↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Digital twins (DTs) are computational models simulating real-world systems’ states and dynamics. Existing DTs struggle with generalization in data-scarce settings, a key limitation. Hybrid Digital Twins (HDTs), combining mechanistic and neural models, address this. However, automatically designing effective HDTs is challenging due to the complex search space.
This paper introduces HDTwinGen, an evolutionary algorithm using Large Language Models (LLMs) to automatically design HDTs. LLMs propose model specifications, offline tools optimize parameters, and feedback guides model evolution. HDTwinGen significantly improves DT generalization, sample efficiency, and evolvability. This automated approach significantly advances DTs’ efficacy in diverse real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on digital twins, hybrid modeling, and evolutionary algorithms. It introduces a novel approach to automatically design effective digital twins, which addresses the limitations of existing methods. The use of LLMs and evolutionary methods opens new avenues for research and potentially revolutionizes how digital twins are designed and applied. This is highly relevant to various fields such as healthcare, environmental modeling, and engineering, where digital twins are increasingly utilized.
Visual Insights#
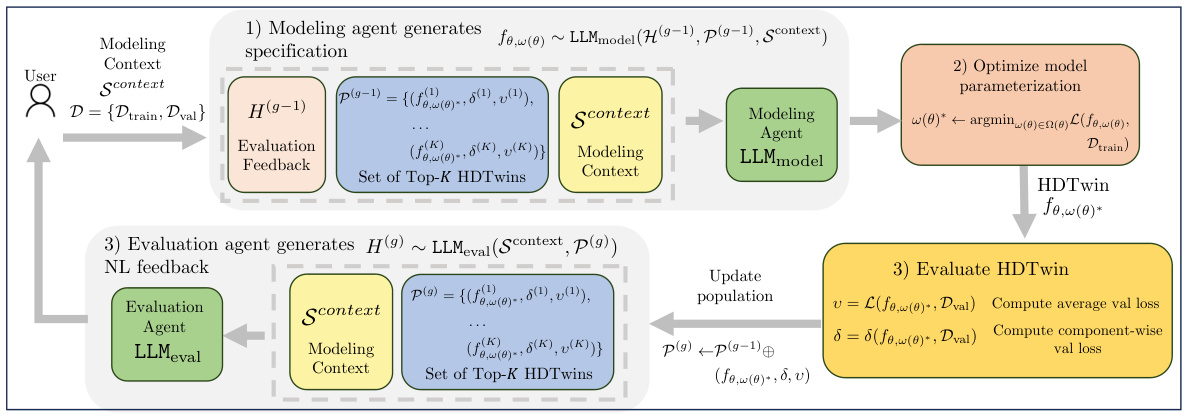
This figure illustrates the HDTwinGen evolutionary framework. It starts with user-defined context and data, showing an iterative process where a modeling agent generates a hybrid digital twin (HDTwin) model specification. The parameters of this specification are then optimized. The resulting HDTwin is evaluated and based on its performance (loss), the model pool is updated, keeping the top-K performing models. An evaluation agent then analyzes these models and provides feedback to improve subsequent HDTwin generations. This loop continues for a specified number of iterations (G).

This table presents a comparison of the test prediction mean squared error (TMSE) achieved by different methods (SINDY, GP, DyNODE, RNN, Transformer, APHYNITY, ZeroShot, ZeroOptim, and HDTwinGen) across six benchmark datasets representing complex real-world systems. Lower TMSE values indicate better performance. HDTwinGen consistently demonstrates the lowest error, highlighting its effectiveness. Confidence intervals are provided to indicate the uncertainty in the reported metrics.
In-depth insights#
Hybrid DT Design#
Hybrid Digital Twin (DT) design is a crucial area of research, aiming to leverage the strengths of both mechanistic and data-driven approaches. Mechanistic models offer strong interpretability and generalization based on first principles, but often lack the flexibility to capture complex real-world dynamics. Data-driven models, particularly neural networks, excel at capturing intricate patterns but suffer from limited generalizability and the ‘black box’ nature of their predictions. Hybrid DT design seeks to mitigate these limitations by combining mechanistic models with data-driven components. This integration often involves using mechanistic models to represent the fundamental system dynamics, while neural networks model complex residual patterns or components poorly captured by mechanistic equations. Key challenges in hybrid DT design include determining an optimal architecture that effectively integrates both modeling paradigms and handling the potential trade-off between interpretability and accuracy. Effective solutions will likely rely on techniques like automated model selection and optimization strategies to explore the vast design space and discover optimal architectures for specific applications.
