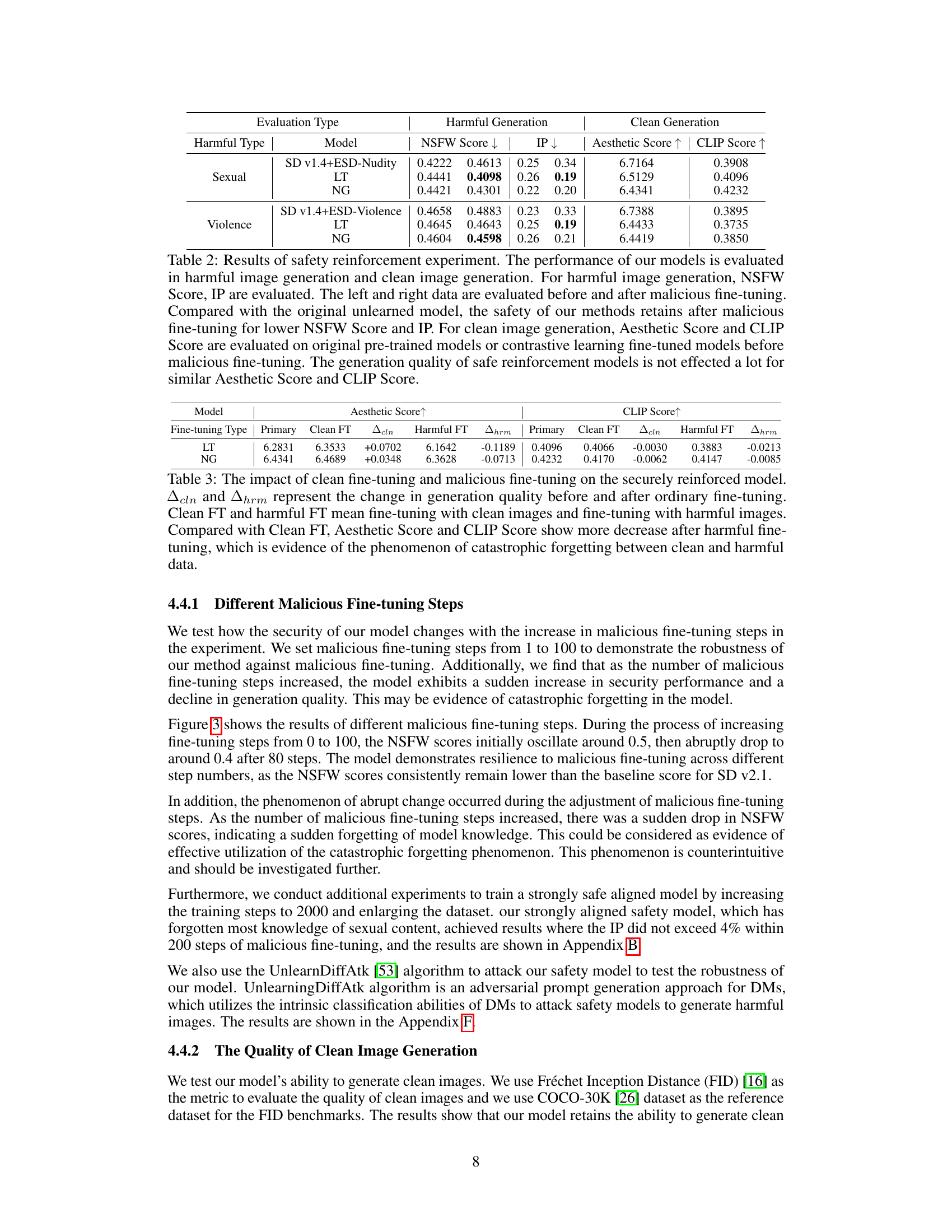
This table presents the results of a safety reinforcement experiment. It compares the performance of original safe models with models reinforced using the proposed method, both before and after malicious fine-tuning. The metrics used include NSFW Score, IP (Inappropriate Rate), Aesthetic Score, and CLIP Score, measuring the balance between safety and maintaining the quality of clean image generation.

