↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Large-scale visual-language models like CLIP struggle with noisy web-sourced data, hindering their performance. Current data selection methods either rely on external models or train new embedding models, both resource intensive. This paper focuses on developing better metrics and selection strategies applicable to any CLIP embedding without requiring special model properties.
The paper proposes two novel methods: negCLIPLoss, a refined quality metric inspired by CLIP’s training loss, and NormSim, a norm-based metric that measures similarity between pretraining data and target data for known downstream tasks. Experiments on a benchmark dataset demonstrate significant performance improvements (5.3% on ImageNet-1k and 2.8% on average across 38 downstream tasks) compared to baselines using only the original CLIP model. Furthermore, the methods are shown to be compatible with existing techniques, achieving a new state-of-the-art.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large-scale visual-language models. It offers novel data selection methods that significantly improve model performance, addressing a critical bottleneck in multimodal contrastive learning. The proposed methods are universally applicable, compatible with existing techniques, and computationally efficient, making them highly valuable for the field. The findings open new avenues for research in data quality assessment and efficient model training, potentially impacting various downstream applications.
Visual Insights#

This figure illustrates how the proposed negCLIPLoss metric addresses the limitations of the traditional CLIPScore metric in evaluating the quality of image-text pairs for multimodal contrastive learning. CLIPScore can either underestimate or overestimate quality due to systematic biases. negCLIPLoss incorporates a normalization term derived from the CLIP training loss to mitigate these biases, providing a more accurate and robust measure of data quality.
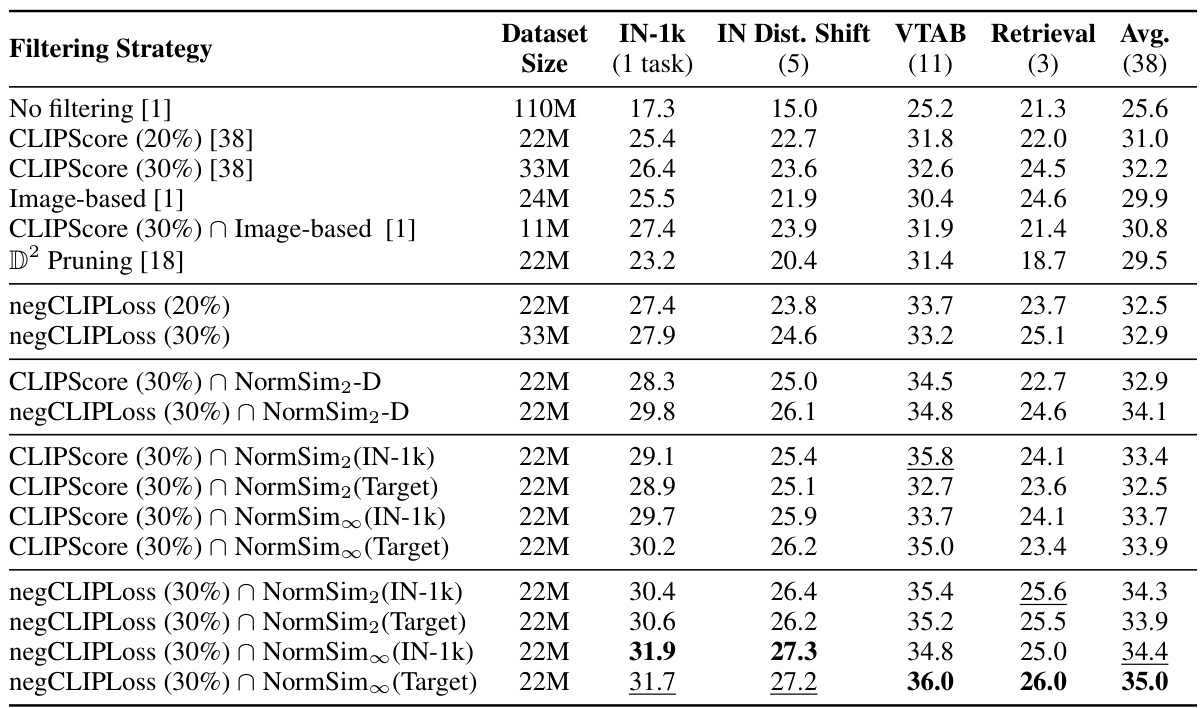
This table presents the results of data selection methods that exclusively utilize OpenAI’s CLIP-L/14 model for filtering, categorized under the D1 category in the paper. The table compares various filtering strategies using metrics such as CLIPScore, negCLIPLoss, and NormSim, showcasing their impact on downstream task performance across different datasets (ImageNet-1k, IN Dist. Shift, VTAB, Retrieval) with varying subset sizes. NormSim is further broken down by its target data source (ImageNet-1k training data or all 24 downstream tasks), and a dynamic version (NormSim-D) using an iteratively refined subset of training data is also evaluated.
In-depth insights#
negCLIPLoss Metric#
The proposed negCLIPLoss metric offers a refined approach to multimodal data selection for contrastive learning, addressing limitations of the conventional CLIPScore. Instead of solely relying on the cosine similarity between individual image-text pairs, negCLIPLoss incorporates a normalization term derived from the CLIP training loss. This normalization considers the alignment between a sample and its contrastive pairs, mitigating biases inherent in CLIPScore where high similarity might not always indicate high-quality data. This normalization effectively reduces systematic biases that could inflate scores, such as those stemming from overly generic captions. The resulting metric provides a more nuanced and robust assessment of data quality, proving superior in identifying high-quality image-text pairs suitable for downstream tasks. Empirical results showcase its effectiveness, yielding significant improvements over CLIPScore in downstream performance across various benchmarks. negCLIPLoss’s compatibility with existing data selection techniques further enhances its practical value, contributing to a more powerful and versatile approach to data filtering in visual-language model training.