LLM-driven Evolution#
LLM-driven evolution represents a significant advancement in automated model design, particularly for complex systems. By leveraging the power of Large Language Models (LLMs), the process of proposing, evaluating, and iteratively refining model architectures becomes significantly more efficient. The use of LLMs as generative agents allows for the exploration of a far wider design space than traditional methods, overcoming limitations posed by manual specification. The automated feedback mechanisms inherent in this approach accelerate convergence to high-performing models, making the process more sample-efficient. While this approach holds immense promise, it’s crucial to address potential limitations, including the risk of bias amplification from the LLM and the need for careful evaluation of the generated models to ensure reliability and generalizability.
Generalization & OOD#
The heading ‘Generalization & OOD’ speaks to a core challenge in applying machine learning models, particularly in complex scenarios. Generalization refers to a model’s ability to perform well on unseen data that differs from its training data. Out-of-Distribution (OOD) data represents data points outside the range or characteristics of the training data. Successfully addressing both requires models that can capture the underlying dynamics of the system rather than simply memorizing training examples. This necessitates robust model architectures and training methodologies. The focus should be on learning generalizable features and relationships, incorporating prior knowledge where available to constrain the search space and improve sample efficiency. Techniques like hybrid models that combine mechanistic and data-driven components can provide robustness and generalizability. Evolutionary algorithms, as explored in the paper, can further enhance model discovery in complex high-dimensional spaces. However, addressing both generalization and OOD remains a significant research area, requiring continued innovation in model design, training methods and evaluation strategies.
Benchmark Datasets#
The selection of benchmark datasets is crucial for evaluating the proposed HDTwinGen model. The paper leverages six diverse real-world datasets, ranging from biomedical PKPD models of lung cancer to ecological models of plankton microcosms and predator-prey dynamics. This multifaceted approach is methodologically sound, as it allows for a comprehensive assessment of the model’s generalizability across different domains and complexities. The inclusion of both simulated and real-world datasets further strengthens the evaluation, offering insights into both the model’s ability to learn from structured data and its performance on noisy, real-world observations. The choice of datasets demonstrates a commitment to rigorous testing, moving beyond easily-analyzed synthetic examples, and thus enhancing the credibility and impact of the findings. Detailed descriptions of each dataset are essential to allow reproducibility of the evaluation, enabling other researchers to verify the results and potentially build upon the presented work.
Future Research#
Future research directions stemming from this work on automatically learning hybrid digital twins could involve several key areas. Extending HDTwinGen to handle broader classes of systems beyond continuous-time dynamical systems is crucial, encompassing discrete-time systems and hybrid systems with both continuous and discrete components. Improving the efficiency and scalability of the evolutionary algorithm is another important direction. This includes exploring more sophisticated evolutionary strategies and optimizing the LLM interaction to minimize computational cost. Investigating the use of alternative model representations and search strategies beyond code-based models for HDTwins will also be valuable, potentially leading to more expressive model architectures and further enhancing the algorithm’s efficiency. A critical area for future work is mitigating the potential biases inherited from the LLMs, ensuring that the generated HDTwins are fair, robust, and reliable, especially when applied in sensitive contexts like healthcare. Finally, rigorous investigations into the theoretical properties and generalizability of the automatically designed HDTwins would offer valuable insights, furthering our understanding of hybrid models and strengthening the foundation for future developments.
More visual insights#
More on figures
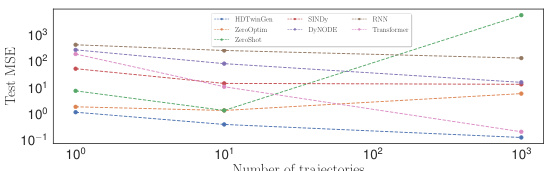
This figure demonstrates the sample efficiency of the HDTwinGen model. It shows the test MSE performance on the Lung Cancer (with Chemo. & Radio.) dataset as the number of training trajectories is varied. Even with very few training trajectories, HDTwinGen outperforms the other models, indicating its ability to learn effectively with limited data. The superior performance is attributed to the use of priors, which help the model generalize better.
