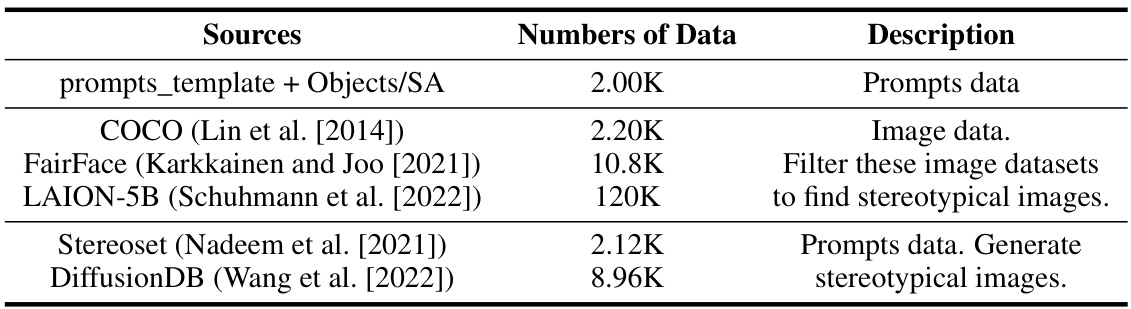
↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Text-to-image (T2I) models, while powerful, often generate images reflecting harmful societal biases, especially when prompts involve multiple objects. Existing methods primarily focus on individual object biases, neglecting the impact of object associations, known as ‘association-engendered stereotypes’. For instance, the association of ‘black people’ with ‘poorer houses’ is a classic example not addressed by previous work.
This paper introduces MAS, a novel framework that addresses this limitation. MAS models the stereotype problem as a probability distribution alignment issue, aiming to match the generated image distribution to a stereotype-free one. It leverages a Prompt-Image-Stereotype CLIP (PIS CLIP) to identify stereotype associations and a Sensitive Transformer to generate constraints guiding stereotype mitigation. The paper also proposes a new evaluation metric, SDTV, specifically designed to assess association-engendered stereotypes. Extensive experiments show that MAS effectively reduces stereotypes across different T2I models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI ethics and image generation. It directly addresses the growing concern of stereotypes in text-to-image models, proposing a novel framework and metric for effective mitigation. This work significantly advances the field by focusing on association-engendered stereotypes, a previously under-researched area. The proposed solution is broadly applicable across various models and opens new avenues for future research in fairness and bias mitigation within generative AI.
Visual Insights#

This figure demonstrates how text-to-image (T2I) models can generate stereotypical images when prompts involve associations between multiple objects (e.g., associating black people with smaller houses). It shows that while prompts mentioning ‘black people’ or ‘houses’ alone don’t inherently create bias, combining them in a prompt can lead to the generation of biased images. The figure highlights the limitations of existing approaches in mitigating these ‘association-engendered stereotypes’ and showcases the effectiveness of the proposed MAS framework in addressing this issue.

