↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Existing vision-language models (VLMs) heavily rely on vision encoders, which introduce limitations in flexibility and efficiency. Training pure decoder-only VLMs without encoders has been challenging due to slow convergence and performance gaps. This paper addresses these issues by proposing a novel training recipe for encoder-free VLMs.
The proposed method introduces two key strategies: bridging vision-language representations within a unified decoder and enhancing visual recognition using extra supervision. These strategies enabled the development of EVE, an encoder-free VLM that rivals encoder-based models while using significantly less data (only 35M publicly accessible samples). EVE achieves superior performance across multiple vision-language benchmarks, outperforming counterparts with mysterious training procedures and undisclosed training data. This demonstrates a transparent and efficient route for developing decoder-only architectures.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel and efficient approach to building vision-language models (VLMs), overcoming limitations of existing encoder-based models. It offers a transparent training process, achieving competitive results with significantly less data and computational resources, opening new avenues for VLM research and broader multi-modal applications. The work also addresses practical deployment challenges by creating simpler, more efficient architectures.
Visual Insights#

This figure compares and contrasts the architectures of encoder-based and encoder-free vision-language models (VLMs). Encoder-based VLMs use a vision encoder to process images, converting them into a format that can be integrated with a large language model (LLM). The two components are connected through an intermediate layer. In contrast, encoder-free VLMs directly process both image and text data within a single unified architecture, eliminating the need for a separate vision encoder. The figure highlights the advantages and disadvantages of each approach, addressing issues such as image resolution flexibility, deployment overhead, and the balance of capacity between the vision and language components.
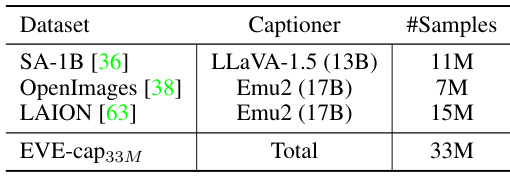
This table details the datasets used for pre-training the EVE model. It shows that the model was pre-trained in two stages. Stage 1 used a subset of the data (16 million or 33 million samples), while Stage 2 used the full 33 million samples. The datasets include SA-1B, OpenImages, and LAION, with each dataset’s image captions generated by either LLaVA-1.5 or Emu2.
In-depth insights#
Encoder-Free VLMs#
