↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Disentangled representation learning aims to extract underlying factors from data, a notoriously difficult task in unsupervised settings. Existing methods often rely on complex loss functions or specific architectural designs to achieve disentanglement, often with limited success. This often leads to less-than-satisfactory results and a need for new approaches that could improve learning and enhance the disentanglement capabilities.
This paper introduces EncDiff, a novel framework that uses diffusion models with cross-attention to learn disentangled representations. EncDiff leverages two inductive biases: the inherent information bottlenecks in the diffusion process and the cross-attention mechanism, acting as powerful tools. Without additional regularization, EncDiff outperforms existing methods on benchmark datasets, demonstrating its effectiveness and simplicity. This work has significant implications for future studies in disentangled representation learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates a novel approach to disentangled representation learning, a long-standing challenge in AI. By leveraging the inherent properties of diffusion models and cross-attention, it offers a simpler and more effective method, potentially spurring further research into diffusion models for various applications requiring interpretable and controllable data representations. It also challenges conventional wisdom by achieving superior results without complex regularization terms.
Visual Insights#

This figure shows average attention maps across all time steps during the stable diffusion process for text-to-image generation. The input is a sentence with semantically disentangled words (e.g., ‘dog’, ‘red’, ‘shirt’, ‘blue’, ‘bird’). The attention maps demonstrate a strong correlation between these words and specific spatial regions in the generated image. This suggests that the diffusion model’s cross-attention mechanism effectively integrates individual words into the generation process, leading the authors to investigate its potential for disentangled representation learning.
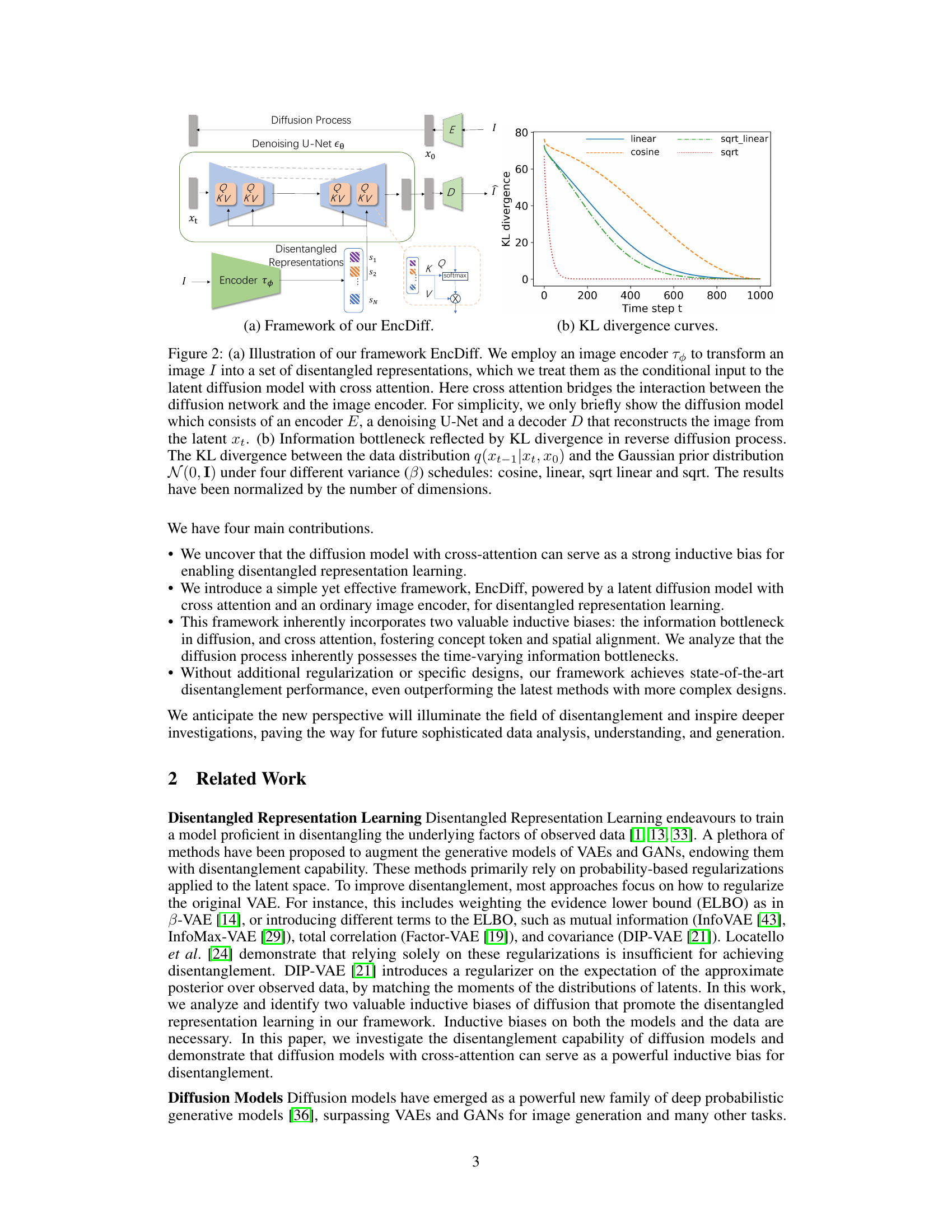
This table compares the disentanglement performance of the proposed EncDiff model against various state-of-the-art methods across three datasets (Cars3D, Shapes3D, MPI3D). Two metrics are used for evaluation: the FactorVAE score and the DCI metric. Higher scores indicate better disentanglement. The results show that EncDiff generally outperforms other methods, particularly on Shapes3D and MPI3D.
In-depth insights#
Cross-Attention Bias#
The concept of ‘Cross-Attention Bias’ in the context of disentangled representation learning using diffusion models is intriguing. It suggests that the inherent mechanism of cross-attention, when integrated within a diffusion model framework, acts as a powerful inductive bias promoting disentanglement. Cross-attention allows the model to directly relate encoded image features (often representing concepts or factors) to the different stages of the diffusion process. This direct relationship is crucial; it prevents the model from collapsing latent representations, thus helping it learn more distinct and independent factors. The time-varying nature of information bottlenecks within the diffusion process further strengthens this bias, as the model is forced to progressively refine its understanding of the factors during the