NormSim Scoring#
NormSim scoring, as proposed in the research paper, presents a novel approach to data selection for multimodal contrastive learning. Instead of solely relying on the alignment between visual and textual modalities within a single sample (as in CLIPScore), NormSim incorporates information from downstream tasks by measuring the similarity between the visual features of the training data and a target dataset representing the downstream task distribution. This is a significant departure from existing methods, as it directly incorporates task-relevant information into the data selection process. The method leverages p-norm similarity to quantify this relationship, offering flexibility in emphasizing either the closest or most dissimilar samples based on the chosen p-value. The authors’ empirical results demonstrate that NormSim effectively complements existing data selection strategies, leading to notable improvements on downstream tasks. NormSim’s power lies in its ability to focus the data selection on training samples most relevant to the target tasks. A key advantage is its compatibility with various existing techniques, making it a valuable addition to the multimodal contrastive learning pipeline. The use of a proxy downstream dataset when target data is unavailable is also a practical contribution, increasing the applicability of NormSim across different scenarios.
Data Selection Methods#
The research paper explores data selection methods for enhancing multimodal contrastive learning, a technique used in training large-scale visual-language models. It critically examines existing approaches, highlighting their limitations, particularly when dealing with noisy web-curated datasets. The core contribution lies in proposing novel methods, negCLIPLoss and NormSim. negCLIPLoss improves data quality assessment by incorporating contrastive pairs into the evaluation metric, addressing shortcomings of traditional methods. NormSim introduces a norm-based metric that leverages downstream task knowledge, improving the selection of training data relevant to specific tasks. The paper demonstrates the effectiveness of these new methods through extensive experiments, showcasing superior performance compared to existing baselines on various downstream tasks. Overall, the work presents a significant advancement in data selection strategies for multimodal contrastive learning, emphasizing the importance of combining quality assessment with task relevance for optimal model performance. The methods are also shown to be compatible with existing state-of-the-art techniques, further enhancing their applicability.
Multimodal Contrastive Learning#
Multimodal contrastive learning is a machine learning technique that learns representations from multiple modalities (e.g., image, text, audio) by contrasting similar and dissimilar samples across modalities. The core idea is to learn embeddings that capture the semantic relationships between different modalities, enabling tasks such as zero-shot image classification or cross-modal retrieval. The paper explores data selection methods for improving the performance of multimodal contrastive learning models. It introduces two novel techniques: negCLIPLoss, which refines the standard CLIP loss for better data quality assessment; and NormSim, a norm-based metric that leverages downstream task knowledge for improved data selection. The results demonstrate significant performance gains over existing approaches, highlighting the potential of these novel methods for enhancing multimodal contrastive learning and showcasing the importance of effective data selection in improving model generalization and robustness.
Future Research#
Future research directions stemming from this CLIPLoss and NormSim-based data selection work could explore several promising avenues. Extending the NormSim metric to incorporate other modalities beyond vision, such as audio or text features, could lead to more robust and comprehensive data selection for truly multimodal tasks. Investigating the interplay between data diversity and quality is crucial; while this paper demonstrates improved performance, further research could quantify the optimal balance between these factors. Applying the methods to other large-scale multimodal datasets is important to confirm generalizability. Developing more efficient algorithms for computing negCLIPLoss and NormSim in a way scalable to even larger datasets would enhance practical applicability. Finally, a deeper investigation into the theoretical underpinnings of negCLIPLoss and NormSim, particularly exploring their relationships with downstream task performance and generalizability, could yield valuable insights.
More visual insights#
More on figures
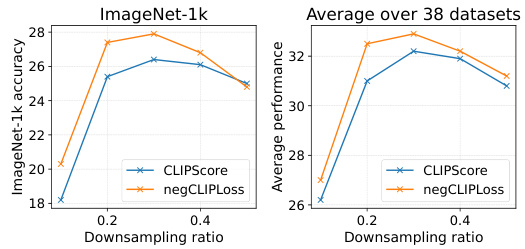
This figure compares the performance of negCLIPLoss and CLIPScore on the DataComp-medium benchmark across various downsampling ratios. It shows the ImageNet-1k accuracy and the average performance across 38 downstream datasets. The results demonstrate that negCLIPLoss consistently outperforms CLIPScore across different downsampling ratios, suggesting its effectiveness as a superior metric for data selection in multimodal contrastive learning.
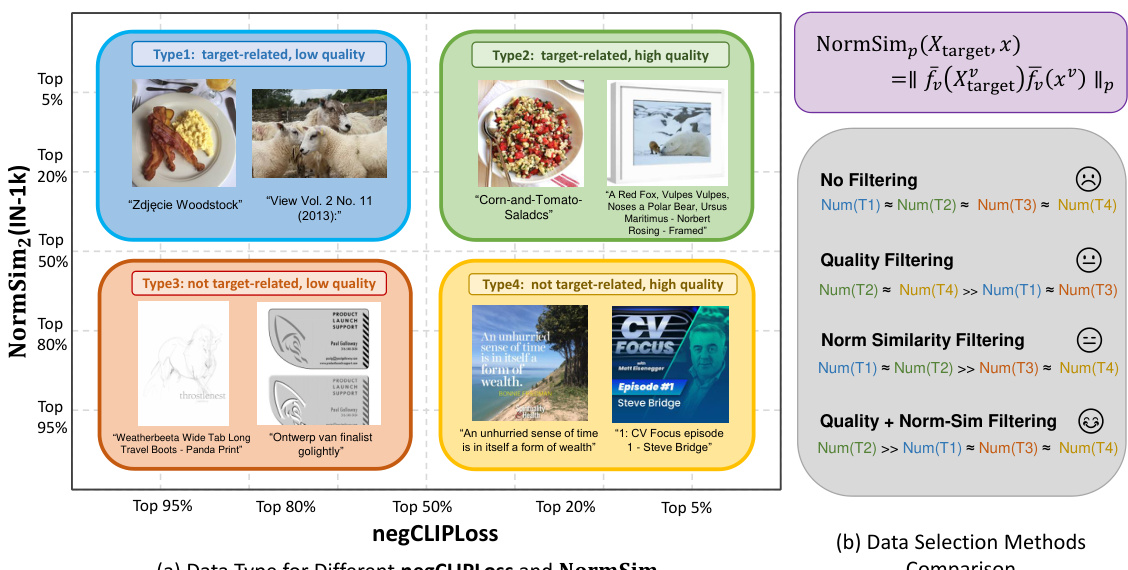
This figure illustrates the NormSim metric’s effectiveness in data selection within the DataComp benchmark. It shows how NormSim, combined with negCLIPLoss, balances data quality (measured by negCLIPLoss) with relevance to target downstream tasks (measured by NormSim). Panel (a) visualizes four data types based on their NormSim and negCLIPLoss scores, highlighting that high-quality data (high negCLIPLoss) may not always be relevant to the downstream tasks (low NormSim). Panel (b) compares the distribution of these data types across various data selection methods, demonstrating that the combination of negCLIPLoss and NormSim effectively selects a higher proportion of target-related, high-quality data.