Encoder-free Vision-Language Models (VLMs) represent a significant departure from traditional encoder-based architectures. The core innovation lies in eliminating the vision encoder, a component typically used to extract visual features before processing with a language model. This removal offers several potential advantages: increased flexibility in handling diverse image resolutions and aspect ratios, reduced computational overhead during deployment, and a more streamlined model architecture. However, training encoder-free VLMs presents challenges, primarily due to the difficulty of directly bridging vision and language representations within a unified decoder. Effective training strategies are key, involving careful initialization and pre-training techniques that align visual and linguistic information within the model before moving to supervised fine-tuning. The authors’ solution, EVE, demonstrates promising results, showing that encoder-free VLMs can achieve competitive performance with their encoder-based counterparts despite using a simpler design and fewer resources. The research highlights the importance of training methodologies to tackle the challenges of pure decoder architectures, suggesting a potentially more efficient and transparent path for future VLM development.
Efficient Training#
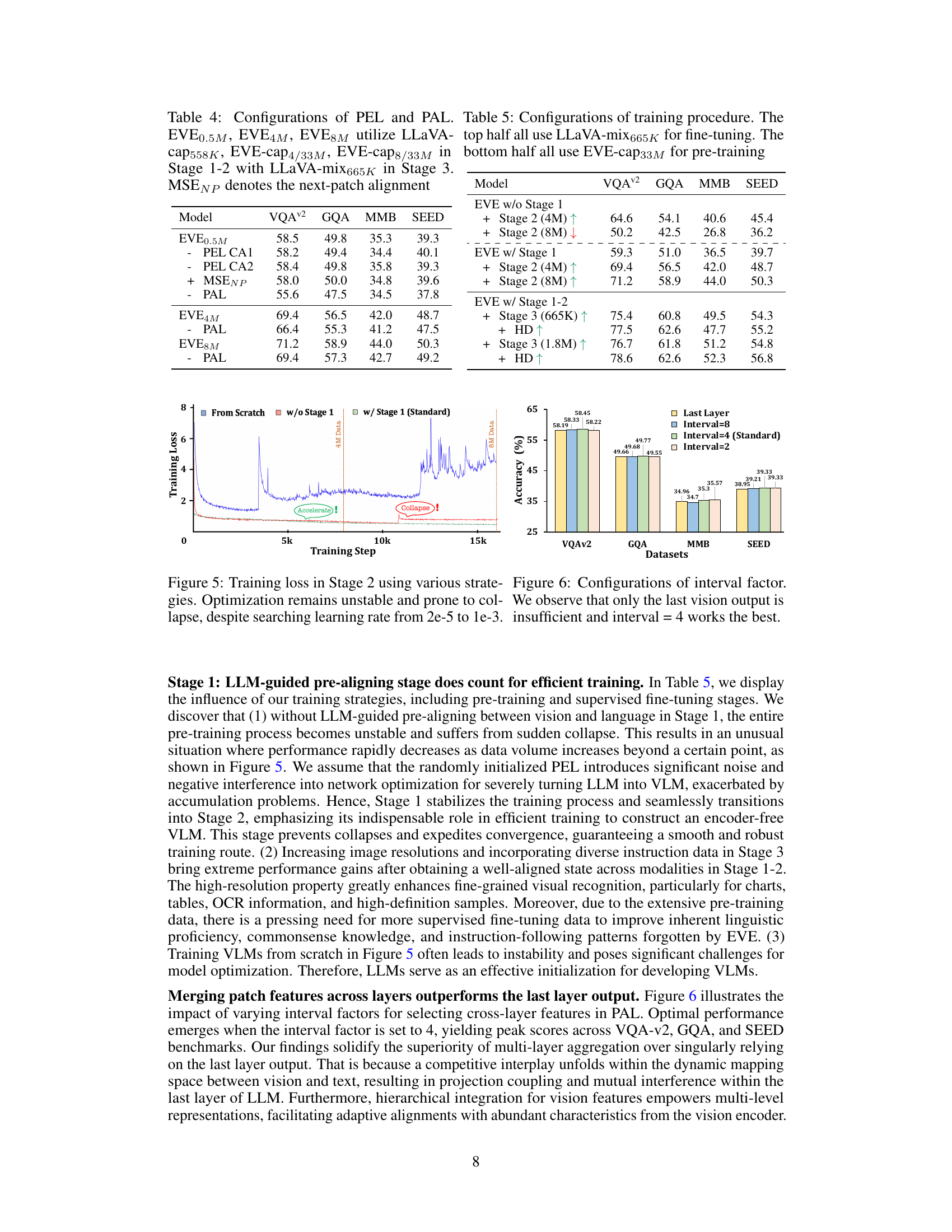
Efficient training of large vision-language models (VLMs) is a critical challenge due to their substantial computational demands. This paper addresses this by introducing encoder-free VLMs, which significantly reduce the computational burden associated with traditional encoder-based architectures. The key to efficient training lies in a three-stage process: LLM-guided pre-aligning establishes initial vision-language alignment using a frozen LLM, preventing model collapse and accelerating convergence. Generative pre-training then leverages this alignment to optimize the entire VLM architecture. Finally, supervised fine-tuning enhances performance using multi-modal dialogue data. The strategy of progressively training the model, starting with a smaller, more manageable model, before scaling up to full-size helps prevent unstable optimization and resource exhaustion. Implicit integration of visual information via a patch alignment layer further contributes to efficiency by avoiding the need for extensive pre-trained visual encoders. This combination of novel architecture, data utilization, and training methodology demonstrates a substantially efficient pathway towards creating high-performing VLMs.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a thorough comparison of the proposed model against existing state-of-the-art methods. This would involve selecting relevant and established benchmarks, clearly defining evaluation metrics, and presenting results in a clear and easily interpretable format, including tables and charts. Statistical significance testing should be used to ensure that observed differences between the model and baselines are meaningful, and not due to random chance. The discussion should not only report quantitative performance but also analyze the qualitative aspects of the model’s