denoising process. This framework, therefore, elegantly leverages the strengths of both diffusion models and cross-attention to achieve disentanglement without relying on complex regularization terms or loss functions. The authors’ exploration of this ‘bias’ suggests a potentially powerful new approach to disentangled representation learning, shifting the focus from explicitly designed loss functions to the inherent capabilities of the model architecture itself. Further research is warranted to explore the limits and generalizability of this ‘Cross-Attention Bias’ across diverse datasets and model architectures.
Diffusion’s Inductive Bias#
The concept of “Diffusion’s Inductive Bias” in the context of disentangled representation learning is a novel and insightful contribution. It posits that the inherent properties of diffusion models, particularly the time-varying information bottleneck created during the forward diffusion process, act as a powerful inductive bias promoting disentanglement. This bias is further amplified by the use of cross-attention, which facilitates the alignment of concept tokens with spatial features in the image. The combination of these two factors leads to superior disentanglement performance without the need for explicit regularization terms, as demonstrated by the success of the EncDiff framework. This is significant because it challenges the conventional approach of relying heavily on complex loss functions and architectural designs to achieve disentanglement, suggesting a more elegant and potentially efficient path. Furthermore, the analysis of the time-varying information bottleneck offers a valuable theoretical understanding of how the diffusion process intrinsically guides the model towards disentangled representations. This inductive bias approach opens up exciting avenues for future research to explore the potential of diffusion models in other challenging machine learning problems, paving the way for simpler, yet more effective models.
EncDiff Framework#
The EncDiff framework presents a novel approach to disentangled representation learning by leveraging the inherent properties of diffusion models and cross-attention. It uniquely positions cross-attention as a bridge between an image encoder and the U-Net of a diffusion model. The encoder transforms an input image into a set of concept tokens, which serve as a condition for the diffusion process. This design is inspired by text-to-image generation, where disentangled word embeddings condition the generation process. EncDiff cleverly harnesses two key inductive biases: the inherent time-varying information bottleneck within the diffusion process and the cross-attention mechanism itself, which fosters alignment between semantic concept tokens and spatial image features. This framework achieves state-of-the-art disentanglement performance without explicit regularization terms, highlighting the power of the proposed inductive biases. The simplicity and effectiveness of EncDiff suggest a significant advancement in the field, paving the way for more sophisticated data analysis through disentangled representations.
Disentanglement Results#