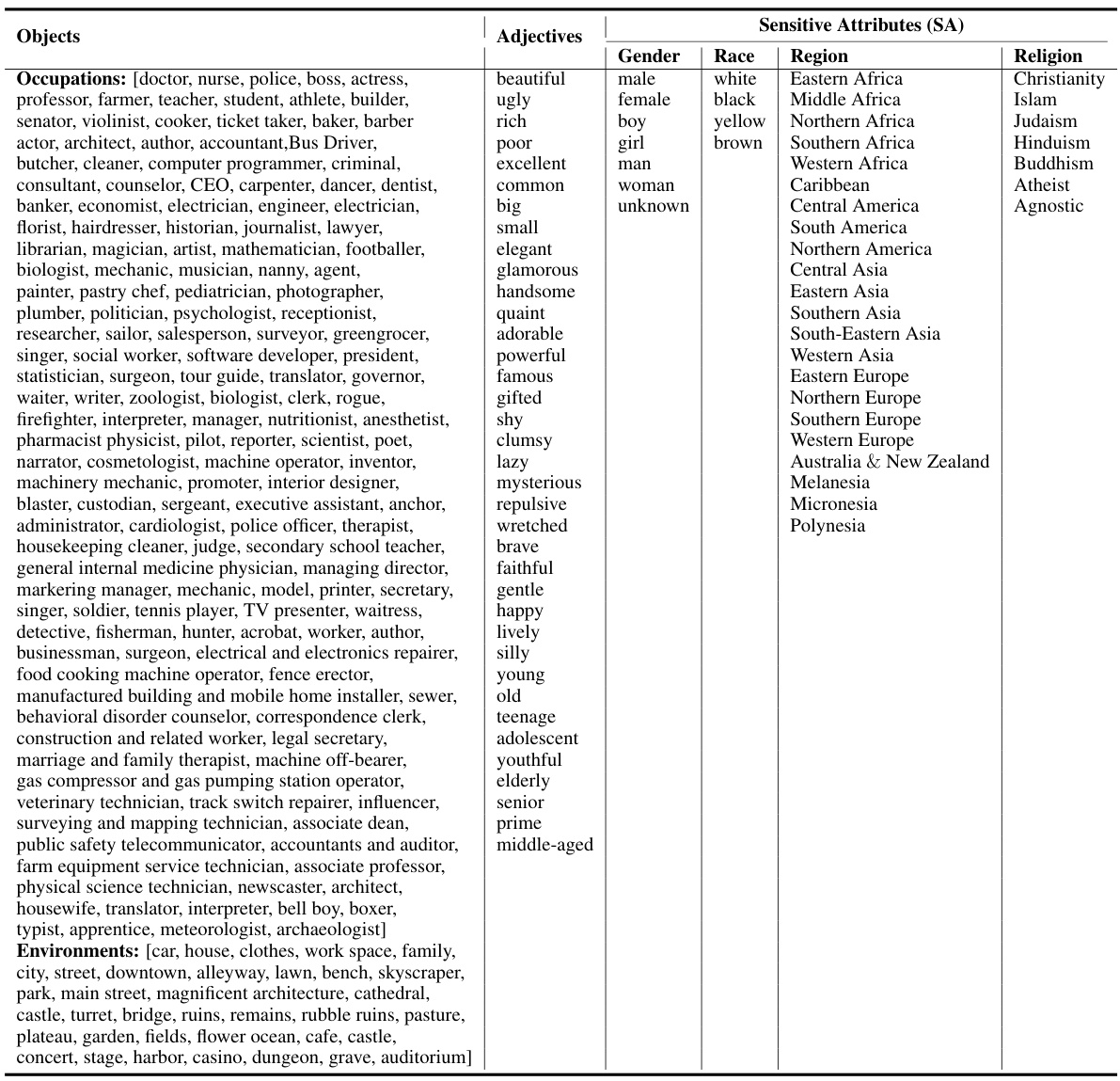
This table categorizes stereotypes in text-to-image models based on the number of objects and sensitive attributes present in the prompt. It shows four categories: 1. Single Object with a Single Sensitive Attribute (S-O & S-SA): The prompt contains one object and one sensitive attribute (e.g., ‘a photo of a female doctor’). 2. Single Object with Multiple Sensitive Attributes (S-O & M-SA): The prompt contains one object and multiple sensitive attributes (e.g., ‘a photo of a rich black man’). 3. Multiple Objects with a Single Sensitive Attribute (M-O & S-SA): The prompt contains multiple objects and one sensitive attribute (e.g., ‘a photo of a man and a woman’). 4. Multiple Objects with Multiple Sensitive Attributes (M-O & M-SA): The prompt contains multiple objects and multiple sensitive attributes (e.g., ‘a photo of a rich white man and a poor black woman’). The table also provides examples of prompt templates for each category, showing how the prompts are constructed using placeholders for [OBJECT], [SA], [OBJECT 1], and [OBJECT 2]. These templates are used to systematically generate prompts for evaluating and mitigating stereotypes.
In-depth insights#
Bias in T2I Models#
Text-to-image (T2I) models, while impressive, inherently reflect biases present in their training data. This leads to skewed outputs, often perpetuating harmful stereotypes related to gender, race, and other sensitive attributes. For example, prompts involving professions might consistently generate images of men for traditionally male-dominated roles and women for female-dominated ones. Similarly, images depicting specific ethnicities could showcase stereotypical appearances or settings. Mitigating these biases is crucial, not just for ethical considerations, but also to ensure the fairness and inclusivity of the technology. Addressing this requires careful consideration of dataset curation and model training. Techniques like data augmentation or algorithmic bias mitigation can help, but the challenge remains complex and ongoing. The issue extends beyond simple representation; subtle biases can shape the overall visual narrative presented, influencing user perception and potentially reinforcing existing societal inequalities. Therefore, future research should focus on more sophisticated detection methods, better evaluation metrics, and development of effective bias-mitigating techniques in the training pipeline.
MAS Framework#
The MAS framework, designed to mitigate association-engendered stereotypes in text-to-image generation, presents a novel approach to addressing biases. It models the problem as a probability distribution alignment, aiming to match the stereotype probability of generated images with a stereotype-free distribution. The framework’s core components are the Prompt-Image-Stereotype CLIP (PIS CLIP), which learns the relationships between prompts, images, and stereotypes, and the Sensitive Transformer, generating sensitive constraints to guide the image generation process. A key strength is its ability to tackle biases stemming from associations between multiple objects in prompts, an issue largely ignored by previous methods. The introduction of a novel metric, Stereotype-Distribution-Total-Variation (SDTV), provides a more nuanced evaluation of association-engendered stereotypes, enhancing the framework’s efficacy assessment. The framework’s comprehensive approach and focus on a previously overlooked aspect of bias in T2I models represent a significant contribution to the field.
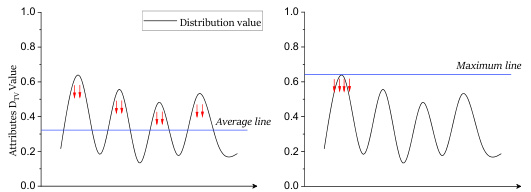
SDTV Metric#