This table presents a comparison of the changes in image generation quality (Aesthetic and CLIP scores) before and after fine-tuning a model with both clean and harmful images. The results show that harmful fine-tuning leads to more significant degradation in the quality of clean image generation than clean fine-tuning, highlighting the effect of catastrophic forgetting.
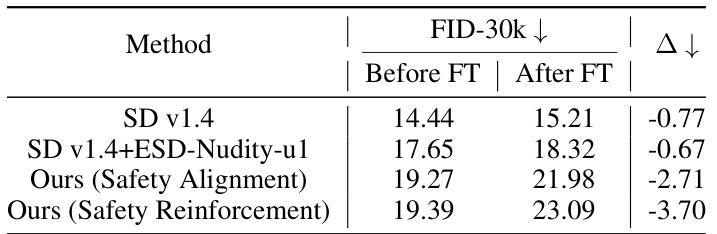
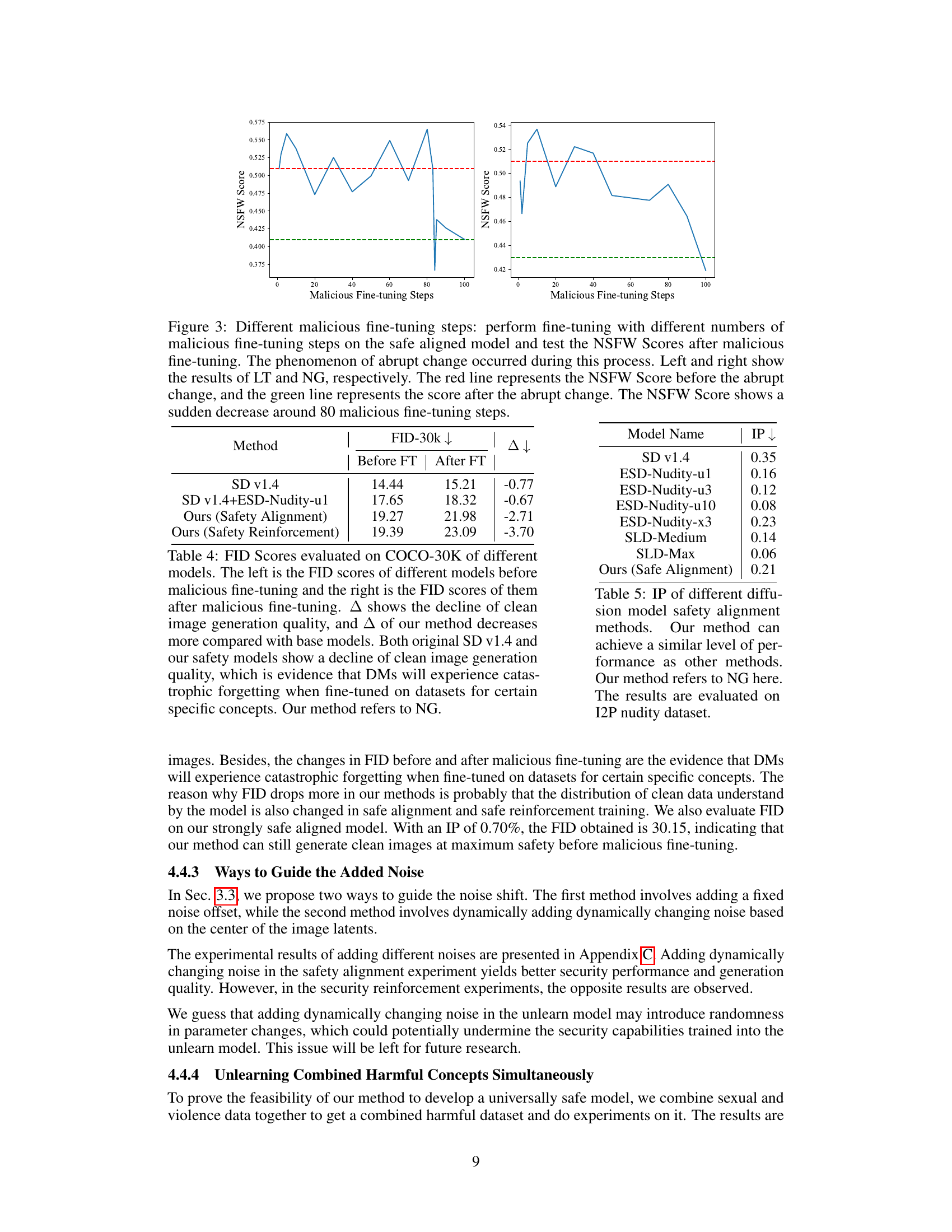
This table presents FID scores (Fréchet Inception Distance) calculated on the COCO-30K dataset, evaluating the quality of clean image generation before and after malicious fine-tuning. Lower FID scores indicate better quality. It compares different models: the original Stable Diffusion (SD) v1.4, SD v1.4 fine-tuned with an