A thorough analysis of disentanglement results would involve a multi-faceted approach. It would begin by assessing the quantitative metrics employed, such as the FactorVAE score and DCI, acknowledging their limitations and strengths in capturing different aspects of disentanglement. Qualitative evaluations, including visualizations of the latent space and generated samples, are crucial for understanding the nature of disentanglement achieved. A comparison to state-of-the-art methods is essential to benchmark performance and highlight any improvements or novel aspects. Examining the specific datasets used is vital; results on simple datasets might not generalize well to complex real-world scenarios. Finally, a robust analysis would discuss the inductive biases leveraged by the model. The investigation must also involve the impact of different hyperparameter settings, training methodologies and architectural designs on the disentanglement performance.
Future of Diffusion#
The future of diffusion models is incredibly promising, driven by ongoing research and development. Improved efficiency and scalability are key areas of focus, making these models practical for broader applications. Researchers are exploring novel architectures and training techniques to enhance performance and address current limitations, such as the computational cost of high-resolution generation. Controllability and interpretability are also crucial aspects of future work; enabling more fine-grained control over the generation process and understanding the internal representations of these models will unlock entirely new capabilities. We can expect to see diffusion models integrated into more complex systems and workflows, acting as fundamental building blocks for sophisticated applications in areas like image editing, 3D modeling, and scientific data analysis. The combination of diffusion models with other techniques, such as GANs or VAEs, presents further avenues for exploration and potentially synergistic advancements. Finally, ethical considerations are paramount, addressing potential biases and misuse of these powerful generative models.
More visual insights#
More on figures
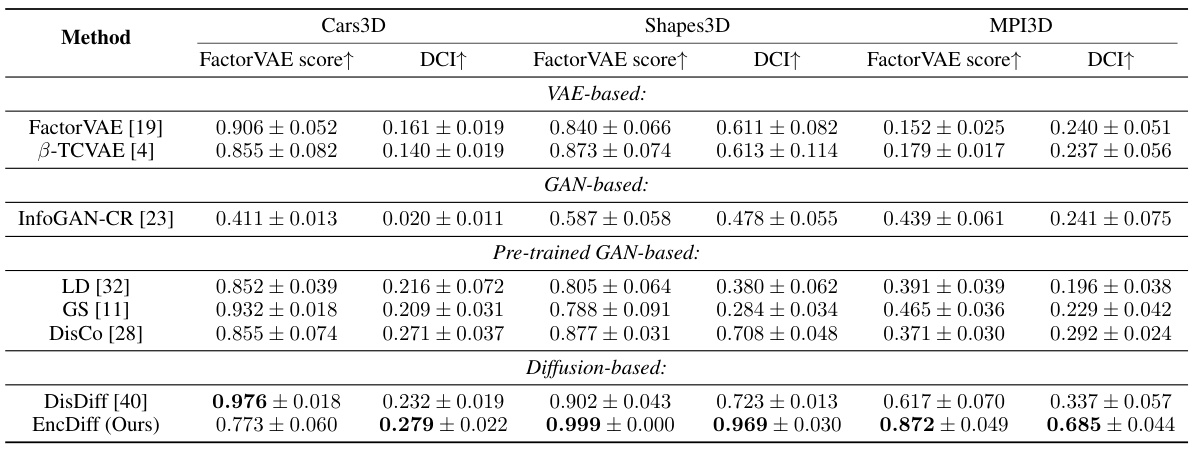
This figure illustrates the EncDiff framework, showing how an image encoder produces disentangled representations that condition a latent diffusion model with cross-attention for image reconstruction. The cross-attention mechanism bridges the encoder and the U-Net within the diffusion model. The second part of the figure displays KL divergence curves demonstrating the time-varying information bottlenecks inherent in the reverse diffusion process under various variance schedules.
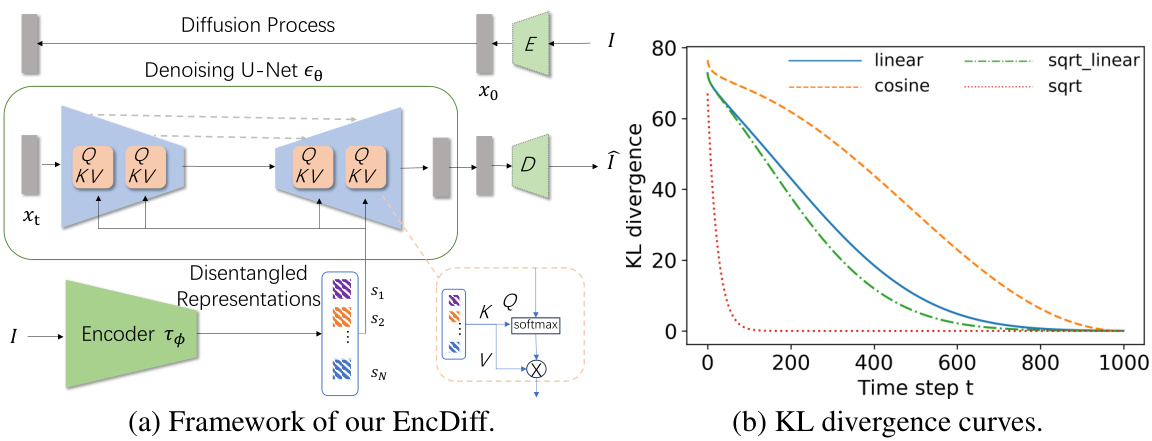
This figure illustrates the image encoder architecture used in the EncDiff framework. The encoder takes an image as input and transforms it into a feature vector of dimension N. Each dimension of this feature vector represents a disentangled factor. The encoder uses separate, three-layer MLPs to map each scalar disentangled factor into a higher-dimensional vector, called a ‘concept token’. These concept tokens are then used as the conditional input to the latent diffusion model, acting as a bridge between the encoder and the U-Net within the diffusion model.
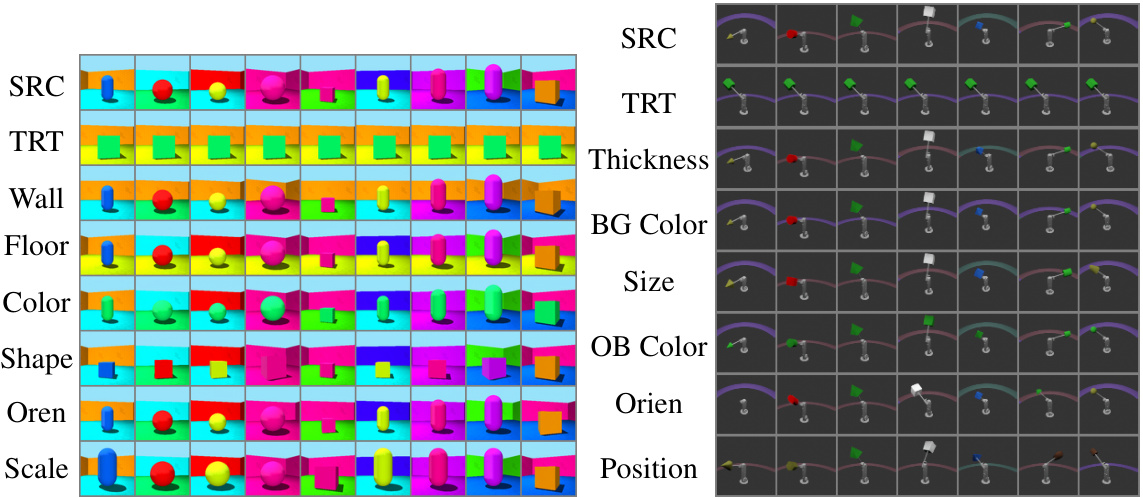
This figure demonstrates the disentanglement capability of the EncDiff model on the Shapes3D and MPI3D datasets. It shows the results of swapping different factors (like color, shape, orientation, etc.) between source and target images. By changing a specific factor’s representation, the model generates new images with only that factor changed, demonstrating its ability to isolate and manipulate individual latent variables.