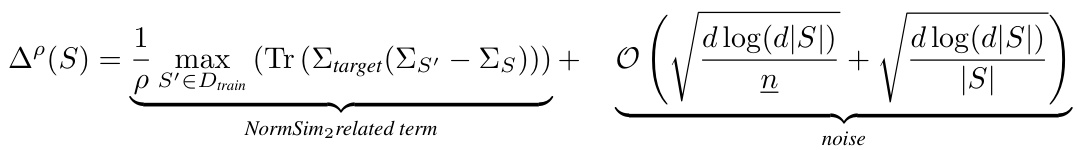
This figure illustrates the three main directions for data selection methods in multimodal contrastive learning. It highlights the resources used in each approach: the CLIP teacher model, downstream target data, external image-text datasets, and external non-CLIP models. Direction 1 uses only the original CLIP model and target data; Direction 2 trains a new CLIP model using external data; and Direction 3 leverages external non-CLIP models for data selection. The figure emphasizes that the proposed methods (negCLIPLoss and NormSim) are orthogonal to existing techniques and can be combined to achieve state-of-the-art results.
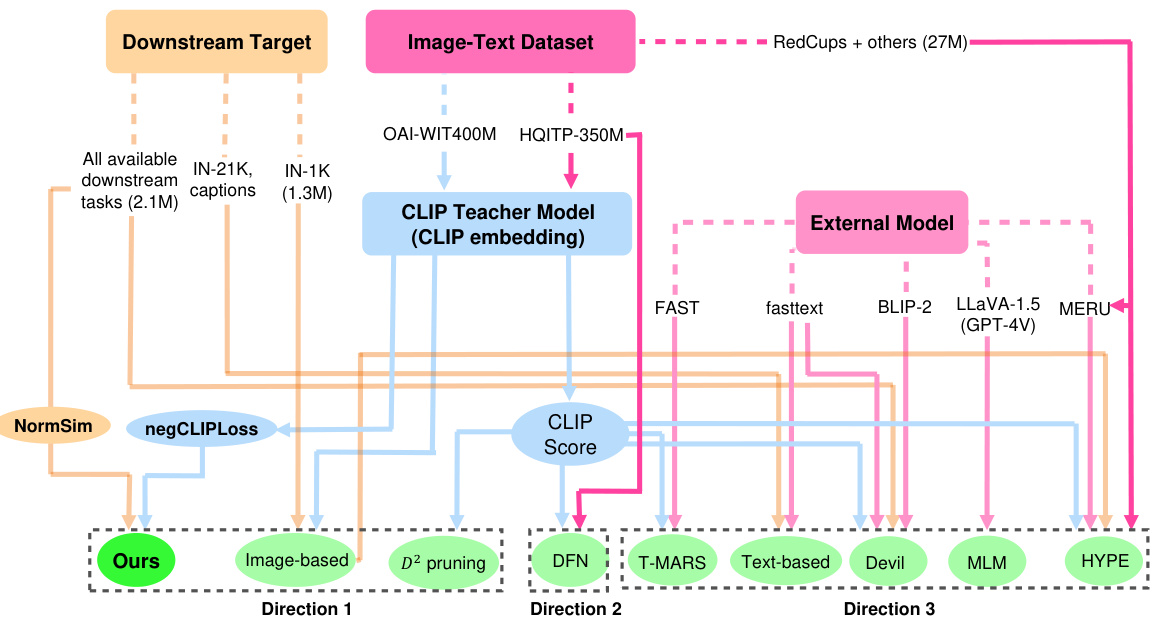
This figure illustrates the three main approaches to data selection for multimodal contrastive learning. The three directions are differentiated by the resources they leverage: Direction 1 uses only the original CLIP model and target downstream data. Direction 2 trains a new CLIP-style model using external data for improved selection. Direction 3 employs external non-CLIP models to aid in the selection process. The figure shows how the authors’ proposed methods (NormSim and negCLIPLoss) fit within this framework, ultimately achieving state-of-the-art results by combining with existing methods.
