↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current methods for evaluating how well text-to-image models match prompts rely heavily on subjective human judgments, which are inconsistent and difficult to compare across studies. This makes it difficult to track progress in the field and compare different models reliably. This paper proposes a new solution to solve the issue.
The paper introduces T2IScoreScore, a new benchmark that uses semantic error graphs to objectively measure how well a given metric can correctly order and separate images based on their faithfulness to a given prompt. The results show that simpler metrics are surprisingly as good as more complicated, and much more computationally expensive, methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces an objective benchmark (T2IScoreScore) for evaluating text-to-image faithfulness metrics. Current methods rely on subjective human judgments, leading to inconsistent results. T2IScoreScore provides a much-needed standard for comparing metrics, fostering innovation and improving the reliability of text-to-image models. This will be especially important as these models are increasingly used in various high-stakes applications.
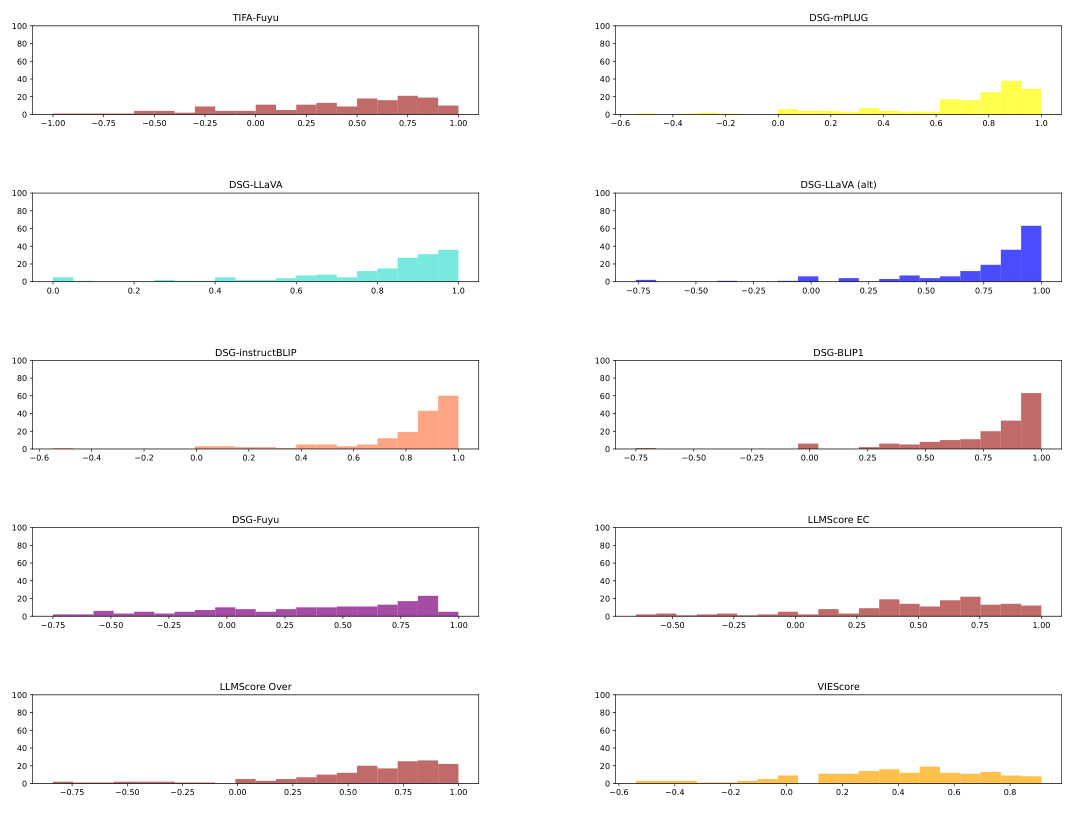
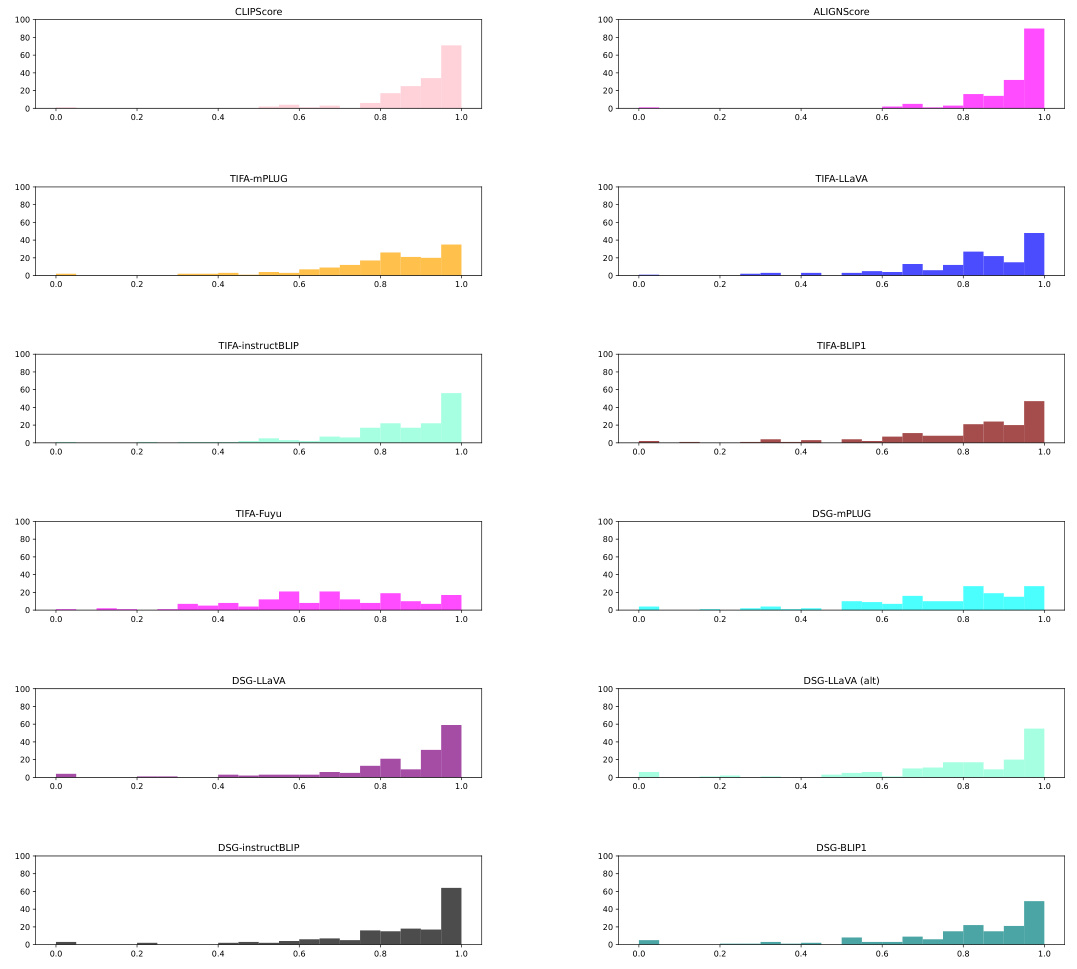
Visual Insights#

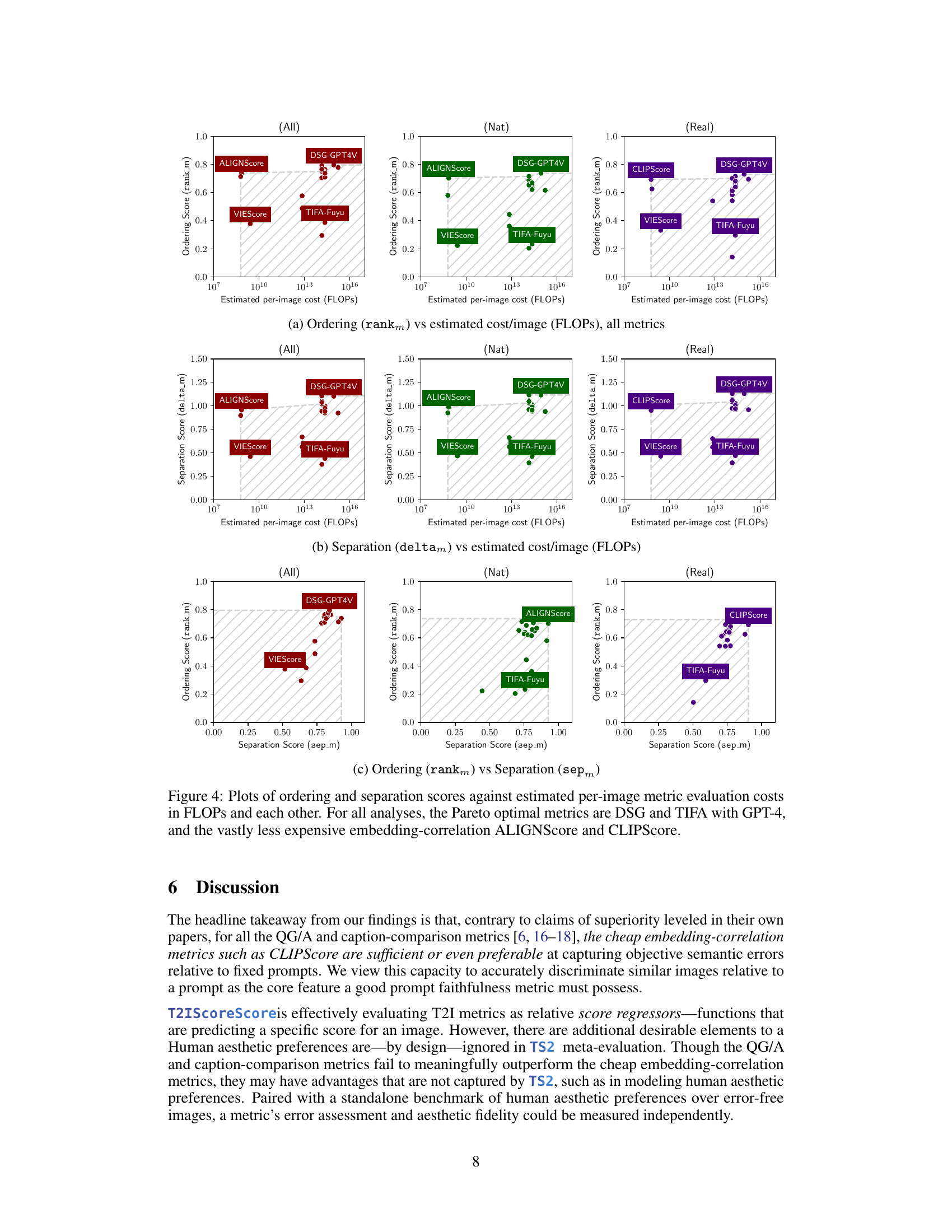
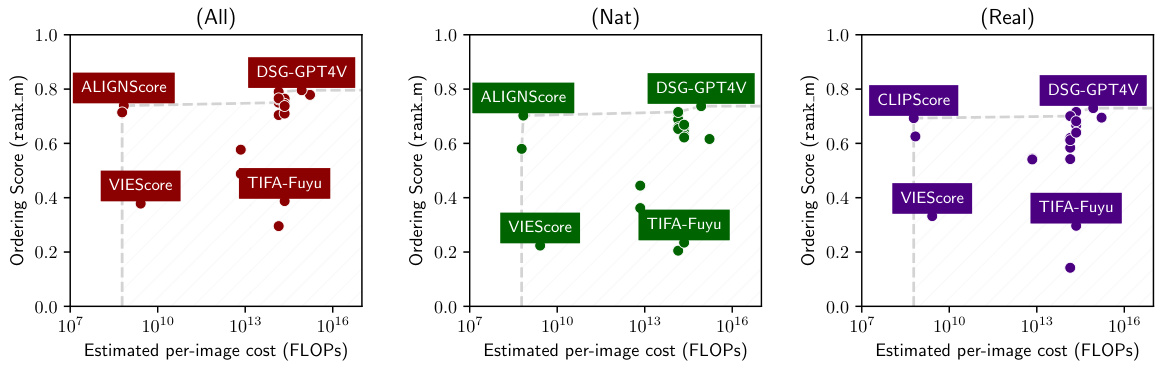
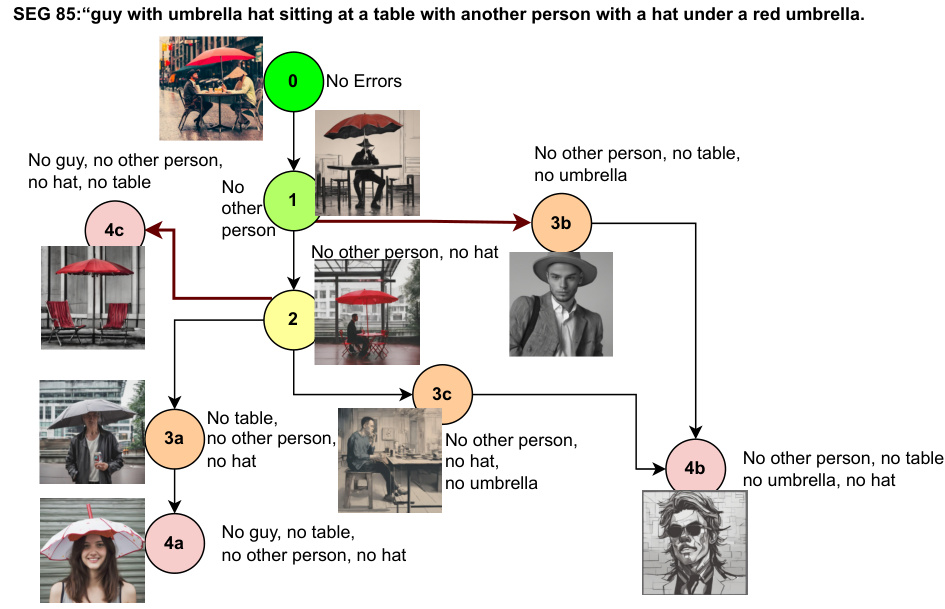
This figure presents a schematic overview of the T2IScoreScore (TS2) framework. It shows how the TS2 system evaluates text-to-image (T2I) faithfulness metrics by using Semantic Error Graphs (SEGs). These graphs consist of nodes representing images with varying degrees of error relative to the prompt and edges indicating the type and number of errors. TS2 assesses the metrics based on their ability to correctly rank the images within the SEG according to error level (Ordering, using Spearman’s correlation) and to separate images with different types of errors (Separation, using the Kolmogorov-Smirnov test). The core components are a dataset with SEGs, a metric wrapper to process different T2I faithfulness metrics, and a set of meta-metrics that quantify the performance of the metrics on the SEGs.

