↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Scene Text Editing (STE) aims to modify text in images while maintaining realism. Existing GAN-based methods struggle with generalization, while diffusion-based methods suffer from style deviations. This paper introduces TextCtrl, a novel diffusion-based STE method that incorporates Style-Structure guidance and a Glyph-adaptive Mutual Self-attention mechanism to improve style consistency and rendering accuracy.
TextCtrl’s design explicitly addresses the limitations of previous approaches by disentangling text styles and representing glyph structures effectively. It uses a novel conditional diffusion model that integrates these features for accurate editing. The study also introduces ScenePair, a new real-world dataset for more comprehensive STE evaluation. Experiments on this new dataset demonstrate the improved performance of TextCtrl compared to existing methods in terms of both style fidelity and accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it presents TextCtrl, a novel approach to scene text editing that significantly improves both style fidelity and text accuracy. It also introduces ScenePair, the first real-world dataset for evaluating scene text editing, enabling more robust and reliable comparisons between different methods. This work addresses existing limitations in GAN and diffusion-based methods, opening new avenues for research in text-to-image synthesis and image manipulation.
Visual Insights#
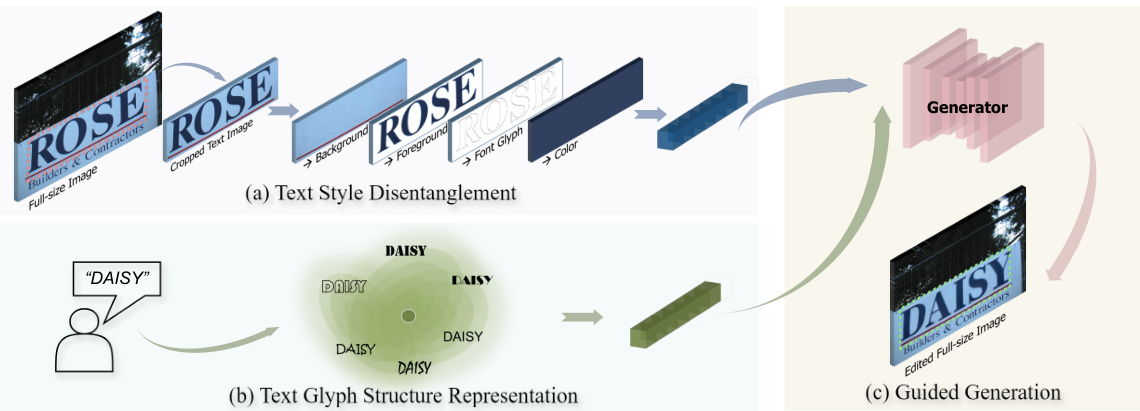
This figure illustrates the TextCtrl method’s decomposition of Scene Text Editing (STE) into three sub-tasks. Panel (a) shows the disentanglement of text style into its constituent features: background, foreground, font glyph, and color. Panel (b) depicts how the glyph structure is represented using a cluster centroid approach based on various font text features. Panel (c) demonstrates how these extracted style and structure features guide the generator to perform the actual scene text editing.
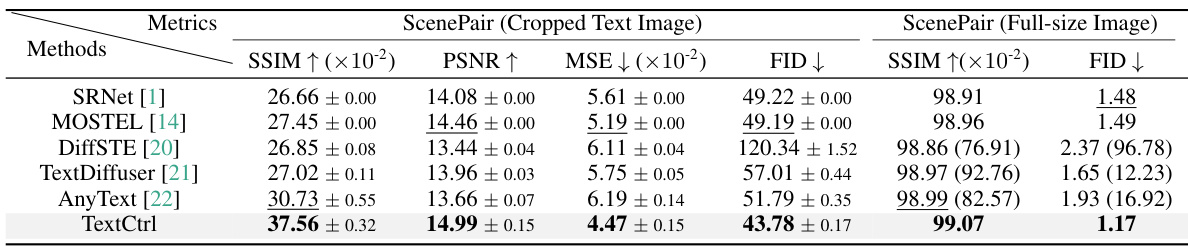
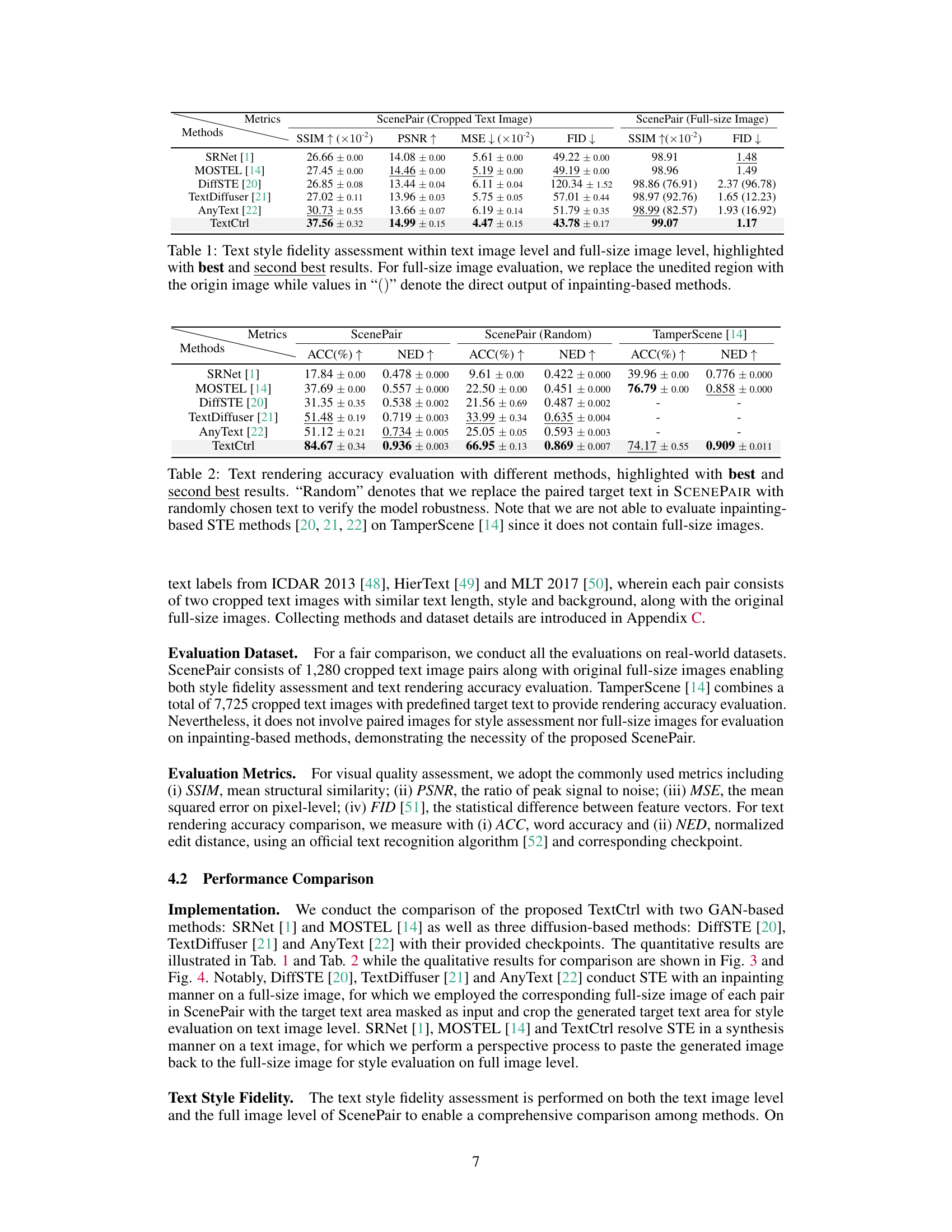
This table presents a quantitative comparison of different scene text editing methods in terms of style fidelity. It assesses two levels: text image level (cropped region) and full image level (entire image with the edited text region replacing the original). Metrics used include SSIM (structural similarity), PSNR (peak signal-to-noise ratio), MSE (mean squared error), and FID (Fréchet Inception Distance). The best and second-best results for each metric and level are highlighted. For the full-size image evaluation, methods using inpainting were evaluated in two ways: using only the inpainted region and by replacing the inpainted region with the original to evaluate the impact of the background restoration.