behavior, potentially highlighting strengths and weaknesses in different scenarios or tasks. A strong benchmark section would also address any limitations of the benchmarks themselves, and provide context for interpreting the results, especially when comparing models with different training procedures or data sets. Finally, a thoughtful discussion of the results relative to the model’s contributions is key; simply reporting numbers isn’t sufficient. The section should connect performance to claims made earlier in the paper and highlight the novelty and impact of the findings.
Ablation Study#
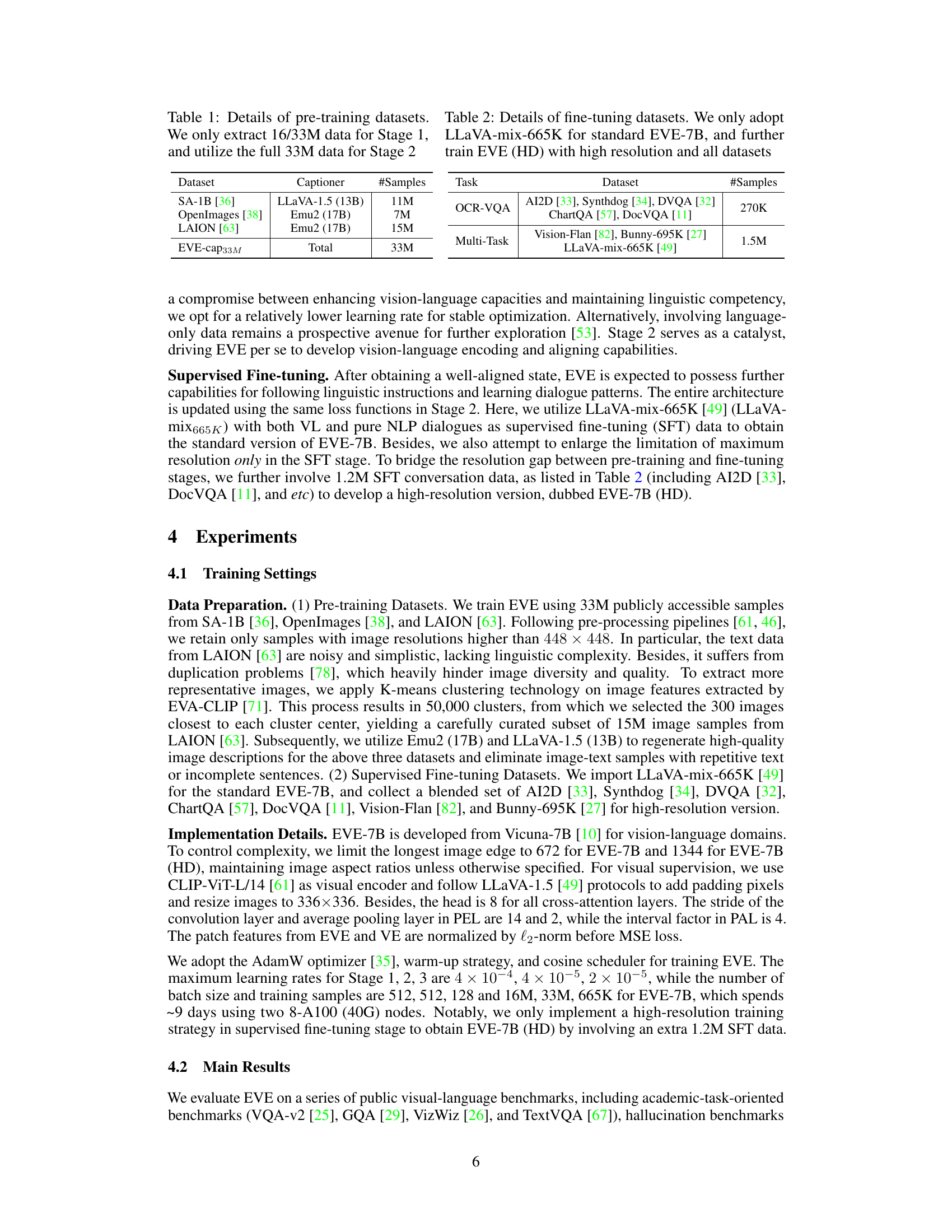
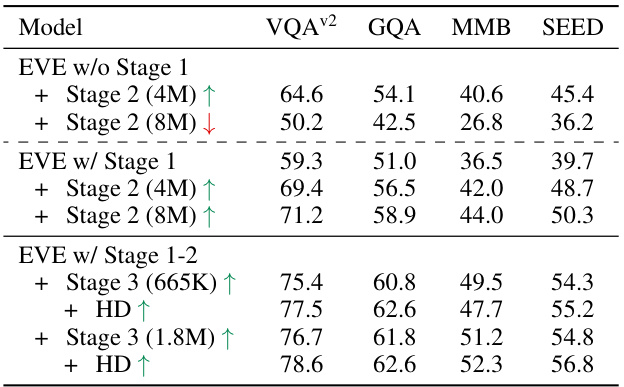
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a vision-language model (VLM), this might involve removing or modifying elements such as the patch embedding layer, the patch aligning layer, or specific attention mechanisms to assess their impact on overall performance. A well-designed ablation study provides crucial insights into the architecture’s design choices, illuminating which components are essential for achieving state-of-the-art results and which are redundant. By isolating the effects of each module, researchers can understand the model’s inner workings, potentially revealing areas for improvement or simplification. The results often guide future design decisions, allowing for the development of more efficient and robust models. For instance, an ablation study might demonstrate that a particular component is crucial for handling high-resolution images but has a negligible impact on other aspects of performance, helping to prioritize future optimization efforts.
Future Work#
Future research directions stemming from this encoder-free vision-language model (EVE) are multifaceted. Improving the model’s performance on tasks requiring complex reasoning and nuanced linguistic understanding remains a key goal. This could involve exploring advanced training strategies, such as incorporating more diverse and higher-quality data, implementing more sophisticated loss functions, or leveraging techniques like mixture-of-experts. Furthermore, extending EVE’s capabilities to handle other modalities (audio, video, depth, etc.) is a promising area of investigation. This requires developing pre-alignment strategies for these modalities, potentially through the use of modality-specific encoders, and aligning them with language before full multi-modal training. Exploring the scaling behavior of EVE with larger models and datasets is crucial for determining its practical limits and potential. The efficiency gains demonstrated by EVE suggest a pathway towards scalable multi-modal models. Finally, a comprehensive investigation into the robustness and safety aspects of EVE is critical before broader deployment. This involves addressing potential biases in the data and mitigating risks of misuse.
More visual insights#
More on figures