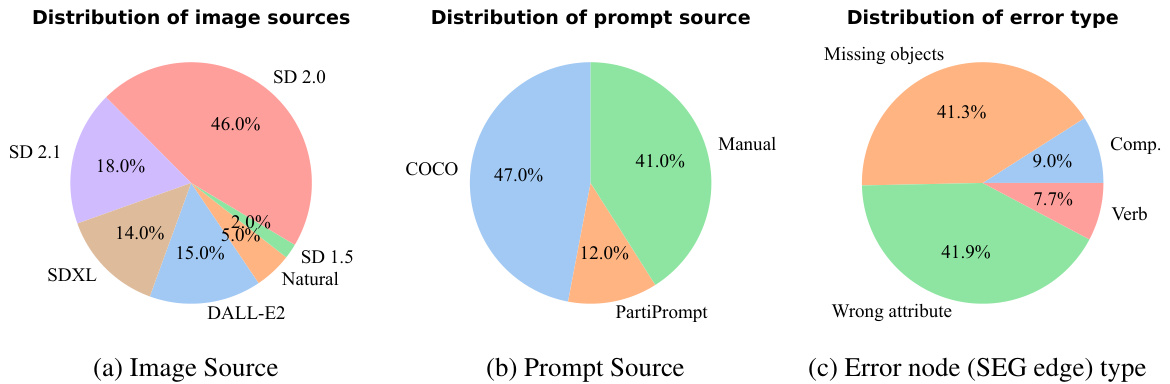
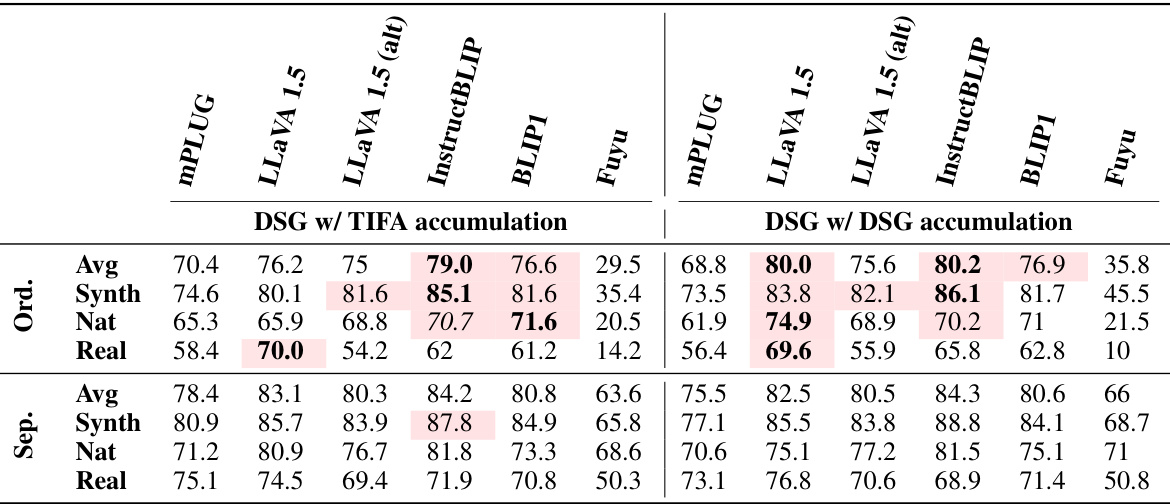
This table compares different benchmark datasets used for evaluating text-to-image (T2I) faithfulness metrics. It shows the total number of images, the average number of images per prompt, the average number of images per prompt with equivalent preference scores, the total number of image comparisons possible, and whether or not the dataset includes ad-hoc T2I errors. The table categorizes the datasets into benchmarks for captioning models, image retrieval/matching models, and T2I faithfulness metrics, highlighting the characteristics of each dataset type and indicating which ones are particularly suitable for evaluating T2I metrics.
In-depth insights#
T2I Benchmarking#
T2I (text-to-image) benchmarking is crucial for evaluating the progress and capabilities of these models. Current benchmarks often rely on subjective human evaluation using Likert scales, which can be inconsistent and lack objectivity. This approach is further limited by its reliance on small, hand-picked datasets that may not fully represent the diverse range of prompts and image characteristics encountered in real-world scenarios. Automated metrics offer a potential solution, but their reliability and ability to capture nuanced aspects of image fidelity and semantic coherence remain open questions. A key challenge lies in designing metrics that are not only objective but also capture the multi-faceted nature of successful T2I generation, including aspects such as detail, style, composition, and faithfulness to the prompt’s semantics. Moving forward, rigorous benchmarking methods must be developed that combine objective and subjective assessment strategies, utilize large and diverse datasets that comprehensively represent the complexity of the task, and are carefully designed to avoid bias and ensure generalizability. Ultimately, successful benchmarking will enable a better understanding of model strengths and weaknesses, leading to the development of more robust and capable T2I systems.
Meta-metric Design#
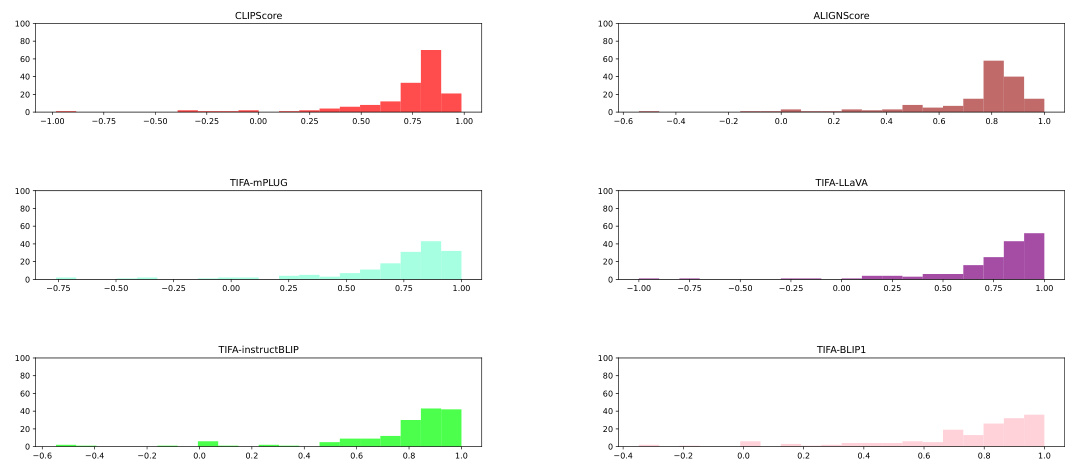
The effective design of meta-metrics for evaluating text-to-image prompt coherence metrics is crucial. It necessitates a multifaceted approach that goes beyond simple correlation with human judgments. A key consideration is the creation of structured datasets which systematically incorporate a range of semantic errors, allowing for the rigorous assessment of a metric’s ability to rank images based on error severity. This requires careful consideration of error types, prompt design, and image generation processes. Moreover, objective statistical measures must be employed to evaluate metric performance, avoiding subjective biases. The chosen meta-metrics should assess both ordering (ability to correctly rank images by error) and separation (ability to distinguish between different error levels) for different error types. The incorporation of computation cost as another factor in the meta-evaluation process provides a more comprehensive understanding of the efficiency and practicality of various metrics. Ultimately, a robust meta-metric design enables a more objective and nuanced evaluation of prompt faithfulness metrics, leading to improved development of these methods and ultimately impacting the overall quality of text-to-image generation models.