In-depth insights#
Style-Structure Guidance#
The concept of ‘Style-Structure Guidance’ in scene text editing (STE) is crucial for generating high-fidelity results. It suggests a two-pronged approach to controlling the generation process: manipulating the style (e.g., font, color, background) independently from the structure (glyph shapes, spatial arrangement). This disentanglement allows for finer control over the editing process, enabling precise modifications to the text’s visual appearance while maintaining style consistency. Effective style-structure guidance requires a robust representation of both aspects. The method should learn to separate these features during training, then utilize this understanding during inference to guide the text generation process and minimize unwanted style deviations or structural inconsistencies. The success of this approach depends heavily on the quality of feature extraction and representation, as well as the ability of the model to effectively integrate these features during generation. Furthermore, it necessitates a suitable evaluation benchmark capturing both stylistic and structural fidelity. Therefore, a comprehensive evaluation method should be employed to ascertain the approach’s effectiveness in achieving both high text accuracy and visual realism.
Diffusion Model STE#
Diffusion models have emerged as a powerful technique for image generation and manipulation, and their application to Scene Text Editing (STE) is a promising area of research. Diffusion-based STE methods offer several advantages over GAN-based approaches, such as improved sample quality and a reduced risk of mode collapse. However, challenges remain, including controlling the style of the generated text and ensuring that the edited text is consistent with the background. Prior guidance control is essential to address these issues. By carefully incorporating style and structural information into the diffusion process, it’s possible to improve text style consistency, rendering accuracy, and overall image quality. Fine-grained disentanglement of style features, and robust text glyph structure representation are also key to developing effective and high-fidelity diffusion-based STE models. The creation of high-quality real-world evaluation benchmarks is crucial for future progress in this field. Research focusing on these areas will likely yield significant advancements in diffusion-based STE techniques.
ScenePair Dataset#