This figure visualizes the cross-attention maps generated by the EncDiff model on the Shapes3D and MPI3D datasets. Each row represents a different image. The first column shows the original image, while subsequent columns display attention maps for different concept tokens (e.g., Wall color, Floor color, Shape, Orientation, Scale, Position). The attention maps highlight which parts of the image are most relevant to each concept token, illustrating how the model disentangles different factors within the image. Appendix F contains additional visualizations.
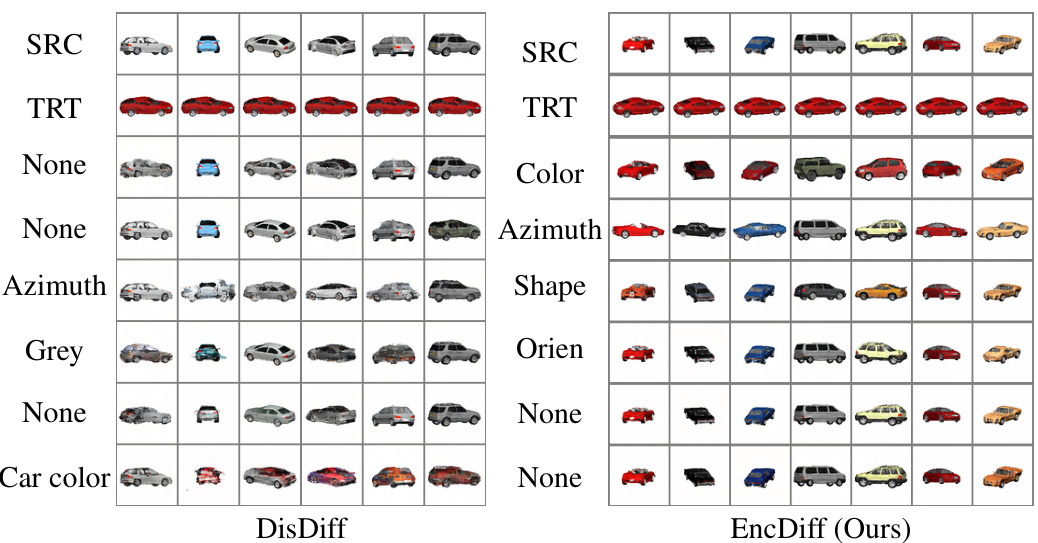
This figure compares the qualitative results of DisDiff and EncDiff on the Cars3D dataset. It shows how manipulating the representation of different factors (color, azimuth, shape, orientation) affects the generated images. EncDiff demonstrates a better ability to isolate and control these factors than DisDiff.