ESD-Nudity-u1 model for safety, and the proposed method with safety alignment and reinforcement. The ‘Δ’ column shows the decrease in FID score (quality drop) after malicious fine-tuning. The results highlight the impact of malicious fine-tuning and demonstrate that the proposed method mitigates the quality degradation more effectively.
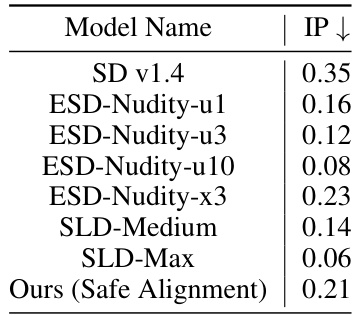
This table compares the Inappropriate Rate (IP) of different models designed to prevent the generation of inappropriate images. It includes several baseline models (ESD-Nudity variants, SLD-Medium, SLD-Max) and the proposed method (‘Ours (Safe Alignment)’). The IP metric quantifies the percentage of images incorrectly identified as safe. Lower IP values indicate better safety performance. The table shows that the proposed method achieves comparable safety performance to the state-of-the-art baselines.
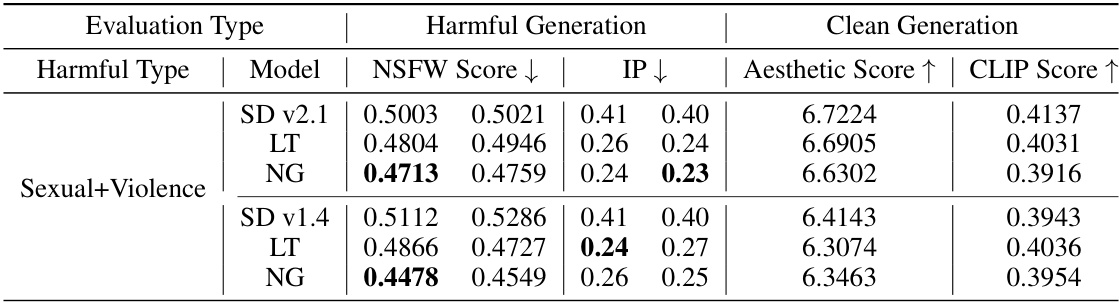
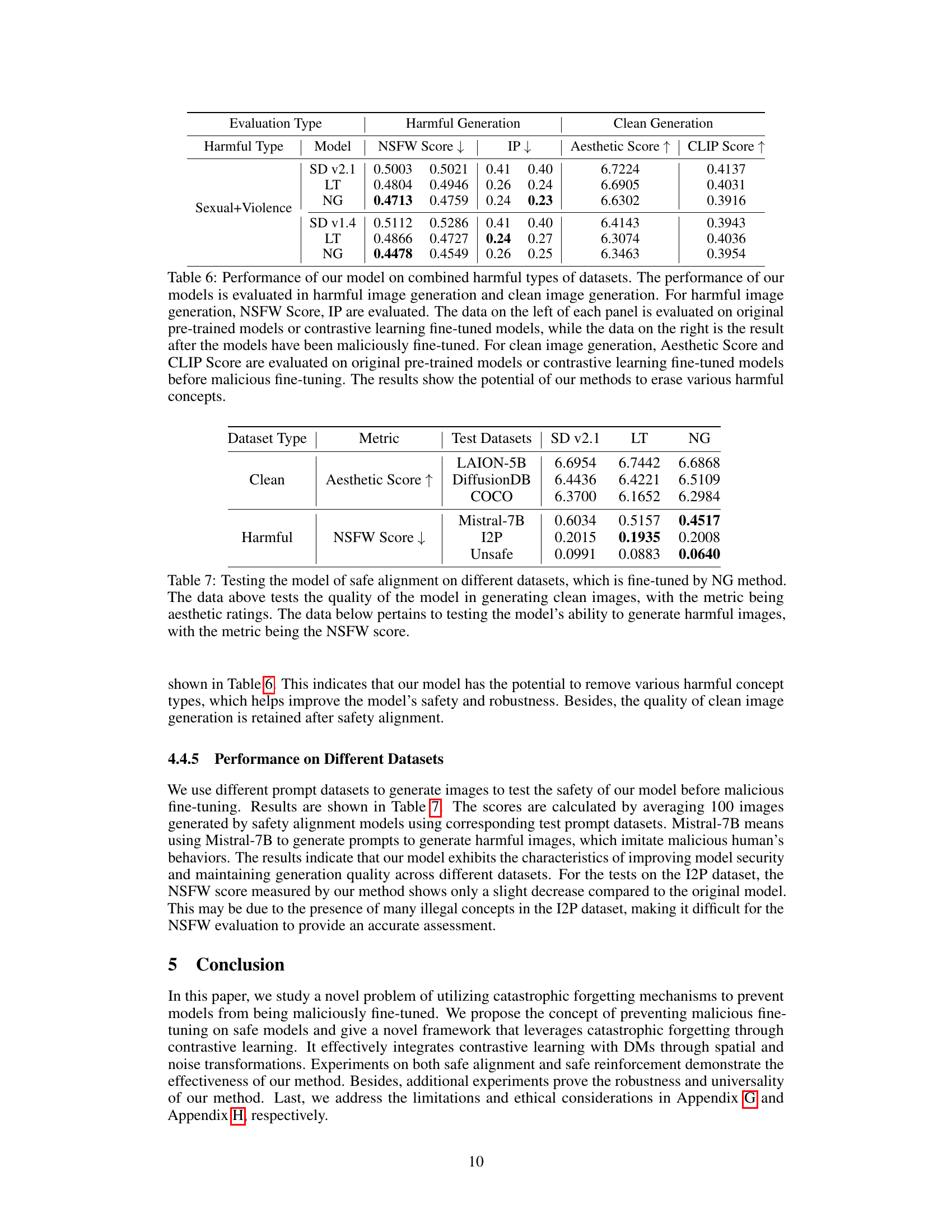
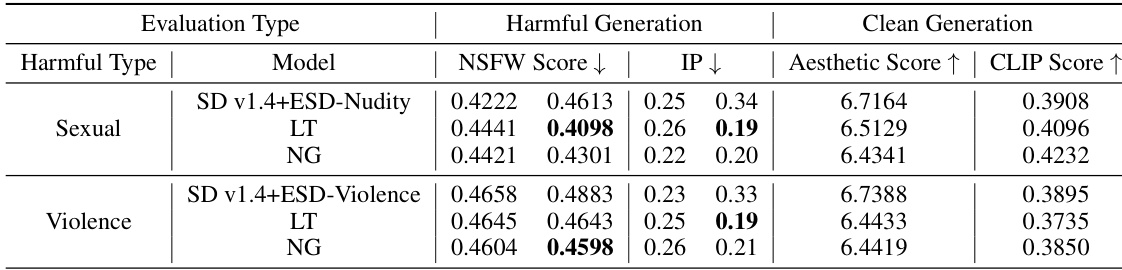
This table presents the results of experiments evaluating the model’s performance on datasets containing both sexual and violent content. It compares the NSFW score, inappropriate rate (IP), aesthetic score, and CLIP score before and after malicious fine-tuning, for both the original model and models fine-tuned with the proposed latent transformation (LT) and noise guidance (NG) methods. The results demonstrate the effectiveness of these methods in preventing the generation of harmful images while maintaining the generation quality of clean images.