The creation of a novel dataset, ScenePair, represents a significant contribution to the field of scene text editing (STE). Its focus on real-world image pairs, featuring similar style and word length, directly addresses the limitations of existing synthetic datasets. These real-world examples offer a more realistic and robust evaluation benchmark, moving beyond the constraints and domain gaps often associated with artificial data. The inclusion of both cropped text images and their corresponding full-size counterparts enables comprehensive evaluation of both visual quality and rendering accuracy. By providing this richer context, ScenePair allows for a more thorough assessment of STE methods, promoting fairer comparisons and driving advancements in the field. The deliberate collection process ensures higher quality and relevance, making ScenePair a valuable resource for researchers seeking to advance the accuracy and style fidelity of STE models. This dataset facilitates a much needed advancement beyond isolated text assessments toward an evaluation of the holistic context of scene-based text editing.
Glyph Attention#
The concept of ‘Glyph Attention’ in a scene text editing context suggests a mechanism that selectively focuses on the visual characteristics of individual glyphs within a text image. This approach moves beyond holistic text representation and enables fine-grained control over style and structure. By attending to specific glyphs, the model can more effectively preserve the stylistic consistency of the original text while modifying content. This targeted approach is crucial for high-fidelity text editing because it allows for subtle adjustments to font features, color, and spatial arrangement at the glyph level, avoiding the jarring inconsistencies that can arise from coarse-grained manipulations. A well-designed Glyph Attention mechanism can improve rendering accuracy and enhance the overall visual quality of the edited image, leading to more convincing and realistic results. The challenge lies in effectively learning the visual features that define each glyph, while also maintaining contextual understanding of its place within the larger word and sentence.
Future of STE#
The future of Scene Text Editing (STE) holds immense potential, driven by advancements in diffusion models, large language models (LLMs), and high-resolution image generation. Improved style disentanglement techniques will enable more precise control over text style and background consistency. We can expect more robust and versatile STE models capable of handling complex scenes, diverse text styles, and arbitrary shapes. Real-world benchmarks are crucial for evaluating progress and driving the development of more generalizable methods. Ethical considerations regarding potential misuse in creating deepfakes and other forms of misinformation must also be addressed to ensure responsible innovation. Further research in incorporating semantic understanding from LLMs should improve accuracy and allow for more sophisticated text manipulation. Ultimately, the goal is to achieve a seamless and intuitive STE experience with highly realistic results.
More visual insights#
More on figures