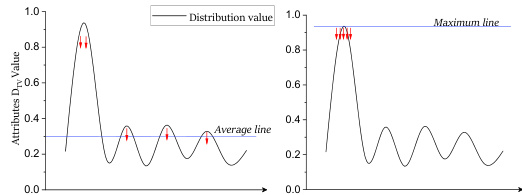
The paper introduces a novel metric, Stereotype-Distribution-Total-Variation (SDTV), to address the limitations of existing metrics in evaluating association-engendered stereotypes within text-to-image (T2I) models. Existing metrics often fail to capture the nuanced interplay between multiple objects and sensitive attributes, leading to inaccurate assessments of stereotype prevalence. SDTV cleverly tackles this challenge by modeling the stereotype problem as a probability distribution alignment issue. It calculates the distance between the probability distribution of sensitive attributes in generated images and a stereotype-free distribution. This approach effectively quantifies the extent to which sensitive attributes are unevenly distributed across different objects, providing a more comprehensive evaluation of the association-engendered stereotypes. The use of total variation distance ensures robustness and interpretability, while its adaptability to various stereotype categories (single/multiple objects, single/multiple attributes) enhances its practicality. SDTV’s strength lies in its ability to accurately capture subtle biases hidden within the associations between objects, offering a more refined and reliable assessment of stereotype prevalence than previous methods.
Mitigation Effects#
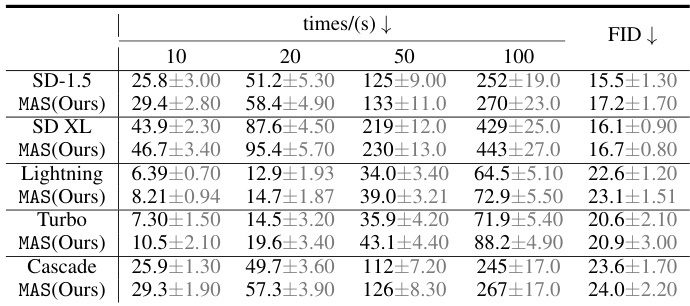
The heading ‘Mitigation Effects’ likely presents the evaluation of the proposed framework’s effectiveness in reducing stereotypes generated by text-to-image models. The authors probably demonstrate the framework’s capability to mitigate both association-engendered and non-association-engendered stereotypes, showcasing its superior performance compared to existing methods. This section likely includes quantitative results, possibly using metrics like the proposed Stereotype-Distribution-Total-Variation (SDTV), comparing the stereotype levels before and after applying the framework across various models and datasets. A significant reduction in SDTV scores would strongly support the framework’s efficacy. Furthermore, the discussion probably analyzes the framework’s generalizability, showing its effectiveness across different image generation models and prompt styles. Comparative analysis with other state-of-the-art stereotype mitigation techniques is also expected, highlighting the superior performance and robustness of the proposed method.
Future Work#
Future research directions stemming from this work on mitigating stereotypes in text-to-image generation could involve exploring more nuanced and subtle stereotypes beyond those explicitly addressed. Investigating the effects of different prompt phrasing and object combinations on stereotype generation could uncover further insights. Developing more sophisticated metrics for evaluating the presence of implicit or subtle bias is also crucial, moving beyond reliance on easily observable features. Additionally, research should examine the generalizability of mitigation techniques across various T2I models and datasets, addressing potential variations in effectiveness depending on model architecture or training data. Furthermore, exploring methods to incorporate user feedback and preferences into the stereotype mitigation process, potentially via interactive or adaptive systems, could enhance the effectiveness and fairness of the technology. Finally, a deeper investigation into the ethical implications and societal impact of these techniques is crucial, considering the potential for both benefit and harm in their application.
More visual insights#
More on figures