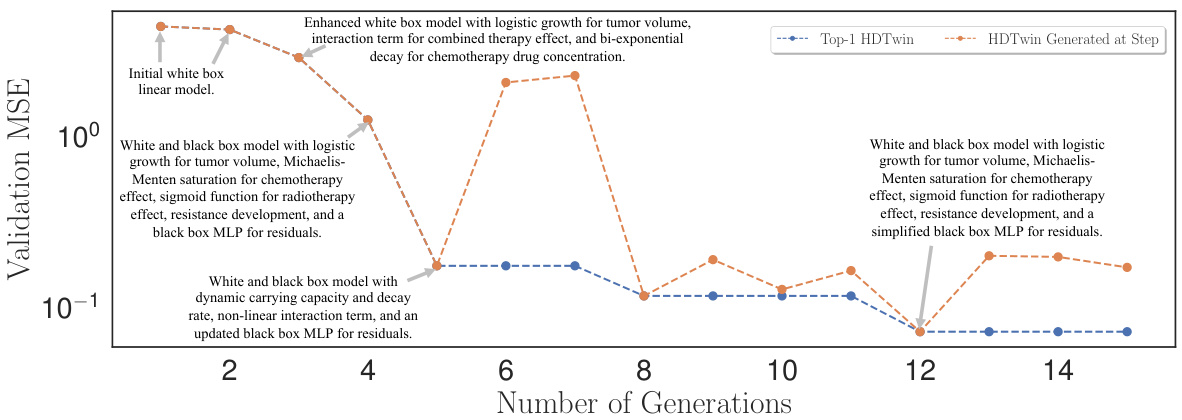
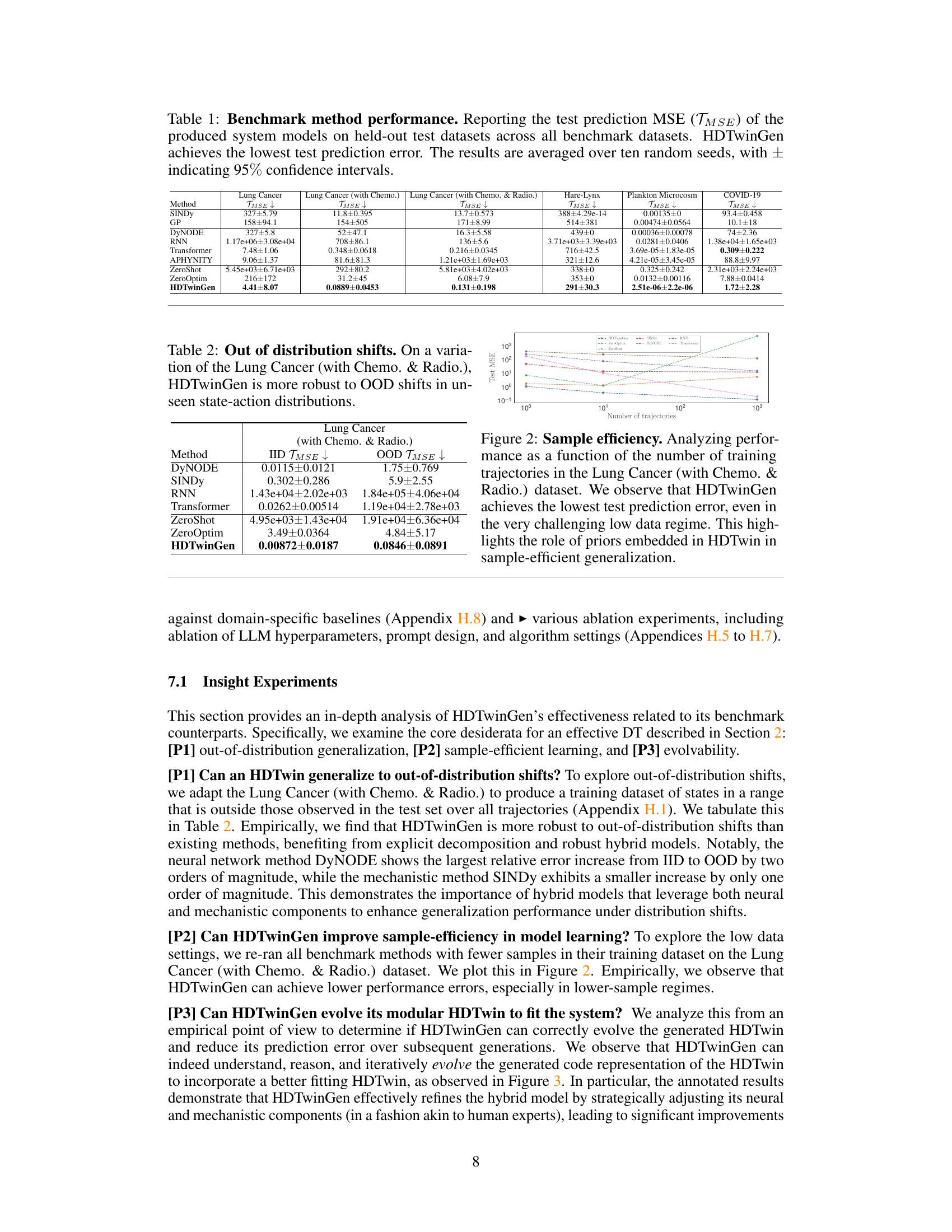
This figure shows how the HDTwinGen algorithm iteratively improves the hybrid digital twin model over multiple generations. The validation mean squared error (MSE) is plotted against the number of generations. Each point represents a generated model, with the top-performing model at each generation highlighted. The figure also includes descriptions of several