VLM-based Metrics#
The heading ‘VLM-based Metrics’ suggests an examination of evaluation methods leveraging Vision-Language Models (VLMs). These metrics likely assess the coherence between generated images and their text prompts by employing VLMs’ ability to understand both visual and textual data. A key aspect would be exploring the advantages of VLM-based approaches over other techniques, such as feature-based methods. Potential benefits might include a more nuanced understanding of semantic relationships and better handling of complex prompts. However, a thoughtful analysis should also delve into the limitations. For example, the computational cost of VLMs could be a significant drawback. Furthermore, the reliability of VLM-based evaluations could be affected by the limitations of the underlying VLM. The discussion might also compare the accuracy of VLM-based metrics against human evaluations to determine their effectiveness and identify any discrepancies. Finally, the section likely compares various VLM architectures and their impact on the performance of the metrics, uncovering which models are better suited for these types of assessments. Overall, a deep dive into VLM-based metrics demands careful consideration of their strengths, weaknesses, and overall applicability in the context of evaluating text-to-image models.
Pareto Optimality#
Pareto optimality, in the context of evaluating text-to-image (T2I) prompt coherence metrics, signifies achieving a balance between performance and computational cost. A Pareto optimal metric is one where no improvement in performance can be achieved without increasing computational expense. The research paper likely investigates the trade-offs between various T2I metrics, revealing which metrics offer superior performance at lower computational costs. This analysis would pinpoint the metrics that are most efficient, providing valuable insights for researchers and practitioners seeking to balance accuracy with resource constraints. Finding Pareto optimal metrics is crucial because it identifies the most efficient solutions, enabling cost-effective implementations in various applications. The paper likely highlights how certain metrics demonstrate Pareto optimality, signifying their superiority as they deliver high performance without demanding excessive computational resources, leading to cost-effectiveness and scalability. Therefore, understanding Pareto optimality is essential to choosing the best T2I metric for specific application needs and resource limits. The study’s findings could suggest that simpler metrics, like CLIPScore, can be Pareto optimal compared to more complex, computationally intensive ones. This challenges prevailing assumptions and may reshape future metric development by focusing on efficiency.
Future Directions#
Future research could explore expanding the T2IScoreScore benchmark to encompass a wider array of T2I models and prompt types, thereby enhancing its generalizability and robustness. Investigating the impact of different VLM architectures and training methodologies on the performance of faithfulness metrics within the T2IScoreScore framework would provide valuable insights into their relative strengths and weaknesses. Furthermore, a deeper examination of the interplay between subjective human preferences and objective metric scores remains crucial. This could involve developing new meta-metrics that directly capture the human perception of image-prompt coherence and incorporate both objective and subjective evaluation criteria. Exploring the potential of incorporating implicit knowledge and common-sense reasoning into faithfulness metrics is another area worthy of investigation. This could involve leveraging knowledge graphs or other forms of structured knowledge to better understand the relationships between image components and prompt semantics. Finally, future research could focus on developing advanced techniques to reduce VLM hallucinations in the context of faithfulness metric evaluation. Addressing this limitation will lead to more reliable and accurate assessment of T2I models’ prompt faithfulness. Ultimately, the long-term goal should be the development of a comprehensive and widely accepted benchmark for evaluating T2I faithfulness metrics that combines objective and subjective assessment and leverages the latest advancements in VLM technology.