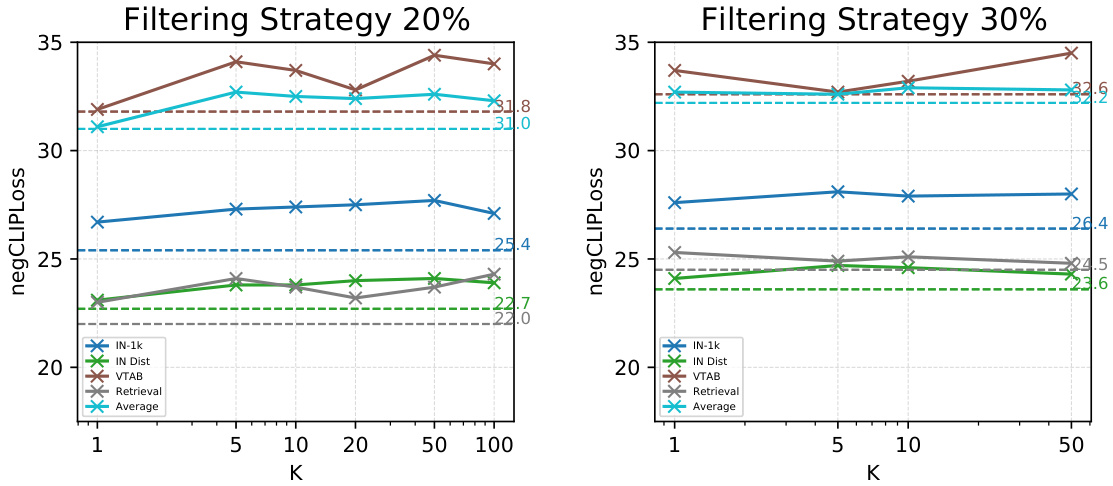
This figure shows the performance of negCLIPLoss and CLIPScore on the DataComp-medium benchmark across different downstream tasks (ImageNet-1k, IN Dist, VTAB, Retrieval) with varying numbers of randomly selected batches (K) used in the negCLIPLoss calculation. The results indicate that using at least 5 batches (K≥5) leads to consistent improvement of negCLIPLoss over CLIPScore across all metrics.

This figure illustrates how the proposed negCLIPLoss method addresses the limitations of the traditional CLIPScore metric in evaluating the quality of image-text pairs. CLIPScore can misjudge data quality, either underestimating or overestimating it. negCLIPLoss improves accuracy by incorporating a normalization term derived from CLIP training loss, effectively mitigating biases and leading to a more precise quality assessment. The examples show how CLIPScore’s limitations result in inaccurate rankings, while negCLIPLoss offers a more reliable evaluation.

This figure illustrates how the proposed negCLIPLoss metric addresses the limitations of the traditional CLIPScore metric in evaluating the quality of image-text pairs for multimodal contrastive learning. CLIPScore, which measures cosine similarity between image and text embeddings, can underestimate or overestimate quality due to systematic biases. NegCLIPLoss incorporates a normalization term derived from CLIP training loss, effectively mitigating these biases and providing a more accurate assessment of data quality. The examples in the figure demonstrate scenarios where CLIPScore misjudges quality, while negCLIPLoss provides a more nuanced and accurate evaluation.
This figure illustrates the concept of negCLIPLoss and how it addresses the limitations of CLIPScore in assessing the quality of image-text pairs. CLIPScore, a commonly used metric, can either underestimate or overestimate the quality. negCLIPLoss improves upon this by incorporating a normalization term derived from the negative CLIP loss calculated on training data. This normalization helps to correct for systematic biases that might lead to inaccurate CLIPScore values. The figure uses examples with visual and textual descriptions to demonstrate how negCLIPLoss provides a more accurate and reliable metric for evaluating data quality.