models, illustrating how the architecture and complexity of the model evolve over time, ultimately leading to a more accurate and efficient representation of the underlying system.
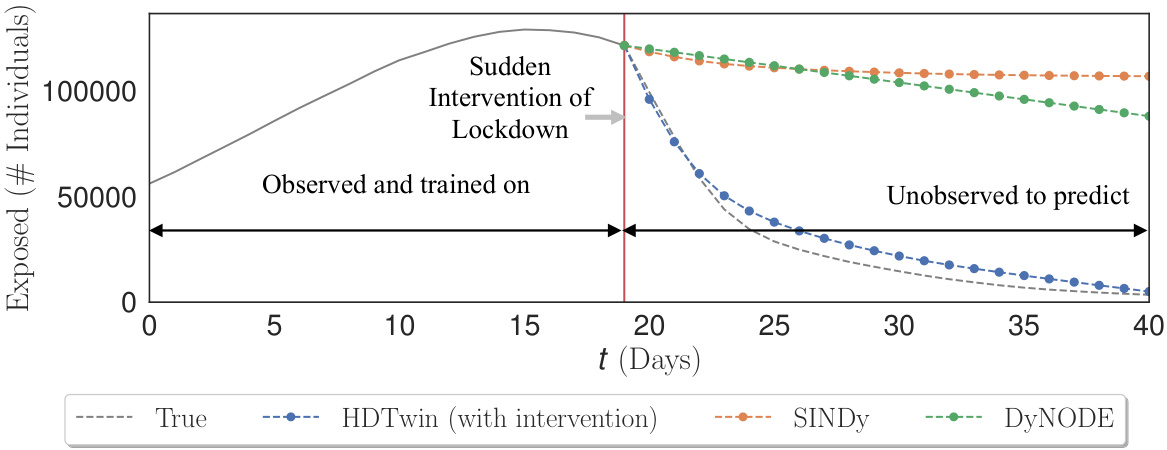
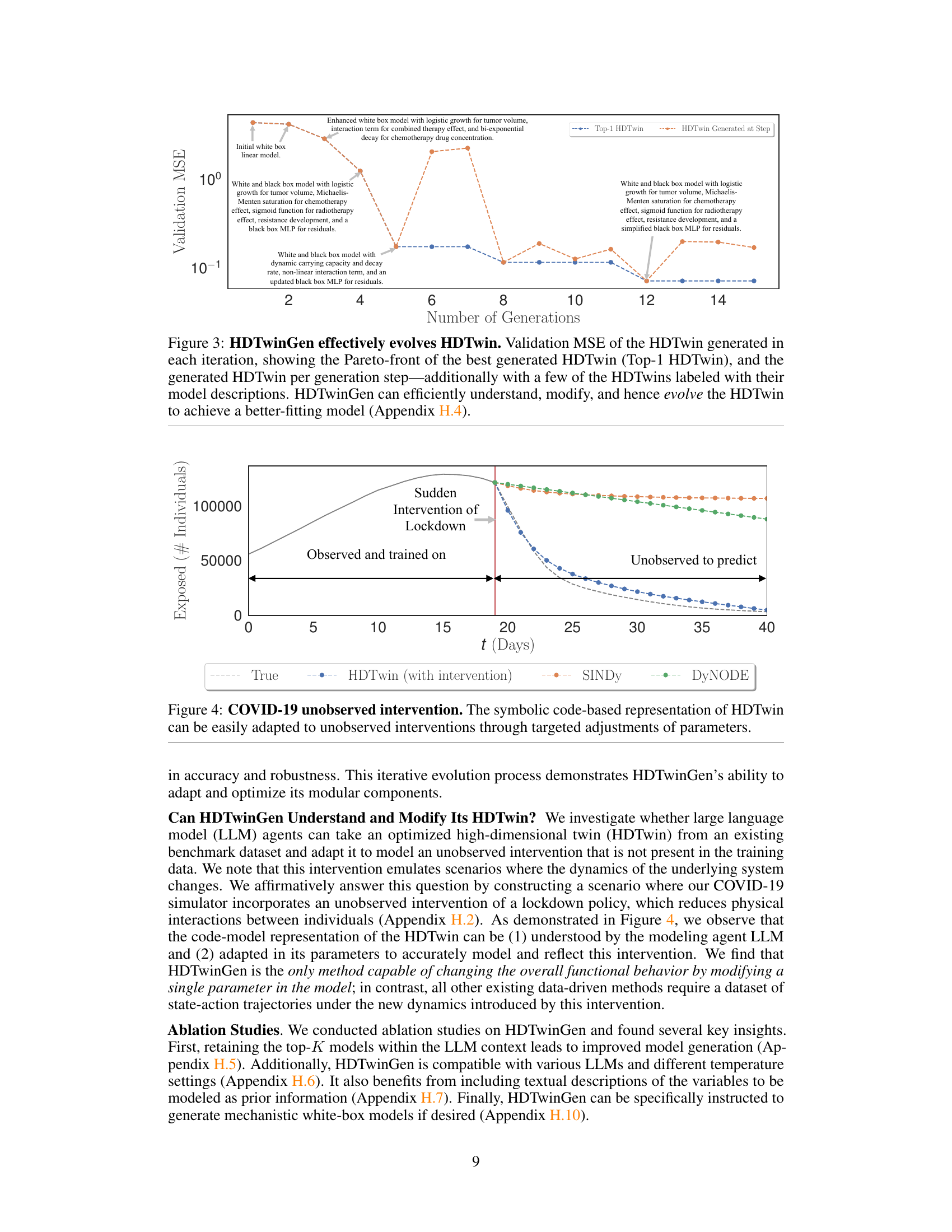
This figure demonstrates the ability of HDTwins, generated by HDTwinGen, to adapt to unanticipated real-world events. A COVID-19 epidemic simulation is used, where a lockdown (intervention) occurs midway through the simulation period. The training data only includes the time period before the lockdown. The HDTwin model is able to adjust its parameters to accurately predict the change in the number of exposed individuals after the lockdown is introduced, a task that is challenging for other models (DyNODE and SINDy) which only see data before the intervention. The HDTwin’s code-based representation makes it easily adaptable.