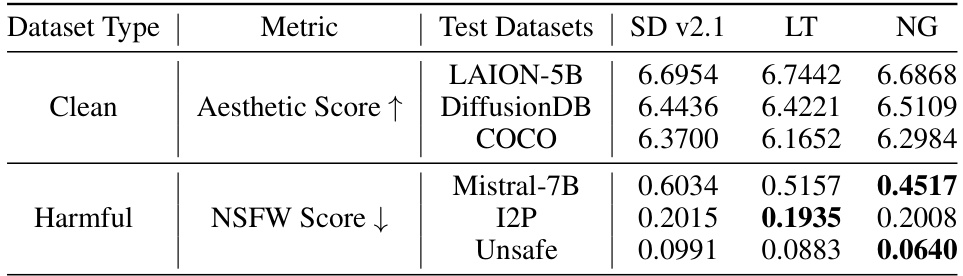
This table presents the results of evaluating the safety and image quality of the model on various datasets. The ‘Clean’ section shows the Aesthetic Score (higher is better) for clean image generation on LAION-5B, DiffusionDB, and COCO datasets. The ‘Harmful’ section shows the NSFW Score (lower is better) for harmful image generation on Mistral-7B, I2P, and Unsafe datasets. The results demonstrate the model’s ability to generate high-quality clean images while effectively suppressing the generation of harmful images across different datasets.