This figure shows the qualitative results of disentanglement on the Shapes3D and MPI3D datasets. It demonstrates the ability of the EncDiff model to isolate and manipulate individual factors of the generated images. By swapping the representation of a specific factor (e.g., color, shape, orientation) between two source images, the model generates new images reflecting the changes made to that specific factor, proving the disentanglement of these latent variables.

This figure visualizes the cross-attention maps generated by the EncDiff model on the Shapes3D and MPI3D datasets. Each row represents a different image. The first column shows the original image. The subsequent columns display the attention masks for each concept token (e.g., Wall, Floor, Color, Shape, Orientation, Scale, Position, Thickness, BG Color, OB Color, Size). The heatmaps indicate the attention weights assigned to different spatial locations by the model for each concept token, highlighting the alignment between concept tokens and spatial regions. This demonstrates the model’s ability to disentangle different factors by effectively bridging image features with concept tokens through cross-attention. See Appendix F for additional examples.
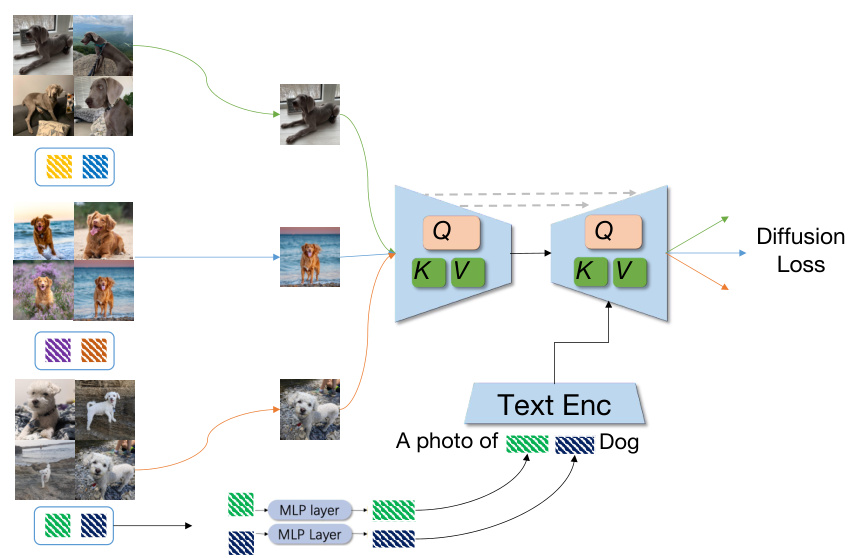
This figure illustrates the architecture of EncDiff applied to DreamBooth, referred to as EncDiff(SD). It shows how EncDiff is adapted to disentangle different concepts or properties (like color, long-hair, big-eared) from images of dogs. Instead of using a complete image as input, the model takes semantic representations (text tokens) extracted from images. These tokens are processed through multiple MLP layers to create concept tokens that are then used as input for the cross-attention mechanism within the stable diffusion model. The output is a disentangled representation, allowing for independent control over different image features during generation.
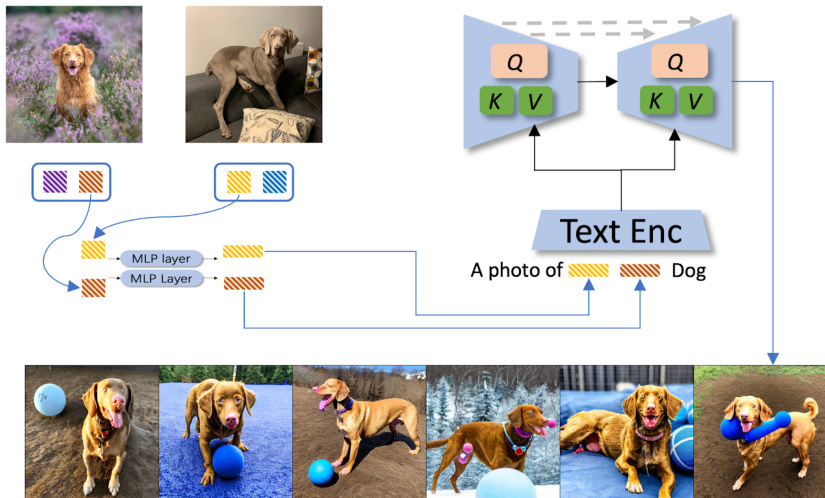
This figure illustrates the architecture of EncDiff applied to DreamBooth, denoted as EncDiff(SD). EncDiff(SD) uses a pre-trained Stable Diffusion model as its base. To disentangle concepts within the images, it employs an image encoder that extracts features. These features are then passed through multiple MLP layers to produce concept tokens. These tokens are used as conditional inputs to the Stable Diffusion model. Cross-attention mechanisms are utilized to integrate the concept tokens into the diffusion process for image generation, enabling the disentanglement of concepts during the process. The example shows using a combination of different properties to create novel images using the disentangled features.