This figure shows the architecture of the TextCtrl model, which is composed of four main parts: (a) Text Glyph Structure Encoder, (b) Text Style Encoder, (c) Diffusion Generator, and (d) Glyph-adaptive Mutual Self-Attention. The encoder parts pre-process the input text and image respectively, extracting stylistic and structural information. The generator then uses this information to create a modified image. Finally, the Glyph-adaptive Mutual Self-Attention mechanism refines the generation by incorporating information from the original image. The diagram visually outlines the flow of information between each component.

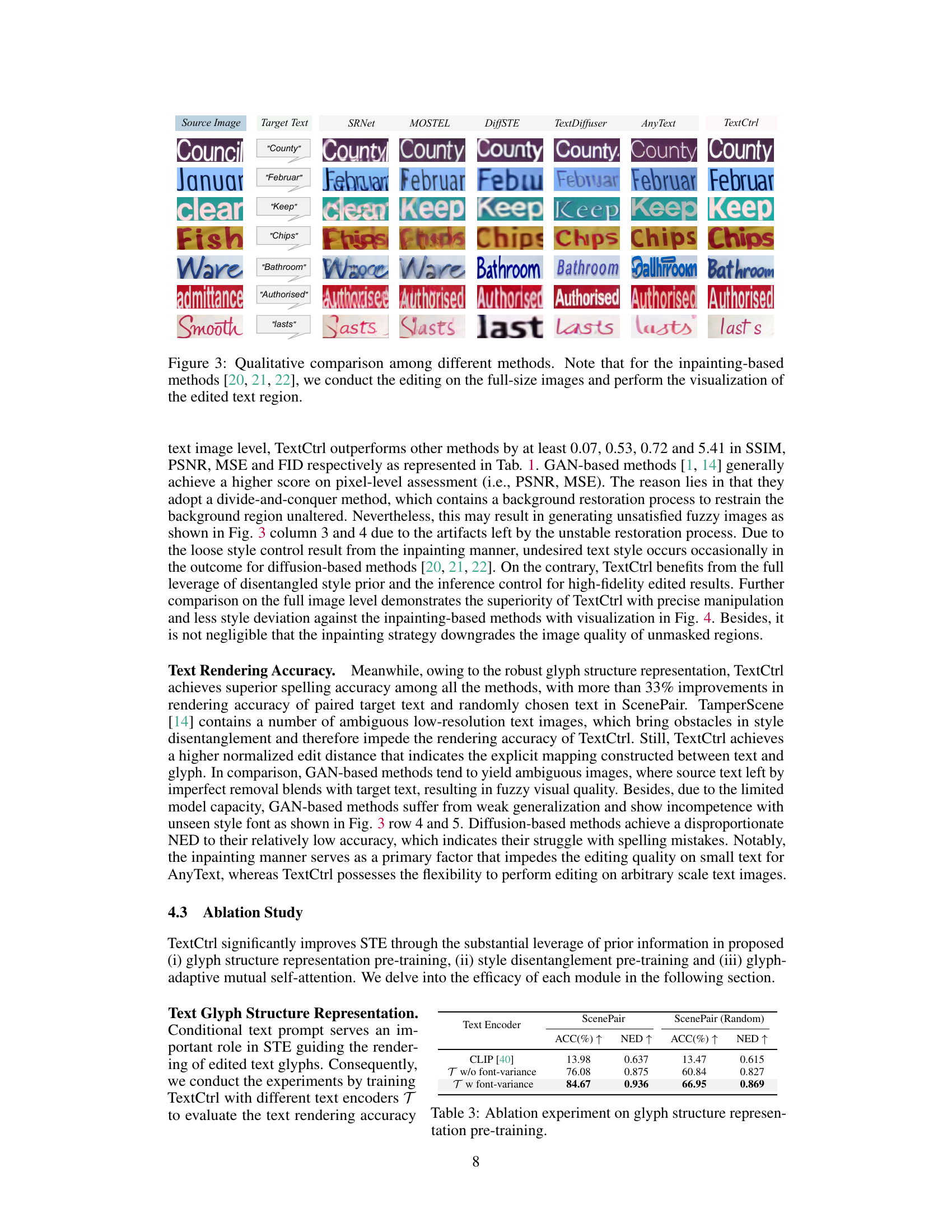
This figure shows a qualitative comparison of the results of different scene text editing methods, including SRNet, MOSTEL, DiffSTE, TextDiffuser, AnyText, and the proposed TextCtrl method. Each row demonstrates the results for a different input image and target text change. It highlights the variations in style preservation, text accuracy, and overall visual quality achieved by each method. The inpainting-based methods edit the full-size images, but only the edited text region is shown here for comparison.