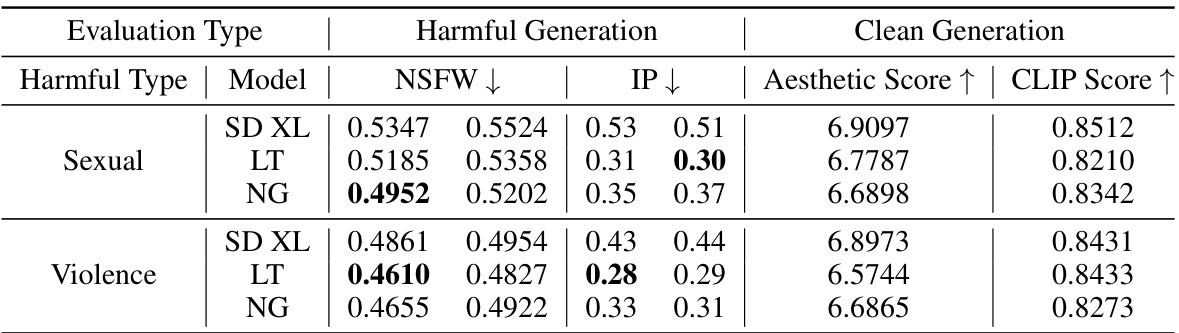
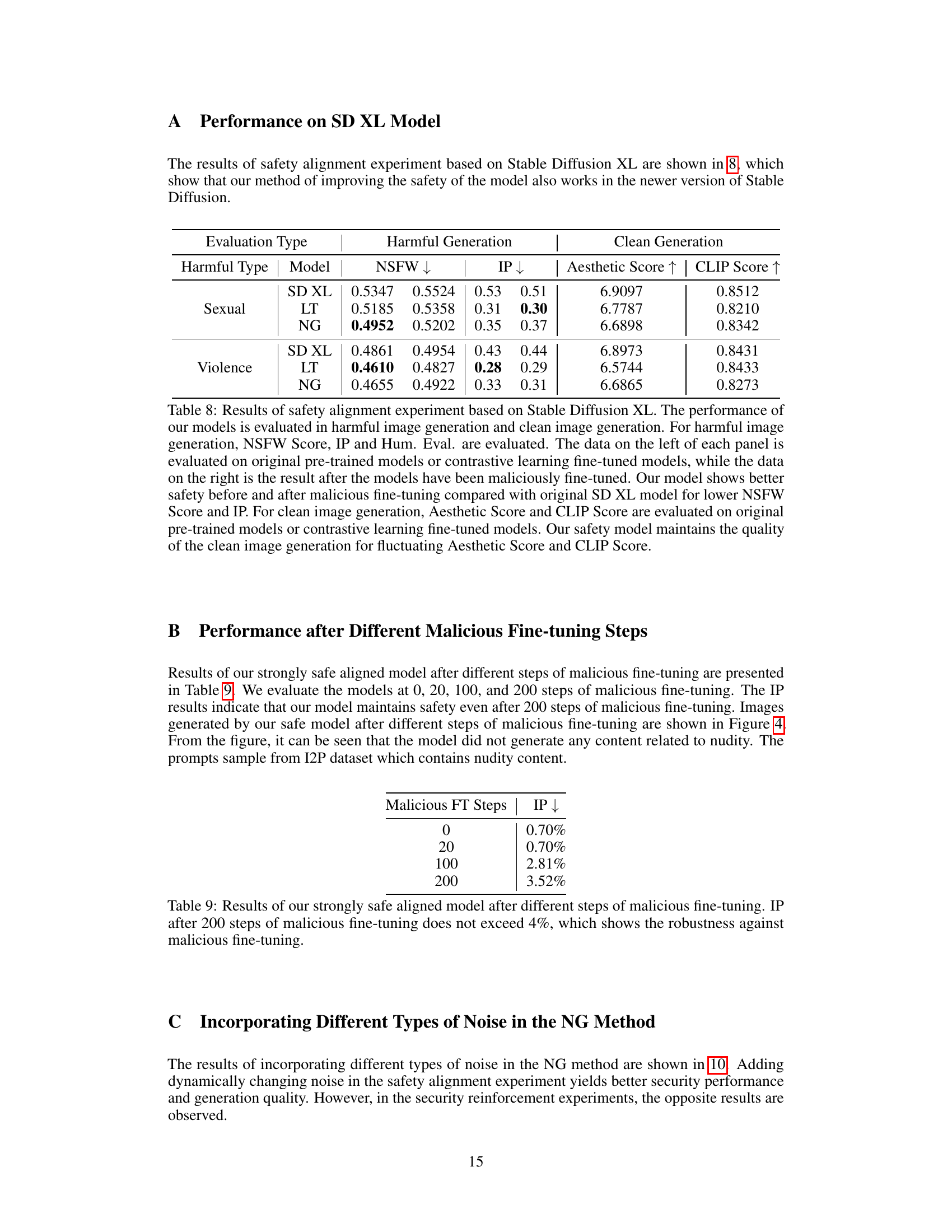
This table presents the results of a safety alignment experiment using Stable Diffusion XL. It compares the performance of the original model and models fine-tuned with the proposed method (LT and NG) before and after malicious fine-tuning. The metrics evaluated include NSFW Score, IP, Aesthetic Score, and CLIP Score, assessing both the generation of harmful and clean images. The results demonstrate the effectiveness of the method in improving the safety and maintaining the quality of clean image generation.