This figure illustrates the NormSim metric’s effectiveness in data selection for multimodal contrastive learning. Panel (a) shows how NormSim and negCLIPLoss interact; high negCLIPLoss indicates high-quality data, but NormSim further filters out data irrelevant to downstream tasks, as shown using ImageNet-1k as an example. Panel (b) demonstrates that combining NormSim and negCLIPLoss improves data quality and relevance to the target task, thus boosting performance.

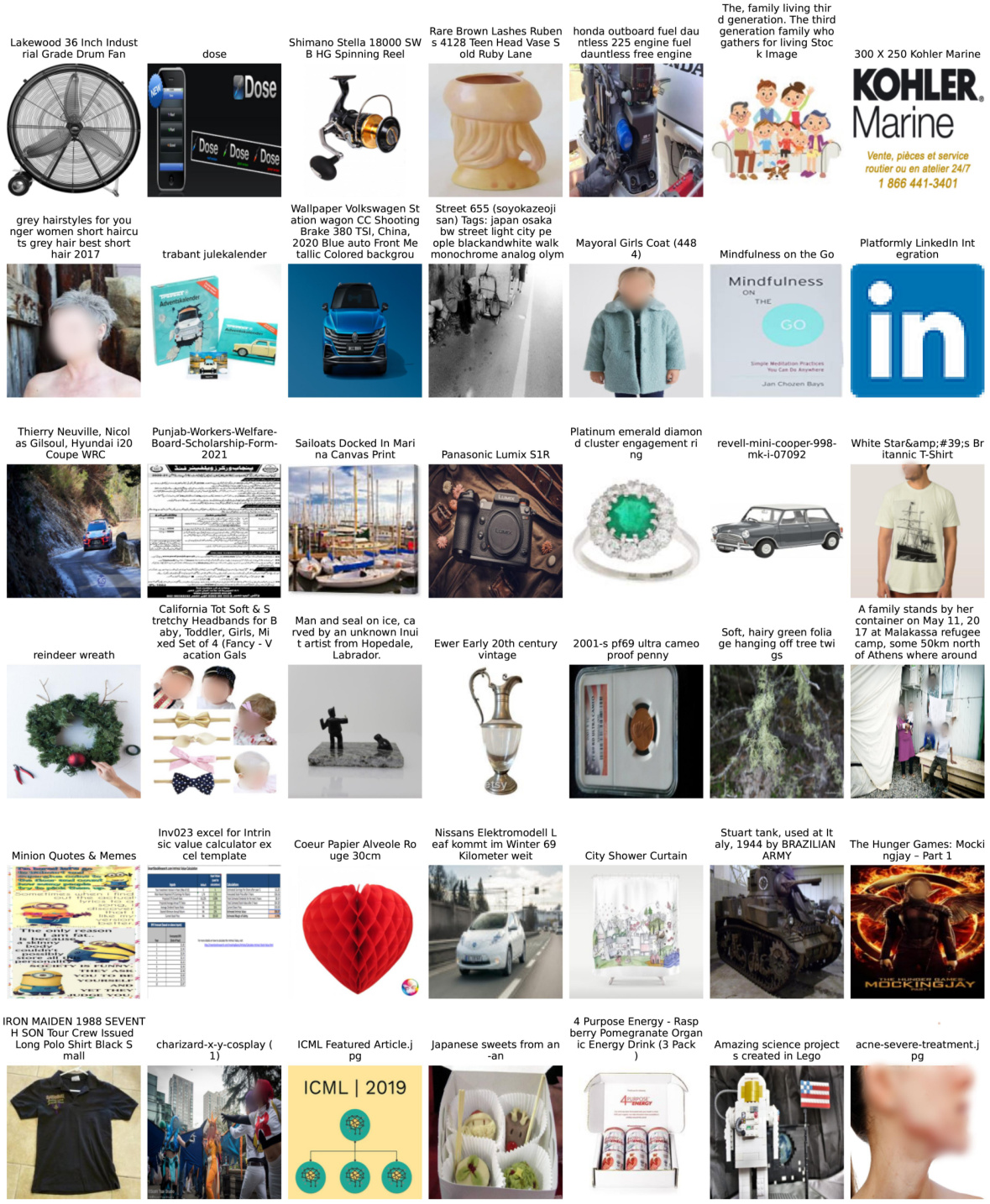
This figure visualizes a subset of images selected using the NormSim∞(Target) metric. NormSim∞(Target) is a method introduced in the paper to select high-quality training data by measuring the similarity between the visual features of the training data and a target dataset (in this case, the ImageNet-1k dataset). The figure shows examples of images from the top 50% of the ranked data, illustrating the type of images considered to be high quality and relevant to the downstream tasks according to this metric. The visualization is intended to give the reader an idea of the kinds of images the model considers high-quality, and potentially offers insights into the characteristics that make them valuable for multimodal contrastive learning.
This figure illustrates the concept of negCLIPLoss and how it addresses the limitations of CLIPScore in accurately assessing the quality of image-text pairs. CLIPScore, by only considering the cosine similarity between image and text embeddings of a single sample, can underestimate or overestimate the quality, especially in cases with systematic biases. negCLIPLoss improves upon this by introducing a normalization term based on the alignment between a sample and its contrastive pairs, leading to more robust and accurate quality measurements.
More on tables
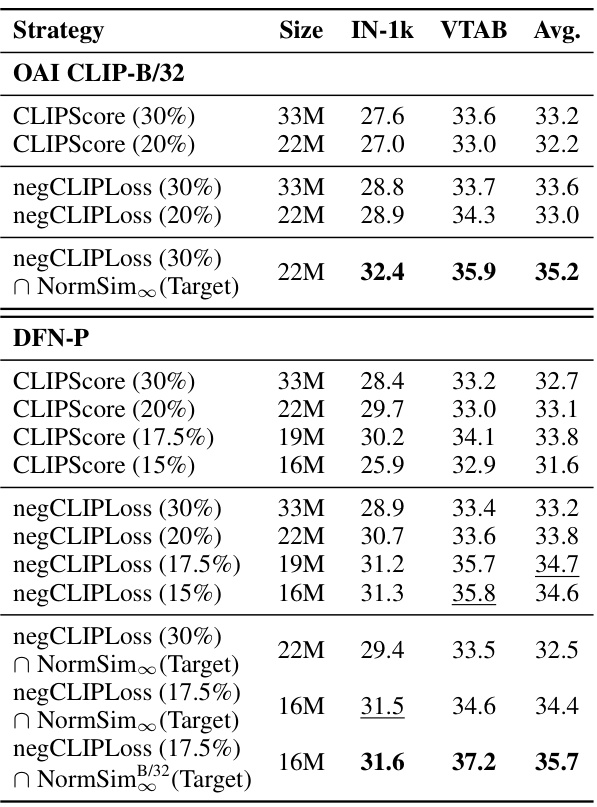
This table presents the results on the DataComp-medium benchmark for various data selection methods. It focuses on comparing the performance of different strategies using only OpenAI’s CLIP-B/32 model or the publicly available DFN-P model. The table shows the dataset size used, ImageNet-1k accuracy, VTAB average score, and the overall average across all 38 downstream tasks in the benchmark. The results highlight the impact of different data selection techniques on model performance in the context of multimodal contrastive learning.