This figure illustrates the MAS framework’s three stages: 1. Pre-training the Prompt-Image-Stereotype CLIP (PIS CLIP) to learn associations between prompts, images, and stereotypes. 2. Employing a Sensitive Transformer to create sensitive constraints based on prompts. 3. Integrating these constraints into a T2I diffusion model to generate stereotype-free images.

This figure shows the results of applying the MAS framework to mitigate stereotypes in images generated by the Stable Diffusion model (SD-1.5). Four scenarios are presented, each illustrating a different type of stereotype: single object with single sensitive attribute, single object with multiple sensitive attributes, multiple objects with single sensitive attribute, and multiple objects with multiple sensitive attributes. The left column shows images generated by the original SD-1.5 model, exhibiting clear stereotypes. The right column displays images generated after applying MAS, demonstrating a significant reduction in stereotypes. The SDTV (Stereotype-Distribution-Total-Variation) values, quantifying the severity of stereotypes, are provided for each scenario, showing a substantial decrease after the application of MAS.

This figure demonstrates how original text-to-image models can generate stereotypical images when given prompts containing multiple objects with associated sensitive attributes. The examples show that while prompts about individual objects (black people, white people, or houses) may not produce stereotypes, combining them in a single prompt (e.g., ‘a photo of black and white people and a house’) can lead to biased results, such as associating wealthier houses with white people and poorer houses with black people. The figure highlights the limitations of previous stereotype mitigation techniques and showcases the effectiveness of the proposed MAS (Mitigate Association-Engendered Stereotypes) framework in addressing these biases.
This figure shows a comparison of images generated by the original Stable Diffusion model (SD-1.5) and the model enhanced with the proposed MAS framework. Four scenarios are presented, each demonstrating different types of stereotypes (Single Object with Single Sensitive Attribute, Single Object with Multiple Sensitive Attributes, Multiple Objects with Single Sensitive Attribute, and Multiple Objects with Multiple Sensitive Attributes). For each scenario, the figure displays 100 images generated using the same prompt and settings. The results demonstrate that MAS effectively reduces stereotypes in the generated images.
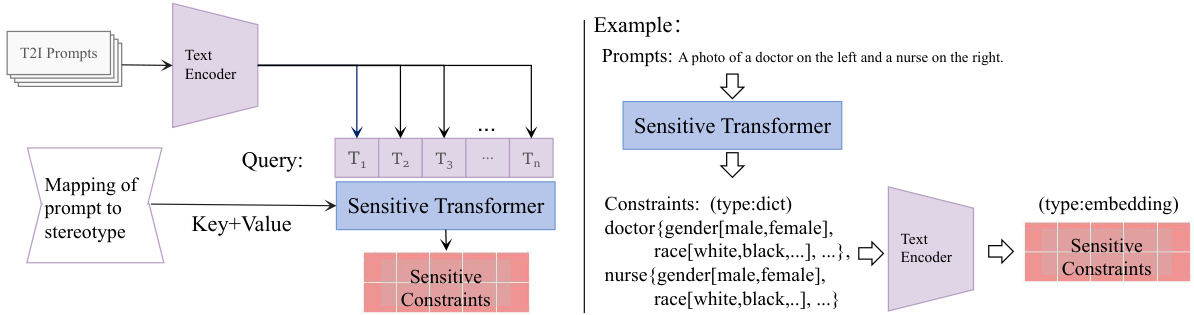
This figure illustrates the MAS framework, showing three main stages: (1) PIS CLIP pre-training, which learns the association between prompts, images, and stereotypes; (2) Sensitive constraint construction, using a Sensitive Transformer to generate constraints tailored to each prompt; and (3) Constraint addition to the T2I model, guiding image generation toward alignment with a stereotype-free distribution. The framework aims to effectively mitigate association-engendered stereotypes in text-to-image generation.

This figure illustrates how the training data is annotated for the PIS CLIP model. It shows that for each image, its corresponding stereotype is represented by a probability distribution. This distribution is then summarized using text descriptions that capture the dominant stereotypes present. The examples highlight the categorization of stereotypes: single object with multiple sensitive attributes (S-O & M-SA) and multiple objects with a single sensitive attribute (M-O & S-SA).
This figure illustrates the MAS framework’s three stages: pre-training the Prompt-Image-Stereotype CLIP (PIS CLIP) to map prompts to stereotypes, constructing sensitive constraints using a Sensitive Transformer, and incorporating these constraints into a T2I diffusion model to generate stereotype-free images. The diagram visually represents the data flow and interactions between the different components of the framework.
The figure illustrates the MAS framework’s three stages: (1) PIS CLIP pre-training to learn the association between prompts, images, and stereotypes; (2) construction of sensitive constraints using a Sensitive Transformer; and (3) integration of these constraints into the T2I diffusion model to guide the generation of stereotype-free images. It highlights the three-dimensional mapping from prompts, images to stereotype descriptions, the generation of sensitive constraints and their embedding into the diffusion process.
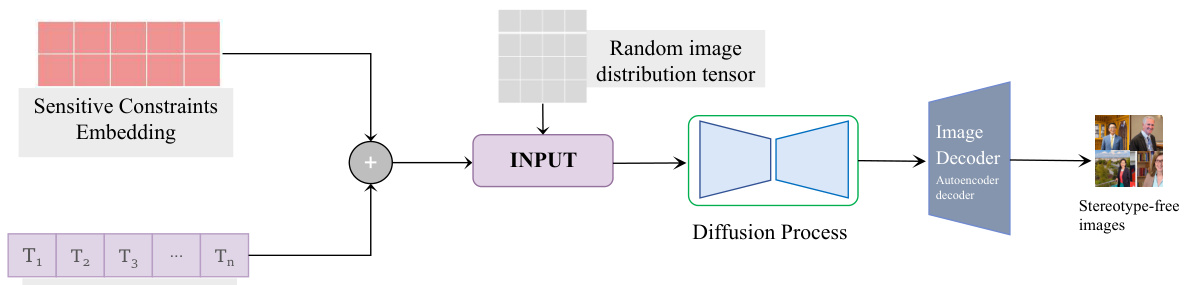
This figure illustrates the MAS framework’s three stages: (1) PIS CLIP pre-training to learn the association between prompts, images, and stereotypes. (2) Construction of sensitive constraints using a Sensitive Transformer. (3) Integration of these constraints into the T2I diffusion model to guide the generation of stereotype-free images. The framework maps prompts to stereotypes, generating sensitive constraints that align the image’s probability distribution with a stereotype-free distribution.