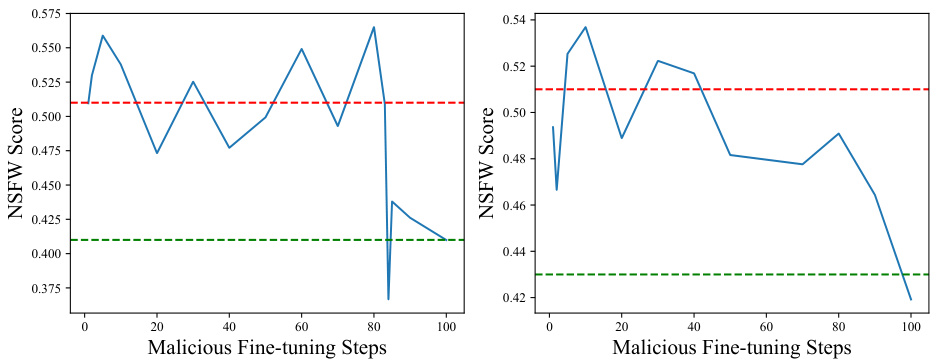
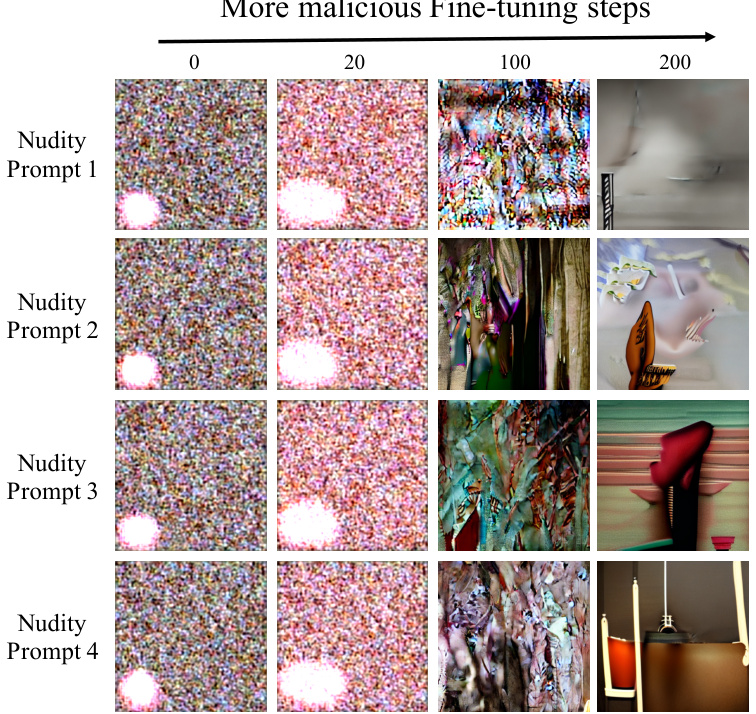
This table presents the results of evaluating the model’s robustness against malicious fine-tuning by varying the number of malicious fine-tuning steps. The Inappropriate Rate (IP), a measure of the model’s safety, is assessed after 0, 20, 100, and 200 malicious fine-tuning steps. The results show that even after 200 steps of malicious fine-tuning, the IP remains below 4%, indicating that the model effectively resists malicious attempts to make it generate harmful images.
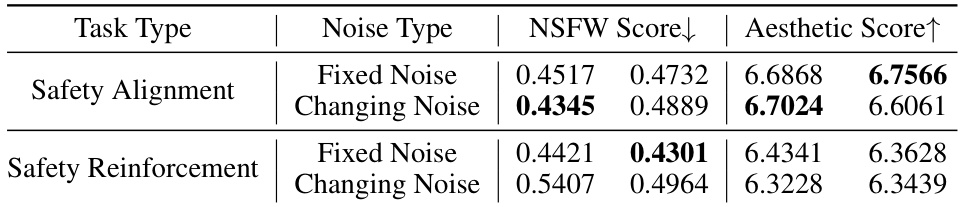
This table presents the results of an experiment comparing two noise-adding methods (fixed noise and changing noise) within two different training scenarios (safety alignment and safety reinforcement). It shows the NSFW scores (lower is better, indicating fewer unsafe images) and Aesthetic scores (higher is better, indicating better image quality) before and after malicious fine-tuning. The results indicate the effectiveness of the noise methods in improving model safety.

This table presents the results of attacking a safety-aligned diffusion model using the UnlearnDiffAtk method. It compares the attack success rate (ASR) of the proposed model against three other unlearned diffusion models (ESD, FMN, SLD). The lower ASR values indicate a stronger resilience to attacks. The proposed model demonstrates a significantly lower ASR when attacked, indicating better safety and robustness against malicious fine-tuning.
Full paper#