This figure compares the results of four different methods (DiffSTE, TextDiffuser, AnyText, and TextCtrl) for scene text editing on three full-size images. Each row represents a different image and each column shows the results from a specific method. It demonstrates the visual differences between these methods, particularly regarding the accuracy of text rendering, style preservation, and overall image quality.

This figure visualizes the style feature embedding using t-SNE. It shows that text images with similar color cluster in different regions of feature space, indicating that the style representation captures the image entirety. A closer look reveals that text images sharing the same text style and background are clustered together, regardless of the specific text content, highlighting the effectiveness of the style disentanglement process.

This figure shows a qualitative comparison of text editing results with and without the Glyph-adaptive Mutual Self-Attention (GaMuSa) mechanism. It demonstrates the effectiveness of GaMuSa in improving background color consistency, text font quality, and glyph texture during the inference stage. Two rows of examples are given, the top row showing background color regulation, and the bottom row showing glyph texture improvement. In each row, the leftmost image is the source image, the middle image shows the result without GaMuSa, and the rightmost image shows the result with GaMuSa.
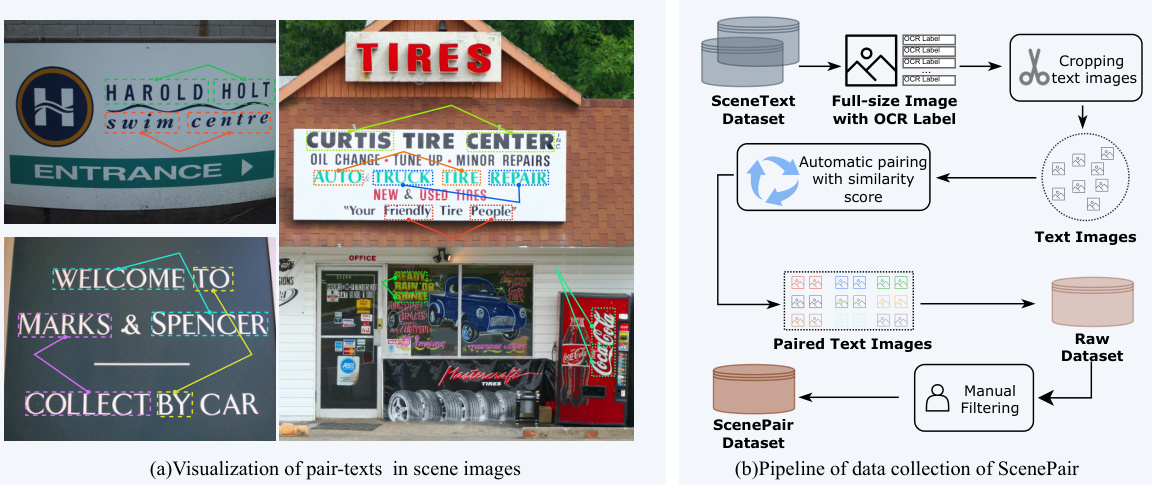
This figure illustrates the process of creating the ScenePair dataset. Part (a) shows an example of real-world signage where multiple text elements share similar styles, demonstrating the dataset’s basis. Part (b) is a flowchart detailing the dataset’s construction: starting with several scene text datasets, text regions are automatically identified and paired based on style similarity using an OCR (Optical Character Recognition) and a similarity algorithm. Manual review and filtering are then performed to curate the final ScenePair dataset.