The figure illustrates the architecture of EVE, an encoder-free vision-language model. It shows how image patches are embedded using a patch embedding layer and then combined with text embeddings in a causal decoder-only architecture. A patch aligning layer uses visual representation supervision to enhance image perception and linguistic conceptual alignment. The model learns to predict the next word, aligning visual and linguistic information.
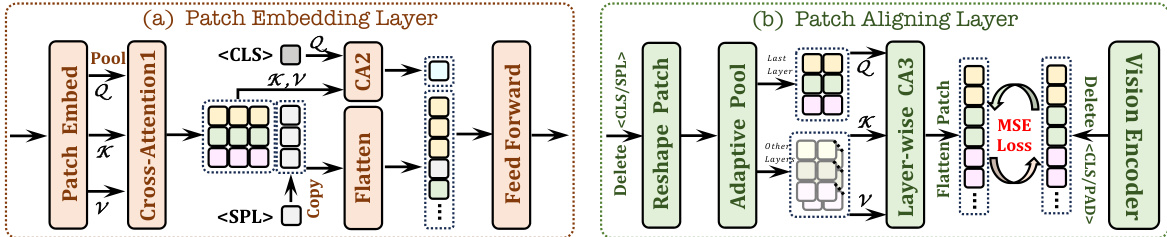
This figure details the architecture of two key components in the EVE model: the Patch Embedding Layer and the Patch Aligning Layer. The Patch Embedding Layer efficiently encodes image information into patch features, leveraging cross-attention to refine representations and a special
token for holistic understanding. The Patch Aligning Layer then aligns these patch features with those from a vision encoder to further enhance visual perception. It achieves this by removing unnecessary tokens and adjusting patch feature sizes to match the semantic representations of the vision encoder. The process involves layer-wise cross-attention and minimizes the Mean Squared Error (MSE) between EVE and the vision encoder.