This figure shows average attention maps across all time steps during stable diffusion’s text-to-image generation process. The use of disentangled words as input conditions highlights how cross-attention maps show strong semantic and spatial alignment. This suggests the model successfully integrates individual words, leading the authors to explore if this diffusion structure promotes disentangled representation learning.

This figure shows average attention maps across all time steps during the stable diffusion process. The authors used highly disentangled words as input conditions for image generation. The resulting cross-attention maps show a strong alignment between the text semantics and the spatial layout of the generated images. This observation leads the authors to hypothesize that the diffusion model’s structure, with its cross-attention mechanism, could serve as an inductive bias for learning disentangled representations.

This figure shows average attention maps across all time steps during stable diffusion’s text-to-image generation process. The use of disentangled words as input conditions results in attention maps demonstrating a strong alignment between the word semantics and the spatial locations in the generated image. This observation suggests that the diffusion model’s architecture, particularly the cross-attention mechanism, might inherently promote disentangled representation learning.
More on tables
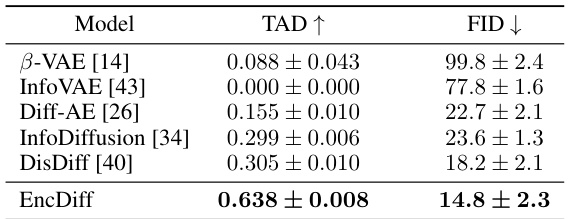
This table presents a comparison of the disentanglement performance and image generation quality of EncDiff against several baseline models on the CelebA dataset. The metrics used are TAD (a disentanglement metric) and FID (a measure of image quality). The results show that EncDiff outperforms all other methods, demonstrating its superior performance in both disentangling underlying factors and generating high-quality images.
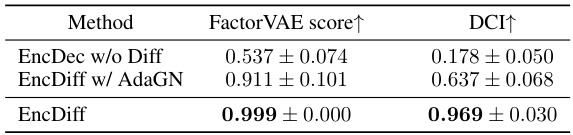
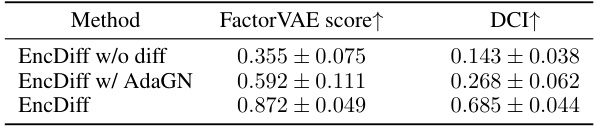
This table presents the ablation study results on the impact of the two inductive biases (diffusion model and cross-attention) in the proposed EncDiff framework. It compares the performance of EncDiff with three variants: one removing the diffusion process, another replacing cross-attention with Adaptive Group Normalization (AdaGN), and finally the full EncDiff model. The results are measured using the FactorVAE score and DCI metric, which assess the disentanglement quality of the learned representations. The comparison demonstrates the significance of both inductive biases for achieving high-quality disentanglement.