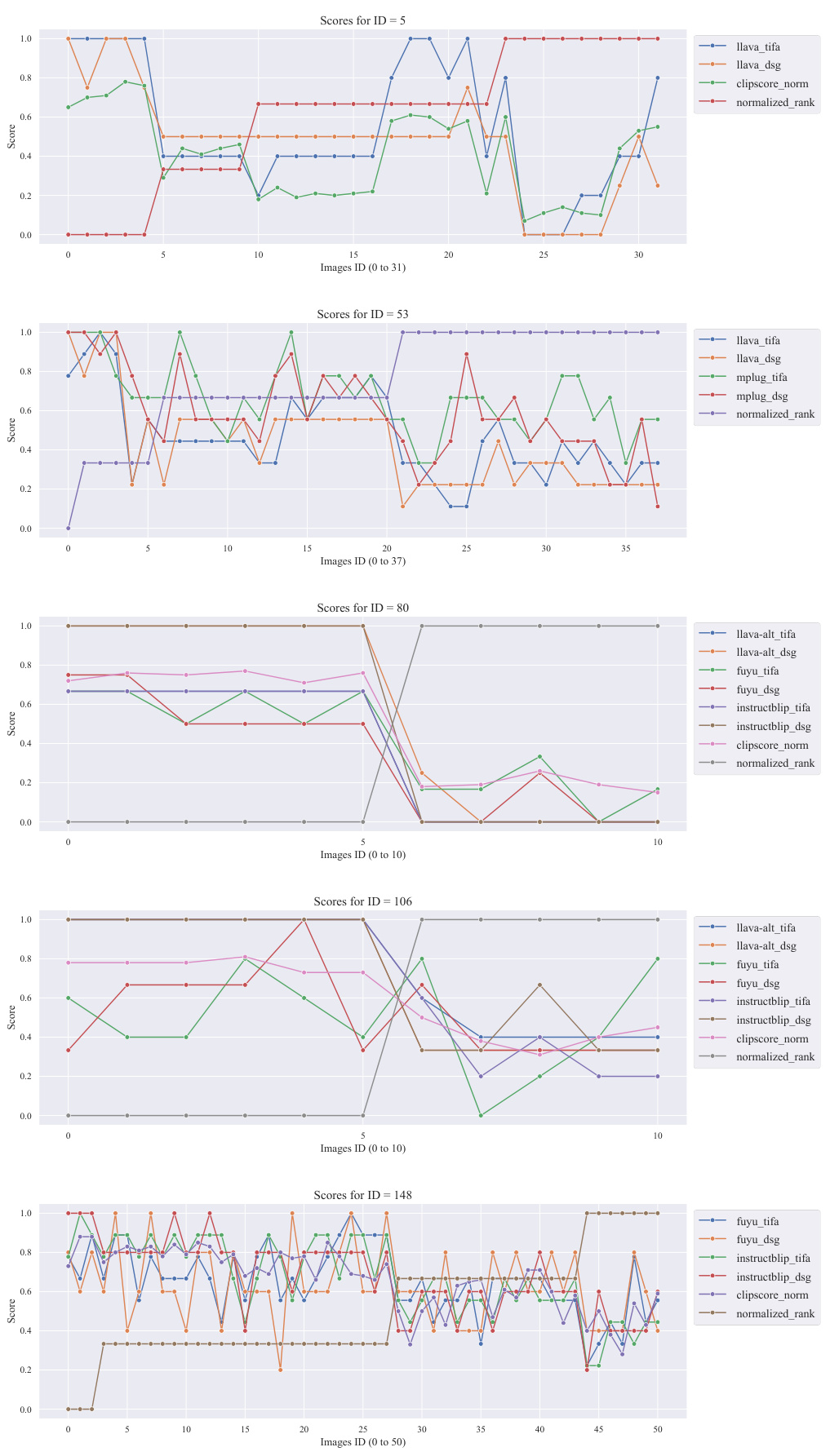
More visual insights#
More on figures

This figure illustrates the T2IScoreScore framework for evaluating text-to-image prompt coherence metrics. It shows how a dataset of images with varying degrees of semantic errors (relative to a prompt) is used to construct a semantic error graph (SEG). The framework then assesses metrics based on their ability to correctly order the images within the SEG according to error severity (using Spearman’s rank correlation) and to separate image groups with different error types (using the Kolmogorov-Smirnov statistic). This objective evaluation provides a more rigorous way to benchmark T2I metrics compared to previous approaches that relied heavily on correlation with human judgments.
This figure presents a schematic overview of the T2IScoreScore (TS2) framework. It illustrates how the TS2 system evaluates text-to-image (T2I) faithfulness metrics. The process starts with a dataset of images generated from a given prompt. These images are then organized into a Semantic Error Graph (SEG), where nodes represent image sets with specific errors relative to the prompt, and edges represent the relationships between these errors. T2I metrics are then used to score each image. TS2 assesses these metrics based on two key criteria: 1) the ability of the metric to correctly order the images within the SEG according to their error level (measured by Spearman’s rank correlation); and 2) the ability to separate images with different error types (measured using the Kolmogorov-Smirnov statistic). The figure visually depicts the flow of data and analysis within the TS2 framework.
This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how TS2 evaluates text-to-image (T2I) metrics by using semantic error graphs (SEGs). A SEG is a graph where nodes represent images and edges represent semantic errors relative to the prompt. TS2 assesses the ability of a T2I metric to correctly order these images based on their error count (using Spearman’s rank correlation) and to separate images with different error types (using the Kolmogorov-Smirnov statistic). The framework evaluates metrics based on their ability to achieve both correct ordering and separation of images.

This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how TS2 evaluates text-to-image (T2I) faithfulness metrics by using semantic error graphs (SEGs). A SEG contains a prompt and a set of images with increasing levels of error relative to that prompt. TS2 then assesses how well a given T2I metric can correctly order these images based on error level (using Spearman’s rank correlation) and separate images with different types of errors (using the Kolmogorov-Smirnov statistic).

This figure presents a schematic overview of the T2IScoreScore (TS2) framework. It shows how different text-to-image (T2I) faithfulness metrics are evaluated. The process starts with a dataset of images generated from a given prompt. These images are then organized into a Semantic Error Graph (SEG), where nodes represent sets of images with specific types and numbers of errors relative to the prompt, and edges represent the relationships between these nodes. The T2I metrics are then used to score the images. TS2 then assesses the metrics based on two meta-metrics: 1) how well the metric’s scores correlate with the correct ordering of images in the SEG (Spearman’s rank correlation coefficient), and 2) how well the metric separates the scores of images in different error nodes (Kolmogorov-Smirnov statistic). This provides an objective way to benchmark the performance of T2I faithfulness metrics.