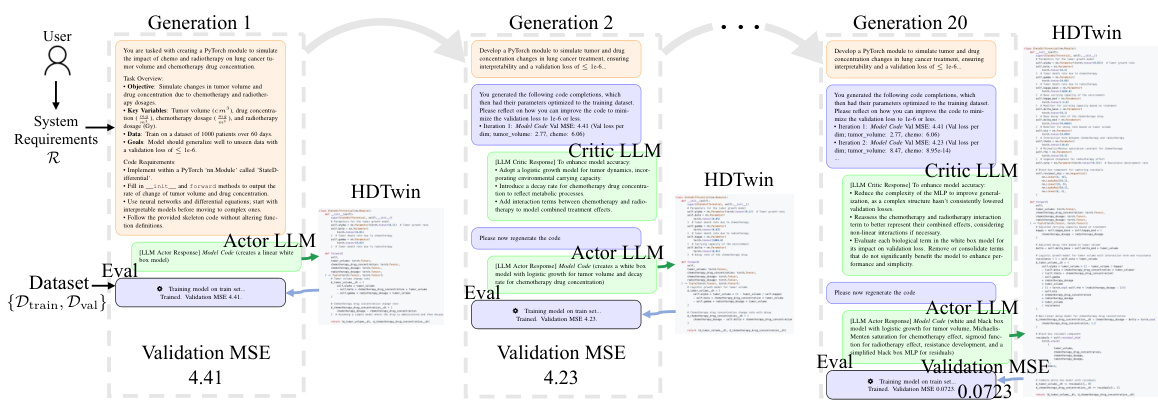
The figure illustrates the HDTwinGen evolutionary framework. It starts with a user-provided modeling context and dataset. The modeling agent generates a hybrid digital twin model specification (as Python code), which is then optimized using offline tools. The HDTwin’s performance is evaluated, and the top-performing models are selected. An evaluation agent analyzes these models and provides feedback to the modeling agent, guiding the generation of improved models. This iterative process repeats until the desired performance is achieved, resulting in an optimized HDTwin.
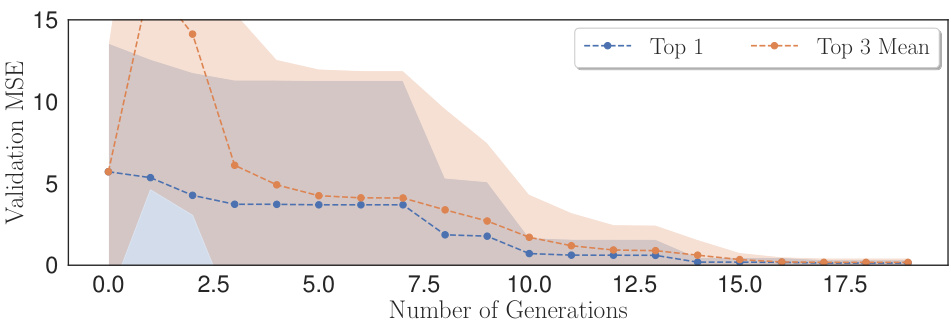
This figure shows the average validation mean squared error (MSE) for the top-performing HDTwin model (Top 1) and the average MSE for the top three HDTwin models (Top 3 Mean) across multiple generations of the HDTwinGen evolutionary algorithm. The shaded area represents the 95% confidence interval. It illustrates the iterative improvement in model accuracy as HDTwinGen evolves the HDTwin models over generations, achieving lower validation MSE over time, for the Lung Cancer (with Chemo. & Radio.) dataset.

This figure illustrates the HDTwinGen evolutionary framework, which iteratively generates, optimizes, and evaluates hybrid digital twin (HDTwin) models. The process starts with user-provided context (Scontext) and datasets (Dtrain, Dval). In each iteration, a modeling agent proposes HDTwin specifications, which are optimized offline, and an evaluation agent provides feedback using performance metrics. This iterative refinement leads to increasingly effective HDTwin models.

This figure illustrates the HDTwinGen evolutionary framework. It starts with user-defined modeling context and data. The modeling agent generates model specifications (as Python code), which are then optimized offline. The model is evaluated, and top-performing models are selected. The evaluation agent then provides feedback, driving iterative improvement of the model specifications until the final HDTwin is produced.

This figure illustrates the HDTwinGen evolutionary framework. It starts with user-provided modeling context and data, which includes training and validation datasets. The modeling agent then generates model specifications represented as Python programs. These specifications are subsequently optimized offline to obtain parameters. The resulting HDTwins are then evaluated based on model and component-wise losses. The top-performing models are retained, and feedback is provided to improve model specifications. This process iteratively enhances model performance.