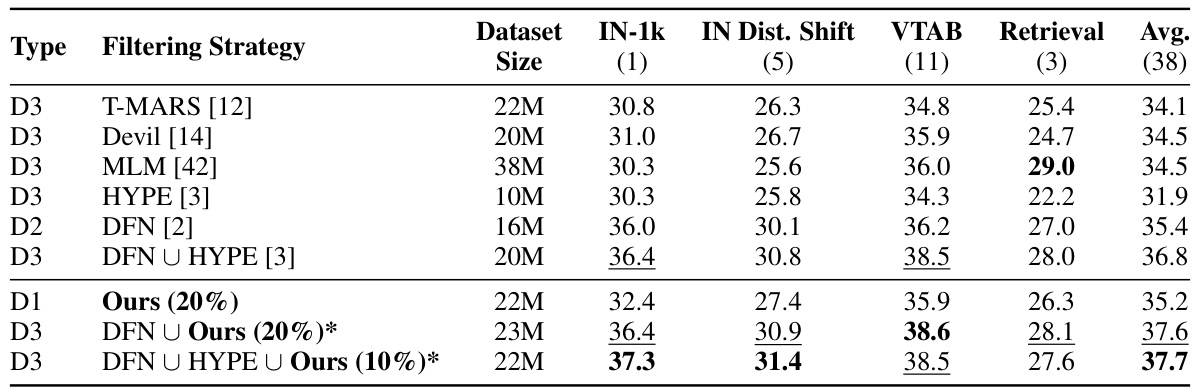
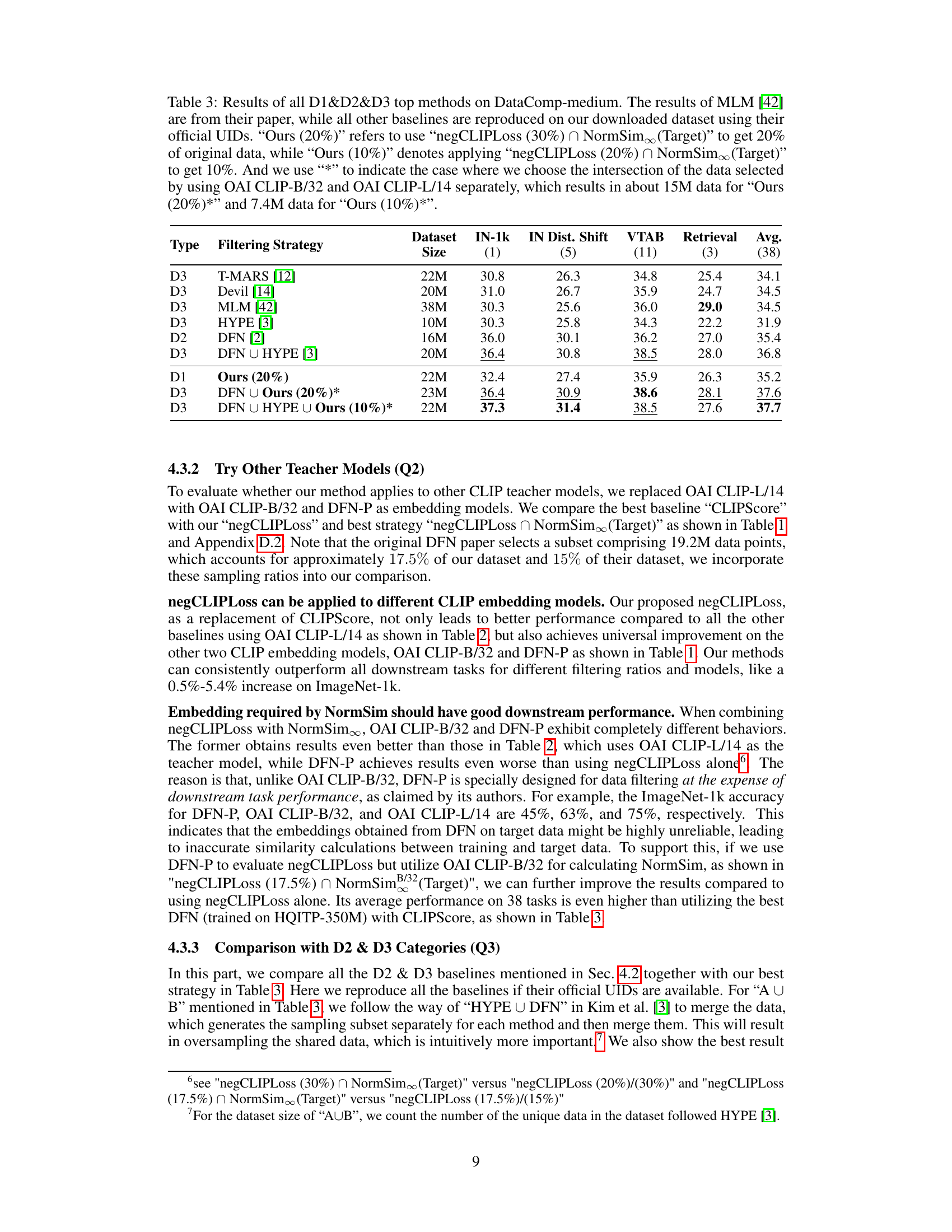
This table presents a comparison of the top-performing data selection methods from categories D1, D2, and D3 on the DataComp-medium benchmark. It shows the performance (ImageNet-1k, IN Dist. Shift, VTAB, Retrieval, and average across 38 downstream tasks) achieved by each method. The methods are categorized based on the resources used: D1 uses only the original OpenAI CLIP model, D2 trains a new CLIP model using external data, and D3 uses external non-CLIP models to aid in data selection. The table also shows that the proposed methods (Ours) outperform most of the D3 methods and can boost the performance of the SOTA method by combining them.
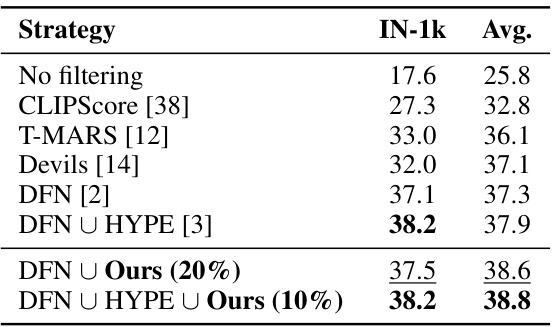
This table presents the ImageNet-1k and average performance across 38 downstream tasks for various data selection methods on the full DataComp-medium dataset (128 million image-text pairs). It compares the performance of different methods, including those that only use OpenAI’s CLIP model, those that train new CLIP models, and those that use external models or datasets. Notably, it shows that combining the proposed negCLIPLoss and NormSim methods with existing state-of-the-art methods (DFN and HYPE) leads to further improvements in performance.