This figure provides a visual overview of the T2IScoreScore (TS2) framework. It illustrates how TS2 evaluates text-to-image (T2I) metrics by assessing their ability to correctly order images based on their semantic errors relative to a given prompt. The process involves creating a semantic error graph (SEG), where nodes represent images with varying degrees of error and edges represent the types of errors. TS2 then uses statistical tests (Spearman’s ρ for ordering and Kolmogorov-Smirnov for separation) to score the T2I metrics based on how well they align with the objective error structure of the SEG.
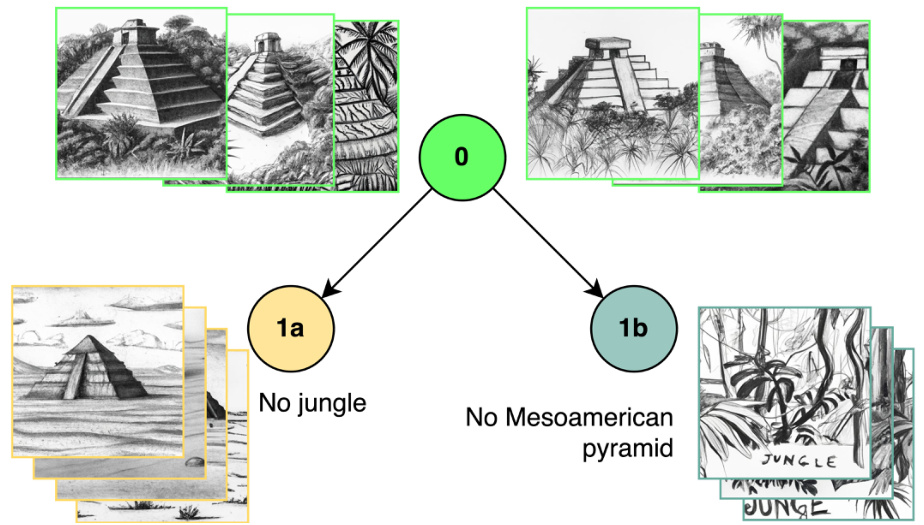
This figure presents a schematic overview of the T2IScoreScore (TS2) system. TS2 evaluates text-to-image (T2I) metrics by assessing their ability to correctly rank images according to their semantic errors relative to a given prompt. The process involves creating a semantic error graph (SEG), where nodes represent images with increasing numbers of errors, and edges connect images with different error types. TS2 uses two meta-metrics: Spearman’s rank correlation (ρ) to measure the ordering of images and the Kolmogorov-Smirnov statistic to measure the separation between nodes. The system is designed to objectively evaluate T2I metrics by comparing their performance to these objective criteria, rather than relying on subjective human judgements.

This figure presents a schematic overview of the T2IScoreScore (TS2) framework. It illustrates how TS2 evaluates text-to-image (T2I) faithfulness metrics. The process starts with a dataset of images generated from a given prompt. These images are then organized into a Semantic Error Graph (SEG), where nodes represent images with varying degrees of semantic errors relative to the prompt, and edges connect nodes representing different types of errors. T2I metrics are then evaluated based on their ability to correctly rank the images within the SEG according to their error level (using Spearman’s rank correlation), and to separate the nodes in the SEG representing different error levels (using the Kolmogorov-Smirnov statistic). The better a T2I metric performs on these two criteria, the higher its score, and the more reliable the metric is deemed to be.
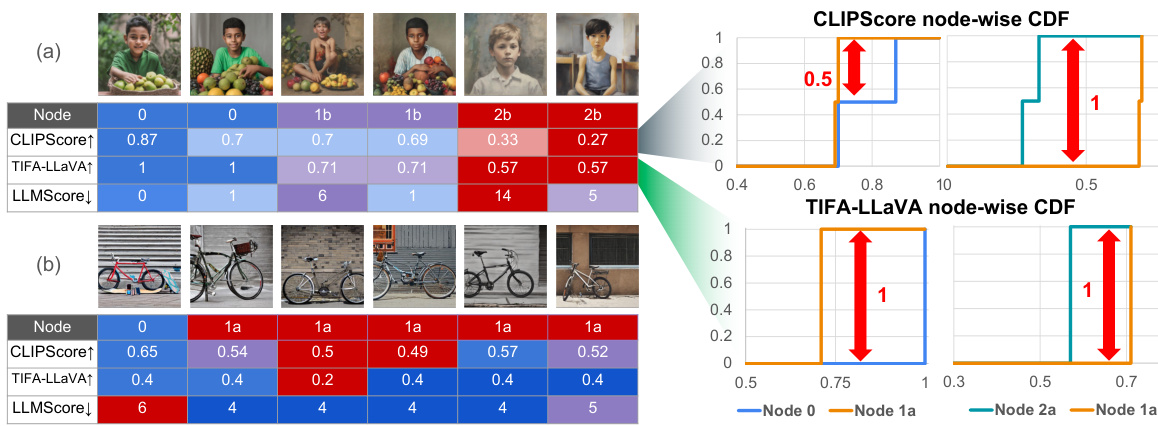
This figure provides a visual overview of the T2IScoreScore (TS2) framework. It illustrates how TS2 evaluates text-to-image (T2I) faithfulness metrics. The process starts with a dataset of images generated from a given prompt. These images are then organized into a semantic error graph (SEG), where nodes represent groups of images with similar errors, and edges indicate the progression of increasing errors. TS2 then assesses metrics based on their ability to correctly rank-order these images according to their error level (using Spearman’s correlation) and to separate the different error groups (using the Kolmogorov-Smirnov statistic).