This figure shows the architecture of the proposed TextCtrl model. It is decomposed into four parts: (a) a text glyph structure encoder that uses pre-trained glyph structure representation; (b) a text style encoder that uses pre-trained text style disentanglement; (c) a prior-guided diffusion generator that incorporates style and structure guidance; and (d) an improved inference control mechanism with glyph-adaptive mutual self-attention. Each component plays a crucial role in the scene text editing process.

This figure displays pairs of source and edited text images from the TamperScene dataset. The editing was performed using the TextCtrl model. Each pair shows the original text and the modified text, illustrating the model’s ability to accurately replace the text while maintaining the style and overall quality of the image.

This figure shows several examples of scene text editing results produced by the proposed TextCtrl model on images from the ICDAR 2013 dataset. It visually demonstrates the model’s ability to modify text within real-world scene images while preserving the overall visual style and context of the scene.

This figure shows examples where the TextCtrl model fails to accurately edit text, particularly text with complex shapes. The failures are attributed to insufficient geometric prior guidance during the text editing process. The images illustrate that while the model often successfully changes the text content, it struggles to maintain the original shape and style of the text, especially when it is curved or irregular.
More on tables
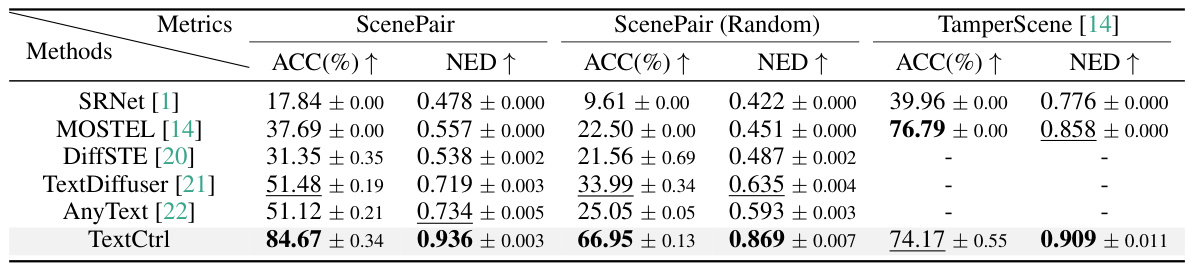
This table presents a comparison of different scene text editing (STE) methods on two datasets: ScenePair and TamperScene. The metrics used are text rendering accuracy (ACC) and normalized edit distance (NED). ScenePair is a new dataset of real-world image pairs, while TamperScene is an existing dataset. The ‘Random’ column in ScenePair shows results when the target text is replaced with random text to test model robustness. The table highlights the best and second-best performing methods for each metric and dataset.

This table presents the results of ablation experiments conducted to evaluate the impact of glyph structure representation pre-training on the performance of the TextCtrl model. Specifically, it compares the text rendering accuracy (ACC) and Normalized Edit Distance (NED) achieved by using different text encoders (CLIP, T without font-variance augmentation, and T with font-variance augmentation) on the ScenePair dataset and a randomized version of the ScenePair dataset.

This table presents the ablation study on the style disentanglement pre-training. It compares the performance of three different methods on the SSIM, MSE, and FID metrics: using ControlNet [31], using the proposed style encoder (S) without pre-training, and using the style encoder (S) with pre-training. The results demonstrate that using the proposed style encoder (S) with pre-training achieves the best performance across all metrics.
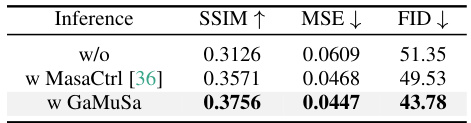
This table presents the ablation study on the inference enhancement method, Glyph-adaptive Mutual Self-Attention (GaMuSa). It compares the performance of three different inference methods: without any enhancement, with MasaCtrl [36], and with GaMuSa. The evaluation metrics used are SSIM, MSE, and FID. The results show that GaMuSa significantly improves the style fidelity and reduces visual inconsistencies during inference.

This table shows the number of parameters for each module in the TEXTCTRL model. The modules are the diffusion generator (G), the encoder-decoder VAE (ε), the text glyph structure encoder (T), the text style encoder (S), and the vision encoder (R). The total number of parameters in the model is 1216M.
Full paper#