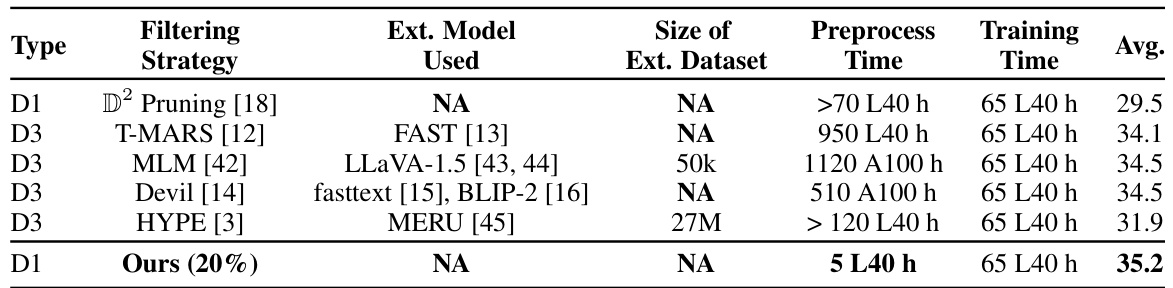
This table compares the preprocessing time and external resources required by different data selection methods. It highlights that the proposed method (negCLIPLoss) significantly reduces the preprocessing time compared to other methods that utilize external models or datasets. The table emphasizes the computational efficiency of the proposed approach.
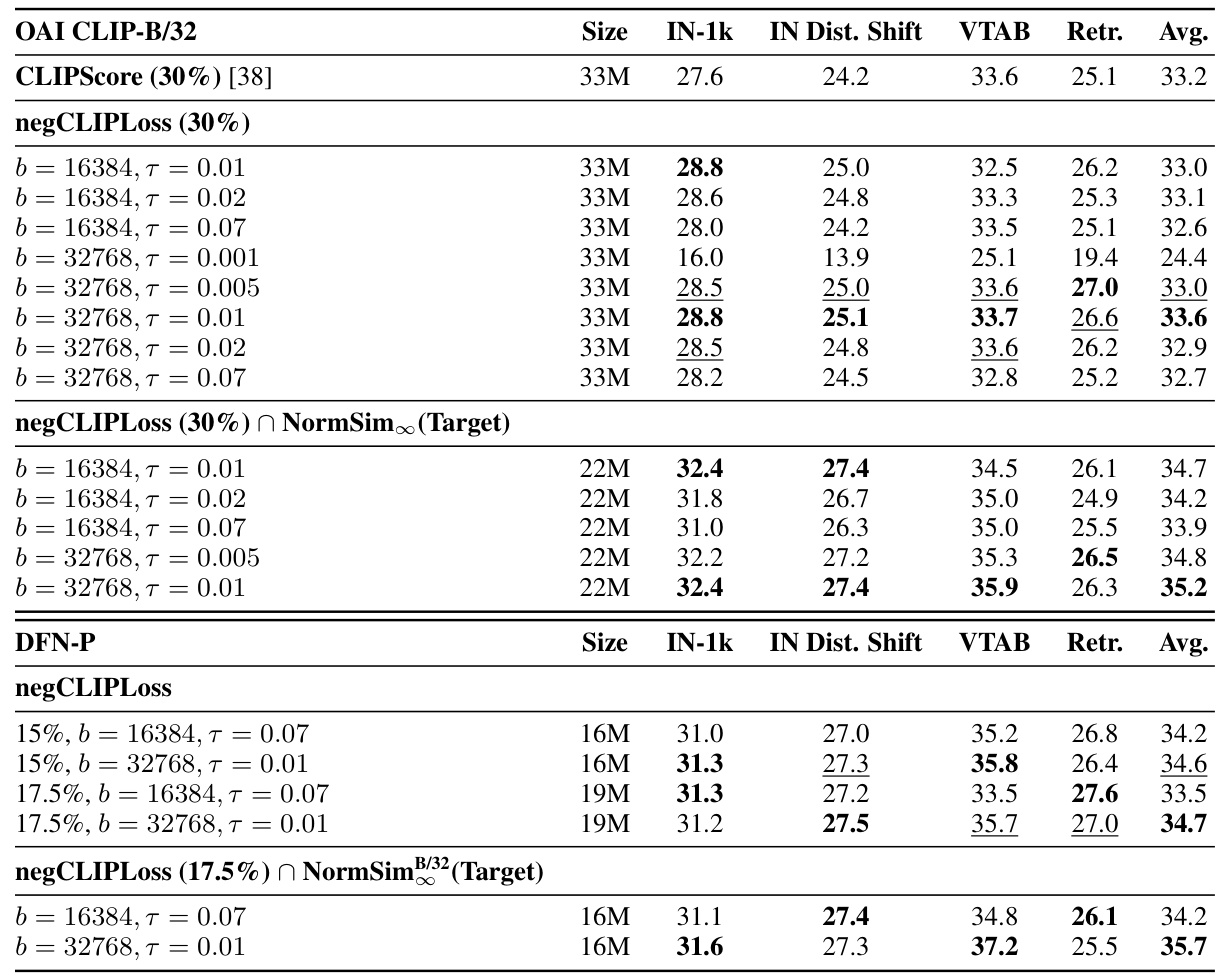
This table compares different data selection methods using two different CLIP models (OAI CLIP-B/32 and DFN-P). It shows the performance on ImageNet-1k and several downstream tasks (IN Dist. Shift, VTAB, Retrieval) using different filtering strategies, including CLIPScore and negCLIPLoss, both alone and in combination with NormSim(Target). It highlights the impact of negCLIPLoss in improving the performance compared to the baseline CLIPScore across various evaluation metrics and dataset sizes. The table also demonstrates the compatibility of negCLIPLoss with other advanced models (DFN-P).