This figure shows a schematic overview of the T2IScoreScore (TS2) system. The system takes a dataset of images generated from a given prompt as input. These images are organized into a Semantic Error Graph (SEG), where nodes represent sets of images with similar errors relative to the prompt, and edges represent the type and number of errors. TS2 then evaluates the ability of various text-to-image (T2I) faithfulness metrics to correctly order the images in the SEG based on their error level, using Spearman’s rank correlation coefficient, and to separate the images in different error nodes, using the Kolmogorov-Smirnov statistic. The meta-metrics are then used to score the T2I metrics objectively.
This figure provides a visual overview of the T2IScoreScore (TS2) framework. TS2 evaluates text-to-image (T2I) metrics by assessing their ability to correctly order and separate images within a Semantic Error Graph (SEG). The SEG is a graph where nodes represent image sets with varying degrees of semantic errors with respect to a given prompt. The framework uses two meta-metrics: Spearman’s correlation (ρ) to check the ordering of images in the SEG according to their error level, and the Kolmogorov-Smirnov statistic to assess the separation between nodes representing different error levels. The figure illustrates the data flow through the TS2 system, highlighting the key components and the evaluation process.
This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how T2I metrics are evaluated based on their ability to correctly rank images within a Semantic Error Graph (SEG). The SEG represents a set of images with increasing levels of error relative to a given prompt. The framework assesses two key aspects of the metrics: 1) Ordering (using Spearman’s rank correlation coefficient to measure the alignment between the ranked images and their actual error levels); 2) Separation (using the Kolmogorov-Smirnov statistic to measure the separability of different error node populations within the metric’s score distribution).
This figure illustrates the T2IScoreScore (TS2) framework for evaluating text-to-image (T2I) prompt coherence metrics. It shows how a dataset of images with varying degrees of error related to a given prompt is used to create a semantic error graph (SEG). The metrics are then evaluated based on their ability to correctly order the images within the SEG according to their error level, as measured by Spearman’s rank correlation and the Kolmogorov-Smirnov statistic. This provides an objective way to assess the performance of different T2I metrics.
This figure presents a high-level overview of the T2IScoreScore (TS2) framework. It illustrates how TS2 evaluates text-to-image (T2I) faithfulness metrics. The process begins with a dataset containing prompts and a set of images generated from those prompts. These images are then organized into a semantic error graph (SEG), which visually represents the semantic coherence of each image compared to the prompt. The framework assesses how well each T2I faithfulness metric correctly orders images in the SEG based on their increasing level of error, measuring both the ordering (using Spearman’s rank correlation) and separation (using the Kolmogorov-Smirnov statistic) of the image nodes in the SEG. In short, TS2 objectively benchmarks how well a given T2I faithfulness metric can accurately evaluate the faithfulness of the image generation to its corresponding prompt by measuring how well a metric orders and separates images based on their error levels relative to the prompt.
This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how TS2 evaluates text-to-image (T2I) metrics by using a semantic error graph (SEG). The SEG organizes images based on their semantic errors relative to a given prompt. TS2 then assesses the metrics based on their ability to correctly order these images within the SEG according to their error levels and to separate the images into distinct clusters based on error type. The evaluation uses established statistical tests such as Spearman’s rank correlation (for ordering) and the Kolmogorov-Smirnov statistic (for separation) to provide objective scores.

This figure shows a schematic overview of the T2IScoreScore (TS2) framework. It illustrates how T2I metrics are evaluated based on their performance in organizing images within a Semantic Error Graph (SEG). The SEG represents a prompt and a set of images with increasing levels of error. The framework assesses two key aspects: the correct ordering of images based on error severity (Spearman’s ρ), and the separation of images with different error types (Kolmogorov-Smirnov statistic).

This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how the system evaluates text-to-image (T2I) faithfulness metrics by using semantic error graphs (SEGs). The SEGs contain a prompt and a set of images with increasing levels of error. The system then assesses the metrics based on their ability to correctly order these images according to their error level (using Spearman’s rank correlation) and separate the images with different error levels (using the Kolmogorov-Smirnov statistic).

This figure illustrates the T2IScoreScore (TS2) framework for evaluating text-to-image (T2I) prompt coherence metrics. It shows how TS2 uses semantic error graphs (SEGs) to assess metrics. An SEG contains a prompt and a set of images with increasing levels of error relative to the prompt. TS2 then evaluates how well a metric can correctly order these images based on their error level (using Spearman’s rank correlation) and separate images with different error types (using the Kolmogorov-Smirnov statistic). This provides an objective way to benchmark T2I metrics, independent of human subjective judgements.

This figure provides a visual overview of the T2IScoreScore (TS2) framework. It shows how the system evaluates text-to-image (T2I) metrics by using a semantic error graph (SEG). The SEG contains a prompt and a set of images with increasing levels of error. The system assesses metrics based on their ability to correctly order images within the SEG according to the error level and to effectively separate images with different error types. The key evaluation metrics are Spearman’s rank correlation (for ordering) and the Kolmogorov-Smirnov statistic (for separation).

This figure provides a visual overview of the T2IScoreScore (TS2) system, which is used to objectively evaluate text-to-image (T2I) prompt coherence metrics. The system takes a dataset of images generated from a prompt, along with their corresponding prompts. Then, it uses a semantic error graph (SEG) to organize the images based on their semantic errors, relative to the original prompt. Finally, meta-metrics are used to evaluate the quality of the input T2I evaluation metrics. These meta-metrics include Spearman’s rank correlation coefficient (for ordering) and the Kolmogorov-Smirnov statistic (for separation).
Full paper#