This figure illustrates the three-stage training process for the EVE model. Stage 1 involves LLM-guided pre-alignment, where a frozen LLM guides the initial vision-language alignment. Stage 2 is generative pre-training, where the entire backbone is updated. Stage 3 is supervised fine-tuning. The figure highlights the crucial role of Stage 1 in preventing model collapse and accelerating convergence. It also notes that the Patch Aligning Layer (PAL) is removed during inference.

This figure shows the training loss curves for different training strategies in Stage 2 of the EVE model training. The blue curve represents training from scratch without the LLM-guided pre-aligning stage, showing significant instability and model collapse. The red and green curves represent training without and with the LLM-guided pre-aligning stage (Stage 1), respectively. The green curve demonstrates much more stable and faster convergence, emphasizing the crucial role of Stage 1 in efficient and robust training.

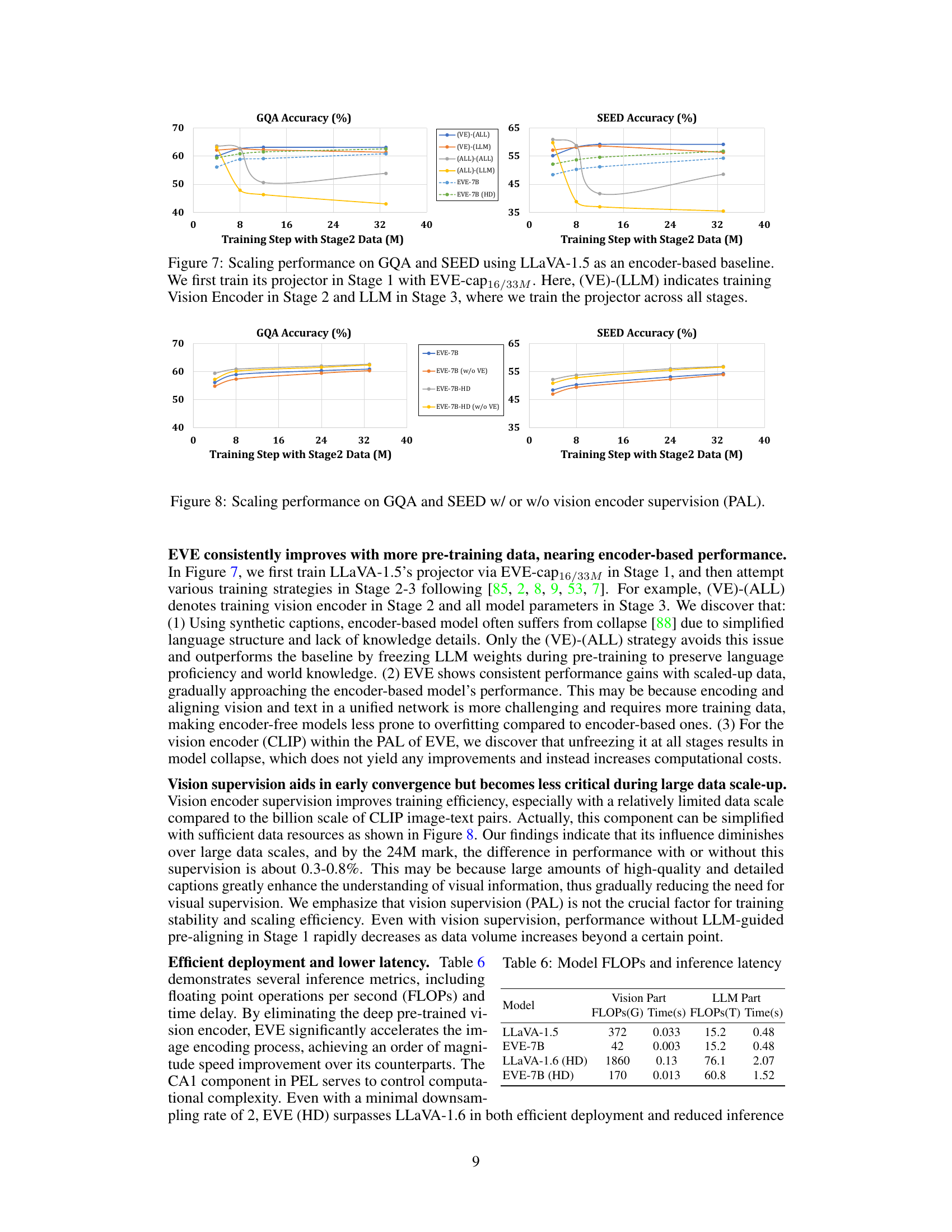
This figure shows the scaling performance of EVE-7B and EVE-7B (HD) on GQA and SEED benchmarks, comparing them to LLaVA-1.5 (an encoder-based baseline). It illustrates how performance changes with increasing amounts of training data in Stage 2. The different line styles represent different training strategies: (VE)-(ALL) trains the vision encoder in Stage 2 and all model parameters in Stage 3; (VE)-(LLM) trains the vision encoder in Stage 2 and the language model in Stage 3; (ALL)-(ALL) trains all model parameters in both stages; (ALL)-(LLM) trains all model parameters in Stage 2 and the language model in Stage 3. The results demonstrate that EVE consistently improves with more training data, approaching the performance of the encoder-based LLaVA-1.5 baseline.