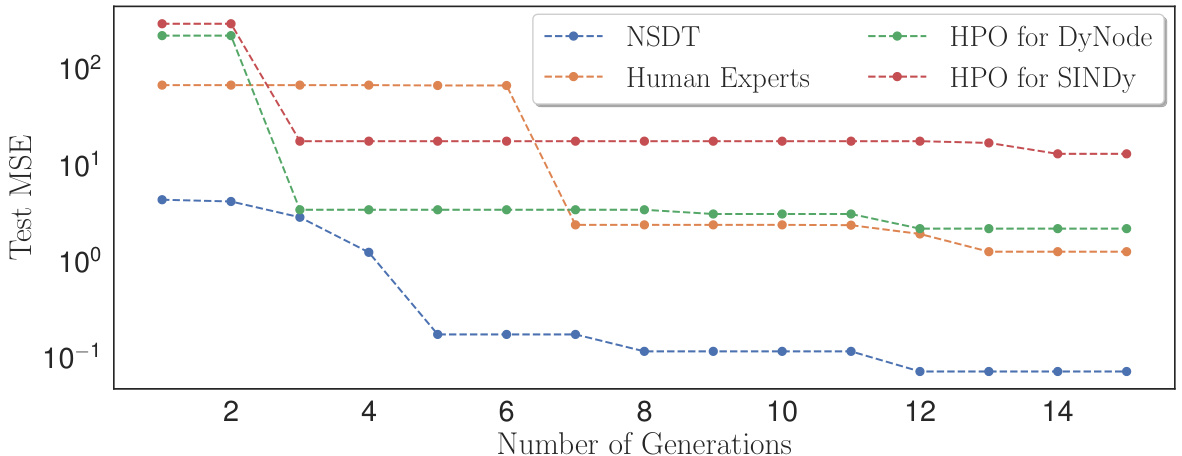
This figure compares the best-performing model’s test MSE across different methods over a fixed budget of model evaluations. It shows the performance of HDTwinGen against human experts and Bayesian hyperparameter optimization (BO) for DyNODE and SINDy. The results indicate that HDTwinGen consistently produces better-performing models than human experts and the BO-tuned baselines, highlighting its efficiency and effectiveness in finding high-performing models within a limited number of iterations.
More on tables
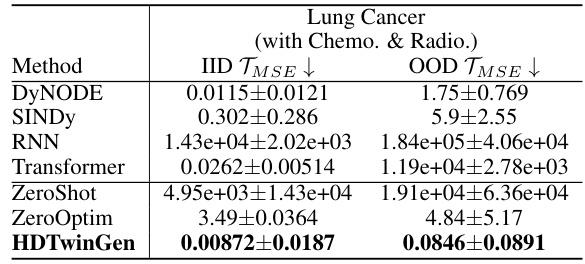
This table compares the performance of several methods (DyNODE, SINDY, RNN, Transformer, ZeroShot, ZeroOptim, and HDTwinGen) on an out-of-distribution (OOD) task. The IID TMSE (In-Distribution Mean Squared Error) column shows the performance on the original, seen data distribution, and the OOD TMSE shows performance when the model is tested on unseen state-action distributions. The results demonstrate that HDTwinGen is more robust to OOD shifts than other methods, highlighting its ability to generalize better to unseen conditions.
This table presents a comparison of the test prediction Mean Squared Error (MSE) for different methods on six benchmark datasets. The methods compared include various neural network models (DyNODE, RNN, Transformer), equation discovery methods (SINDy, GP), a hybrid model (APHYNITY), and ablations of the proposed HDTwinGen method (ZeroShot, ZeroOptim). HDTwinGen consistently achieves the lowest MSE, demonstrating its superior performance.

This table presents a comparison of the test prediction mean squared error (TMSE) achieved by different methods on six benchmark datasets. The methods compared include various neural network models (DyNODE, RNN, Transformer), mechanistic models (SINDy, GP), a hybrid model (APHYNITY), and the proposed HDTwinGen approach. The TMSE values, averaged over ten runs with different random seeds, are shown along with 95% confidence intervals, demonstrating the superior performance of HDTwinGen in accurately modeling the systems.