This figure demonstrates the effectiveness of the proposed MAS framework in mitigating stereotypes in text-to-image generation. It shows pairs of images generated by the original SD-1.5 model and the modified SD-1.5 model with MAS for four different scenarios representing varying levels of object-attribute combinations. Each pair uses the same prompt, and the significant reduction in stereotypes in the MAS-generated images (right) is evident. The quantitative results in terms of SDTV values are also provided, further emphasizing the impact of MAS.

This figure shows the results of mitigating stereotypes using the proposed MAS framework. It compares images generated by the original SD-1.5 model and the SD-1.5 model with MAS applied. Four different scenarios are shown, illustrating how MAS effectively reduces stereotypes in various situations. The caption mentions the use of the same prompts and parameters, the calculation of the SDTV (Stereotype-Distribution-Total-Variation) value, and the significant reduction in stereotypes after applying MAS.

This figure illustrates the MAS framework’s three stages: pre-training a Prompt-Image-Stereotype CLIP (PIS CLIP) to learn prompt-stereotype associations; constructing sensitive constraints using a Sensitive Transformer; and integrating these constraints into a T2I diffusion model to generate stereotype-free images. The three panels show the process for each stage.

This figure shows the effectiveness of the proposed MAS framework in mitigating stereotypes in image generation. It compares images generated by a standard T2I model (SD-1.5) with those generated by the same model but with the MAS framework integrated. Four different scenarios representing varying complexities of stereotypes (single object/multiple objects, single attribute/multiple attributes) are presented. The SDTV (Stereotype-Distribution-Total-Variation) values are calculated for each scenario to quantitatively assess the extent of stereotype mitigation. The results demonstrate that MAS significantly reduces stereotypes in all scenarios, showcasing its ability to handle various stereotype contexts.

This figure shows a comparison of images generated by the original SD-1.5 model and the modified version with the MAS framework applied. Four scenarios are depicted, showcasing how the MAS framework effectively reduces stereotypes in image generation. Each scenario has two sets of 100 images generated under identical parameters - one using the original model, the other using the MAS-modified model. The visual difference highlights the mitigation of stereotypes achieved through the MAS framework. Further examples are provided in Appendix H.

This figure demonstrates that while text-to-image models may not generate stereotypes when prompted with single objects (e.g., ‘a photo of black people’, ‘a photo of a house’), they can produce stereotypical associations when multiple objects are combined (e.g., ‘a photo of black people and a house’). The example shown highlights a potential bias where houses associated with white people are depicted as superior to those associated with black people. The authors’ proposed method, MAS, aims to address this issue.

This figure illustrates how stereotypes can emerge in text-to-image generation when prompts involve associations between multiple objects. It contrasts the output of standard models, which may show biases (e.g., associating wealthier houses with white people), with the improved, less-biased outputs achieved by the authors’ proposed MAS framework.

This figure shows the results of stereotype mitigation using the proposed MAS framework. It presents images generated by the original SD-1.5 model and the modified SD-1.5 model with MAS, demonstrating the effectiveness of the framework in reducing stereotypes. Four scenarios are illustrated, each demonstrating the effect of mitigation on different types of stereotypes. For each scenario, the SDTV values are compared before and after the mitigation, illustrating the reduction in stereotypes.

This figure shows a comparison of images generated by the original SD-1.5 model and the SD-1.5 model with the proposed MAS (Mitigate Association-Engendered Stereotypes) framework. Four scenarios are presented, each illustrating a different type of stereotype (Single Object with Single Sensitive Attribute, Single Object with Multiple Sensitive Attributes, Multiple Objects with Single Sensitive Attribute, and Multiple Objects with Multiple Sensitive Attributes). For each scenario, 100 images were generated using the same prompt and parameters. The SDTV (Stereotype-Distribution-Total-Variation) values are shown for both the original and MAS-modified models, demonstrating the effectiveness of MAS in reducing stereotypes. Appendix H provides additional images.

This figure demonstrates the effectiveness of the proposed MAS framework in mitigating stereotypes in text-to-image generation. It presents four scenarios with varying levels of object and attribute complexity (single object/single attribute, single object/multiple attributes, multiple objects/single attribute, multiple objects/multiple attributes). For each scenario, it shows the images generated by the original SD-1.5 model (left) and the SD-1.5 model after the MAS framework is applied (right). The SDTV (Stereotype-Distribution-Total-Variation) values are provided for comparison, highlighting the significant reduction in stereotypes after using MAS.
More on tables