This figure demonstrates the impact of vision encoder supervision (PAL) on the performance of EVE-7B and EVE-7B (HD) models across different training data sizes on GQA and SEED benchmarks. The plot shows that the models consistently improve with more pre-training data, regardless of whether or not PAL is used. The effect of PAL is more pronounced with smaller datasets and diminishes as the amount of training data increases.

This figure compares and contrasts the architectures of encoder-based and encoder-free vision-language models (VLMs). Encoder-based VLMs utilize a vision encoder to process images, converting them into a visual representation that is then passed to a large language model (LLM) for further processing. A projector module often bridges the two components. In contrast, encoder-free VLMs process images and text directly within a single unified architecture, eliminating the need for a separate vision encoder and thereby simplifying the model and improving flexibility. The figure highlights the key differences in architecture and workflow and points to several limitations (image resolution, deployment overhead, capacity balance) of the encoder-based model that motivate the exploration of the encoder-free approach.

This figure compares and contrasts the architectures of encoder-based and encoder-free Vision-Language Models (VLMs). Encoder-based VLMs consist of a vision encoder to process images, a large language model for text understanding, and a projector that bridges the two modalities. In contrast, encoder-free VLMs use a single, unified architecture that processes both visual and textual inputs simultaneously without a dedicated vision encoder. The figure highlights several key distinctions and challenges of each architecture, including differences in image resolution/aspect ratio handling, deployment overhead, and capacity balance between the visual and language components.
More on tables