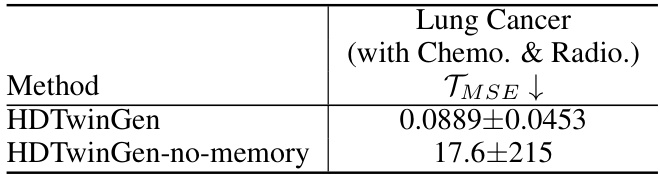
This table presents the ablation study results for the HDTwinGen model by removing its memory, only keeping the last hybrid model it generated. It compares the test prediction MSE (TMSE) for HDTwinGen with and without memory on the Lung Cancer (with Chemo. & Radio.) dataset. The results demonstrate the impact of memory on the model’s generalization performance, showing significantly lower error with memory enabled.

This table presents the results of an ablation study where different LLMs were used with the HDTwinGen framework. It shows the test mean squared error (TMSE) for each LLM, averaged over ten runs. The table demonstrates that HDTwinGen’s performance correlates with the capabilities of the underlying LLM, achieving the best performance with a more capable LLM (GPT-4). The results are reported with 95% confidence intervals to indicate statistical significance.

This table presents a comparison of the test prediction mean squared error (TMSE) achieved by different methods on six real-world benchmark datasets. The TMSE is a measure of how well each method predicts the system’s dynamics on unseen data. The results are averaged over ten independent runs with different random seeds, and 95% confidence intervals are provided to indicate the uncertainty of the estimates. The table highlights that HDTwinGen consistently achieves the lowest TMSE across all datasets, demonstrating its superior performance in modeling complex dynamical systems.

This table presents a comparison of the test prediction mean squared error (TMSE) achieved by different methods on six real-world datasets. The methods include several state-of-the-art neural network models (DyNODE, RNN, Transformer), mechanistic models (SINDY, GP), a hybrid model (APHYNITY), and two ablations of the proposed HDTwinGen method (ZeroShot, ZeroOptim). The results highlight HDTwinGen’s superior performance in accurately modeling complex dynamical systems, achieving the lowest TMSE across all datasets. Error bars represent 95% confidence intervals based on averaging over ten independent runs with different random seeds.

This table presents a comparison of the test prediction Mean Squared Error (MSE) achieved by different methods (SINDy, GP, DyNODE, RNN, Transformer, AphyNITY, ZeroShot, ZeroOptim, and HDTwinGen) across six benchmark datasets (Lung Cancer, Lung Cancer (with Chemo.), Lung Cancer (with Chemo. & Radio.), Hare-Lynx, Plankton Microcosm, and COVID-19). The results highlight the superior performance of HDTwinGen in terms of prediction accuracy. The values represent averages over ten independent runs, each using different random seeds, with 95% confidence intervals indicating the variability of the results.

This table presents the results of testing different machine learning models (DyNODE, SINDY, ZeroShot, ZeroOptim, and HDTwinGen) on five procedurally generated synthetic datasets. Each model’s performance is measured by its Test Mean Squared Error (TMSE), averaged over ten independent runs. The table highlights that HDTwinGen consistently achieves the lowest TMSE across all datasets, demonstrating its superior performance in this benchmark.

This table presents the test prediction mean squared error (TMSE) for six different dynamical systems. Multiple methods were used to model each system. The methods include neural network approaches (DyNODE, RNN, Transformer), symbolic regression techniques (SINDy, GP), a hybrid model (APHYNITY), and two variants of the proposed method HDTwinGen (ZeroShot, ZeroOptim). HDTwinGen consistently achieves the lowest TMSE values across all datasets. The TMSE values represent the average over 10 independent runs with 95% confidence intervals to show the variability in results.

This table presents a comparison of the test prediction Mean Squared Error (TMSE) achieved by different methods on six benchmark datasets. The TMSE represents the average error of each method in predicting the system’s dynamics on unseen data. HDTwinGen consistently outperforms other methods across the datasets.

This table presents a comparison of the test prediction Mean Squared Error (MSE) achieved by different methods across six benchmark datasets. The methods include several neural network-based approaches (DyNODE, RNN, Transformer), mechanistic equation discovery methods (SINDY, GP), a previously published hybrid model (APHYNITY), and two ablations of the proposed HDTwinGen method (ZeroShot, ZeroOptim). The table highlights that HDTwinGen consistently outperforms other methods in terms of prediction accuracy, achieving the lowest TMSE across all datasets. The reported values are averages across 10 runs with different random seeds, with confidence intervals provided to indicate the reliability of the results.
Full paper#