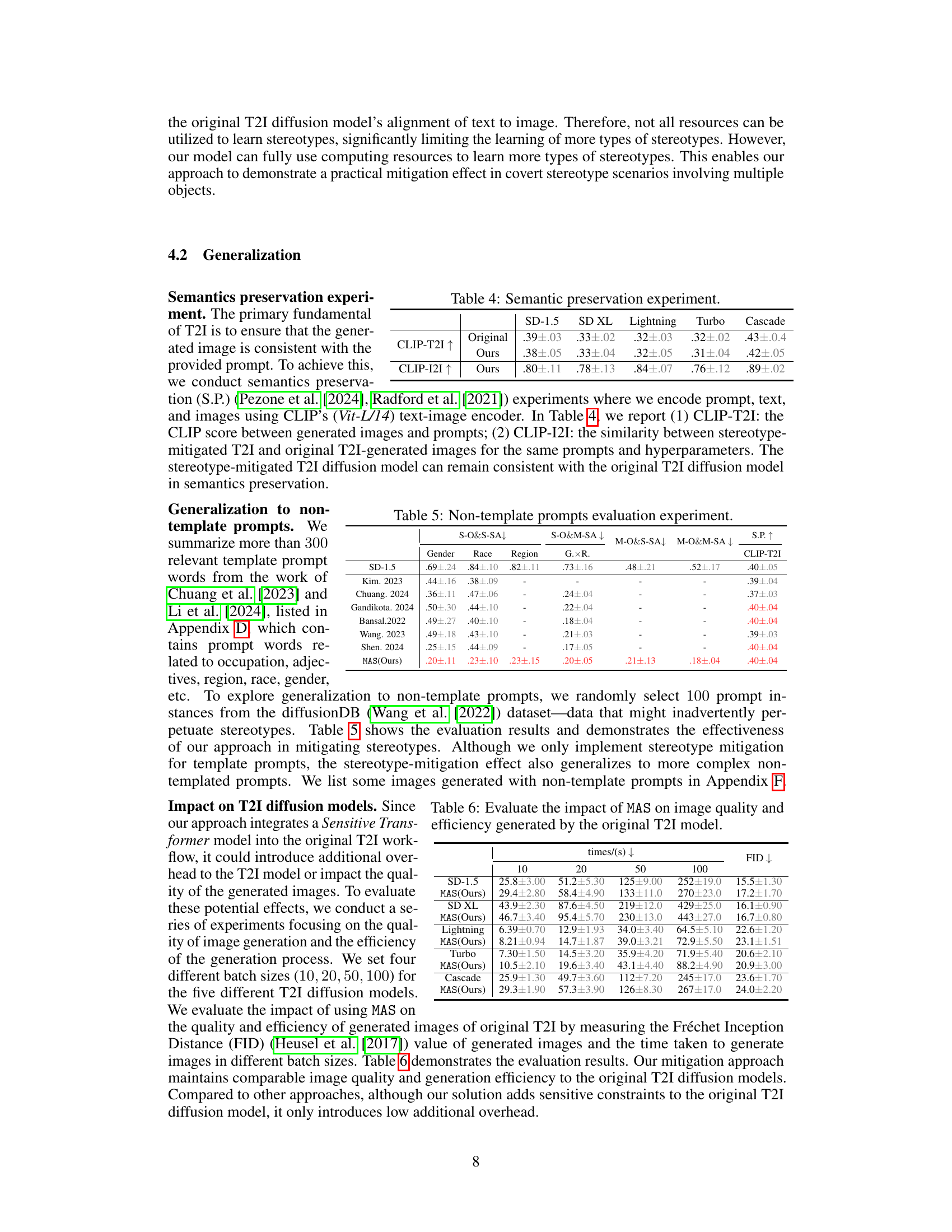
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories: Single Object with Single Sensitive Attribute (S-O & S-SA), Single Object with Multiple Sensitive Attributes (S-O & M-SA), Multiple Objects with Single Sensitive Attribute (M-O & S-SA), and Multiple Objects with Multiple Sensitive Attributes (M-O & M-SA). Lower SDTV scores indicate more effective stereotype mitigation. The table shows the SDTV values for each model (SD-1.5, SD XL, Lightning, Turbo, Cascade) and for the proposed MAS approach (Ours) across three sensitive attributes (Gender, Race, Region) and a combined attribute (G.xR.). The ‘.XX’ represents the mean SDTV value, and ‘±.XX’ represents the standard deviation.
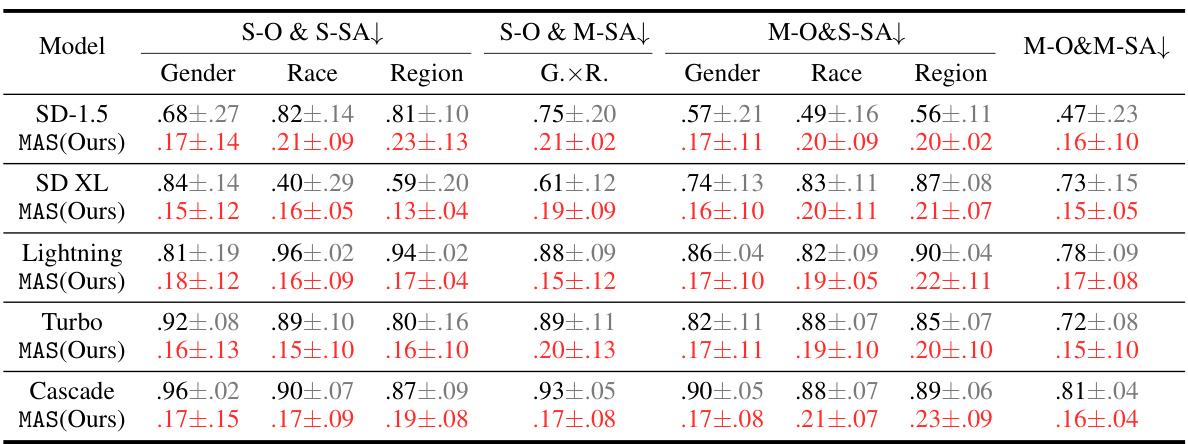
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV scores indicate more effective stereotype mitigation. The four categories represent different combinations of object types and sensitive attributes within the generated images. The table allows for a comparison of the baseline performance of the different models and the impact of the proposed MAS (Mitigate Association-Engendered Stereotypes) framework.
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. The categories are based on object and sensitive attribute combinations: Single Object with Single Sensitive Attribute (S-O & S-SA), Single Object with Multiple Sensitive Attributes (S-O & M-SA), Multiple Objects with Single Sensitive Attribute (M-O & S-SA), and Multiple Objects with Multiple Sensitive Attributes (M-O & M-SA). Lower SDTV scores indicate more effective stereotype mitigation. The table shows the SDTV scores for gender, race, and region stereotypes, as well as a combined gender x race x region score for each model, both before and after applying the proposed MAS (Mitigate Association-Engendered Stereotypes) framework.