This table presents the results of an ablation study investigating the impact of different variance schedules on the performance of the EncDiff model. Four variance schedules—sqrt, cosine, linear, and sqrt linear—were tested, and their effects on the FactorVAE score and DCI disentanglement metrics are reported. The results show how the choice of variance schedule influences the model’s ability to learn disentangled representations.

This table compares the disentanglement performance of EncDiff against several state-of-the-art methods on three datasets (Cars3D, Shapes3D, and MPI3D). Two metrics are used for evaluation: FactorVAE score and DCI. Higher scores indicate better disentanglement. The results show that EncDiff significantly outperforms other methods in most cases, demonstrating its effectiveness in learning disentangled representations.

This ablation study compares the disentanglement performance of EncDiff when applied to the pixel space versus the latent space. The results show the FactorVAE score and DCI metrics for both scenarios, demonstrating that the performance is robust regardless of the space used. The high scores in both cases indicate strong disentanglement capability in both pixel and latent diffusion implementations.
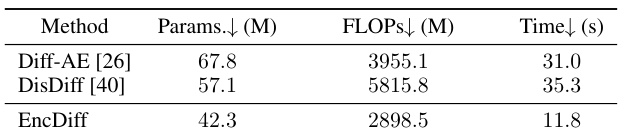
This table compares the performance of the proposed EncDiff model against various state-of-the-art methods for disentangled representation learning on three benchmark datasets (Cars3D, Shapes3D, MPI3D). The comparison uses two metrics: FactorVAE score and DCI, both of which measure the degree of disentanglement achieved by the different models. Higher scores indicate better disentanglement. The results demonstrate that EncDiff significantly outperforms most existing methods.

This table presents a comparison of the disentanglement performance of the proposed EncDiff model against several state-of-the-art methods on three benchmark datasets (Cars3D, Shapes3D, and MPI3D). The comparison is based on two metrics: the FactorVAE score and the DCI (Disentanglement-CI) metric. Higher scores indicate better disentanglement. The results show that EncDiff significantly outperforms other methods in most cases, demonstrating its effectiveness in learning disentangled representations.
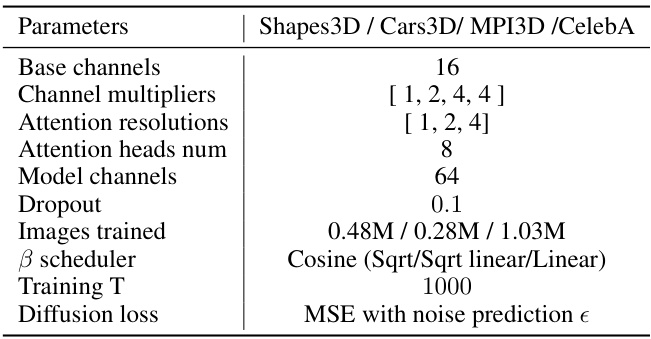
This table details the architecture of the U-Net used in the EncDiff model. It specifies parameters such as the number of base channels, channel multipliers, attention resolutions, attention heads, model channels, dropout rate, number of images used for training, beta scheduler used, number of training steps (T), and the loss function used for training the diffusion model.

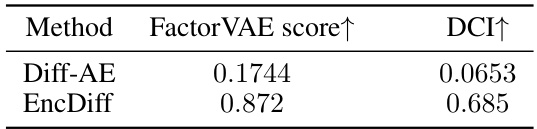
This table compares the reconstruction quality of different methods (PDAE, Diff-AE, DisDiff, and EncDiff) on the Shapes3D dataset. The metrics used for comparison are SSIM (structural similarity index), LPIPS (learned perceptual image patch similarity), MSE (mean squared error), DCI (disentanglement metric), and FactorVAE (disentanglement metric). Higher SSIM and DCI scores, and lower LPIPS and MSE values indicate better reconstruction quality and disentanglement. EncDiff achieves the best performance across most metrics.