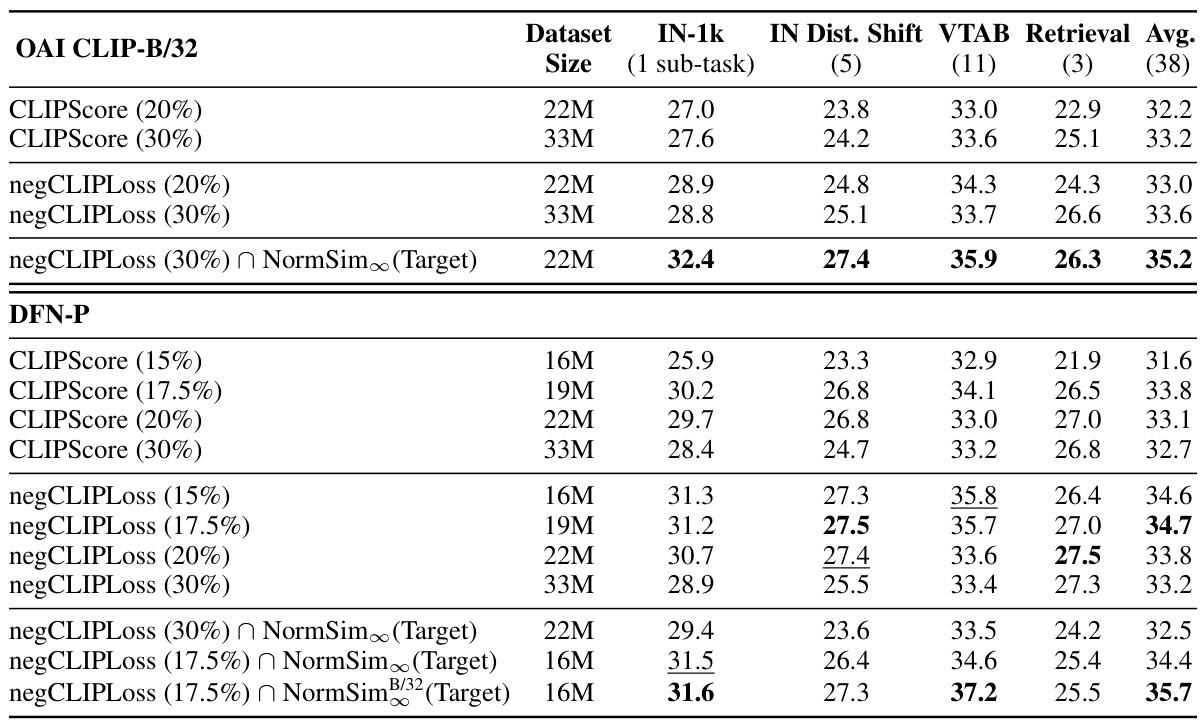
This table presents the results of data selection methods that exclusively utilize OpenAI’s CLIP-L/14 model, categorized under the D1 category. It compares different strategies using various metrics such as CLIPScore, negCLIPLoss, and NormSim, combined with different target datasets and subset selection techniques. The table shows the performance across multiple downstream tasks, including ImageNet-1k, IN Dist. Shift, VTAB, and Retrieval, with the average performance across 38 tasks.
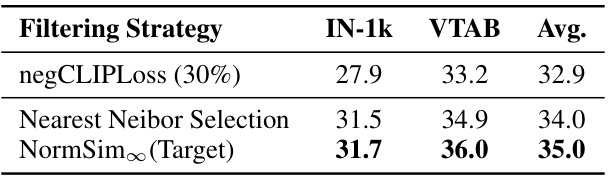
This table compares the performance of NormSim and nearest neighbor selection methods on the downstream tasks (IN-1k and VTAB). Both methods were used in conjunction with negCLIPLoss (30%). The selected subset size is 22M for both approaches. The table shows that NormSim∞ (Target) outperforms both negCLIPLoss(30%) and Nearest Neighbor Selection on both ImageNet-1k and VTAB tasks, and achieves the highest average performance.
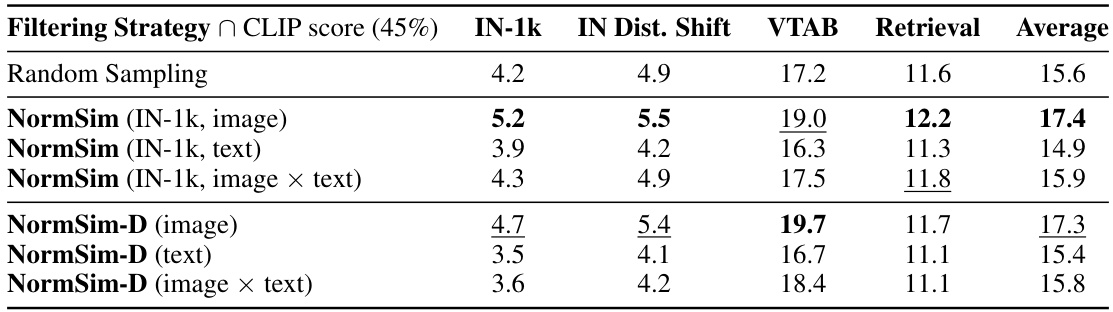
This table presents the ablation study of NormSim and its variants on the DataComp-small dataset. It compares the performance of using image-only, text-only, and image-text embeddings to represent the target data distribution when calculating NormSim. The results show the impact of using different embedding types on downstream task performance. The experiment setup involves initial data selection based on CLIP score (45%) and further filtering based on different NormSim variants to a final subset of 3.3M data points.
Full paper#