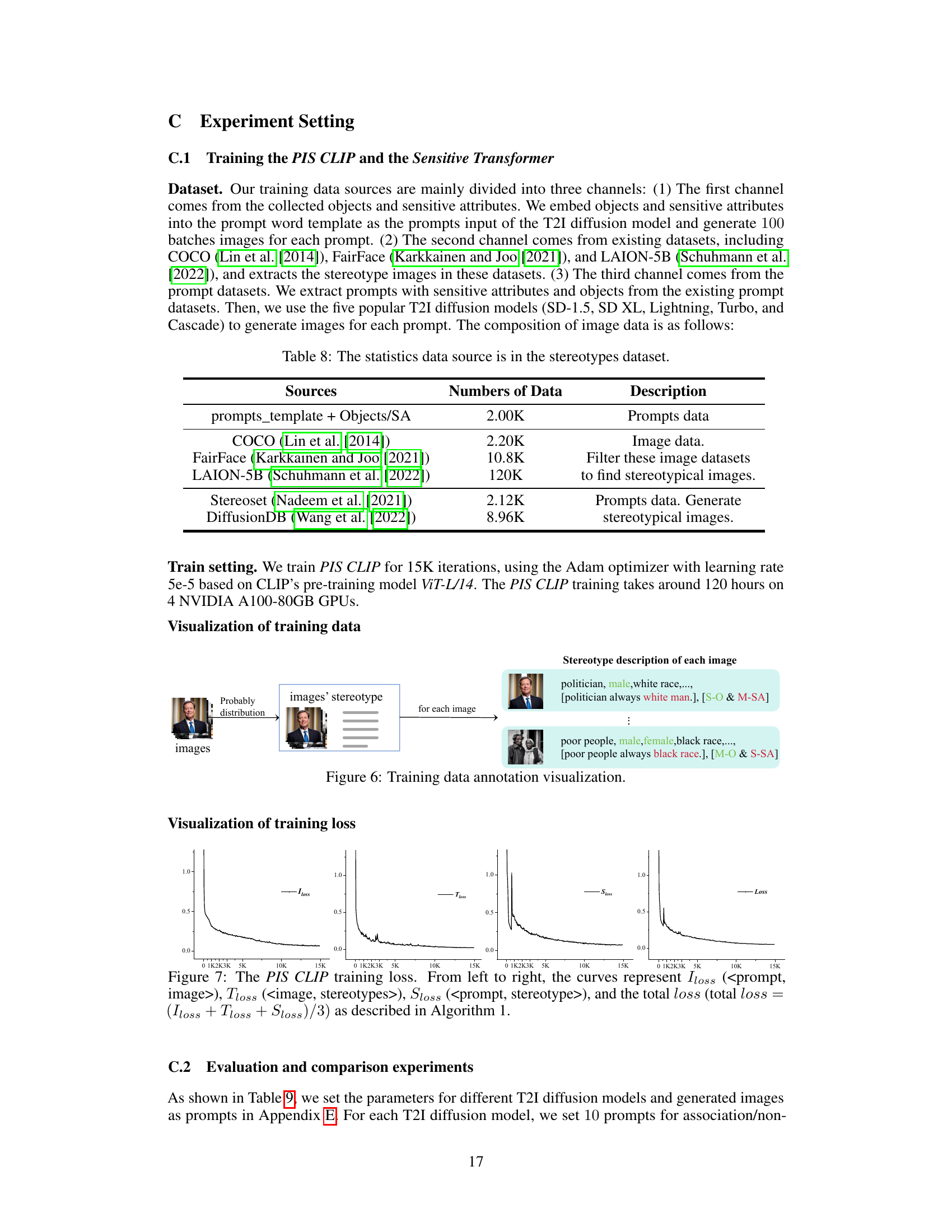
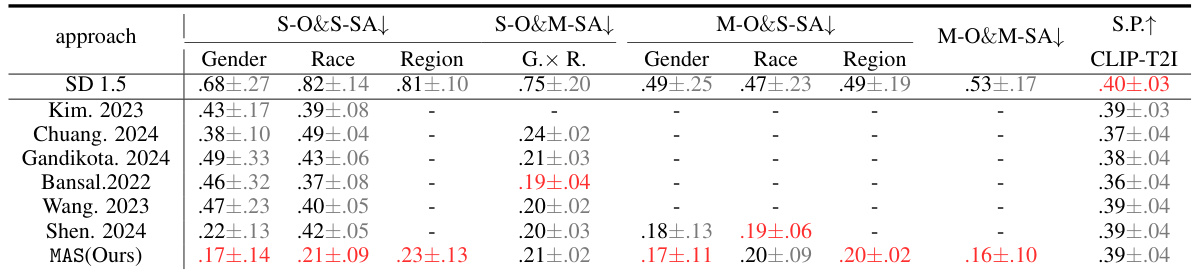
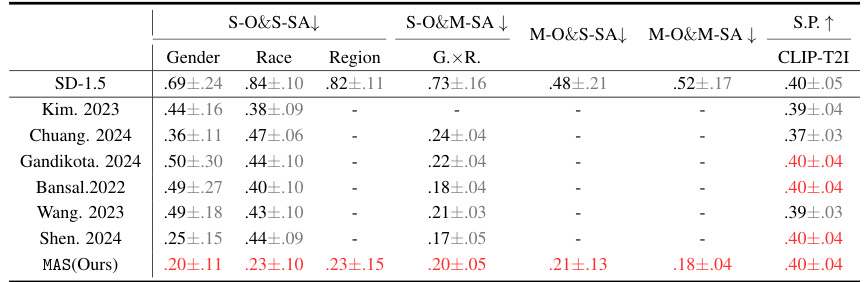
This table presents the results of a semantic preservation experiment. It shows the CLIP scores (CLIP-T2I and CLIP-I2I) for five different T2I models (SD-1.5, SD XL, Lightning, Turbo, Cascade) before and after applying the MAS (Mitigate Association-Engendered Stereotypes) framework. The CLIP-T2I score measures the similarity between generated images and prompts, while CLIP-I2I compares the similarity between images generated by the original T2I model and the stereotype-mitigated T2I model. Lower scores indicate better semantic preservation.
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV values indicate less severe stereotypes. The categories represent different combinations of object types and sensitive attributes (single or multiple). The table allows for a comparison of the models’ performance in mitigating stereotypes and showcases the effectiveness of the proposed MAS framework.
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV scores indicate a better mitigation of stereotypes. The four categories represent different combinations of object types (single vs. multiple) and sensitive attributes (single vs. multiple). The results showcase the effectiveness of the proposed MAS framework in reducing stereotypes generated by T2I models. The ‘optimal result’ column highlights the best performance achieved for each category.