This table presents the details of the datasets used for fine-tuning the EVE model. It shows that the standard EVE-7B model was fine-tuned using the LLaVA-mix-665K dataset. A high-resolution version of EVE (EVE-HD) was also trained, using the LLaVA-mix-665K dataset along with additional datasets, namely AI2D [33], Synthdog [34], DVQA [32], ChartQA [57], DocVQA [11], Vision-Flan [82], and Bunny-695K [27], resulting in a larger number of samples for the high-resolution training.
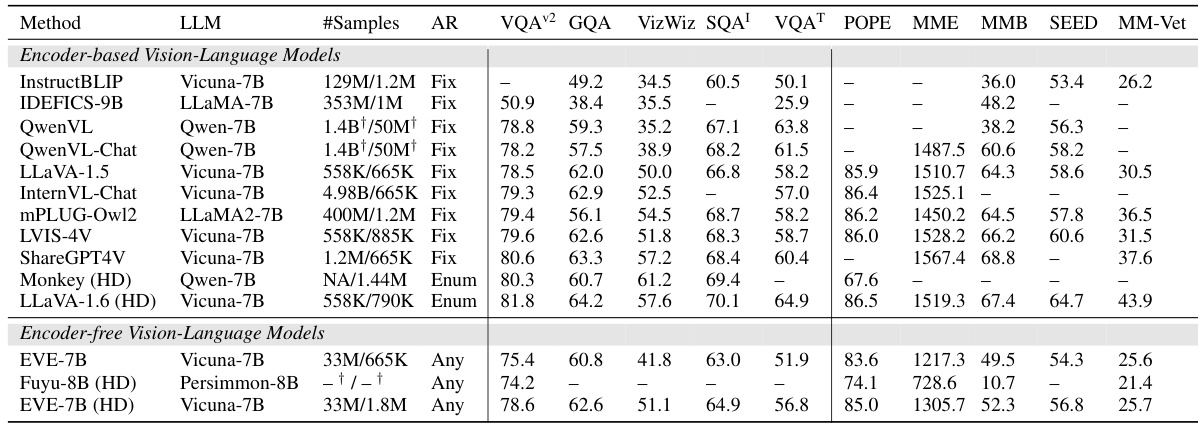
This table compares the performance of EVE-7B and EVE-7B (HD) against various state-of-the-art encoder-based and encoder-free vision-language models across multiple benchmark datasets. The metrics used for comparison include scores on different vision-language tasks (VQA-v2, GQA, VizWiz, ScienceQA-IMG, TextVQA, POPE, MME, MMBench, SEED, and MM-Vet). The table also indicates the size of LLMs used, the amount of training data, and whether high-resolution images were used.

This table presents an ablation study on the configurations of the Patch Embedding Layer (PEL) and Patch Aligning Layer (PAL) within the EVE model. It shows the performance (VQAv2, GQA, MMB, SEED scores) of different EVE model variants, each differing in the inclusion/exclusion or specific configuration of the PEL and PAL components. Different sizes of training datasets were also used for comparison, helping to analyze the effectiveness of PEL and PAL at various scales.
This table compares the performance of EVE and other state-of-the-art Vision-Language Models (VLMs) across various vision-language benchmarks. It highlights EVE’s performance relative to encoder-based models, considering factors like the number of training samples, image aspect ratios, and high-resolution image capabilities. The benchmarks used cover a range of tasks and dataset scales.
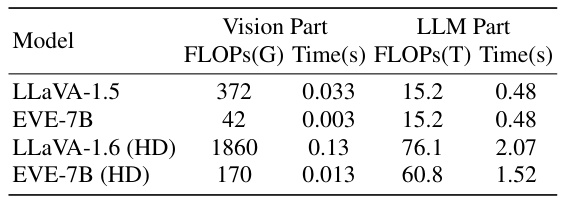
This table compares the computational cost (FLOPs) and inference speed (Time) for both the vision and LLM components of four different models: LLaVA-1.5, EVE-7B, LLaVA-1.6 (HD), and EVE-7B (HD). It highlights the significant reduction in FLOPs and inference time achieved by EVE models, especially EVE-7B, compared to their LLaVA counterparts, demonstrating the efficiency gains from the encoder-free architecture. The (HD) versions represent high-resolution models.

This table lists the datasets used in the supervised fine-tuning stage of the EVE model training. It shows the proportion of each dataset in the mixture (Sample Ratio), the number of samples from that dataset (Size), and the type of task the data is relevant to (Task). The datasets are diverse, covering conversation, text-only, general question answering, knowledge-based question answering, OCR-based question answering, grounding, multi-task learning, chart question answering, science question answering, and document-related tasks.

This table shows the hyperparameter settings used during the three training stages of the EVE model. It details the batch size, learning rate, learning rate schedule (cosine decay), learning rate warmup ratio, weight decay, number of epochs, optimizer (AdamW), and DeepSpeed stage used in each stage.

This table compares the performance of EVE and other state-of-the-art Vision-Language Models (VLMs) across various vision-language benchmarks. It shows the different models used, the number of training samples, image aspect ratio, high-resolution image usage, and the performance scores on various benchmarks. The benchmarks include academic-task-oriented, open-world multi-modal understanding and scientific problem benchmarks. The table highlights EVE’s competitive performance, especially considering its smaller size and reliance on publicly available data.
Full paper#