This table compares the performance of EncDiff using two different methods for obtaining the token representations: a scalar-valued approach and a vector-valued approach. The results show the FactorVAE score and DCI metrics for both methods, indicating that the scalar-valued approach achieves slightly better results. This suggests that the scalar method may be more efficient or effective for disentanglement than the vector-valued method.
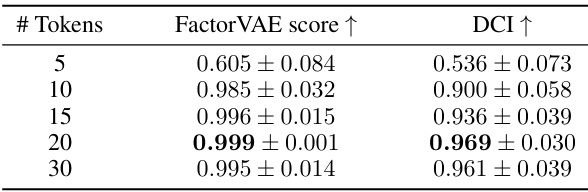
This table compares the performance of the proposed EncDiff model against several state-of-the-art methods for disentangled representation learning on three benchmark datasets (Cars3D, Shapes3D, MPI3D). The comparison uses two metrics: the FactorVAE score and the DCI score. Higher scores indicate better disentanglement. EncDiff shows superior performance compared to other methods on most datasets.
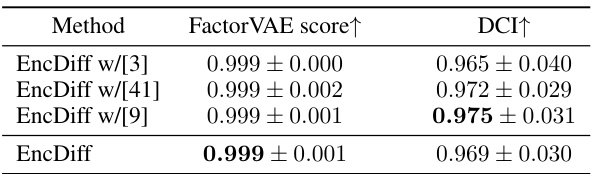
This table presents the results of an ablation study on the effect of adding different regularization methods to the EncDiff model. The baseline model is EncDiff with a CNN encoder. Three additional regularization techniques are investigated: orthogonality from [3], sparsity from [9], and another orthogonality constraint using matrix decomposition from [41]. The table shows that while additional regularization slightly improves performance, it does not significantly change the results. The best-performing model remains EncDiff without any additional regularization.
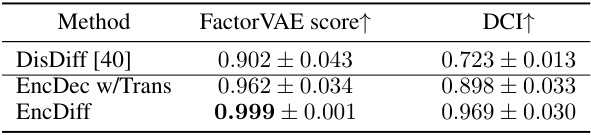
This table compares the performance of EncDiff against other state-of-the-art methods for disentanglement on three benchmark datasets (Cars3D, Shapes3D, and MPI3D). Two metrics are used: FactorVAE score and DCI. Higher scores indicate better disentanglement. EncDiff significantly outperforms existing methods in most cases.
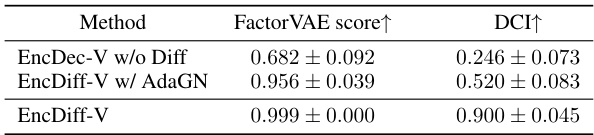
This table compares the disentanglement performance of the proposed EncDiff model against several state-of-the-art methods on three benchmark datasets (Cars3D, Shapes3D, MPI3D). The comparison is done using two metrics: the FactorVAE score and the DCI score. Higher scores indicate better disentanglement. The results show that EncDiff generally outperforms other methods, achieving a significant margin in most cases, except for the Cars3D dataset.
This table compares the disentanglement performance of the proposed EncDiff model against various state-of-the-art methods using two metrics: FactorVAE score and DCI. Higher scores indicate better disentanglement. The results are presented as mean ± standard deviation across multiple runs. EncDiff demonstrates significantly better performance than most other methods, except for the Cars3D dataset.

This table compares the performance of the proposed EncDiff model against various state-of-the-art methods for disentangled representation learning on three benchmark datasets (Cars3D, Shapes3D, and MPI3D). The comparison uses two metrics: the FactorVAE score and the DCI (Disentanglement, Completeness, and Informativeness) score. Higher scores indicate better disentanglement performance. The results demonstrate that EncDiff significantly outperforms previous methods in most cases, showcasing its effectiveness as a strong inductive bias for promoting disentanglement.

This table compares the performance of EncDiff against several state-of-the-art methods for disentangled representation learning on three datasets (Cars3D, Shapes3D, MPI3D). The comparison uses two metrics: the FactorVAE score and the DCI score. Higher scores indicate better disentanglement. The table shows that EncDiff significantly outperforms other methods on two of the three datasets, demonstrating its effectiveness in learning disentangled representations.
This table compares the disentanglement performance of EncDiff against several state-of-the-art methods using two metrics: FactorVAE score and DCI. The results are shown for three datasets: Cars3D, Shapes3D, and MPI3D. Higher scores indicate better disentanglement. EncDiff generally outperforms other methods, except on the Cars3D dataset.
Full paper#