This table presents the Stereotype Distribution Total Variation (SDTV) values for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV scores indicate more effective stereotype mitigation. The four categories represent different combinations of object types and sensitive attributes, allowing for a comprehensive evaluation of the model’s performance in various stereotype scenarios. The results show that the proposed MAS approach significantly reduces SDTV values compared to the original models, demonstrating its effectiveness in mitigating stereotypes.
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV scores indicate better mitigation of stereotypes. The categories represent different combinations of single or multiple objects and single or multiple sensitive attributes. The models are evaluated for gender, race, and region stereotypes.

This table shows the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. Lower SDTV scores indicate fewer stereotypes. The categories are: single object with single sensitive attribute (S-O & S-SA), single object with multiple sensitive attributes (S-O & M-SA), multiple objects with single sensitive attribute (M-O & S-SA), and multiple objects with multiple sensitive attributes (M-O & M-SA). The sensitive attributes evaluated are gender, race, and region. The table allows comparison of the baseline models’ performance to the proposed MAS model’s performance in mitigating stereotypes.
This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) models across four stereotype categories. The categories combine single/multiple objects with single/multiple sensitive attributes, evaluating the severity of stereotypes generated by each model. Lower SDTV scores indicate better stereotype mitigation. The table shows the effectiveness of the proposed MAS framework compared to the original models for each category.

This table presents the Stereotype-Distribution-Total-Variation (SDTV) scores for five popular text-to-image (T2I) diffusion models across four stereotype categories. Lower SDTV values indicate less severe stereotypes. The categories combine single/multiple objects with single/multiple sensitive attributes. The table shows the effectiveness of the proposed MAS framework in mitigating stereotypes across different models and stereotype types.
Full paper#